Inicio rápido: Creación de un clúster de Apache Kafka en Azure HDInsight mediante Azure Portal
Apache Kafka es una plataforma de streaming distribuida y de código abierto. A menudo se usa como agente de mensajes, ya que proporciona una funcionalidad similar a una cola de mensajes de publicación o suscripción.
En este inicio rápido aprenderá a crear un clúster de Apache Kafka mediante Azure Portal. También aprenderá a usar las utilidades incluidas para enviar y recibir mensajes con Apache Kafka. Para una explicación detallada de las configuraciones disponibles, consulte el artículo sobre la configuración de clústeres en HDInsight. Para más información sobre el uso del portal para crear clústeres, consulte el artículo sobre la creación de clústeres en el portal.
Advertencia
La facturación de los clústeres de HDInsight se prorratea por minuto, tanto si se usan como si no. Por consiguiente, asegúrese de eliminar el clúster cuando termine de usarlo. Consulte Eliminación de un clúster de HDInsight.
Solo los recursos dentro de la misma red virtual pueden tener acceso a la API de Apache Kafka. En este inicio rápido, accederá al clúster directamente mediante SSH. Para conectar otros servicios, redes o máquinas virtuales con Apache Kafka, primero debe crear una red virtual y, a continuación, crear los recursos dentro de la red. Para más información, consulte el documento Conexión a Kafka en HDInsight mediante una instancia de Azure Virtual Network. Para más información general sobre la planificación de redes virtuales para HDInsight, consulte Planificación de una red virtual para Azure HDInsight.
Si no tiene una suscripción a Azure, cree una cuenta gratuita antes de empezar.
Prerrequisitos
Un cliente SSH. Para más información, consulte Conexión a través de SSH con HDInsight (Apache Hadoop).
Creación de un clúster de Apache Kafka
Para crear un clúster de Apache Kafka en HDInsight, siga estos pasos:
Inicie sesión en Azure Portal.
En el menú superior, seleccione + Crear un recurso.
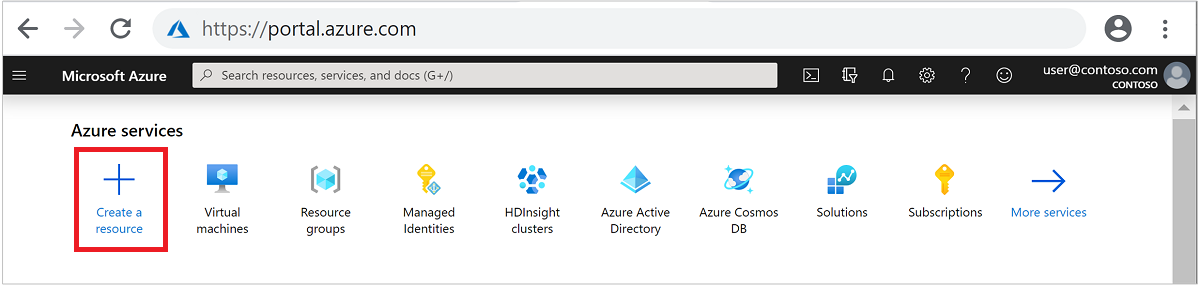
Seleccione Analytics>Azure HDInsight para ir a la página Crear clúster de HDInsight.
En la pestaña Básico, especifique la siguiente información:
Propiedad Descripción Subscription En la lista desplegable, seleccione la suscripción de Azure que se usa para el clúster. Resource group Cree un grupo de recursos o seleccione uno existente. Un grupo de recursos es un contenedor de componentes de Azure. En este caso, el grupo de recursos contiene el clúster de HDInsight y la cuenta de Azure Storage dependiente. Nombre del clúster Escriba un nombre único global. El nombre puede tener un máximo de 59 caracteres, letras, números y guiones incluidos. El primer y el último carácter del nombre no pueden ser guiones. Region En la lista desplegable, seleccione una región donde crear el clúster. Elija la región más cercana para mejorar el rendimiento. Tipo de clúster Seleccione Seleccionar tipo de clúster para abrir una lista. En ella, seleccione Kafka como tipo de clúster. Versión Se especificará la versión predeterminada para el tipo de clúster. Seleccione en la lista desplegable si desea especificar una versión diferente. Nombre de usuario y contraseña de inicio de sesión del clúster El nombre de inicio de sesión predeterminado es admin. La contraseña debe tener un mínimo de 10 caracteres y contener al menos un dígito, una letra mayúscula y una letra minúscula, y un carácter no alfanumérico (excepto los caracteres' ` "). Asegúrese de no proporcionar contraseñas comunes, comoPass@word1.Nombre de usuario de Secure Shell (SSH) El nombre de usuario predeterminado es sshuser. Puede proporcionar otro nombre para el nombre de usuario de SSH.Uso de la contraseña de inicio de sesión del clúster para SSH Seleccione esta casilla para que el usuario de SSH tenga la misma contraseña que la proporcionada para el usuario de inicio de sesión del clúster. 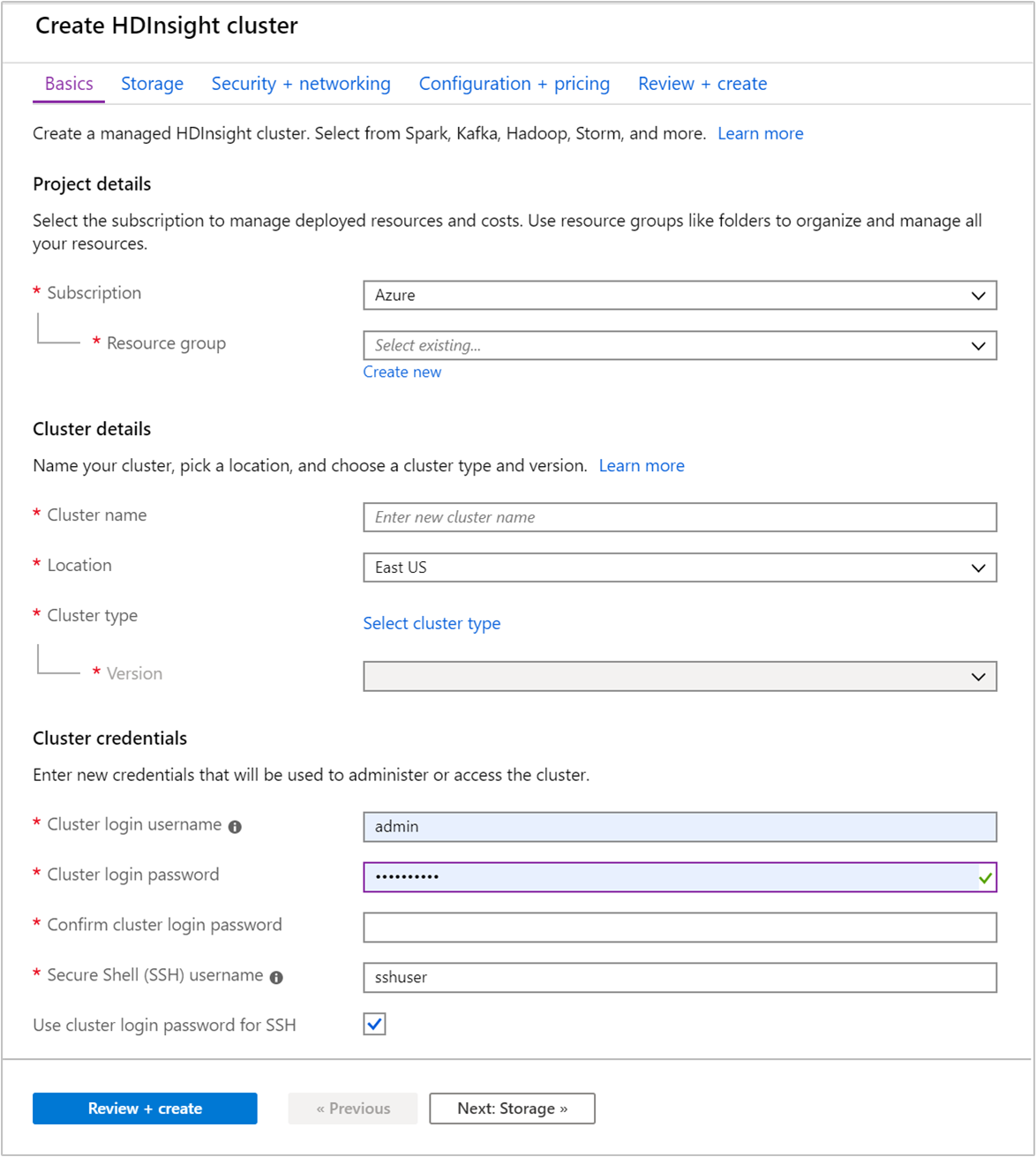
Cada región de Azure (ubicación) proporciona dominios de error. Un dominio de error es una agrupación lógica del hardware subyacente en un centro de datos de Azure. Todos los dominios de error comparten la fuente de energía y el conmutador de red. Las máquinas virtuales y los discos administrados que implementan los nodos en un clúster de HDInsight se distribuyen por estos dominios de error. Esta arquitectura limita el impacto potencial de errores del hardware físico.
Para lograr la alta disponibilidad de los datos, seleccione una ubicación (región) que contenga tres dominios de error. Para información sobre el número de dominios de error de una región, consulte el documento sobre la disponibilidad de las máquinas virtuales Linux.
Seleccione la pestaña Siguiente: Almacenamiento >> para avanzar a la configuración de almacenamiento.
En la pestaña Almacenamiento, proporcione los valores siguientes:
Propiedad Descripción Tipo de almacenamiento principal Use el valor predeterminado Azure Storage. Método de selección Use el valor predeterminado Seleccionar de la lista. Cuenta de almacenamiento principal Utilice la lista desplegable para seleccionar una cuenta de almacenamiento existente o bien elija Crear nuevo. Si crea una cuenta nueva, el nombre debe tener una longitud de entre 3 y 24 caracteres y solo puede contener números y letras minúsculas. Contenedor Use el valor que se rellena automáticamente. 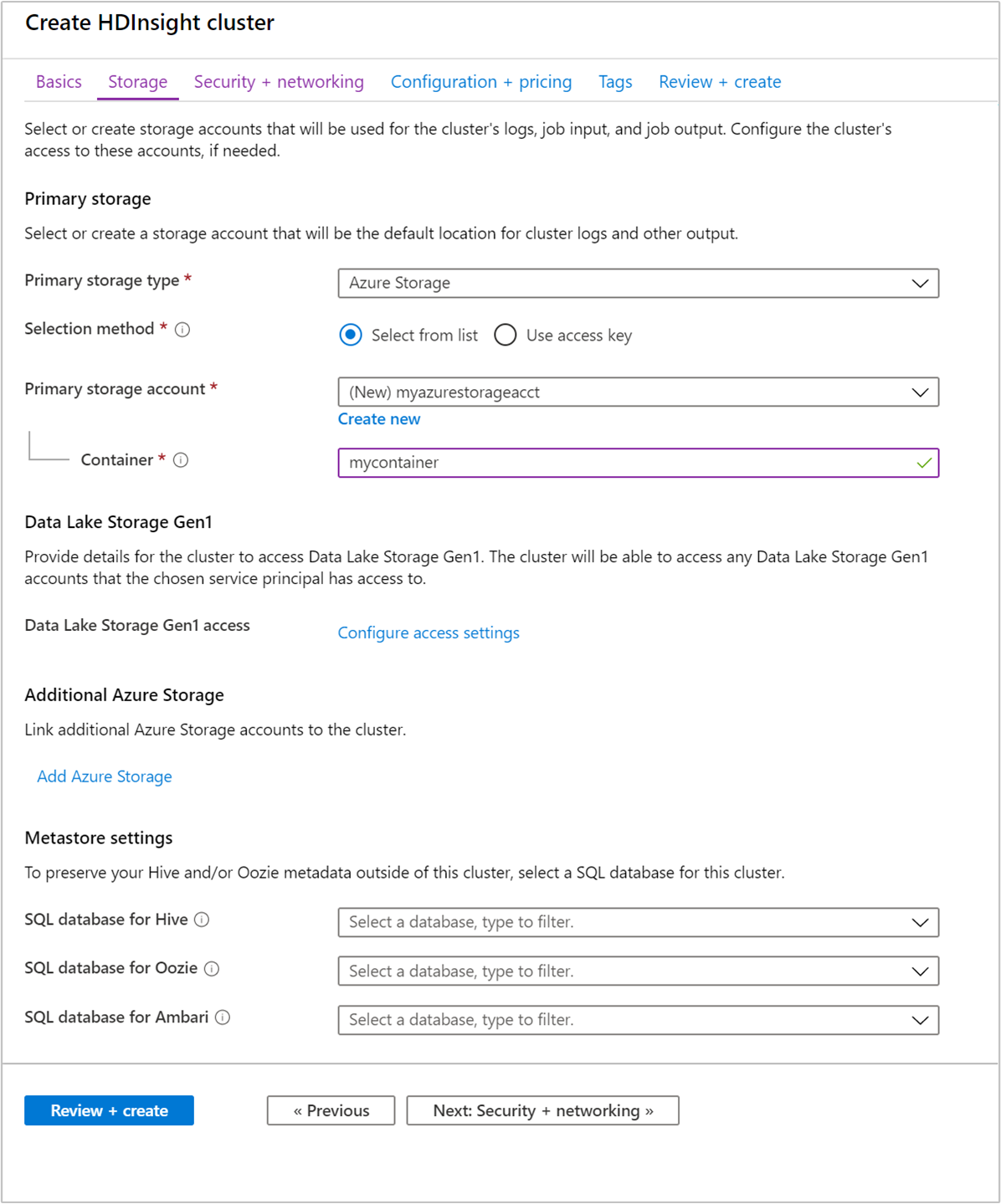
Seleccione la pestaña Seguridad y redes.
En este inicio rápido, deje la configuración de seguridad predeterminada. Para más información acerca de Enterprise Security Package, visite Configurar un clúster de HDInsight con Enterprise Security Package mediante Microsoft Entra Domain Services. Para aprender a usar su propia clave para el Cifrado de disco de Apache Kafka, visite Cifrado de disco mediante claves administradas por el cliente.
Si desea conectar su clúster a una red virtual, seleccione una red virtual desde la lista desplegable Red virtual.
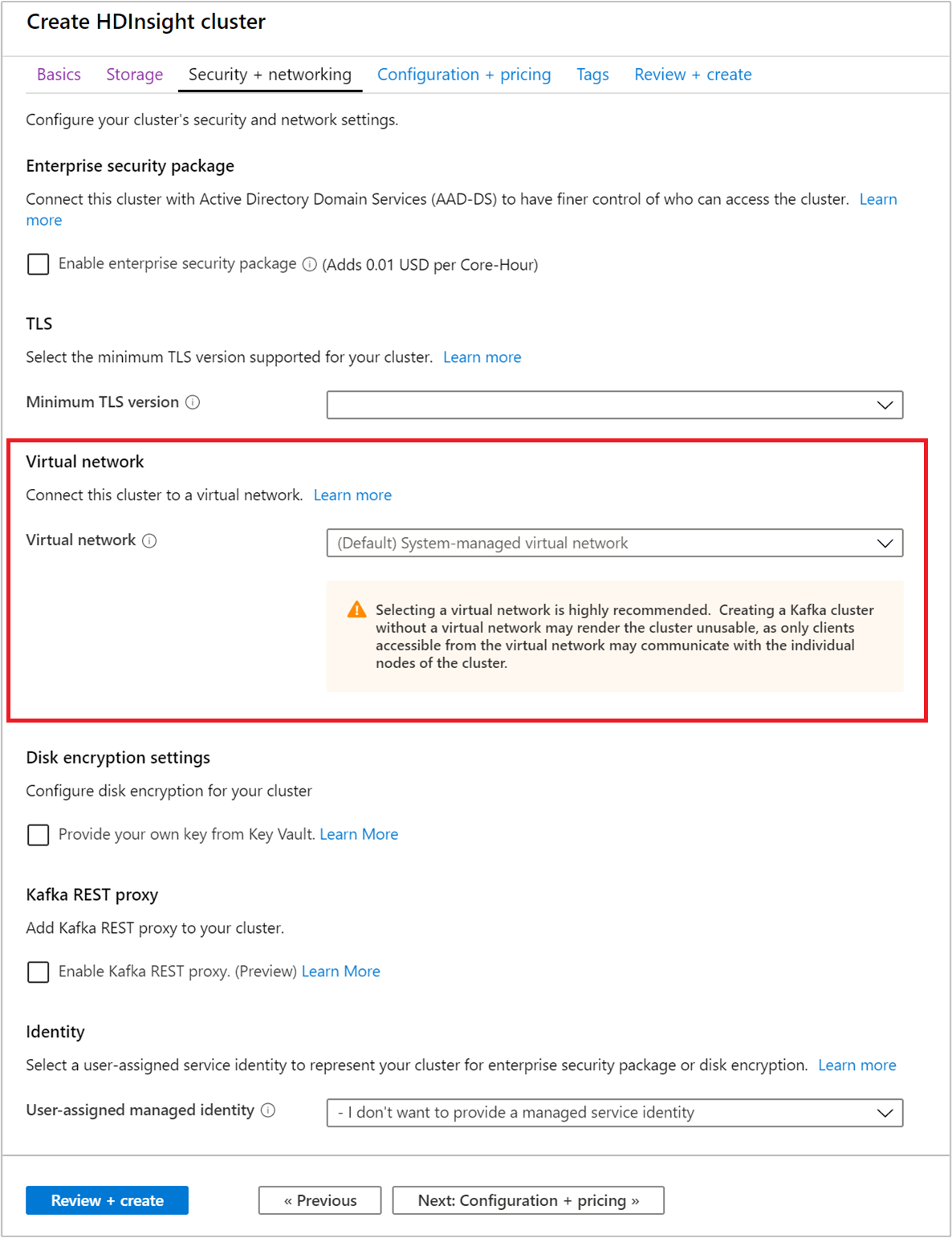
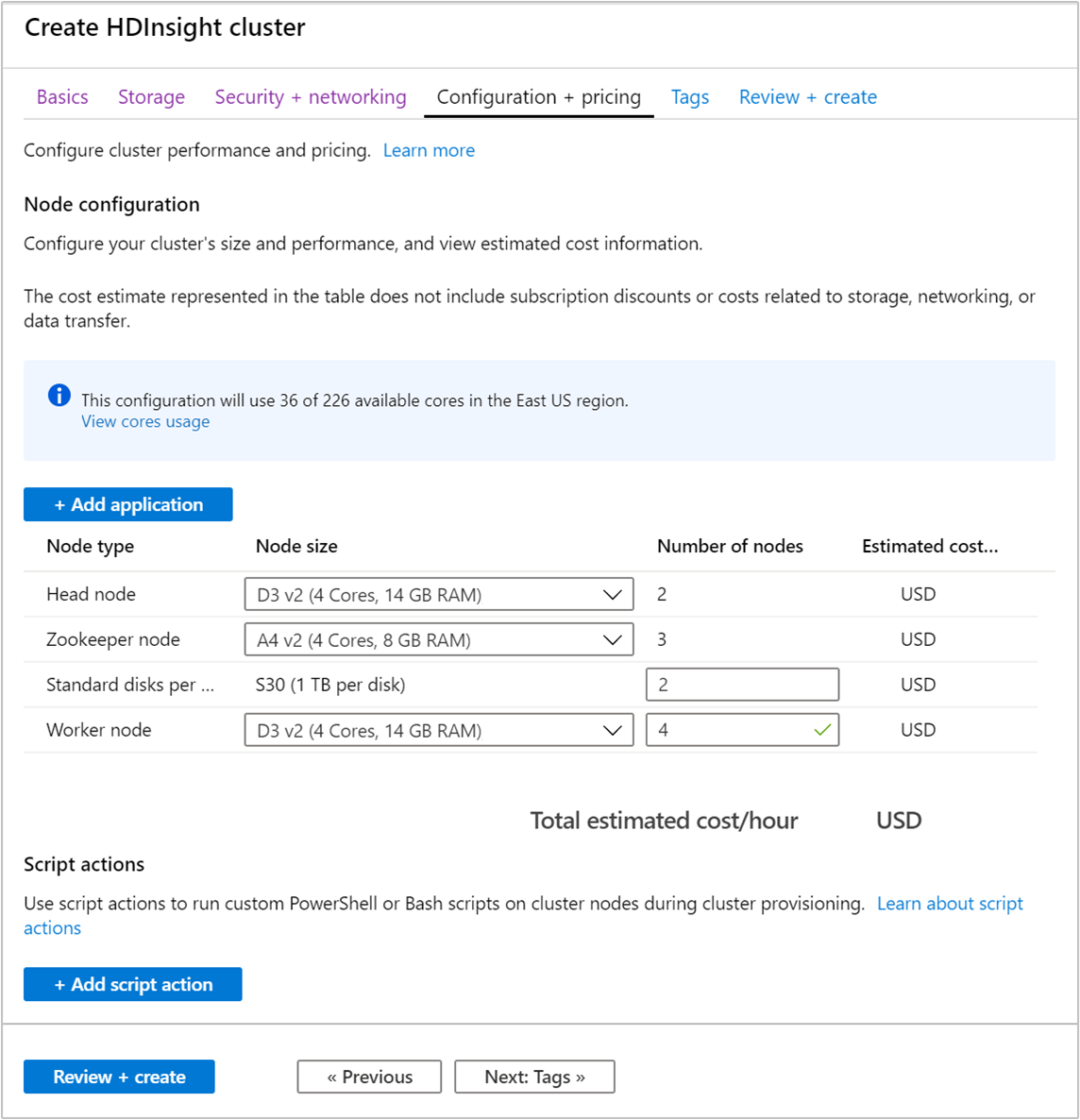
Seleccione la pestaña Configuration + pricing (Configuración y precios).
Para garantizar la disponibilidad de Apache Kafka en HDInsight, la entrada del número de nodos para Nodo de trabajo debe establecerse en tres o más. El valor predeterminado es 4.
La entrada Standard disks per worker node (Discos estándar por nodo de trabajo) configura la escalabilidad de Apache Kafka en HDInsight. Apache Kafka en HDInsight usa el disco local de las máquinas virtuales del clúster para almacenar datos. Como Apache Kafka tiene muchas E/S, Azure Managed Disks se usa para proporcionar alto rendimiento y mayor espacio de almacenamiento por nodo. El tipo de disco administrado puede ser Estándar (HDD) o Premium (SSD). El tipo de disco depende del tamaño de máquina virtual que usan los nodos de trabajo (agentes de Apache Kafka). Los discos Premium se usan automáticamente con máquinas virtuales de las series DS y GS. Todos los otros tipos de máquina virtual usan discos estándar.
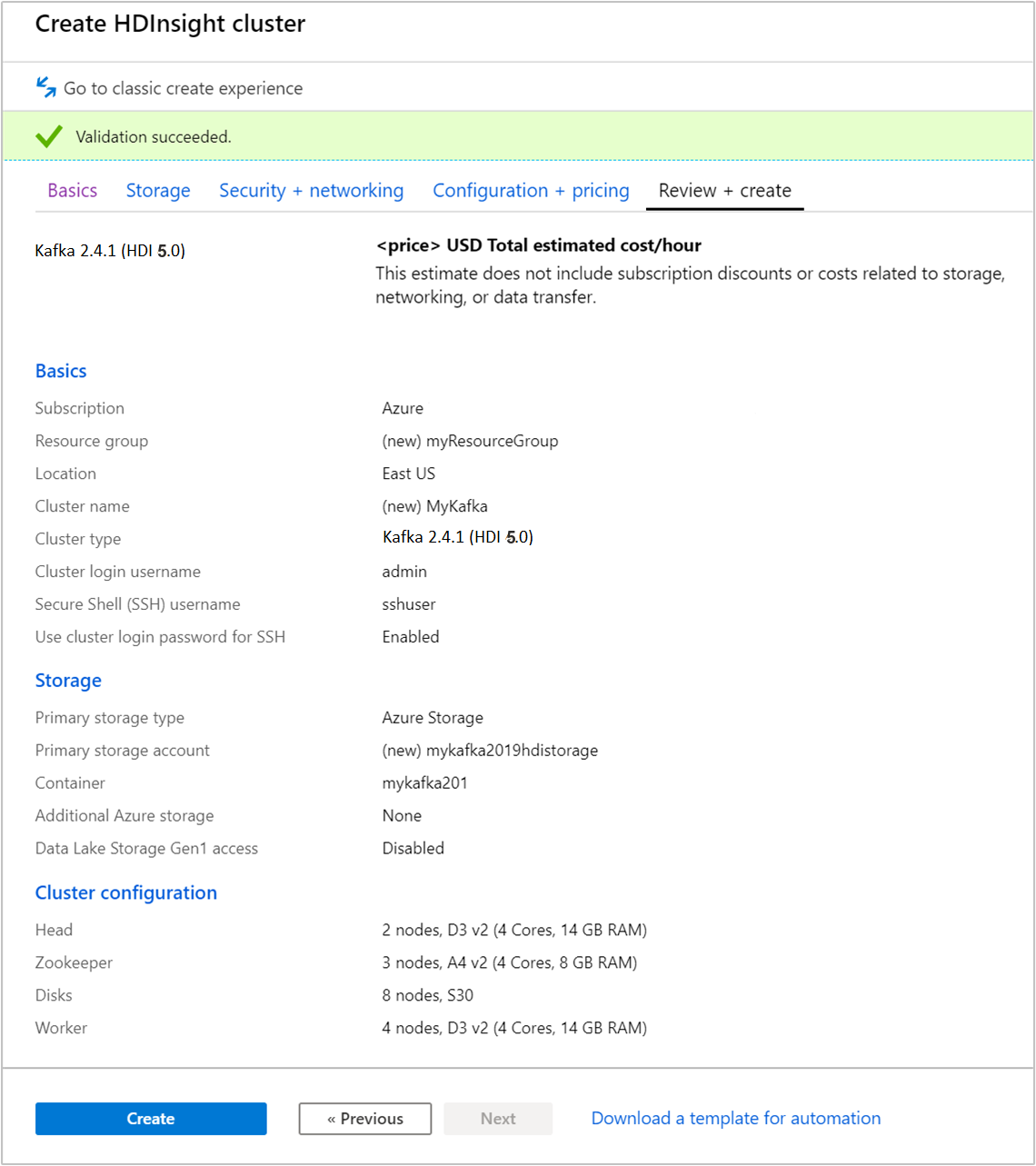
Seleccione la pestaña Revisar y crear.
Revise la configuración del clúster. Cambie la configuración que sea incorrecta. Por último, seleccione Crear para crear el clúster.
Un clúster puede tardar hasta 20 minutos en crearse.
Conectarse al clúster
Use el comando SSH para conectarse al clúster. Modifique el comando siguiente: reemplace CLUSTERNAME por el nombre del clúster y, luego, escriba el comando:
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netCuando se le solicite, escriba la contraseña del usuario de SSH.
Una vez que se haya conectado, verá información similar al texto siguiente:
Authorized uses only. All activity may be monitored and reported. Welcome to Ubuntu 16.04.4 LTS (GNU/Linux 4.13.0-1011-azure x86_64) * Documentation: https://help.ubuntu.com * Management: https://landscape.canonical.com * Support: https://ubuntu.com/advantage Get cloud support with Ubuntu Advantage Cloud Guest: https://www.ubuntu.com/business/services/cloud 83 packages can be updated. 37 updates are security updates. Welcome to Apache Kafka on HDInsight. Last login: Thu Mar 29 13:25:27 2018 from 108.252.109.241
Obtención de la información del host de Apache Zookeeper y del agente
Cuando se trabaja con Kafka, debe conocer los hosts de Apache Zookeeper y del agente. Estos hosts se usan con la API de Apache Kafka y muchas de las utilidades que se incluyen con Kafka.
En esta sección, obtendrá la información de host de la API de REST de Apache Ambari en el clúster.
Instale jq, un procesador JSON de línea de comandos. Esta utilidad se usa para analizar documentos JSON y es útil para analizar la información de host. En la conexión SSH abierta, escriba el siguiente comando para instalar
jq:sudo apt -y install jqConfigure una variable de contraseña. Reemplace
PASSWORDpor la contraseña de inicio de sesión del clúster y, después, escriba el comando:export PASSWORD='PASSWORD'Extraiga el nombre del clúster con las mayúsculas y minúsculas correctas. Las mayúsculas y minúsculas reales del nombre del clúster pueden no ser como cabría esperar, dependen de la forma en que se haya creado el clúster. Este comando obtendrá las mayúsculas y minúsculas reales y después las almacenará en una variable. Escriba el comando siguiente:
export CLUSTER_NAME=$(curl -u admin:$PASSWORD -sS -G "http://headnodehost:8080/api/v1/clusters" | jq -r '.items[].Clusters.cluster_name')Nota:
Si está realizando este proceso desde fuera del clúster, hay un procedimiento diferente para almacenar el nombre del clúster. Obtenga el nombre del clúster en minúsculas desde Azure Portal. A continuación, sustituya el nombre del clúster por
<clustername>en el siguiente comando y ejecútelo:export clusterName='<clustername>'.Para establecer una variable de entorno con la información de host de Zookeeper, use el comando siguiente. El comando recupera todos los hosts de Zookeeper y, a continuación, devuelve solo las dos primeras entradas. Esto se debe a que quiere cierta redundancia en caso de que un host sea inaccesible.
export KAFKAZKHOSTS=$(curl -sS -u admin:$PASSWORD -G https://$CLUSTER_NAME.azurehdinsight.net/api/v1/clusters/$CLUSTER_NAME/services/ZOOKEEPER/components/ZOOKEEPER_SERVER | jq -r '["\(.host_components[].HostRoles.host_name):2181"] | join(",")' | cut -d',' -f1,2);Nota
Este comando requiere acceso a Ambari. Si el clúster se encuentra detrás de un grupo de seguridad de red, ejecute este comando desde una máquina que pueda acceder a Ambari.
Para comprobar que la variable de entorno se ha establecido correctamente, use el comando siguiente:
echo $KAFKAZKHOSTSEste comando devuelve información similar al texto siguiente:
<zookeepername1>.eahjefxxp1netdbyklgqj5y1ud.ex.internal.cloudapp.net:2181,<zookeepername2>.eahjefxxp1netdbyklgqj5y1ud.ex.internal.cloudapp.net:2181Para establecer una variable de entorno con la información de host del agente de Apache Kafka, use el comando siguiente:
export KAFKABROKERS=$(curl -sS -u admin:$PASSWORD -G https://$CLUSTER_NAME.azurehdinsight.net/api/v1/clusters/$CLUSTER_NAME/services/KAFKA/components/KAFKA_BROKER | jq -r '["\(.host_components[].HostRoles.host_name):9092"] | join(",")' | cut -d',' -f1,2);Nota
Este comando requiere acceso a Ambari. Si el clúster se encuentra detrás de un grupo de seguridad de red, ejecute este comando desde una máquina que pueda acceder a Ambari.
Para comprobar que la variable de entorno se ha establecido correctamente, use el comando siguiente:
echo $KAFKABROKERSEste comando devuelve información similar al texto siguiente:
<brokername1>.eahjefxxp1netdbyklgqj5y1ud.cx.internal.cloudapp.net:9092,<brokername2>.eahjefxxp1netdbyklgqj5y1ud.cx.internal.cloudapp.net:9092
Administración de temas de Apache Kafka
Kafka almacena flujos de datos en temas. Puede usar la utilidad kafka-topics.sh para administrar temas.
Para crear un tema, use el comando siguiente en la conexión SSH:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 3 --partitions 8 --topic test --bootstrap-server $KAFKABROKERSEste comando se conecta a Broker mediante la información de host almacenada en
$KAFKABROKERS. Y, luego, crea un tema de Apache Kafka llamado test.Los datos almacenados en este tema se dividen en ocho particiones.
Cada partición se replica en tres nodos de trabajo del clúster.
Si ha creado el clúster en una región de Azure que proporciona tres dominios de error, use un factor de replicación de 3. De lo contrario, use un factor de replicación de 4.
En regiones con tres dominios de error, un factor de replicación de 3 permite que las réplicas se distribuyan entre los dominios de error. En regiones con dos dominios de error, un factor de replicación de cuatro permite que las réplicas se distribuyan equitativamente entre los dominios.
Para información sobre el número de dominios de error de una región, consulte el documento sobre la disponibilidad de las máquinas virtuales Linux.
Apache Kafka no es compatible con dominios de error de Azure. Al crear réplicas de la partición de temas, puede que estas no se distribuyan correctamente con alta disponibilidad.
Para garantizar la alta disponibilidad, use la herramienta de reequilibrado de particiones de Apache Kafka. Esta herramienta se debe ejecutar desde una conexión SSH en el nodo principal del clúster de Apache Kafka.
Para obtener la máxima disponibilidad de los datos de Apache Kafka, debe reequilibrar las réplicas de las particiones del tema cuando:
Cree un nuevo tema o una partición
Escale verticalmente un clúster
Para mostrar temas, use el comando siguiente:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --list --bootstrap-server $KAFKABROKERSEste comando muestra los temas disponibles en el clúster de Apache Kafka.
Para eliminar un tema, use el comando siguiente:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --delete --topic topicname --bootstrap-server $KAFKABROKERSEste comando elimina el tema
topicname.Advertencia
Si elimina el tema
testque ha creado anteriormente, debe volver a crearlo. Se usa más adelante en este documento.
Para obtener más información acerca de los comandos disponibles con la utilidad kafka-topics.sh, use el siguiente comando:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh
Generación y consumo de registros
Kafka almacena registros en temas. Los registros se generan mediante productores y se consumen mediante consumidores. Los productores y consumidores se comunican con el servicio de agente de Kafka. Cada nodo de trabajo del clúster de HDInsight es un host de agente de Apache Kafka.
Use los pasos siguientes para almacenar registros en el tema de prueba que creó anteriormente y luego leerlos mediante un consumidor:
Para escribir registros en el tema, use la utilidad
kafka-console-producer.shdesde la conexión SSH:/usr/hdp/current/kafka-broker/bin/kafka-console-producer.sh --broker-list $KAFKABROKERS --topic testDespués de este comando, llega a una línea vacía.
Escriba un mensaje de texto en la línea vacía y presione ENTRAR. Escriba algunos mensajes de esta forma y, a continuación, use Ctrl + C para volver al símbolo del sistema normal. Cada línea se envía como un registro independiente al tema de Apache Kafka.
Para leer registros del tema, use la utilidad
kafka-console-consumer.shdesde la conexión SSH:/usr/hdp/current/kafka-broker/bin/kafka-console-consumer.sh --bootstrap-server $KAFKABROKERS --topic test --from-beginningEste comando recupera los registros del tema y los muestra. Con
--from-beginningse indica al consumidor que comience desde el principio del flujo, de modo que se recuperan todos los registros.Si está utilizando una versión anterior de Kafka, reemplace
--bootstrap-server $KAFKABROKERSpor--zookeeper $KAFKAZKHOSTS.Use Ctrl + C para detener el consumidor.
También puede crear mediante programación los productores y consumidores. Para obtener un ejemplo del uso de esta API, consulte el documento Producer y Consumer API de Apache Kafka.
Limpieza de recursos
Para limpiar los recursos creados por esta guía de inicio rápido, puede eliminar el grupo de recursos. Al eliminar el grupo de recursos, también se elimina el clúster de HDInsight asociado y otros recursos asociados al grupo.
Para quitar el grupo de recursos mediante Azure Portal:
- En Azure Portal, expanda el menú en el lado izquierdo para abrir el menú de servicios y elija Grupos de recursos para mostrar la lista de sus grupos de recursos.
- Busque el grupo de recursos que desea eliminar y haga clic con el botón derecho en Más (...) en el lado derecho de la lista.
- Seleccione Eliminar grupo de recursos y confirme la elección.
Advertencia
Al eliminar un clúster de Apache Kafka en HDInsight, se eliminan todos los datos almacenados en Kafka.