Inicio rápido: Limpieza y transformación de datos interactivos con Apache Spark en Azure Machine Learning
Para controlar la limpieza y transformación de datos interactivos de cuadernos de Azure Machine Learning, la integración de Azure Machine Learning con Azure Synapse Analytics, proporciona un acceso sencillo al marco de Apache Spark. Este acceso permite la limpieza y transformación de datos interactivos de cuaderno de Azure Machine Learning.
En esta guía de inicio rápido, aprenderá a realizar la administración interactiva de datos con la informática sin servidor Spark de Azure Machine Learning, la cuenta de almacenamiento Azure Data Lake Storage (ADLS) Gen 2 y el traspaso de identidad de usuario.
Requisitos previos
- Una suscripción a Azure; si no tiene una suscripción a Azure, cree una cuenta gratuita antes de empezar.
- Un área de trabajo de Azure Machine Learning. Visite Creación de recursos del área de trabajo.
- Una cuenta de almacenamiento de Azure Data Lake Storage (ADLS) Gen 2. Visite Creación de una cuenta de almacenamiento de Azure Data Lake Storage (ADLS) Gen 2.
Almacenamiento de las credenciales de la cuenta de almacenamiento de Azure como secretos en Azure Key Vault
Para almacenar las credenciales de la cuenta de almacenamiento de Azure como secretos en Azure Key Vault, con la interfaz de usuario del portal de Azure:
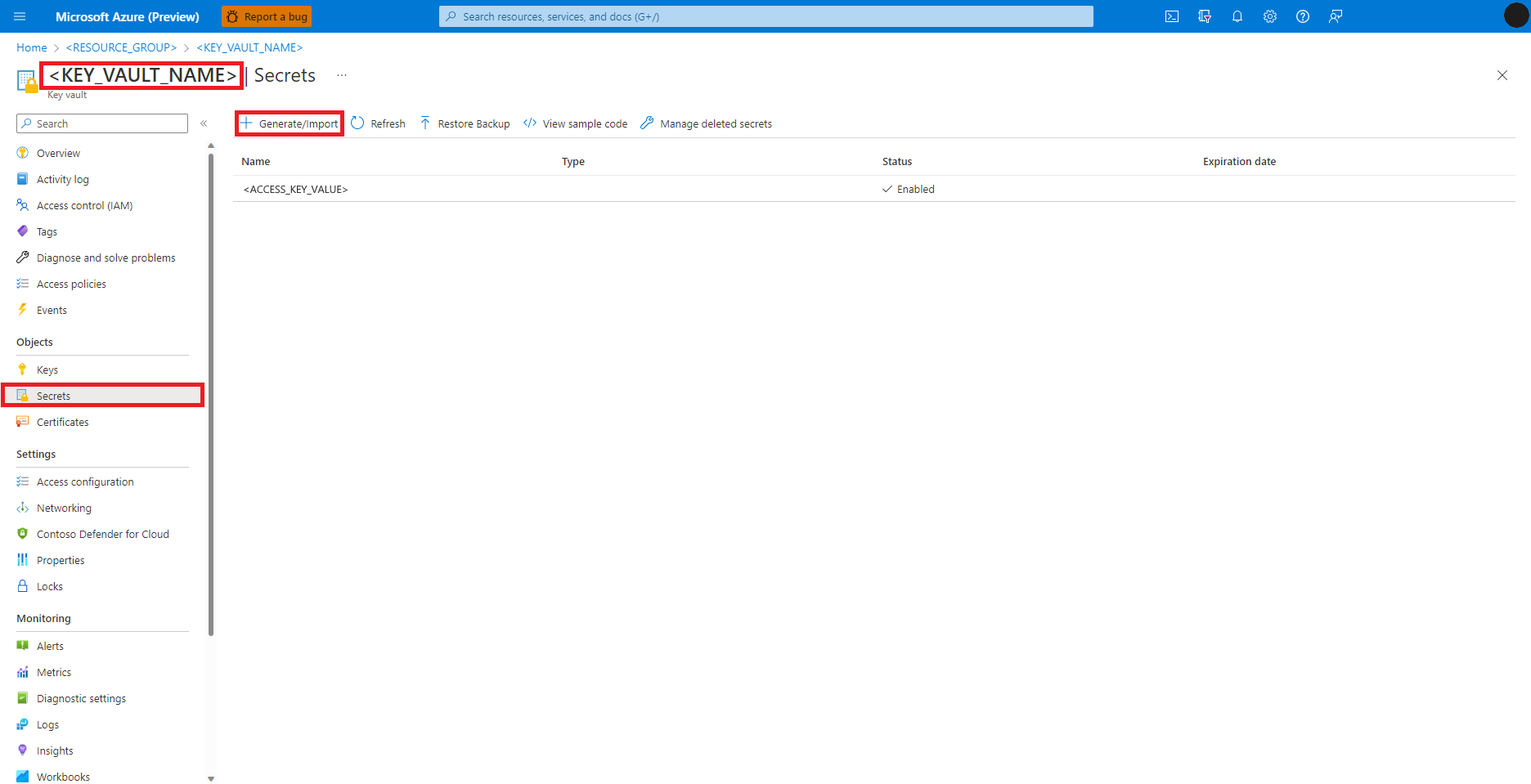
Vaya hasta Azure Key Vault en el portal de Azure
Seleccione Secretos en el panel izquierdo
Seleccione Generar/Importar.
En la pantalla Crear un secreto, introduzca un Nombre para el secreto que desea crear
Vaya hasta el apartado Cuenta de Azure Blob Storage, en el portal de Azure, como se muestra en esta imagen:
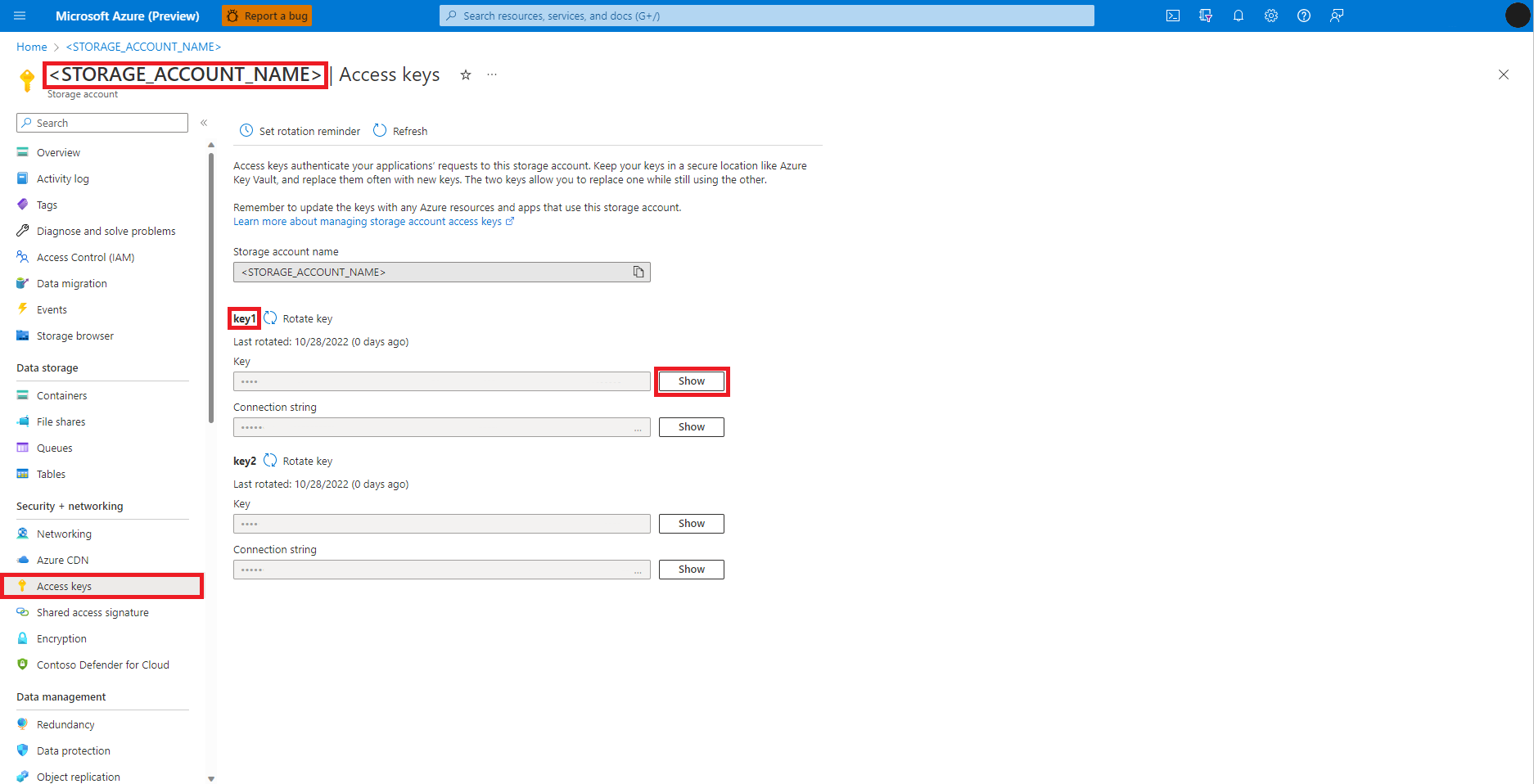
Seleccione Claves de acceso en el panel izquierdo de la página Cuenta de Azure Blob Storage
Seleccione Mostrar junto a Clave 1, y luego, Copiar al portapapeles para obtener la clave de acceso a la cuenta de almacenamiento
Nota:
Seleccione las opciones adecuadas para copiar
- Tokens de firma de acceso compartido (SAS) del contenedor de Azure Blob Storage
- Credenciales de entidad de servicio de la cuenta de almacenamiento de Azure Data Lake Storage (ADLS) Gen 2
- tenant ID
- id. de cliente y
- secret
en las respectivas interfaces de usuario mientras crea los secretos de Azure Key Vault para ellos
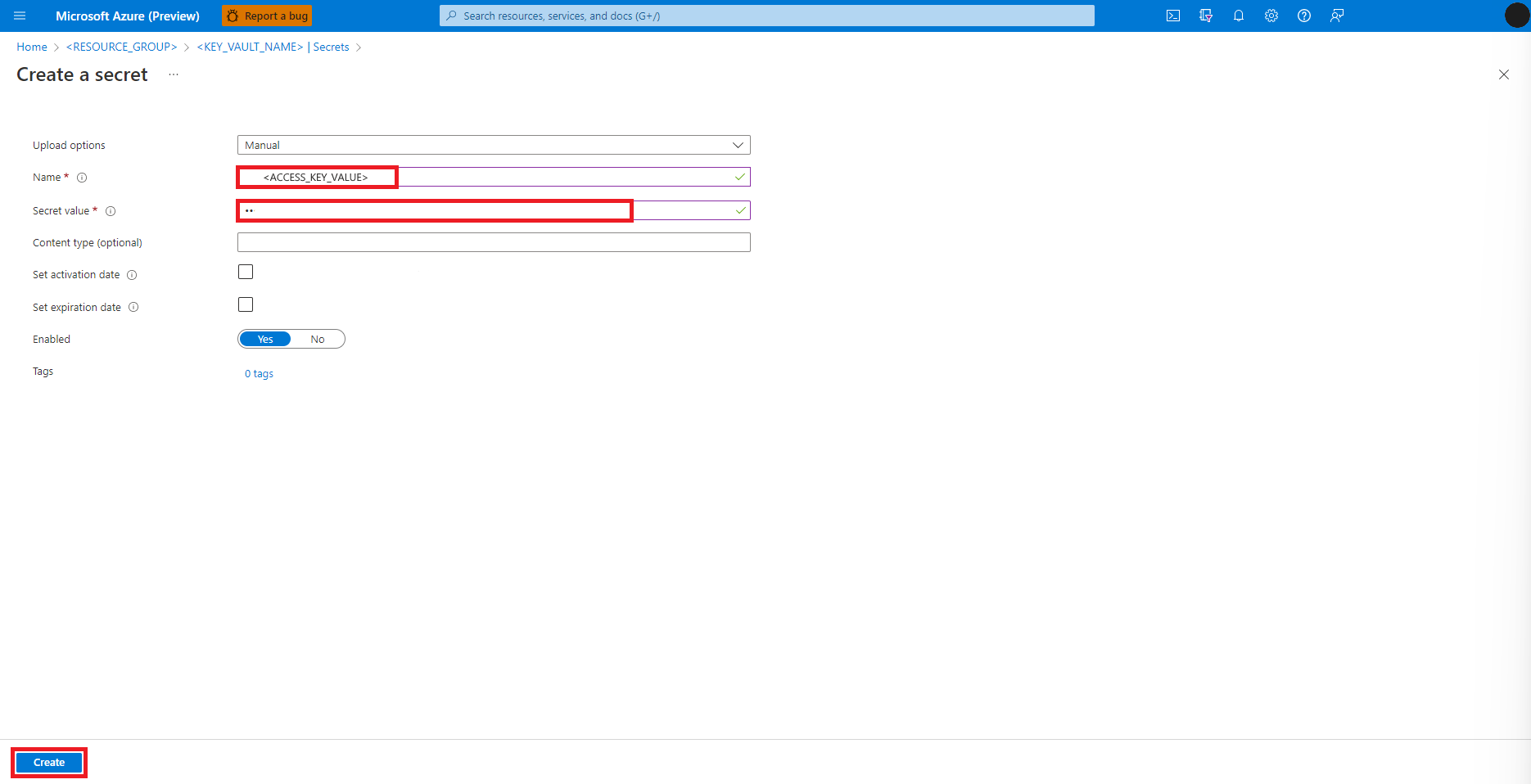
Vuelva hasta la pantalla Crear un secreto
En el cuadro de texto Valor secreto, introduzca la credencial de clave de acceso para la cuenta de almacenamiento Azure, que se copió en el portapapeles en el paso anterior
Seleccione Crear
Sugerencia
La CLI de Azure y la biblioteca cliente de secretos de Azure Key Vault para Python también pueden crear secretos de Azure Key Vault.
Adición de asignaciones de roles en cuentas de almacenamiento de Azure
Debemos asegurarnos de que las rutas de acceso de datos de entrada y salida sean accesibles antes de iniciar la limpieza y transformación de datos interactivos. En primer lugar, para
la identidad del usuario que ha iniciado la sesión de blocs de notas
o
una entidad de servicio
asigne roles Lector y Lector de datos de Storage Blob a la identidad de usuario del usuario que ha iniciado sesión. Sin embargo, en determinados escenarios, es posible que deseemos volver a escribir los datos modificados en la cuenta de almacenamiento de Azure. Los roles Lector y Lector de datos de Storage Blob proporcionan acceso de solo lectura a la identidad de usuario o a la entidad de servicio. Para habilitar el acceso de lectura y escritura, asigne los roles Colaborador y Colaborador de datos de Storage Blob a la identidad de usuario o a la entidad de servicio. Para asignar roles adecuados a la identidad de usuario:
Busque y seleccione el servicio Cuentas de almacenamiento

En la página Cuentas de almacenamiento, seleccione la cuenta de almacenamiento de Azure Data Lake Storage (ADLS) Gen 2 de la lista. Se abre una página con la Información general de la cuenta de almacenamiento
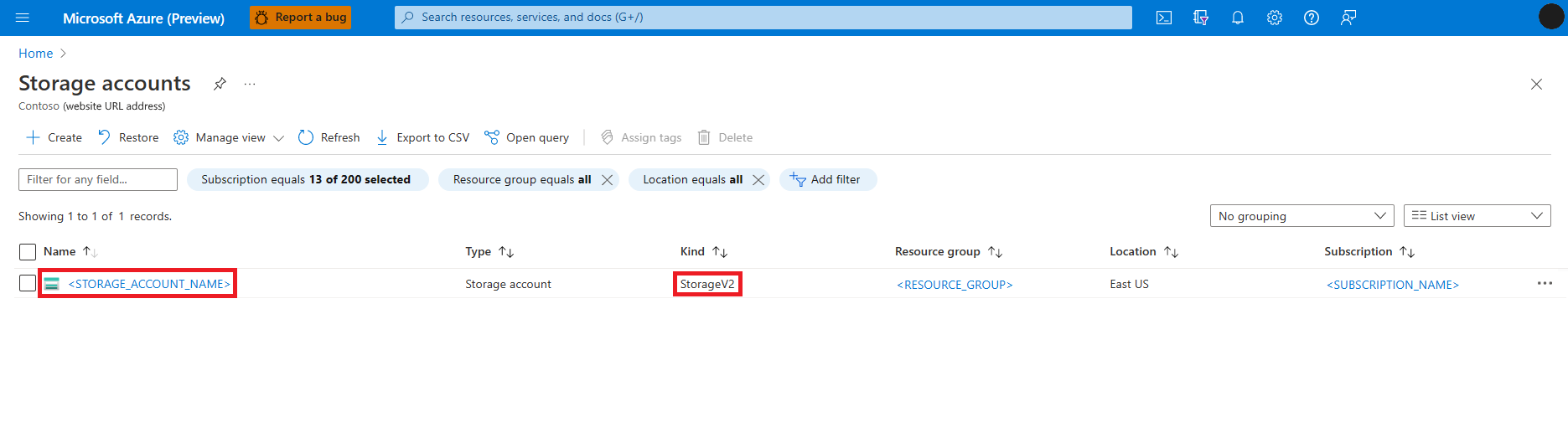
Seleccione Control de acceso (IAM) en el panel izquierdo
Seleccione Agregar asignación de roles.

Busque y seleccione el rol Colaborador de datos de Storage Blob
Seleccione Siguiente.

Seleccione Usuario, grupo o entidad de servicio
Elija + Seleccionar miembros
Busque la identidad de usuario siguiente: Seleccionar
Seleccione la identidad de usuario de la lista para que se muestra en Miembros seleccionados
Seleccione la identidad de usuario adecuada
Seleccione Siguiente.

Seleccione Revisar y asignar

Repita los pasos del 2 al 13 para la asignación de rol de Colaborador






Una vez que la identidad del usuario tiene asignados los roles adecuados, los datos de la cuenta de almacenamiento de Azure deben ser accesibles.
Nota:
Si un grupo Synapse Spark adjunto apunta a un grupo Synapse Spark, en un área de trabajo Azure Synapse, que tiene una red virtual administrada asociada, debe configurar un punto de conexión privado administrado a una cuenta de almacenamiento para garantizar el acceso a los datos.
Garantizar el acceso a los recursos para trabajos de Spark
Para acceder a los datos y a otros recursos, los trabajos de Spark pueden usar una identidad administrada o una identidad de usuario. En la siguiente tabla se resumen los diferentes mecanismos de acceso a los recursos mientras se utiliza el proceso sin servidor Spark de Azure Machine Learning y el grupo Spark de Synapse adjunto.
| Grupo de Spark | Identidades admitidas | Identidad predeterminada |
|---|---|---|
| Proceso de Spark sin servidor | Identidad de usuario, identidad administrada asignada por el usuario asociada al área de trabajo | Identidad del usuario |
| Grupo de Spark de Synapse asociado | Identidad de usuario, identidad administrada asignada por el usuario asociada al grupo de Spark de Synapse conectado, identidad administrada asignada por el sistema del grupo de Spark de Synapse asociado | Identidad administrada asignada por el sistema del grupo de Spark de Synapse asociado |
Si la CLI o el código del SDK define una opción para utilizar la identidad administrada, el proceso de Spark administrado sin servidor de Azure Machine Learning se basa en una identidad administrada asignada por el usuario asociada al área de trabajo. Puede adjuntar una identidad administrada asignada por el usuario a un área de trabajo de Azure Machine Learning existente con Azure Machine Learning CLI v2 o con ARMClient.
Pasos siguientes
- Apache Spark en Azure Machine Learning
- Asociación y administración de un grupo de Spark de Synapse en Azure Machine Learning
- Limpieza y transformación de datos interactivos con Apache Spark en Azure Machine Learning
- Envío de trabajos de Spark en Azure Machine Learning
- Ejemplos de código para trabajos de Spark mediante la CLI de Azure Machine Learning
- Ejemplos de código para trabajos de Spark mediante el SDK de Python de Azure Machine Learning