Administración de entradas y salidas para componentes y canalizaciones
Las canalizaciones de Azure Machine Learning admiten entradas y salidas tanto a nivel de componente como de canalización. En este artículo se describen las entradas y salidas de canalización y componentes y cómo administrarlas.
En el nivel de componente, las entradas y salidas definen la interfaz de componente. Puede usar la salida de un componente como entrada para otro componente de la misma canalización primaria, lo que permite pasar datos o modelos entre componentes. Esta interconectividad representa el flujo de datos dentro de la canalización.
En el nivel de canalización, puede usar entradas y salidas para enviar trabajos de canalización con distintas entradas o parámetros de datos, como learning_rate. Las entradas y salidas son especialmente útiles cuando se invoca una canalización a través de un punto de conexión REST. Puede asignar valores diferentes a la entrada de canalización o acceder a la salida de diferentes trabajos de canalización. Para obtener más información, vea Creación de trabajos y datos de entrada para puntos de conexión por lotes.
Tipos de entrada y salida
Los siguientes tipos se admiten como entradas y salidas de componentes o canalizaciones:
Tipos de datos. Para obtener más información, vea Tipos de datos.
uri_fileuri_foldermltable
Tipos de modelo.
mlflow_modelcustom_model
Los siguientes tipos primitivos también se admiten solo para las entradas:
- Tipos primitivos
stringnumberintegerboolean
No se admite la salida de tipo primitivo.
Entradas y salidas de ejemplo
Estos ejemplos proceden de la canalización de Regresión de datos de taxis de Nueva York en el repositorio de GitHub Ejemplos de Azure Machine Learning.
- El componente de entrenamiento tiene una
numberentrada denominadatest_split_ratio. - El componente de preparación tiene una salida de tipo
uri_folder. El código fuente del componente lee los archivos CSV de la carpeta de entrada, procesa los archivos y escribe los archivos CSV procesados en la carpeta de salida. - El componente de entrenamiento tiene una salida de tipo
mlflow_model. El código fuente del componente guarda el modelo entrenado mediante el métodomlflow.sklearn.save_model.
Serialización de salida
El uso de los datos o salidas del modelo serializa las salidas y las guarda como archivos en una ubicación de almacenamiento. Los pasos posteriores pueden acceder a los archivos durante la ejecución del trabajo montando esta ubicación de almacenamiento o descargando o cargando los archivos en el sistema de archivos de proceso.
El código fuente del componente debe serializar el objeto de salida, que normalmente se almacena en memoria, en archivos. Por ejemplo, podría serializar un dataframe de pandas en un archivo CSV. Azure Machine Learning no define ningún método estandarizado para la serialización de objetos. Tiene la flexibilidad de elegir los métodos preferidos para serializar objetos en archivos. En el componente de bajada, puede elegir cómo deserializar y leer estos archivos.
Rutas de acceso de entrada y salida del tipo de datos
Para las entradas y salidas del recurso de datos, debe especificar un parámetro de ruta de acceso que apunte a la ubicación de datos. En la tabla siguiente se muestran las ubicaciones de datos admitidas para las entradas y salidas de canalización de Azure Machine Learning, con ejemplos de parámetros path.
| Location | Entrada | Salida | Ejemplo |
|---|---|---|---|
| Ruta de acceso en la máquina local | ✓ | ./home/<username>/data/my_data |
|
| Ruta de acceso en un servidor http/s público | ✓ | https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv |
|
| Ruta de acceso en Azure Storage | * | wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>o abfss://<file_system>@<account_name>.dfs.core.windows.net/<path> |
|
| Ruta de acceso en un almacén de datos de Azure Machine Learning | ✓ | ✓ | azureml://datastores/<data_store_name>/paths/<path> |
| Ruta de acceso a un recurso de datos | ✓ | ✓ | azureml:my_data:<version> |
* No se recomienda usar Azure Storage directamente para la entrada, ya que es posible que necesite una configuración de identidad adicional para leer los datos. Es mejor usar las rutas de acceso del almacén de datos de Azure Machine Learning, que se admiten en varios tipos de trabajo de canalización.
Modos de entrada y salida de tipo de datos
En el caso de las entradas y salidas del tipo de datos, puede elegir entre varios modos de descarga, carga y montaje para definir cómo el destino de proceso accede a los datos. En la tabla siguiente se muestran los modos admitidos para diferentes tipos de entradas y salidas.
| Tipo | upload |
download |
ro_mount |
rw_mount |
direct |
eval_download |
eval_mount |
|---|---|---|---|---|---|---|---|
Entrada de uri_folder |
✓ | ✓ | ✓ | ||||
Entrada de uri_file |
✓ | ✓ | ✓ | ||||
Entrada de mltable |
✓ | ✓ | ✓ | ✓ | ✓ | ||
Salida de uri_folder |
✓ | ✓ | |||||
Salida de uri_file |
✓ | ✓ | |||||
Salida de mltable |
✓ | ✓ | ✓ |
Se recomiendan los modos ro_mount o rw_mount para la mayoría de los casos. Para obtener más información, vea Modos.
Entradas y salidas en gráficos de canalización
En la página de trabajo de canalización de Azure Machine Learning Studio, las entradas y salidas de componente aparecen como círculos pequeños denominados puertos de entrada y salida. Estos puertos representan el flujo de datos en la canalización. La salida del nivel de canalización se muestra en cuadros púrpuras para facilitar la identificación.
En la captura de pantalla siguiente de la gráfico de canalización de Regresión de datos de taxis de Nueva York se muestran muchas entradas y salidas de componentes y canalizaciones.

Al mantener el puntero sobre un puerto de entrada o salida, se muestra el tipo.
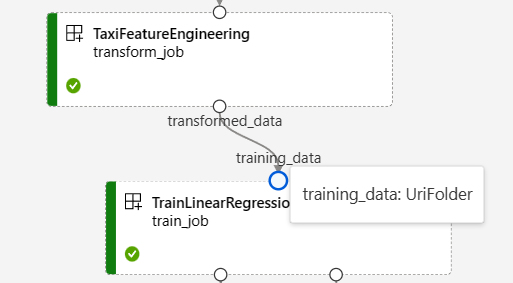
El gráfico de canalización no muestra entradas de tipo primitivo. Estas entradas aparecen en la pestaña Configuración de la canalización Información general del trabajo del panel para las entradas de nivel de canalización o el panel de componentes para las entradas de nivel de componente. Para abrir el panel de componentes, haga doble clic en el componente del gráfico.

Al editar una canalización en el Diseñador de Studio, las entradas y salidas de canalización se encuentran en el panel de Interfaz de canalización, y las entradas y salidas de componentes se encuentran en el panel de componentes.
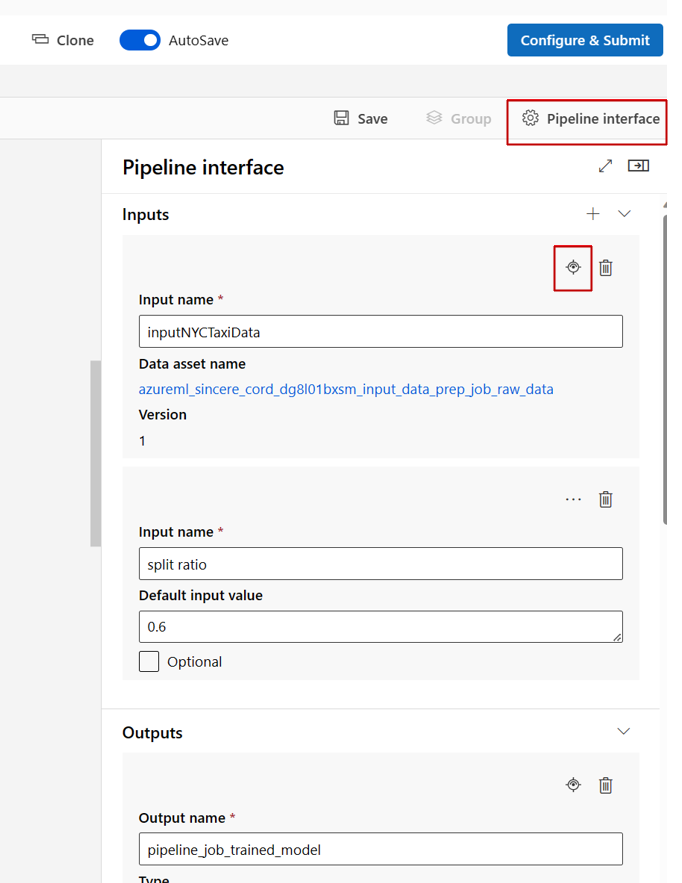
Promoción de entradas y salidas de componentes al nivel de canalización
La promoción de la entrada y salida de un componente al nivel de canalización permite sobrescribir la entrada y salida del componente al enviar un trabajo de canalización. Esta capacidad es especialmente útil para desencadenar canalizaciones mediante puntos de conexión REST.
En los ejemplos siguientes se muestra cómo promover entradas y salidas de nivel de componente a entradas y salidas de nivel de canalización.
La canalización siguiente promueve tres entradas y tres salidas al nivel de canalización. Por ejemplo, pipeline_job_training_max_epocs es la entrada de nivel de canalización porque se declara en la sección inputs en el nivel raíz.
En train_job de la sección jobs, se hace referencia a la entrada denominada max_epocs como ${{parent.inputs.pipeline_job_training_max_epocs}}, lo que significa que la entrada train_job del max_epocs hace referencia a la entrada de nivel de la canalización pipeline_job_training_max_epocs. La salida de canalización se promueve mediante el mismo esquema.
$schema: https://azuremlschemas.azureedge.net/latest/pipelineJob.schema.json
type: pipeline
display_name: 1b_e2e_registered_components
description: E2E dummy train-score-eval pipeline with registered components
inputs:
pipeline_job_training_max_epocs: 20
pipeline_job_training_learning_rate: 1.8
pipeline_job_learning_rate_schedule: 'time-based'
outputs:
pipeline_job_trained_model:
mode: upload
pipeline_job_scored_data:
mode: upload
pipeline_job_evaluation_report:
mode: upload
settings:
default_compute: azureml:cpu-cluster
jobs:
train_job:
type: command
component: azureml:my_train@latest
inputs:
training_data:
type: uri_folder
path: ./data
max_epocs: ${{parent.inputs.pipeline_job_training_max_epocs}}
learning_rate: ${{parent.inputs.pipeline_job_training_learning_rate}}
learning_rate_schedule: ${{parent.inputs.pipeline_job_learning_rate_schedule}}
outputs:
model_output: ${{parent.outputs.pipeline_job_trained_model}}
services:
my_vscode:
type: vs_code
my_jupyter_lab:
type: jupyter_lab
my_tensorboard:
type: tensor_board
log_dir: "outputs/tblogs"
# my_ssh:
# type: tensor_board
# ssh_public_keys: <paste the entire pub key content>
# nodes: all # Use the `nodes` property to pick which node you want to enable interactive services on. If `nodes` are not selected, by default, interactive applications are only enabled on the head node.
score_job:
type: command
component: azureml:my_score@latest
inputs:
model_input: ${{parent.jobs.train_job.outputs.model_output}}
test_data:
type: uri_folder
path: ./data
outputs:
score_output: ${{parent.outputs.pipeline_job_scored_data}}
evaluate_job:
type: command
component: azureml:my_eval@latest
inputs:
scoring_result: ${{parent.jobs.score_job.outputs.score_output}}
outputs:
eval_output: ${{parent.outputs.pipeline_job_evaluation_report}}
Puede encontrar el ejemplo completo en canalización train-score-eval con componentes registrados en el repositorio ejemplos de Azure Machine Learning.
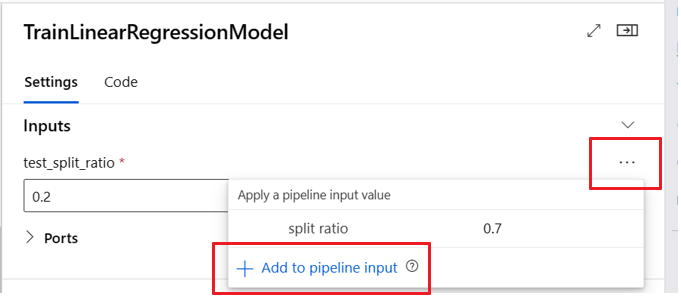
Definición de entradas opcionales
De forma predeterminada, todas las entradas son necesarias y deben tener un valor predeterminado o asignarse un valor cada vez que envíe un trabajo de canalización. Sin embargo, puede definir una entrada opcional.
Nota:
No se admiten salidas opcionales.
Establecer entradas opcionales puede ser útil en dos escenarios:
Si define una entrada de tipo de modelo o datos opcional y no le asigna un valor al enviar el trabajo de canalización, el componente de canalización carece de esa dependencia de datos. Si el puerto de entrada del componente no está vinculado a ningún nodo de componente o de datos o modelo, la canalización invoca el componente directamente en lugar de esperar a una dependencia anterior.
Si establece
continue_on_step_failure = Truepara la canalización, peronode2usa la entrada necesaria denode1,node2no se ejecuta si se produce un error ennode1. Sinode1entrada es opcional,node2se ejecuta incluso si se produce un error ennode1. En el gráfico siguiente se muestra este escenario.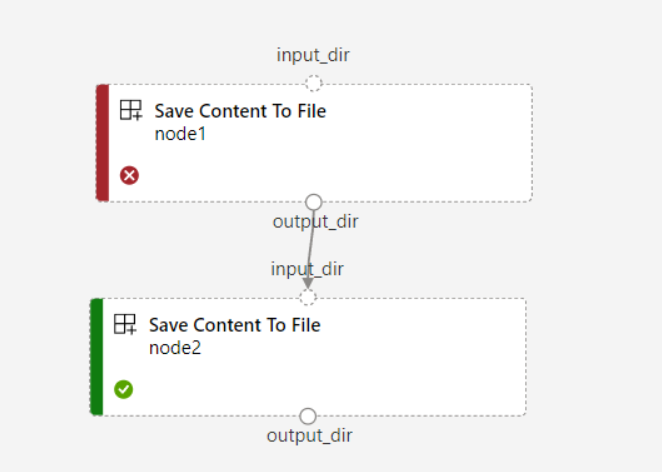
En el ejemplo de código siguiente se muestra cómo definir la entrada opcional. Cuando la entrada se establece como optional = true, debe usar $[[]] para adoptar las entradas de la línea de comandos, como en las líneas resaltadas del ejemplo.
$schema: https://azuremlschemas.azureedge.net/latest/commandComponent.schema.json
name: train_data_component_cli
display_name: train_data
description: A example train component
tags:
author: azureml-sdk-team
type: command
inputs:
training_data:
type: uri_folder
max_epocs:
type: integer
optional: true
learning_rate:
type: number
default: 0.01
optional: true
learning_rate_schedule:
type: string
default: time-based
optional: true
outputs:
model_output:
type: uri_folder
code: ./train_src
environment: azureml://registries/azureml/environments/sklearn-1.5/labels/latest
command: >-
python train.py
--training_data ${{inputs.training_data}}
$[[--max_epocs ${{inputs.max_epocs}}]]
$[[--learning_rate ${{inputs.learning_rate}}]]
$[[--learning_rate_schedule ${{inputs.learning_rate_schedule}}]]
--model_output ${{outputs.model_output}}

Personalización de rutas de acceso de salida
De forma predeterminada, la salida del componente se almacena en el {default_datastore} establecido para la canalización, azureml://datastores/${{default_datastore}}/paths/${{name}}/${{output_name}}. Si no se establece, el valor predeterminado es el almacenamiento de blobs del área de trabajo.
El trabajo {name} se resuelve en tiempo de ejecución del trabajo y {output_name} es el nombre que definió en el componente YAML. Puede personalizar dónde almacenar la salida definiendo una ruta de acceso de salida.
El archivo pipeline.yml en ejemplo de canalización train-score-eval con componentes registrados define una canalización que tiene tres salidas de nivel de canalización. Puede usar el siguiente comando para establecer rutas de acceso de salida personalizadas para la salida pipeline_job_trained_model.
# define the custom output path using datastore uri
# add relative path to your blob container after "azureml://datastores/<datastore_name>/paths"
output_path="azureml://datastores/{datastore_name}/paths/{relative_path_of_container}"
# create job and define path using --outputs.<outputname>
az ml job create -f ./pipeline.yml --set outputs.pipeline_job_trained_model.path=$output_path

Descargas de salidas
Puede descargar salidas en el nivel de canalización o componente.
Descarga de salidas de nivel de canalización
Puede descargar todas las salidas de un trabajo o descargar una salida específica.
# Download all the outputs of the job
az ml job download --all -n <JOB_NAME> -g <RESOURCE_GROUP_NAME> -w <WORKSPACE_NAME> --subscription <SUBSCRIPTION_ID>
# Download a specific output
az ml job download --output-name <OUTPUT_PORT_NAME> -n <JOB_NAME> -g <RESOURCE_GROUP_NAME> -w <WORKSPACE_NAME> --subscription <SUBSCRIPTION_ID>

Descargar salidas de componentes
Para descargar las salidas de un componente secundario, enumere primero todos los trabajos secundarios de un trabajo de canalización y, a continuación, use código similar para descargar las salidas.
# List all child jobs in the job and print job details in table format
az ml job list --parent-job-name <JOB_NAME> -g <RESOURCE_GROUP_NAME> -w <WORKSPACE_NAME> --subscription <SUBSCRIPTION_ID> -o table
# Select the desired child job name to download output
az ml job download --all -n <JOB_NAME> -g <RESOURCE_GROUP_NAME> -w <WORKSPACE_NAME> --subscription <SUBSCRIPTION_ID>
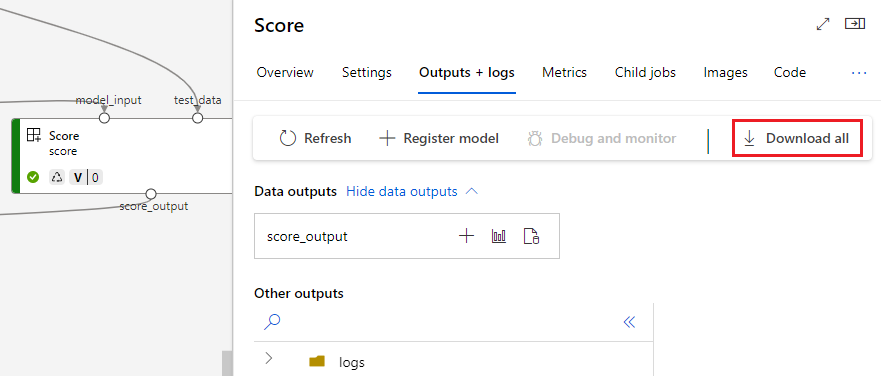
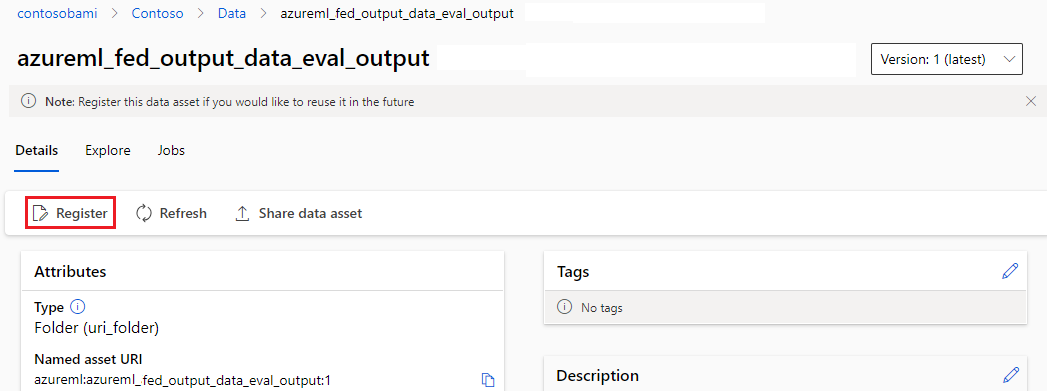
Registrar la salida como un recurso con nombre
Puede registrar la salida de un componente o canalización como un recurso con nombre asignando un name y version a la salida. El recurso registrado se puede mostrar en el área de trabajo a través de la interfaz de usuario de Studio, la CLI o el SDK y se puede hacer referencia a este en trabajos futuros del área de trabajo.
Registro de la salida de nivel de canalización
display_name: register_pipeline_output
type: pipeline
jobs:
node:
type: command
inputs:
component_in_path:
type: uri_file
path: https://dprepdata.blob.core.windows.net/demo/Titanic.csv
component: ../components/helloworld_component.yml
outputs:
component_out_path: ${{parent.outputs.component_out_path}}
outputs:
component_out_path:
type: mltable
name: pipeline_output # Define name and version to register pipeline output
version: '1'
settings:
default_compute: azureml:cpu-cluster
Registro de la salida del componente
display_name: register_node_output
type: pipeline
jobs:
node:
type: command
component: ../components/helloworld_component.yml
inputs:
component_in_path:
type: uri_file
path: 'https://dprepdata.blob.core.windows.net/demo/Titanic.csv'
outputs:
component_out_path:
type: uri_folder
name: 'node_output' # Define name and version to register a child job's output
version: '1'
settings:
default_compute: azureml:cpu-cluster