Implementación de modelos de MLflow en implementaciones por lotes en Azure Machine Learning
SE APLICA A: Extensión ML de la CLI de Azure v2 (actual)SDK de Python azure-ai-ml v2 (actual)
Extensión ML de la CLI de Azure v2 (actual)SDK de Python azure-ai-ml v2 (actual)
En este artículo se describe cómo implementar modelos de MLflow en Azure Machine Learning para la inferencia por lotes mediante puntos de conexión por lotes. Al implementar modelos de MLflow en puntos de conexión por lotes, Azure Machine Learning completa las siguientes tareas:
- Proporciona una imagen base de MLflow o un entorno mantenido que contiene las dependencias necesarias para ejecutar un trabajo por lotes de Azure Machine Learning.
- Crea automáticamente una canalización de trabajo por lotes con un script de puntuación que se puede usar para procesar los datos mediante la paralelización.
Para más información sobre los tipos de archivo de entrada admitidos y detalles sobre cómo funciona el modelo de MLflow, vea Consideraciones para la implementación con fines de inferencia por lotes.
Requisitos previos
Suscripción a Azure. Si no tiene una suscripción a Azure, cree una cuenta gratuita antes de empezar.
Un área de trabajo de Azure Machine Learning. Para crear un área de trabajo, vea Administración de áreas de trabajo de Azure Machine Learning.
Los siguientes permisos en el área de trabajo de Azure Machine Learning:
- Para crear o administrar puntos de conexión e implementaciones: utilice un rol de Propietario, Colaborador o personalizado al que se le hayan asignado los permisos
Microsoft.MachineLearningServices/workspaces/batchEndpoints/*. - Para crear implementaciones de Azure Resource Manager en el grupo de recursos del área de trabajo: use un rol de Propietario, Colaborador o personalizado que tenga asignado el permiso
Microsoft.Resources/deployments/writeen el grupo de recursos donde se implementa el área de trabajo.
- Para crear o administrar puntos de conexión e implementaciones: utilice un rol de Propietario, Colaborador o personalizado al que se le hayan asignado los permisos
La CLI de Azure Machine Learning o el SDK de Azure Machine Learning para Python:
Ejecute el siguiente comando para instalar la CLI de Azure y la extensión
mlpara Azure Machine Learning:az extension add -n mlLas implementaciones de componentes de canalización para puntos de conexión por lotes se introdujeron en la versión 2.7 de la extensión
mlpara la CLI de Azure. Use el comandoaz extension update --name mlpara obtener la versión más reciente.
Conexión con su área de trabajo
El área de trabajo es el recurso de nivel superior de Azure Machine Learning. Proporciona un lugar centralizado para trabajar con todos los artefactos que cree al usar Azure Machine Learning. En esta sección, se conectará al área de trabajo donde realizará las tareas de implementación.
En el siguiente comando, escriba el id. de suscripción, el nombre del área de trabajo, el nombre de grupo de recursos y la ubicación:
az account set --subscription <subscription>
az configure --defaults workspace=<workspace> group=<resource-group> location=<location>
Exploración del ejemplo
En el ejemplo de este artículo se muestra cómo implementar un modelo de MLflow en un punto de conexión por lotes para realizar predicciones por lotes. El modelo de MLflow se basa en el conjunto de datos sobre enfermedades cardiacas de la UCI. La base de datos contiene 76 atributos, pero en el ejemplo solo se usa un subconjunto de 14. El modelo intenta predecir la presencia de enfermedades cardíacas en un paciente con un valor entero de 0 (sin presencia) a 1 (presencia).
El modelo se entrena mediante un clasificadorXGBBoost. Todo el preprocesamiento necesario se empaqueta como una canalización de scikit-learn, lo que convierte al modelo en una canalización de un extremo a otro que va desde los datos sin procesar a las predicciones.
El ejemplo de este artículo se basa en ejemplos de código incluidos en el repositorio azureml-examples. Para ejecutar los comandos localmente sin tener que copiar o pegar YAML y otros archivos, use los siguientes comandos para clonar el repositorio e ir a la carpeta del lenguaje de codificación:
git clone https://github.com/Azure/azureml-examples --depth 1
cd azureml-examples/cli
Los archivos de este ejemplo se encuentran en la siguiente carpeta:
cd endpoints/batch/deploy-models/heart-classifier-mlflow
Siga estos pasos en Jupyter Notebooks
Puede seguir este ejemplo mediante un cuaderno público de Jupyter Notebook. En el repositorio clonado, abra el cuaderno mlflow-for-batch-tabular.ipynb.
Implementación del modelo de MLflow
En esta sección, implementará un modelo de MLflow en un punto de conexión por lotes para que pueda ejecutar la inferencia por lotes en datos nuevos. Antes de avanzar con la implementación, debe asegurarse de que el modelo está registrado y que hay un clúster de proceso disponible en el área de trabajo.
Registro del modelo
Los puntos de conexión por lotes solo pueden implementar modelos registrados. En este artículo, usará una copia local del modelo en el repositorio. Como resultado, solo tiene que publicar el modelo en el registro en el área de trabajo.
Nota:
Si el modelo que va a implementar ya está registrado, puede continuar con la sección Creación del clúster de proceso.
Para registrar el modelo, ejecute el comando siguiente:
MODEL_NAME='heart-classifier-mlflow'
az ml model create --name $MODEL_NAME --type "mlflow_model" --path "model"
Creación de un clúster de proceso
Debe asegurarse de que las implementaciones por lotes se pueden ejecutar en alguna infraestructura disponible (proceso). Las implementaciones por lotes se pueden ejecutar en cualquier proceso de Machine Learning que ya exista en el área de trabajo. Varias implementaciones por lotes pueden compartir la misma infraestructura de proceso.
En este artículo, trabajará en un clúster de proceso de Machine Learning denominado cpu-cluster. En el ejemplo siguiente se comprueba que existe un proceso en el área de trabajo o se crea uno.
Cree un clúster de proceso:
az ml compute create -n batch-cluster --type amlcompute --min-instances 0 --max-instances 5
Creación del punto de conexión por lotes
Para crear un punto de conexión, necesita un nombre y una descripción. El nombre del punto de conexión aparece en el URI asociado al punto de conexión, por lo que debe ser único dentro de una región de Azure. Por ejemplo, solo puede haber un punto de conexión por lotes con el nombre mybatchendpoint en la región WestUS2.
Coloque el nombre del punto de conexión en una variable para facilitar la referencia más adelante:
Ejecute el siguiente comando:
ENDPOINT_NAME="heart-classifier"Creación del punto de conexión:
Para crear un punto de conexión, cree una configuración de
YAMLcomo la del código siguiente:endpoint.yml
$schema: https://azuremlschemas.azureedge.net/latest/batchEndpoint.schema.json name: heart-classifier-batch description: A heart condition classifier for batch inference auth_mode: aad_tokenCree el punto de conexión con el siguiente comando:
az ml batch-endpoint create -n $ENDPOINT_NAME -f endpoint.yml
Creación de la implementación por lotes
En los modelos de MLflow no es necesario que indique un entorno o un script de puntuación al crear la implementación. El entorno o el script de puntuación se crean automáticamente. Pero puede especificarlos si quiere personalizar cómo la implementación realiza la inferencia.
Para crear una implementación en el punto de conexión creado, cree una configuración de
YAMLcomo la que se muestra en el código siguiente. Puede comprobar el esquema YAML del punto de conexión por lotes completo para obtener más propiedades.deployment-simple/deployment.yml
$schema: https://azuremlschemas.azureedge.net/latest/modelBatchDeployment.schema.json endpoint_name: heart-classifier-batch name: classifier-xgboost-mlflow description: A heart condition classifier based on XGBoost type: model model: azureml:heart-classifier-mlflow@latest compute: azureml:batch-cluster resources: instance_count: 2 settings: max_concurrency_per_instance: 2 mini_batch_size: 2 output_action: append_row output_file_name: predictions.csv retry_settings: max_retries: 3 timeout: 300 error_threshold: -1 logging_level: infoCree la implementación con el siguiente comando:
az ml batch-deployment create --file deployment-simple/deployment.yml --endpoint-name $ENDPOINT_NAME --set-default
Importante
Configure el valor timeout en la implementación en función del tiempo que tarde el modelo en ejecutar la inferencia en un único lote. Cuanto mayor sea el tamaño del lote, más tiempo tendrá el valor timeout. Recuerde que el valor mini_batch_size indica el número de archivos de un lote y no el número de muestras. Al trabajar con datos tabulares, cada archivo puede contener varias filas, lo que aumenta el tiempo necesario para que el punto de conexión por lotes procese cada archivo. En esos casos, use valores timeout altos para evitar errores de tiempo de espera.
Invocar el punto de conexión
Aunque puede invocar una implementación específica dentro de un punto de conexión, es habitual invocar el propio punto de conexión y dejar que este decida qué implementación se va a usar. Este tipo de implementación se denomina implementación "predeterminada". Este enfoque le permite cambiar la implementación predeterminada, lo que posibilidad cambiar el modelo que atiende la implementación sin cambiar el contrato con el usuario que invoca el punto de conexión.
Use la instrucción siguiente para actualizar la implementación predeterminada:
DEPLOYMENT_NAME="classifier-xgboost-mlflow"
az ml batch-endpoint update --name $ENDPOINT_NAME --set defaults.deployment_name=$DEPLOYMENT_NAME
El punto de conexión por lotes ya está listo para su uso.
Prueba de la implementación
Para probar el punto de conexión, use un ejemplo de datos sin etiquetar ubicados en este repositorio que se puedan usar con el modelo. Los puntos de conexión por lotes solo pueden procesar los datos que se encuentran en la nube y que son accesibles desde el área de trabajo de Machine Learning. En este ejemplo, el ejemplo se carga en un almacén de datos de Machine Learning. Debe crear un recurso de datos que se pueda usar a fin de invocar el punto de conexión para la puntuación. Tenga en cuenta que los puntos de conexión por lotes aceptan datos que se pueden colocar en varias ubicaciones.
Primero, cree el recurso de datos. Este recurso de datos consta de una carpeta con varios archivos CSV que se quieren procesar en paralelo mediante puntos de conexión por lotes. Puede omitir este paso si los datos ya están registrados como un recurso de datos o quiere usar otro tipo de entrada.
Cree una definición de recurso de datos en YAML:
heart-dataset-unlabeled.yml
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json name: heart-dataset-unlabeled description: An unlabeled dataset for heart classification. type: uri_folder path: dataCree el recurso de datos:
az ml data create -f heart-dataset-unlabeled.yml
Después de cargar los datos, invoque el punto de conexión.
Sugerencia
En los siguientes comandos, observe que el nombre de implementación no se indica en la operación
invoke. El punto de conexión enruta automáticamente el trabajo a la implementación predeterminada porque el punto de conexión solo tiene una. Puede tener como destino una implementación específica si indica el argumento o parámetrodeployment_name.Ejecute el comando siguiente:
JOB_NAME = $(az ml batch-endpoint invoke --name $ENDPOINT_NAME --input azureml:heart-dataset-unlabeled@latest --query name -o tsv)Nota:
Es posible que la utilidad
jqno esté instalada en todas las instalaciones. Para obtener las instrucciones de instalación, consulte Descarga de jq.Se inicia un trabajo por lotes tan pronto como el comando vuelve. Puede supervisar el estado del trabajo hasta que finalice:
Ejecute el siguiente comando:
az ml job show -n $JOB_NAME --web
Análisis de salidas
Las predicciones de salida se generan en el archivo predictions.csv, como se indica en la configuración de implementación. El trabajo genera una salida denominada score donde se coloca este archivo. Solo se genera un archivo por trabajo por lotes.
El archivo tiene la estructura siguiente:
Al modelo se envía una fila por cada punto de datos. Para los datos tabulares, el archivo predictions.csv contiene una fila para cada fila presente en cada uno de los archivos procesados. Para otros tipos de datos (imágenes, audio, texto), hay una fila por cada archivo procesado.
Las columnas siguientes están en el archivo (en el orden especificado):
row(opcional): el índice de fila correspondiente en el archivo de datos de entrada. Esta columna solo se aplica si los datos de entrada son tabulares. Las predicciones se devuelven en el mismo orden en que aparecen en el archivo de entrada. Puede usar el número de fila para comparar con la predicción correspondiente.prediction: la predicción asociada a los datos de entrada. Este valor se devuelve "tal cual" ha sido proporcionado por la funciónpredict().del modelo.file_name: el nombre de archivo desde el que se leen los datos. En datos tabulares, use este campo para determinar qué predicción pertenece a cada dato de entrada.
Puede descargar los resultados del trabajo con el nombre del trabajo.
Use los siguientes comandos para descargar las predicciones:
az ml job download --name $JOB_NAME --output-name score --download-path ./
Después de descargar el archivo, puede abrirlo con la herramienta de edición que prefiera. En el ejemplo siguiente se cargan las predicciones mediante un elemento DataFrame Pandas.
import pandas as pd
score = pd.read_csv(
"named-outputs/score/predictions.csv", names=["row", "prediction", "file"]
)En la salida se muestra una tabla:
| Row | Predicción | Archivo |
|---|---|---|
| 0 | 0 | heart-unlabeled-0.csv |
| 1 | 1 | heart-unlabeled-0.csv |
| 2 | 0 | heart-unlabeled-0.csv |
| ... | ... | ... |
| 307 | 0 | heart-unlabeled-3.csv |
Sugerencia
Observe que en este ejemplo, los datos de entrada contienen datos tabulares en formato CSV. Hay cuatro archivos de entrada diferentes: heart-unlabeled-0.csv, heart-unlabeled-1.csv, heart-unlabeled-2.csv y heart-unlabeled-3.csv.
Revisión de consideraciones para la inferencia por lotes
Machine Learning admite la implementación de modelos de MLflow en puntos de conexión por lotes sin tener que indicar un script de puntuación. Este enfoque es una manera cómoda de implementar modelos que necesitan procesar grandes cantidades de datos, como en el procesamiento por lotes. Machine Learning usa información en la especificación del modelo de MLflow para orquestar el proceso de inferencia.
Exploración de la distribución del trabajo en los trabajadores
Los puntos de conexión por lotes distribuyen el trabajo en el nivel de archivo tanto para los datos estructurados como para los no estructurados. Como consecuencia, solo se admiten archivos de URI y carpetas de URI para esta característica. Cada trabajo procesa lotes con el número de archivos que indica Mini batch size. En el caso de los datos tabulares, los puntos de conexión por lotes no tienen en cuenta el número de filas que hay dentro de cada archivo al distribuir el trabajo.
Advertencia
Las estructuras de carpetas anidadas no se exploran durante la inferencia. Si crea particiones de los datos mediante carpetas, asegúrese de aplanar la estructura antes de continuar.
Las implementaciones por lotes llamarán a la función predict del modelo de MLflow una vez por archivo. Par los archivos .csv con varias filas, esta acción puede imponer una presión de memoria en el proceso subyacente. El comportamiento puede aumentar el tiempo que tarda el modelo en puntuar un solo archivo, especialmente para modelos costosos como los modelos de lenguaje grande. Si encuentra varias excepciones de memoria insuficiente o entradas de tiempo de espera en los registros, considere la posibilidad de dividir los datos en archivos más pequeños con menos filas o de implementar el procesamiento por lotes en el nivel de fila dentro del script de puntuación o modelo.
Revisión de la compatibilidad con los tipos de archivo
Los siguientes tipos de datos se admiten para la inferencia por lotes al implementar modelos de MLflow sin un entorno o un script de puntuación. Para procesar otro tipo de archivo, o bien ejecutar la inferencia de forma diferente, puede crear la implementación si personaliza la implementación del modelo de MLflow con un script de puntuación.
| Extensión de archivo | Tipo devuelto como entrada del modelo | Requisito de firma |
|---|---|---|
.csv, .parquet, .pqt |
pd.DataFrame |
ColSpec. Si no se proporciona, no se aplican los tipos de columna. |
.png, .jpg, .jpeg, .tiff, .bmp, .gif |
np.ndarray |
TensorSpec. La entrada se vuelve a configurar para que coincida con la forma de los tensores, si está disponible. Si no hay ninguna firma disponible, se infieren tensores de tipo np.uint8. Para más información, vea Consideraciones sobre el procesamiento de imágenes de modelos de MLflow. |
Advertencia
Cualquier archivo no admitido que pueda estar presente en los datos de entrada hace que se produzca un error en el trabajo. En esos casos, puede ver un error como ERROR:azureml:Error al procesar el archivo de entrada: "/mnt/batch/tasks/.../un-archivo-dado.avro". No se admite el tipo de archivo "avro"..
Descripción del cumplimiento de firmas para modelos de MLflow
Los trabajos de implementación por lotes aplican los tipos de datos de la entrada mientras se leen los datos mediante la firma del modelo de MLflow disponible. Como resultado, la entrada de datos cumple los tipos indicados en la firma del modelo. Si los datos no se pueden analizar según lo previsto, se produce un error similar a ERROR:azureml:Error al procesar el archivo de entrada: "/mnt/batch/tasks/.../un-archivo-dado.csv". Excepción: literal no válido para int() con base 10: "valor".
Sugerencia
Las firmas en los modelos de MLflow son opcionales, pero se recomiendan encarecidamente. Proporcionan una manera cómoda de detectar tempranamente los problemas de compatibilidad de datos. Para obtener más información sobre cómo registrar modelos con firmas, consulte Registro de modelos con una firma personalizada, un entorno o ejemplos.
Puede inspeccionar la firma del modelo abriendo el archivo de MLmodel asociado al modelo de MLflow. Para más información sobre cómo funcionan las firmas en MLflow, vea Firmas en MLflow.
Examen de la compatibilidad con variantes
Las implementaciones por lotes solo admiten la implementación de modelos de MLflow con una variante pyfunc. Para implementar otra variante, vea Personalización de la implementación de modelos con script de puntuación.
Personalización de la implementación de modelos con script de puntuación
Los modelos de MLflow se pueden implementar en puntos de conexión por lotes sin indicar un script de puntuación en la definición de implementación. Pero puede optar por indicar este archivo (normalmente denominado controlador por lotes) para personalizar la ejecución de la inferencia.
Normalmente, este flujo de trabajo se selecciona para los escenarios siguientes:
- Procesar tipos de archivo no compatibles con las implementaciones por lotes de implementaciones de MLflow.
- Personalizar cómo se ejecuta el modelo, como usar un tipo específico para cargarlo con la función
mlflow.<flavor>.load(). - Completar el procesamiento previo o posterior en la rutina de puntuación, cuando no la completa el propio modelo.
- Ajustar la presentación de un modelo que no se representa correctamente con datos tabulares, como un gráfico de tensor que representa una imagen.
- Permitir que el modelo lea datos en fragmentos porque no puede procesar cada archivo a la vez debido a restricciones de memoria.
Importante
A fin de indicar un script de puntuación para una implementación de modelo de MLflow, debe especificar el entorno en el que se ejecuta la implementación.
Uso del script de puntuación
Siga estos pasos para implementar un modelo de MLflow con un script de puntuación personalizado:
Identifique la carpeta donde se coloca el modelo de MLflow.
En el portal de Azure Machine Learning, vaya a Modelos.
Seleccione el modelo que va implementar y después la pestaña Artefactos.
Anote la carpeta que se muestra. Esta carpeta se indicó cuando se registró el modelo.
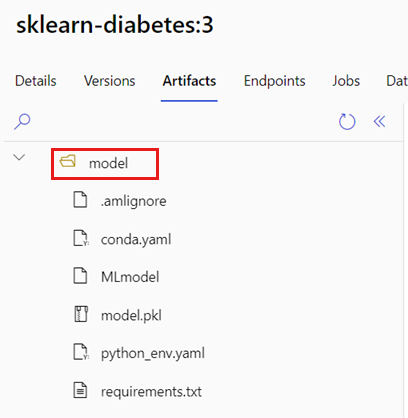
Cree un script de puntuación. Observe cómo se incluye el nombre de carpeta anterior
modelen la funcióninit().deployment-custom/code/batch_driver.py
# Copyright (c) Microsoft. All rights reserved. # Licensed under the MIT license. import os import glob import mlflow import pandas as pd import logging def init(): global model global model_input_types global model_output_names # AZUREML_MODEL_DIR is an environment variable created during deployment # It is the path to the model folder # Please provide your model's folder name if there's one model_path = glob.glob(os.environ["AZUREML_MODEL_DIR"] + "/*/")[0] # Load the model, it's input types and output names model = mlflow.pyfunc.load(model_path) if model.metadata and model.metadata.signature: if model.metadata.signature.inputs: model_input_types = dict( zip( model.metadata.signature.inputs.input_names(), model.metadata.signature.inputs.pandas_types(), ) ) if model.metadata.signature.outputs: if model.metadata.signature.outputs.has_input_names(): model_output_names = model.metadata.signature.outputs.input_names() elif len(model.metadata.signature.outputs.input_names()) == 1: model_output_names = ["prediction"] else: logging.warning( "Model doesn't contain a signature. Input data types won't be enforced." ) def run(mini_batch): print(f"run method start: {__file__}, run({len(mini_batch)} files)") data = pd.concat( map( lambda fp: pd.read_csv(fp).assign(filename=os.path.basename(fp)), mini_batch ) ) if model_input_types: data = data.astype(model_input_types) # Predict over the input data, minus the column filename which is not part of the model. pred = model.predict(data.drop("filename", axis=1)) if pred is not pd.DataFrame: if not model_output_names: model_output_names = ["pred_col" + str(i) for i in range(pred.shape[1])] pred = pd.DataFrame(pred, columns=model_output_names) return pd.concat([data, pred], axis=1)Cree un entorno donde se pueda ejecutar el script de puntuación. Como en este ejemplo se trata de un modelo de MLflow, los requisitos de Conda también se especifican en el paquete del modelo. Para más información sobre los modelos de MLflow y los archivos incluidos, vea El formato MLmodel.
En este paso, se crea el entorno con las dependencias de Conda del archivo. También debe incluir el paquete
azureml-core, que es necesario para las implementaciones por lotes.Sugerencia
Si el modelo ya está registrado en el registro de modelos, puede descargar y copiar el archivo
conda.ymlasociado al modelo. El archivo está disponible en Estudio de Azure Machine Learning en Modelos>Seleccione el modelo en la lista>Artefactos. En la carpeta raíz, seleccione el archivoconda.ymly, después, seleccione Descargar o copie su contenido.Importante
En este ejemplo se usa un entorno de Conda que se especifica en
/heart-classifier-mlflow/environment/conda.yaml. Este archivo se ha creado mediante la combinación del archivo de dependencias de Conda de MLflow original y la adición del paqueteazureml-core. No puede usar el archivoconda.ymldirectamente desde el modelo.La definición de entorno se incluye en la propia definición de implementación como un entorno anónimo. Verá las líneas siguientes en la implementación:
environment: name: batch-mlflow-xgboost image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest conda_file: environment/conda.yamlConfigurar la implementación:
Para crear una implementación en el punto de conexión creado, cree una configuración de
YAMLcomo la que se muestra en el fragmento de código siguiente. Puede comprobar el esquema YAML del punto de conexión por lotes completo para obtener más propiedades.deployment-custom/deployment.yml
$schema: https://azuremlschemas.azureedge.net/latest/modelBatchDeployment.schema.json endpoint_name: heart-classifier-batch name: classifier-xgboost-custom description: A heart condition classifier based on XGBoost type: model model: azureml:heart-classifier-mlflow@latest environment: name: batch-mlflow-xgboost image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest conda_file: environment/conda.yaml code_configuration: code: code scoring_script: batch_driver.py compute: azureml:batch-cluster resources: instance_count: 2 settings: max_concurrency_per_instance: 2 mini_batch_size: 2 output_action: append_row output_file_name: predictions.csv retry_settings: max_retries: 3 timeout: 300 error_threshold: -1 logging_level: infoCreación de la implementación:
Ejecute el código siguiente:
az ml batch-deployment create --file deployment-custom/deployment.yml --endpoint-name $ENDPOINT_NAME
El punto de conexión por lotes ya está listo para su uso.
Limpieza de recursos
Después de completar el ejercicio, elimine los recursos que ya no sean necesarios.
Ejecute el siguiente código para eliminar el punto de conexión por lotes y todas las implementaciones subyacentes:
az ml batch-endpoint delete --name $ENDPOINT_NAME --yes
Este comando no elimina los trabajos de puntuación por lotes.