Confiabilidad en Azure Traffic Manager
Este artículo contiene la compatibilidad con la recuperación ante desastres entre regiones y la continuidad empresarial para Azure Traffic Manager.
Recuperación ante desastres entre regiones y continuidad empresarial
La recuperación ante desastres (DR) consiste en recuperarse de eventos de alto impacto, como desastres naturales o implementaciones con errores, lo que produce tiempo de inactividad y pérdida de datos. Independientemente de la causa, el mejor remedio para un desastre es un plan de recuperación ante desastres bien definido y probado y un diseño de aplicaciones que apoye activamente la recuperación ante desastres. Antes de empezar a pensar en la creación del plan de recuperación ante desastres, vea Recomendaciones para diseñar una estrategia de recuperación ante desastres.
En lo que respecta a la recuperación ante desastres, Microsoft usa el modelo de responsabilidad compartida. En un modelo de responsabilidad compartida, Microsoft garantiza que la infraestructura de línea base y los servicios de plataforma estén disponibles. Al mismo tiempo, muchos servicios de Azure no replican automáticamente datos ni se revierten desde una región con errores para realizar la replicación cruzada en otra región habilitada. Para esos servicios, es responsable de configurar un plan de recuperación ante desastres que funcione para la carga de trabajo. La mayoría de los servicios que se ejecutan en ofertas de plataforma como servicio (PaaS) de Azure proporcionan características e instrucciones para admitir la recuperación ante desastres y puede usar características específicas del servicio para admitir la recuperación rápida para ayudar a desarrollar el plan de recuperación ante desastres.
Azure Traffic Manager es un equilibrador de carga de tráfico basado en DNS que permite distribuir el tráfico a las aplicaciones orientadas al público en regiones globales de Azure. Traffic Manager también proporciona puntos de conexión públicos con alta disponibilidad y rápida capacidad de respuesta.
Traffic Manager usa DNS para dirigir las solicitudes del cliente al punto de conexión de servicio adecuado en función de un método de enrutamiento del tráfico. Traffic Manager también proporciona supervisión de estado de todos los puntos de conexión. El punto de conexión de puede ser cualquier servicio accesible desde Internet hospedado dentro o fuera de Azure. Traffic Manager proporciona una serie de métodos de enrutamiento del tráfico y opciones de supervisión del punto de conexión para satisfacer las distintas necesidades de las aplicaciones y los modelos de conmutación automática por error. Traffic Manager es resistente a errores, incluidos los que afecten a toda una región de Azure.
Recuperación ante desastres en la geografía de varias regiones
DNS es uno de los mecanismos más eficaces para desviar el tráfico de red. DNS es eficaz porque DNS suele ser global y externo al centro de datos. DNS también está aislado de cualquier error a nivel regional o de zona de disponibilidad (AZ).
Hay dos aspectos técnicos en la configuración de la arquitectura de recuperación ante desastres:
El uso de un mecanismo de implementación para replicar instancias, datos y configuraciones entre entornos principales y en espera. Este tipo de recuperación ante desastres se puede realizar de forma nativa a través de Azure Site Recovery, consulte Documentación de Azure Site Recovery mediante dispositivos o servicios de asociados de Microsoft Azure como Veritas o NetApp.
El desarrollo de una solución para desviar el tráfico de red y el tráfico web desde el sitio principal al sitio en espera. Este tipo de recuperación ante desastres se puede lograr con Azure DNS, Azure Traffic Manager (DNS) o equilibradores de carga globales de otros fabricantes.
Este artículo se centra específicamente en la planificación de la recuperación ante desastres de Azure Traffic Manager.
Detección, notificación y administración de interrupciones
Durante un desastre, se sondea el punto de conexión principal y el estado cambia a degradado y el sitio de recuperación ante desastres permanece En línea. De forma predeterminada, Traffic Manager envía todo el tráfico al punto de conexión principal (prioridad más alta). Si el punto de conexión principal aparece degradado, Traffic Manager enruta el tráfico al segundo punto de conexión mientras no funcione correctamente. Es posible configurar más puntos de conexión en Traffic Manager que pueden actuar como puntos de conexión de conmutación por error adicionales o como equilibradores de carga para compartir la carga entre puntos de conexión.
Configuración de la recuperación ante desastres y la detección de interrupciones
Cuando hay arquitecturas complejas y varios conjuntos de recursos capaces de realizar la misma función, puede configurar Azure Traffic Manager (basado en DNS) para comprobar el mantenimiento de los recursos y enrutar el tráfico desde el recurso que no es correcto hacia el recurso correcto.
En el ejemplo siguiente, la región primaria y la región secundaria tienen una implementación completa. Esta implementación incluye los servicios en la nube y una base de datos sincronizada.
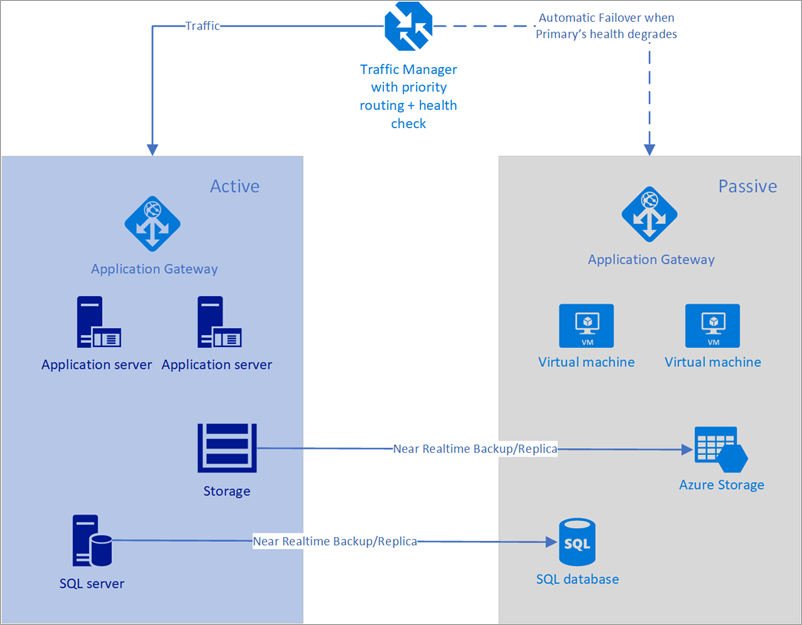
Figura: conmutación por error automática con Azure Traffic Manager
Sin embargo, la región principal es la única que controla activamente las solicitudes de red de los usuarios. La región secundaria no pasa a ser la activa hasta que la región principal experimenta una interrupción del servicio. En ese caso, todas las solicitudes de red nuevas se enrutan a la región secundaria. Puesto que la copia de seguridad de la base de datos es casi instantánea, los equilibradores de carga tienen direcciones IP cuyo mantenimiento se puede comprobar y las instancias están siempre en ejecución, esta topología proporciona una opción para alcanzar un RTO bajo y una conmutación por error sin ninguna intervención manual. La región de conmutación por error secundaria debe estar lista para empezar a trabajar inmediatamente después de que se produzca un error en la región principal.
Este escenario es ideal para el uso de Azure Traffic Manager, que dispone de sondeos integrados para varios tipos de comprobaciones de mantenimiento incluidas HTTP, HTTPS y TCP. Azure Traffic Manager también tiene un motor de reglas que se puede configurar para conmutar por error cuando se produce un error, como se describe a continuación. Veamos la solución siguiente con Traffic Manager:
- El cliente tiene el punto de conexión de la región 1, conocido como prod.contoso.com, con la dirección IP estática 100.168.124.44 y un punto de conexión en la región 2, conocido como dr.contoso.com, con la dirección IP estática 100.168.124.43.
- Cada uno de estos entornos tiene como front-end una propiedad de cara al público; por ejemplo, un equilibrador de carga. El equilibrador de carga se puede configurar para que tenga un punto de conexión basado en DNS o un nombre de dominio completo (FQDN), como se muestra a continuación.
- Todas las instancias en la región 2 tienen replicación casi en tiempo real con la región 1. Además, las imágenes de las máquinas están actualizadas y todo el software y los datos de configuración tienen aplicadas las actualizaciones y están en consonancia con la región 1.
- El escalado automático está preconfigurado con antelación.
Para configurar la conmutación por error con Azure Traffic Manager:
Crear un nuevo perfil de Azure Traffic Manager Cree un nuevo perfil de Azure Traffic Manager con el nombre contoso123 y seleccione el método de enrutamiento por prioridad. Si tiene un grupo de recursos existente y desea asociarlo, puede seleccionar un grupo de recursos existente; de lo contrario, cree un nuevo grupo de recursos.
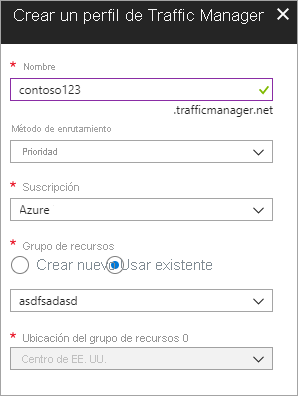
Ilustración: creación de un perfil de Traffic Manager
Creación de puntos de conexión en el perfil de Traffic Manager
En este paso, creará los puntos de conexión que apuntan a los sitios de producción y de recuperación ante desastres. A continuación, elija el Tipo como un punto de conexión externo, pero si el recurso está hospedado en Azure, también puede elegir Punto de conexión de Azure. Si elige Punto de conexión de Azure, a continuación, seleccione un Recurso de destino, que puede ser una instancia de App Service o una Dirección IP pública que es asignada por Azure. La prioridad se establece en 1, ya que es el servicio principal para la región 1. Del mismo modo, cree también el punto de conexión de recuperación ante desastres en Traffic Manager.
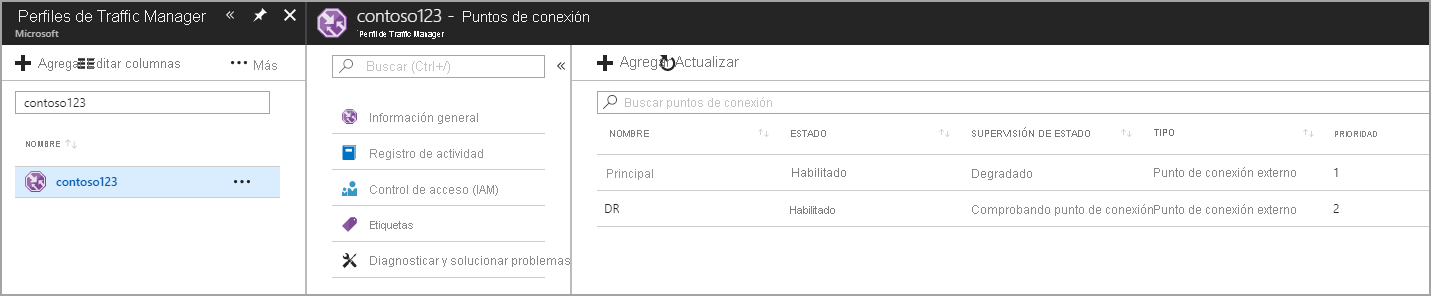
Figura: creación de puntos de conexión de recuperación ante desastres
Configuración de la comprobación de mantenimiento y de la conmutación por error
En este paso, se establece el TTL de DNS en 10 segundos, que es respetado por la mayoría de los sistemas de resolución recursivos orientados a Internet. Esta configuración significa que ningún sistema de resolución DNS almacenará en memoria caché la información durante más de 10 segundos.
Para la configuración de supervisión del punto de conexión, la ruta de acceso actualmente se establece en / o raíz, aunque puede personalizar la configuración del punto de conexión para que evalúe una ruta de acceso; por ejemplo, prod.contoso.com/index.
En el ejemplo siguiente se muestra https como el protocolo de sondeo. No obstante, también puede elegir http o tcp. La elección del protocolo depende de la aplicación final. El intervalo de sondeo se establece en 10 segundos, lo que permite un sondeo rápido y los reintentos se establecen en 3. Como resultado, Traffic Manager conmutará por error al segundo punto de conexión si tres intervalos consecutivos registran un error.
La fórmula siguiente define el tiempo total de una conmutación por error automatizada:
Time for failover = TTL + Retry * Probing intervalY en este caso, el valor es 10 + 3 * 10 = 40 segundos (máximo).
Si los reintentos se establecen en 1 y el valor de TTL se establece en 10 segundos, el tiempo de la recuperación por error es 10 + 1 * 10 = 20 segundos.
Establezca los reintentos en un valor mayor que 1 para eliminar las posibilidades de conmutaciones por error debidas a falsos positivos o a cualquier señal en la red de escasa relevancia.
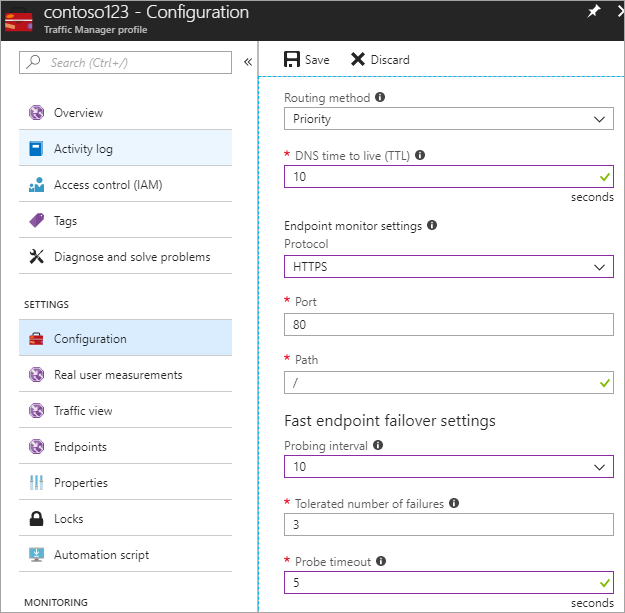
Figura: configuración de la comprobación de mantenimiento y de la conmutación por error
Pasos siguientes
Más información acerca de Azure Traffic Manager.
Obtenga más información sobre Azure DNS.