Depuración de un conjunto de aptitudes de Azure AI Search en Azure Portal
Inicie una sesión de depuración basada en el portal para identificar y resolver errores, validar los cambios e insertar cambios en un conjunto de aptitudes existente en un servicio Azure AI Search.
Una sesión de depuración es una ejecución de indexador y conjunto de aptitudes almacenada en caché, orientada a un único documento, que puede usar para editar y probar los cambios en el conjunto de aptitudes de forma interactiva. Cuando haya terminado de depurar, puede guardar los cambios en el conjunto de aptitudes.
Para obtener información sobre cómo funciona una sesión de depuración, consulte Sesiones de depuración en Azure AI Search. Para practicar un flujo de trabajo de depuración con un documento de ejemplo, consulte Tutorial: Sesiones de depuración.
Requisitos previos
Un servicio de Búsqueda de Azure AI, cualquier región o nivel.
Una cuenta de Azure Storage, que se usa para guardar el estado de la sesión.
Una canalización de enriquecimiento existente, que incluye un origen de datos, un conjunto de aptitudes, un indexador y un índice.
Seguridad y permisos
Para guardar una sesión de depuración en Azure Storage, la identidad del servicio de búsqueda debe tener permisos de Colaborador de datos de blobs de almacenamiento en Azure Storage. De lo contrario, planee elegir una cadena de conexión de acceso completo para la conexión de sesión de depuración a Azure Storage.
Si utiliza un firewall para proteger la cuenta de Azure Storage, configúrelo para que este permita el acceso al servicio de búsqueda.
Limitaciones
Las sesiones de depuración funcionan con todos los orígenes de datos del indexador disponibles en general y con la mayoría de los orígenes de datos de versión preliminar, con las siguientes excepciones:
Indexador de SharePoint Online.
Indexador de Azure Cosmos DB for MongoDB.
En Azure Cosmos DB for NoSQL, si se produce un error en una fila durante la ejecución del indexado y no se encuentran metadatos correspondientes, es posible que la sesión de depuración no elija la fila correcta.
En el caso de la API de SQL de Azure Cosmos DB, si una colección con particiones anteriormente no tenía particiones, la sesión de depuración no encontrará el documento.
En el caso de las aptitudes personalizadas, no se admite una identidad administrada asignada por el usuario para una conexión de sesión de depuración a Azure Storage. Como se indica en los requisitos previos, puede usar una identidad administrada por el sistema o especificar una cadena de conexión de acceso completo que incluya una clave. Para más información, consulte Conexión de un servicio de búsqueda a otros recursos de Azure mediante una identidad administrada.
Creación de una sesión de depuración
Inicie sesión en Azure Portal y encuentre su servicio de búsqueda.
En el menú de la izquierda, seleccione Administración de búsqueda>Sesiones de depuración.
En la barra de acciones de la parte superior, seleccione Agregar sesión de depuración.
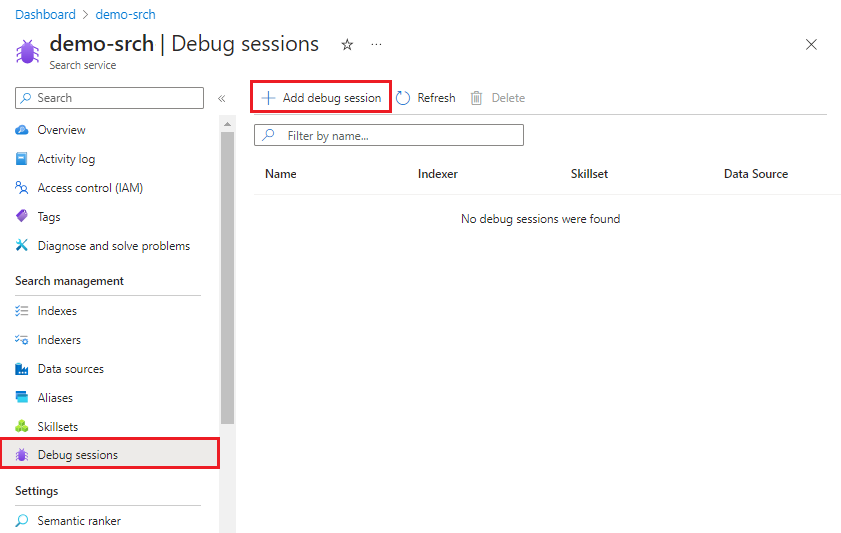
En Debug session name (Nombre de la sesión de depuración), proporcione un nombre que le ayude a recordar de qué conjunto de aptitudes, indexador y origen de datos trata la sesión de depuración.
En Plantilla del indexador, seleccione el indexador que impulsa el conjunto de aptitudes que quiere depurar. Las copias tanto del indexador como del conjunto de aptitudes se usan para inicializar la sesión.
En Document to debug (Documento que se va a depurar), elija el primer documento del índice o seleccione un documento específico. Si selecciona un documento específico, se le pide un URI o un identificador de fila en función del origen de datos.
Si el documento específico es un blob, proporcione el URI del blob. Puede encontrar el URI en la página de propiedades del blob en Azure Portal.
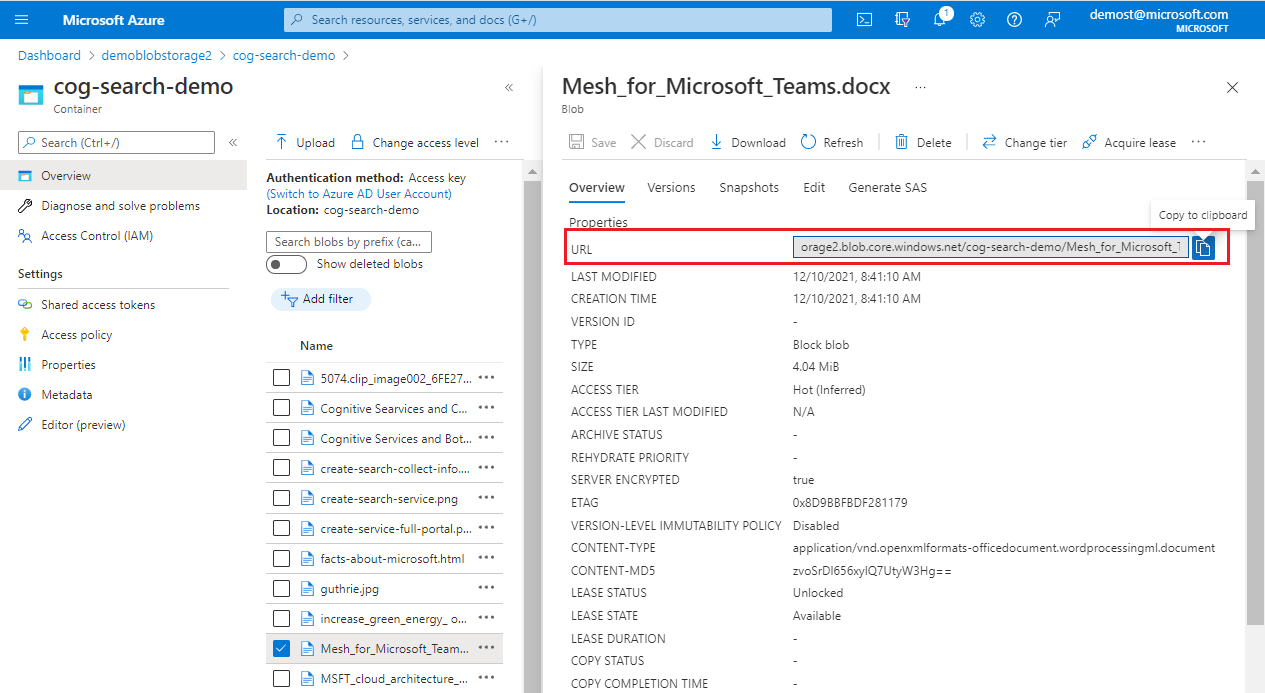
En Cuenta de almacenamiento, elija una cuenta de almacenamiento de uso general para almacenar en caché la sesión de depuración.
Seleccione Autenticar mediante identidad administrada si asignó previamente permisos de colaborador de datos de Storage Blob a la identidad administrada por el sistema del servicio de búsqueda. Si no activa esta casilla, el servicio de búsqueda se conecta mediante una cadena de conexión de acceso completo.
Seleccione Guardar.
- La Búsqueda de Azure AI crea un contenedor de blobs en Azure Storage denominado ms-az-cognitive-search-debugsession.
- Dentro de ese contenedor, crea una carpeta con el nombre que proporcionó para el nombre de la sesión.
- Inicia la sesión de depuración.


Para empezar la sesión de depuración, se ejecuta el indexador y el conjunto de aptitudes en el documento seleccionado. El contenido y los metadatos del documento creados están visibles y disponibles en la sesión.
Se puede cancelar una sesión de depuración mientras se ejecuta. Si presiona el botón Cancelar, debería poder analizar los resultados parciales.
Se espera que una sesión de depuración tarde más tiempo en ejecutarse que el indexador, ya que pasa por un procesamiento adicional.
Inicio con errores y advertencias
El historial de ejecución del indexador en Azure Portal proporciona la lista completa de errores y advertencias para todos los documentos. En una sesión de depuración, los errores y advertencias se limitan a un documento. Recorrerá esta lista, hará los cambios y, después, volverá a la lista para comprobar si se resolvieron los problemas.
Recuerde que una sesión de depuración se basa en un documento de todo el índice. Si una entrada o salida tiene un aspecto incorrecto, el problema podría ser específico de ese documento. Puede elegir otro documento para confirmar si los errores y las advertencias son generalizados o específicos de un solo documento.
Seleccione Errores o Advertencias para obtener una lista de problemas.

Como procedimiento recomendado, resuelva los problemas con las entradas antes de pasar a las salidas.
Para demostrar si una modificación resuelve un error, siga estos pasos:
Seleccione Guardar en el panel de detalles de la aptitud para conservar los cambios.
Seleccione Ejecutar en la ventana de sesión para invocar la ejecución del conjunto de aptitudes mediante la definición modificada.
Vuelva a Errores o Advertencias para ver si se reduce el recuento.
Ver contenido enriquecido o generado
Las canalizaciones de enriquecimiento con inteligencia artificial extraen o deducen la información y estructura de los documentos de origen, creando un documento enriquecido en el proceso. La primera vez que se crea un documento enriquecido es durante el descifrado de documentos y se rellena con un nodo raíz (/document), además de nodos para cualquier contenido que se extraiga directamente del origen de datos, como los metadatos y la clave de documento. Las aptitudes crean más nodos durante la ejecución de aptitudes, donde la salida de cada aptitud agrega un nuevo nodo al árbol de enriquecimiento.
Todo el contenido creado o usado por un conjunto de aptitudes aparece en el Evaluador de expresiones. Puede mantener el puntero sobre los vínculos para ver cada valor de entrada o salida en el árbol de documentos enriquecido. Para ver la entrada o la salida de cada aptitud, siga estos pasos:
En una sesión de depuración, expanda la flecha azul para ver los detalles contextuales. De forma predeterminada, el detalle es la estructura de datos del documento enriquecido. Sin embargo, si selecciona una aptitud o una asignación, los detalles se refieren a ese objeto.

Seleccione una aptitud.
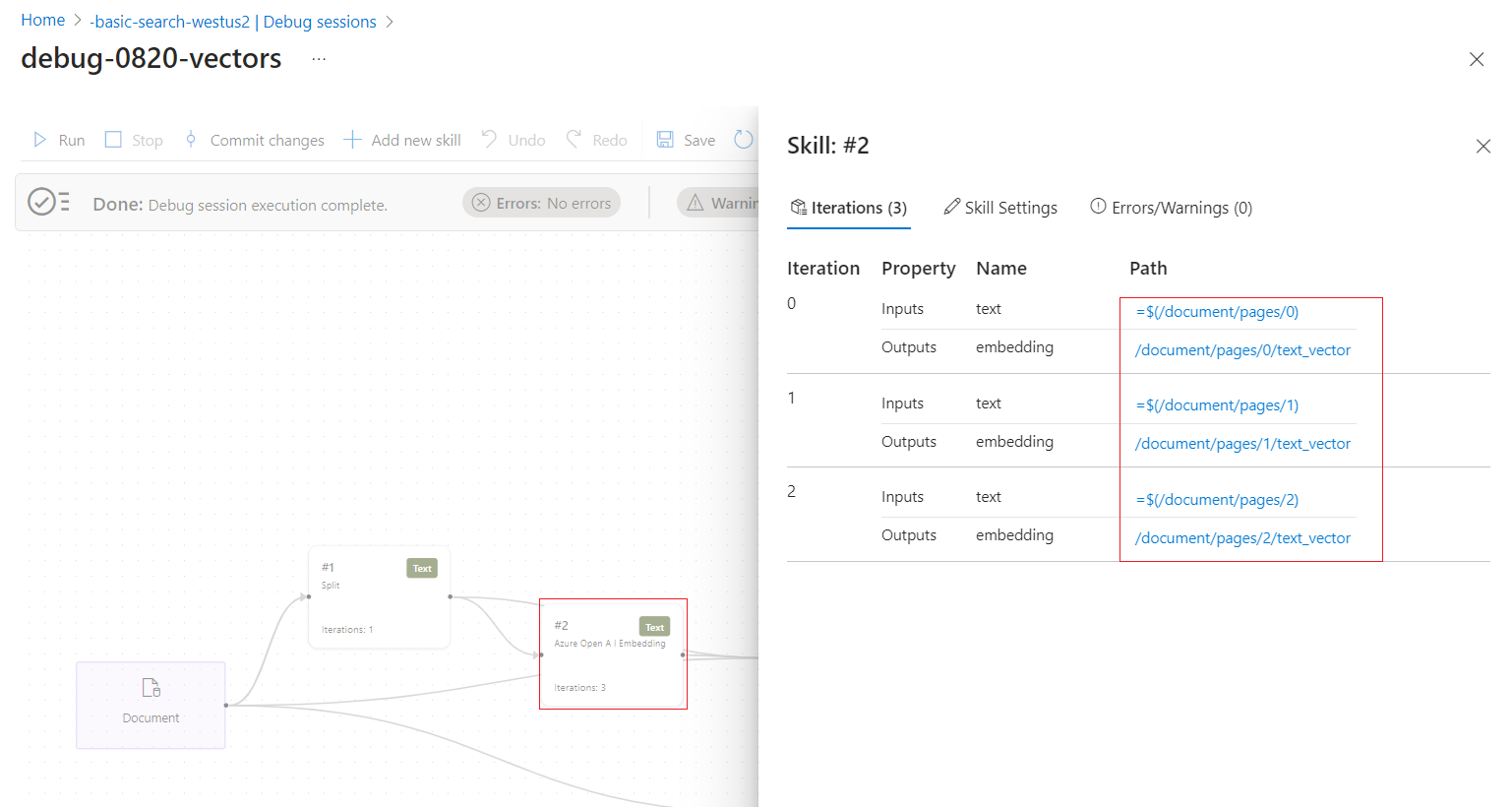
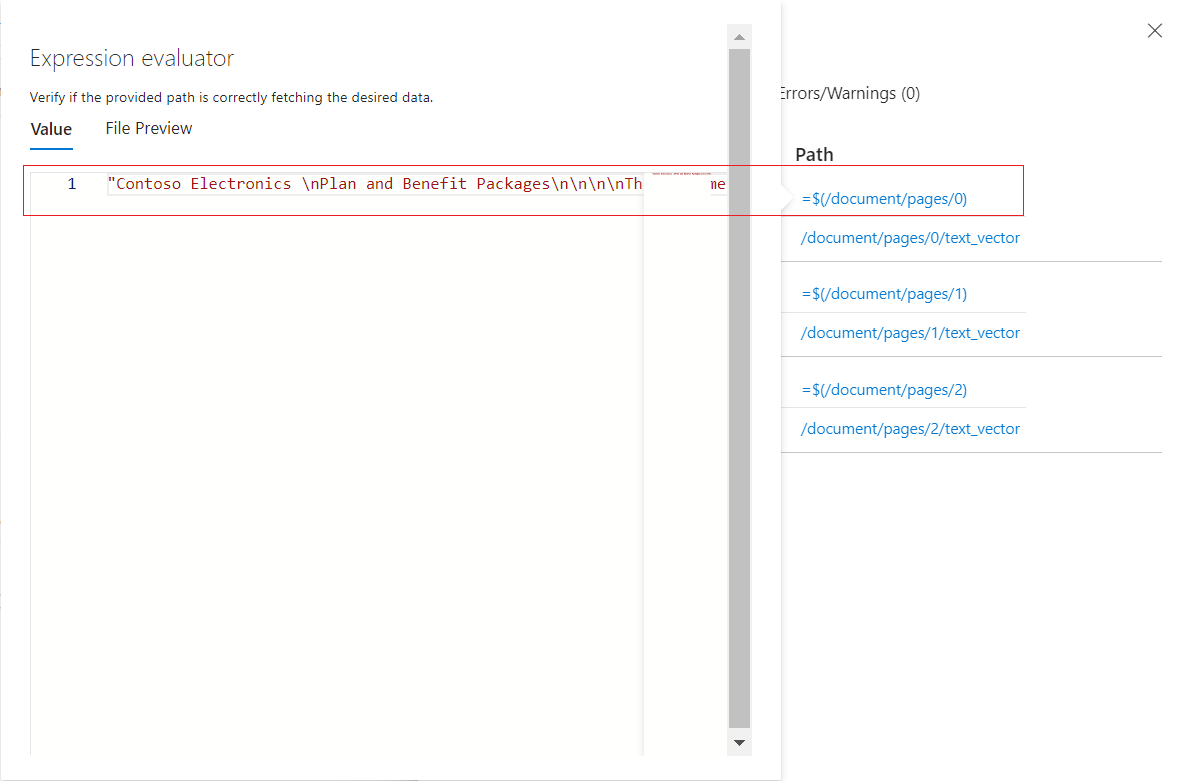
Siga los vínculos para profundizar más en el procesamiento de aptitudes. Por ejemplo, en la captura de pantalla siguiente se muestra la salida de la primera iteración de la aptitud división de texto.



Comprobación de las asignaciones del índice
Si las aptitudes generan una salida, pero el índice de búsqueda está vacío, compruebe las asignaciones de campos. Las asignaciones de campos especifican cómo el contenido sale de la canalización y entra en un índice de búsqueda.
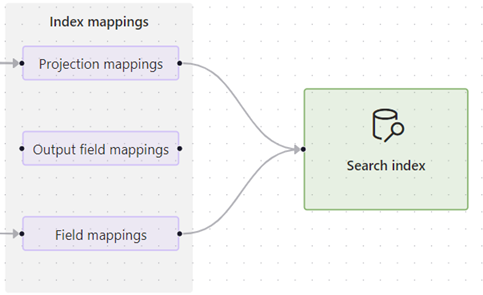
Seleccione una de las opciones de asignación y expanda la vista de detalles para revisar las definiciones de origen y destino.
LasAsignaciones de proyección se encuentran en conjuntos de aptitudes que proporcionan vectorización integrada, como las aptitudes creadas por el Asistente para importar y vectorizar datos. Estas asignaciones determinan las asignaciones de campos primario y secundario (fragmento) y si un índice secundario se crea solo para el contenido fragmentado
Las Asignaciones de campos de salida se encuentran en indexadores y se usan cuando los conjuntos de aptitudes invocan aptitudes integradas o personalizadas. Estas asignaciones se usan para establecer la ruta de acceso de los datos desde un nodo del árbol de enriquecimiento hacia un campo del índice de búsqueda. Para obtener más información sobre las rutas de acceso, consulte sintaxis de ruta de acceso del nodo de enriquecimiento.
Las Asignaciones de campos se encuentran en las definiciones del indexador y establecen la ruta de acceso de datos del contenido sin procesar en el origen de datos y un campo del índice. También puede usar asignaciones de campos para agregar pasos de codificación y descodificación.
En este ejemplo se muestran los detalles de una asignación de proyección. Puede editar el código JSON para corregir cualquier problema de asignación.

Edición de definiciones de aptitud
Si las asignaciones de campos son correctas, compruebe la configuración y el contenido de las aptitudes individuales. Si una aptitud no genera resultados, es posible que falte una propiedad o un parámetro, que se puede determinar a través de mensajes de error y validación.
Otros problemas, como un contexto no válido o una expresión de entrada, pueden ser más difíciles de resolver porque el error le mostrará lo que está mal, pero no cómo corregirlo. Para obtener ayuda con el contexto y la sintaxis de entrada, consulte Enriquecimientos de referencia en un conjunto de aptitudes de Azure AI Search. Para obtener ayuda con mensajes individuales, consulte Solución de errores y advertencias del indexador comunes.
En los pasos siguientes se muestra cómo obtener información sobre una aptitud.
Seleccione una aptitud en la superficie de trabajo. El panel Detalles de la aptitud se abre a la derecha.
Edite una definición de aptitud mediante la Configuración de aptitud. Puede editar el código JSON directamente.
Compruebe la sintaxis de la ruta de acceso para hacer referencia a los nodos de un árbol de enriquecimiento. A continuación se muestran algunas de las rutas de acceso de entrada más comunes:
-
/document/contentpara fragmentos de texto. Este nodo se rellena a partir de la propiedad content del blob. -
/document/merged_contentpara fragmentos de texto en conjuntos de aptitudes que incluyen la aptitud Combinación de texto. -
/document/normalized_images/*para el texto que se reconoce o se deduce de las imágenes.
-
Depurar una capacidad personalizada localmente
Las aptitudes personalizadas pueden ser más difíciles de depurar porque el código se ejecuta externamente, por lo que la sesión de depuración no se puede usar para depurarlas. En esta sección se describe cómo depurar localmente la aptitud de API web personalizada, la sesión de depuración, Visual Studio Code y ngrok o Tunnelmole. Esta técnica funciona con capacidades personalizadas que se ejecutan en Azure Functions o cualquier otro Web Framework que se ejecuta localmente (por ejemplo, FastAPI).
Obtener una dirección URL pública
En esta sección se describen dos enfoques para obtener una dirección URL pública a una aptitud personalizada.
Usar Tunnelmole
Tunnelmole es una herramienta de tunelización de código abierto que puede crear una dirección URL pública que reenvía las solicitudes a la máquina local a través de un túnel.
Instalar Tunnelmole:
- npm:
npm install -g tunnelmole - Linux:
curl -s https://tunnelmole.com/sh/install-linux.sh | sudo bash - Mac:
curl -s https://tunnelmole.com/sh/install-mac.sh --output install-mac.sh && sudo bash install-mac.sh - Windows: instalación mediante npm. O bien, si no tiene NodeJS instalado, descargue el archivo .exe precompilado para Windows y colóquelo en algún lugar de la ruta de acceso.
- npm:
Ejecute este comando para crear un nuevo túnel:
tmole 7071Debería ver una respuesta similar a la siguiente:
http://m5hdpb-ip-49-183-170-144.tunnelmole.net is forwarding to localhost:7071 https://m5hdpb-ip-49-183-170-144.tunnelmole.net is forwarding to localhost:7071En el ejemplo anterior,
https://m5hdpb-ip-49-183-170-144.tunnelmole.netreenvía al puerto7071en el equipo local, que es el puerto predeterminado donde se exponen las funciones de Azure.
Usar ngrok
ngrok es una aplicación popular, de código cerrado y multiplataforma que puede crear una dirección URL de tunelización o reenvío, de modo que las solicitudes de Internet lleguen a la máquina local. Use ngrok para reenviar solicitudes de una canalización de enriquecimiento en el servicio de búsqueda a la máquina para permitir la depuración local.
Instalar ngrok.
Abra un terminal y vaya a la carpeta con el ejecutable ngrok.
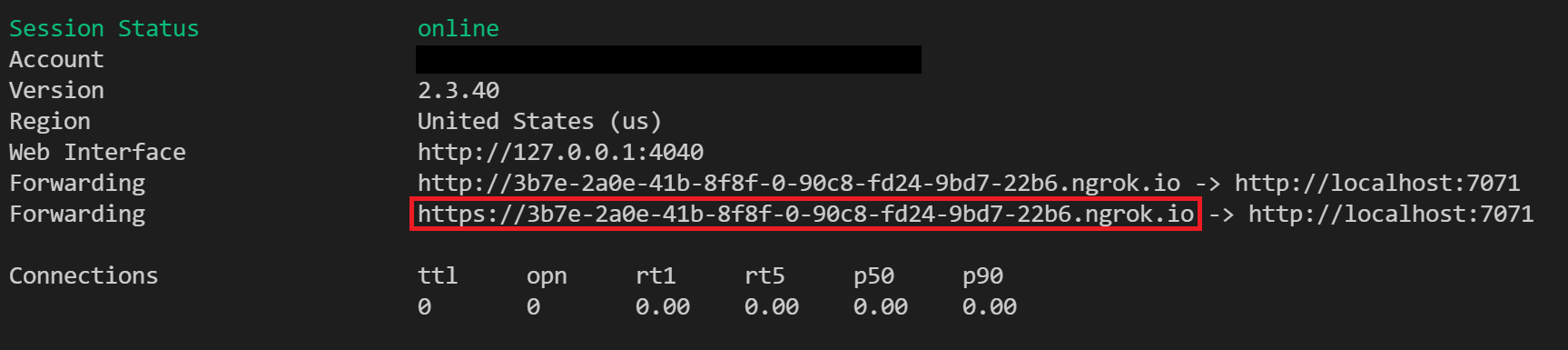
Ejecute ngrok con el siguiente comando para crear un nuevo túnel:
ngrok http 7071Nota:
De forma predeterminada, las funciones de la solución Función de Azure se encuentran en el puerto 7071. Otras herramientas y configuraciones pueden requerir que proporcione un puerto diferente.
Cuando se inicia ngrok, copie y guarde la dirección URL de reenvío pública para el paso siguiente. La dirección URL de reenvío se genera aleatoriamente.
Configuración en Azure Portal
Una vez que tenga una dirección URL pública para la aptitud personalizada, modifique el URI de la API web de la aptitud de personalizada dentro de una sesión de depuración para llamar a la dirección URL de reenvío de Tunnelmole o ngrok. Asegúrese de anexar "/api/FunctionName" al usar la Función de Azure para ejecutar el código del conjunto de aptitudes.
Puede editar la definición de aptitud en la sección Configuración de aptitudes del panel Detalles de la aptitud.
Prueba del código
En este momento, las nuevas solicitudes de la sesión de depuración ahora se deben enviar a la función local de Azure. Puede usar puntos de interrupción en el Visual Studio Code para depurar el código o ejecutar paso a paso.
Pasos siguientes
Ahora que conoce el diseño y las funcionalidades del editor visual de Sesiones de depuración, pruebe el tutorial para obtener una experiencia práctica.