Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
La limpieza de datos se convierte en uno de los aspectos más importantes de los proyectos de aprendizaje automático. La integración de la integración de Azure Machine Learning con Azure Synapse Analytics proporciona acceso a un grupo de Apache Spark, respaldado por Azure Synapse, para la limpieza de datos interactivos que usa cuadernos de Azure Machine Learning.
En este artículo, aprenderá a controlar la limpieza de datos mediante
- Proceso de Spark sin servidor
- Grupo de Spark de Synapse asociado
Requisitos previos
- Una suscripción a Azure: si aún no tiene ninguna, cree una cuenta gratuita antes de empezar.
- Un área de trabajo de Azure Machine Learning. Visite Crear recursos del área de trabajo para obtener más información.
- Una cuenta de almacenamiento de Azure Data Lake Storage (ADLS) Gen 2. Visite Crear una cuenta de almacenamiento de Azure Data Lake Storage (ADLS) Gen 2 para obtener más información.
- (Opcional): una instancia de Azure Key Vault. Visite Crear un Azure Key Vault para obtener más información.
- (Opcional): una entidad de servicio. Visite Crear una entidad de servicio para obtener más información.
- (Opcional): un grupo de Synapse Spark asociado en el área de trabajo de Azure Machine Learning.
Antes de iniciar las tareas de limpieza y transformación de datos, obtenga información sobre el proceso de almacenamiento de secretos.
- Clave de acceso de la cuenta de Azure Blob Storage
- Token de firma de acceso compartido (SAS)
- Información de la entidad de servicio de Azure Data Lake Storage (ADLS) Gen 2
en Azure Key Vault. También deberá saber cómo controlar las asignaciones de roles en las cuentas de almacenamiento de Azure. En las secciones siguientes de este documento se describen estos conceptos. A continuación, exploraremos los detalles de la limpieza de datos interactivos mediante los grupos de Spark en Azure Machine Learning Notebooks.
Sugerencia
Para obtener información sobre la configuración de asignación de roles de la cuenta de Almacenamiento de Azure o si accede a los datos de las cuentas de almacenamiento mediante el acceso directo de identidad de usuario, visite Agregar asignaciones de roles en cuentas de almacenamiento de Azure para obtener más información.
Limpieza y transformación de datos interactivos con Apache Spark
Para la limpieza de datos interactivos con Apache Spark en Cuadernos de Azure Machine Learning, Azure Machine Learning ofrece proceso de Spark sin servidor y grupo de Synapse Spark conectado. El proceso de Spark sin servidor no requiere la creación de recursos en el área de trabajo de Azure Synapse. En su lugar, un proceso de Spark sin servidor totalmente administrado está disponible directamente en los cuadernos de Azure Machine Learning. El uso de un proceso de Spark sin servidor es la manera más fácil de acceder a un clúster de Spark en Azure Machine Learning.
Proceso de Spark sin servidor en cuadernos de Azure Machine Learning
Un proceso de Spark sin servidor está disponible en cuadernos de Azure Machine Learning de manera predeterminada. Para acceder a él en un cuaderno, seleccione Proceso de Spark sin servidor en Spark sin servidor de Azure Machine Learning, en el menú de selección Proceso.
La interfaz de usuario de Notebooks también proporciona opciones para la configuración de sesión de Spark para el proceso de Spark sin servidor. Para configurar una sesión de Spark:
- Seleccione Configurar sesión en la parte superior de la pantalla.
- Seleccione una versión de Apache Spark en el menú desplegable.
Importante
Azure Synapse Runtime para Apache Spark: Anuncios
- Entorno de ejecución de Azure Synapse para Apache Spark 3.2:
- Fecha de anuncio de EOLA: 8 de julio de 2023
- Fecha de fin de la asistencia: 8 de julio de 2024. Luego de esta fecha, el tiempo de ejecución se desactivará.
- Apache Spark 3.3:
- Fecha de anuncio de EOLA: 12 de julio de 2024
- Fecha de finalización del soporte: 31 de marzo de 2025. Luego de esta fecha, el tiempo de ejecución se desactivará.
- Para obtener compatibilidad continua y un rendimiento óptimo, se recomienda la migración a Apache Spark 3.4
- Entorno de ejecución de Azure Synapse para Apache Spark 3.2:
- Seleccione Tipo de instancia en el menú desplegable. Actualmente se admiten estos tipos:
Standard_E4s_v3Standard_E8s_v3Standard_E16s_v3Standard_E32s_v3Standard_E64s_v3
- Escriba un valor de Tiempo de espera de sesión de Spark, en minutos.
- Seleccione si desea asignar ejecutores dinámicamente
- Seleccione el número de Ejecutores para la sesión de Spark.
- Seleccione Tamaño del ejecutor en el menú desplegable.
- Seleccione Tamaño del controlador en el menú desplegable.
- Para usar un archivo de Conda para configurar una sesión de Spark, seleccione la casilla Cargar archivo de Conda. A continuación, seleccione Examinar y elija el archivo de Conda con la configuración de sesión de Spark que quiera.
- Agregue propiedades de Opciones de configuración, valores de entrada en los cuadros de texto Propiedad y Valor y seleccione Agregar.
- Seleccione Aplicar.
- En la ventana emergente ¿Configurar nueva sesión?, seleccione Detener sesión.
Los cambios de configuración de sesión se conservan y están disponibles para otra sesión de cuaderno que se inicia mediante el proceso de Spark sin servidor.
Sugerencia
Si usa paquetes de Conda de nivel de sesión, puede mejorar el tiempo de arranque en frío si establece la variable de configuración spark.hadoop.aml.enable_cache en verdadero. El arranque en frío de sesión con paquetes de Conda de nivel de sesión suele tardar entre 10 y 15 minutos cuando la sesión se inicia por primera vez. Sin embargo, los arranques en frío de sesión posteriores con la variable de configuración establecida en true suelen tardar de tres a cinco minutos.
Importación y limpieza y transformación de datos de Azure Data Lake Storage (ADLS) Gen 2
Puede acceder y organizar datos almacenados en cuentas de almacenamiento de Azure Data Lake Storage (ADLS) Gen 2 con abfss:// URI de datos. Para ello, debe seguir uno de los dos mecanismos de acceso a datos:
- Paso a través de la identidad del usuario
- Acceso a datos basado en la entidad de servicio
Sugerencia
La limpieza y transformación de datos con un proceso de Spark sin servidor y el paso de identidad de usuario para acceder a datos en una cuenta de almacenamiento Azure Data Lake Storage (ADLS) Gen 2 requieren el menor número de pasos de configuración.
Para iniciar la limpieza y transformación de datos interactivos con el paso a través de la identidad del usuario:
Compruebe que la identidad del usuario tiene las asignaciones de roles Colaborador y Colaborador de datos de Storage Blob en la cuenta de almacenamiento de Azure Data Lake Storage (ADLS) Gen 2.
Para usar el proceso de Spark sin servidor, seleccione Proceso de Spark sin servidor en Spark sin servidor de Azure Machine Learning, en el menú de selección Proceso.
Para usar un grupo de Synapse Spark conectado, seleccione un grupo de Synapse Spark conectado en Grupos de Synapse Spark, en el menú de selección Proceso.
Este ejemplo de código de limpieza y transformación de datos de Titanic muestra el uso de un URI de datos en formato
abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/<PATH_TO_DATA>conpyspark.pandasypyspark.ml.feature.Imputer.import pyspark.pandas as pd from pyspark.ml.feature import Imputer df = pd.read_csv( "abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/data/titanic.csv", index_col="PassengerId", ) imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy( "mean" ) # Replace missing values in Age column with the mean value df.fillna( value={"Cabin": "None"}, inplace=True ) # Fill Cabin column with value "None" if missing df.dropna(inplace=True) # Drop the rows which still have any missing value df.to_csv( "abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/data/wrangled", index_col="PassengerId", )Nota:
En este ejemplo de código de Python se usa
pyspark.pandas. Esto solo se admite en el entorno de ejecución Spark versión 3.2 o posteriores.
Para limpiar y transformar los datos mediante el acceso a través de una entidad de servicio:
Compruebe que la entidad de servicio tiene las asignaciones de roles Colaborador y Colaborador de datos de Storage Blob en la cuenta de almacenamiento de Azure Data Lake Storage (ADLS) Gen 2.
Cree secretos de Azure Key Vault para el identificador de inquilino de la entidad de servicio, el identificador de cliente y los valores de secretos de cliente.
En el menú de selección de Compute, seleccione Computación Serverless Spark en Azure Machine Learning Serverless Spark. También puede seleccionar un grupo de Synapse Spark asociado en Grupos de Synapse Spark en el menú de selección de Compute.
Establezca el identificador de inquilino de la entidad de servicio, el identificador de cliente y los valores de secreto de cliente en la configuración y ejecute el ejemplo de código siguiente.
La llamada
get_secret()en el código depende del nombre de la instancia de Azure Key Vault y de los nombres de los secretos de Azure Key Vault creados para el id. de inquilino de la entidad de servicio, el id. de cliente y el secreto de cliente. Establezca estos valores o nombres de propiedad correspondientes en la configuración:- Propiedad de id. de cliente:
fs.azure.account.oauth2.client.id.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net - Propiedad de secreto de cliente:
fs.azure.account.oauth2.client.secret.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net - Propiedad de id. de inquilino:
fs.azure.account.oauth2.client.endpoint.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net - Valor de identificador de inquilino:
https://login.microsoftonline.com/<TENANT_ID>/oauth2/token
from pyspark.sql import SparkSession sc = SparkSession.builder.getOrCreate() token_library = sc._jvm.com.microsoft.azure.synapse.tokenlibrary.TokenLibrary # Set up service principal tenant ID, client ID and secret from Azure Key Vault client_id = token_library.getSecret("<KEY_VAULT_NAME>", "<CLIENT_ID_SECRET_NAME>") tenant_id = token_library.getSecret("<KEY_VAULT_NAME>", "<TENANT_ID_SECRET_NAME>") client_secret = token_library.getSecret("<KEY_VAULT_NAME>", "<CLIENT_SECRET_NAME>") # Set up service principal which has access of the data sc._jsc.hadoopConfiguration().set( "fs.azure.account.auth.type.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", "OAuth" ) sc._jsc.hadoopConfiguration().set( "fs.azure.account.oauth.provider.type.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider", ) sc._jsc.hadoopConfiguration().set( "fs.azure.account.oauth2.client.id.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", client_id, ) sc._jsc.hadoopConfiguration().set( "fs.azure.account.oauth2.client.secret.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", client_secret, ) sc._jsc.hadoopConfiguration().set( "fs.azure.account.oauth2.client.endpoint.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", "https://login.microsoftonline.com/" + tenant_id + "/oauth2/token", )- Propiedad de id. de cliente:
Utilizando los datos del Titanic, importe y procese los datos utilizando la URI de datos en el formato
abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/<PATH_TO_DATA>que se muestra en el ejemplo de código.
Importación y limpieza y transformación de datos de Azure Blob Storage
Puede acceder a los datos de Azure Blob Storage con la clave de acceso de la cuenta de almacenamiento o un token de firma de acceso compartido (SAS). Debe almacenar estas credenciales en Azure Key Vault como un secreto y establecerlas como propiedades en la configuración de la sesión.
Para iniciar la limpieza y transformación de datos interactivos:
En el panel izquierdo de Estudio de Azure Machine Learning, seleccione Notebooks.
En el menú de selección de Compute, seleccione Computación Serverless Spark en Azure Machine Learning Serverless Spark. También puede seleccionar un grupo de Synapse Spark asociado en Grupos de Synapse Spark en el menú de selección de Compute.
Para configurar la clave de acceso de la cuenta de almacenamiento o un token de firma de acceso compartido (SAS) para el acceso a datos en los cuadernos de Azure Machine Learning:
Para la clave de acceso, establezca la propiedad
fs.azure.account.key.<STORAGE_ACCOUNT_NAME>.blob.core.windows.net, como se muestra en este fragmento de código:from pyspark.sql import SparkSession sc = SparkSession.builder.getOrCreate() token_library = sc._jvm.com.microsoft.azure.synapse.tokenlibrary.TokenLibrary access_key = token_library.getSecret("<KEY_VAULT_NAME>", "<ACCESS_KEY_SECRET_NAME>") sc._jsc.hadoopConfiguration().set( "fs.azure.account.key.<STORAGE_ACCOUNT_NAME>.blob.core.windows.net", access_key )Para el token de SAS, establezca la propiedad
fs.azure.sas.<BLOB_CONTAINER_NAME>.<STORAGE_ACCOUNT_NAME>.blob.core.windows.net, como se muestra en este fragmento de código:from pyspark.sql import SparkSession sc = SparkSession.builder.getOrCreate() token_library = sc._jvm.com.microsoft.azure.synapse.tokenlibrary.TokenLibrary sas_token = token_library.getSecret("<KEY_VAULT_NAME>", "<SAS_TOKEN_SECRET_NAME>") sc._jsc.hadoopConfiguration().set( "fs.azure.sas.<BLOB_CONTAINER_NAME>.<STORAGE_ACCOUNT_NAME>.blob.core.windows.net", sas_token, )Nota:
Las llamadas
get_secret()en los fragmentos de código anteriores requieren el nombre de Azure Key Vault y los nombres de los secretos creados para la clave de acceso de la cuenta de almacenamiento de blobs de Azure o el token SAS.
Ejecute el código de limpieza y transformación de datos en el mismo cuaderno. Aplique formato al URI de datos como
wasbs://<BLOB_CONTAINER_NAME>@<STORAGE_ACCOUNT_NAME>.blob.core.windows.net/<PATH_TO_DATA>, similar a lo que se muestra en este fragmento de código:import pyspark.pandas as pd from pyspark.ml.feature import Imputer df = pd.read_csv( "wasbs://<BLOB_CONTAINER_NAME>@<STORAGE_ACCOUNT_NAME>.blob.core.windows.net/data/titanic.csv", index_col="PassengerId", ) imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy( "mean" ) # Replace missing values in Age column with the mean value df.fillna( value={"Cabin": "None"}, inplace=True ) # Fill Cabin column with value "None" if missing df.dropna(inplace=True) # Drop the rows which still have any missing value df.to_csv( "wasbs://<BLOB_CONTAINER_NAME>@<STORAGE_ACCOUNT_NAME>.blob.core.windows.net/data/wrangled", index_col="PassengerId", )Nota:
En este ejemplo de código de Python se usa
pyspark.pandas. Esto solo se admite en el entorno de ejecución Spark versión 3.2 o posteriores.
Importación y limpieza y transformación de datos desde el almacén de datos de Azure Machine Learning
Para acceder a los datos desde el Almacén de datos de Azure Machine Learning, defina una ruta de acceso a los datos en el almacén de datos con formato de URI azureml://datastores/<DATASTORE_NAME>/paths/<PATH_TO_DATA>. Para limpiar y transformar datos de un almacén de datos de Azure Machine Learning en una sesión de Notebooks de forma interactiva:
Seleccione Proceso de Spark sin servidor en Spark sin servidor de Azure Machine Learning en el menú de selección Proceso, o seleccione un grupo de Synapse Spark adjunto en Grupos de Synapse Spark en el menú de selección Proceso.
Este ejemplo de código muestra cómo leer y ordenar datos del Titanic desde un almacén de datos de Azure Machine Learning, mediante el URI del almacén de datos
azureml://,pyspark.pandasypyspark.ml.feature.Imputer.import pyspark.pandas as pd from pyspark.ml.feature import Imputer df = pd.read_csv( "azureml://datastores/workspaceblobstore/paths/data/titanic.csv", index_col="PassengerId", ) imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy( "mean" ) # Replace missing values in Age column with the mean value df.fillna( value={"Cabin": "None"}, inplace=True ) # Fill Cabin column with value "None" if missing df.dropna(inplace=True) # Drop the rows which still have any missing value df.to_csv( "azureml://datastores/workspaceblobstore/paths/data/wrangled", index_col="PassengerId", )Nota:
En este ejemplo de código de Python se usa
pyspark.pandas. Esto solo se admite en el entorno de ejecución Spark versión 3.2 o posteriores.
Los almacenes de datos de Azure Machine Learning pueden acceder a los datos mediante las credenciales de la cuenta de almacenamiento de Azure
- clave de acceso
- Token de SAS
- entidad de servicio
o usan acceso a datos sin credenciales. Según el tipo de almacén de datos y el tipo de cuenta de almacenamiento de Azure subyacente, seleccione un mecanismo de autenticación adecuado para garantizar el acceso a los datos. En esta tabla se resumen los mecanismos de autenticación para acceder a los datos de los almacenes de datos de Azure Machine Learning:
| Tipo de cuenta de almacenamiento | Acceso a datos sin credenciales | Mecanismo de acceso a datos | Asignaciones de roles |
|---|---|---|---|
| Blob de Azure | No | Clave de acceso o token de SAS | No se necesitan asignaciones de roles |
| Blob de Azure | Sí | Paso a través de la identidad del usuario* | La identidad de usuario debe tener las asignaciones de roles adecuadas en la cuenta de Azure Blob Storage |
| Azure Data Lake Storage (ADLS) Gen 2 | No | Entidad de servicio | La entidad de servicio debe tener las asignaciones de roles adecuadas en la cuenta de almacenamiento de Azure Data Lake Storage (ADLS) Gen 2 |
| Azure Data Lake Storage (ADLS) Gen 2 | Sí | Paso a través de la identidad del usuario | La identidad de usuario debe tener las asignaciones de roles adecuadas en la cuenta de almacenamiento de Azure Data Lake Storage (ADLS) Gen 2 |
* El tránsito de identidad del usuario funciona para almacenes de datos sin credenciales que apuntan a cuentas de Azure Blob Storage, solo si la eliminación temporal no está habilitada.
Acceso a datos en el recurso compartido de archivos predeterminado
El recurso compartido de archivos predeterminado se monta en el proceso de Spark sin servidor y en los grupos de Synapse Spark conectados.
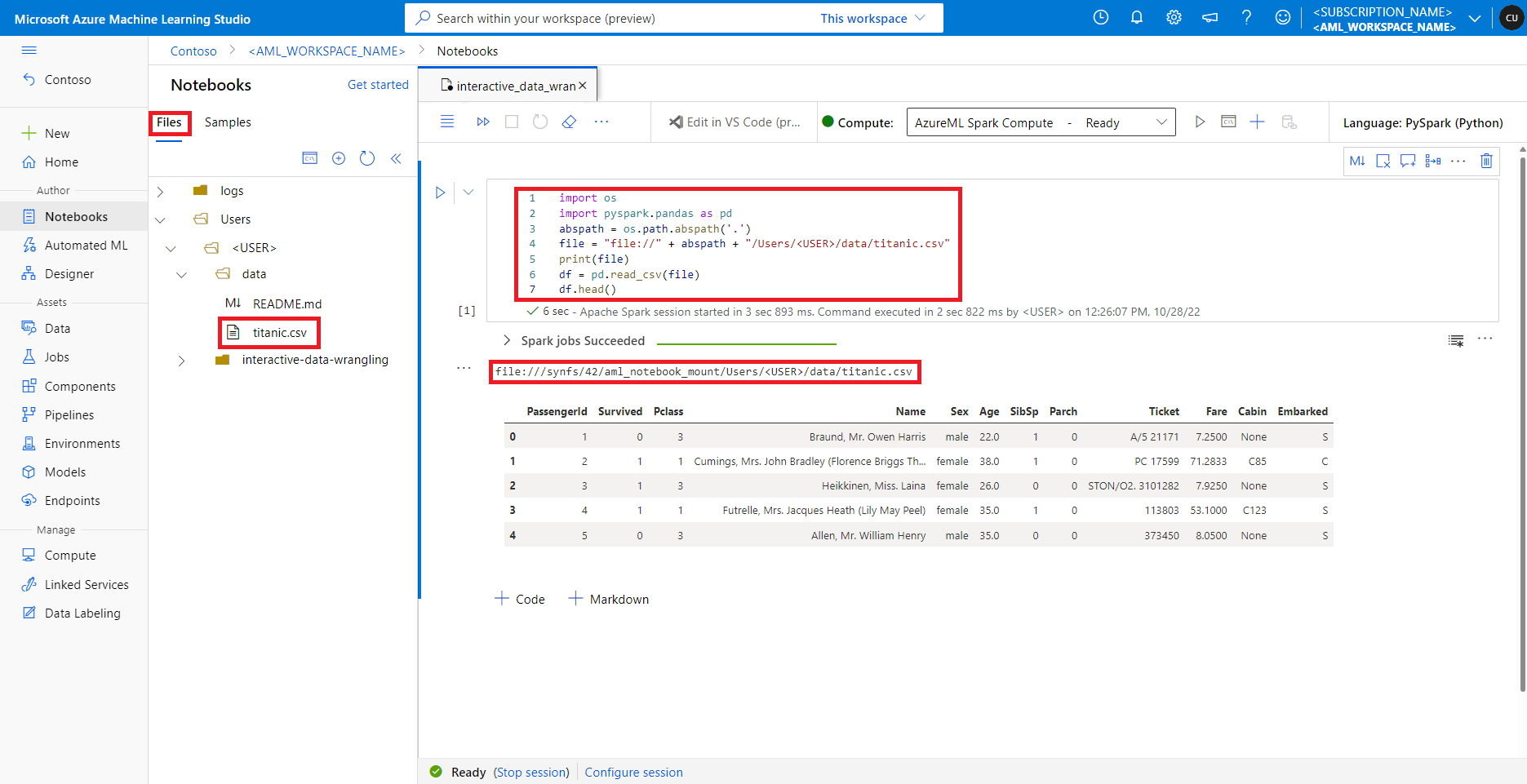
En Estudio de Azure Machine Learning, los archivos del recurso compartido de archivos predeterminado se muestran en el árbol de directorios en la pestaña Archivos. El código de cuaderno puede acceder directamente a los archivos almacenados en este recurso compartido de archivos con el protocolo file://, junto con la ruta de acceso absoluta del archivo, sin más configuraciones. Este fragmento de código muestra cómo acceder a un archivo almacenado en el recurso compartido de archivos predeterminado:
import os
import pyspark.pandas as pd
from pyspark.ml.feature import Imputer
abspath = os.path.abspath(".")
file = "file://" + abspath + "/Users/<USER>/data/titanic.csv"
print(file)
df = pd.read_csv(file, index_col="PassengerId")
imputer = Imputer(
inputCols=["Age"],
outputCol="Age").setStrategy("mean") # Replace missing values in Age column with the mean value
df.fillna(value={"Cabin" : "None"}, inplace=True) # Fill Cabin column with value "None" if missing
df.dropna(inplace=True) # Drop the rows which still have any missing value
output_path = "file://" + abspath + "/Users/<USER>/data/wrangled"
df.to_csv(output_path, index_col="PassengerId")
Nota:
En este ejemplo de código de Python se usa pyspark.pandas. Esto solo se admite en el entorno de ejecución Spark versión 3.2 o posteriores.