Tutorial: Migración de WebSphere Application Server a máquinas virtuales de Azure con alta disponibilidad y recuperación ante desastres
En este tutorial se muestra una manera sencilla y eficaz de implementar alta disponibilidad y recuperación ante desastres para Java mediante WebSphere Application Server en máquinas virtuales de Azure. La solución muestra cómo lograr un objetivo de tiempo de recuperación (RTO) y un objetivo de punto de recuperación (RPO) bajos mediante una sencilla aplicación de Jakarta EE controlada por base de datos que se ejecuta en WebSphere Application Server. La alta disponibilidad y recuperación ante desastres es un tema complejo, con muchas soluciones posibles. La mejor solución depende de sus requisitos únicos. Para ver otras formas de implementar alta disponibilidad y recuperación ante desastres, consulte los recursos al final de este artículo.
En este tutorial, aprenderá a:
- Use los procedimientos recomendados optimizados para Azure para lograr alta disponibilidad y recuperación ante desastres.
- Configure un grupo de conmutación por error de Microsoft Azure SQL Database en regiones emparejadas.
- Configurar el clúster principal de WebSphere en máquinas virtuales de Azure.
- Configurar la recuperación ante desastres del clúster mediante Azure Site Recovery.
- Configure una instancia de Azure Traffic Manager.
- Prueba de una conmutación por error de principal a secundaria.
En el diagrama siguiente se muestra la arquitectura que ha creado:

Azure Traffic Manager comprueba el estado de las regiones y enruta el tráfico en consecuencia al nivel de aplicación. La región primaria tiene una implementación completa del clúster de WebSphere. Después de proteger la región primaria mediante Azure Site Recovery, puede restaurar la región secundaria durante la conmutación por error. Como resultado, la región primaria está atendiendo activamente las solicitudes de red de los usuarios, mientras que la región secundaria es pasiva y se activa para recibir tráfico solo cuando la región primaria experimenta una interrupción del servicio.
Azure Traffic Manager detecta el estado de la aplicación implementada en IBM HTTP Server para implementar el enrutamiento condicional. El RTO de conmutación por error geográfica del nivel de aplicación depende del tiempo para apagar el clúster principal, restaurar el clúster secundario, iniciar máquinas virtuales y ejecutar el clúster de WebSphere secundario. El RPO depende de la directiva de replicación de Azure Site Recovery y Azure SQL Database. Esta dependencia se debe a que los datos del clúster se almacenan y replican en el almacenamiento local de las máquinas virtuales y los datos de la aplicación se conservan y replican en el grupo de conmutación por error de Azure SQL Database.
En el diagrama anterior se muestra la región primaria y la región secundaria como las dos regiones que componen la arquitectura de alta disponibilidad y recuperación ante desastres. Estas regiones deben ser regiones emparejadas de Azure. Para obtener más información sobre las regiones emparejadas, consulte Replicación entre regiones de Azure. El artículo usa Este de EE. UU. y Oeste de EE. UU. como las dos regiones, pero puede ser cualquier región emparejada que tenga sentido para su escenario. Para obtener la lista de emparejamientos de regiones, consulte la sección Regiones emparejadas de Azure de Replicación entre regiones de Azure.
El nivel de base de datos consta de un grupo de conmutación por error de Azure SQL Database con un servidor principal y un servidor secundario. El punto de conexión del agente de escucha de lectura y escritura siempre apunta al servidor principal y está conectado al clúster de WebSphere en cada región. Una conmutación por error geográfica cambia todas las bases de datos secundarias del grupo al rol principal. Para el RPO de conmutación por error geográfica y el RTO de Azure SQL Database, consulte Información general sobre la continuidad empresarial con Azure SQL Database.
Este tutorial se redactó con Azure Site Recovery y el servicio Azure SQL Database porque el tutorial se basa en las características de alta disponibilidad de estos servicios. Otras opciones de base de datos son posibles, pero debe tener en cuenta las características de alta disponibilidad de la base de datos que elija.
Requisitos previos
- Suscripción a Azure. Si no tiene una suscripción a Azure, cree una cuenta gratuita antes de empezar.
- Asegúrese de que tiene el rol
Contributoren la suscripción. Para comprobar la asignación, siga los pasos descritos en Enumeración de asignaciones de roles de Azure mediante Azure Portal. - Prepare una máquina local con Windows, Linux o macOS instalado.
- Instalación y configuración de Git.
- Instale una implementación de Java SE, versión 17 o posterior, por ejemplo, la compilación de Microsoft de OpenJDK.
- Instale Maven, versión 3.9.3 o posterior.
Configuración de un grupo de conmutación por error de Azure SQL Database en regiones emparejadas
En esta sección, creará un grupo de conmutación por error de Azure SQL Database en regiones emparejadas para su uso con los clústeres y la aplicación de WebSphere. En una sección posterior, configurará WebSphere para almacenar sus datos de sesión en esta base de datos. En esta práctica se hace referencia a Creación de una tabla para la persistencia de la sesión.
En primer lugar, cree la instancia principal de Azure SQL Database siguiendo los pasos de Azure Portal descritos en Inicio rápido: Creación de una base de datos única - Azure SQL Database. Siga los pasos hasta la sección "Limpiar recursos", pero sin incluirla. Siga las instrucciones a medida que avanza por el artículo y vuelva a este artículo después de crear y configurar la instancia de Azure SQL Database.
Cuando llegue a la sección Creación de una base de datos única, siga los pasos que se indican a continuación:
- En el paso 4 para crear un nuevo grupo de recursos, guarde el valor de Nombre del grupo de recursos; por ejemplo,
myResourceGroup. - En el paso 5 para el nombre de la base de datos, guarde el valor Nombre de la base de datos; por ejemplo,
mySampleDatabase. - En el paso 6 para crear el servidor, siga estos pasos:
- Rellene un nombre de servidor único; por ejemplo,
sqlserverprimary-mjg022624. - En Ubicación, seleccione (EE. UU.) Este de EE. UU.
- En Método de autenticación, seleccione Usar autenticación de SQL.
- Guarde el valor de Inicio de sesión de administrador del servidor; por ejemplo,
azureuser. - Guarde el valor de Contraseña.
- Rellene un nombre de servidor único; por ejemplo,
- En el paso 8, en Entorno de carga de trabajo, seleccione Desarrollo. Examine la descripción y tenga en cuenta otras opciones para la carga de trabajo.
- En el paso 11, para Redundancia de almacenamiento de copia de seguridad, seleccione Almacenamiento de copia de seguridad con redundancia local. Considere otras opciones para las copias de seguridad. Para obtener más información, consulte la sección Redundancia de almacenamiento de copia de seguridad de Copias de seguridad automatizadas en Azure SQL Database.
- En el paso 14, en la configuración de Reglas de firewall, en Permitir que los servicios y recursos de Azure accedan a este servidor, seleccione Sí.
- En el paso 4 para crear un nuevo grupo de recursos, guarde el valor de Nombre del grupo de recursos; por ejemplo,
Cuando llegue a la sección Consulta de la base de datos, siga estos pasos:
En el paso 3, escriba la información de inicio de sesión del administrador del servidor de Autenticación de SQL para iniciar sesión.
Nota:
Si se produce un error de inicio de sesión con un mensaje de error similar a El cliente con la dirección IP 'xx.xx.xx.xx' no puede acceder al servidor, seleccione Allowlist IP xx.xx.xx.xx en el servidor <your-sqlserver-name> al final del mensaje de error. Espere hasta que las reglas de firewall del servidor completen la actualización y, a continuación, seleccione Aceptar de nuevo.
Después de ejecutar la consulta de ejemplo en el paso 5, desactive el editor, escriba la consulta siguiente y, a continuación, seleccione Ejecutar de nuevo:
CREATE TABLE sessions ( ID VARCHAR(128) NOT NULL, PROPID VARCHAR(128) NOT NULL, APPNAME VARCHAR(128) NOT NULL, LISTENERCNT SMALLINT, LASTACCESS BIGINT, CREATIONTIME BIGINT, MAXINACTIVETIME INT, USERNAME VARCHAR(256), SMALL VARBINARY(MAX), MEDIUM VARCHAR(MAX), LARGE VARBINARY(MAX) );Después de una ejecución correcta, debería ver el mensaje Consulta correcta: Filas afectadas: 0.
La tabla de base de datos
sessionsse usa para almacenar datos de sesión para la aplicación WebSphere. Los datos del clúster de WebSphere, incluidos los registros de transacciones, se conservan en el almacenamiento local de las máquinas virtuales donde se implementa el clúster.
A continuación, cree un grupo de conmutación por error de Azure SQL Database siguiendo los pasos de Azure Portal en Configuración de un grupo de conmutación por error para Azure SQL Database. Solo necesita las secciones siguientes: Crear grupo de conmutación por error y Probar conmutación por error planeada. Siga estos pasos a medida que avanza por el artículo y vuelva a este artículo después de crear y configurar el grupo de conmutación por error de Azure SQL Database.
En la sección Crear grupo de conmutación por error, siga estos pasos:
- En el paso 5 para crear el grupo de conmutación por error, escriba y guarde el nombre del grupo de conmutación por error único; por ejemplo,
failovergroup-mjg022624. - En el paso 5 para configurar el servidor, seleccione la opción para crear un nuevo servidor secundario y, a continuación, siga estos pasos:
- Especifique un nombre único para el servidor, por ejemplo,
sqlserversecondary-mjg022624. - Escriba el mismo administrador del servidor y la misma contraseña que el servidor principal.
- En Ubicación, seleccione (US) Oeste de EE. UU.
- Asegúrese de que la opción Permitir que los servicios de Azure accedan al servidor esté seleccionada.
- Especifique un nombre único para el servidor, por ejemplo,
- En el paso 5 para configurar las Bases de datos del grupo, seleccione la base de datos que creó en el servidor principal; por ejemplo,
mySampleDatabase.
- En el paso 5 para crear el grupo de conmutación por error, escriba y guarde el nombre del grupo de conmutación por error único; por ejemplo,
Después de completar todos los pasos de la sección Probar conmutación por error planeada, mantenga abierta la página del grupo de conmutación por error y úsela para la prueba de conmutación por error de los clústeres de WebSphere más adelante.
Configuración del clúster principal de WebSphere en máquinas virtuales de Azure
En esta sección, creará los clústeres principales de WebSphere en máquinas virtuales de Azure mediante la oferta IBM WebSphere Application Server Cluster en máquinas virtuales de Azure. El clúster secundario se restaura desde el clúster principal durante la conmutación por error mediante Azure Site Recovery más adelante.
Implementación del clúster principal de WebSphere
En primer lugar, abra la oferta de Clúster de IBM WebSphere Application Server en máquinas virtuales de Azure en el explorador y seleccione Crear. Debería ver el panel Aspectos básicos de la oferta.
Siga estos pasos para rellenar el panel Aspectos básicos:
- Asegúrese de que el valor que se muestra para Suscripción es el mismo que tiene los roles enumerados en la sección de requisitos previos.
- Debe implementar la oferta en un grupo de recursos vacío. En el campo Grupo de recursos, seleccione Crear nuevo y rellene un valor único para el grupo de recursos, por ejemplo,
was-cluster-eastus-mjg022624. - En Detalles de la instancia, en Región, seleccione Este de EE. UU.
- En ¿Implementar con derechos de WebSphere existente o con licencia de evaluación?, seleccione Evaluación para este tutorial. También puede seleccionar Con derechos y proporcionar su credencial ibMid.
- Seleccione He leído y acepto el Contrato de licencia de IBM..
- Deje los valores predeterminados para los demás campos.
- Seleccione Siguiente para ir al panel Configuración del clúster.

Siga estos pasos para rellenar el panel Configuración del clúster:
- En Contraseña de administrador de máquina virtual, indique una contraseña.
- En Contraseña de administrador de WebSphere, indique una contraseña. Guarde el nombre de usuario y la contraseña del administrador de WebSphere.
- Deje los valores predeterminados para los demás campos.
- Seleccione Siguiente para ir al panel Equilibrador de carga.

Siga estos pasos para rellenar el panel Equilibrador de carga:
- En Contraseña de administrador de máquina virtual, indique una contraseña.
- En Contraseña de administrador de servidor HTTP de IBM, indique una contraseña.
- Deje los valores predeterminados para los demás campos.
- Seleccione Siguiente para ir al panel Redes.

Debería ver todos los campos rellenados previamente con los valores predeterminados en el panel Redes. Seleccione Siguiente para ir al panel Base de datos.

En los pasos siguientes se muestra cómo rellenar el panel Base de datos:
- En ¿Conectarse a una base de datos?, seleccione Sí.
- En Elegir tipo de base de datos, seleccione Microsoft SQL Server.
- En Nombre JNDI, escriba jdbc/WebSphereCafeDB.
- En Cadena de conexión de origen de datos (jdbc:sqlserver://<host>:<port>;database=<database>), reemplace los marcadores de posición por los valores que guardó en la sección anterior para el grupo de conmutación por error de Azure SQL Database, por ejemplo,
jdbc:sqlserver://failovergroup-mjg022624.database.windows.net:1433;database=mySampleDatabase. - En Nombre de usuario de base de datos, escriba el nombre de inicio de sesión del administrador del servidor y el nombre del grupo de conmutación por error que guardó en la sección anterior, por ejemplo,
azureuser@failovergroup-mjg022624.Nota:
Tenga especial cuidado de usar el nombre de host y el nombre de usuario de base de datos correctos del servidor de bases de datos para el grupo de conmutación por error, en lugar del nombre de host del servidor y el nombre de usuario de la base de datos principal o de copia de seguridad. Al utilizar los valores del grupo de conmutación por error, le está indicando a WebSphere que debe comunicarse con el grupo de conmutación por error. Sin embargo, en lo que respecta a WebSphere, es simplemente una conexión de base de datos normal.
- Escriba la contraseña de inicio de sesión del administrador del servidor que guardó anteriormente para Contraseña de base de datos. Introduzca el mismo valor para Confirmar contraseña.
- Deje los valores predeterminados para los demás campos.
- Seleccione Revisar + crear.
- Espere hasta que se complete correctamente el proceso Ejecutando validación final... y, a continuación, seleccione Crear.

Después de un tiempo, debería ver la página Implementación donde se muestra Implementación en curso.
Nota:
Si ve algún problema durante el proceso Ejecutando validación final..., corríjalo e inténtelo de nuevo.
En función de las condiciones de la red y de otras actividades de la región seleccionada, la implementación puede tardar hasta 25 minutos en completarse. Después, debería ver el texto Su implementación se ha completado en la página de implementación.
Comprobación de la implementación del clúster
Ha implementado un servidor HTTP de IBM (IHS) y un WebSphere Deployment Manager (Dmgr) en el clúster. El IHS actúa como equilibrador de carga para todos los servidores de aplicaciones del clúster. Dmgr proporciona una consola web para la configuración del clúster.
Siga estos pasos para comprobar si la consola IHS y Dmgr funcionan antes de pasar al paso siguiente:
Vuelva a la página Implementación y seleccione Salidas.
Copie el valor de la propiedad ihsConsole Abra esa dirección URL en una nueva pestaña del explorador. Tenga en cuenta que no se usa
httpspara el IHS en este ejemplo. Debería ver una página principal del IHS sin ningún mensaje de error. Si no es así, debe solucionar y resolver el problema antes de continuar. Mantenga abierta la consola y úsela para comprobar la implementación de la aplicación del clúster más adelante.
Copie y guarde el valor de la propiedad adminSecuredConsole. Ábralo en una nueva pestaña del explorador. Acepte la advertencia del explorador para el certificado TLS autofirmado. No pase a producción usando un certificado TLS autofirmado.
Debería ver la página de inicio de sesión de WebSphere Integrated Solutions Console. Inicie sesión en la consola con el nombre de usuario y la contraseña del administrador de WebSphere que guardó anteriormente. Si no puede iniciar sesión, debe solucionar y resolver el problema antes de continuar. Mantenga abierta la consola y úsela para una configuración adicional del clúster de WebSphere más adelante.

Siga estos pasos para obtener el nombre de la dirección IP pública del IHS. Se usará al configurar Azure Traffic Manager más adelante.
- Abra el grupo de recursos donde está implementado clúster; por ejemplo, seleccione Información general para volver al panel Información general de la página de implementación y, a continuación, seleccione Ir al grupo de recursos.
- En la tabla de recursos, busque la columna Tipo. Selecciónela para ordenar por tipo de recurso.
- Busque el recurso Dirección IP pública con el prefijo
ihsy, a continuación, copie y guarde el nombre.
Configuración del clúster
En primer lugar, siga estos pasos para habilitar la opción Sincronizar cambios con nodos para que cualquier configuración se pueda sincronizar automáticamente con todos los servidores de aplicaciones:
- Vuelva a la consola de WebSphere Integrated Solutions e inicie sesión de nuevo si ha cerrado la sesión.
- En el panel de navegación, seleccione Administración del sistema>Preferencias de consola.
- En el panel Preferencias de consola, seleccione Sincronizar cambios con nodos y, a continuación, seleccione Aplicar. Debería ver el mensaje Sus preferencias se han cambiado.
A continuación, siga estos pasos para configurar sesiones distribuidas de base de datos para todos los servidores de aplicaciones:
- En el panel de navegación, seleccione Servidores>Tipos de servidor>Servidores de aplicaciones de WebSphere.
- En el panel Servidores de aplicaciones, debería ver 3 servidores de aplicaciones en la lista. Para cada servidor de aplicaciones, siga estas instrucciones para configurar las sesiones distribuidas de la base de datos:
- En la tabla debajo del texto Puede administrar los siguientes recursos, seleccione el hipervínculo para el servidor de aplicaciones, que comienza por
MyCluster. - En la sección Configuración del contenedor, seleccione Administración de sesiones.
- En la sección Propiedades adicionales, seleccione Configuración del entorno distribuido.
- En Sesiones distribuidas, seleccione Base de datos (compatible solo para el contenedor web).
- Seleccione Base de datos y siga estos pasos:
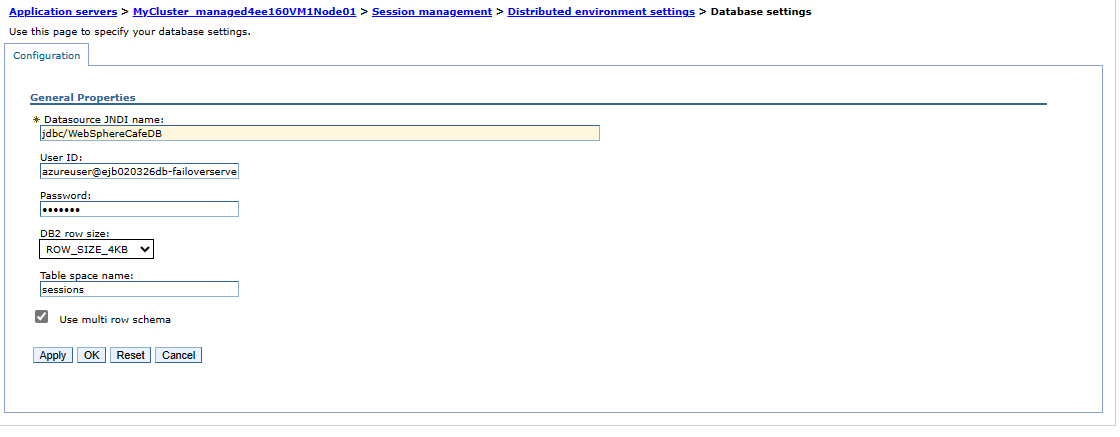
- En Nombre JNDI del origen de datos, escriba jdbc/WebSphereCafeDB.
- En ID de usuario, escriba el nombre de inicio de sesión del administrador del servidor y el nombre del grupo de conmutación por error que guardó en la sección anterior, por ejemplo,
azureuser@failovergroup-mjg022624. - Rellene la contraseña de inicio de sesión del administrador de Azure SQL Server que guardó anteriormente para Contraseña.
- En Nombre de espacio de tabla, escriba sessions.
- Seleccione Usar esquema de varias filas.
- Seleccione Aceptar. Se le redirigirá al panel Configuración del entorno distribuido.
- En la sección Propiedades adicionales, seleccione Parámetros de ajuste personalizados.
- En Nivel de ajuste, seleccione Bajo (optimizar para la conmutación por error).
- Seleccione Aceptar.
- En Mensajes, seleccione Guardar. Espere hasta la finalización.
- Seleccione Servidores de aplicaciones en la barra de ruta de navegación superior. Se le redirigirá al panel Servidores de aplicaciones.
- En la tabla debajo del texto Puede administrar los siguientes recursos, seleccione el hipervínculo para el servidor de aplicaciones, que comienza por
- En el panel de navegación, seleccione Servidores>Clústeres>Clústeres de servidores de aplicaciones de WebSphere.
- En el panel Clústeres del servidor de aplicaciones de WebSphere, debería ver el clúster
MyClusteren la lista. Active la casilla junto a MyCluster. - Seleccione Ripplestart.
- Espere hasta que se reinicie el clúster. Puede seleccionar el icono Estado y, si la nueva ventana no muestra Iniciado, vuelva a la consola y actualice la página web después de un tiempo. Repita la operación hasta que vea Iniciado. Es posible que vea Inicio parcial antes de alcanzar el estado Iniciado.
Mantenga abierta la consola y úsela para la implementación de aplicaciones más adelante.
Implementación de una aplicación de ejemplo
En esta sección se muestra cómo implementar y ejecutar una aplicación de Java/Jakarta EE CRUD de ejemplo en un clúster de WebSphere para la prueba de conmutación por error de recuperación ante desastres más adelante.
Ha configurado servidores de aplicaciones para usar el origen de datos jdbc/WebSphereCafeDB para almacenar los datos de sesión anteriormente, lo que permite la conmutación por error y el equilibrio de carga en un clúster de servidores de aplicaciones de WebSphere. La aplicación de ejemplo también configura un esquema de persistencia para conservar los datos de la aplicación coffee en el mismo origen de datos jdbc/WebSphereCafeDB.
En primer lugar, use los siguientes comandos para descargar, compilar y empaquetar el ejemplo:
git clone https://github.com/Azure-Samples/websphere-cafe
cd websphere-cafe
git checkout 20240326
mvn clean package
Si ve un mensaje acerca de estar en estado Detached HEAD, puede omitir este mensaje.
El paquete debería generarse correctamente y ubicarse en <parent-path-to-your-local-clone>/websphere-cafe/websphere-cafe-application/target/websphere-cafe.ear. Si no ve el paquete, debe solucionar el problema antes de continuar.
A continuación, siga estos pasos para implementar la aplicación de ejemplo en el clúster:
- Vuelva a la consola de WebSphere Integrated Solutions e inicie sesión de nuevo si ha cerrado la sesión.
- En el panel de navegación, seleccione Aplicaciones>Tipos de aplicaciones>Aplicaciones empresariales de WebSphere.
- En el panel Aplicaciones empresariales, seleccione Instalar>Elegir archivo. A continuación, busque el paquete ubicado en <parent-path-to-your-local-clone>/websphere-cafe/websphere-cafe-application/target/websphere-cafe.ear y seleccione Abrir. Seleccione Siguiente>Siguiente>Siguiente.
- En el panel Asignar módulos a servidores, pulse Ctrl y seleccione todos los elementos enumerados en Clústeres y servidores. Active la casilla situada junto a websphere-cafe.war. Seleccione Aplicar. Seleccione Siguiente hasta que vea el botón Finalizar.
- Seleccione Finalizar>Guardar y espere hasta que finalice. Seleccione Aceptar.
- Seleccione la aplicación instalada
websphere-cafey, a continuación, seleccione Iniciar. Espere hasta que vea mensajes que indican que la aplicación se ha iniciado correctamente. Si no puede ver el mensaje correcto, debe solucionar el problema antes de continuar.
Ahora, siga estos pasos para comprobar que la aplicación se está ejecutando según lo previsto:
Vuelva a la consola de IHS. Anexe la raíz de contexto
/websphere-cafe/de la aplicación implementada a la barra de direcciones, por ejemplo,http://ihs70685e.eastus.cloudapp.azure.com/websphere-cafe/, y pulse Entrar. Debería ver la página de bienvenida de la aplicación de ejemplo.Cree un nuevo café con un nombre y un precio, por ejemplo, Café 1 con el precio $10, que se conserva en la tabla de datos de la aplicación y en la tabla de sesión de la base de datos. La UI que ve debería ser similar a la que aparece en la siguiente captura de pantalla:
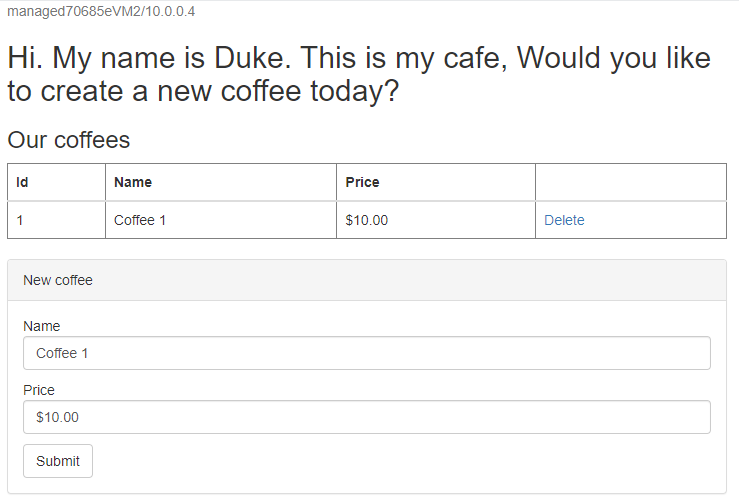

Si la interfaz de usuario no tiene un aspecto similar, solucione el problema para poder continuar.
Configuración de la recuperación ante desastres del clúster mediante Azure Site Recovery
En esta sección, configurará la recuperación ante desastres para máquinas virtuales de Azure en el clúster principal mediante Azure Site Recovery siguiendo los pasos descritos en Tutorial: Configuración de la recuperación ante desastres para máquinas virtuales de Azure. Solo necesita las secciones siguientes: Creación de un almacén de Recovery Services y Habilitación de la replicación. Preste atención a los pasos siguientes a medida que avanza por el artículo y vuelva a este artículo después de proteger el clúster principal:
En la sección Creación de un almacén de Recovery Services, siga estos pasos:
En el paso 5 del grupo de recursos, cree un nuevo grupo de recursos con un nombre único en la suscripción; por ejemplo,
was-cluster-westus-mjg022624.En el paso 6 del nombre del almacén, proporcione un nombre de almacén; por ejemplo,
recovery-service-vault-westus-mjg022624.En el paso 7 de Región, seleccione Oeste de EE. UU..
Antes de seleccionar Revisar y crear en el paso 8, seleccione Siguiente: Redundancia. En el panel Redundancia, seleccione Redundancia geográfica para Redundancia de almacenamiento de copia de seguridad y Habilitar para Restauración entre regiones.
Nota:
Asegúrese de seleccionar Redundancia geográfica en Redundancia de almacenamiento de copia de seguridad y Habilitar en Restauración entre regiones en el panel Redundancia. De lo contrario, el almacenamiento del clúster principal no se puede replicar en la región secundaria.
Habilite Site Recovery siguiendo los pasos de la sección Habilitación de Site Recovery.
Cuando llegue a la sección Habilitar aplicación, siga los pasos siguientes:
- En la sección Seleccionar configuración de origen, siga estos pasos:
En Región, seleccione Este de EE. UU. .
En Grupo de recursos, seleccione el recurso donde se implementa el clúster principal; por ejemplo,
was-cluster-eastus-mjg022624.Nota:
Si el grupo de recursos deseado no aparece en la lista, puede seleccionar Oeste de EE. UU. en primer lugar y, a continuación, volver a Este de EE. UU..
Deje los valores predeterminados para los demás campos. Seleccione Siguiente.
- En la sección Seleccione las máquinas virtuales, en Máquinas virtuales, seleccione las cinco máquinas virtuales enumeradas y, a continuación, seleccione Siguiente.
- En la sección Revisar la configuración de replicación, siga estos pasos:
- En Ubicación de destino, seleccione Oeste de EE. UU..
- En Grupo de recursos de destino, seleccione el grupo de recursos en el que se implementa el almacén de recuperación del servicio; por ejemplo,
was-cluster-westus-mjg022624. - Anote la nueva red virtual de conmutación por error y la subred de conmutación por error, que se asignan de las de la región primaria.
- Deje los valores predeterminados para los demás campos.
- Seleccione Siguiente.
- En la sección Administrar, siga estos pasos:
- En Directiva de replicación, use la directiva predeterminada 24 horas-retention-policy. También puede crear una nueva directiva para su empresa.
- Deje los valores predeterminados para los demás campos.
- Seleccione Siguiente.
- En la sección Revisar, siga estos pasos:
Después de seleccionar Habilitar replicación, observe el mensaje Creación de recursos de Azure. No cierre esta hoja. que se muestra en la parte inferior de la página. No haga nada y espere hasta que el panel se cierre automáticamente. Se le redirigirá a la página de Site Recovery.
En Elementos protegidos, seleccione Elementos replicados. Inicialmente, no hay elementos enumerados porque la replicación todavía está en curso. La replicación tarda aproximadamente una hora en completarse. Actualice la página periódicamente hasta que vea que todas las máquinas virtuales están en estado Protegido , como se muestra en la captura de pantalla de ejemplo siguiente:
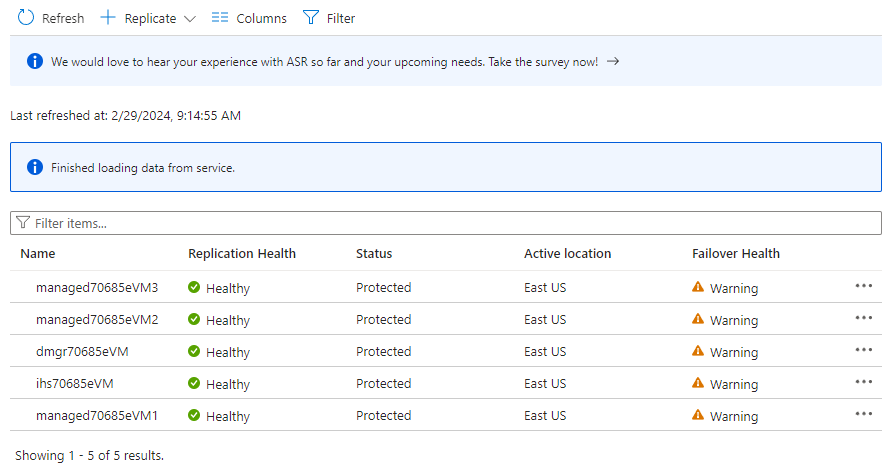
- En la sección Seleccionar configuración de origen, siga estos pasos:

A continuación, cree un plan de recuperación para incluir todos los elementos replicados para que se puedan conmutar por error juntos. Siga las instrucciones de Creación de un plan de recuperación con las siguientes personalizaciones:
- En el paso 2, escriba un nombre para el plan; por ejemplo,
recovery-plan-mjg022624. - En el paso 3, en Origen, seleccione Este de EE. UU. y en Destino, seleccione Oeste de EE. UU.
- En el paso 4 para Seleccionar elementos, seleccione las cinco máquinas virtuales protegidas de este tutorial.
A continuación, se crea un plan de recuperación. Mantenga abierta la página para poder usarla para la prueba de conmutación por error más adelante.
Configuración de red adicional para la región secundaria
También necesita más configuración de red para habilitar y proteger el acceso externo a la región secundaria en un evento de conmutación por error. Siga estos pasos para esta configuración:
Cree una dirección IP pública para Dmgr en la región secundaria siguiendo las instrucciones de Inicio rápido: Creación de una dirección IP pública mediante Azure Portal, con las siguientes personalizaciones:
- En Grupo de recursos, seleccione el grupo de recursos en el que se implementa el almacén de recuperación del servicio; por ejemplo,
was-cluster-westus-mjg022624. - En Región, seleccione (US) Oeste de EE. UU.
- En Nombre, introduzca un valor, por ejemplo,
dmgr-public-ip-westus-mjg022624. - En Etiqueta de nombre DNS, escriba un valor único, por ejemplo,
dmgrmjg022624.
- En Grupo de recursos, seleccione el grupo de recursos en el que se implementa el almacén de recuperación del servicio; por ejemplo,
Cree otra dirección IP pública para IHS en la región secundaria siguiendo la misma guía, con las siguientes personalizaciones:
- En Grupo de recursos, seleccione el grupo de recursos en el que se implementa el almacén de recuperación del servicio; por ejemplo,
was-cluster-westus-mjg022624. - En Región, seleccione (US) Oeste de EE. UU.
- En Nombre, introduzca un valor, por ejemplo,
ihs-public-ip-westus-mjg022624. Escríbalo. - En Etiqueta de nombre DNS, escriba un valor único, por ejemplo,
ihsmjg022624.
- En Grupo de recursos, seleccione el grupo de recursos en el que se implementa el almacén de recuperación del servicio; por ejemplo,
Cree un grupo de seguridad de red en la región secundaria siguiendo las instrucciones de la sección Crear un grupo de seguridad de red de Creación, cambo o eliminación de un grupo de seguridad de red, con las siguientes personalizaciones:
- En Grupo de recursos, seleccione el grupo de recursos en el que se implementa el almacén de recuperación del servicio; por ejemplo,
was-cluster-westus-mjg022624. - En Nombre, introduzca un valor, por ejemplo,
nsg-westus-mjg022624. - En Región, seleccione Oeste de EE. UU.
- En Grupo de recursos, seleccione el grupo de recursos en el que se implementa el almacén de recuperación del servicio; por ejemplo,
Cree una regla de seguridad de entrada para el grupo de seguridad de red siguiendo las instrucciones de la sección Creación de una regla de seguridad del mismo artículo, con las siguientes personalizaciones:
- En el paso 2, seleccione el grupo de seguridad de red que creó; por ejemplo,
nsg-westus-mjg022624. - En el paso 3, seleccione Reglas de seguridad de entrada.
- En el paso 4, personalice la siguiente configuración:
- En Intervalos de puertos de destino, escriba 9060,9080,9043,9443,80.
- En Protocolo, seleccione TCP.
- En Nombre, escriba ALLOW_HTTP_ACCESS.
- En el paso 2, seleccione el grupo de seguridad de red que creó; por ejemplo,
Asocie el grupo de seguridad de red a una subred siguiendo las instrucciones de la sección Asociación o desasociación de un grupo de seguridad de red hacia o desde una subred del mismo artículo, con las siguientes personalizaciones:
- En el paso 2, seleccione el grupo de seguridad de red que creó; por ejemplo,
nsg-westus-mjg022624. - Seleccione Asociar para asociar el grupo de seguridad de red a la subred de conmutación por error que anotó anteriormente.
- En el paso 2, seleccione el grupo de seguridad de red que creó; por ejemplo,
Configuración de una instancia de Azure Traffic Manager
En esta sección, creará una instancia de Azure Traffic Manager para distribuir el tráfico a las aplicaciones públicas en las regiones globales de Azure. El punto de conexión principal apunta a la dirección IP pública del IHS en la región primaria. El punto de conexión secundario apunta a la dirección IP pública del IHS en la región secundaria.
Para crear un perfil de Azure Traffic Manager, siga las instrucciones de Inicio rápido: Creación de un perfil de Traffic Manager mediante Azure Portal. Solo necesita las secciones siguientes: Crear un perfil de Traffic Manager y Agregar puntos de conexión de Traffic Manager. Debe omitir las secciones en las que se le dirigirá para crear recursos de App Service. Siga estos pasos a medida que avanza por estas secciones y vuelva a este artículo después de crear y configurar Azure Traffic Manager.
En la sección Crear un perfil de Traffic Manager, en el paso 2, para Crear perfil de Traffic Manager, siga estos pasos:
- Guarde el nombre de perfil de Traffic Manager único para Nombre (por ejemplo,
tmprofile-mjg022624). - Guarde el nuevo nombre del grupo de recursos para Grupo de recursos; por ejemplo,
myResourceGroupTM1.
- Guarde el nombre de perfil de Traffic Manager único para Nombre (por ejemplo,
Cuando llegue a la sección Agregar puntos de conexión de Traffic Manager, siga estos pasos:
- Después de abrir el perfil de Traffic Manager en el paso 2, en la página Configuración, siga estos pasos:
- En Período de vida (TTL) de DNS, escriba 10.
- En Configuración de supervisión de punto de conexión, en Ruta de acceso, escriba /websphere-cafe/, que es la raíz del contexto de la aplicación de ejemplo implementada.
- En Configuración de conmutación por error de punto de conexión rápido, use los siguientes valores:
- En Sondeo interno, seleccione 10.
- En Número tolerado de errores, escriba 3.
- En Tiempo de espera de sondeo, use 5.
- Seleccione Guardar. Espere hasta que se complete.
- En el paso 4 para agregar el punto de conexión
myPrimaryEndpointprincipal, siga estos pasos:- En Tipo de recurso de destino, seleccione Dirección IP pública.
- Seleccione la lista desplegable Elegir dirección IP pública y escriba el nombre de la dirección IP pública del IHS en la región Este de EE. UU. que guardó anteriormente. Debería ver una entrada coincidente. Selecciónela para Dirección IP pública.
- En el paso 6 para agregar un punto de conmutación por error/secundario,
myFailoverEndpoint, siga estos pasos:- En Tipo de recurso de destino, seleccione Dirección IP pública.
- Seleccione la lista desplegable Elegir dirección IP pública y escriba el nombre de la dirección IP pública del IHS en la región Oeste de EE. UU. que guardó anteriormente. Debería ver una entrada coincidente. Selecciónela para Dirección IP pública.
- Espere un rato. Seleccione Actualizar hasta que el estado Estado de supervisión del punto de conexión
myPrimaryEndpointsea En línea y el Estado de supervisión del punto de conexiónmyFailoverEndpointsea Degradado.
- Después de abrir el perfil de Traffic Manager en el paso 2, en la página Configuración, siga estos pasos:
A continuación, siga estos pasos para comprobar que se puede acceder a la aplicación de ejemplo implementada en el clúster principal de WebSphere desde el perfil de Traffic Manager:
Seleccione Información general para el perfil de Traffic Manager que creó.
Seleccione y copie el nombre del sistema de nombres de dominio (DNS) del perfil de Traffic Manager y, a continuación, añádale
/websphere-cafe/, por ejemplo,http://tmprofile-mjg022624.trafficmanager.net/websphere-cafe/.Abra la URL en una nueva pestaña del explorador. Debería ver el café que creó anteriormente en la página.
Cree otro café con un nombre y un precio diferentes, por ejemplo, Café 2 con el precio 20, que se conserva en la tabla de datos de la aplicación y en la tabla de sesión de la base de datos. La UI que ve debería ser similar a la que aparece en la siguiente captura de pantalla:
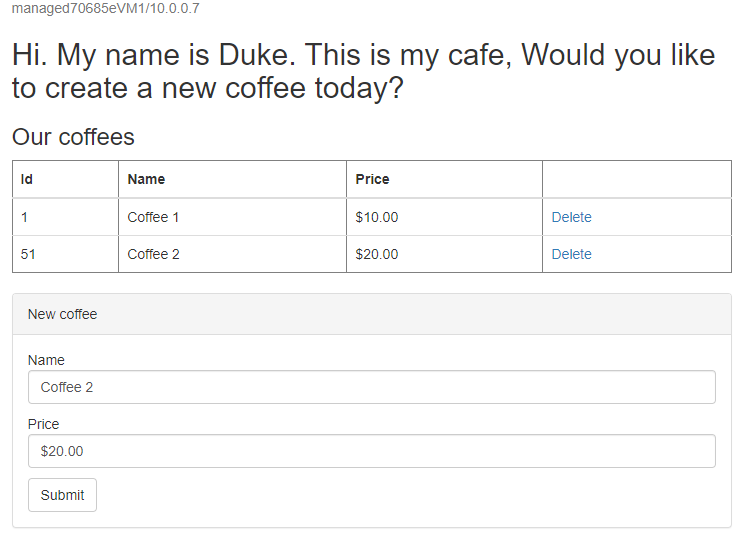

Si la IU no se parece, solucione el problema antes de continuar. Mantenga abierta la consola y úsela para la prueba de conmutación por error más adelante.
Ahora ha configurado un perfil de Traffic Manager. Mantenga abierta la página y úsela para supervisar el cambio de estado del punto de conexión en un evento de conmutación por error más adelante.
Prueba de una conmutación por error de principal a secundaria
Para probar la conmutación por error, conmute por error manualmente el servidor y el clúster de Azure SQL Database y, a continuación, conmute por recuperación mediante Azure Portal.
Conmutación por error en un sitio secundario
Primero, siga estos pasos para conmutar por error la instancia de Azure SQL Database desde el servidor principal al servidor secundario:
- Cambie a la pestaña del explorador del grupo de conmutación por error de Azure SQL Database, por ejemplo,
failovergroup-mjg022624. - Seleccione Conmutación por error>Sí.
- Espere hasta que se complete.
A continuación, siga estos pasos para conmutar por error el clúster de WebSphere con el plan de recuperación:
En el cuadro de búsqueda de la parte superior de Azure Portal, escriba Almacenes de Recovery Services y, a continuación, seleccione Almacenes de Recovery Services en los resultados de la búsqueda.
Seleccione el nombre del almacén de Recovery Services; por ejemplo,
recovery-service-vault-westus-mjg022624.En Administrar, seleccione Recovery Plans (Site Recovery) (Planes de recuperación (Site Recovery)). Seleccione el plan de recuperación que ha creado, por ejemplo,
recovery-plan-mjg022624.Seleccione Failover (Conmutación por error). Seleccione Conozco el riesgo. Omitir la conmutación por error de prueba. Deje los valores predeterminados para los demás campos y seleccione Aceptar.
Nota:
Opcionalmente, puede ejecutar la conmutación por error de prueba y la conmutación por error de prueba de limpieza para asegurarse de que todo funciona según lo previsto antes de probar la conmutación por error. Para obtener más información, consulte Tutorial: Ejecución de un simulacro de recuperación ante desastres para máquinas virtuales de Azure. En este tutorial se prueba la conmutación por error directamente para simplificar el ejercicio.
Supervise la conmutación por error en las notificaciones hasta que se complete. El ejercicio de este tutorial tarda unos 10 minutos.
Opcionalmente, puede ver los detalles del trabajo de conmutación por error seleccionando el evento de conmutación por error, por ejemplo, la conmutación por error de "recovery-plan-mjg022624" está en curso..., desde las notificaciones.
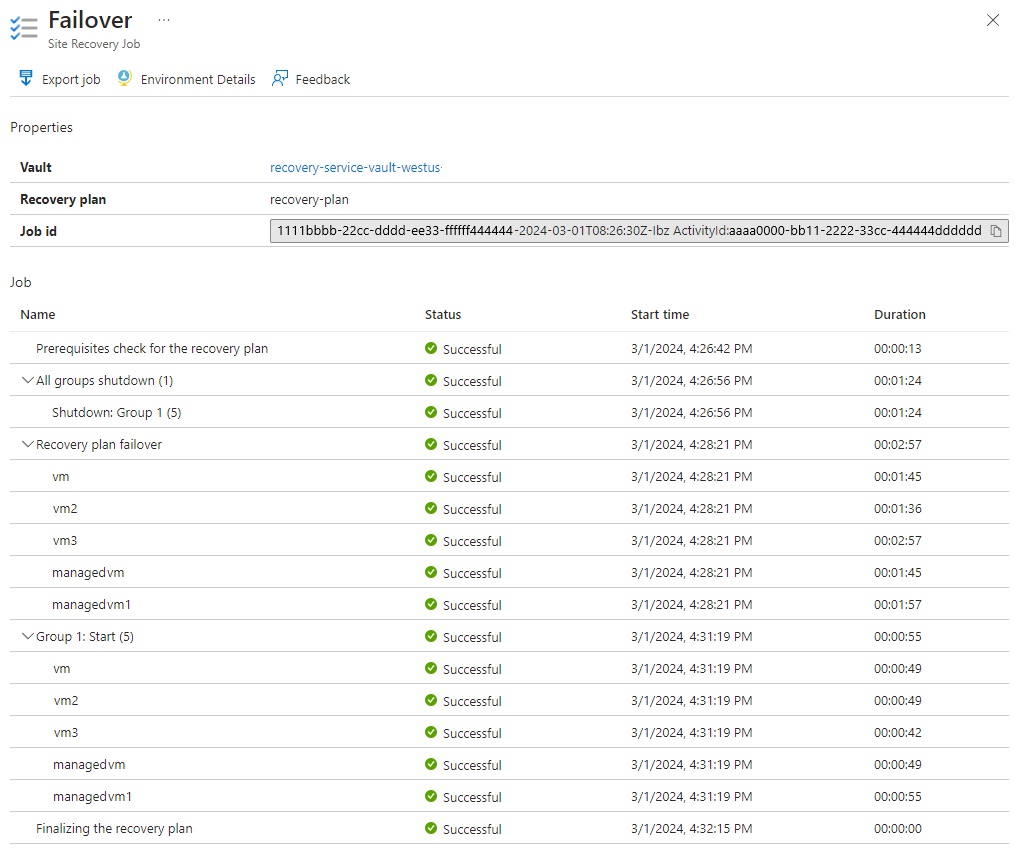




A continuación, siga estos pasos para habilitar el acceso externo a la consola de WebSphere Integrated Solutions y a la aplicación de ejemplo en la región secundaria:
- En el cuadro de búsqueda de la parte superior de Azure Portal, escriba Grupos de recursos y seleccione Grupos de recursos en los resultados de la búsqueda.
- Seleccione el nombre del grupo de recursos para la región secundaria, por ejemplo,
was-cluster-westus-mjg022624. Ordene los elementos por Tipo en la página Grupo de recursos. - Seleccione Interfaz de red con el prefijo
dmgr. Seleccione Configuraciones IP>ipconfig1. Seleccione Asociar dirección IP pública. En Dirección IP pública, seleccione la dirección IP pública con el prefijodmgr. Esta dirección es la que creó anteriormente. En este artículo, la dirección se denominadmgr-public-ip-westus-mjg022624. Seleccione Guardar y espere hasta que finalice. - Vuelva al grupo de recursos y seleccione la interfaz de red con el prefijo
ihs. Seleccione Configuraciones IP>ipconfig1. Seleccione Asociar dirección IP pública. En Dirección IP pública, seleccione la dirección IP pública con el prefijoihs. Esta dirección es la que creó anteriormente. En este artículo, la dirección se denominaihs-public-ip-westus-mjg022624. Seleccione Guardar y espere hasta que finalice.
Ahora, siga estos pasos para comprobar que la conmutación por error funciona según lo previsto:
Busque la etiqueta de nombre DNS para la dirección IP pública del Dmgr que creó anteriormente. Abra la dirección URL de Dmgr WebSphere Integrated Solutions Console en una nueva pestaña del explorador. No olvide usar
https. Por ejemplo,https://dmgrmjg022624.westus.cloudapp.azure.com:9043/ibm/console. Actualice la página hasta que vea la página de bienvenida para iniciar sesión.Inicie sesión en la consola con el nombre de usuario y la contraseña del administrador de WebSphere que guardó anteriormente y, a continuación, siga estos pasos:
En el panel de navegación, seleccione Servidores>Todos los servidores. En el panel Servidores de middleware, debería ver 4 servidores en la lista, incluidos 3 servidores de aplicaciones de WebSphere que constan de un clúster de WebSphere
MyClustery un servidor web que es un IHS. Actualice la página hasta que vea que se inician todos los servidores.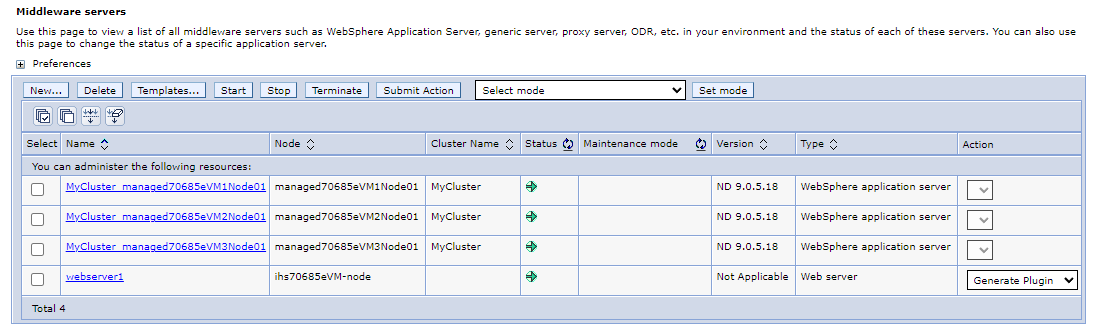
En el panel de navegación, seleccione Aplicaciones>Tipos de aplicaciones>Aplicaciones empresariales de WebSphere. En el panel Aplicaciones empresariales debería ver 1 aplicación,
websphere-cafe, en la lista e iniciada.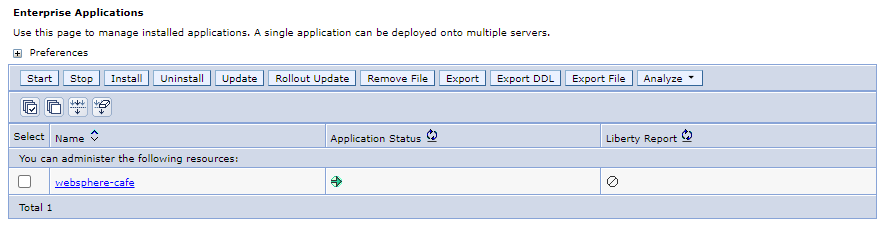
Para validar la configuración del clúster en la región secundaria, siga los pasos descritos en la sección Configuración del clúster. Debería ver que la configuración de Sincronizar cambios con nodos y Sesiones distribuidas se replican en el clúster de conmutación por error, como se muestra en las capturas de pantalla siguientes:
Busque la etiqueta de nombre DNS para la dirección IP pública del IHS que creó anteriormente. Abra la dirección URL de la consola de IHS anexada con el contexto raíz
/websphere-cafe/. Tenga en cuenta que no debe usarhttps. En este ejemplo no se usahttpspara IHS, por ejemplo,http://ihsmjg022624.westus.cloudapp.azure.com/websphere-cafe/. Debería ver dos cafés que creó anteriormente en la página.Cambie a la pestaña del explorador del perfil de Traffic Manager y, a continuación, actualice la página hasta que vea que el valor de Estado de supervisión del punto de conexión
myFailoverEndpointes En línea y el valor de Estado de supervisión del punto de conexiónmyPrimaryEndpointes Degradado.Cambie a la pestaña del explorador con el nombre DNS del perfil de Traffic Manager; por ejemplo,
http://tmprofile-mjg022624.trafficmanager.net/websphere-cafe/. Actualice la página y debería ver los mismos datos almacenados en la tabla de datos de la aplicación y la tabla de sesión mostrada. La UI que ve debería ser similar a la que aparece en la siguiente captura de pantalla: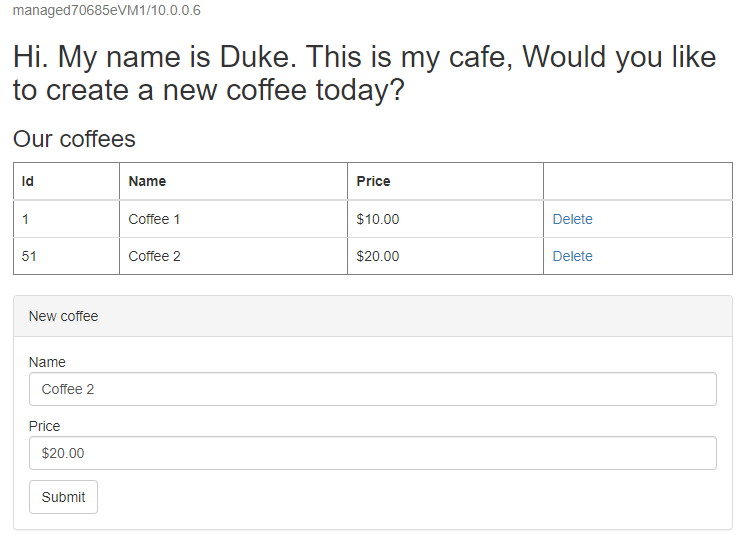
Si no observa este comportamiento, puede deberse a que Traffic Manager tarda tiempo en actualizar DNS para que apunte al sitio de conmutación por error. El problema también podría ser que el explorador almacenara en caché el resultado de la resolución de nombres DNS que apunta al sitio con errores. Espere un rato y vuelva a actualizar la página.





Confirmar la conmutación por error.
Siga estos pasos para confirmar la conmutación por error después de cumplir el resultado de la conmutación por error:
En el cuadro de búsqueda de la parte superior de Azure Portal, escriba Almacenes de Recovery Services y, a continuación, seleccione Almacenes de Recovery Services en los resultados de la búsqueda.
Seleccione el nombre del almacén de Recovery Services; por ejemplo,
recovery-service-vault-westus-mjg022624.En Administrar, seleccione Recovery Plans (Site Recovery) (Planes de recuperación (Site Recovery)). Seleccione el plan de recuperación que ha creado, por ejemplo,
recovery-plan-mjg022624.Seleccione Confirmar>Aceptar.
Supervise la confirmación en las notificaciones hasta que se complete.
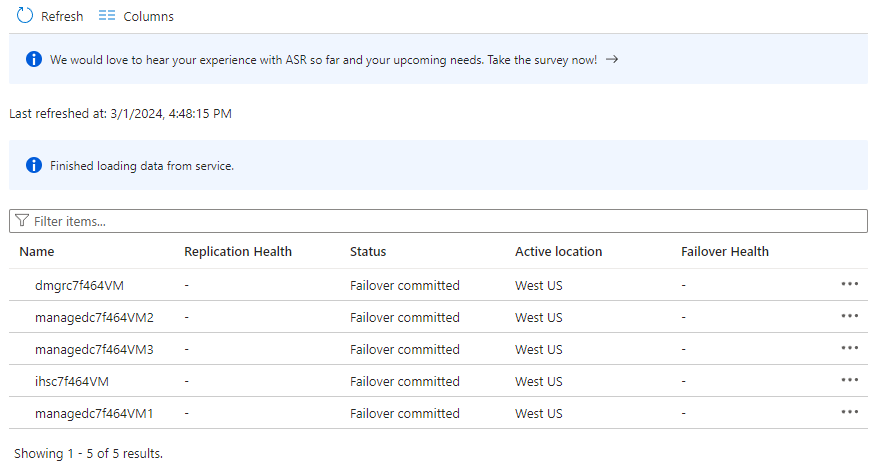
Seleccione Elementos del plan de recuperación. Debería ver 5 elementos enumerados como Conmutación por error confirmada.



Deshabilitación de la replicación
Siga estos pasos para deshabilitar la replicación de los elementos del plan de recuperación y, a continuación, elimine el plan de recuperación:
Para cada elemento de Elementos del plan de recuperación, seleccione el botón de puntos suspensivos (...) y, a continuación, seleccione Deshabilitar replicación.
Si se le pide que proporcione una razón para deshabilitar la protección para esta máquina virtual, seleccione la prefiera; por ejemplo, He completado la migración de mi aplicación. Seleccione Aceptar.
Repita el paso 1 hasta que deshabilite la replicación para todos los elementos.
Supervise el proceso en las notificaciones hasta que se complete.
Seleccione Información general>Eliminar. Seleccione Sí para confirmar la eliminación.

Preparación para la conmutación por recuperación: reprotección del sitio de conmutación por error
La región secundaria es ahora el sitio de conmutación por error y activo. Debe volver a protegerla en la región primaria.
En primer lugar, siga estos pasos para limpiar los recursos que no se usan y que el servicio Azure Site Recovery va a replicar en la región primaria más adelante. No solo puede eliminar el grupo de recursos, ya que Site Recovery restaura los recursos en el grupo de recursos existente.
- En el cuadro de búsqueda de la parte superior de Azure Portal, escriba Grupos de recursos y seleccione Grupos de recursos en los resultados de la búsqueda.
- Seleccione el nombre del grupo de recursos para la región primaria, por ejemplo,
was-cluster-eastus-mjg022624. Ordene los elementos por Tipo en la página Grupo de recursos. - Siga estos pasos para eliminar las máquinas virtuales:
- Seleccione el filtro Tipo y, a continuación, seleccione Máquina virtual en la lista desplegable Valor.
- Seleccione Aplicar.
- Seleccione todas las máquinas virtuales, seleccione Eliminar y escriba eliminar para confirmar la eliminación.
- Seleccione Eliminar.
- Supervise el proceso en las notificaciones hasta que se complete.
- Siga estos pasos para eliminar los discos:
- Seleccione el filtro Tipo y, a continuación, seleccione Discos en la lista desplegable Valor.
- Seleccione Aplicar.
- Seleccione todos los discos, seleccione Eliminar y escriba eliminar para confirmar la eliminación.
- Seleccione Eliminar.
- Supervise el proceso en las notificaciones y espere hasta que se complete.
- Siga estos pasos para eliminar los puntos de conexión:
- Seleccione el filtro Tipo y seleccione Punto de conexión privado en la lista desplegable Valor.
- Seleccione Aplicar.
- Seleccione todos los puntos de conexión privados, seleccione Eliminar y, a continuación, escriba eliminar para confirmar la eliminación.
- Seleccione Eliminar.
- Supervise el proceso en las notificaciones hasta que se complete. Omita este paso si el tipo Punto de conexión privado no aparece en la lista.
- Siga estos pasos para eliminar las interfaces de red:
- Seleccione el filtro Tipo > seleccione Interfaz de red en la lista desplegable Valor.
- Seleccione Aplicar.
- Seleccione todas las interfaces de red, seleccione Eliminar y escriba eliminar para confirmar la eliminación.
- Seleccione Eliminar. Supervise el proceso en las notificaciones hasta que se complete.
- Siga estos pasos para eliminar cuentas de almacenamiento:
- Seleccione el filtro Tipo > seleccione Cuenta de almacenamiento en la lista desplegable Valor.
- Seleccione Aplicar.
- Seleccione todas las cuentas de almacenamiento, seleccione Eliminar y, a continuación, escriba eliminar para confirmar la eliminación.
- Seleccione Eliminar. Supervise el proceso en las notificaciones hasta que se complete.
A continuación, siga los mismos pasos de la sección Configuración de la recuperación ante desastres para el clúster mediante Azure Site Recovery para la región primaria, excepto las siguientes diferencias:
- En la sección Creación de un almacén de Recovery Services, siga estos pasos:
- Seleccione el grupo de recursos implementado en la región primaria; por ejemplo,
was-cluster-eastus-mjg022624. - Escriba otro nombre para el almacén de servicios; por ejemplo,
recovery-service-vault-eastus-mjg022624. - En Región, seleccione Este de EE. UU. .
- Seleccione el grupo de recursos implementado en la región primaria; por ejemplo,
- En Habilitar replicación, siga estos pasos:
- En Región, en Origen, seleccione Oeste de EE. UU.
- En Configuración de replicación, siga estos pasos:
- En Grupo de recursos de destino, seleccione el grupo de recursos existente implementado en la región primaria, por ejemplo,
was-cluster-eastus-mjg022624. - En Conmutación por error de la red virtual, seleccione la red virtual existente en la región primaria.
- En Grupo de recursos de destino, seleccione el grupo de recursos existente implementado en la región primaria, por ejemplo,
- En Crear un plan de recuperación, en Origen, seleccione Oeste de EE. UU. y, en Destino, seleccione Este de EE. UU.
- Omita los pasos de la sección Configuración de red adicional para la región secundaria porque creó y configuró estos recursos anteriormente.
Nota:
Es posible que observe que Azure Site Recovery admite la reprotección de máquinas virtuales cuando existe la máquina virtual de destino. Para obtener más información, consulte la sección Reprotección de la máquina virtual del Tutorial: Conmutación por error de máquinas virtuales de Azure a una región secundaria. Debido al enfoque que estamos tomando para WebSphere, esta característica no funciona. El motivo es que los únicos cambios entre el disco de origen y el disco de destino se sincronizan para el clúster de WebSphere, en función del resultado de la comprobación. Para reemplazar la funcionalidad de la característica de reprotección de máquinas virtuales, en este tutorial se establece una nueva replicación desde el sitio secundario al sitio primario después de la conmutación por error. Todos los discos se copian de la región que ha conmutado por error a la nueva región primaria. Para obtener más información, consulte la sección ¿Qué ocurre durante la reprotección? de Reprotección de máquinas virtuales de Azure conmutadas por error en la región primaria.
Conmutación por recuperación al sitio principal
Siga los mismos pasos de la sección Conmutación por error al sitio secundario para conmutar por recuperación al sitio principal, incluido el servidor de base de datos y el clúster, excepto las siguientes diferencias:
- Seleccione el almacén del servicio de recuperación implementado en la región primaria, por ejemplo,
recovery-service-vault-eastus-mjg022624. - Seleccione el grupo de recursos implementado en la región primaria; por ejemplo,
was-cluster-eastus-mjg022624. - Después de habilitar el acceso externo a WebSphere Integrated Solutions Console y a la aplicación de ejemplo en la región primaria, vuelva a consultar las pestañas del explorador de WebSphere Integrated Solutions Console y la aplicación de ejemplo para el clúster principal que abrió anteriormente. Compruebe que funcionan como se espera. Dependiendo del tiempo necesario para la conmutación por recuperación, es posible que no vea los datos de sesión mostrados en la sección Nuevo café de la interfaz de usuario de la aplicación de ejemplo si expiró más de una hora antes.
- En la sección Confirmar la conmutación por error, seleccione el almacén de Recovery Services implementado en el principal, por ejemplo,
recovery-service-vault-eastus-mjg022624. - En el perfil de Traffic Manager, debería ver que el punto de conexión
myPrimaryEndpointestá En línea y el punto de conexiónmyFailoverEndpointestá Degradado. - En la sección Preparación para la conmutación por recuperación: reprotección del sitio de conmutación por error, siga estos pasos:
- La región primaria es el sitio de conmutación por error y está activo, por lo que debe volver a protegerla en la región secundaria.
- Limpie el recurso implementado en la región secundaria; por ejemplo, los recursos implementados en
was-cluster-westus-mjg022624. - Siga los mismos pasos de la sección Configuración de la recuperación ante desastres para el clúster mediante Azure Site Recovery para proteger la región primaria en la región secundaria, excepto los siguientes cambios:
- Omita los pasos de la sección Creación de un almacén de Recovery Services porque creó uno anteriormente, por ejemplo,
recovery-service-vault-westus-mjg022624. - En Habilitar replicación>Configuraciónd de replicación>Red virtual de conmutación por error, seleccione la red virtual existente en la región secundaria.
- Omita los pasos de la sección Configuración de red adicional para la región secundaria porque creó y configuró estos recursos anteriormente.
- Omita los pasos de la sección Creación de un almacén de Recovery Services porque creó uno anteriormente, por ejemplo,
Limpieza de recursos
Si no va a seguir usando los clústeres de WebSphere y otros componentes, siga estos pasos para eliminar los grupos de recursos para limpiar los recursos usados en este tutorial:
- Escriba el nombre del grupo de recursos de los servidores de Azure SQL Database, por ejemplo,
myResourceGroup, en el cuadro de búsqueda situado en la parte superior de Azure Portal y seleccione el grupo de recursos coincidente en los resultados de búsqueda. - Seleccione Eliminar grupo de recursos.
- En Escriba el nombre del grupo de recursos para confirmar la eliminación, escriba el nombre del grupo de recursos.
- Seleccione Eliminar.
- Repita los pasos del 1 al 4 para el grupo de recursos de Traffic Manager; por ejemplo,
myResourceGroupTM1. - En el cuadro de búsqueda de la parte superior de Azure Portal, escriba Almacenes de Recovery Services y, a continuación, seleccione Almacenes de Recovery Services en los resultados de la búsqueda.
- Seleccione el nombre del almacén de Recovery Services; por ejemplo,
recovery-service-vault-westus-mjg022624. - En Administrar, seleccione Recovery Plans (Site Recovery) (Planes de recuperación (Site Recovery)). Seleccione el plan de recuperación que ha creado, por ejemplo,
recovery-plan-mjg022624. - Siga los mismos pasos de la sección Deshabilitar la replicación para quitar bloqueos en elementos replicados.
- Repita los pasos del 1 al 4 para el grupo de recursos del clúster principal de WebSphere; por ejemplo,
was-cluster-westus-mjg022624. - Repita los pasos del 1 al 4 para el grupo de recursos del clúster secundario de WebSphere; por ejemplo,
was-cluster-eastus-mjg022624.
Pasos siguientes
En este tutorial, ha configurado una solución de alta disponibilidad y recuperación ante desastres que consta de un nivel de infraestructura de aplicación activo-pasivo con un nivel de base de datos activo-pasivo y en el que ambos niveles abarcan dos sitios geográficamente diferentes. En el primer sitio, tanto el nivel de infraestructura de la aplicación como el nivel de base de datos están activos. En el segundo sitio, el dominio secundario se restaura con el servicio Azure Site Recovery y la base de datos secundaria está en espera.
Continúe explorando las siguientes referencias para conocer más opciones para compilar soluciones de alta disponibilidad y recuperación ante desastres y ejecutar WebSphere en Azure: