Inicio rápido: Vectorización de texto e imágenes mediante Azure Portal
Este inicio rápido le ayuda dar sus primeros pasos en la vectorización integrada mediante el asistente para Importación y vectorización de datos en Azure Portal. El asistente fragmenta el contenido y llama a un modelo de inserción para vectorizar el contenido durante la indexación y para las consultas.
Requisitos previos
Suscripción a Azure. cree una de forma gratuita.
Un servicio de Búsqueda de Azure AI en la misma región que Azure AI. Se recomienda el nivel Básico o superior.
Un origen de datos compatible con los documentos de ejemplo del archivo PDF del plan de mantenimiento.
Familiaridad con el asistente. Consulte Asistente para la importación de datos en Azure Portal para más información.
Orígenes de datos admitidos
El asistente Importación y vectorización de datos admite una amplia gama de orígenes de datos de Azure, pero en este inicio rápido se proporcionan pasos solo para los orígenes de datos que funcionan con archivos completos:
Azure Blob Storage para blobs y tablas. Azure Storage debe ser una cuenta de rendimiento estándar (v2 de uso general). Los niveles de acceso pueden ser frecuente, esporádico y frío.
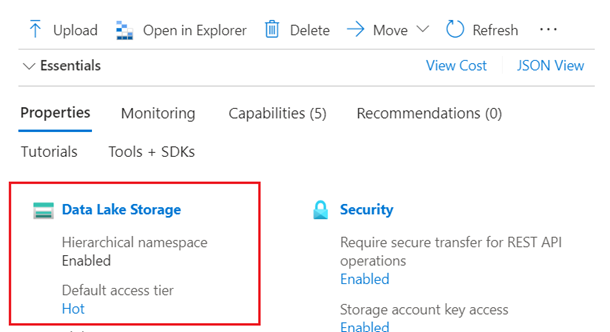
Azure Data Lake Storage (ADLS) Gen2 (una cuenta de Azure Storage con un espacio de nombres jerárquico habilitado). Puede confirmar que tiene Data Lake Storage comprobando la pestaña Propiedades de la página Información general.
Modelos de inserción compatibles
Use un modelo de inserción en una plataforma de Azure AI en la misma región que Búsqueda de Azure AI. Las instrucciones de implementación se encuentran en este artículo.
| Proveedor | Modelos admitidos |
|---|---|
| Azure OpenAI Service | text-embedding-ada-002 text-embedding-3-large text-embedding-3-small |
| Catálogo de modelos de Azure AI Foundry | Para texto: Cohere-embed-v3-english Cohere-embed-v3-multilingual Para imágenes: Facebook-DinoV2-Image-Embeddings-ViT-Base Facebook-DinoV2-Image-Embeddings-ViT-Giant |
| Cuenta de varios servicios de Azure AI | Capacidad multimodal de Visión de Azure AI para la vectorización de texto e imágenes, disponible en regiones seleccionadas. En función de cómo conecte el recurso multiservicio, es posible que la cuenta multiservicio tenga que estar en la misma región que Búsqueda de Azure AI. |
Si usa Azure OpenAI Service, el punto de conexión debe tener un subdominio personalizado asociado. Un subdominio personalizado es un punto de conexión que incluye un nombre único (por ejemplo, https://hereismyuniquename.cognitiveservices.azure.com). Si el servicio se creó a través de Azure Portal, este subdominio se genera automáticamente como parte de la configuración del servicio. Asegúrese de que el servicio incluye un subdominio personalizado antes de usarlo con la integración de la Búsqueda de Azure AI.
Los recursos de Azure OpenAI Service (con acceso a modelos de inserción) que se crearon en el portal AI Foundry no son compatibles. Solo los recursos de Azure OpenAI Service creados en Azure Portal son compatibles con la integración de aptitudes de Incrustación de Azure OpenAI.
Requisitos de punto de conexión público
Para este inicio rápido, todos los recursos anteriores deben tener habilitado el acceso público para que los nodos de Azure Portal puedan acceder a ellos. De lo contrario, se produce un error en el asistente. Una vez que se ejecute el asistente, puede habilitar firewalls y puntos de conexión privados en los componentes de integración de cara a la seguridad. Para obtener más información, consulte Conexiones seguras en los asistentes de importación.
Si ya existen puntos de conexión privados y no se pueden deshabilitar, la opción alternativa es ejecutar el flujo de un extremo a otro correspondiente desde un script o programa en una máquina virtual. La máquina virtual debe estar en la misma red virtual que el punto de conexión privado. Este es un ejemplo de código de Python para la vectorización integrada. El mismo repositorio de GitHub tiene ejemplos en otros lenguajes de programación.
Permisos
Puede usar la autenticación de claves y las cadenas de conexión de acceso completo o Microsoft Entra ID con asignaciones de roles. Se recomiendan asignaciones de roles para las conexiones de servicio de búsqueda a otros recursos.
En Búsqueda de Azure AI, habilite los roles.
Configure su servicio de búsqueda para usar una identidad administrada.
En su plataforma de origen de datos y proveedor de modelos de inserción, cree asignaciones de roles que permitan al servicio de búsqueda acceder a los datos y modelos. En Preparar datos de muestra se proporcionan instrucciones para establecer los roles para cada origen de datos compatible.
Un servicio de búsqueda gratuito admite conexiones basadas en roles a la Búsqueda de Azure AI, pero no admite identidades administradas en conexiones salientes a Azure Storage o Visión de Azure AI. Este nivel de compatibilidad significa que debe usar la autenticación basada en claves en las conexiones entre un servicio de búsqueda gratuito y otros servicios de Azure.
Para conexiones más seguras:
- Use el nivel Básico o superior.
- Configure una identidad administrada y use roles para el acceso autorizado.
Nota:
Si no puede avanzar a través del asistente porque otras opciones no están disponibles (por ejemplo, no puede seleccionar un origen de datos o un modelo de inserción), vuelva a las asignaciones de roles. Los mensajes de error indican que los modelos o implementaciones no existen, cuando, de hecho, la causa real es que el servicio de búsqueda no tiene permiso para acceder a ellos.
Búsqueda de espacio
Si empieza con el servicio gratuito, está limitado a tres índices, orígenes de datos, conjuntos de aptitudes e indizadores. El nivel básico le limita a 15. Asegúrese de que tiene espacio para elementos adicionales antes de empezar. Este inicio rápido crea uno de cada objeto.
Preparación de datos de ejemplo
En esta sección se apunta al contenido que funciona para este inicio rápido.
Inicie sesión en Azure Portal con su cuenta de Azure y vaya a la cuenta de Azure Storage.
En el panel izquierdo, en Almacenamiento de datos, seleccione Contenedores.
Cree un contenedor y, a continuación, cargue los documentos PDF sobre el plan de mantenimiento que se usan para este inicio rápido.
En el panel izquierdo, en Control de acceso, asigne el rol Lector de datos de Blob Storage a la identidad del servicio de búsqueda. O bien, obtenga una cadena de conexión a la cuenta de almacenamiento de la página Claves de acceso.
Si lo desea, puede sincronizar las eliminaciones del contenedor con las eliminaciones en el índice de búsqueda. Estos pasos le permiten configurar el indexador para la detección de eliminación:
Habilite la eliminación temporal en la cuenta de almacenamiento.
Si usa la eliminación temporal nativa, no se requieren más pasos en Azure Storage.
De lo contrario, agregue metadatos personalizados que un indexador pueda examinar para determinar qué blobs se marcan para su eliminación. Asigne un nombre descriptivo a la propiedad personalizada. Por ejemplo, podría asignar un nombre a la propiedad "IsDeleted", establecida en false. Haga esto para cada blob del contenedor. Más adelante, cuando desee eliminar el blob, cambie la propiedad a true. Para más información, consulte Detección de cambios y eliminación al indexar desde Azure Storage
Configuración de modelos de inserción
El asistente puede usar modelos de inserción implementados desde Azure OpenAI, Azure AI Vision o desde el catálogo de modelos en el portal de Azure AI Foundry.
El asistente admite: text-embedding-ada-002, text-embedding-3-large y text-embedding-3-small. Internamente, el asistente llama a la aptitud AzureOpenAIEmbedding para conectarse a Azure OpenAI.
Inicie sesión en Azure Portal con su cuenta de Azure y vaya al recurso de Azure OpenAI.
Configurar permisos:
En el menú izquierdo, seleccione Access Control.
Seleccione Agregar y, después, Agregar asignación de roles.
En Roles de función de trabajo, seleccione Usuario de OpenAI de Cognitive Services y, a continuación, elija Siguiente.
En Miembros, seleccione Identidad administrada y, a continuación, elija Miembros.
Filtre por suscripción y tipo de recurso (servicios de búsqueda) y seleccione la identidad administrada del servicio de búsqueda.
Seleccione Revisar y asignar.
En la página Información general, seleccione Hacer clic aquí para ver los puntos de conexión o Hacer clic aquí para administrar claves si necesita copiar un punto de conexión o una clave de API. Puede pegar estos valores en el asistente si usa un recurso de Azure OpenAI con autenticación basada en claves.
En Administración de recursos e Implementaciones del modelo, seleccione Administrar implementaciones para abrir Azure AI Foundry.
Copie el nombre de implementación de
text-embedding-ada-002u otro modelo de inserción admitido. Si no tiene un modelo de inserción, implemente uno ahora.
Inicio del asistente
Inicie sesión en Azure Portal con su cuenta de Azure y vaya al servicio de Azure AI Search.
En la página Información general, seleccione Importar y vectorizar datos.

Conectarse a los datos propios
El siguiente paso consiste en conectarse a un origen de datos que se usará para el índice de búsqueda.
En Conectar a los datos, seleccione Azure Blob Storage.
Especifique la suscripción de Azure.
Elija la cuenta de almacenamiento y el contenedor que proporcionan los datos.
Especifique si desea compatibilidad con la detección de eliminación. En las siguientes ejecuciones de indexación, el índice de búsqueda se actualiza para quitar los documentos de búsqueda basados en blobs eliminados temporalmente en Azure Storage.
- Los blobs admiten la Eliminación temporal de blobs nativos o la Eliminación temporal mediante datos personalizados.
- Debe haber habilitado anteriormente la eliminación temporal en Azure Storage y, opcionalmente, haber agregado metadatos personalizados que la indexación pueda reconocer como una marca de eliminación. Para obtener más información acerca de estos pasos, consulte Preparación de datos de ejemplo.
- Si configuró los blobs para la eliminación temporal mediante datos personalizados, proporcione el par nombre-valor de la propiedad de metadatos en este paso. Se recomienda "IsDeleted". Si "IsDeleted" se establece en true en un blob, el indexador quita el documento de búsqueda correspondiente en la siguiente ejecución del indexador.
El asistente no comprueba la configuración válida de Azure Storage ni produce un error si no se cumplen los requisitos. En su lugar, la detección de eliminación no funciona y es probable que el índice de búsqueda recopile documentos huérfanos a lo largo del tiempo.
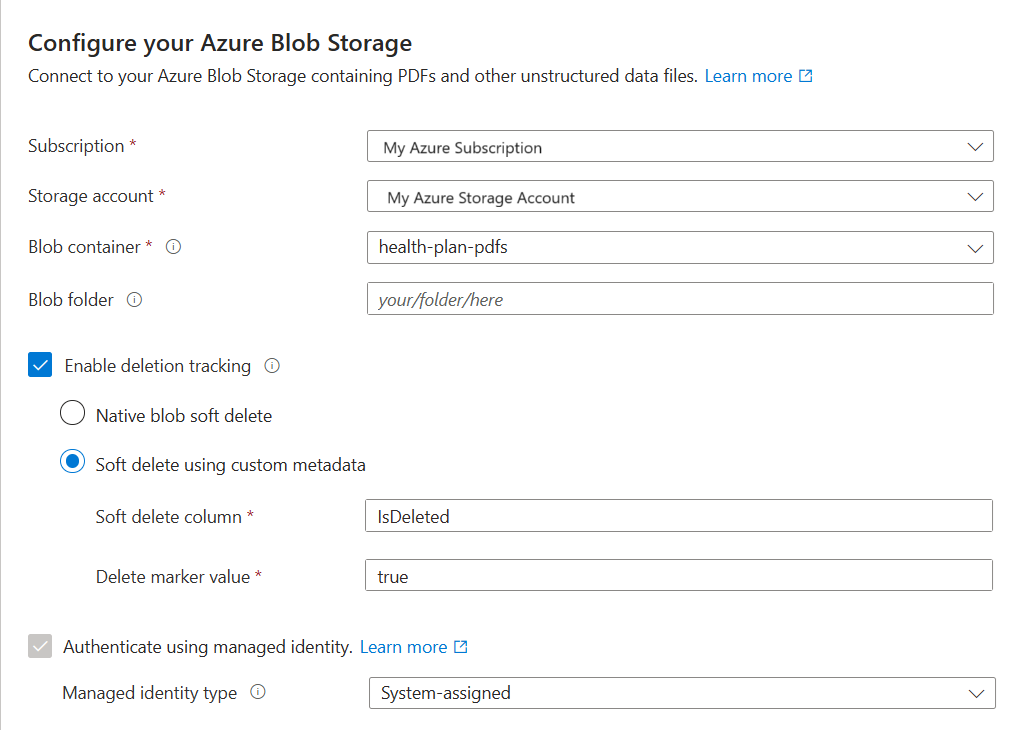
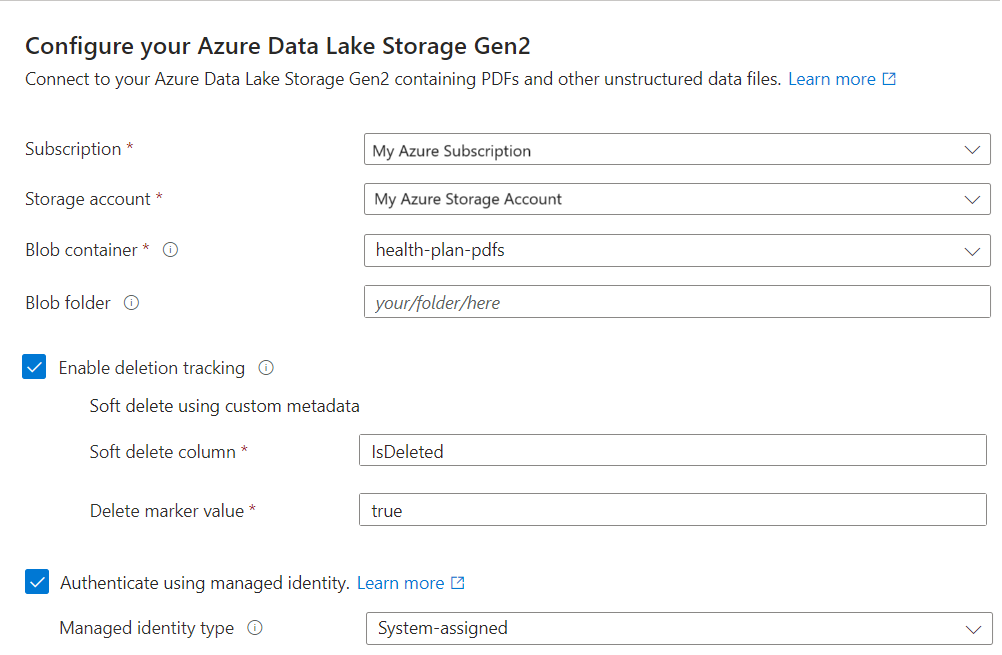
Especifique si quiere que el servicio de búsqueda se conecte a Azure Storage usando su identidad administrada.
- Se le pedirá que elija una identidad administrada por el sistema o administrada por el usuario.
- La identidad debe tener un rol Lector de datos de Blob Storage en Azure Storage.
- No omita este paso. Se produce un error de conexión durante la indexación si el asistente no se puede conectar a Azure Storage.
Seleccione Siguiente.
Vectorizar el texto
En este paso, especifique el modelo de inserción para vectorizar datos fragmentados.
La fragmentación está integrada y no se puede configurar. La configuración efectiva es:
"textSplitMode": "pages",
"maximumPageLength": 2000,
"pageOverlapLength": 500,
"maximumPagesToTake": 0, #unlimited
"unit": "characters"
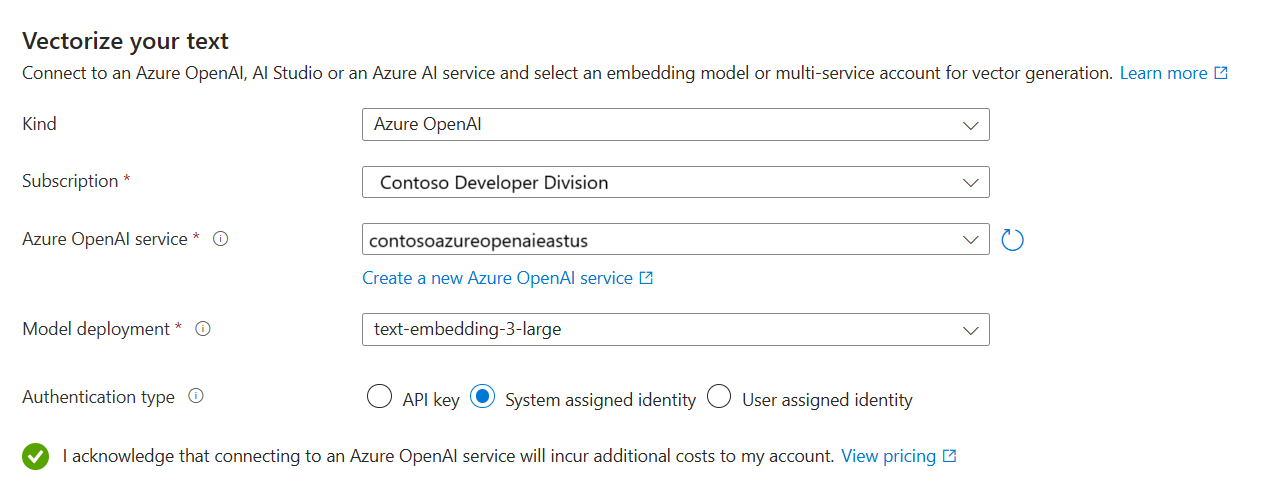
En la página Vectorizar el texto, elija el origen del modelo de inserción:
- Azure OpenAI
- Catálogo de modelos de Azure AI Foundry
- Un recurso multiproceso de Visión de Azure AI existente en la misma región que Búsqueda de Azure AI. Si no hay ninguna cuenta de varios servicios de Servicios de Azure AI en la misma región, esta opción no está disponible.
Elija la suscripción de Azure.
Realice selecciones según el recurso:
En el caso de Azure OpenAI, elija una implementación existente de text-embedding-ada-002, text-embedding-3-large o text-embedding-3-small.
En el caso del catálogo de AI Foundry, elija una implementación existente de un modelo de inserción de Azure o Cohere.
En el caso de las inserciones multimodales de Visión de AI, seleccione la cuenta.
Para más información, consulte Configuración de modelos de inserción anteriormente en este artículo.
Especifique si quiere que el servicio de búsqueda se autentique mediante una clave de API o una identidad administrada.
- La identidad debe tener el rol Usuario de Cognitive Services en la cuenta de varios servicios de Azure AI.
Active la casilla que confirma los efectos de facturación del uso de estos recursos.
Seleccione Siguiente.
Vectorizar y enriquecer las imágenes
Los archivos PDF del plan de mantenimiento incluyen un logotipo corporativo, pero por lo demás no hay imágenes. Puede omitir este paso si usa los documentos de ejemplo.
Sin embargo, si trabaja con contenido que incluye imágenes útiles, puede aplicar inteligencia artificial de dos maneras:
Use un modelo de inserción de imágenes compatibles desde el catálogo o elija la API de inserciones vectoriales de Azure AI Vision para vectorizar imágenes.
Use el reconocimiento óptico de caracteres (OCR) para reconocer el texto de las imágenes. Esta opción invoca la habilidad OCR para leer texto de imágenes.
Búsqueda de Azure AI y el recurso de Azure AI deben estar en la misma región o configurados para conexiones de facturación sin claves.
En la página Vectorizar las imágenes, especifique el tipo de conexión que debe realizar el asistente. Para la vectorización de imágenes, puede conectarse a modelos de inserción en Azure AI Foundry o Visión de Azure AI.
Especifique la suscripción.
En el catálogo de modelos de Azure AI Foundry, especifique el proyecto y la implementación. Para más información, consulte Configuración de modelos de inserción anteriormente en este artículo.
Opcionalmente, puede descifrar imágenes binarias (por ejemplo, archivos de documentos escaneados) y usar OCR para reconocer texto.
Active la casilla que confirma los efectos de facturación del uso de estos recursos.
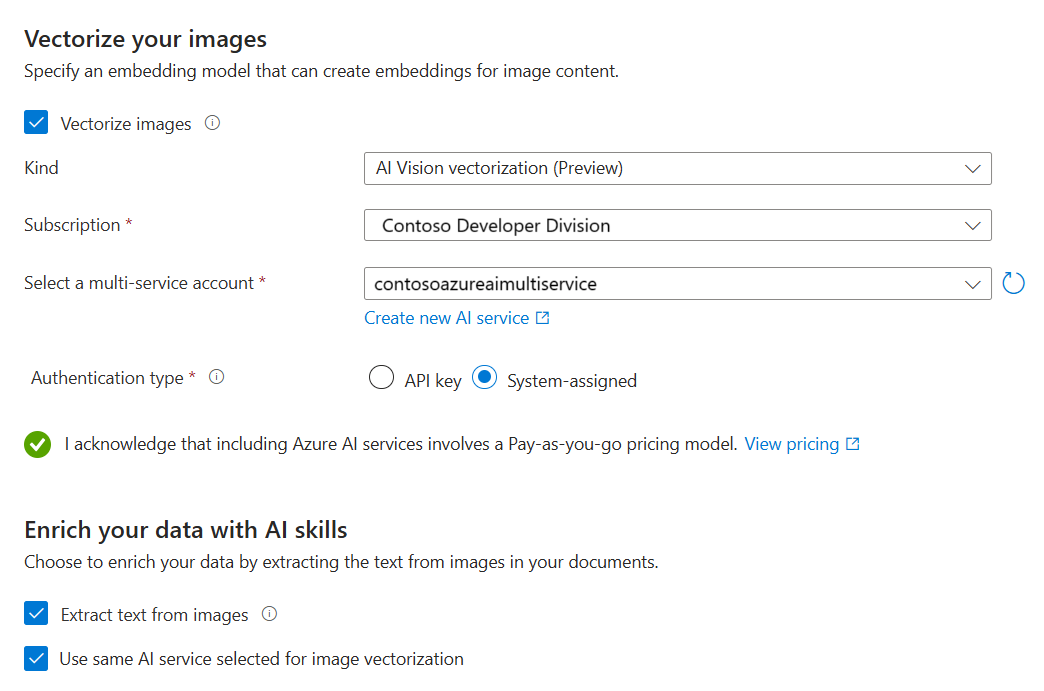
Seleccione Siguiente.
Incorporación de la clasificación semántica
En la página Configuración avanzada, puede agregar opcionalmente la clasificación semántica para volver a clasificar resultados al final de la ejecución de consultas. Cuando se vuelven a clasificar los resultados, las coincidencias que son más relevantes semánticamente se mueven arriba.
Asignar nuevos campos
Puntos clave sobre este paso:
- El esquema de índice proporciona campos vectoriales y no vectoriales para datos fragmentados.
- Puede agregar campos, pero no puede eliminar ni modificar campos generados.
- El modo de análisis de documentos crea fragmentos (un documento de búsqueda por fragmento).
En la página Configuración avanzada, puede agregar campos nuevos, suponiendo que el origen de datos proporcione metadatos o campos que no se hayan seleccionado en el primer paso. De forma predeterminada, el asistente genera los siguientes campos con estos atributos:
| Campo | Se aplica a | Descripción |
|---|---|---|
| chunk_id | Vectores de texto e imagen | Campo de cadena generado. Se puede buscar, recuperar y ordenar. Esta es la clave de documento del índice. |
| text_parent_id | Vectores de texto | Campo de cadena generado. Se puede recuperar y filtrar. Identifica el documento primario desde el que se origina el fragmento. |
| chunk | Vectores de texto e imagen | Campo de cadena. Versión legible humana del fragmento de datos. Se puede buscar y recuperar, pero no filtrar, mostrar u ordenar. |
| title | Vectores de texto e imagen | Campo de cadena. Título del documento legible o título de la página o número de página. Se puede buscar y recuperar, pero no filtrar, mostrar u ordenar. |
| text_vector | Vectores de texto | Collection(Edm.single). Representación vectorial del fragmento. Se puede buscar y recuperar, pero no filtrar, mostrar u ordenar. |
No puede modificar los campos generados ni sus atributos, pero puede agregar nuevos campos si el origen de datos los proporciona. Por ejemplo, Azure Blob Storage proporciona una colección de campos de metadatos.
Seleccione Agregar nuevo.
Elija un campo de origen de la lista de campos disponibles, proporcione un nombre de campo para el índice y acepte el tipo de datos predeterminado o invalide según sea necesario.
Los campos de metadatos se pueden buscar, pero no recuperar, filtrar, mostrar u ordenar.
Seleccione Restablecer si desea restaurar el esquema a su versión original.
Programación de la indexación
En la página Configuración avanzada, puede especificar opcionalmente una programación de ejecución para el indexador.
- Seleccione Siguiente cuando haya terminado con la página Configuración avanzada.
Finalización del asistente
En la página Revisar la configuración, especifique un prefijo para los objetos que creará el asistente. Un prefijo común le ayuda a mantenerse organizado.
Seleccione Crear.
Cuando el asistente completa la configuración, crea los siguientes objetos:
Conexión de origen de datos.
Índice con campos vectoriales, vectorizadores, perfiles vectoriales, algoritmos vectoriales. No se puede modificar ni diseñar el índice predeterminado durante el flujo de trabajo del asistente. Los índices se ajustan a la API REST 2024-05-01-preview.
Conjunto de aptitudes con la aptitud División de texto para la fragmentación y una aptitud de inserción para la vectorización. La aptitud de inserción es la aptitud AzureOpenAIEmbeddingModel para Azure OpenAI o la aptitud AML para el catálogo de modelos de Azure AI Foundry. El conjunto de aptitudes también tiene la configuración de proyecciones de índice que permite asignar datos desde un documento del origen de datos a sus fragmentos correspondientes en un índice "secundario".
Indexador con asignaciones de campos y asignaciones de campos de salida (si procede).
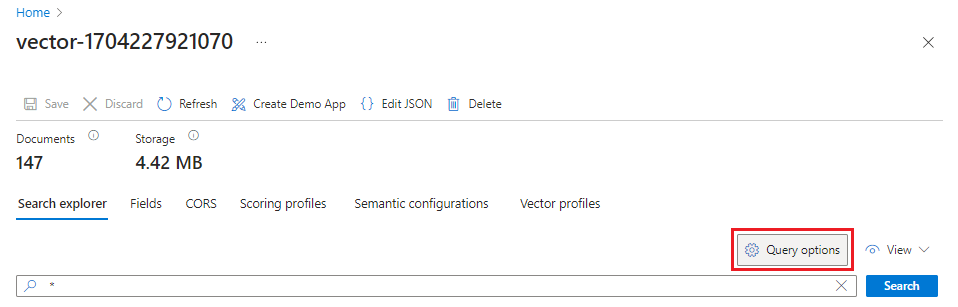
Comprobar los resultados
El Explorador de búsqueda acepta cadenas de texto como entrada y, a continuación, vectoriza el texto para la ejecución de consultas vectoriales.
En Azure Portal, vaya a Administración de búsqueda>Índices y, a continuación, seleccione el índice que creó.
Seleccione Opciones de consulta y oculte los valores vectoriales en los resultados de la búsqueda. Este paso facilita la lectura de los resultados de búsqueda.
En el menú Ver, seleccione Vista JSON para que pueda escribir texto para la consulta vectorial en el parámetro de consulta vectorial
text.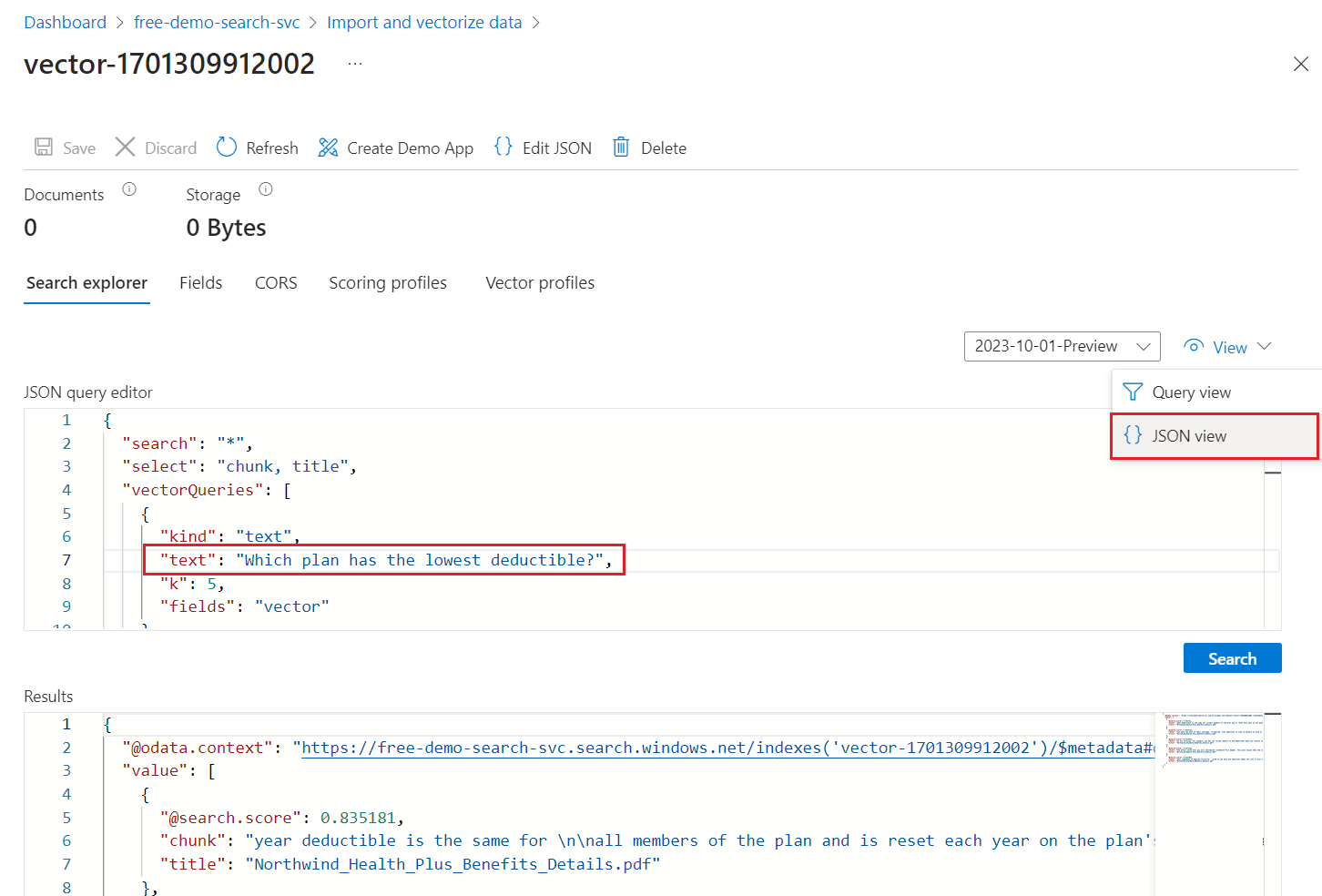
La consulta predeterminada es una búsqueda vacía (
"*"), pero incluye parámetros para devolver las coincidencias de número. Es una consulta híbrida que ejecuta consultas de texto y vectores en paralelo. Incluye la clasificación semántica. Se especifican los campos que se van a devolver en los resultados mediante la instrucciónselect.{ "search": "*", "count": true, "vectorQueries": [ { "kind": "text", "text": "*", "fields": "text_vector,image_vector" } ], "queryType": "semantic", "semanticConfiguration": "my-demo-semantic-configuration", "captions": "extractive", "answers": "extractive|count-3", "queryLanguage": "en-us", "select": "chunk_id,text_parent_id,chunk,title,image_parent_id" }Reemplace ambos marcadores de posición de asterisco (
*) por una pregunta relacionada con los planes de mantenimiento, comoWhich plan has the lowest deductible?.{ "search": "Which plan has the lowest deductible?", "count": true, "vectorQueries": [ { "kind": "text", "text": "Which plan has the lowest deductible?", "fields": "text_vector,image_vector" } ], "queryType": "semantic", "semanticConfiguration": "my-demo-semantic-configuration", "captions": "extractive", "answers": "extractive|count-3", "queryLanguage": "en-us", "select": "chunk_id,text_parent_id,chunk,title" }Seleccione Buscar para ejecutar la consulta.
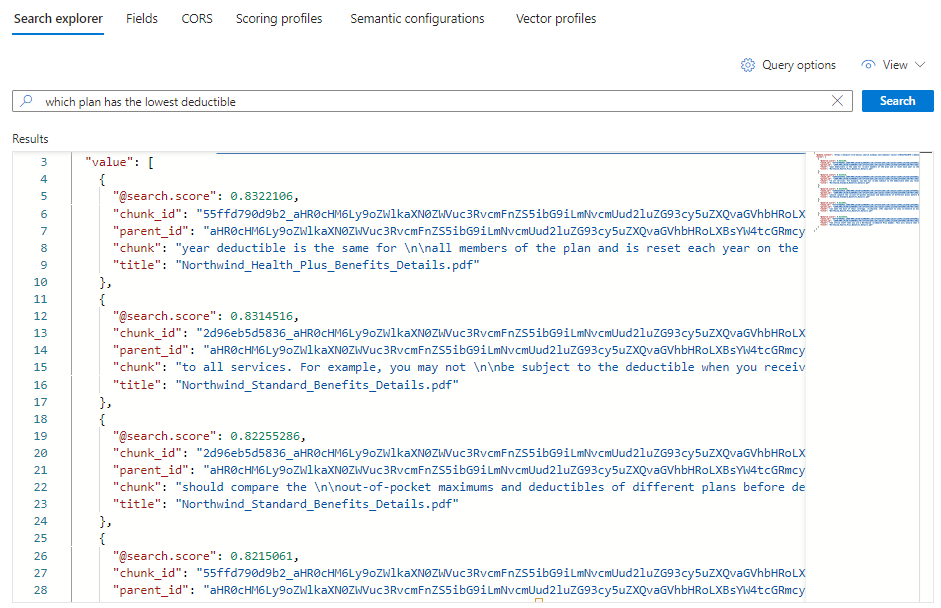
Cada documento es un fragmento del PDF original. El campo
titlemuestra de qué PDF procede el fragmento. Cadachunkes bastante largo. Puede copiar y pegar uno en un editor de texto para leer todo el valor.Para ver todos los fragmentos de un documento específico, agregue un filtro para el campo
title_parent_idde un archivo PDF específico. Puede comprobar la pestaña Campos del índice para confirmar que este campo se pueda filtrar.{ "select": "chunk_id,text_parent_id,chunk,title", "filter": "text_parent_id eq 'aHR0cHM6Ly9oZWlkaXN0c3RvcmFnZWRlbW9lYXN0dXMuYmxvYi5jb3JlLndpbmRvd3MubmV0L2hlYWx0aC1wbGFuLXBkZnMvTm9ydGh3aW5kX1N0YW5kYXJkX0JlbmVmaXRzX0RldGFpbHMucGRm0'", "count": true, "vectorQueries": [ { "kind": "text", "text": "*", "k": 5, "fields": "text_vector" } ] }
Limpieza
Azure AI Search es un recurso facturable. Si ya no es necesario, elimínelo de la suscripción para evitar cargos.
Paso siguiente
Este inicio rápido sirve de introducción al asistente para Importar y vectorizar datos que crea todos los objetos necesarios para la vectorización integrada. Si desea explorar cada paso con detalle, pruebe los ejemplos de vectorización integrada.