Escribir mensajes de evento en Azure Data Lake Storage Gen2 con la API de DataStream de Apache Flink®
Nota:
Retiraremos Azure HDInsight en AKS el 31 de enero de 2025. Antes del 31 de enero de 2025, deberá migrar las cargas de trabajo a Microsoft Fabric o un producto equivalente de Azure para evitar la terminación repentina de las cargas de trabajo. Los clústeres restantes de la suscripción se detendrán y quitarán del host.
Solo el soporte técnico básico estará disponible hasta la fecha de retirada.
Importante
Esta funcionalidad actualmente está en su versión preliminar. En Términos de uso complementarios para las versiones preliminares de Microsoft Azure encontrará más términos legales que se aplican a las características de Azure que están en versión beta, en versión preliminar, o que todavía no se han lanzado con disponibilidad general. Para más información sobre esta versión preliminar específica, consulte la Información de Azure HDInsight sobre la versión preliminar de AKS. Para plantear preguntas o sugerencias sobre la característica, envíe una solicitud en AskHDInsight con los detalles y síganos para obtener más actualizaciones sobre Comunidad de Azure HDInsight.
Apache Flink usa sistemas de archivos para consumir y almacenar datos de forma persistente, tanto para los resultados de las aplicaciones como para la tolerancia a los errores y la recuperación. En este artículo, aprenderá a escribir mensajes de evento en Azure Data Lake Storage Gen2 con la API de DataStream.
Requisitos previos
- Clúster de Apache Flink en HDInsight en AKS
- Clúster de Apache Kafka en HDInsight
- Debe asegurarse de que la configuración de red se haya realizado tal como se describe en Uso de Apache Kafka en HDInsight. Asegúrese de que HDInsight en clústeres de AKS y HDInsight están en la misma red virtual.
- Usar MSI para acceder a ADLS Gen2
- IntelliJ para el desarrollo en una máquina virtual de Azure en HDInsight en la red virtual de AKS
Conector de Apache Flink FileSystem
Este conector del sistema de archivos proporciona las mismas garantías para BATCH y STREAMING y está diseñado para proporcionar exactamente una semántica para la ejecución de STREAMING. Para obtener más información, vea Sistema de archivos Flink DataStream.
Conector de Apache Kafka
Flink proporciona un conector de Apache Kafka para leer y escribir datos en temas de Kafka con garantías de exactamente una vez. Para más información, vea Conector de Apache Kafka.
Compilar el proyecto para Apache Flink
pom.xml en IntelliJ IDEA
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<flink.version>1.17.0</flink.version>
<java.version>1.8</java.version>
<scala.binary.version>2.12</scala.binary.version>
<kafka.version>3.2.0</kafka.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-java -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-connector-files -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-files</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>${flink.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<appendAssemblyId>false</appendAssemblyId>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
Programa para el receptor de ADLS Gen2
abfsGen2.java
Nota:
Reemplazo de bootStrapServers del clúster de Apache Kafka en HDInsight por sus propios agentes para Kafka 3.2
package contoso.example;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.serialization.SimpleStringEncoder;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.configuration.MemorySize;
import org.apache.flink.connector.file.sink.FileSink;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.DefaultRollingPolicy;
import java.time.Duration;
public class KafkaSinkToGen2 {
public static void main(String[] args) throws Exception {
// 1. get stream execution env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Configuration flinkConfig = new Configuration();
flinkConfig.setString("classloader.resolve-order", "parent-first");
env.getConfig().setGlobalJobParameters(flinkConfig);
// 2. read kafka message as stream input, update your broker ip's
String brokers = "<update-broker-ip>:9092,<update-broker-ip>:9092,<update-broker-ip>:9092";
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers(brokers)
.setTopics("click_events")
.setGroupId("my-group")
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStream<String> stream = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");
stream.print();
// 3. sink to gen2, update container name and storage path
String outputPath = "abfs://<container-name>@<storage-path>.dfs.core.windows.net/flink/data/click_events";
final FileSink<String> sink = FileSink
.forRowFormat(new Path(outputPath), new SimpleStringEncoder<String>("UTF-8"))
.withRollingPolicy(
DefaultRollingPolicy.builder()
.withRolloverInterval(Duration.ofMinutes(2))
.withInactivityInterval(Duration.ofMinutes(3))
.withMaxPartSize(MemorySize.ofMebiBytes(5))
.build())
.build();
stream.sinkTo(sink);
// 4. run stream
env.execute("Kafka Sink To Gen2");
}
}
Empaquete el jar, y envíelo a Apache Flink.
Cargue el archivo jar en ABFS.
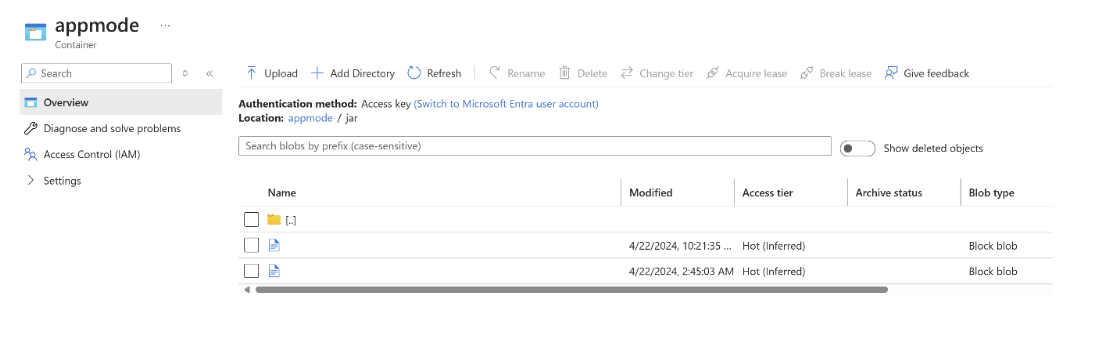
Pase la información del archivo jar del trabajo en
AppModecreación del clúster.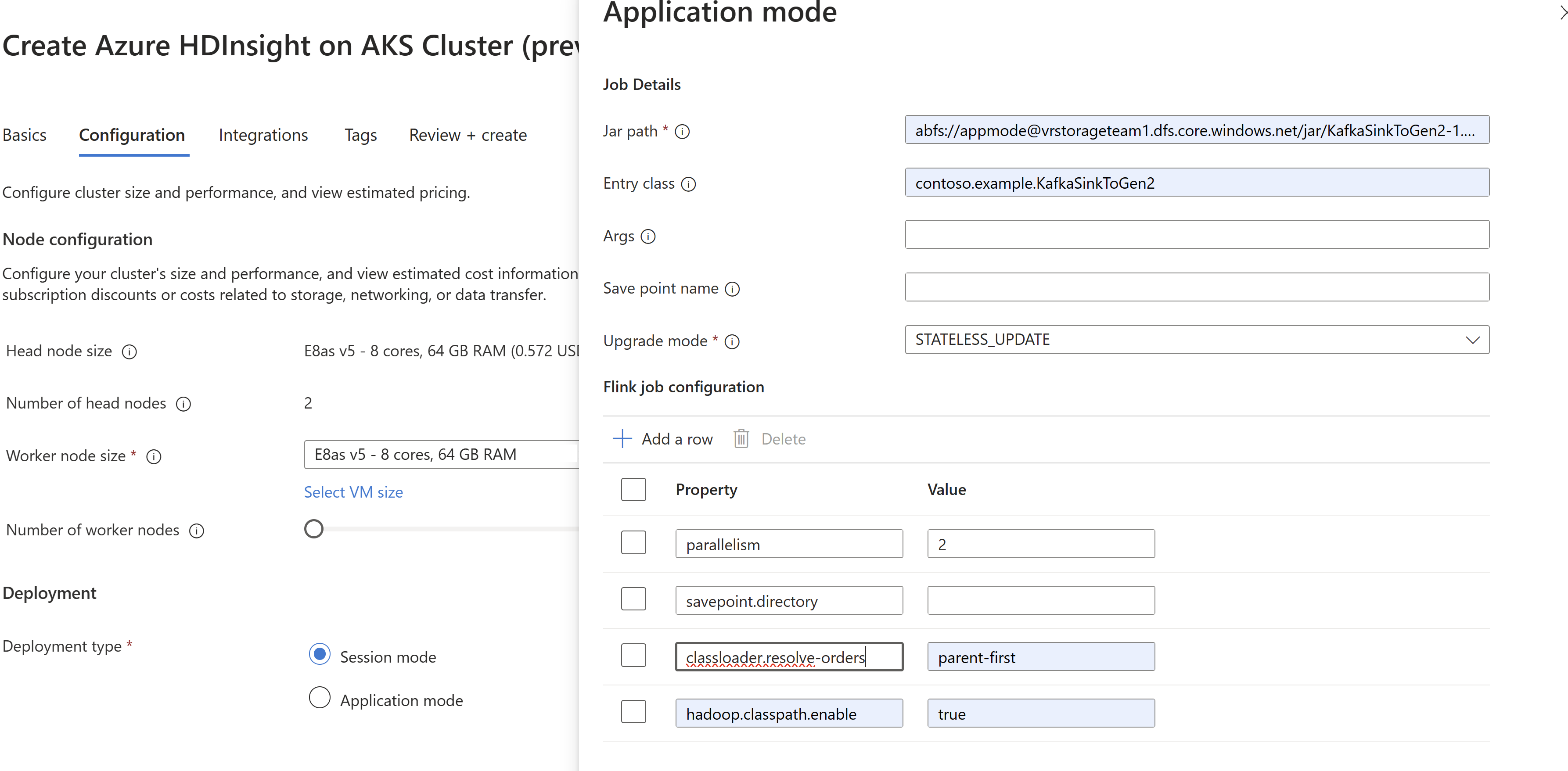
Nota:
Asegúrese de agregar classloader.resolve-order como ‘‘parent-first‘’ y hadoop.classpath.enable como
trueSeleccione Agregación de registro de trabajos para insertar registros de trabajo en la cuenta de almacenamiento.
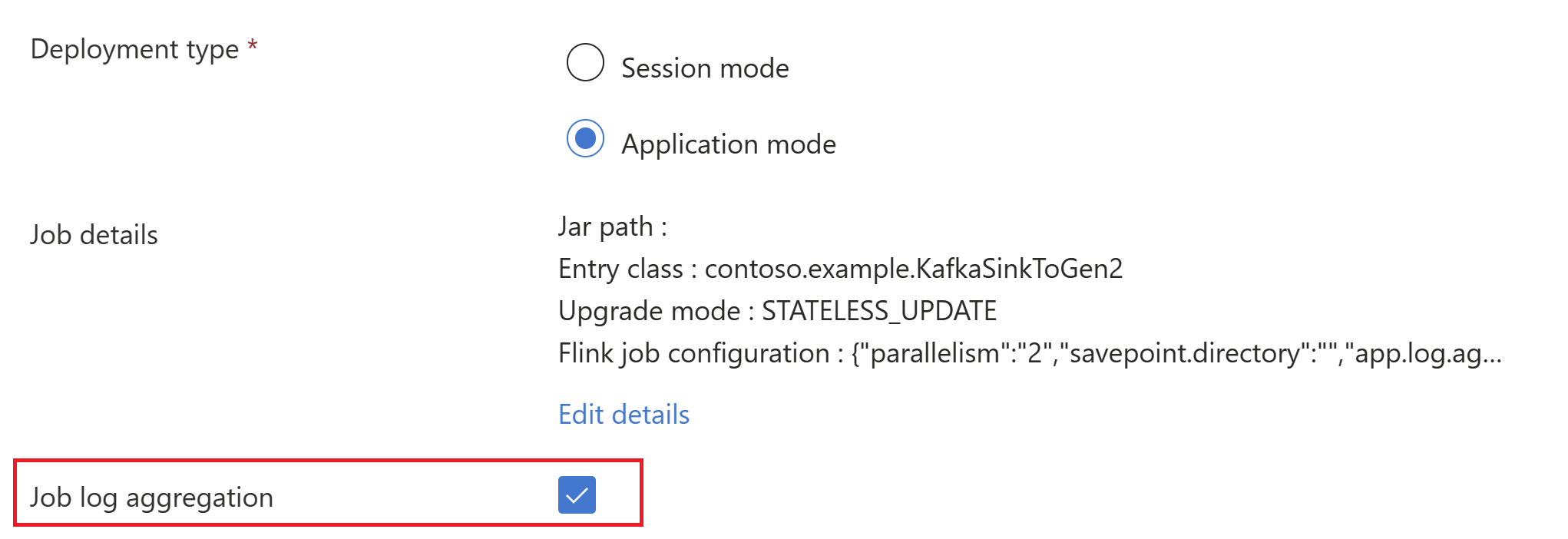
Puede ver el trabajo en ejecución.
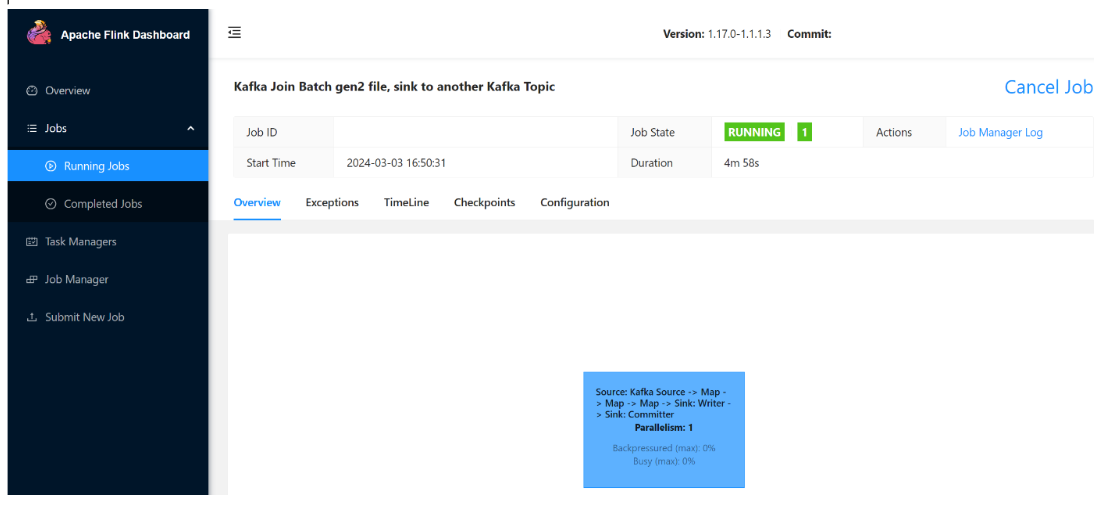




Validar datos de streaming en ADLS Gen2
Estamos viendo el streaming click_events en ADLS Gen2.

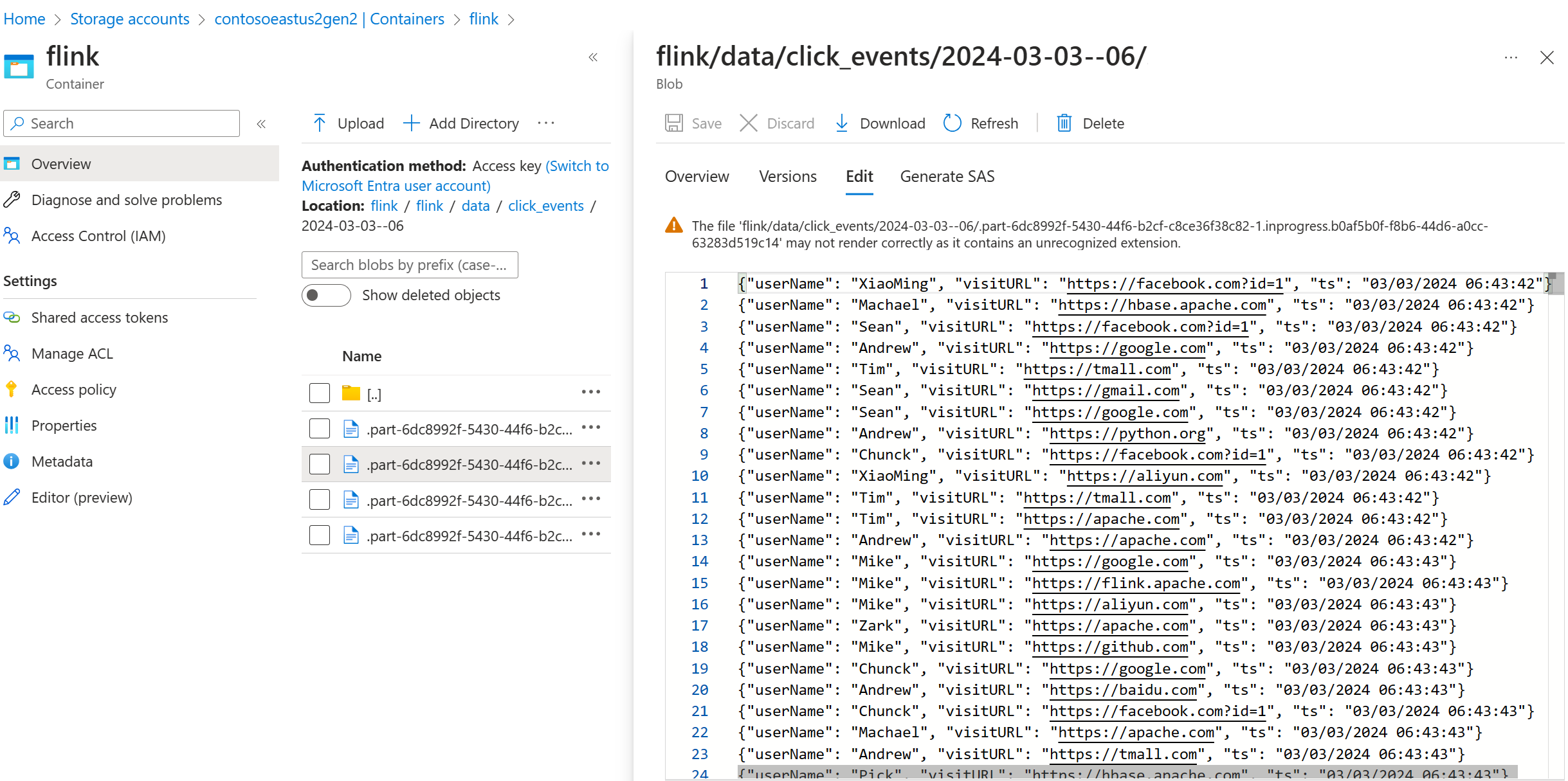
Puede especificar una directiva gradual que implemente el archivo de elementos en curso en cualquiera de las tres condiciones siguientes:
.withRollingPolicy(
DefaultRollingPolicy.builder()
.withRolloverInterval(Duration.ofMinutes(5))
.withInactivityInterval(Duration.ofMinutes(3))
.withMaxPartSize(MemorySize.ofMebiBytes(5))
.build())
Referencia
- Conector de Apache Kafka
- Sistema de archivos Flink DataStream
- Sitio web de Apache Flink
- Apache, Apache Kafka, Kafka, Apache Flink, Flink y los nombres de proyecto de código abierto asociados son marcas comerciales de Apache Software Foundation (ASF).