Evaluación de sistemas de inteligencia artificial mediante el panel de IA responsable
La implementación práctica de IA responsable requiere una ingeniería rigurosa. Sin embargo, la ingeniería rigurosa puede ser tediosa, manual y lenta si no se cuenta con las herramientas y la infraestructura adecuadas.
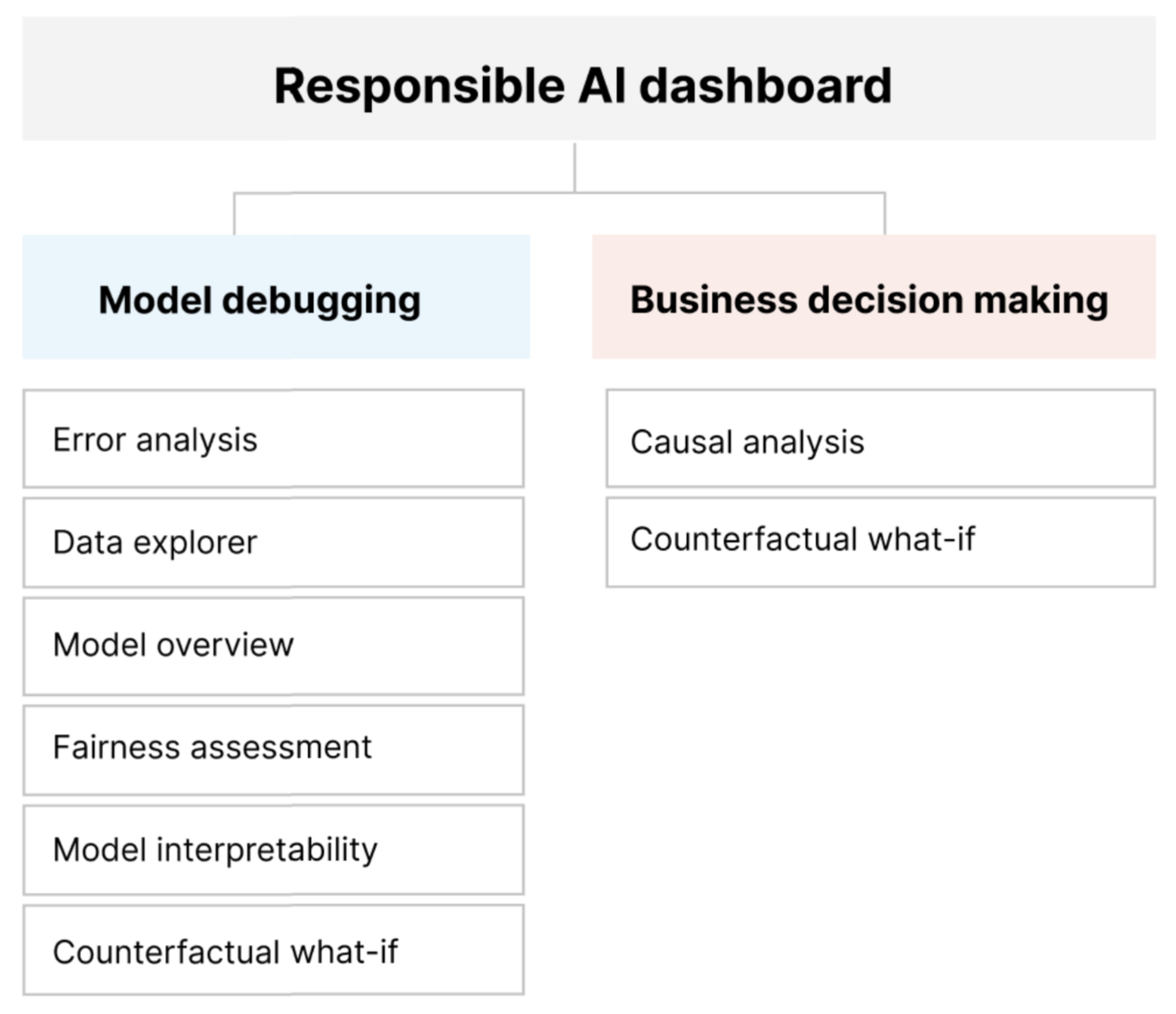
El panel de IA responsable proporciona una única interfaz para ayudarle a implementar IA responsable en la práctica de forma eficaz y eficiente. Reúne varias herramientas de IA responsable maduras en las áreas de:
- Evaluación del rendimiento y la equidad del modelo
- Exploración de datos
- Interpretabilidad de Machine Learning
- Análisis de errores
- Análisis y perturbaciones contrafactuales
- Inferencia causal
El panel ofrece una evaluación holística y depuración de modelos para que pueda tomar decisiones fundamentadas basadas en datos. Tener acceso a todas estas herramientas en una interfaz le permite:
Evaluar y depurar los modelos de Machine Learning mediante la identificación de los errores del modelo y los problemas de equidad, el diagnóstico de por qué se producen esos errores e información sobre los pasos de mitigación.
Aumentar las capacidades de toma de decisiones basadas en datos abordando preguntas como:
"¿Cuál es el cambio mínimo que los usuarios pueden aplicar a sus características para obtener un resultado diferente del modelo?"
"¿Cuál es el efecto causal de reducir o aumentar una característica (por ejemplo, consumo de carne roja) en un resultado real (por ejemplo, progresión de la diabetes)?"
Puede personalizar el panel para incluir solo el subconjunto de herramientas que son pertinentes para su caso de uso.
El panel de IA responsable va acompañado de un cuadro de mandos PDF. El cuadro de mandos permite exportar los metadatos de IA responsable y la información sobre los datos y los modelos. Después, puede compartirlos sin conexión con las partes interesadas del producto y del cumplimiento.
Componentes del panel de IA responsable
El panel de IA responsable reúne, en una vista completa, diversas herramientas nuevas y ya existentes. El panel integra estas herramientas con la CLI de Azure Machine Learning v2, el SDK para Python de Azure Machine Learning v2 y Estudio de Azure Machine Learning. Estas herramientas son:
- Análisis de datos, para comprender y explorar las distribuciones y estadísticas del conjunto de datos.
- Información general del modelo y evaluación de equidad, para evaluar el rendimiento del modelo y los problemas de equidad de grupo del modelo (de qué manera los diversos grupos de personas se ven afectados por las predicciones del modelo).
- Análisis de errores, para ver y comprender cómo se distribuyen los errores en el conjunto de datos.
- Interpretabilidad del modelo (valores de importancia de las características individuales o agregadas), para comprender las predicciones del modelo y cómo se hacen esas predicciones generales e individuales.
- Análisis contrafactual e hipotético para observar de qué modo las alteraciones de las características afectarían a las predicciones del modelo y proporcionarle los puntos de datos más cercanos con predicciones del modelo opuestas o diferentes.
- Análisis causal, para usar datos históricos para ver los efectos causales de las características de tratamiento en los resultados reales.
En conjunto, estas herramientas le permitirán depurar los modelos de Machine Learning, al tiempo que informan las decisiones controladas por datos y controladas por modelos. En el diagrama siguiente, se muestra cómo incorporarlos al ciclo de vida de la inteligencia artificial para mejorar los modelos y obtener información de datos sólida.
Depuración de modelos
La evaluación y depuración de modelos de Machine Learning es fundamental para la confiabilidad, la interoperabilidad, la equidad y el cumplimiento del modelo. Ayuda a determinar cómo y por qué los sistemas de IA se comportan de la manera en que lo hacen. Después, puede usar este conocimiento para mejorar el rendimiento del modelo. Conceptualmente, la depuración de modelos consta de tres fases:
Identificación, para comprender y reconocer los errores del modelo y los problemas de equidad al abordar las preguntas siguientes:
"¿Qué tipos de errores tiene el modelo?"
"¿En qué áreas son más frecuentes los errores?"
Diagnóstico, para explorar los motivos que subyacen a los errores identificados al abordar:
"¿Cuáles son las causas de estos errores?"
"¿Dónde debo centrar los recursos para mejorar el modelo?"
Mitigación, para usar la información de identificación y diagnóstico de las fases anteriores para dar pasos de mitigación específicos y abordar preguntas como:
"¿Cómo puedo mejorar el modelo?"
"¿Qué soluciones sociales o técnicas hay para estos problemas?"

En la tabla siguiente, se describe cuándo usar los componentes del panel de IA responsable para admitir la depuración de modelos:
| Fase | Componente | Descripción |
|---|---|---|
| Identificar | Análisis de errores | El componente de análisis de errores le ayuda a comprender mejor la distribución de errores del modelo e identificar rápidamente cohortes (subgrupos) erróneas de datos. Las funcionalidades de este componente en el panel proceden del paquete de análisis de errores. |
| Identificar | Análisis de equidad | El componente de equidad define grupos en términos de atributos confidenciales, como sexo, raza y edad. A continuación, evalúa cómo afectan las predicciones del modelo a estos grupos y cómo puede mitigar las disparidades. Para evaluar el rendimiento del modelo, examina la distribución de los valores de predicción y los valores de las métricas de rendimiento del modelo entre los grupos. Las funcionalidades de este componente del panel proceden del paquete Fairlearn. |
| Identificar | Introducción al modelo | El componente de información general del modelo agrega métricas de evaluación del modelo en una vista general de la distribución de las predicciones del modelo para una mejor investigación de su rendimiento. Este componente también permite la evaluación de equidad del grupo, resaltando el desglose del rendimiento del modelo en los grupos confidenciales. |
| Diagnóstico | Análisis de datos | El análisis de datos visualiza los conjuntos de datos en función de los resultados previstos y reales, los grupos de errores y las características específicas. Después, puede identificar los problemas de sobrepresentación y representación insuficiente, junto con ver cómo se agrupan los datos en el conjunto de datos. |
| Diagnóstico | Interoperabilidad del modelo | El componente de interpretabilidad genera explicaciones comprensibles por los humanos de las predicciones de un modelo de Machine Learning. Proporciona varias vistas sobre el comportamiento de un modelo: - Explicaciones globales (por ejemplo, ¿qué características afectan al comportamiento general de un modelo de asignación de préstamos?) - Explicaciones locales (por ejemplo, ¿por qué se ha aprobado o rechazado la solicitud de préstamo de un solicitante?) Las funcionalidades de este componente del panel proceden del paquete InterpretML. |
| Diagnóstico | Análisis contrafactual e hipotético | Este componente consta de dos funcionalidades para un mejor diagnóstico de errores: - Generar un conjunto de ejemplos en los que los cambios mínimos en un punto determinado modifican la predicción del modelo. Es decir, los ejemplos muestran los puntos de datos más cercanos con predicciones del modelo opuestas. - Permitir las perturbaciones hipotéticas interactivas y personalizadas de los puntos de datos individuales para comprender de qué manera reacciona el modelo a los cambios de las características. Las funcionalidades de este componente del panel proceden del paquete DiCE. |
Los pasos de mitigación están disponibles mediante herramientas independientes, como Fairlearn. Para obtener más información, consulte los algoritmos de mitigación de falta de equidad.
Toma de decisiones responsable
La toma de decisiones es una de las mayores promesas del aprendizaje automático. El panel de IA responsable puede ayudarle a tomar decisiones empresariales informadas mediante:
Información basada en datos, para comprender mejor los efectos causales del tratamiento en un resultado mediante el uso de datos históricos únicamente. Por ejemplo:
"¿Cómo afectaría un medicamento a la presión arterial de un paciente?"
"¿Cómo afectaría a los ingresos proporcionar valores promocionales a determinados clientes?"
Esta información se proporciona mediante el componente de inferencia causal del panel.
Conclusiones basadas en modelos, para responder a las preguntas de los usuarios (por ejemplo, "¿Qué puedo hacer para obtener un resultado diferente de la inteligencia artificial la próxima vez?") de modo que puedan adoptar medidas. Esta información se proporciona a los científicos de datos mediante el componente de análisis contrafactual e hipotético.

Las funcionalidades de análisis exploratorio de datos, inferencia causal y análisis contrafactual pueden ayudarle a tomar decisiones informadas controladas por modelos y controladas por datos de forma responsable.
Estos componentes del panel de IA responsable permiten la toma de decisiones responsable:
Análisis de datos: puede volver a usar el componente del análisis de datos aquí para comprender las distribuciones de datos e identificar la sobrerrepresentación y la representación insuficiente. La exploración de datos es una parte crítica de la toma de decisiones, ya que no es factible tomar decisiones informadas sobre una cohorte que está representada de forma insuficiente en los datos.
Inferencia causal: el componente de inferencia causal estima cómo cambia un resultado real en presencia de una intervención. Además, ayuda a construir intervenciones prometedoras mediante la simulación de respuestas de la característica a diversas intervenciones y la creación de reglas para determinar qué cohortes de la población se beneficiarían de una intervención determinada. En conjunto, estas funcionalidades le permiten aplicar nuevas directivas y afectar al cambio en el mundo real.
Las funcionalidades de este componente proceden del paquete EconML, que estima los efectos heterogéneos de tratamiento a partir de los datos observacionales mediante el aprendizaje automático.
Análisis contrafactual: puede reutilizar el componente de análisis contrafactual aquí para generar cambios mínimos aplicados a las características de un punto de datos que conducen a predicciones de modelo opuestas. Por ejemplo: Taylor habría obtenido la aprobación del préstamo por parte de la inteligencia artificial si hubiera ganado 10 000 USD más en ingresos anuales y tuviera dos tarjetas de crédito abiertas.
Proporcionar esta información a los usuarios informa su perspectiva. Les educa sobre cómo pueden actuar para obtener el resultado deseado de la inteligencia artificial en el futuro.
Las funcionalidades de este componente proceden del paquete DiCE.
Motivos para usar el panel de IA responsable
Aunque se han logrado avances en herramientas individuales para áreas específicas de la IA responsable, los científicos de datos a menudo tienen que usar varias herramientas para evaluar holísticamente sus modelos y datos. Por ejemplo: es posible que tengan que usar la interpretabilidad del modelo y la evaluación de equidad en conjunto.
Si un científico de datos detecta un problema de equidad con una herramienta, tiene que ir a otra herramienta para comprender qué factores de los datos o del modelo se encuentran en la raíz del problema antes de emprender cualquier paso para la mitigación. Los siguientes factores complican aún más este proceso complicado:
- No hay una ubicación central donde conocer y aprender sobre las herramientas, lo que amplía el tiempo necesario para investigar y aprender nuevas técnicas.
- Las distintas herramientas no se comunican entre sí. Los científicos de datos tienen que reorganizar los conjuntos de datos, los modelos y otros metadatos a medida que los pasan entre las herramientas.
- Las métricas y visualizaciones no se pueden comparar con facilidad y los resultados son difíciles de compartir.
El panel de IA responsable desafía este status quo. Es una herramienta completa y personalizable que reúne experiencias fragmentadas en un solo lugar. Permite incorporarse sin problemas a un único marco personalizable para la depuración de modelos y la toma de decisiones controladas por datos.
Mediante el panel de IA responsable, puede crear cohortes de conjuntos de datos, pasar esas cohortes a todos los componentes admitidos y observar el estado del modelo para las cohortes identificadas. Puede comparar aún más la información de todos los componentes admitidos en una variedad de cohortes creadas previamente para realizar análisis desagregados y encontrar los puntos ciegos del modelo.
Cuando esté listo para compartir esa información con otras partes interesadas, puede extraerlas fácilmente mediante el cuadro de mandos PDF de IA responsable. Adjunte el informe PDF a los informes de cumplimiento o compártalo con los compañeros para generar confianza y obtener su aprobación.
Formas de personalizar el panel de IA responsable
La fortaleza del panel de IA responsable radica en su capacidad de personalización. Permite a los usuarios diseñar flujos de trabajo integrales y a la medida para la depuración de modelos y la toma de decisiones, de manera que puedan abordar sus necesidades específicas.
¿Necesitas un poco de inspiración? Estos son algunos ejemplos de cómo se pueden reunir los componentes del panel para analizar escenarios de diversas maneras:
| Flujo del panel de IA responsable | Caso de uso |
|---|---|
| Información general del modelo > análisis de errores > análisis de datos | Para identificar errores del modelo y diagnosticarlos al comprender la distribución de los datos subyacentes. |
| Información general del modelo > evaluación de la equidad > análisis de datos | Para identificar problemas de equidad del modelo y diagnosticarlos al comprender la distribución de los datos subyacentes. |
| Información general del modelo > análisis de errores > análisis contrafactual e hipotético | Para diagnosticar errores en instancias individuales con análisis contrafactual (cambio mínimo que lleve a una predicción diferente del modelo). |
| Información general del modelo > análisis de datos | Para comprender la causa principal de los errores y problemas de equidad introducidos a través de desequilibrios en los datos o falta de representación de una cohorte de datos determinada. |
| Información general del modelo > interpretabilidad | Para diagnosticar errores del modelo al comprender cómo el modelo ha hecho sus predicciones. |
| Análisis de datos > inferencia causal | Para distinguir entre correlaciones y causas en los datos o decidir los mejores tratamientos que se aplicarán para obtener un resultado positivo |
| Interpretabilidad > inferencia causal | Para saber si los factores que ha usado el modelo para la predicción tienen algún efecto causal en el resultado real |
| Análisis de datos > análisis contrafactual e hipotético | Para abordar las preguntas de los clientes sobre qué pueden hacer la próxima vez para obtener un resultado diferente de un sistema de inteligencia artificial |
Personas que deben usar el panel de IA responsable
Las siguientes personas pueden usar el panel de IA responsable y su correspondiente cuadro de mandos de IA responsable para generar confianza en los sistemas de IA:
- Profesionales de Machine Learning y científicos de datos interesados en depurar y mejorar sus modelos de Machine Learning antes de la implementación
- Profesionales de Machine Learning y científicos de datos interesados en compartir sus registros de estado del modelo con los responsables de productos y las partes interesadas empresariales para generar confianza y recibir permisos de implementación
- Responsables de productos y partes interesadas empresariales que revisan los modelos de Machine Learning antes de la implementación
- Responsables de riesgos que revisan los modelos de Machine Learning para comprender los problemas de equidad y confiabilidad
- Proveedores de soluciones de inteligencia artificial que quieren explicar las decisiones del modelo a los usuarios o ayudarles a mejorar el resultado
- Profesionales de espacios fuertemente regulados que tienen que revisar los modelos de Machine Learning con reguladores y auditores
Limitaciones y escenarios admitidos
- Actualmente, el panel de IA responsable admite modelos de regresión y clasificación (binarios y de varias clases) entrenados en datos estructurados tabulares.
- Actualmente, el panel de IA responsable admite modelos de MLflow registrados en Azure Machine Learning solo con el tipo sklearn (scikit-learn). Los modelos de scikit-learn deben implementar métodos
predict()/predict_proba()o el modelo se debe encapsular dentro de una clase que implemente métodospredict()/predict_proba(). Los modelos se deben poder cargar en el entorno de componentes y deben ser seleccionables. - El panel de IA responsable visualiza actualmente hasta 5000 puntos de datos en la interfaz de usuario del panel. Debe reducir el conjunto de datos a 5 K o menos antes de pasarlo al panel.
- Las entradas del conjunto de datos en el panel de IA responsable deben ser DataFrames de Pandas en formato Parquet. Actualmente, no se admiten datos dispersos de NumPy y SciPy.
- El panel de IA responsable admite actualmente características numéricas o categóricas. Para las características de categorías, el usuario tiene que especificar explícitamente los nombres de las características.
- Actualmente, el panel de IA responsable no admite conjuntos de datos con más de 10 000 columnas.
- Actualmente, el panel de IA responsable no admite el modelo de MLFlow de AutoML.
- Actualmente, el panel de IA responsable no admite modelos de AutoML registrados desde la interfaz de usuario.
Pasos siguientes
- Aprenda a generar el panel de IA responsable mediante la CLI y el SDK o la UI de Estudio de Azure Machine Learning.
- Obtenga información sobre cómo generar un cuadro de mandos de IA responsable en función de la información observada en el panel de IA responsable.