Uso del panel de IA responsable en el Estudio de Azure Machine Learning
Los paneles de inteligencia artificial responsables están vinculados a los modelos registrados. Para ver el panel de inteligencia artificial responsable, vaya al registro del modelo y seleccione el modelo registrado para el que ha generado un panel de inteligencia artificial responsable. A continuación, elija la pestaña IA responsable para ver una lista de paneles generados.

Puede configurar varios paneles y adjuntarlos al modelo registrado. Se pueden adjuntar diferentes combinaciones de componentes (interoperabilidad, análisis de errores, análisis causal, etc.) a cada panel de IA responsable. En la imagen siguiente se muestra la personalización de un panel y los componentes que se generaron en él. En cada panel, puede ver u ocultar varios componentes dentro de la propia interfaz de usuario del panel.

Al seleccionar el nombre del panel, se abrirá en una vista completa del explorador. Para volver a la lista de paneles, puede seleccionar Volver a los detalles de los modelos en cualquier momento.

Funcionalidad completa con recursos de proceso integrados
Algunas características del panel de IA responsable necesitan cálculos dinámicos, en el momento y en tiempo real (por ejemplo, análisis de hipótesis). Si no conecta un recurso de proceso al panel, es posible que falte alguna funcionalidad. Al conectar un recurso de proceso se habilitará la funcionalidad completa del panel de inteligencia artificial responsable para los siguientes componentes:
- Análisis de errores
- Si establece la cohorte de datos global en cualquier cohorte de interés, se actualizará el árbol de errores en lugar de deshabilitarlo.
- Se admite la selección de otras métricas de error o rendimiento.
- Se admite la selección de cualquier subconjunto de características para entrenar el mapa del árbol de errores.
- Se admite el cambio del número mínimo de muestras necesarias por nodo hoja y profundidad de árbol de errores.
- Se admite la actualización dinámica del mapa térmico para un máximo de dos características.
- Importancia de característica
- Se admite un trazado de expectativa condicional (ICE) individual en la pestaña de importancia de características individuales.
- Elemento contrafactual hipotético
- Se admite la generación de un nuevo punto de datos contrafactual hipotético para comprender el cambio mínimo necesario para un resultado deseado.
- Análisis causal
- Se admite la selección de cualquier punto de datos individual; esta opción conlleva la perturbación de sus características de tratamiento y podrá ver el resultado causal esperado de la hipótesis causal admitida (solo para escenarios de regresión de Machine Learning).
También puede encontrar esta información en la página Panel de inteligencia artificial responsable seleccionando el icono Información, como se muestra en la imagen siguiente:

Habilitación de la funcionalidad completa del panel de inteligencia artificial responsable
Seleccione una instancia de proceso en ejecución en la lista desplegable Proceso en la parte superior del panel. Si no tiene un proceso en ejecución, cree una nueva instancia de proceso seleccionando el signo más (+) junto a la lista desplegable. También puede seleccionar el botón Iniciar proceso para iniciar una instancia de proceso detenida. La creación o el inicio de una instancia de proceso puede tardar unos minutos.

Una vez que el proceso esté en estado En ejecución, el panel de inteligencia artificial responsable comenzará a conectarse a la instancia de proceso. Para ello, se creará un proceso de terminal en la instancia de proceso seleccionada y se iniciará el punto de conexión de IA responsable en el terminal. Seleccione Ver salidas del terminal para ver el proceso del terminal actual.

Cuando el panel de IA responsable esté conectado a la instancia de proceso, verá una barra de mensajes verde que indica que el panel es totalmente funcional.

Si el proceso tarda un tiempo y el panel de IA responsable todavía no está conectado a la instancia de proceso o aparece una barra de mensajes de error roja, significa que hay problemas al iniciar el punto de conexión de IA responsable. Seleccione Ver salidas del terminal y desplácese hacia abajo hasta la parte inferior para ver el mensaje de error.

Si tiene dificultades para averiguar cómo resolver el problema "no se pudo conectar a la instancia de proceso", seleccione el icono Sonrisa en la esquina superior derecha. Envíenos sus comentarios sobre cualquier error o problema que encuentre. Puede incluir captura de pantalla y su dirección de correo electrónico en el formulario de comentarios.




Introducción a la interfaz de usuario del panel de IA responsable
El panel de IA responsable incluye un conjunto sólido y completo de visualizaciones y funcionalidades que le ayudarán a analizar el modelo de Machine Learning o a tomar decisiones empresariales controladas por datos:
- Controles globales
- Análisis de errores
- Información general del modelo y métricas de equidad
- Análisis de datos
- Importancia de las características (explicaciones del modelo)
- Elemento contrafactual hipotético
- Análisis causal
Controles globales
En la parte superior del panel, puede crear cohortes (subgrupos de puntos de datos que comparten las características especificadas) para centrar el análisis de cada componente. El nombre de la cohorte aplicada actualmente al panel siempre se muestra en la parte superior izquierda de este. La vista predeterminada del panel es todo el conjunto de datos, titulado Todos los datos (valor predeterminado).

- Configuración de cohortes: permite ver y modificar los detalles de cada cohorte en un panel lateral.
- Configuración del panel: permite ver y modificar el diseño del panel general en un panel lateral.
- Cambiar cohorte: permite seleccionar una cohorte diferente y ver sus estadísticas en una ventana emergente.
- Nueva cohorte: permite crear y agregar una nueva cohorte al panel.
Seleccione Configuración de cohortes para abrir un panel con una lista de las cohortes, donde puede crearlas, editarlas, duplicarlas o eliminarlas.

Al seleccionar Nueva cohorte en la parte superior del panel o en la configuración de cohortes, se abre un nuevo panel con opciones para filtrar en función de las siguientes opciones:
- Índice: filtra por la posición del punto de datos en el conjunto de datos completo.
- Conjunto de datos: filtra por el valor de una característica determinada del conjunto de datos.
- Y predicho: filtra por la predicción que ha realizado el modelo.
- Valor Y real: filtra por el valor real de la característica de destino.
- Error (regresión): filtra por error o resultado de clasificación (clasificación); hay filtros por tipo y precisión de la clasificación.
- Valores de categorías: filtra por una lista de valores que se deben incluir.
- Valores numéricos: filtra por una operación booleana sobre los valores (por ejemplo, seleccione los puntos de datos en los que la edad < 64).

Puede asignar un nombre a la nueva cohorte de conjunto de datos, seleccione Agregar filtro para agregar cada filtro que quiera usar y, a continuación, realizar una de las acciones siguientes:
- Seleccione Guardar para guardar la nueva cohorte en la lista de cohortes.
- Seleccione Guardar y cambiar para guardar y cambiar inmediatamente la cohorte global del panel a la cohorte recién creada.

Seleccione Configuración del panel para abrir un panel con una lista de los componentes que ha configurado en este. Puede ocultar componentes en el panel seleccionando el icono Papelera, como se muestra en la imagen siguiente:

Puede volver a agregar componentes al panel con el icono de signo más azul circular (+) en el divisor entre cada componente, como se muestra en la siguiente imagen:

Análisis de errores
En las secciones siguientes se explica cómo interpretar y usar mapas de árbol de errores y mapas térmicos.
Mapa del árbol de errores
El primer panel del componente Análisis de errores es un mapa de árboles, que muestra cómo se distribuye el error del modelo entre varias cohortes con una visualización del árbol. Seleccione cualquier nodo para ver la ruta de predicción en las características en las que se encontró un error.

- Vista de mapa térmico: cambia a la visualización del mapa térmico de la distribución de errores.
- Lista de características: permite modificar las características que se usan en el mapa térmico mediante un panel lateral.
- Cobertura de errores: muestra el porcentaje de todos los errores del conjunto de datos concentrados en el nodo seleccionado.
- Error (regresión) o Tasa de errores (clasificación): muestra el error o el porcentaje de errores de todos los puntos de datos del nodo seleccionado.
- Nodo: representa una cohorte del conjunto de datos (potencialmente con filtros aplicados) y el número de errores fuera del número total de puntos de datos de la cohorte.
- Línea de relleno: visualiza la distribución de los puntos de datos en cohortes secundarias basadas en filtros, con el número de puntos de datos representados a través del grosor de línea.
- Información de la selección: contiene información sobre el nodo seleccionado en un panel lateral.
- Guardar como una nueva cohorte: crea una nueva cohorte con los filtros especificados.
- Instancias de la cohorte base: muestra el número total de puntos del conjunto de datos completo y el número de puntos predichos correcta e incorrectamente.
- Instancias de la cohorte seleccionada: muestra el número total de puntos del nodo seleccionado y el número de puntos predichos correcta e incorrectamente.
- Ruta de predicción (filtros): enumera los filtros colocados sobre el conjunto de datos completo para crear una cohorte más pequeña.
Seleccione el botón Lista de características para abrir un panel lateral, desde el que puede volver a entrenar el árbol de errores según características específicas.

- Características de búsqueda: permite buscar características específicas en el conjunto de datos.
- Características: muestra el nombre de la característica en el conjunto de datos.
- Importancia: esta es una guía sobre cómo puede estar relacionada la característica con el error. Se calcula a través de la puntuación de información mutua entre la característica y el error en las etiquetas. Puede usar esta puntuación para decidir qué características elegir en el análisis de errores.
- Marca de verificación: permite agregar o quitar la característica del mapa del árbol.
- Profundidad máxima: profundidad máxima del árbol suplente entrenado según los errores.
- Número de hojas: número de hojas del árbol suplente entrenado según los errores.
- Número mínimo de muestras en una hoja: cantidad mínima de datos necesarios para crear una hoja.
Mapa térmico de errores
Al seleccionar la pestaña Mapa térmico, se cambia a otra vista del error en el conjunto de datos. Puede seleccionar una o varias celdas del mapa térmico y crear nuevas cohortes. Puede elegir hasta dos características para crear un mapa térmico.

- Celdas: muestra el número de celdas seleccionadas.
- Cobertura de errores: muestra el porcentaje de todos los errores concentrados en las celdas seleccionadas.
- Tasa de errores: muestra el porcentaje de errores de todos los puntos de datos en las celdas seleccionadas.
- Características del eje: selecciona la intersección de las características que se van a mostrar en el mapa térmico.
- Celdas: representa una cohorte del conjunto de datos (con filtros aplicados) y el porcentaje de errores fuera del número total de puntos de datos de la cohorte. Un contorno azul indica las celdas seleccionadas y el rojo oscuro representa la concentración de errores.
- Ruta de predicción (filtros): enumera los filtros colocados sobre el conjunto de datos completo para cada cohorte seleccionada.
Información general del modelo y métricas de equidad
El componente de información general del modelo proporciona un conjunto completo de métricas de rendimiento y equidad para evaluar el modelo, junto con métricas clave de disparidad de rendimiento con características y cohortes de conjuntos de datos especificadas.
Cohortes de conjunto de datos
En el panel Cohortes del conjunto de datos puede investigar el modelo mediante la comparación del rendimiento del modelo de varias cohortes de conjuntos de datos que especifica el usuario (accesible a través del icono Configuración de cohortes de la esquina superior derecha del panel).

- Ayuda para elegir métricas: al seleccionar este icono se abrirá un panel con más información sobre las métricas de rendimiento del modelo que están disponibles para que se muestren en la tabla. Ajuste con facilidad las métricas que puede ver mediante la lista desplegable de selección múltiple para seleccionar y anular la selección de métricas de rendimiento.
- Mostrar mapa térmico: activar y desactivar para mostrar u ocultar la visualización del mapa térmico en la tabla. El degradado del mapa térmico corresponde al intervalo normalizado entre el valor más bajo y el valor más alto de cada columna.
- Tabla de métricas para cada cohorte de conjunto de datos: vista de columnas para cohortes de conjuntos de datos, tamaño de muestra de cada cohorte y métricas de rendimiento del modelo seleccionadas para cada cohorte.
- Gráfico de barras en el que se visualiza la métrica individual: vista de error absoluto medio entre las cohortes para facilitar la comparación.
- Elección de métrica (eje x): seleccione este botón para elegir qué métricas ver en el gráfico de barras.
- Elección de cohortes (eje y): seleccione este botón para elegir qué cohortes ver en el gráfico de barras. La selección de Cohorte de características puede que esté deshabilitada a menos que especifique primero las características que quiere en la pestaña Cohorte de características del componente.
Seleccione Ayuda para elegir métricas para abrir un panel con una lista de métricas de rendimiento del modelo y sus definiciones, lo que puede ayudarle a seleccionar las métricas adecuadas que se van a ver.
| Escenario de aprendizaje automático | Métricas |
|---|---|
| Regresión | Error absoluto medio, Error cuadrático medio, R cuadrado, Predicción media. |
| clasificación | Precisión, Recuperación, Puntuación F1, Tasa de falsos positivos, Tasa de falsos negativos, Tasa de selección. |
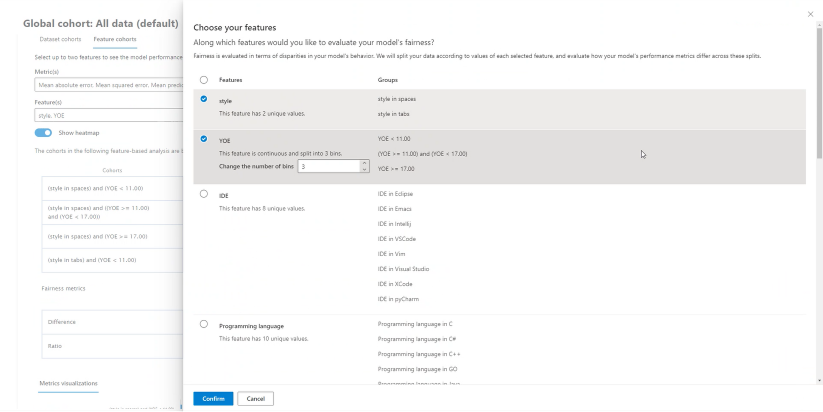
Cohortes de características
En el panel Cohortes de características puede investigar el modelo mediante la comparación del rendimiento del modelo entre las características confidenciales y no confidenciales que especifica el usuario (por ejemplo, rendimiento en varias cohortes de género, raza y nivel de ingresos).

Ayuda para elegir métricas: al seleccionar este icono se abrirá un panel con más información sobre las métricas que están disponibles para mostrarse en la tabla. Ajuste con facilidad las métricas que puede ver mediante la lista desplegable de selección múltiple para seleccionar y anular la selección de métricas de rendimiento.
Ayuda para elegir características: al seleccionar este icono se abrirá un panel con más información sobre las características que están disponibles para mostrarse en la tabla con descriptores de cada característica y funcionalidad de discretización (consulte más a continuación). Ajuste con facilidad las características que quiere ver mediante el menú desplegable de selección múltiple para seleccionar y anular la selección de características.
Mostrar mapa térmico: activar y desactivar para ver una visualización de mapa térmico. El degradado del mapa térmico corresponde al intervalo normalizado entre el valor más bajo y el valor más alto de cada columna.
Tabla de métricas para cada cohorte de características: una tabla con columnas para cohortes de características (subcohorte de la característica seleccionada), tamaño de muestra de cada cohorte y métricas de rendimiento del modelo seleccionado para cada cohorte de características.
Métricas de equidad o métricas de disparidad: una tabla que corresponde a la tabla de métricas y muestra la diferencia máxima o la relación máxima en las puntuaciones de rendimiento entre dos cohortes de características.
Gráfico de barras en el que se visualiza la métrica individual: vista de error absoluto medio entre las cohortes para facilitar la comparación.
Elección de cohortes (eje y): seleccione este botón para elegir qué cohortes ver en el gráfico de barras.
Al seleccionar Elegir cohortes, se abrirá un panel con una opción para mostrar una comparación de cohortes de conjuntos de datos seleccionadas o cohortes de características en función de lo que está seleccionado en la lista desplegable de selección múltiple debajo de este. Seleccione Confirmar para guardar los cambios en la vista del gráfico de barras.
Elección de métrica (eje x): seleccione este botón para elegir qué métrica ver en el gráfico de barras.


Análisis de datos
Con el componente de análisis de datos, el panel Vista de tabla muestra una vista de tabla del conjunto de datos para todas las características y filas.
En el panel Vista de diagrama se muestran gráficos agregados e individuales de puntos de datos. Puede analizar las estadísticas de datos a lo largo del eje X y del eje Y mediante filtros como el resultado previsto, las características del conjunto de datos y los grupos de errores. Esta vista le permite comprender la representación excesiva e infrarrepresentación en el conjunto de datos.

Seleccione una cohorte de conjunto de datos para explorar: especifique la cohorte del conjunto de datos de la lista de cohortes para las que quiere ver las estadísticas de datos.
Eje X: muestra el tipo de valor que se traza horizontalmente. Modifique los valores seleccionando el botón para abrir un panel lateral.
Eje Y: muestra el tipo de valor que se va a trazar verticalmente. Modifique los valores seleccionando el botón para abrir un panel lateral.
Tipo de gráfico: especifica el tipo de gráfico. Elija entre trazados agregados (gráficos de barras) o puntos de datos individuales (gráfico de dispersión).
Al seleccionar la opción Puntos de datos individuales en Tipo de gráfico, se puede desplazar a una vista desagregada de los datos con la disponibilidad de un eje de colores.

Importancia de las características (explicaciones del modelo)
El componente de explicación del modelo permite ver qué características son más importantes en las predicciones del modelo. Para ver qué características afectaron a la predicción del modelo en general, vaya al panel Importancia de la característica agregada o consulte las importancias de las características para puntos de datos individuales en el panel Importancia de las características individuales.
Importancia de las características agregadas (explicaciones globales)

Características principales k: aquí se enumeran las características globales más importantes de una predicción y permite cambiarlas mediante una barra deslizante.
Importancia de las características agregadas: visualiza el peso de cada característica en la influencia de las decisiones del modelo en todas las predicciones.
Ordenar por: permite seleccionar las importancias de la cohorte para ordenar el gráfico de importancia de las características agregadas.
Tipo de gráfico: permite seleccionar entre una vista de trazado de barras de importancia media para cada característica y un gráfico de cuadros de importancia para todos los datos.
Al seleccionar una de las características del gráfico de barras, se rellena el trazado de dependencia, como se muestra en la imagen siguiente. El trazado de dependencia muestra la relación de los valores de una característica con los valores de importancia de característica correspondientes que afectan a la predicción del modelo.
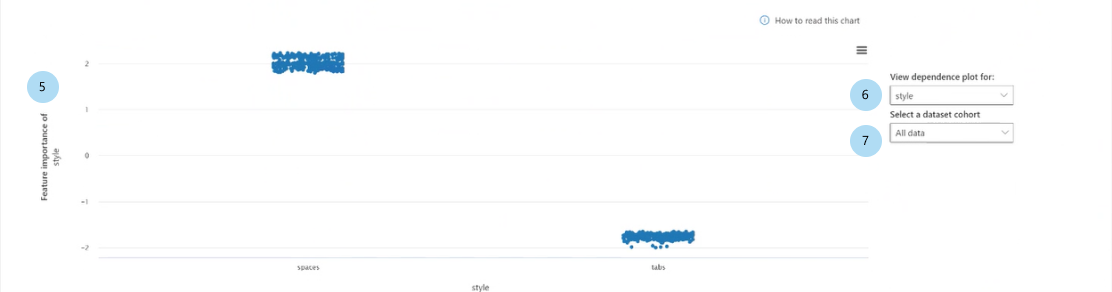
Importancia de la característica [característica] (regresión) o importancia de la característica [característica] en la [clase predicha] (clasificación): traza la importancia de una característica determinada en las predicciones. En los escenarios de regresión, los valores de importancia se establecen según los términos de la salida, por lo que la importancia positiva de la característica significa que contribuyó positivamente a la salida. Lo contrario se aplica a la importancia negativa de las características. En los escenarios de clasificación, las importancias positivas de las características significan que el valor de la característica contribuye a la clase predicha indicada en el título del eje Y. La importancia negativa de las características significa que contribuye en contra de la clase predicha.
Ver el trazado de dependencia para: selecciona la característica cuyas importancias quiera trazar.
Seleccionar una cohorte de conjunto de datos: selecciona la cohorte cuyas importancias quiera trazar.

Importancias de las características individuales (explicaciones locales)
En la imagen siguiente se muestra cómo influyen las características en las predicciones realizadas en puntos de datos específicos. Puede elegir hasta cinco puntos de datos para comparar las importancias de las características.

Tabla de selección de puntos: consulte los puntos de datos y seleccione hasta cinco puntos para mostrar en el gráfico de importancia de la característica o en el trazado ICE debajo de la tabla.

Trazado de importancia de características: un trazado de barras de la importancia de cada característica para la predicción del modelo en los puntos de datos seleccionados.
- Características K principales: permite especificar el número de características para mostrar las importancias mediante un control deslizante.
- Ordenar por: permite seleccionar el punto (de los seleccionados anteriormente) cuyas importancias de la característica se muestran en orden descendente en el trazado de importancia de la característica.
- Ver valores absolutos: permite alternar valores para ordenar el trazado de la barra por los valores absolutos. Esto le permite ver las características de mayor impacto, independientemente de su dirección positiva o negativa.
- Trazado de barras: muestra la importancia de cada característica del conjunto de datos para realizar la predicción del modelo de los puntos de datos seleccionados.
Trazado de expectativas condicionales individuales (ICE): cambia al trazado ICE que muestra predicciones del modelo en un intervalo de valores de una característica determinada.

- Mínimo (características numéricas): especifica el límite inferior del intervalo de predicciones en el trazado ICE.
- Máximo (características numéricas): especifica el límite superior del intervalo de predicciones en el trazado ICE.
- Pasos (características numéricas): especifica el número de puntos para mostrar predicciones dentro del intervalo.
- Valores de características (características categóricas): especifica los valores de características de categorías para los que se van a mostrar las predicciones.
- Característica: especifica la característica para la que se van a realizar predicciones.
Elemento contrafactual hipotético
El análisis contrafactual proporciona un conjunto diverso de ejemplos de hipótesis que se han generado cambiando mínimamente los valores de las características para generar la clase de predicción (clasificación) o el intervalo deseado (regresión).

Selección de puntos: selecciona el punto para crear un elemento contrafactual y mostrarlo a continuación en el trazado de características de clasificación superior.
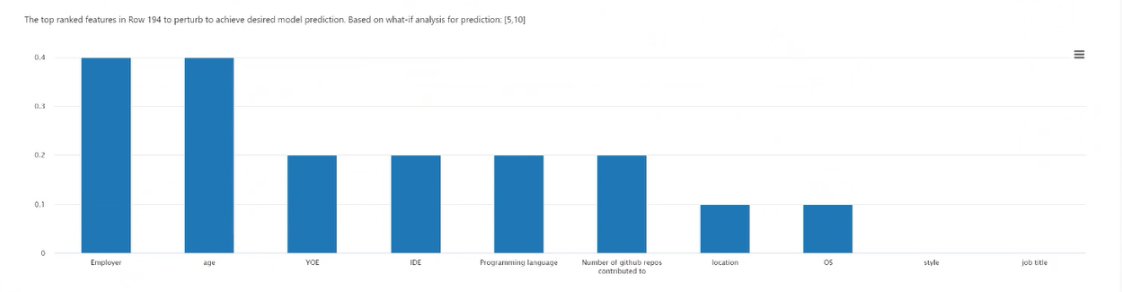
Trazado de características de clasificación superior: muestra, en orden descendente en términos de frecuencia media, las características que se van a modificar para crear un conjunto diverso de elementos contrafactuales de la clase deseada. Debe generar al menos 10 elementos contrafactuales diferentes por punto de datos para habilitar este gráfico, debido a la falta de precisión al tener un número menor de elementos contrafactuales.
Punto de datos seleccionado: realiza la misma acción que la selección de puntos de la tabla, excepto en un menú desplegable.
Clase deseada para los elementos contrafactuales: especifica la clase o el intervalo según los cuales se van a generar elementos contrafactuales.
Crear elemento contrafactual hipotético: abre un panel para la creación de puntos de datos hipotéticos de elementos contrafactuales.
Al seleccionar el botón Crear elementos contrafactuales hipotéticos se abre un panel de ventana completa.
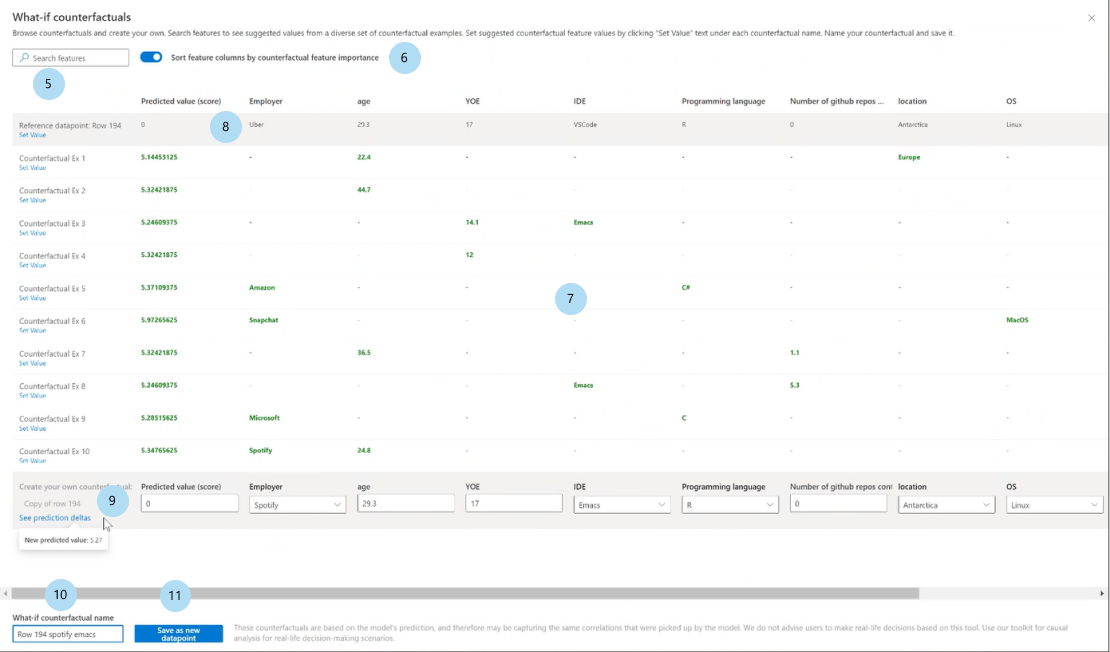
Características de búsqueda: busca características para observar y cambiar valores.
Ordenar elementos contrafactuales por características clasificadas: ordena ejemplos contrafactuales en orden de efecto de perturbación. (Consulte también el Trazado de características de clasificación superior descrito anteriormente).
Ejemplos contrafactuales: enumera los valores de características de los elementos contrafactuales de ejemplo con la clase o el rango deseados. La primera fila es el punto de datos de referencia original. Seleccione Establecer valor para establecer todos los valores de su propio punto de datos contrafactual en la fila inferior con los valores del ejemplo contrafactual que se ha generado previamente.
El valor o la clase predichos enumeran la predicción del modelo de una clase contrafactual, dadas las características modificadas.
Crear su propio elemento contrafactual: le permite modificar sus propias características para cambiar el elemento contrafactual. Las características que se han cambiado del valor de característica original se indicarán con el título en negrita (por ejemplo, Empleador y Lenguaje de programación). Al seleccionar Ver delta de predicción, se mostrará la diferencia en el nuevo valor de predicción del punto de datos original.
Nombre del elemento contrafactual hipotético: le permite asignar un nombre al elemento contrafactual de forma única.
Guardar como nuevo punto de datos: guarda el elemento contrafactual que ha creado.


Análisis causal
En las secciones siguientes se explica cómo leer el análisis causal del conjunto de datos en tratamientos seleccionados especificados por el usuario.
Efectos causales agregados
Al seleccionar la pestaña Efectos causales agregados del componente Análisis causal, se mostrarán los efectos causales promedio de las características de tratamiento predefinidas (las características que quiere administrar para optimizar el resultado).
Nota:
La funcionalidad global de cohortes no se admite en el componente de análisis causal.

Tabla de efectos causales de un elemento agregado directo: muestra el efecto causal de cada característica agregada en todo el conjunto de datos y las estadísticas de confianza asociadas.
- Tratamientos continuos: según el promedio de esta muestra, aumentar esta característica en una unidad hará que la probabilidad de la clase aumente en X unidades, donde X es el efecto causal.
- Tratamientos binarios: según el promedio de esta muestra, activar esta característica hará que la probabilidad de la clase aumente en X unidades, donde X es el efecto causal.
Trazado de valores de efecto causal de agregado directo: visualiza los efectos causales y los intervalos de confianza de los puntos de la tabla.
Efectos causales individuales e hipótesis causales
Para obtener una vista granular de los efectos causales en un punto de datos individual, cambie a la pestaña Hipótesis causal individual.

- Eje X: selecciona la característica que se va a trazar en el eje X.
- Eje Y: selecciona la característica que se va a trazar en el eje Y.
- Trazado de dispersión causal individual: visualiza los puntos de la tabla como trazado de dispersión para seleccionar el punto de datos que se va a analizar causalmente y así poder ver los efectos causales individuales siguientes.
- Establecimiento de un nuevo valor de tratamiento:
- (numérico): muestra un control deslizante para cambiar el valor de la característica numérica como una intervención real.
- (categórico): muestra una lista desplegable para seleccionar el valor de la característica de categorías.
Directiva de tratamiento
La selección de la pestaña Directiva de tratamiento cambia a una vista para ayudar a determinar las intervenciones del mundo real y muestra los tratamientos que se aplicarán para lograr un resultado determinado.

Establecer características de tratamiento: selecciona la característica para cambiarla como una intervención real.
Directiva de tratamiento global recomendada: muestra las intervenciones recomendadas para las cohortes de datos y así mejorar el valor de la característica objetivo. La tabla se puede leer de izquierda a derecha, donde la segmentación del conjunto de datos se encuentra primero en filas y, a continuación, en columnas. Por ejemplo, en el caso de 658 personas cuyo empleador no es Snapchat y su lenguaje de programación no es JavaScript, la directiva de tratamiento recomendada es aumentar el número de repositorios de GitHub en los que han contribuido.
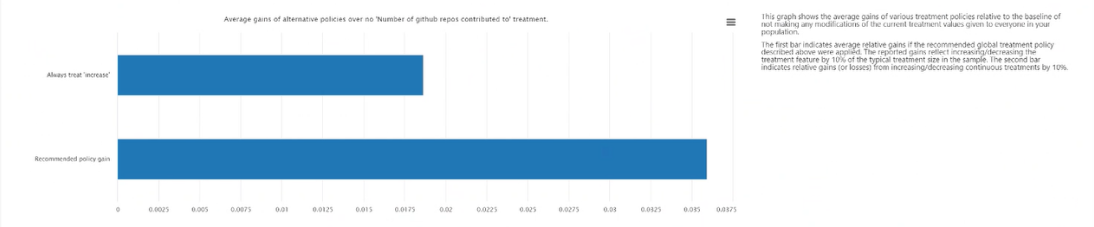
Promedio de ganancias de directivas alternativas sobre la aplicación continua del tratamiento: traza el valor de la característica objetivo en un gráfico de barras del promedio de ganancia en el resultado de la directiva de tratamiento recomendada anterior frente a la opción de aplicar siempre el tratamiento.
Directiva de tratamiento individual recomendada:
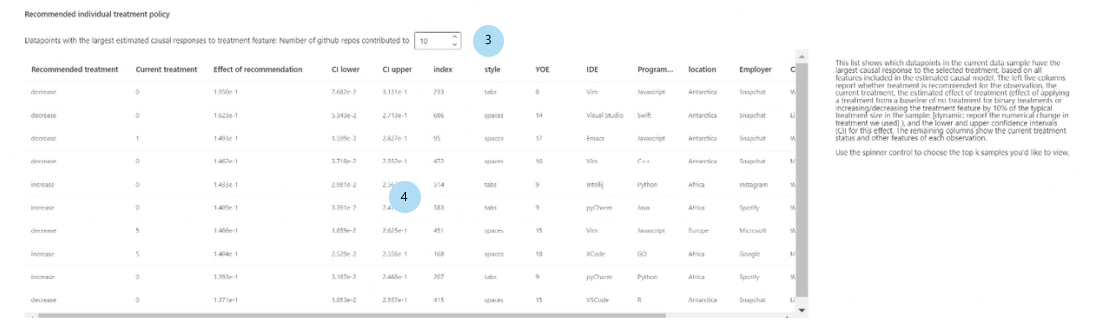
Mostrar las mejores muestras de puntos de datos K ordenados según los efectos causales para la característica de tratamiento recomendada: selecciona el número de puntos de datos que se muestran en la tabla siguiente.
Tabla de directivas de tratamiento individual recomendada: enumera, en orden descendente del efecto causal, los puntos de datos cuyas características objetivo mejorarían más mediante una intervención.


Pasos siguientes
- Resuma y comparta sus conclusiones de inteligencia artificial responsable con el cuadro de mandos de IA responsable en forma de exportación a PDF.
- Obtenga más información sobre los conceptos y técnicas detrás del panel de inteligencia artificial responsable.
- Vea cuadernos de YAML y Python de muestra para generar un panel de IA responsable con YAML o Python.
- Explore las características del panel de inteligencia artificial responsable mediante esta demostración web interactiva de AI Lab.
- Obtenga más información sobre cómo se puede usar el panel de IA responsable y el cuadro de mandos para depurar datos y modelos, e informar sobre la mejor toma de decisiones en esta entrada de blog de la comunidad tecnológica.
- Obtenga información sobre cómo el Servicio Nacional de Salud del Reino Unido (NHS) ha utilizado el panel de inteligencia artificial responsable y el cuadro de mandos en una historia de cliente real.