Confiabilidad en Azure HDInsight
En este artículo se describe la compatibilidad con la confiabilidad en Azure HDInsighty se tratan zonas de disponibilidad y recuperación entre regiones y continuidad empresarial. Para obtener información general más detallada sobre la confiabilidad de Azure, consulte Confiabilidad de Azure.
Compatibilidad de zonas de disponibilidad
Las zonas de disponibilidad son grupos físicamente separados de centros de datos dentro de cada región de Azure. Cuando se produce un error en una zona, los servicios pueden conmutar por error a una de las zonas restantes.
Para más información sobre las zonas de disponibilidad en Azure, consulte ¿Qué son las zonas de disponibilidad?
Azure HDInsight admite una configuración de implementación zonal. Los nodos de clúster de Azure HDInsight se colocan en una sola zona que se selecciona en la región seleccionada. Un clúster de HDInsight zonal está aislado de las interrupciones que se producen en otras zonas. Sin embargo, si una interrupción afecta a la zona específica elegida para el clúster de HDInsight, el clúster no estará disponible. Este modelo de implementación proporciona conectividad de red de baja latencia y económica dentro del clúster. La replicación de este modelo de implementación en varias zonas de disponibilidad puede proporcionar un mayor nivel de disponibilidad para protegerse frente a errores de hardware.
Importante
En el caso de las implementaciones en las que los usuarios no especifican una zona específica, los tipos de nodo no son resistentes a la zona y pueden experimentar tiempo de inactividad durante una interrupción en cualquier zona de esa región.
Requisitos previos
Las zonas de disponibilidad solo se admiten para los clústeres creados después del 15 de junio de 2023. La configuración de la zona de disponibilidad no se puede actualizar después de crear el clúster. Tampoco puede actualizar un clúster de zona sin disponibilidad para usar zonas de disponibilidad.
Los clústeres se deben crear en una red virtual personalizada.
Debe traer su propia base de datos SQL para la base de datos de Ambari y el metastore externo, como metastore de Hive, para que pueda configurar estas bases de datos en la misma zona de disponibilidad.
Los clústeres de HDInsight deben crearse con la opción de zona de disponibilidad en una de las siguientes regiones:
- Este de Australia
- Sur de Brasil
- Centro de Canadá
- Centro de EE. UU.
- Este de EE. UU.
- Este de EE. UU. 2
- Centro de Francia
- Centro-oeste de Alemania
- Japón Oriental
- Centro de Corea del Sur
- Norte de Europa
- Centro de Catar
- Sudeste de Asia
- Centro-sur de EE. UU.
- Sur de Reino Unido 2
- US Gov - Virginia
- Oeste de Europa
- Oeste de EE. UU. 2
Creación de un clúster de HDInsight con zona de disponibilidad
Puede usar la plantilla de Azure Resource Manager (ARM) para iniciar un clúster de HDInsight en una zona de disponibilidad especificada.
En la sección de recursos, debe agregar una sección de ‘zonas’ y proporcionar en qué zona de disponibilidad desea que se implemente este clúster.
"resources": [
{
"type": "Microsoft.HDInsight/clusters",
"apiVersion": "2021-06-01",
"name": "[parameters('cluster name')]",
"location": "East US 2",
"zones": [
"1"
],
}
]
Comprobación de nodos dentro de una zona de disponibilidad entre zonas
Cuando el clúster de HDInsight esté listo, puede comprobar la ubicación para ver en qué zona de disponibilidad se implementan.

Respuesta de la API Get:
[
{
"location": "East US 2",
"zones": [
"1"
],
}
]
Escalado vertical del clúster
Puede escalar verticalmente un clúster de HDInsight con más nodos de trabajo. Los nodos de trabajo recién agregados se colocarán en la misma zona de disponibilidad de este clúster.
Migración de zonas de disponibilidad
Actualmente, los clústeres de Azure HDInsight no admiten la migración in situ de instancias de clúster existentes para soporte de zonas de disponibilidad. Sin embargo, puede elegir volver a crear el clústery elegir una región o zona de disponibilidad diferente durante la creación del clúster. Un clúster en espera secundario en una región diferente y una zona de disponibilidad diferente se puede usar en escenarios de recuperación ante desastres.
Experiencia a nivel de zona
Cuando una zona de disponibilidad deja de funcionar:
- No se puede usar ssh en este clúster.
- No se puede eliminar, escalar verticalmente o reducir verticalmente este clúster.
- No se pueden enviar trabajos ni ver el historial de trabajos.
- Todavía puede enviar una nueva solicitud de creación de clústeres en otra región.
Recuperación ante desastres entre regiones y continuidad empresarial
La recuperación ante desastres (DR) consiste en recuperarse de eventos de alto impacto, como desastres naturales o implementaciones con errores, lo que produce tiempo de inactividad y pérdida de datos. Independientemente de la causa, el mejor remedio para un desastre es un plan de recuperación ante desastres bien definido y probado y un diseño de aplicaciones que apoye activamente la recuperación ante desastres. Antes de empezar a pensar en la creación del plan de recuperación ante desastres, vea Recomendaciones para diseñar una estrategia de recuperación ante desastres.
En lo que respecta a la recuperación ante desastres, Microsoft usa el modelo de responsabilidad compartida. En un modelo de responsabilidad compartida, Microsoft garantiza que la infraestructura de línea base y los servicios de plataforma estén disponibles. Al mismo tiempo, muchos servicios de Azure no replican automáticamente datos ni se revierten desde una región con errores para realizar la replicación cruzada en otra región habilitada. En esos servicios, es responsable de configurar un plan de recuperación ante desastres válido para su carga de trabajo. La mayoría de los servicios que se ejecutan en ofertas de plataforma como servicio (PaaS) de Azure proporcionan características e instrucciones para admitir la recuperación ante desastres y puede usar características específicas del servicio para admitir la recuperación rápida para ayudar a desarrollar el plan de recuperación ante desastres.
Los clústeres de Azure HDInsight dependen de muchos servicios de Azure, como almacenamiento, bases de datos, Active Directory, Active Directory Domain Services, redes y Key Vault. Una aplicación de análisis bien diseñada, de alta disponibilidad y tolerante a errores debe diseñarse con suficiente redundancia para resistir las interrupciones regionales o locales en uno o varios de estos servicios. En esta sección se proporciona información general sobre los procedimientos recomendados, la disponibilidad de una sola región y varias regiones, y las opciones de optimización para el planeamiento de la continuidad empresarial.
Recuperación ante desastres en la geografía de varias regiones
La mejora de la continuidad empresarial mediante la recuperación ante desastres de alta disponibilidad entre regiones requiere diseños arquitectónicos de mayor complejidad y un costo más alto. En las siguientes tablas se detallan algunas áreas técnicas que pueden aumentar el costo total de propiedad.
Optimizaciones de costos
| Área | Causa de la escalación de costo | Estrategias de optimización |
|---|---|---|
| Almacenamiento de datos | Duplicación de tablas o datos principales en una región secundaria. | Replique solo los datos mantenidos. |
| Salida de datos | Las transferencias de datos entre regiones salientes tienen un precio. Revise las directrices de precios de ancho de banda. | Replique solo los datos mantenidos para reducir la superficie de salida de la región. |
| Cálculo del clúster | Clústeres de HDInsight adicionales en la región secundaria. | Use scripts automatizados para implementar un proceso secundario después del error principal. Use el escalado automático para mantener el tamaño del clúster secundario al mínimo. Use SKU de máquinas virtuales más baratas. Cree los clústeres secundarios en las regiones donde se pueden descontar las SKU de máquinas virtuales. |
| Autenticación | Los escenarios multiusuario de la región secundaria incurren en configuraciones adicionales de Microsoft Entra Domain Services. | Evite las configuraciones multiusuario en la región secundaria. |
Optimizaciones de complejidad
| Área | Causa de la escalación de complejidad | Estrategias de optimización |
|---|---|---|
| Patrones de lectura y escritura | Requerir que los elementos primarios y secundarios estén habilitados para lectura y escritura. | Diseñe el elemento secundario para que sea de solo lectura. |
| RTO y RPO cero | Requerir pérdida de datos cero (RPO = 0) y tiempo de inactividad cero (RTO = 0). | Diseñe RPO y RTO de manera que se reduzca el número de componentes que deben conmutar por error. Para obtener más información sobre RTO y RPO, consulte ¿Qué son la continuidad empresarial, la alta disponibilidad y la recuperación ante desastres?. |
| Funcionalidad empresarial | Requerir toda la funcionalidad empresarial de la primaria en la secundaria. | Evalúe si puede realizar la ejecución con un subconjunto crítico mínimo básico de la funcionalidad empresarial en la secundaria. |
| Conectividad | Requerir que todos los sistemas ascendentes y descendentes de la conectividad primaria se conecten también a la secundaria. | Limite la conectividad secundaria a un subconjunto crítico mínimo básico. |
Cuando el plan de recuperación ante desastres de varias regiones, tenga en cuenta las siguientes recomendaciones:
Determine la funcionalidad de negocio mínima que necesitará si se produce un desastre y por qué. Por ejemplo, evalúe si necesita capacidades de conmutación por error para la capa de transformación de datos (que se muestra en amarillo) y la capa de servicio de datos (que se muestra en azul) o si solo necesita conmutación por error para la capa de servicio de datos.
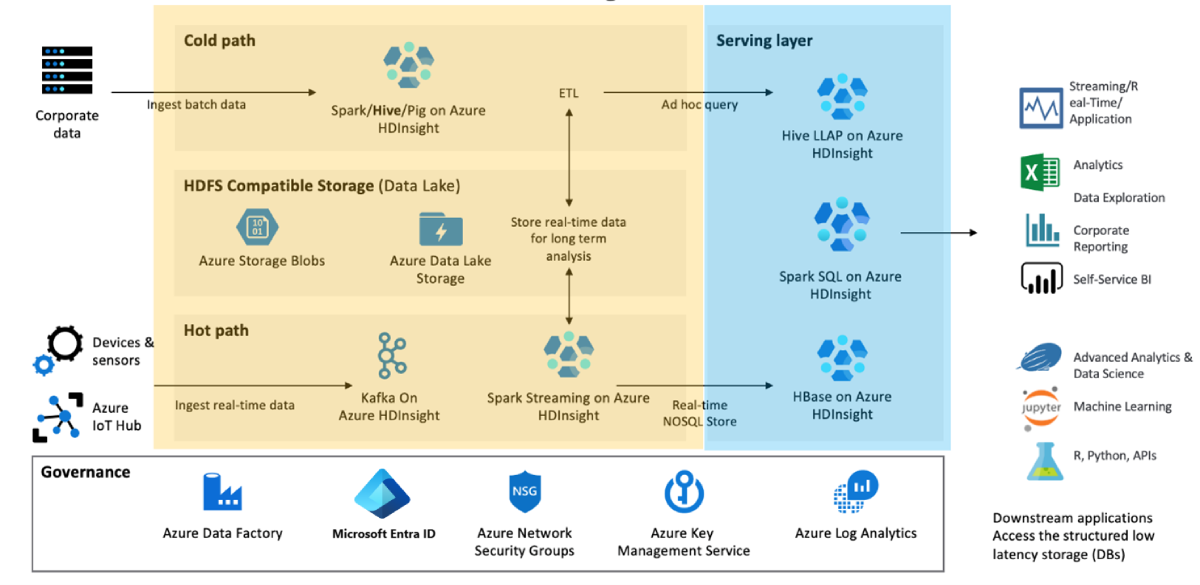
Segmente los clústeres en función de la carga de trabajo, el ciclo de vida de desarrollo y los departamentos. El hecho de tener más clústeres reduce las posibilidades de que un único error grande afecte a varios procesos empresariales diferentes.
Haga que sus regiones secundarias sean de solo lectura. Las regiones de conmutación por error con capacidades de lectura y escritura pueden conducir a arquitecturas complejas.
Los clústeres transitorios son más fáciles de administrar cuando se produce un desastre. Diseñe sus cargas de trabajo de forma que los clústeres se puedan reciclar y no se mantenga ningún estado en ellos.
A menudo, las cargas de trabajo se dejan sin terminar si se produce un desastre y es necesario reiniciar en la nueva región. Diseñe las cargas de trabajo para que sean idempotentes por naturaleza.
Use la automatización durante las implementaciones de clústeres y asegúrese de que los valores de configuración del clúster se incluyen en el script en la medida de lo posible para garantizar una implementación rápida y totalmente automatizada si se produce un desastre.
Detección, notificación y administración de interrupciones
Use las herramientas de supervisión de Azure en HDInsight para detectar un comportamiento anómalo en el clúster y establecer las notificaciones de alerta correspondientes. Puede implementar las soluciones de administración específicas del clúster de HDInsight preconfiguradas que recopilan las métricas de rendimiento importantes del tipo de clúster específico. Para más información, consulte Supervisión de Azure para HDInsight.
Suscríbase a las alertas de estado de Azure para recibir notificaciones sobre problemas de servicio, mantenimiento planeado, avisos de estado y seguridad para una suscripción, un servicio o una región. Las notificaciones de estado que incluyen la causa del problema y la hora de llegada estimada resuelta le ayudan a ejecutar mejor la conmutación por error y la conmutación por recuperación. Para obtener más información, consulte Documentación de Azure Service Health.
Recuperación ante desastres en una sola región geográfica
Cada componente de un sistema HDInsight básico tiene sus propios mecanismos de tolerancia a errores de una sola región. Tenga en cuenta que no siempre toma un evento catastrófico para afectar a la funcionalidad empresarial. Los incidentes de servicio en uno o varios de los servicios siguientes en una sola región también pueden provocar la pérdida de la funcionalidad empresarial esperada.
Proceso (máquinas virtuales): clúster de Azure HDInsight. HDInsight ofrece un Acuerdo de Nivel de Servicio de disponibilidad del 99,9 %. Para proporcionar alta disponibilidad en una sola implementación, HDInsight viene acompañado de muchos servicios que están en modo de alta disponibilidad de manera predeterminada. Los mecanismos de tolerancia a errores de HDInsight los proporcionan los servicios de alta disponibilidad de los ecosistemas de Microsoft y Apache OSS.
Los siguientes componentes de infraestructura están diseñados para ser de alta disponibilidad:
- Nodos principales activos y en espera
- Varios nodos de puerta de enlace
- Tres nodos de Quorum de Zookeeper
- Nodos de trabajo distribuidos por dominios de actualización y de error
Los siguientes servicios también están diseñados para ser de alta disponibilidad:
- Servidor Apache Ambari
- Servidores de escala de tiempo de la aplicación para YARN
- Servidor de Historial de trabajos para MapReduce de Hadoop
- Apache Livy
- HDFS
- YARN Resource Manager
- HBase Master
Para más información, consulte servicios de alta disponibilidad admitidos con Azure HDInsight.
Metastores: Azure SQL Database. HDInsight usa Azure SQL Database como metastore, lo que proporciona un Acuerdo de Nivel de Servicio del 99,99 %. Se conservan tres réplicas de datos dentro de un centro de datos con replicación sincrónica. Si se produce una pérdida de réplica, se proporciona una réplica alternativa sin problemas. La replicación geográfica activa es compatible de forma integrada con un máximo de cuatro centros de datos. Cuando hay una conmutación por error, ya sea manual o del centro de datos, la primera réplica de la jerarquía se convierte automáticamente en compatible con lectura y escritura. Para más información, consulte Continuidad empresarial de Azure SQL Database.
Storage: Azure Data Lake Gen2 o Blob Storage. HDInsight recomienda Azure Data Lake Storage Gen2 como capa de almacenamiento subyacente. Azure Storage, incluido Azure Data Lake Storage Gen2, proporciona un Acuerdo de Nivel de Servicio del 99,9 %. HDInsight usa el servicio LRS en el que se conservan tres réplicas de datos dentro de un centro de datos y la replicación es sincrónica. Si se produce una pérdida de réplica, se proporciona una réplica sin problemas.
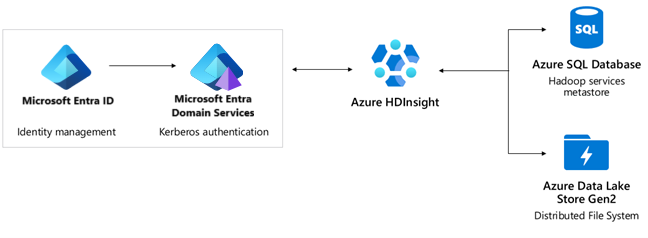
Autenticación: Microsoft Entra ID, Microsoft Entra Domain Services, Enterprise Security Package.
- Microsoft Entra ID proporciona un Acuerdo de Nivel de Servicio del 99,9 %. Active Directory es un servicio global con varios niveles de redundancia interna y capacidad de recuperación automática. Para obtener más información, consulte cómo Microsoft en la mejora continua de la confiabilidad del Microsoft Entra ID.
- Microsoft Entra Domain Services proporciona un Acuerdo de Nivel de Servicio del 99,9 %. Microsoft Entra Domain Services es un servicio de alta disponibilidad hospedado en centros de datos distribuidos globalmente. Los conjuntos de réplicas son una característica en vista previa de Microsoft Entra Domain Services que habilita la recuperación geográfica ante desastres si una región de Azure se queda sin conexión. Para más información, consulte conjuntos de réplicas conceptos y características de Microsoft Entra Domain Services para obtener más información.
- Azure DNS proporciona un Acuerdo de Nivel de Servicio del 100 %. HDInsight usa Azure DNS en varios lugares para la resolución de nombres de dominio.
Servicios opcionales, como Azure Key Vault y Azure Data Factory.