Acceso a datos del almacenamiento en la nube de Azure durante el desarrollo interactivo
SE APLICA A:  SDK de Python azure-ai-ml v2 (actual)
SDK de Python azure-ai-ml v2 (actual)
Un proyecto de aprendizaje automático suele comenzar con el análisis exploratorio de datos (AED), el preprocesamiento de datos (limpieza e ingeniería de características) e incluye la construcción de prototipos de modelos de ML para validar hipótesis. Esta fase de creación de prototipos del proyecto es muy interactiva por naturaleza y se presta al desarrollo en un cuaderno de Jupyter Notebook o un IDE con una consola interactiva de Python. En este artículo, aprenderá a:
- Acceda desde un URI de almacén de datos de Azure Machine Learning como si fuera un sistema de archivos.
- Materialice los datos en Pandas mediante la biblioteca de Python
mltable. - Materialice los recursos de datos de Azure Machine Learning en Pandas mediante la biblioteca de Python
mltable. - Materializar los datos mediante una descarga explícita con la utilidad
azcopy.
Prerrequisitos
- Un área de trabajo de Azure Machine Learning. Para más información, consulte Administración de áreas de trabajo de Azure Machine Learning en el portal o con el SDK de Python (v2).
- Un almacén de datos de Azure Machine Learning. Para más información, consulte Creación de almacenes de datos.
Sugerencia
En las instrucciones de este artículo se describe el acceso a los datos durante el desarrollo interactivo. Se aplica a cualquier host que pueda ejecutar una sesión de Python. Esto puede incluir su máquina local, una VM en la nube, un Codespace de GitHub, etc. Recomendamos el uso de una instancia de computación de Azure Machine Learning: una estación de trabajo en la nube totalmente gestionada y preconfigurada. Para más información, consulte Creación de una instancia de proceso de Azure Machine Learning.
Importante
Asegúrese de que tiene instaladas las bibliotecas azure-fsspec, mltable y azure-ai-ml de Python más recientes en el entorno de Python:
pip install -U azureml-fsspec==1.3.1 mltable azure-ai-ml
La versión más reciente del paquete azure-fsspec puede cambiar con el tiempo. Para obtener más información sobre el paquete de azure-fsspec, visite este recurso.
Acceso a datos desde un identificador URI de almacén de datos, como un sistema de archivos
Un almacén de datos de Azure Machine Learning es una referencia a una cuenta de almacenamiento existente en Azure. Las ventajas de la creación y utilización de almacenes de datos incluyen:
- Una API común y fácil de usar para interactuar con diferentes tipos de almacenamiento (Blob/Archivos/ADLS).
- Fácil descubrimiento de almacenes de datos útiles en operaciones de equipo.
- Soporte de acceso basado tanto en credenciales (por ejemplo, token SAS) como en identidades (uso de Microsoft Entra ID o identidad administrada), para acceder a los datos.
- En el caso del acceso basado en credenciales, la información de conexión se protege para anular la exposición de claves en scripts.
- Examinar los datos y copiar y pegar los identificadores URI de almacén de datos en la interfaz de usuario de Estudio de ML.
Un identificador URI de almacén de datos es un identificador uniforme de recursos, que es una referencia a una ubicación de almacenamiento (ruta de acceso) en la cuenta de almacenamiento de Azure. Un URI de almacén de datos tiene este formato:
# Azure Machine Learning workspace details:
subscription = '<subscription_id>'
resource_group = '<resource_group>'
workspace = '<workspace>'
datastore_name = '<datastore>'
path_on_datastore = '<path>'
# long-form Datastore uri format:
uri = f'azureml://subscriptions/{subscription}/resourcegroups/{resource_group}/workspaces/{workspace}/datastores/{datastore_name}/paths/{path_on_datastore}'.
Estos identificadores URI de almacén de datos son una implementación conocida de la especificación de sistema de archivos (fsspec): una interfaz de tipo Python unificada para sistemas de archivos locales, remotos e insertados y almacenamiento de bytes. Primero, use pip para instalar el paquete azureml-fsspec y su paquete azureml-dataprep de dependencia. A continuación, puede utilizar la implementación fsspec Azure Machine Learning Datastore.
La implementación del almacén de datos de Azure Machine Learning fsspec gestiona automáticamente el paso de credenciales/identidades que utiliza el almacén de datos de Azure Machine Learning. Puede evitar la exposición de claves de cuenta en los scripts y procedimientos de inicio de sesión adicionales en una instancia de proceso.
Por ejemplo, puede usar directamente los URI de almacén de datos en Pandas. En este ejemplo se muestra cómo leer un archivo CSV:
import pandas as pd
df = pd.read_csv("azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>/paths/<folder>/<filename>.csv")
df.head()
Sugerencia
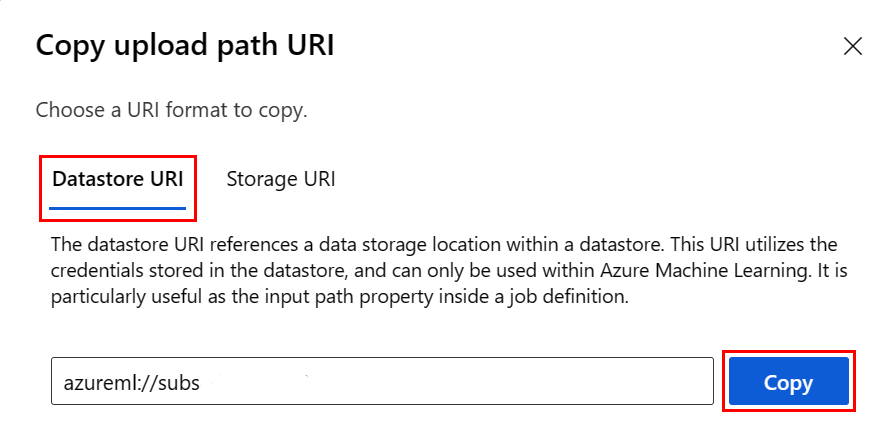
Para evitar recordar el formato del URI del almacén de datos, puede copiar y pegar el URI del almacén de datos desde la interfaz de usuario de Studio con estos pasos:
- En el menú izquierdo, seleccione Data y, luego, la pestaña Datastores.
- Seleccione el nombre del almacén de datos y, luego, Browse.
- Busque el archivo o la carpeta que quiere leer en Pandas y seleccione los puntos suspensivos (...) situados a su lado. Seleccione en el menú Copiar URI. Puede seleccionar el identificador URI del almacén de datos para copiarlo en el cuaderno o script.
También puede crear una instancia de un sistema de archivos de Azure Machine Learning y realizar comandos similares al sistema de archivos, como ls, glob, exists y open.
- El
ls()método enumera los archivos de un directorio específico. Puede usar ls(), ls(.), ls (<<folder_level_1>/<folder_level_2>) para enumerar archivos. Se admiten "." y ".".", en rutas de acceso relativas. - El método
glob()admite el uso de comodines "*" y "**". - El método
exists()devuelve un valor booleano que indica si existe un archivo especificado en el directorio raíz actual. - El método
open()devuelve un objeto similar a un archivo, que puede pasarse a cualquier otra biblioteca que espere trabajar con archivos python. El código también puede usar este objeto, como si fuera un objeto de archivo de Python normal. Estos objetos similares a archivos respetan el uso de contextoswith, como se muestra en este ejemplo:
from azureml.fsspec import AzureMachineLearningFileSystem
# instantiate file system using following URI
fs = AzureMachineLearningFileSystem('azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastore*s*/datastorename')
fs.ls() # list folders/files in datastore 'datastorename'
# output example:
# folder1
# folder2
# file3.csv
# use an open context
with fs.open('./folder1/file1.csv') as f:
# do some process
process_file(f)
Carga de archivos mediante AzureMachineLearningFileSystem
from azureml.fsspec import AzureMachineLearningFileSystem
# instantiate file system using following URI
fs = AzureMachineLearningFileSystem('azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastorename>/paths/')
# you can specify recursive as False to upload a file
fs.upload(lpath='data/upload_files/crime-spring.csv', rpath='data/fsspec', recursive=False, **{'overwrite': 'MERGE_WITH_OVERWRITE'})
# you need to specify recursive as True to upload a folder
fs.upload(lpath='data/upload_folder/', rpath='data/fsspec_folder', recursive=True, **{'overwrite': 'MERGE_WITH_OVERWRITE'})
lpath es la ruta de acceso local y rpath es la ruta de acceso remota.
Si las carpetas que especifique en rpath aún no existen, creamos las carpetas automáticamente.
Se admiten tres modos de sobrescritura:
- APPEND: si existe un archivo con el mismo nombre en la ruta de destino, APPEND mantiene el archivo original.
- FAIL_ON_FILE_CONFLICT: si existe un archivo con el mismo nombre en la ruta de destino, FAIL_ON_FILE_CONFLICT lanza un error.
- MERGE_WITH_OVERWRITE: si existe un archivo con el mismo nombre en la ruta de acceso de destino, MERGE_WITH_OVERWRITE sobrescribe ese archivo existente con el nuevo archivo.
Descarga de archivos mediante AzureMachineLearningFileSystem
# you can specify recursive as False to download a file
# downloading overwrite option is determined by local system, and it is MERGE_WITH_OVERWRITE
fs.download(rpath='data/fsspec/crime-spring.csv', lpath='data/download_files/, recursive=False)
# you need to specify recursive as True to download a folder
fs.download(rpath='data/fsspec_folder', lpath='data/download_folder/', recursive=True)
Ejemplos
Estos ejemplos muestran el uso de la especificación del sistema de archivos en escenarios comunes.
Lectura de un único archivo CSV en Pandas
Puede leer un único archivo CSV en Pandas como se muestra:
import pandas as pd
df = pd.read_csv("azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>/paths/<folder>/<filename>.csv")
Lectura de una carpeta de archivos CSV en Pandas
El método read_csv() de Pandas no admite la lectura de una carpeta de archivos .csv. Para gestionar esto, agregue las rutas CSV y concaténelas en un marco de datos con el método Pandas concat(). El siguiente ejemplo de código muestra cómo lograr esta concatenación con el sistema de archivos de Azure Machine Learning:
import pandas as pd
from azureml.fsspec import AzureMachineLearningFileSystem
# define the URI - update <> placeholders
uri = 'azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>'
# create the filesystem
fs = AzureMachineLearningFileSystem(uri)
# append csv files in folder to a list
dflist = []
for path in fs.glob('/<folder>/*.csv'):
with fs.open(path) as f:
dflist.append(pd.read_csv(f))
# concatenate data frames
df = pd.concat(dflist)
df.head()
Lectura de archivos .csv en Dask
En este ejemplo se muestra cómo leer un archivo CSV en una trama de datos dask:
import dask.dd as dd
df = dd.read_csv("azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>/paths/<folder>/<filename>.csv")
df.head()
Lectura de una carpeta de archivos Parquet en Pandas
Como parte de un proceso ETL, los archivos parquet suelen escribirse en una carpeta, que luego puede emitir archivos relevantes para el ETL, como el progreso, los commits, etc. Este ejemplo muestra archivos creados a partir de un proceso ETL (archivos que comienzan por _) que luego producen un archivo parquet de datos.
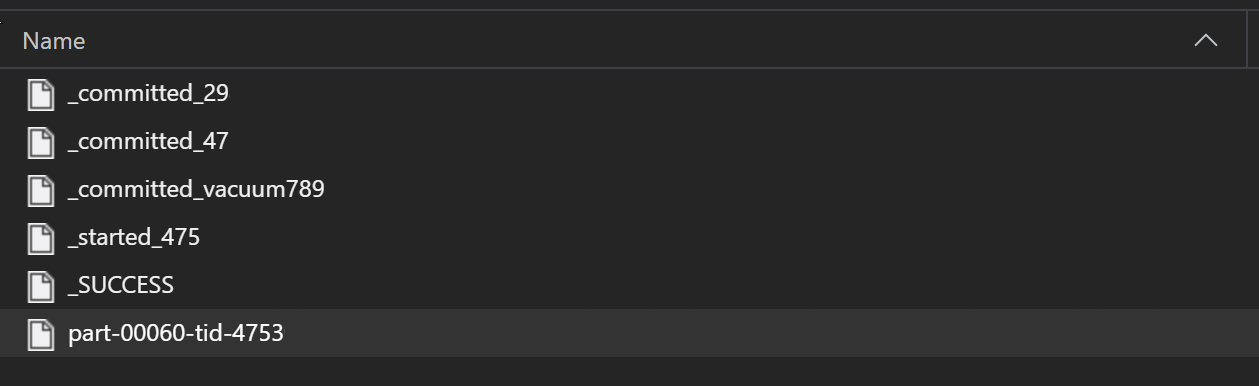
En estos casos, solo leerá los archivos parquet de la carpeta e ignorará los archivos del proceso ETL. Este ejemplo de código muestra cómo los patrones glob pueden leer sólo los archivos parquet de una carpeta:
import pandas as pd
from azureml.fsspec import AzureMachineLearningFileSystem
# define the URI - update <> placeholders
uri = 'azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>'
# create the filesystem
fs = AzureMachineLearningFileSystem(uri)
# append parquet files in folder to a list
dflist = []
for path in fs.glob('/<folder>/*.parquet'):
with fs.open(path) as f:
dflist.append(pd.read_parquet(f))
# concatenate data frames
df = pd.concat(dflist)
df.head()
Acceso a datos desde el sistema de archivos de Azure Databricks (dbfs)
La especificación Filesystem (fsspec) tiene una serie de implementaciones conocidas, incluido el Databricks Filesystem (dbfs).
Para acceder a los datos del recurso dbfs, necesita lo siguiente:
- Nombre de la instancia, que tiene el formulario
adb-<some-number>.<two digits>.azuredatabricks.net. Puede encontrar este valor en la URL de su área de trabajo de Azure Databricks. - Token de acceso personal (PAT), para más información sobre cómo crear un PAT, consulte Autenticación mediante tokens de acceso personal de Azure Databricks.
Con estos valores, debe crear una variable de entorno en su instancia de cálculo para el token PAT:
export ADB_PAT=<pat_token>
A continuación, puede acceder a los datos de Pandas, como se muestra en este ejemplo:
import os
import pandas as pd
pat = os.getenv(ADB_PAT)
path_on_dbfs = '<absolute_path_on_dbfs>' # e.g. /folder/subfolder/file.csv
storage_options = {
'instance':'adb-<some-number>.<two digits>.azuredatabricks.net',
'token': pat
}
df = pd.read_csv(f'dbfs://{path_on_dbfs}', storage_options=storage_options)
Lectura de imágenes con pillow
from PIL import Image
from azureml.fsspec import AzureMachineLearningFileSystem
# define the URI - update <> placeholders
uri = 'azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>'
# create the filesystem
fs = AzureMachineLearningFileSystem(uri)
with fs.open('/<folder>/<image.jpeg>') as f:
img = Image.open(f)
img.show()
Ejemplo de conjunto de datos personalizado de PyTorch
En este ejemplo, creará un conjunto de datos personalizado de PyTorch para procesar las imágenes. Se supone que existe un archivo de anotaciones (en formato CSV), con esta estructura general:
image_path, label
0/image0.png, label0
0/image1.png, label0
1/image2.png, label1
1/image3.png, label1
2/image4.png, label2
2/image5.png, label2
Las subcarpetas almacenan estas imágenes, según sus etiquetas:
/
└── 📁images
├── 📁0
│ ├── 📷image0.png
│ └── 📷image1.png
├── 📁1
│ ├── 📷image2.png
│ └── 📷image3.png
└── 📁2
├── 📷image4.png
└── 📷image5.png
Una clase de conjunto de datos de PyTorch personalizada debe implementar tres funciones: __init__, __len__y __getitem__, como se muestra aquí:
import os
import pandas as pd
from PIL import Image
from torch.utils.data import Dataset
class CustomImageDataset(Dataset):
def __init__(self, filesystem, annotations_file, img_dir, transform=None, target_transform=None):
self.fs = filesystem
f = filesystem.open(annotations_file)
self.img_labels = pd.read_csv(f)
f.close()
self.img_dir = img_dir
self.transform = transform
self.target_transform = target_transform
def __len__(self):
return len(self.img_labels)
def __getitem__(self, idx):
img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0])
f = self.fs.open(img_path)
image = Image.open(f)
f.close()
label = self.img_labels.iloc[idx, 1]
if self.transform:
image = self.transform(image)
if self.target_transform:
label = self.target_transform(label)
return image, label
A continuación, puede crear una instancia del conjunto de datos como se muestra aquí:
from azureml.fsspec import AzureMachineLearningFileSystem
from torch.utils.data import DataLoader
# define the URI - update <> placeholders
uri = 'azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>'
# create the filesystem
fs = AzureMachineLearningFileSystem(uri)
# create the dataset
training_data = CustomImageDataset(
filesystem=fs,
annotations_file='/annotations.csv',
img_dir='/<path_to_images>/'
)
# Prepare your data for training with DataLoaders
train_dataloader = DataLoader(training_data, batch_size=64, shuffle=True)
Materialización de los datos en Pandas mediante la biblioteca mltable
La biblioteca mltable también puede ayudar a acceder a los datos en el almacenamiento en la nube. La lectura de datos en Pandas con mltable tiene este formato general:
import mltable
# define a path or folder or pattern
path = {
'file': '<supported_path>'
# alternatives
# 'folder': '<supported_path>'
# 'pattern': '<supported_path>'
}
# create an mltable from paths
tbl = mltable.from_delimited_files(paths=[path])
# alternatives
# tbl = mltable.from_parquet_files(paths=[path])
# tbl = mltable.from_json_lines_files(paths=[path])
# tbl = mltable.from_delta_lake(paths=[path])
# materialize to Pandas
df = tbl.to_pandas_dataframe()
df.head()
Rutas de acceso admitidas
La biblioteca mltable admite la lectura de datos tabulares desde diferentes tipos de ruta de acceso:
| Location | Ejemplos |
|---|---|
| Ruta de acceso en la máquina local | ./home/username/data/my_data |
| Ruta de acceso en un servidor http(s) público | https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv |
| Ruta de acceso en Azure Storage | wasbs://<container_name>@<account_name>.blob.core.windows.net/<path> abfss://<file_system>@<account_name>.dfs.core.windows.net/<path> |
| Un almacén de datos de Azure Machine Learning de forma larga | azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<wsname>/datastores/<name>/paths/<path> |
Nota:
mltable realiza el acceso directo de credenciales de usuario para las rutas de acceso de los almacenes de datos de Azure Storage y Azure Machine Learning. Si no tiene permisos para los datos del almacenamiento subyacente, no podrá acceder a los datos.
Archivos, carpetas y patrones globales
mltable admite la lectura desde:
- archivos, por ejemplo:
abfss://<file_system>@<account_name>.dfs.core.windows.net/my-csv.csv - carpetas, por ejemplo
abfss://<file_system>@<account_name>.dfs.core.windows.net/my-folder/ - patrones globales, por ejemplo
abfss://<file_system>@<account_name>.dfs.core.windows.net/my-folder/*.csv - O bien, una combinación de archivos, carpetas y patrones globales
La flexibilidad de mltable permite materializar los datos en una sola trama de datos a partir de una combinación de almacenamiento local o en la nube y combinaciones de archivos, carpetas y patrones globales. Por ejemplo:
path1 = {
'file': 'abfss://filesystem@account1.dfs.core.windows.net/my-csv.csv'
}
path2 = {
'folder': './home/username/data/my_data'
}
path3 = {
'pattern': 'abfss://filesystem@account2.dfs.core.windows.net/folder/*.csv'
}
tbl = mltable.from_delimited_files(paths=[path1, path2, path3])
Formatos de archivos admitidos
mltable admite los siguientes formatos de archivo:
- Texto delimitado (por ejemplo: archivos .csv):
mltable.from_delimited_files(paths=[path]) - Parquet:
mltable.from_parquet_files(paths=[path]) - Delta:
mltable.from_delta_lake(paths=[path]) - Formato de líneas JSON:
mltable.from_json_lines_files(paths=[path])
Ejemplos
Lectura de un archivo .csv
Actualice los marcadores de posición (<>) en el fragmento de código con su información específica:
import mltable
path = {
'file': 'abfss://<filesystem>@<account>.dfs.core.windows.net/<folder>/<file_name>.csv'
}
tbl = mltable.from_delimited_files(paths=[path])
df = tbl.to_pandas_dataframe()
df.head()
Lectura de los archivos Parquet de una carpeta
En el código de ejemplo siguiente, se muestra cómo puede usar mltable patrones globales, como los caracteres comodín, para tener la seguridad de que solo se lean los archivos Parquet.
Actualice los marcadores de posición (<>) en el fragmento de código con su información específica:
import mltable
path = {
'pattern': 'abfss://<filesystem>@<account>.dfs.core.windows.net/<folder>/*.parquet'
}
tbl = mltable.from_parquet_files(paths=[path])
df = tbl.to_pandas_dataframe()
df.head()
Lectura de recursos de datos
Esta sección muestra cómo acceder a sus activos de datos de Azure Machine Learning en Pandas.
Recurso de tabla
Si anteriormente ha creado un recurso de tabla en Azure Machine Learning (un elemento mltable o un elemento TabularDataset de la versión V1), puede cargarlo en Pandas mediante:
import mltable
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
data_asset = ml_client.data.get(name="<name_of_asset>", version="<version>")
tbl = mltable.load(f'azureml:/{data_asset.id}')
df = tbl.to_pandas_dataframe()
df.head()
Recurso de archivo
Si registró un recurso de archivo (un archivo CSV, por ejemplo), puede leer ese recurso en una trama de datos de Pandas con este código:
import mltable
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
data_asset = ml_client.data.get(name="<name_of_asset>", version="<version>")
path = {
'file': data_asset.path
}
tbl = mltable.from_delimited_files(paths=[path])
df = tbl.to_pandas_dataframe()
df.head()
Recurso de carpeta
Si registró un recurso de carpeta (uri_folder o un V1 FileDataset), por ejemplo, una carpeta que contiene un archivo CSV, puede leer ese recurso en una trama de datos de Pandas con este código:
import mltable
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
data_asset = ml_client.data.get(name="<name_of_asset>", version="<version>")
path = {
'folder': data_asset.path
}
tbl = mltable.from_delimited_files(paths=[path])
df = tbl.to_pandas_dataframe()
df.head()
Nota sobre la lectura y el procesamiento de grandes volúmenes de datos con Pandas
Sugerencia
Pandas no está diseñado para controlar grandes conjuntos de datos. Pandas solo puede procesar los datos que pueden caber en la memoria de la instancia de proceso.
En el caso de grandes conjuntos de datos, se recomienda usar Spark administrado por Azure Machine Learning. Esto proporciona la API de Pandas de PySpark.
Es posible que quiera iterar rápidamente en un subconjunto más pequeño de un conjunto de datos grande antes de escalar verticalmente a un trabajo asincrónico remoto. mltable proporciona funcionalidad integrada para obtener muestras de datos de gran tamaño mediante el método take_random_sample:
import mltable
path = {
'file': 'https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv'
}
tbl = mltable.from_delimited_files(paths=[path])
# take a random 30% sample of the data
tbl = tbl.take_random_sample(probability=.3)
df = tbl.to_pandas_dataframe()
df.head()
También puede tomar subconjuntos de datos grandes con estas operaciones:
Descarga de datos mediante la utilidad azcopy
Utilice la utilidad azcopy para descargar los datos en el SSD local de su host (máquina local, VM en la nube, Instancia de proceso de Azure Machine Learning, etc.), en el sistema de archivos local. La utilidad azcopy, que está preinstalada en una instancia de proceso de Azure Machine Learning, controla la descarga de datos. Si no usa una instancia de proceso de Azure Machine Learning ni una Data Science Virtual Machine (DSVM), es posible que tenga que instalar azcopy. Para más información, consulte azcopy.
Precaución
No se recomiendan descargas de datos en la /home/azureuser/cloudfiles/code ubicación de una instancia de proceso. Esto está diseñado para almacenar artefactos de cuadernos y código, no para datos. La lectura de datos desde esta ubicación incurrirá en una sobrecarga de rendimiento significativa en el entrenamiento. En su lugar, se recomienda almacenar los datos en home/azureuser, que es la unidad SSD local del nodo de proceso.
Abra un terminal y cree un directorio, por ejemplo:
mkdir /home/azureuser/data
Inicie sesión en azcopy mediante:
azcopy login
A continuación, puede copiar los datos mediante un identificador URI de almacenamiento.
SOURCE=https://<account_name>.blob.core.windows.net/<container>/<path>
DEST=/home/azureuser/data
azcopy cp $SOURCE $DEST