Arquitecturas de continuidad empresarial de Azure HDInsight
En este artículo se ofrecen algunos ejemplos de arquitecturas de continuidad empresarial que puede que quiera tener en cuenta para Azure HDInsight. La tolerancia a una función reducida durante un desastre es una decisión empresarial que varía de una aplicación a otra. En el caso de algunas aplicaciones, puede ser aceptable que no estén disponibles o que lo estén de forma parcial con función reducida o retrasos en el procesamiento durante un tiempo. Sin embargo, en el caso de otras, cualquier función reducida podría ser inaceptable.
Nota:
Las arquitecturas que se presentan en este artículo no son en absoluto completas. Debe diseñar sus propias arquitecturas únicas una vez que haya realizado determinaciones objetivas en torno a la continuidad empresarial esperada, la complejidad operativa y el costo de propiedad.
Apache Hive e Interactive Query
Hive Replication V2 es la versión recomendada para la continuidad empresarial en los clústeres de Hive e Interactive Query de HDInsight. Las secciones persistentes de un clúster de Hive independiente que deben replicarse son la Capa de almacenamiento y el metastore de Hive. Los clústeres de Hive en un escenario de varios usuarios con Enterprise Security Package necesitan Microsoft Entra Domain Services y el metastore de Ranger.
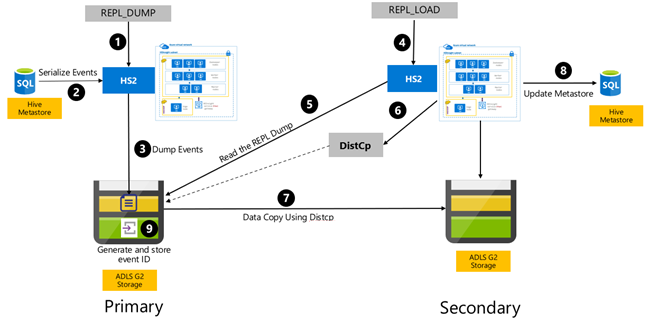
La replicación basada en eventos de Hive se configura entre los clústeres principal y secundario. Se compone de dos fases distintas, arranque y ejecuciones incrementales:
El arranque replica todo el almacén de Hive, incluida la información del metastore de Hive, de principal a secundario.
Las ejecuciones incrementales se automatizan en el clúster principal y los eventos generados durante las ejecuciones incrementales se reproducen en el clúster secundario. El clúster secundario se pone al día con los eventos generados en el clúster principal, asegurándose de que el clúster secundario es coherente con los eventos del clúster principal después de la ejecución de la replicación.
El clúster secundario solo es necesario en el momento de la replicación para ejecutar la copia distribuida, DistCp, pero el almacenamiento y los metastores deben ser persistentes. Puede optar por poner en marcha un clúster secundario con scripts a petición antes de la replicación, ejecutar el script de replicación en él y, después, anularlo después de la replicación correcta.
El clúster secundario normalmente es de solo lectura. Puede hacer que el clúster secundario sea de lectura y escritura, pero esto agrega complejidad adicional que implica la replicación de los cambios del clúster secundario en el clúster principal.
RPO y RTO de replicación basada en eventos de Hive
RPO: la pérdida de datos se limita al último evento de replicación incremental correcto, de principal a secundario.
RTO: el tiempo que existe entre el error y la reanudación de las transacciones ascendentes y descendentes con el secundario.
Arquitecturas de Apache Hive e Interactive Query
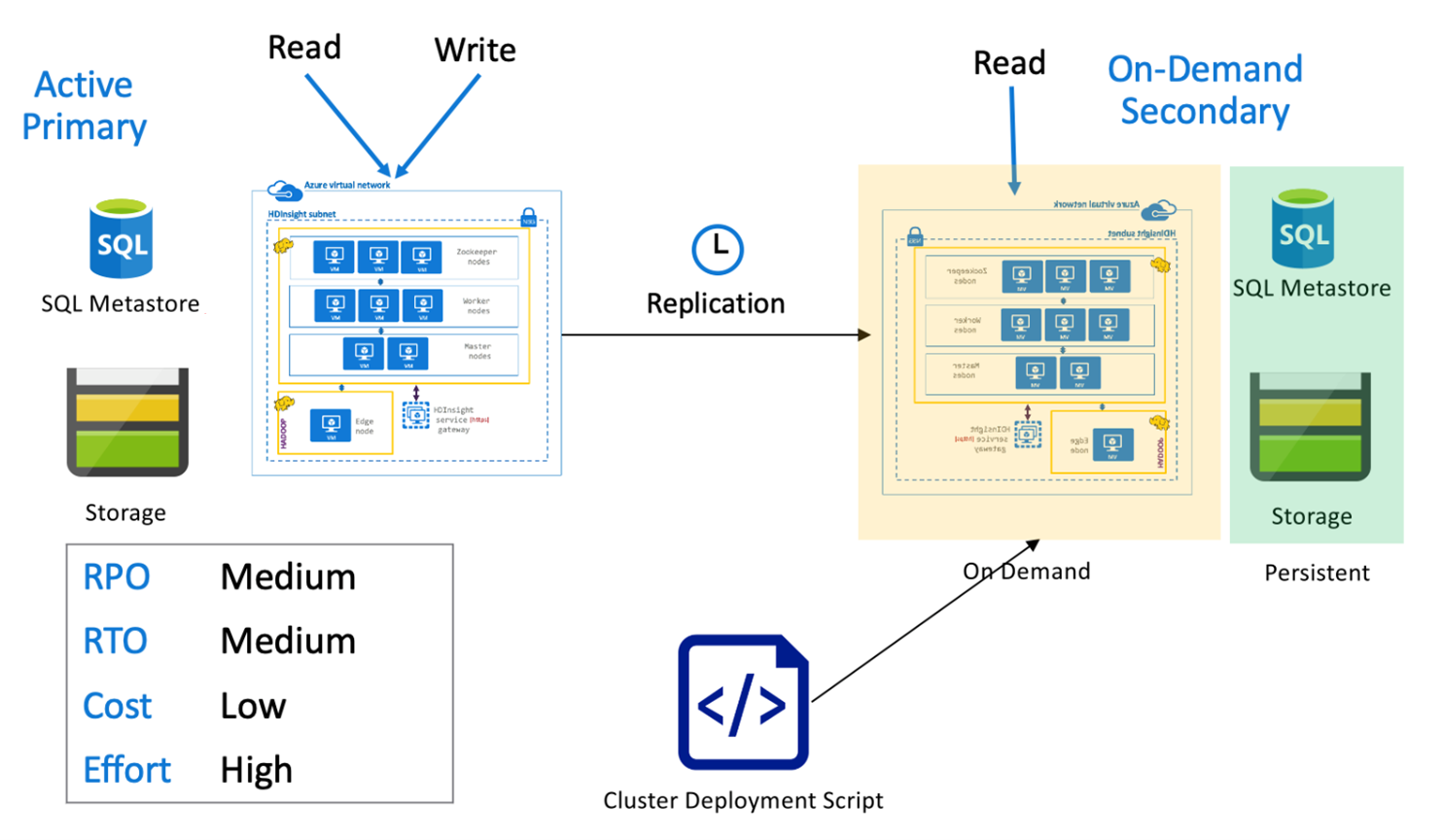
Primaria activa con secundaria a petición de Hive
En una arquitectura primaria activa con secundaria a petición, las aplicaciones escriben en la región primaria activa mientras no se aprovisiona ningún clúster en la región secundaria durante las operaciones normales. El metastore y el almacenamiento de SQL de la región secundaria son persistentes, mientras que el clúster de HDInsight se genera mediante script y se implementa a petición solo antes de que se ejecute la replicación de Hive programada.
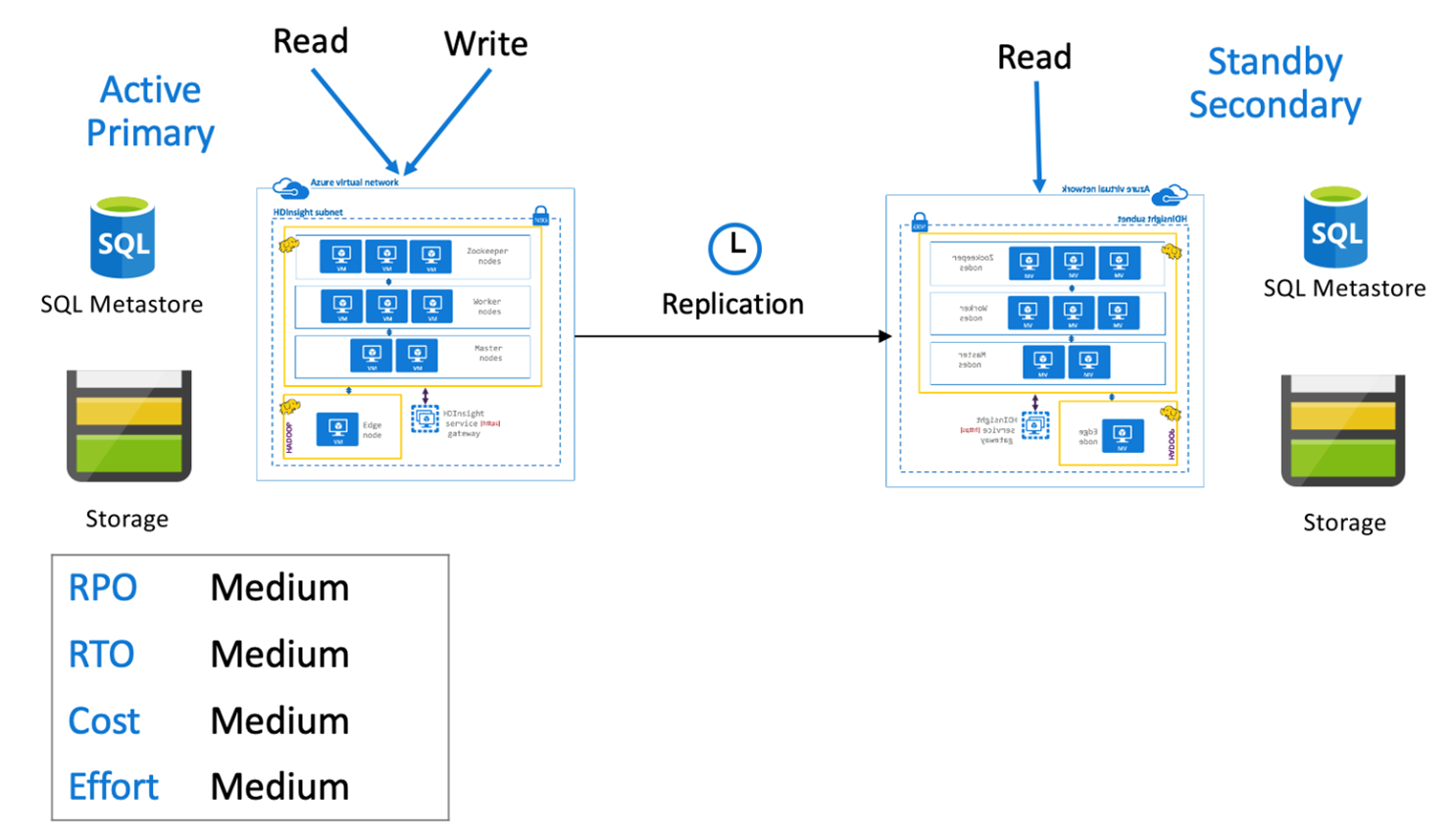
Primaria activa con secundaria en espera de Hive
En una arquitectura primaria activa con secundaria en espera, las aplicaciones escriben en la región primaria activa mientras que un clúster secundario reducido verticalmente en espera en modo de solo lectura se ejecuta durante las operaciones normales. En el transcurso de estas operaciones, puede optar por descargar las operaciones de lectura específicas de la región en la secundaria.
Para obtener más información sobre la replicación de Hive y observar ejemplos de código, vea Uso de la replicación de Apache Hive en clústeres de Azure HDInsight.
Spark de Apache
Las cargas de trabajo de Spark pueden implicar o no un componente de Hive. Para permitir que las cargas de trabajo de Spark SQL lean y escriban datos de Hive, los clústeres de HDInsight Spark comparten los metastores personalizados de Hive desde clústeres de Hive o Interactive Query en la misma región. En estos escenarios, la replicación entre regiones de las cargas de trabajo de Spark también debe acompañar a la replicación de almacenamiento y metastores de Hives. Los escenarios de conmutación por error de esta sección se aplican a ambos:
- Instalación de Spark SQL en tablas ACID mediante la instalación de Hive Warehouse Connector (HWC) con un clúster de HDInsight Interactive Query.
- Carga de trabajo de Spark SQL en tablas que no son ACID mediante un clúster de HDInsight Hadoop.
En el caso de los escenarios en los que Spark funciona en modo independiente, los datos mantenidos y los archivos JAR de Spark almacenados (para trabajos de Livy) deben replicarse desde la región primaria a la secundaria de forma regular mediante DistCP de Azure Data Factory.
Se recomienda usar sistemas de control de versiones para almacenar cuadernos y bibliotecas de Spark donde se pueden implementar fácilmente en clústeres principales o secundarios. Asegúrese de que, tanto las soluciones basadas en cuadernos como las no basadas en estos, están preparadas para cargar los montajes de datos correctos en el área de trabajo principal o secundaria.
Si hay bibliotecas específicas del cliente que van más allá de lo que HDInsight proporciona de forma nativa, se les debe realizar el seguimiento y se deben cargar periódicamente en el clúster secundario en espera.
Replicación RPO y RTO de Apache Spark
RPO: la pérdida de datos se limita a la última replicación incremental correcta (Spark y Hive), de principal a secundario.
RTO: el tiempo que existe entre el error y la reanudación de las transacciones ascendentes y descendentes con el secundario.
Arquitecturas de Apache Spark
Activa primaria con secundaria a petición de Spark
Las aplicaciones leen y escriben en los clústeres de Spark y Hive en la región primaria, mientras que no se aprovisiona ningún clúster en la región secundaria durante las operaciones normales. El metastore de SQL, el almacenamiento de Hive y el almacenamiento de Spark son persistentes en la región secundaria. Los clústeres de Spark y Hive se generan mediante scripts y se implementan a petición. La replicación de Hive se usa para replicar el almacenamiento y los metastores de Hive mientras el elemento DistCP de Azure Data Factory se puede usar para copiar el almacenamiento independiente de Spark. Los clústeres de Hive deben implementarse antes de que se ejecuten todas las replicaciones de Hive debido al proceso DistCp de dependencia.

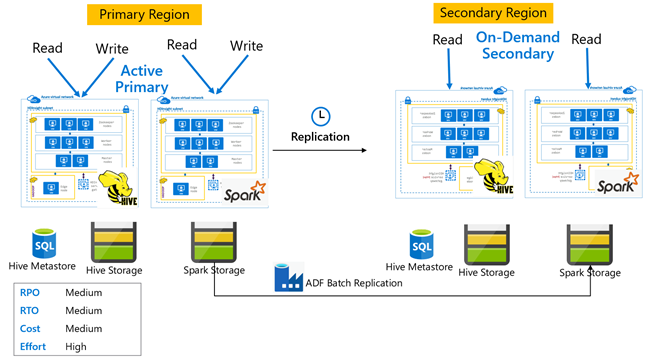
Primaria activa con secundaria en espera de Spark
Las aplicaciones leen y escriben en los clústeres de Spark y Hive en la región primaria, mientras que los clústeres de Hive y Spark reducidos verticalmente en espera en modo de solo lectura se ejecutan en la región secundaria durante las operaciones normales. Durante las operaciones normales, puede optar por descargar las operaciones de lectura de Hive y Spark específicas de la región en la secundaria.
HBase Apache
La exportación y la replicación de HBase son formas comunes de habilitar la continuidad empresarial entre los clústeres de HDInsight HBase.
La exportación de HBase es un proceso de replicación por lotes que usa la utilidad de exportación de HBase para exportar tablas del clúster primario de HBase a su almacenamiento subyacente de Azure Data Lake Storage Gen 2. Después, se puede acceder a los datos exportados desde el clúster secundario de HBase e importarlos en las tablas que deben existir previamente en el secundario. Aunque la exportación de HBase ofrece granularidad de nivel de tabla, en situaciones de actualización incremental, el motor de automatización de exportación controla el intervalo de filas incrementales que se van a incluir en cada ejecución. Para obtener más información, vea Copia de seguridad y replicación de HDInsight HBase.
La replicación de HBase usa la replicación casi en tiempo real entre los clústeres de HBase de forma totalmente automatizada. La replicación se realiza en el nivel de tabla. Para la replicación, se pueden establecer como destino todas las tablas o tablas específicas. La replicación de HBase es coherente en última instancia, lo que significa que es posible que las ediciones recientes en una tabla de la región primaria no estén disponibles para todas las regiones secundarias de forma inmediata. Se garantiza que, en última instancia, las secundarias sean coherentes con la primaria. La replicación de HBase se puede configurar entre dos o más clústeres de HDInsight HBase si se cumple lo siguiente:
- Las regiones primaria y secundaria están en la misma red virtual.
- Las regiones primaria y secundaria están en diferentes redes virtuales emparejadas de la misma región.
- Las regiones primaria y secundaria están en diferentes redes virtuales emparejadas en distintas regiones.
Para obtener más información, vea Configuración de la replicación de clústeres de Apache HBase en redes virtuales de Azure.
Hay algunas otras formas de realizar copias de seguridad de clústeres de HBase, como copiar la carpeta HBasecopiar tablas e instantáneas.
RPO y RTO de HBase
Exportación de HBase
- RPO: la pérdida de datos se limita a la última importación incremental por lotes correcta de la región secundaria desde la primaria.
- RTO: el tiempo que existe entre el error de la primaria y la reanudación de las operaciones de E/S en la secundaria.
Replicación de HBase
- RPO: la pérdida de datos se limita al último envío de WalEdit recibido en la región secundaria.
- RTO: el tiempo que existe entre el error de la primaria y la reanudación de las operaciones de E/S en la secundaria.
Arquitecturas de HBase
La replicación de HBase se puede configurar en tres modos: Líder-seguidor, Líder-líder y Cíclico.
Replicación de HBase: modelo Líder-seguidor
En esta configuración entre regiones, la replicación es unidireccional desde la región primaria a la secundaria. Para la replicación unidireccional se pueden identificar todas las tablas o tablas específicas de la región primaria. Durante las operaciones normales, el clúster secundario se puede usar para atender las solicitudes de lectura en su propia región.
El clúster secundario funciona como un clúster de HBase normal que puede hospedar sus propias tablas y puede atender a lecturas y escrituras a partir de aplicaciones regionales. Sin embargo, las escrituras en las tablas replicadas o las tablas nativas a secundarias no se replican de nuevo en la primaria.
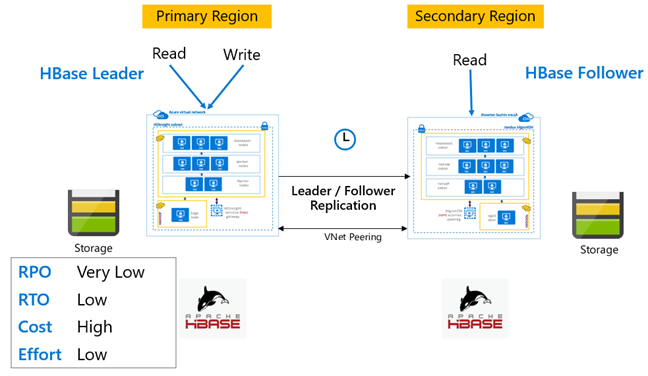
Replicación de HBase: modelo de líder
Esta configuración entre regiones es muy similar a la unidireccional, salvo que la replicación se produce de forma bidireccional entre la región primaria y la secundaria. Las aplicaciones pueden usar ambos clústeres en modo de lectura y escritura y las actualizaciones son intercambios de forma asincrónica entre ellos.
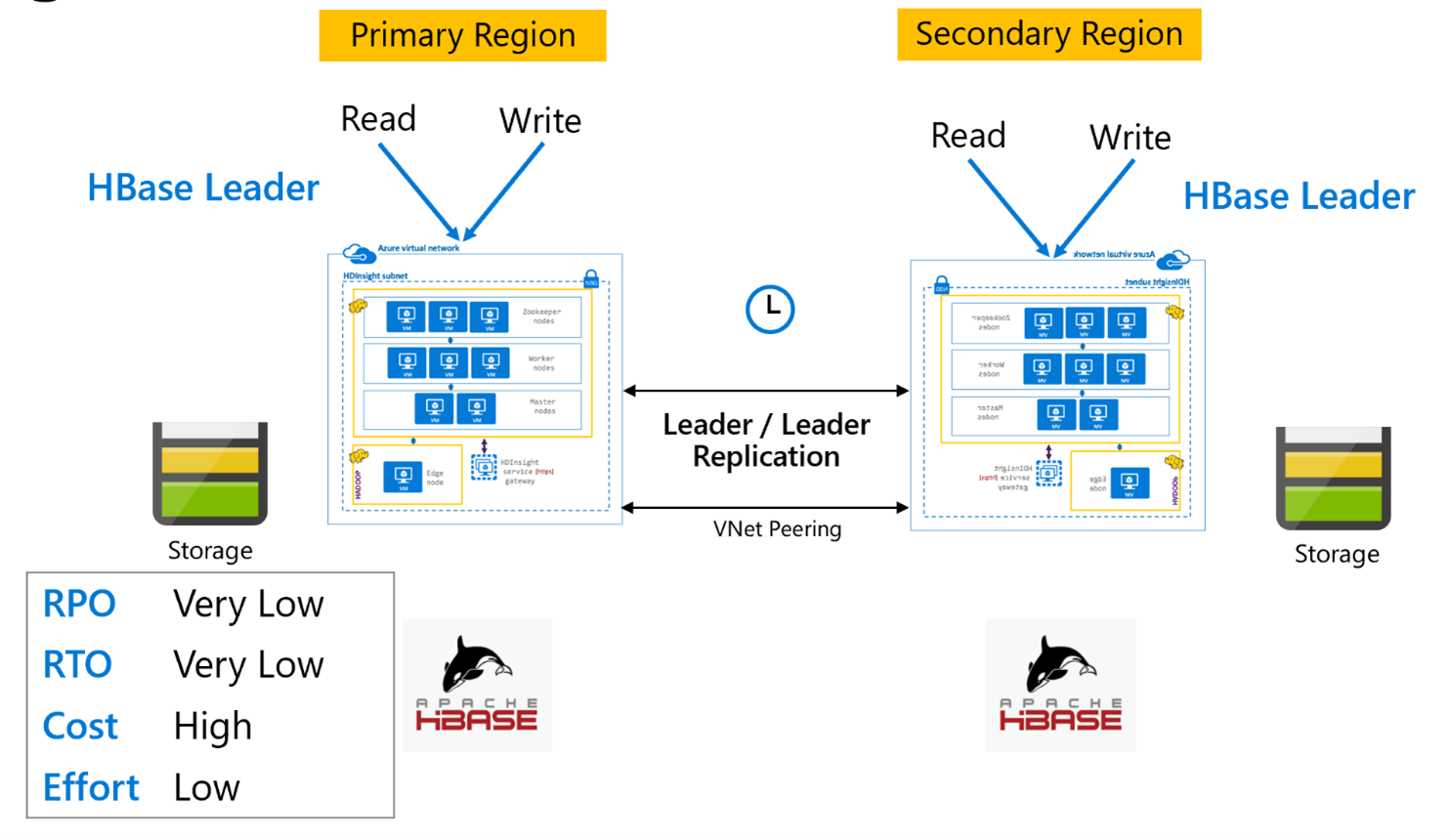
Replicación de HBase: Varias regiones o Cíclico
El modelo de replicación de Varias regiones o Cíclico es una extensión de la replicación de HBase y se puede usar para crear una arquitectura de HBase globalmente redundante con varias aplicaciones que leen y escriben en clústeres de HBase específicos de la región. Los clústeres se pueden configurar en varias combinaciones de Líder/líder o de Líder/seguidor, en función de los requisitos empresariales.

Apache Kafka
Para habilitar la disponibilidad entre regiones, HDInsight 4.0 es compatible con Kafka MirrorMaker, que se puede usar a fin de mantener una réplica secundaria del clúster primario de Kafka en otra región. MirrorMaker actúa como un par de consumidor-productor de alto nivel, consume a partir de un tema específico en el clúster principal y genera un tema con el mismo nombre en el servidor secundario. La replicación entre clústeres para la recuperación ante desastres de alta disponibilidad mediante MirrorMaker incluye la suposición de que los productores y consumidores deben conmutar por error en el clúster de réplicas. Para obtener más información, vea Uso de MirrorMaker para replicar temas de Apache Kafka con Kafka en HDInsight.
En función de la duración del tema cuando se inicia la replicación, la replicación del tema de MirrorMaker puede conducir a distintos desplazamientos entre los temas de origen y de réplica. Los clústeres de HDInsight Kafka también admiten la replicación de particiones de temas, que es una característica de alta disponibilidad en el nivel de clúster individual.

Arquitecturas de Apache Kafka
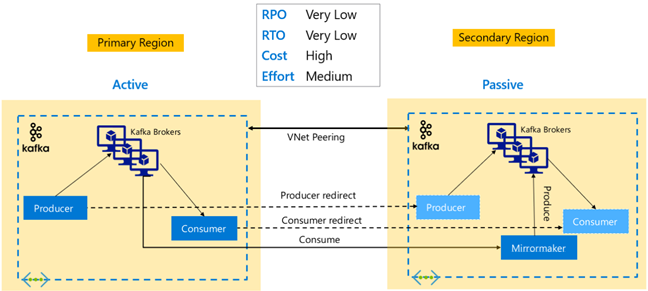
Replicación de Kafka: Activo-pasivo
La configuración Activo-Pasivo permite la creación de reflejo unidireccional asíncrono de Activo a Pasivo. Los productores y consumidores deben tener en cuenta la existencia de un clúster Activo y Pasivo y deben estar preparados para conmutar por error en el Pasivo en caso de que se produzca un error en el Activo. A continuación se muestran algunas ventajas y desventajas de la configuración Activo-pasivo.
Ventajas:
- La latencia de red entre clústeres no afecta al rendimiento del clúster Activo.
- Simplicidad en la replicación unidireccional.
Desventajas:
- El clúster Pasivo puede continuar infrautilizado.
- Complejidad de diseño en la incorporación de reconocimiento de la conmutación por error en productores y consumidores de aplicaciones.
- Posible pérdida de datos durante el error del clúster Activo.
- Coherencia final entre los temas de los clústeres Activos y Pasivo.
- Las conmutaciones por recuperación en la primaria pueden dar lugar a incoherencias de mensajes en los temas.
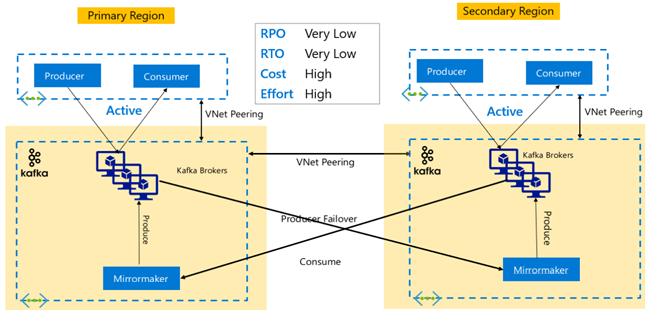
Replicación de Kafka: Activo-activo
La configuración activo-activo implica dos clústeres de Kafka de HDInsight emparejados con la red virtual, separados por regiones y con replicación asincrónica bidireccional con MirrorMaker. En este diseño, los mensajes que consumen los consumidores de la región primaria también se ponen a disposición de los consumidores de la secundaria y viceversa. A continuación se muestran algunas ventajas y desventajas de la configuración de Activo-activo.
Ventajas:
- Debido a su estado duplicado, las conmutaciones por error y las conmutaciones por recuperación son más fáciles de ejecutar.
Desventajas:
- La configuración, la administración y la supervisión son más complejas que las del modelo Activo-pasivo.
- Debe abordarse el problema de la replicación circular.
- La replicación bidireccional supone costos de salida de datos regionales más altos.
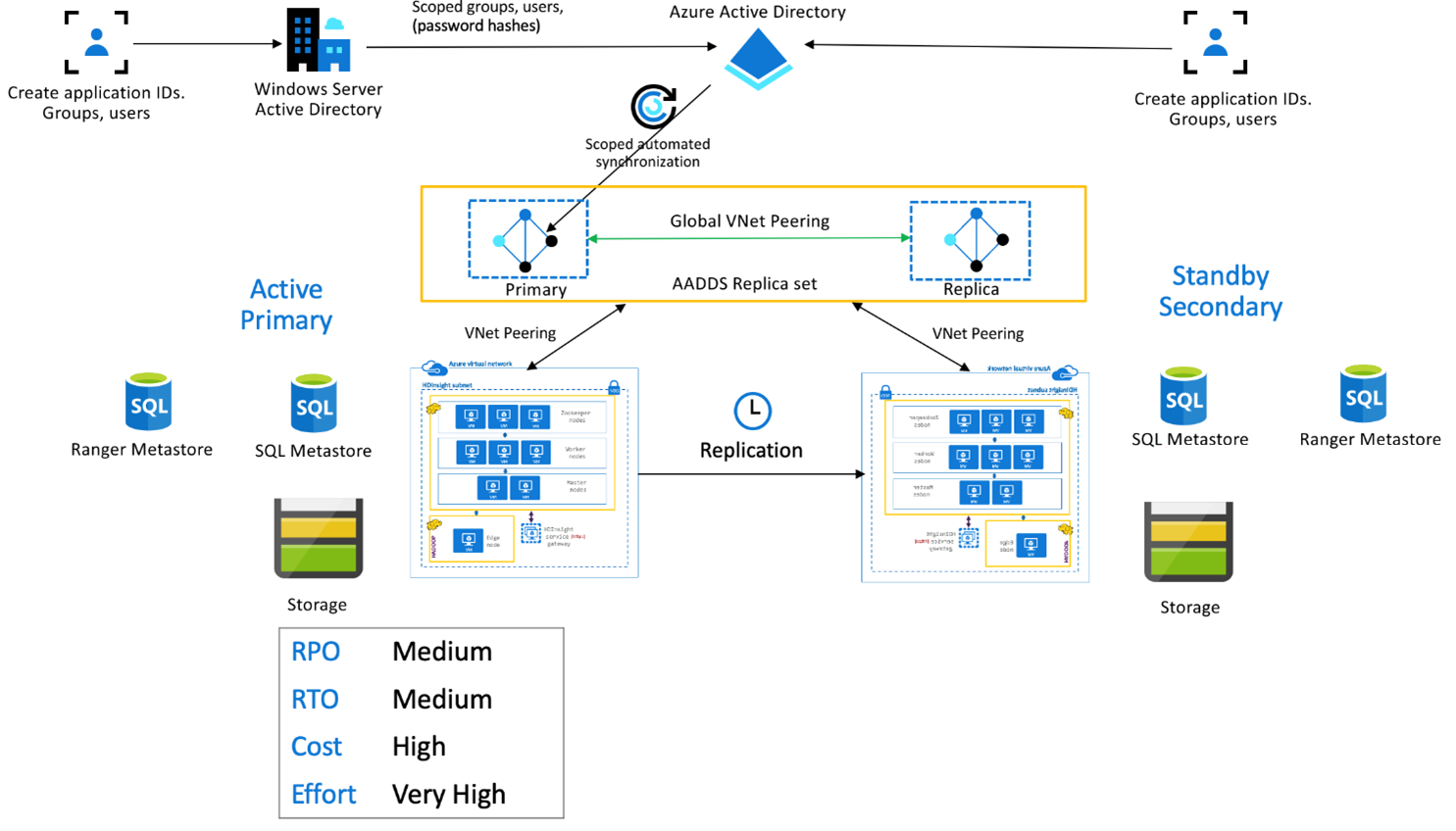
Enterprise Security Package de Azure HDInsight
Esta configuración se usa para habilitar la función de varios usuarios en los conjuntos de réplicas primario y secundario, así como en conjuntos de réplicas de Microsoft Entra Domain Services, a fin de asegurarse de que los usuarios puedan autenticarse en ambos clústeres. Durante las operaciones normales, es necesario configurar las directivas de Ranger en el secundario para asegurarse de que los usuarios están restringidos a las operaciones de lectura. En la arquitectura siguiente, se explica el aspecto que podría tener una configuración primaria activa-secundaria en espera de Hive habilitada para ESP.
Replicación del metastore de Ranger:
El metastore de Ranger se utiliza para almacenar y servir de forma persistente directivas de Ranger para controlar la autorización de datos. Se recomienda mantener directivas de Ranger independientes en la primaria y secundaria, y mantener la secundaria como réplica de lectura.
Si el requisito es mantener sincronizadas las directivas de Ranger entre la primaria y la secundaria, use la importación/exportación de Ranger para realizar copias de seguridad periódicas e importar directivas de Ranger de la primaria a la secundaria.
La replicación de directivas de Ranger entre la primaria y la secundaria puede hacer que la secundaria esté habilitada para escritura, lo que puede dar lugar a escrituras involuntarias en la secundaria que provoquen incoherencias en los datos.
Pasos siguientes
Para más información sobre los elementos que se describen en este artículo, consulte: