Uso de las características extendidas del Servidor de historial de Apache Spark para depurar y diagnosticar aplicaciones Spark
En este artículo se muestra cómo usar las características extendidas del Servidor de historial de Apache Spark para depurar y diagnosticar las aplicaciones Spark en ejecución y completadas. La extensión incluye la pestaña Data (Datos), la pestaña Graph (Gráfico) y la pestaña Diagnosis (Diagnóstico). En la pestaña Data (Datos), puede comprobar los datos de entrada y salida del trabajo de Spark. En la pestaña Graph (Gráfico), puede comprobar el flujo de datos y reproducir el gráfico del trabajo. En la pestaña Diagnóstico, puede consultar las características Asimetría de datos, Desfase horario y Análisis de uso del ejecutor.
Obtención de acceso al Servidor de historial de Spark
El Servidor de historial de Spark es la interfaz de usuario web para aplicaciones Spark completadas y en ejecución. Puede abrirla desde Azure Portal o desde una dirección URL.
Apertura de la interfaz de usuario web del Servidor de historial de Spark desde Azure Portal
En Azure Portal, abra el clúster de Spark. Para obtener más información, consulte Enumeración y visualización de clústeres.
En Paneles de clúster, seleccione Servidor de historial de Spark. Cuando se le pida, escriba las credenciales de administrador del clúster Spark.
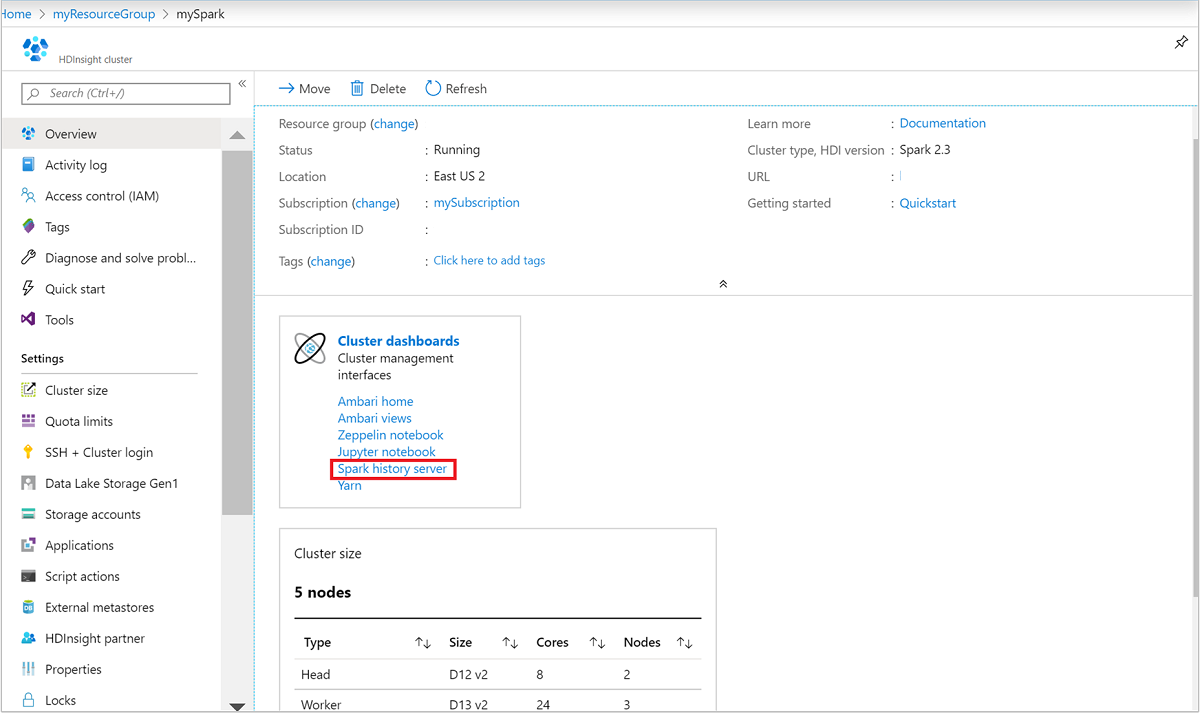 Azure Portal." border="true":::
Azure Portal." border="true":::
Apertura de la interfaz de usuario web del Servidor de historial de Spark mediante dirección URL
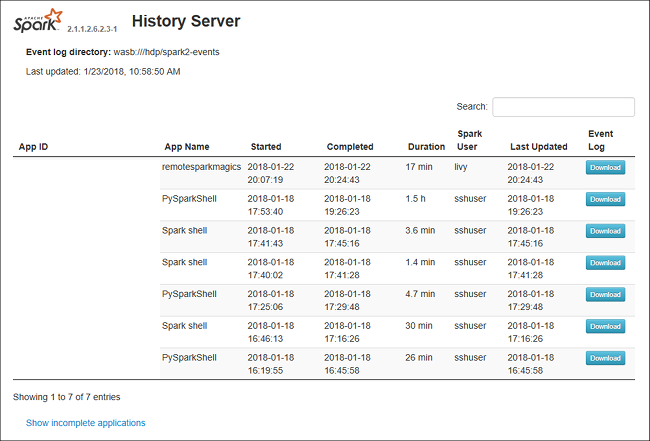
Abra el Servidor de historial de Spark; para ello, vaya a https://CLUSTERNAME.azurehdinsight.net/sparkhistory, donde CLUSTERNAME es el nombre del clúster de Spark.
La interfaz de usuario web del Servidor de historial de Spark puede tener un aspecto similar al de esta imagen:
Uso de la pestaña Datos del Servidor de historial de Spark
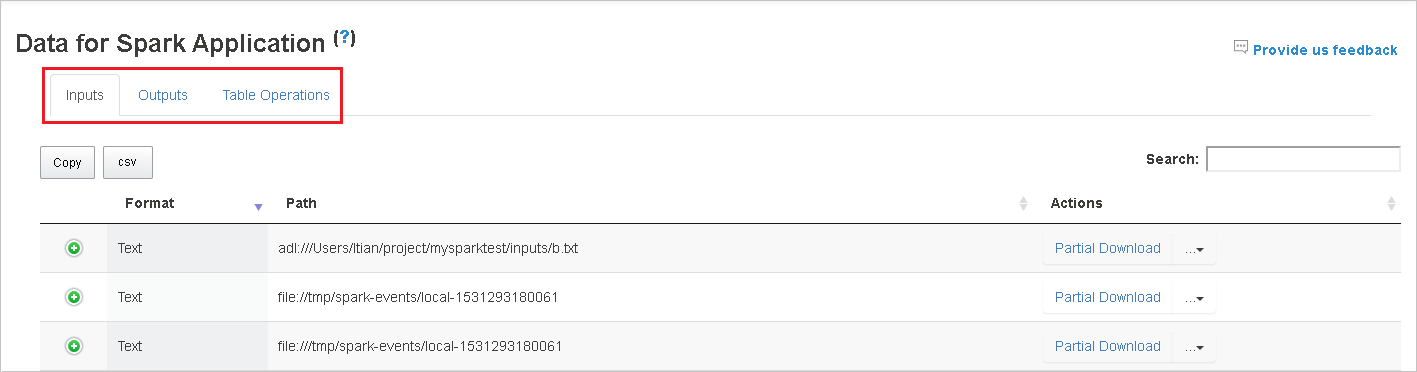
Seleccione el identificador del trabajo y, a continuación, seleccione Data (Datos) en el menú de herramientas para obtener la vista de datos.
Revise por separado las pestañas Inputs (Entradas), Outputs (Salidas) y Table Operations (Operaciones de tablas).
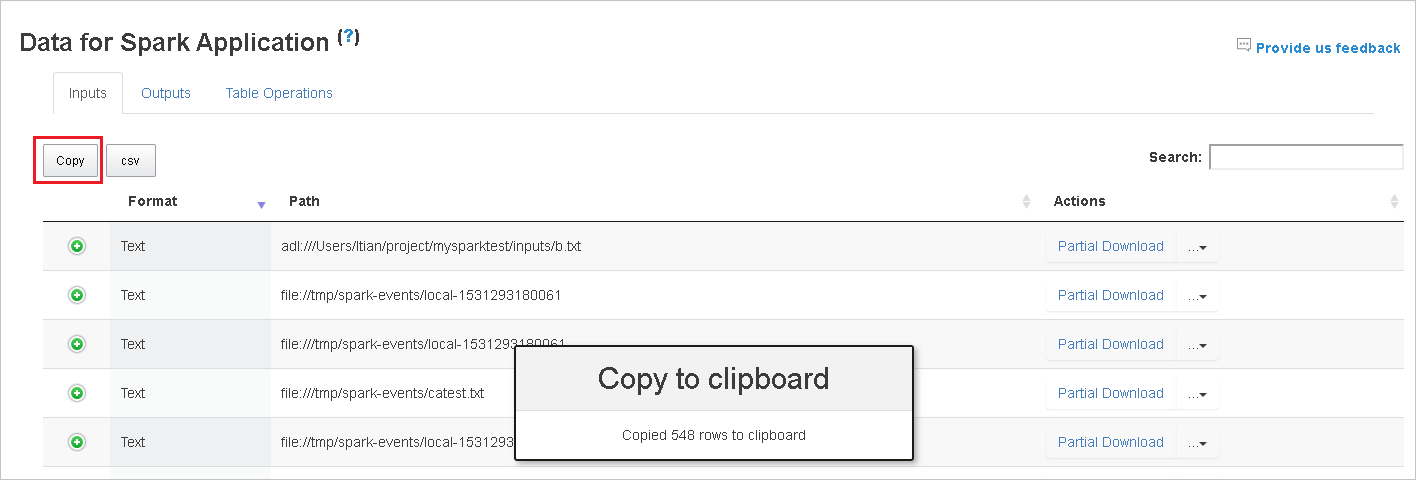
Seleccione el botón Copy (Copiar) para copiar todas las filas.
Guarde todos los datos como archivo .CSV; para ello, seleccione el botón CSV.
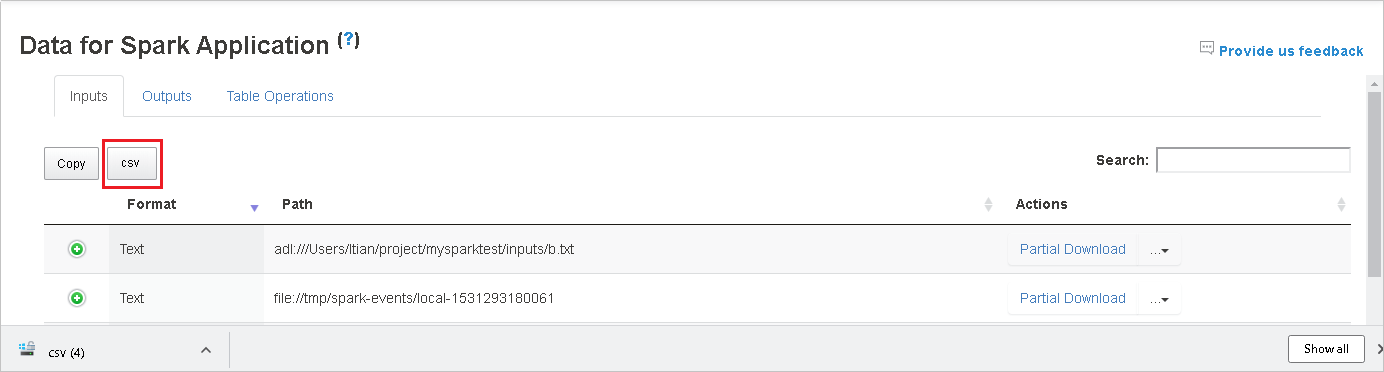
Busque los datos escribiendo palabras clave en el campo Search (Buscar). Los resultados de la búsqueda se mostrarán inmediatamente.
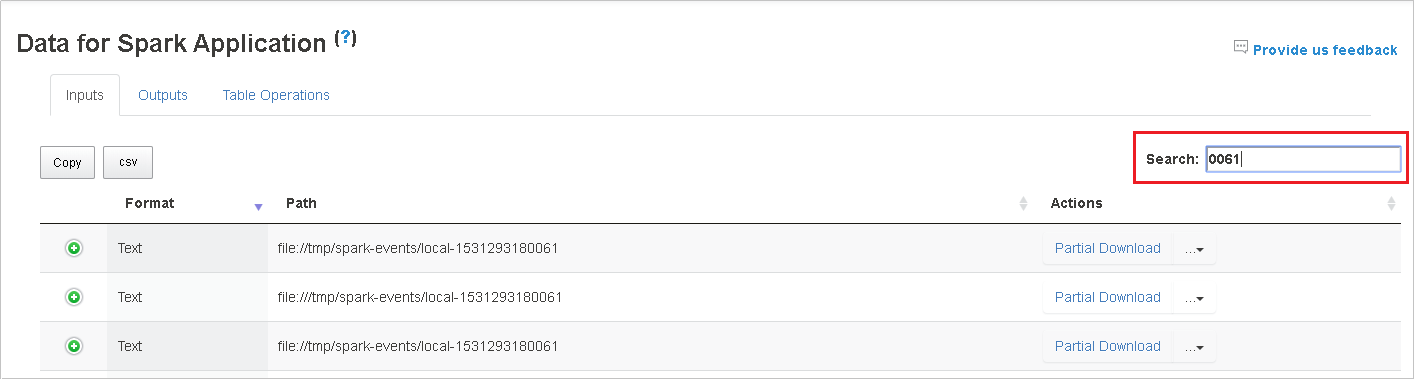
Seleccione el encabezado de columna para ordenar la tabla. Seleccione el signo más para expandir una fila y mostrar más detalles. Seleccione el signo menos para contraer una fila.
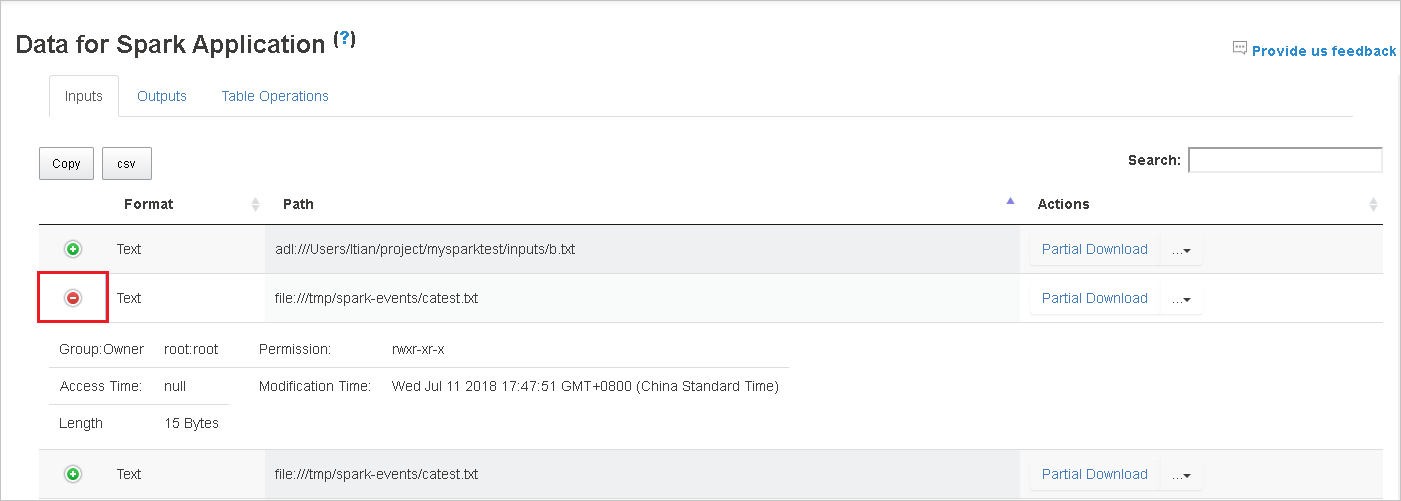
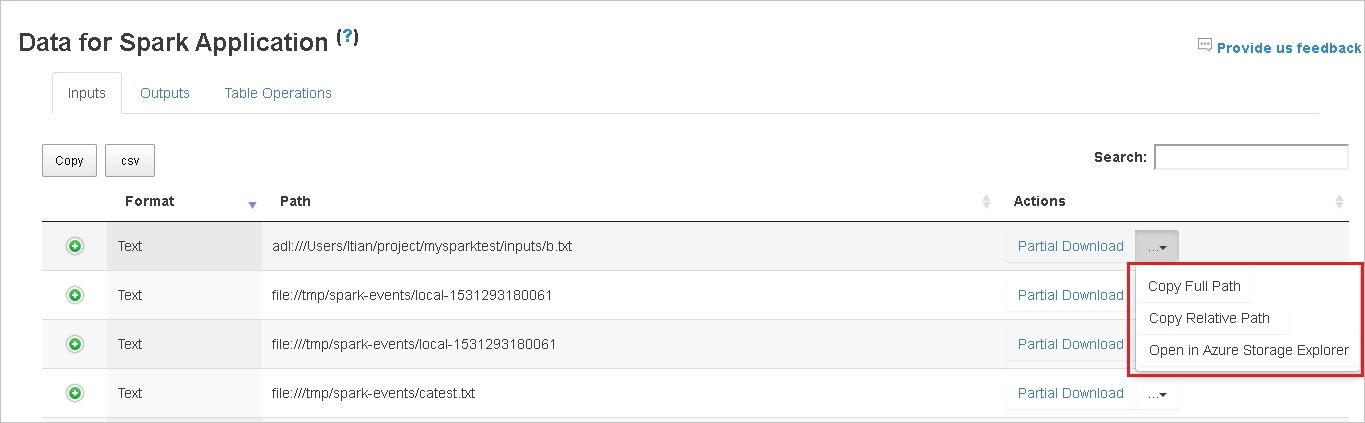
Descargue un solo archivo; para ello, seleccione el botón Partial Download (Descarga parcial) de la derecha. El archivo seleccionado se descargará localmente. Si el archivo ya no existe, se abrirá una nueva pestaña para mostrar los mensajes de error.
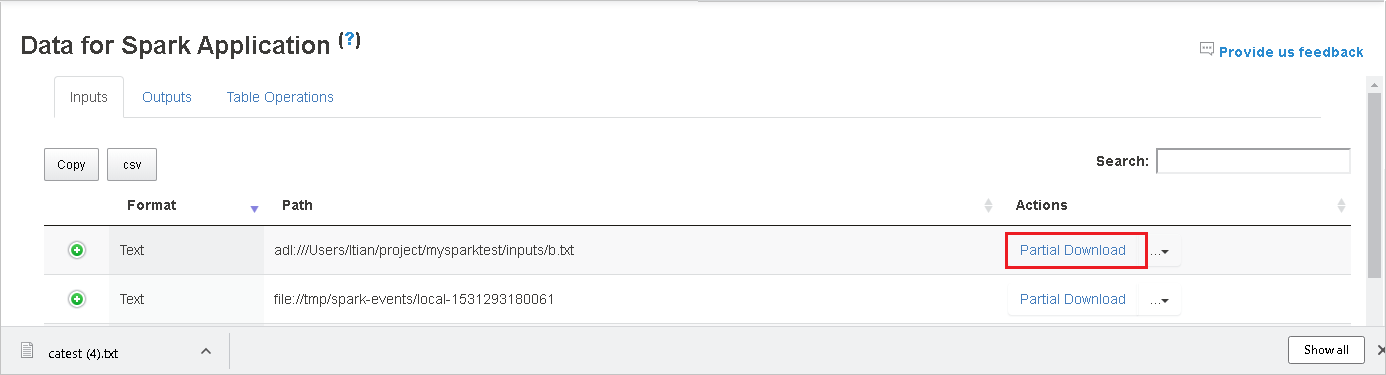
Copie una ruta de acceso completa o una ruta de acceso relativa; para ello, seleccione la opción Copy Full Path (Copiar ruta de acceso completa) o Copy Relative Path (Copiar ruta de acceso relativa) que se expande desde el menú de descarga. Para los archivos de Azure Data Lake Storage, seleccione Open in Azure Storage Explorer (Abrir en Explorador de Azure Storage) para iniciar el Explorador de Azure Storage y buscar la carpeta después del inicio de sesión.
Si hay demasiadas filas para mostrar en una sola página, seleccione los números de página en la parte inferior de la tabla para explorarla.

Para más información, seleccione o mantenga el ratón sobre el signo de interrogación junto a Data for Spark Application (Datos de la aplicación Spark) para mostrar la información sobre herramientas.
Para enviar comentarios sobre problemas, seleccione Provide us feedback (Envíenos sus comentarios).
Uso de la pestaña Gráfico del Servidor de historial de Spark
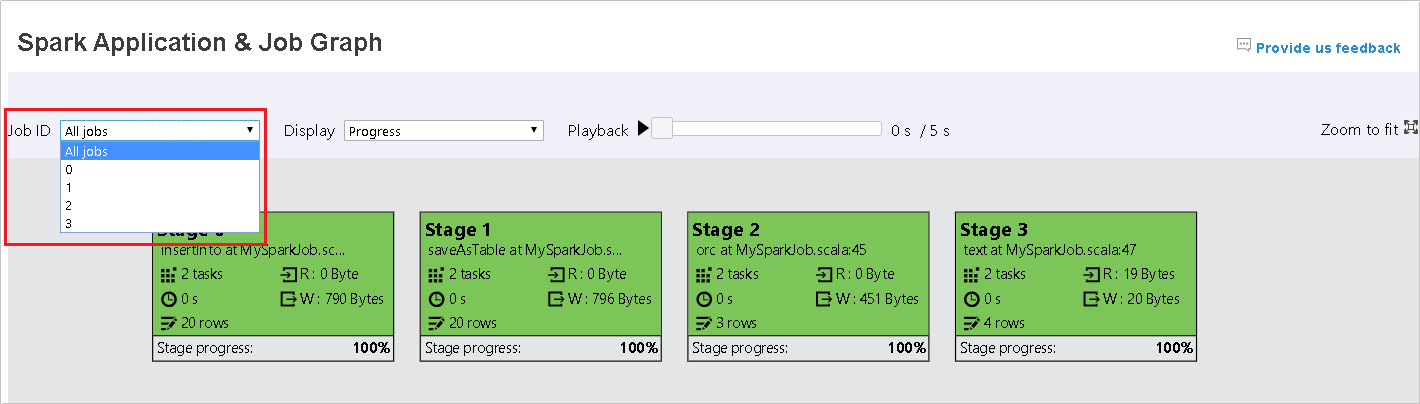
Seleccione el identificador del trabajo y, a continuación, seleccione Graph (Gráfico) en el menú de herramientas para obtener el gráfico del trabajo. De forma predeterminada, el gráfico mostrará todos los trabajos. Filtre los resultados mediante el menú desplegable Job ID (Identificador del trabajo).
La opción Progress (Progreso) está seleccionada de forma predeterminada. Compruebe el flujo de datos; para ello, seleccione Read (Leído) o Written (Escrito) en la lista desplegable Display (Mostrar).
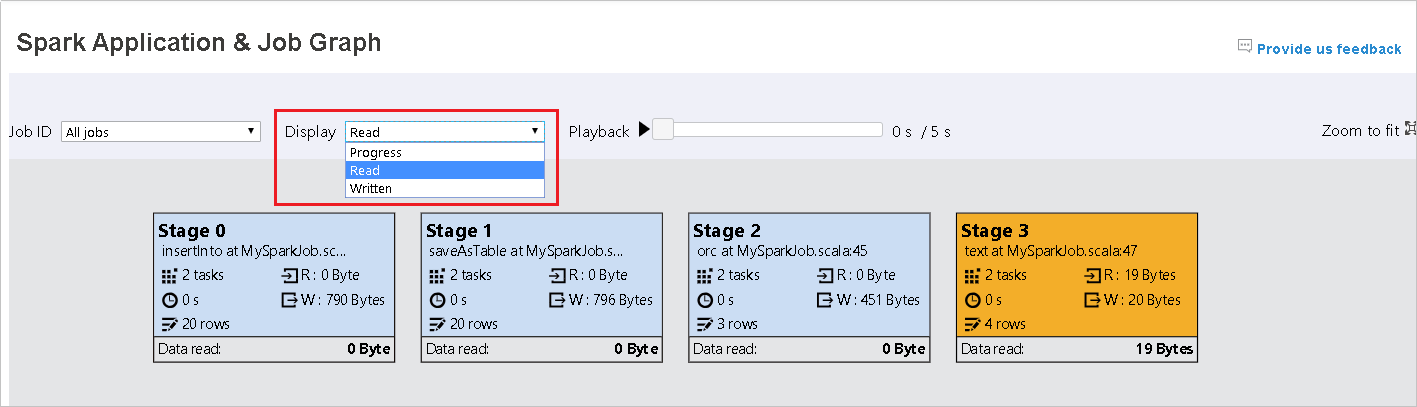
El color de fondo de cada tarea corresponde a un mapa térmico.

Color Descripción Verde el trabajo se ha completado correctamente. Naranja Se produjo un error en la tarea, pero esto no afecta al resultado final del trabajo. Estas tareas tienen instancias duplicadas o de reintento que pueden realizarse correctamente más tarde. Azul la tarea se está ejecutando. Blanco la tarea está esperando para ejecutarse o la fase se ha omitido. Rojo error en la tarea. 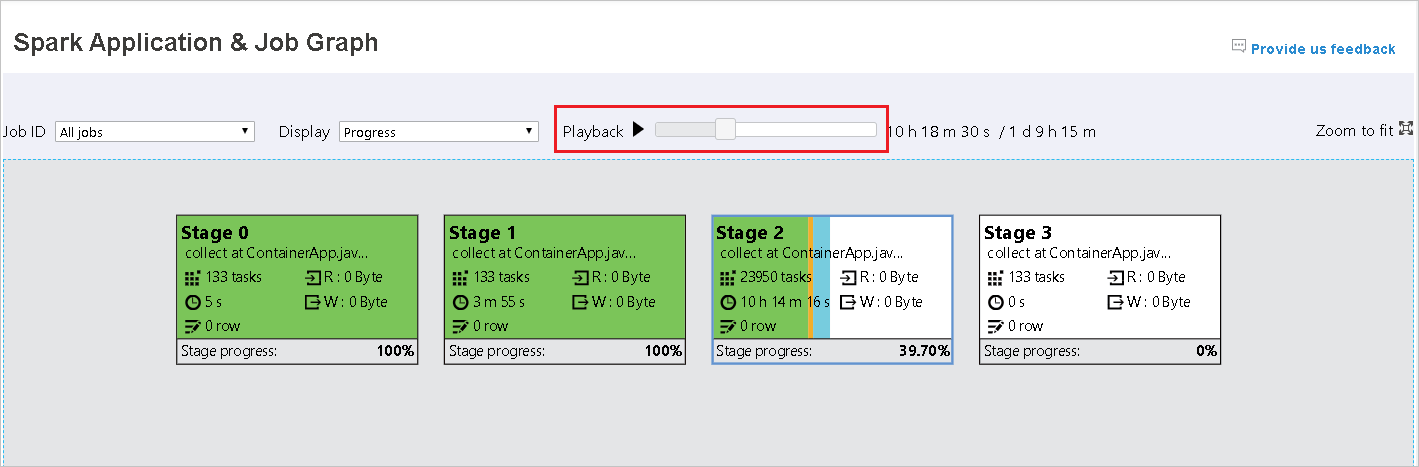
Las fases omitidas se muestran en blanco.
Nota:
La reproducción está disponible para los trabajos completados. Seleccione el botón Playback (Reproducción) para volver a reproducir el trabajo. Puede detener el trabajo en cualquier momento; para ello, seleccione el botón de detención. Cuando se reproduce un trabajo, cada tarea mostrará su estado por color. No se admite la reproducción en trabajos incompletos.
Desplácese para acercar o alejar el gráfico del trabajo o seleccione Zoom to fit (Ampliar para ajustar) para ajustarlo a la pantalla.
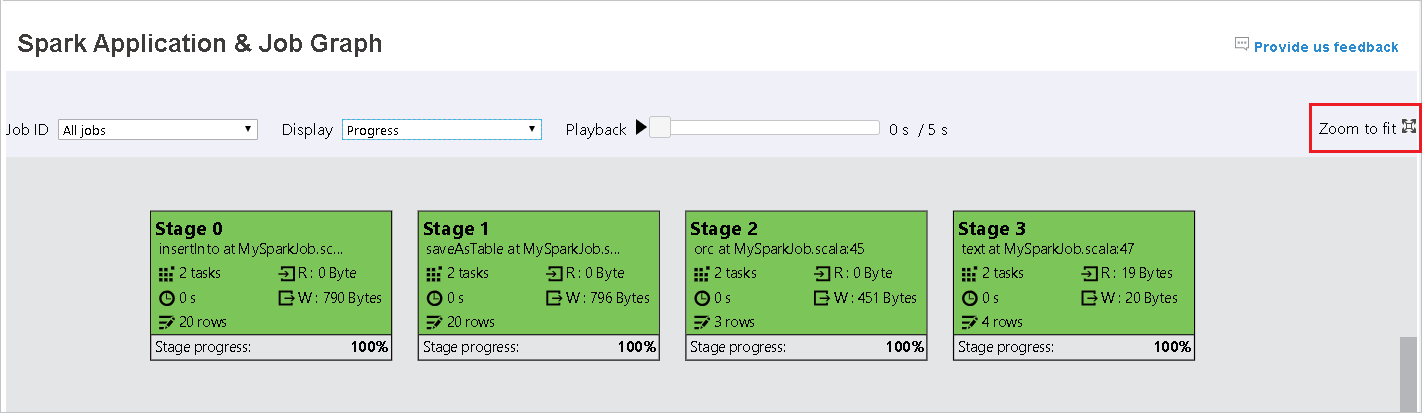
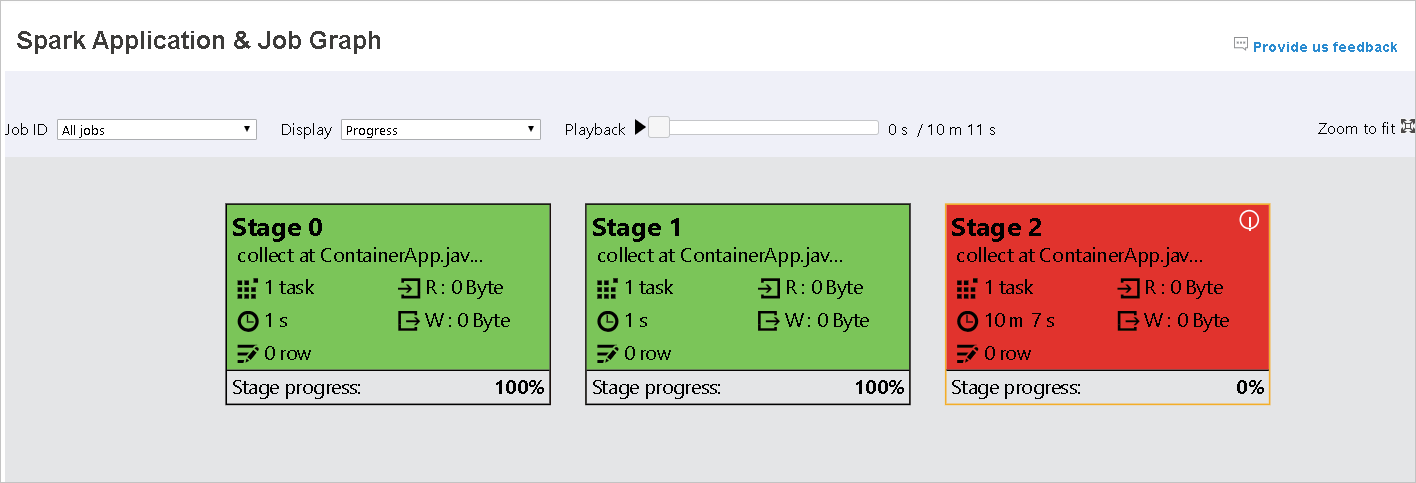
Cuando se produzca un error en las tareas, mantenga el ratón sobre el nodo del gráfico para ver la información sobre herramientas y, a continuación, seleccione la fase para abrirla en una nueva página.
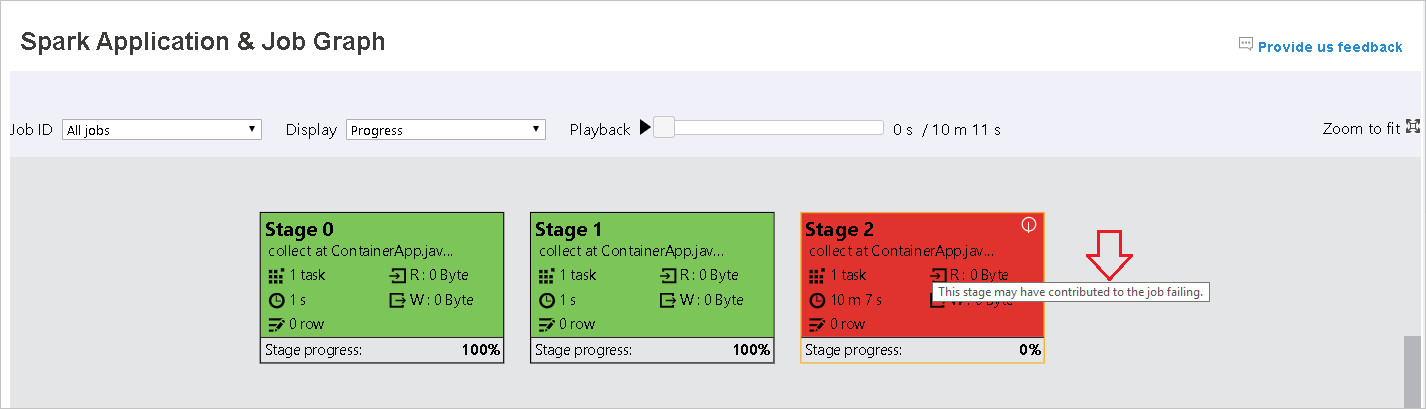
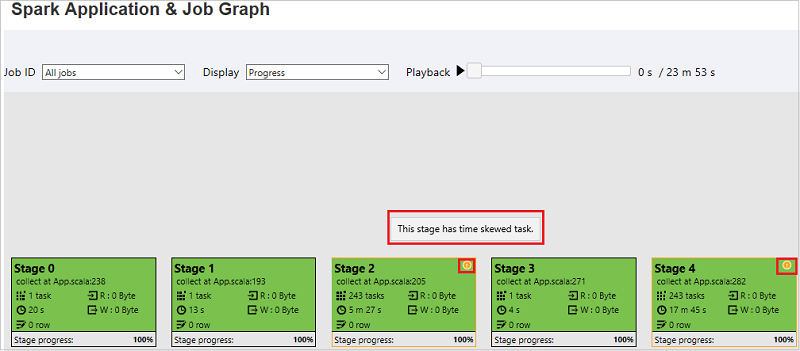
En la página Spark Application & Job Graph (Gráfico de la aplicación Spark y el trabajo), las fases mostrarán información sobre herramientas e iconos pequeños si las tareas cumplen estas condiciones:
Asimetría de datos: tamaño de lectura de datos > tamaño promedio de lectura de datos de todas las tareas dentro de esta fase * 2 y tamaño de lectura de datos > 10 MB
Desfase horario: tiempo de ejecución > tiempo promedio de ejecución de todas las tareas dentro de esta fase * 2 y tiempo de ejecución > 2 minutos
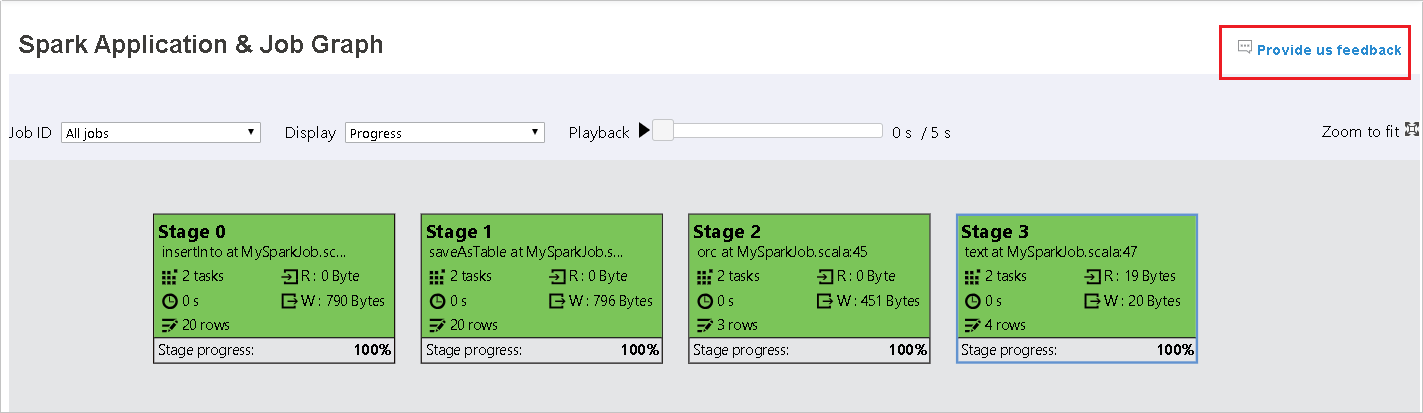
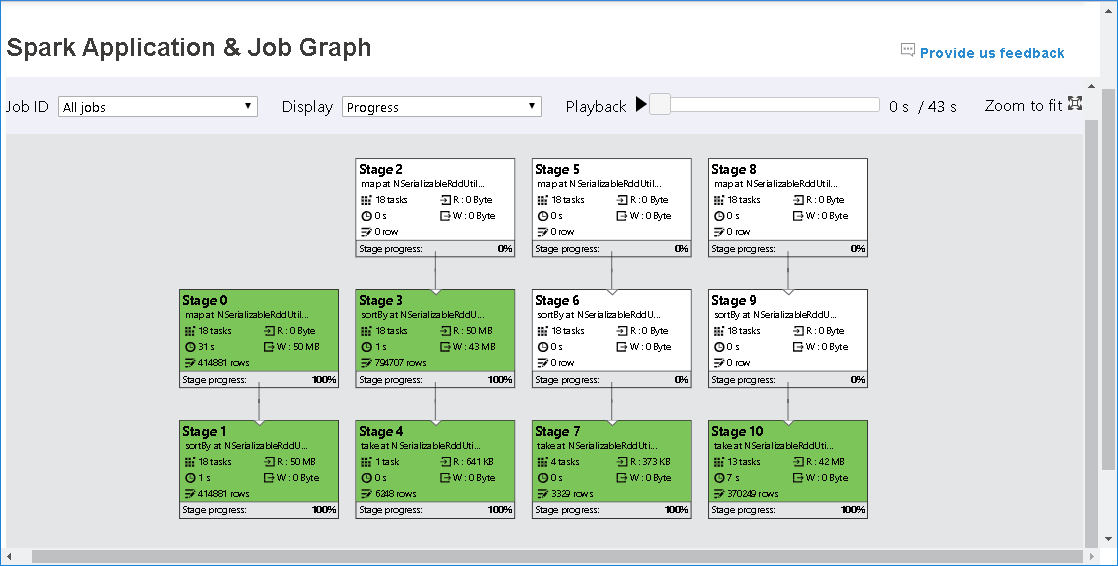
El nodo del gráfico del trabajo mostrará la siguiente información de cada fase:
ID
Nombre o descripción
Número total de tareas
Datos leídos: suma del tamaño de entrada y el tamaño de lectura aleatorio
Datos escritos: suma del tamaño de salida y el tamaño de escritura aleatorio
Tiempo de ejecución: tiempo entre la hora de inicio del primer intento y la hora de finalización del último intento
Recuento de filas: suma de los registros de entrada, los registros de salida, los registros de lectura aleatoria y los registros de escritura aleatoria
Progreso
Nota
De forma predeterminada, el nodo del gráfico del trabajo mostrará información del último intento de cada fase (excepto en el tiempo de ejecución de la fase). Pero durante la reproducción, el nodo del gráfico del trabajo mostrará información sobre cada intento.
Nota
En el caso de los tamaños de lectura y escritura de datos, usamos 1 MB = 1000 KB = 1000 * 1000 bytes.
Seleccione Provide us feedback (Envíenos sus comentarios) para enviar comentarios sobre problemas.
Uso de la pestaña Diagnóstico del Servidor de historial de Spark
Seleccione el identificador del trabajo y luego Diagnosis (Diagnóstico) en el menú de herramientas para obtener la vista de diagnóstico del trabajo. La pestaña Diagnosis (Diagnóstico) incluye Asimetría de datos, Desfase horario y Análisis de uso del ejecutor.
Seleccione las pestañas correspondientes para revisar la Asimetría de datos, el Desfase horario y el Análisis de uso del ejecutor.
Asimetría de datos
Seleccione la pestaña Data Skew (Asimetría de datos). Las tareas sesgadas correspondientes se muestran en función de los parámetros especificados.
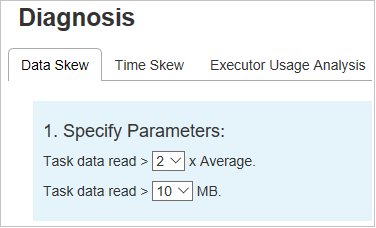
Especificar parámetros
La sección Specify Parameters (Especificar parámetros) muestra los parámetros que se usan para detectar la asimetría de datos. La regla predeterminada es: La lectura de datos de tarea es tres veces mayor que la lectura de datos de tarea promedio y la lectura de datos de tarea es mayor que 10 MB. Si desea definir su propia regla para las tareas sesgadas, puede elegir los parámetros. Las secciones Skewed Stage (Fase sesgada) y Skew Chart (Gráfico de sesgo) se actualizarán en consecuencia.
Fase sesgada
La sección Skewed Stage (Fase sesgada) muestra las fases que tienen tareas con desfase que cumplen los criterios especificados. Si hay más de una tarea con desfase en una fase, la sección Skewed Stage (Fase sesgada) muestra solo la tarea más sesgada (es decir, los datos más grandes con asimetría de datos).
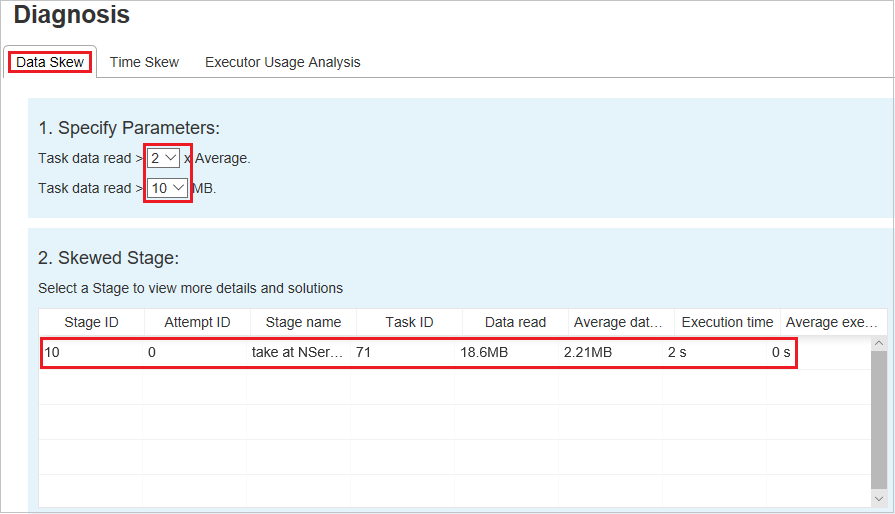
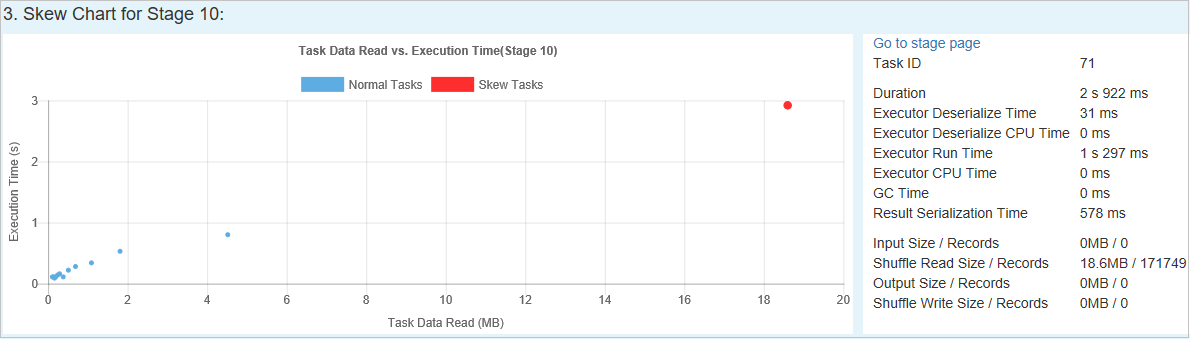
Gráfico de sesgo
Cuando se selecciona una fila de la tabla Skew Stage (Fase sesgada), Skew Chart (Gráfico de sesgo) muestra más detalles de distribuciones de tareas en función de la lectura de datos y el tiempo de ejecución. Las tareas sesgadas se marcan en rojo y las tareas normales se marcan en azul. Por motivos de rendimiento, el gráfico muestra hasta 100 tareas de ejemplo. Los detalles de la tarea se muestran en el panel inferior derecho.
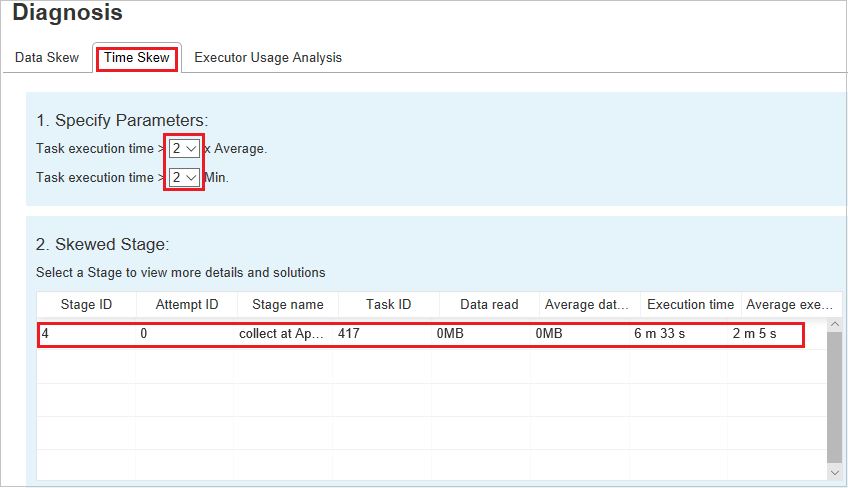
Desfase horario
En la pestaña Desfase horario se muestran las tareas sesgadas en función del tiempo de ejecución de la tarea.
Especificar parámetros
La sección Specify Parameters (Especificar parámetros) muestra los parámetros que se usan para detectar el desfase horario. La regla predeterminada es: el tiempo de ejecución de la tarea es mayor que tres veces el tiempo de ejecución promedio y el tiempo de ejecución de la tarea es superior a 30 segundos. Puede cambiar los parámetros en función de sus necesidades. Skewed Stage (Fase sesgada) y Skew Chart (Gráfico de sesgo) muestran información sobre las fases y las tareas correspondientes del mismo modo que la pestaña Data Skew (Asimetría de datos).
Al seleccionar Time Skew (Desfase horario), los resultados filtrados se muestran en la sección Skewed Stage (Fase sesgada) según los parámetros establecidos en la sección Specify Parameters (Especificar parámetros). Al seleccionar un elemento de la sección Skewed Stage (Fase sesgada), se muestra el gráfico correspondiente en la tercera sección y los detalles de la tarea en el panel inferior derecho.
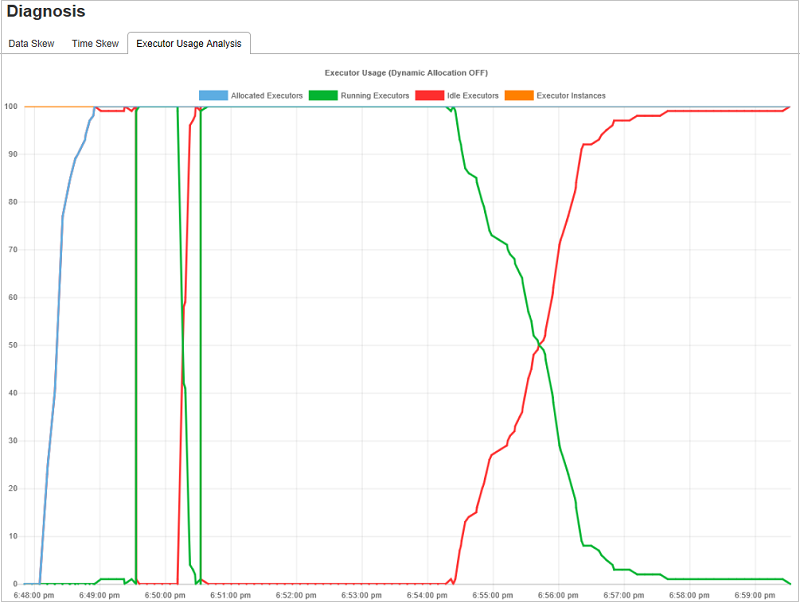
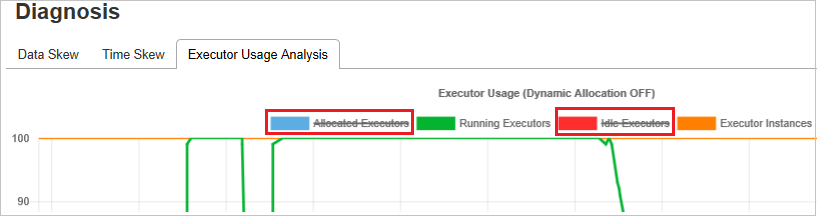
Gráficos de análisis de uso del ejecutor
Executor Usage Graph (Gráfico de uso del ejecutor) visualiza el estado de ejecución y la asignación del ejecutor real del trabajo.
Al seleccionar Executor Usage Analysis (Análisis de uso del ejecutor), se trazan cuatro curvas diferentes sobre el uso del ejecutor: Allocated Executors (Ejecutores asignados), Running Executors (Ejecutores en ejecución), idle Executors (Ejecutores inactivos) y Max Executor Instances (Número máximo de instancias del ejecutor). Cada evento Ejecutor agregado o Ejecutor eliminado aumentará o disminuirá los ejecutores asignados. Puede comprobar la escala de tiempo del evento en la pestaña Jobs (Trabajos) para comparaciones adicionales.
Seleccione el icono de color para seleccionar o anular la selección del contenido correspondiente en todos los borradores.
Preguntas más frecuentes
¿Cómo puedo revertir a la versión de la comunidad?
Para revertir a la versión de la comunidad, realice los pasos siguientes.
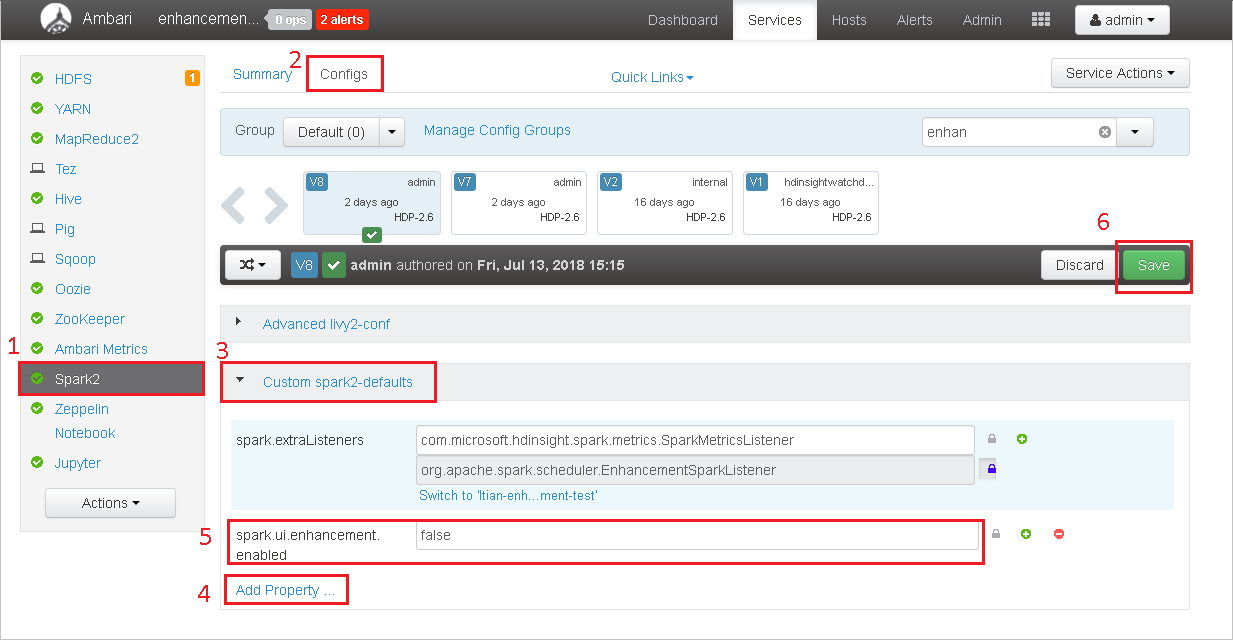
Abra el clúster en Ambari.
Vaya a Spark2>Configs (Configuraciones).
Seleccione Custom spark2-defaults.
Seleccione Add Property ... (Agregar propiedad...).
Agregue spark.ui.enhancement.enabled=false y guárdelo.
La propiedad se establece ahora en false.
Para guardar la configuración, seleccione Guardar.
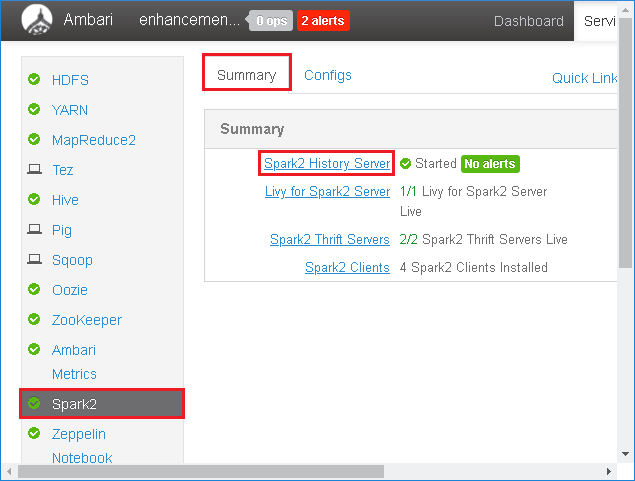
En el panel izquierdo, seleccione Spark2. A continuación, en la pestaña Summary (Resumen), seleccione Spark2 History Server.
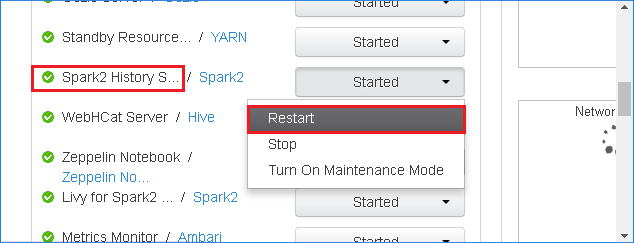
Para reiniciar el Servidor de historial de Spark, seleccione el botón Started (Iniciado) a la derecha de Spark2 History Server y, a continuación, seleccione Restart (Reiniciar) en el menú desplegable.
Actualice la interfaz de usuario web del Servidor de historial de Spark. Se revertirá a la versión de la comunidad.
¿Cómo puedo cargar un evento del Servidor de historial de Spark para informar de un problema?
Si se produce un error en el Servidor de historial de Spark, realice los pasos siguientes para notificar el evento.
Seleccione Download (Descargar) en la interfaz de usuario web del Servidor de historial de Spark para descargar el evento.
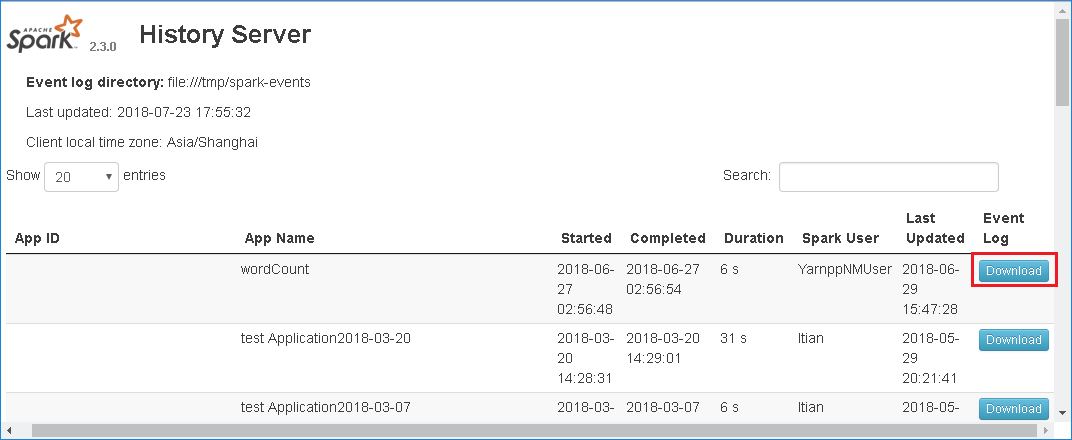
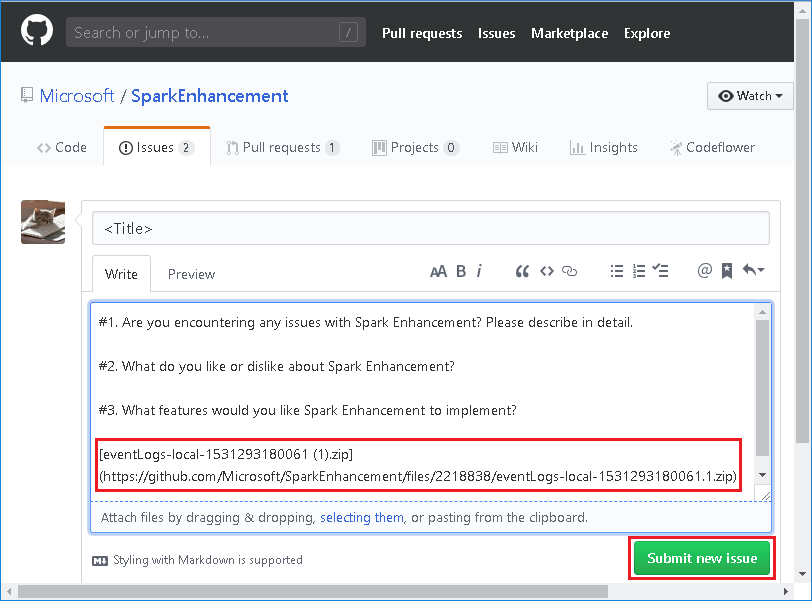
Seleccione Provide us feedback (Envíenos sus comentarios) en la página Spark Application & Job Graph (Gráfico de la aplicación Spark y el trabajo).
Proporcione el título y una descripción del error. A continuación, arrastre el archivo .zip al campo de edición y seleccione Submit new issue (Enviar nuevo comentario).
¿Cómo puedo actualizar un archivo .jar en un escenario de revisión?
Si desea actualizar con una revisión, use el siguiente script, que actualizará spark-enhancement.jar*.
upgrade_spark_enhancement.sh:
#!/usr/bin/env bash
# Copyright (C) Microsoft Corporation. All rights reserved.
# Arguments:
# $1 Enhancement jar path
if [ "$#" -ne 1 ]; then
>&2 echo "Please provide the upgrade jar path."
exit 1
fi
install_jar() {
tmp_jar_path="/tmp/spark-enhancement-hotfix-$( date +%s )"
if wget -O "$tmp_jar_path" "$2"; then
for FILE in "$1"/spark-enhancement*.jar
do
back_up_path="$FILE.original.$( date +%s )"
echo "Back up $FILE to $back_up_path"
mv "$FILE" "$back_up_path"
echo "Copy the hotfix jar file from $tmp_jar_path to $FILE"
cp "$tmp_jar_path" "$FILE"
"Hotfix done."
break
done
else
>&2 echo "Download jar file failed."
exit 1
fi
}
jars_folder="/usr/hdp/current/spark2-client/jars"
jar_path=$1
if ls ${jars_folder}/spark-enhancement*.jar 1>/dev/null 2>&1; then
install_jar "$jars_folder" "$jar_path"
else
>&2 echo "There is no target jar on this node. Exit with no action."
exit 0
fi
Uso
upgrade_spark_enhancement.sh https://${jar_path}
Ejemplo
upgrade_spark_enhancement.sh https://${account_name}.blob.core.windows.net/packages/jars/spark-enhancement-${version}.jar
Uso del archivo bash desde Azure Portal
Inicie Azure Portal y, a continuación, seleccione el clúster.
Complete una acción de script con los parámetros siguientes.
Propiedad Value Tipo de script - Personalizado Nombre UpgradeJar URI de script de Bash https://hdinsighttoolingstorage.blob.core.windows.net/shsscriptactions/upgrade_spark_enhancement.shTipos de nodo Principal, trabajo Parámetros https://${account_name}.blob.core.windows.net/packages/jars/spark-enhancement-${version}.jar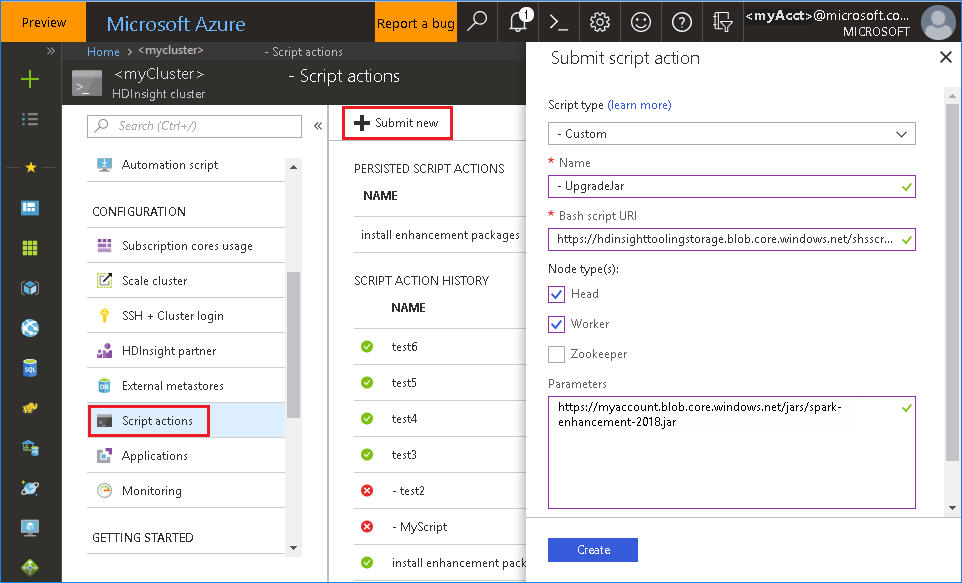
Problemas conocidos
Actualmente, el Servidor de historial de Spark solo funciona para Spark 2.3 y 2.4.
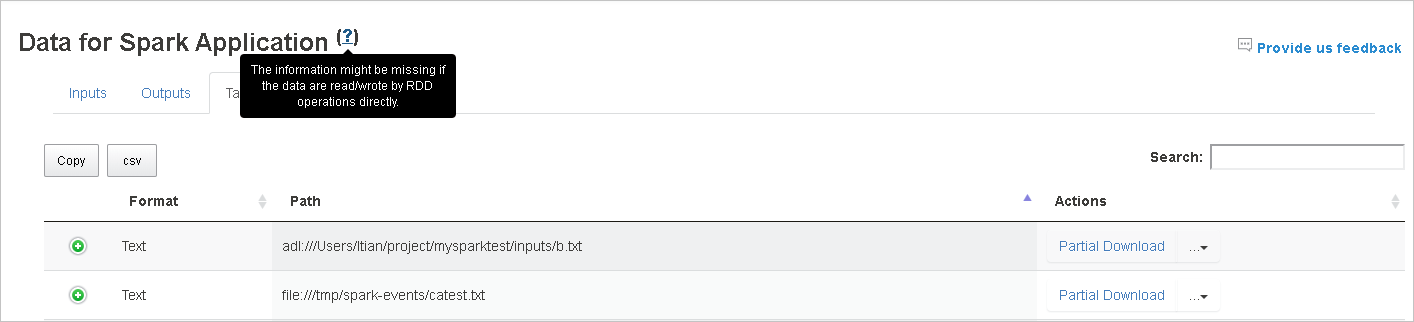
Los datos de entrada y salida que usan RDD no se mostrarán en la pestaña Data (Datos).
Pasos siguientes
- Administración de recursos de un clúster Apache Spark en Azure HDInsight
- Configuración de opciones de Apache Spark
Sugerencias
Si tiene algún comentario o si experimenta algún problema al usar esta herramienta, envíe un correo electrónico a (hdivstool@microsoft.com).