Creación de trabajos y datos de entrada para puntos de conexión por lotes
Al usar puntos de conexión por lotes en Azure Machine Learning, puede realizar operaciones por lotes largas en grandes cantidades de datos de entrada. Los datos se pueden ubicar tanto en diferentes lugares, como en distintas regiones. Algunos tipos de puntos de conexión por lotes también pueden recibir parámetros literales como entradas.
En este artículo se describe cómo especificar entradas de parámetro para puntos de conexión por lotes y crear trabajos de implementación. El proceso admite el trabajo con datos de varios orígenes, como recursos de datos, almacenes de datos, cuentas de almacenamiento y archivos locales.
Requisitos previos
Un punto de conexión e implementación. Para crear estos recursos, consulte Implementación de modelos de MLflow en implementaciones por lotes en Azure Machine Learning.
Permisos para ejecutar una implementación de punto de conexión por lotes. Puede usar los roles Científico de datos de AzureML, Colaborador y Propietario para ejecutar una implementación. Para revisar los permisos específicos necesarios para las definiciones de roles personalizados, consulte Autorización en puntos de conexión por lotes.
Credenciales para invocar un punto de conexión. Para obtener más información, consulte Establecimiento de autenticación.
Acceso de lectura a los datos de entrada desde el clúster de proceso donde se implementa el punto de conexión.
Sugerencia
Algunas situaciones requieren el uso de un almacén de datos sin credenciales o una cuenta externa de Azure Storage como entrada de datos. En estos escenarios, asegúrese de configurar clústeres de proceso para el acceso a datos, ya que la identidad administrada del clúster de proceso se usa para montar la cuenta de almacenamiento. Todavía tiene control de acceso pormenorizado, ya que la identidad del trabajo (invocador) se usa para leer los datos subyacentes.
Establecer autenticación
Para invocar un punto de conexión, necesita un token de Microsoft Entra válido. Al invocar un punto de conexión, Azure Machine Learning crea un trabajo de implementación por lotes en la identidad asociada al token.
- Si usa la CLI de Azure Machine Learning (v2) o el SDK de Azure Machine Learning para Python (v2) para invocar puntos de conexión, no es necesario obtener manualmente el token de Microsoft Entra. Durante el inicio de sesión, el sistema autentica la identidad del usuario. También recupera y pasa el token por usted.
- Si usa la API de REST para invocar puntos de conexión, debe obtener el token manualmente.
Puede usar credenciales propias para la invocación, como se describe en los procedimientos siguientes.
Use la CLI de Azure para iniciar sesión mediante la autenticación interactiva o de código de dispositivo:
az login
Para obtener más información sobre los distintos tipos de credenciales, consulte Ejecución de trabajos mediante distintos tipos de credenciales.
Creación de trabajos básicos
Para crear un trabajo a partir de un punto de conexión por lotes, se invoca el punto de conexión. La invocación se puede realizar mediante la CLI de Azure Machine Learning, el SDK de Azure Machine Learning para Python o una llamada a la API de REST.
En los ejemplos siguientes se muestran los conceptos básicos de la invocación de un punto de conexión por lotes que recibe una única carpeta de datos de entrada para su procesamiento. Para obtener ejemplos que implican varias entradas y salidas, consulte Descripción de las entradas y salidas.
Use la operación invoke en puntos de conexión por lotes:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data
Invocación de una implementación específica
Los puntos de conexión por lotes pueden hospedar varias implementaciones en el mismo punto de conexión. El punto de conexión predeterminado se usa a menos que el usuario especifique lo contrario. Puede usar los procedimientos siguientes para cambiar la implementación que usa.
Use el argumento --deployment-name o -d para especificar el nombre de la implementación:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--deployment-name $DEPLOYMENT_NAME \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data
Configuración de las propiedades del trabajo
Puede configurar algunas propiedades de trabajo en el momento de la invocación.
Nota:
Actualmente, solo puede configurar propiedades de trabajo en puntos de conexión por lotes con implementaciones de componentes de canalización.
Configuración del nombre del experimento
Use los procedimientos siguientes para configurar el nombre del experimento.
Use el argumento --experiment-name para especificar el nombre del experimento:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--experiment-name "my-batch-job-experiment" \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data
Descripción de las entradas y salidas
Los puntos de conexión por lotes proporcionan una API duradera que los consumidores pueden usar para crear trabajos por lotes. La misma interfaz se puede usar para especificar las entradas y las salidas que espera la implementación. Use entradas para pasar cualquier información que el punto de conexión necesite para realizar el trabajo.
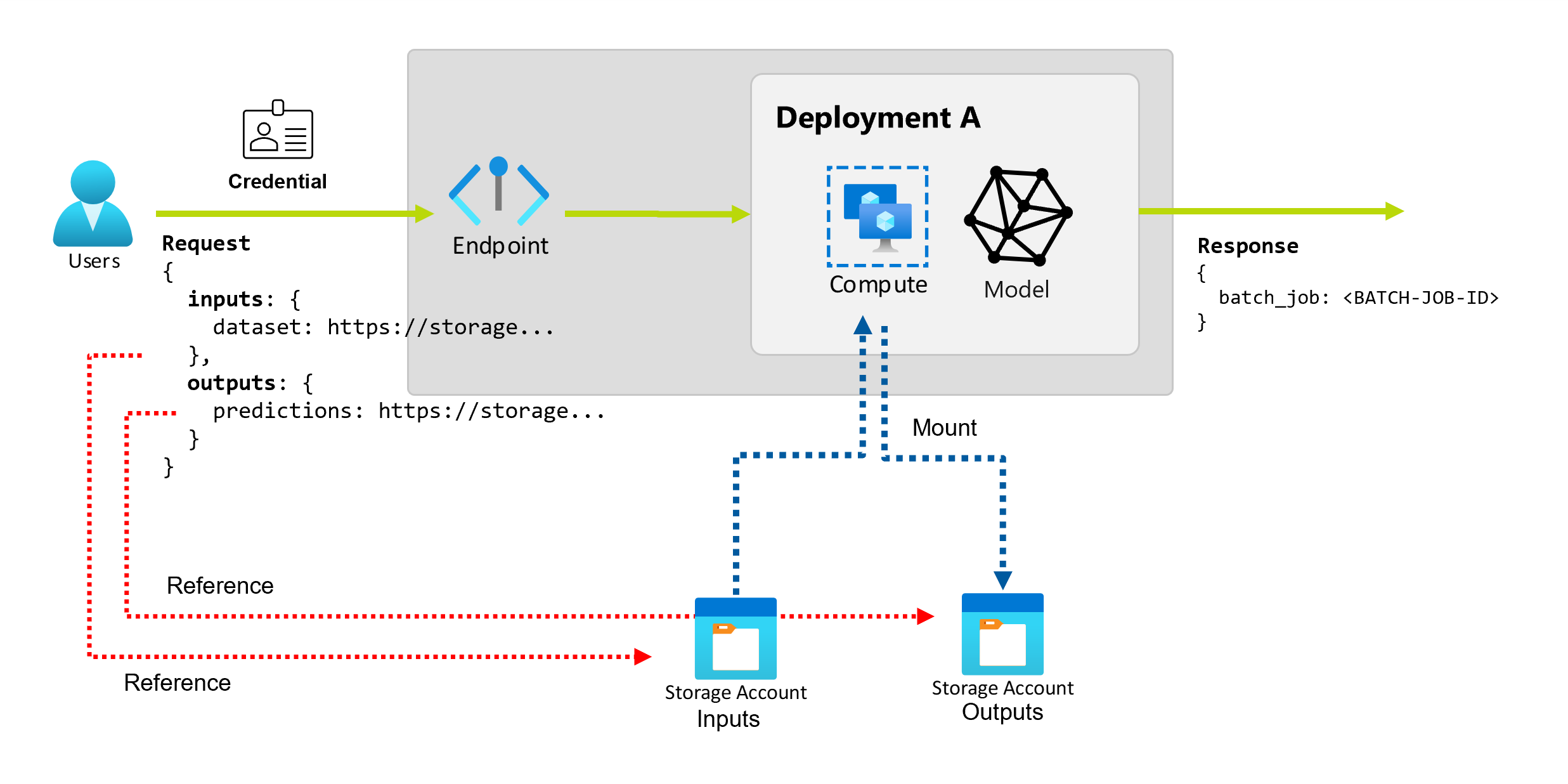
Los puntos de conexión por lotes admiten dos tipos de entradas:
- Entradas de datos, o punteros a una ubicación de almacenamiento específica o a un recurso de Azure Machine Learning
- Entradas literales, o valores literales como números o cadenas que quiere pasar al trabajo.
El número y el tipo de entradas y salidas dependen del tipo de implementación por lotes. Las implementaciones de modelos siempre requieren una entrada de datos y generan una salida de datos. Las entradas literales no se admiten en las implementaciones de modelos. En cambio, las implementaciones de componentes de canalización proporcionan una construcción más general para crear puntos de conexión. En una implementación de componentes de canalización, puede especificar cualquier número de entradas de datos, entradas literales y salidas.
En la tabla siguiente se resumen las entradas y salidas de las implementaciones por lotes:
| Tipo de implementación | Número de entradas | Tipos de entrada admitidos | Número de salidas | Tipos de salida compatibles |
|---|---|---|---|---|
| Implementación de modelo | 1 | Entradas de datos | 1 | Salidas de datos |
| Implementación de componentes de canalización | 0-N | Entradas de datos y entradas literales | 0-N | Salidas de datos |
Sugerencia
Las entradas y salidas siempre se denominan. Cada nombre actúa como clave para identificar los datos y pasar el valor durante la invocación. Dado que las implementaciones de modelos siempre requieren una entrada y salida, los nombres se omiten durante la invocación en las implementaciones de modelos. Puede asignar el nombre que mejor describa el caso de uso, como sales_estimation.
Exploración de las entradas de datos
Las entradas de datos hacen referencia a entradas que apuntan a una ubicación donde se colocan los datos. Como los puntos de conexión por lotes suelen consumir grandes cantidades de datos, no se pueden pasar los datos de entrada como parte de la solicitud de invocación. En su lugar, especifique la ubicación donde debería ir el punto de conexión por lotes para buscar los datos. Los datos de entrada se montan y transmiten en la instancia de proceso de destino para mejorar el rendimiento.
Los puntos de conexión de Batch pueden leer archivos que se encuentran en los siguientes tipos de almacenamiento:
-
Recursos de datos de Azure Machine Learning, incluida la carpeta (
uri_folder) y los tipos de archivo (uri_file). - Almacenes de datos de Azure Machine Learning, incluidos Azure Blob Storage, Azure Data Lake Storage Gen1 y Azure Data Lake Storage Gen2.
- Cuentas de Azure Storage, incluidos Blob Storage, Data Lake Storage Gen1 y Data Lake Storage Gen2.
- Carpetas y archivos de datos locales, cuando se usa la CLI de Azure Machine Learning o el SDK de Azure Machine Learning para Python para invocar puntos de conexión. Pero los datos locales se cargan en el almacén de datos predeterminado del área de trabajo de Azure Machine Learning.
Importante
Aviso de desuso: los conjuntos de datos de tipo FileDataset (V1) están en desuso y se retirarán en el futuro. Los puntos de conexión por lotes existentes que dependen de esta funcionalidad seguirán funcionando. Pero no hay compatibilidad con los conjuntos de datos V1 en los puntos de conexión por lotes creados con:
- Versiones de la CLI de Azure Machine Learning v2 que están disponibles con carácter general (2.4.0 y versiones posteriores).
- Versiones de la API de REST que están disponibles con carácter general (2022-05-01 y versiones posteriores).
Exploración de las entradas literales
Las entradas literales hacen referencia a entradas que se pueden representar y resolver en tiempo de invocación, como cadenas, números y valores booleanos. Normalmente, se usan entradas literales para pasar parámetros al punto de conexión como parte de una implementación de componentes de canalización. Los puntos de conexión por lotes admiten los siguientes tipos literales:
stringbooleanfloatinteger
Las entradas literales solo se admiten en implementaciones de componentes de canalización. Para ver cómo especificar puntos de conexión literales, consulte Creación de trabajos con entradas literales.
Exploración de las salidas de datos
Las salidas de datos hacen referencia a la ubicación donde se colocan los resultados de un trabajo por lotes. Cada salida se identifica por un nombre y Azure Machine Learning asigna automáticamente una ruta de acceso única a cada salida con nombre. Puede especificar otra ruta de acceso si es necesario.
Importante
Los puntos de conexión de Batch solo admiten la escritura de salidas en almacenes de datos de Blob Storage. Si necesita escribir en una cuenta de almacenamiento con espacios de nombres jerárquicos habilitados, como Data Lake Storage Gen2, puede registrar el servicio de almacenamiento como almacén de datos de Blob Storage, ya que los servicios son totalmente compatibles. De este modo, puede escribir salidas de puntos de conexión por lotes en Data Lake Storage Gen2.
Creación de trabajos con entradas de datos
En los siguientes ejemplos se muestra cómo crear trabajos al tomar entradas de datos de recursos de datos, almacenes de datos y cuentas de Azure Storage.
Uso de datos de entrada de un recurso de datos
Los recursos de datos de Azure Machine Learning (anteriormente conocidos como conjuntos de datos) se admiten como entradas para trabajos. Siga estos pasos para ejecutar un trabajo de punto de conexión por lotes que usa datos de entrada almacenados en un recurso de datos registrado en Azure Machine Learning.
Advertencia
Actualmente no se admiten los recursos de datos de tipo table (MLTable).
Cree el recurso de datos. En este ejemplo, consta de una carpeta que contiene varios archivos CSV. Los puntos de conexión por lotes se usan para procesar los archivos en paralelo. Puede omitir este paso si los datos ya están registrados como un recurso de datos.
Cree una definición de recurso de datos en un archivo YAML denominado heart-data.yml:
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json name: heart-data description: An unlabeled data asset for heart classification. type: uri_folder path: dataCree el recurso de datos:
az ml data create -f heart-data.yml
Configure la entrada:
DATA_ASSET_ID=$(az ml data show -n heart-data --label latest | jq -r .id)El id. de recurso de datos tiene el formato
/subscriptions/<subscription-ID>/resourceGroups/<resource-group-name>/providers/Microsoft.MachineLearningServices/workspaces/<workspace-name>/data/<data-asset-name>/versions/<data-asset-version>.Ejecute el punto de conexión:
Use el argumento
--setpara especificar la entrada. En primer lugar, reemplace los guiones del nombre del recurso de datos por caracteres de subrayado. Las claves solo pueden contener caracteres alfanuméricos y caracteres de subrayado.az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --set inputs.heart_data.type="uri_folder" inputs.heart_data.path=$DATA_ASSET_IDPara un punto de conexión que atiende una implementación de modelo, puede usar el argumento
--inputpara especificar la entrada de datos, ya que una implementación de modelo siempre necesita una entrada de datos.az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $DATA_ASSET_IDEl argumento
--settiende a generar comandos largos al especificar varias entradas. En tales casos, puede enumerar las entradas en un archivo y, a continuación, hacer referencia al archivo al invocar el punto de conexión. Por ejemplo, puede crear un archivo YAML denominado inputs.yml que contenga las siguientes líneas:inputs: heart_data: type: uri_folder path: /subscriptions/<subscription-ID>/resourceGroups/<resource-group-name>/providers/Microsoft.MachineLearningServices/workspaces/<workspace-name>/data/heart-data/versions/1A continuación, puede ejecutar el siguiente comando, que usa el argumento
--filepara especificar las entradas:az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.yml
Uso de datos de entrada desde un almacén de datos
Los trabajos de implementación por lotes pueden hacer referencia directamente a datos que se encuentran en almacenes de datos registrados de Azure Machine Learning. En este ejemplo, primero cargará algunos datos en un almacén de datos en el área de trabajo de Azure Machine Learning. A continuación, ejecute una implementación por lotes en esos datos.
En este ejemplo se usa el almacén de datos predeterminado, pero puede usar otro almacén de datos. En cualquier área de trabajo de Azure Machine Learning, el nombre del almacén de datos de blobs predeterminado es workspaceblobstore. Si quiere usar otro almacén de datos en los pasos siguientes, reemplace workspaceblobstore por el nombre del almacén de datos preferido.
Cargue datos de ejemplo en el almacén de datos. Los datos de ejemplo están disponibles en el repositorio de azureml-examples. Puede encontrar los datos en la carpeta sdk/python/endpoints/batch/deploy-models/heart-classifier-mlflow/data de ese repositorio.
- En Estudio de Azure Machine Learning, abra la página recursos de datos del almacén de datos de blobs predeterminado y busque el nombre de su contenedor de blobs.
- Use una herramienta como el Explorador de Azure Storage o AzCopy para cargar los datos de ejemplo en una carpeta denominada heart-disease-uci-unlabeled en ese contenedor.
Configure la información de entrada:
Coloque la ruta de acceso del archivo en la variable
INPUT_PATH:DATA_PATH="heart-disease-uci-unlabeled" INPUT_PATH="azureml://datastores/workspaceblobstore/paths/$DATA_PATH"Observe cómo la carpeta
pathsforma parte de la ruta de acceso de entrada. Este formato indica que el valor siguiente es una ruta de acceso.Ejecute el punto de conexión:
Use el argumento
--setpara especificar la entrada:az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --set inputs.heart_data.type="uri_folder" inputs.heart_data.path=$INPUT_PATHPara un punto de conexión que atiende una implementación de modelo, puede usar el argumento
--inputpara especificar la entrada de datos, ya que una implementación de modelo siempre necesita una entrada de datos.az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $INPUT_PATH --input-type uri_folderEl argumento
--settiende a generar comandos largos al especificar varias entradas. En tales casos, puede enumerar las entradas en un archivo y, a continuación, hacer referencia al archivo al invocar el punto de conexión. Por ejemplo, puede crear un archivo YAML denominado inputs.yml que contenga las siguientes líneas:inputs: heart_data: type: uri_folder path: azureml://datastores/workspaceblobstore/paths/<data-path>Si los datos están en un archivo, use el tipo
uri_filepara la entrada en su lugar.A continuación, puede ejecutar el siguiente comando, que usa el argumento
--filepara especificar las entradas:az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.yml
Uso de datos de entrada de una cuenta de Azure Storage
Los puntos de conexión por lotes de Azure Machine Learning pueden leer datos de ubicaciones en la nube en cuentas de Azure Storage, tanto públicas como privadas. Siga estos pasos para ejecutar un trabajo de punto de conexión por lotes con datos en una cuenta de almacenamiento.
Para más información sobre configuraciones adicionales necesarias para leer datos de cuentas de almacenamiento, vea Configuración de clústeres de proceso para el acceso a datos.
Configure la entrada:
Establezca la variable
INPUT_DATA:INPUT_DATA="https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data"Si los datos están en un archivo, use un formato similar al siguiente para definir la ruta de acceso de entrada:
INPUT_DATA="https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data/heart.csv"Ejecute el punto de conexión:
Use el argumento
--setpara especificar la entrada:az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --set inputs.heart_data.type="uri_folder" inputs.heart_data.path=$INPUT_DATAPara un punto de conexión que atiende una implementación de modelo, puede usar el argumento
--inputpara especificar la entrada de datos, ya que una implementación de modelo siempre necesita una entrada de datos.az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $INPUT_DATA --input-type uri_folderEl argumento
--settiende a generar comandos largos al especificar varias entradas. En tales casos, puede enumerar las entradas en un archivo y, a continuación, hacer referencia al archivo al invocar el punto de conexión. Por ejemplo, puede crear un archivo YAML denominado inputs.yml que contenga las siguientes líneas:inputs: heart_data: type: uri_folder path: https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/dataA continuación, puede ejecutar el siguiente comando, que usa el argumento
--filepara especificar las entradas:az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.ymlSi los datos están en un archivo, use el tipo
uri_fileen el archivo inputs.yml para la entrada de datos.
Creación de trabajos con entradas literales
Las implementaciones de componentes de canalización pueden tomar entradas literales. Para obtener un ejemplo de una implementación por lotes que contiene una canalización básica, consulte Implementación de canalizaciones con puntos de conexión por lotes.
En el ejemplo siguiente, se muestra cómo especificar una entrada denominada score_mode, de tipo string, con un valor de append:
Coloque las entradas en un archivo YAML, como una llamada inputs.yml:
inputs:
score_mode:
type: string
default: append
Ejecute el comando siguiente, que usa el argumento --file para especificar las entradas.
az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.yml
También puede usar el argumento --set para especificar el tipo y el valor predeterminado. Pero este enfoque tiende a generar comandos largos cuando se especifican varias entradas:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--set inputs.score_mode.type="string" inputs.score_mode.default="append"
Creación de trabajos con salidas de datos
En el ejemplo siguiente se muestra cómo cambiar la ubicación de una salida denominada score. Por motivos de exhaustividad, el ejemplo también configura una entrada denominada heart_data.
En este ejemplo se usa el almacén de datos predeterminado, workspaceblobstore. Pero puede usar cualquier otro almacén de datos del área de trabajo siempre que sea una cuenta de Blob Storage. Si desea usar otro almacén de datos, reemplace workspaceblobstore en los pasos siguientes por el nombre del almacén de datos preferido.
Obtenga el identificador del almacén de datos.
DATA_STORE_ID=$(az ml datastore show -n workspaceblobstore | jq -r '.id')El identificador del almacén de datos tiene el formato
/subscriptions/<subscription-ID>/resourceGroups/<resource-group-name>/providers/Microsoft.MachineLearningServices/workspaces/<workspace-name>/datastores/workspaceblobstore.Creación de una salida de datos:
Defina los valores de entrada y salida en un archivo denominado inputs-and-outputs.yml. Use el identificador del almacén de datos en la ruta de acceso de salida. Por motivos de exhaustividad, defina también la entrada de datos.
inputs: heart_data: type: uri_folder path: https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data outputs: score: type: uri_file path: <data-store-ID>/paths/batch-jobs/my-unique-pathNota:
Observe cómo la carpeta
pathsforma parte de la ruta de acceso de salida. Este formato indica que el valor siguiente es una ruta de acceso.Ejecute la implementación:
Use el argumento
--filepara especificar los valores de entrada y salida:az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs-and-outputs.yml