Tamaño del índice vectorial y mantenimiento por debajo de los límites
Para cada campo vectorial, Azure AI Search construye un índice de vector interno mediante los parámetros de algoritmo especificados en el campo. Dado que Azure AI Search impone cuotas en el tamaño del índice vectorial, debe saber cómo calcular y supervisar el tamaño del vector para asegurarse de que permanece bajo los límites.
Nota:
Nota sobre la terminología. Internamente, las estructuras de datos físicas de un índice de búsqueda incluyen contenido sin procesar (que se usa para patrones de recuperación que requieren contenido no tokenizado), índices invertidos (usados para campos de texto que se pueden buscar) e índices vectoriales (usados para campos vectoriales que se pueden buscar). En este artículo se explican los límites de los índices de vectores internos que respaldan cada uno de los campos vectoriales.
Sugerencia
Las técnicas de optimización de vectores ahora están disponibles con carácter general. Use funcionalidades como tipos de datos estrechos, cuantificación escalar y binaria, y eliminación del almacenamiento redundante para mantenerse bajo la cuota de vectores y la cuota de almacenamiento.
Puntos clave sobre la cuota y el tamaño del índice de vector
El tamaño del índice vectorial se mide en bytes.
Las cuotas de vector se basan en restricciones de memoria. Todos los índices vectoriales que se pueden buscar deben cargarse en la memoria. Al mismo tiempo, también debe haber suficiente memoria para otras operaciones en tiempo de ejecución. Existen cuotas de vectores para asegurarse de que el sistema general permanece estable y equilibrado para todas las cargas de trabajo.
Los índices vectoriales también están sujetos a la cuota de disco, en el sentido de que todos los índices están sujetos a la cuota de disco. No hay ninguna cuota de disco independiente para los índices vectoriales.
Las cuotas de vectores se aplican en el servicio de búsqueda en su conjunto, por partición, lo que significa que si agrega particiones, la cuota de vectores aumenta. Las cuotas de vectores por partición son mayores en los servicios más recientes. Para obtener más información, consulte Límites de tamaño del índice de vectores.
Cómo comprobar el tamaño y la cantidad de particiones
Si no está seguro de cuáles son los límites del servicio de búsqueda, estas son dos maneras de obtener esa información:
En Azure Portal, en la página de información general del servicio de búsqueda, tanto la pestaña Propiedades como la pestaña Uso muestran el tamaño de particiones y el almacenamiento, así como el tamaño de cuota de vectores y el tamaño del índice de vectores.
En Azure Portal, en la página Escalado, puede revisar el número y el tamaño de las particiones.
Comprobación de la fecha de creación del servicio
Los servicios más recientes creados después del 3 de abril de 2024 ofrecen cinco a diez veces más almacenamiento de vectores que los más antiguos con la misma tarifa de facturación de nivel. Si el servicio es anterior, considere la posibilidad de crear un nuevo servicio y migrar el contenido.
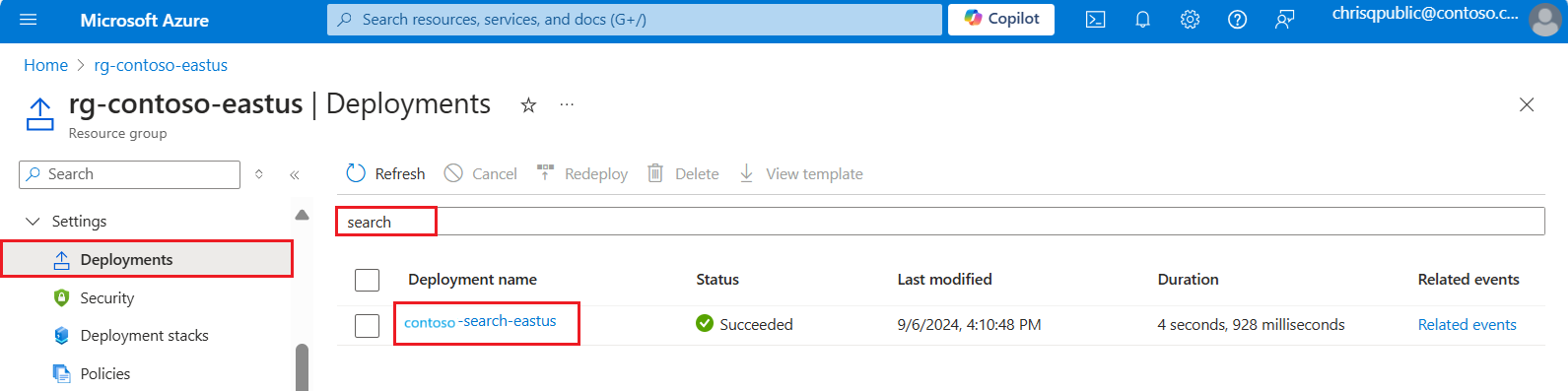
En Azure Portal, abra el grupo de recursos que contiene el servicio de búsqueda.
En el panel izquierdo, en Configuración, seleccione Implementaciones.
Busque la implementación del servicio de búsqueda. Si hay muchas implementaciones, use el filtro para buscar "search".
Seleccione la implementación. Si tiene más de una, haga clic para ver si se resuelve en el servicio de búsqueda.
Expanda los detalles de la implementación. Debería ver Creado y la fecha de creación.
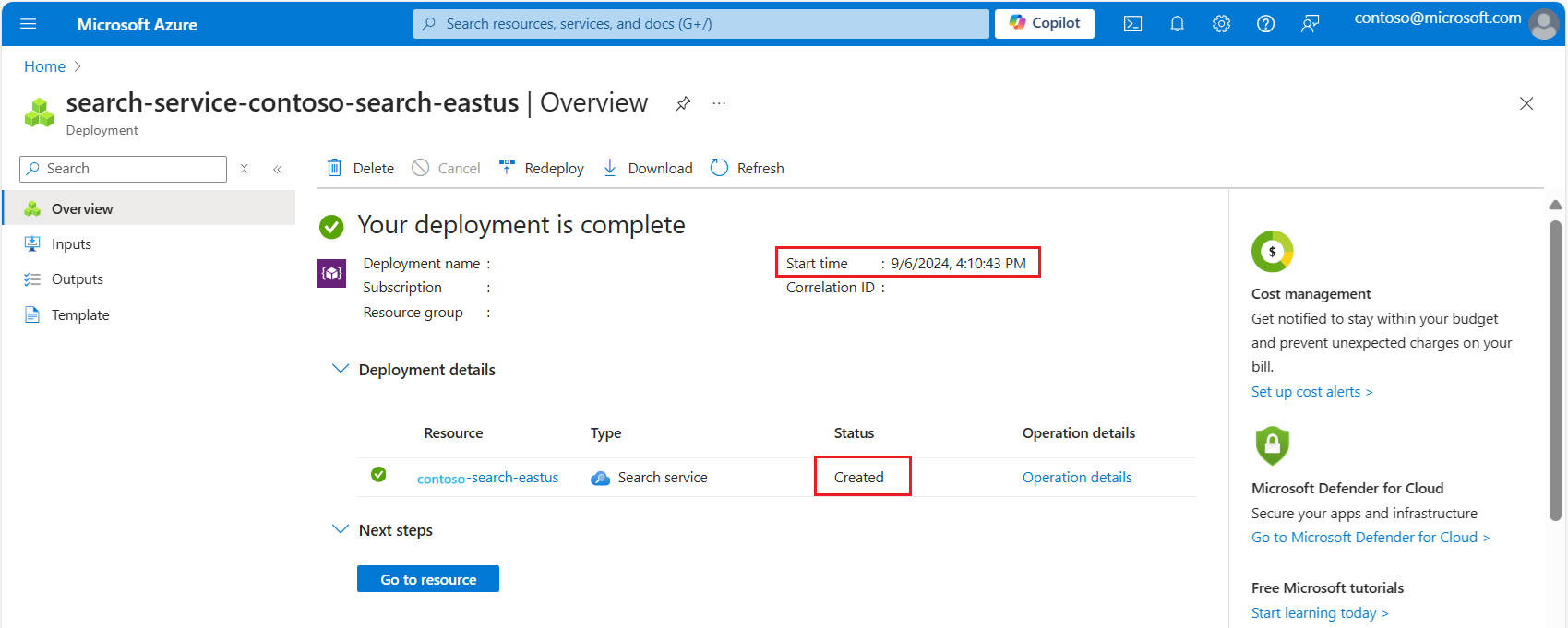
Ahora que conoce la antigüedad del servicio de búsqueda, revise los límites de cuota de vectores en función de la creación del servicio: Límites de tamaño del índice de vectores.


Cómo obtener el tamaño del índice vectorial
Una solicitud de métricas vectoriales es una operación del plano de datos. Puede usar Azure Portal, las API REST o los SDK de Azure para obtener el uso de vectores en el nivel de servicio mediante estadísticas de servicio y para índices individuales.
La información de uso se puede encontrar en la página Información generalde la pestaña Uso. Las páginas del portal se actualizan cada pocos minutos, por lo que si ha actualizado recientemente un índice, espere un poco antes de comprobar los resultados.
La siguiente captura de pantalla es para un servicio de búsqueda estándar 1 (S1) anterior, configurado para una partición y una réplica.
- La cuota de almacenamiento es una restricción de disco e incluye todos los índices (vectoriales y no vectoriales) de un servicio de búsqueda.
- La cuota de tamaño del índice vectorial es una restricción de memoria. Es la cantidad de memoria necesaria para cargar todos los índices vectoriales internos creados para cada campo vectorial de un servicio de búsqueda.
La captura de pantalla indica que los índices (vectoriales y no vectoriales) consumen casi 460 megabytes de almacenamiento disponible en disco. Los índices vectoriales consumen casi 93 megabytes de memoria en el nivel de servicio.

Las cuotas para el tamaño del índice de almacenamiento y vector aumentan o reducen a medida que se agregan o quitan particiones. Si cambia el recuento de particiones, el icono muestra un cambio correspondiente en la cuota de almacenamiento y vector.
Nota:
En el disco, los índices vectoriales no son 93 megabytes. Los índices vectoriales del disco ocupan aproximadamente tres veces más espacio que los índices vectoriales en memoria. Consulte Cómo afectan los campos vectoriales al almacenamiento en disco para obtener más detalles.
Factores que afectan al tamaño del índice vectorial
Hay tres componentes principales que afectan al tamaño del índice vectorial interno:
- Tamaño sin procesar de los datos
- Sobrecarga del algoritmo seleccionado
- Sobrecarga de eliminar o actualizar los documentos dentro del índice
Tamaño sin procesar de los datos
Cada vector suele ser una matriz de números de punto flotante de precisión sencilla en un campo de tipo Collection(Edm.Single).
Las estructuras de datos vectoriales requieren almacenamiento, representado en el siguiente cálculo como el "tamaño sin procesar" de los datos. Use este tamaño sin procesar para calcular los requisitos de tamaño del índice vectorial de los campos vectoriales.
El tamaño de almacenamiento de un vector viene determinado por su dimensionalidad. Multiplique el tamaño de un vector por el número de documentos que contienen ese campo vectorial para obtener el tamaño sin procesar:
raw size = (number of documents) * (dimensions of vector field) * (size of data type)
| Tipo de datos EDM | Tamaño del tipo de datos |
|---|---|
Collection(Edm.Single) |
4 bytes |
Collection(Edm.Half) |
2 bytes |
Collection(Edm.Int16) |
2 bytes |
Collection(Edm.SByte) |
1 byte |
Sobrecarga de memoria del algoritmo seleccionado
Cada algoritmo de vecino más cercano (ANN) aproximado genera estructuras de datos adicionales en memoria para permitir una búsqueda eficaz. Estas estructuras consumen espacio adicional dentro de la memoria.
Para el algoritmo HNSW, la sobrecarga de memoria oscila entre el 1 % y el 20 %.
La sobrecarga de memoria es menor para las dimensiones más altas porque aumenta el tamaño sin procesar de los vectores, mientras que las estructuras de datos adicionales siguen siendo un tamaño fijo, ya que almacenan información sobre la conectividad dentro del grafo. Por lo tanto, la contribución de las estructuras de datos adicionales constituye una parte más pequeña del tamaño general.
La sobrecarga de memoria es mayor para los valores más grandes del parámetro HNSW m, que determina el número de vínculos bidireccionales creados para cada nuevo vector durante la construcción del índice. Esto se debe a que m contribuye aproximadamente con entre 8 bytes y 10 bytes por documento multiplicado por m.
En la tabla siguiente se resumen los porcentajes de sobrecarga observados en las pruebas internas:
| Dimensiones | Parámetro HNSW (m) | Porcentaje de sobrecarga |
|---|---|---|
| 96 | 4 | 20% |
| 200 | 4 | 8 % |
| 768 | 4 | %2 |
| 1536 | 4 | %1 |
| 3072 | 4 | 0,5 % |
Estos resultados muestran la relación entre las dimensiones, el parámetro HNSW m y la sobrecarga de memoria para el algoritmo HNSW.
Sobrecarga de eliminar o actualizar los documentos dentro del índice
Cuando un documento con un campo vectorial se elimina o actualiza (las actualizaciones se representan internamente como una operación de eliminación e inserción), el documento subyacente se marca como eliminado y omitido durante las consultas posteriores. A medida que se indexan nuevos documentos y crece el índice vectorial interno, el sistema limpia estos documentos eliminados y reclama los recursos. Esto significa que probablemente observarás un retraso entre la eliminación de documentos y los recursos subyacentes que se liberan.
Nos referimos a esto como la relación de documentos eliminados. Dado que la relación de documentos eliminados depende de las características de indexación del servicio, no hay un método heurístico universal para calcular este parámetro y no hay ninguna API o script que devuelva la relación que se aplica en el servicio. Observamos que la mitad de nuestros clientes tienen una relación de documentos eliminados inferior al 10 %. Si tiendes a realizar eliminaciones o actualizaciones de alta frecuencia, es posible que observes una mayor proporción de documentos eliminados.
Este es otro factor que afecta al tamaño del índice vectorial. Desafortunadamente, no tenemos un mecanismo para exponer la relación de documentos eliminados actual.
Estimación del tamaño total de los datos en memoria
Teniendo en cuenta los factores descritos anteriormente, para calcular el tamaño total del índice vectorial, use el siguiente cálculo:
(raw_size) * (1 + algorithm_overhead (in percent)) * (1 + deleted_docs_ratio (in percent))
Por ejemplo, para calcular el raw_size, supongamos que usas un modelo popular de Azure OpenAI, text-embedding-ada-002 con 1536 dimensiones. Esto significa que un documento consumiría 1536 Edm.Single (floats) o 6144 bytes, ya que cada Edm.Single es de 4 bytes. 1000 documentos con un único campo vectorial y 1536 dimensiones consumiría en total 1000 documentos x 1536 floats/doc = 1 536 000 floats o 6 144 000 bytes.
Si tienes varios campos vectoriales, debes realizar este cálculo para cada campo vectorial dentro del índice y sumarlos todos juntos. Por ejemplo, 1000 documentos con dos campos vectoriales de 1536 dimensiones consumen 1000 documentos x 2 campos x 1536 floats/doc x 4 bytes/float = 12 288 000 bytes.
Para obtener el tamaño del índice vectorial, multiplica este raw_size por la sobrecarga del algoritmo y la proporción de documentos eliminados. Si la sobrecarga del algoritmo para los parámetros HNSW elegidos es del 10 % y la proporción de documentos eliminada es del 10 %, obtenemos: 6.144 MB * (1 + 0.10) * (1 + 0.10) = 7.434 MB.
Cómo afectan los campos vectoriales al almacenamiento en disco
La mayoría de este artículo proporciona información sobre el tamaño de los vectores en memoria. Si desea conocer el tamaño del vector en el disco, el consumo de disco para los datos vectoriales es aproximadamente tres veces el tamaño del índice de vectores en memoria. Por ejemplo, si el uso del vectorIndexSize es de 100 megabytes (10 millones de bytes), habría usado al menos 300 megabytes de cuota storageSize para acomodar los índices vectoriales.