Tutorial: Migración de Oracle WebLogic Server a máquinas virtuales de Azure con alta disponibilidad y recuperación ante desastres
En este tutorial se muestra una manera sencilla y eficaz de implementar alta disponibilidad y recuperación ante desastres (HA/DR) para Java mediante Oracle WebLogic Server (WLS) en máquinas virtuales de Azure. La solución muestra cómo lograr un objetivo de tiempo de recuperación (RTO) y un objetivo de punto de recuperación (RPO) bajos mediante una sencilla aplicación de Jakarta EE controlada por base de datos que se ejecuta en WLS. La alta disponibilidad y recuperación ante desastres es un tema complejo, con muchas soluciones posibles. La mejor solución depende de sus requisitos únicos. Para ver otras formas de implementar alta disponibilidad y recuperación ante desastres, consulte los recursos al final de este artículo.
En este tutorial, aprenderá a:
- Use los procedimientos recomendados optimizados para Azure para lograr alta disponibilidad y recuperación ante desastres.
- Configure un grupo de conmutación por error de Microsoft Azure SQL Database en regiones emparejadas.
- Configure clústeres WLS emparejados en máquinas virtuales de Azure.
- Configure una instancia de Azure Traffic Manager.
- Configure la alta disponibilidad y recuperación ante desastres combinada para clústeres de WLS.
- Prueba de una conmutación por error de principal a secundaria.
En el diagrama siguiente se muestra la arquitectura que se construye:

Azure Traffic Manager comprueba el estado de las regiones y enruta el tráfico en consecuencia al nivel de aplicación. La región primaria y secundaria tienen una implementación completa del clúster de WLS. Sin embargo, la región primaria es la única que atiende activamente las solicitudes de red de los usuarios. La región secundaria es pasiva y se activa para recibir tráfico solo cuando la región primaria experimenta una interrupción del servicio. Azure Traffic Manager usa la característica de comprobación de estado de Azure Application Gateway para implementar este enrutamiento condicional. El clúster principal de WLS está en funcionamiento y el clúster secundario está apagado. El RTO de conmutación por error geográfica del nivel de aplicación depende de la hora de inicio de las máquinas virtuales y de la ejecución del clúster WLS secundario. El RPO depende de Azure SQL Database porque los datos se conservan y replican en el grupo de conmutación por error de Azure SQL Database.
El nivel de base de datos consta de un grupo de conmutación por error de Azure SQL Database con un servidor principal y un servidor secundario. El servidor principal está en modo de lectura y escritura activo y está conectado al clúster de WLS principal. El servidor secundario está en modo de solo lectura pasiva y está conectado al clúster de WLS secundario. Una conmutación por error geográfica cambia todas las bases de datos secundarias del grupo al rol principal. Para obtener información sobre el RPO y el RTO de la conmutación por error geográfica de Azure SQL Database, consulte Información general sobre la continuidad empresarial.
Este artículo se redactó con el servicio Azure SQL Database porque el artículo se basa en las características de alta disponibilidad (HA) de ese servicio. Otras opciones de base de datos son posibles, pero debe tener en cuenta las características de alta disponibilidad de la base de datos que elija. Para obtener más información, incluida la información sobre cómo optimizar la configuración de orígenes de datos para la replicación, consulte Configuración de orígenes de datos para la implementación activa-pasiva de Oracle Fusion Middleware.
Requisitos previos
- Suscripción a Azure. Si no tiene una suscripción a Azure, cree una cuenta gratuita antes de empezar.
- Asegúrese de que se le ha asignado el rol
Ownero los rolesContributoryUser Access Administratoren la suscripción. Para comprobar la asignación, siga los pasos descritos en Enumeración de asignaciones de roles de Azure mediante Azure Portal. - Prepare una máquina local con Windows, Linux o macOS instalado.
- Instalación y configuración de Git.
- Instale una implementación de Java SE, versión 17 o posterior, por ejemplo, la compilación de Microsoft de OpenJDK.
- Instale Maven, versión 3.9.3 o posterior.
Configuración de un grupo de conmutación por error de Azure SQL Database en regiones emparejadas
En esta sección, creará un grupo de conmutación por error de Azure SQL Database en regiones emparejadas para su uso con los clústeres y la aplicación de WLS. En una sección posterior, configurará WLS para almacenar sus datos de sesión y los datos del registro de transacciones (TLOG) en esta base de datos. Esta práctica es coherente con la arquitectura de disponibilidad máxima (MAA) de Oracle. Esta guía proporciona una adaptación de Azure para MAA. Para más información sobre MAA, consulte Arquitectura de máxima disponibilidad de Oracle.
En primer lugar, cree la instancia principal de Azure SQL Database siguiendo los pasos de Azure Portal descritos en Inicio rápido: Creación de una base de datos única - Azure SQL Database. Siga los pasos hasta la sección "Limpiar recursos", pero sin incluirla. Siga las instrucciones a medida que avanza por el artículo y vuelva a este artículo después de crear y configurar la instancia de Azure SQL Database.
Cuando llegue a la sección Creación de una base de datos única, siga los pasos que se indican a continuación:
- En el paso 4 para crear un nuevo grupo de recursos, guarde el valor de Nombre del grupo de recursos; por ejemplo, myResourceGroup.
- En el paso 5 para el nombre de la base de datos, guarde el valor Nombre de la base de datos; por ejemplo, mySampleDatabase.
- En el paso 6 para crear el servidor, siga estos pasos:
- Guarde el nombre de servidor único; por ejemplo, sqlserverprimary-ejb120623.
- En Ubicación, seleccione (EE. UU.) Este de EE. UU.
- En Método de autenticación, seleccione Usar autenticación de SQL.
- Guarde el valor de Inicio de sesión de administrador del servidor; por ejemplo, azureuser.
- Guarde el valor de Contraseña.
- En el paso 8, en Entorno de carga de trabajo, seleccione Desarrollo. Examine la descripción y tenga en cuenta otras opciones para la carga de trabajo.
- En el paso 11, para Redundancia de almacenamiento de copia de seguridad, seleccione Almacenamiento de copia de seguridad con redundancia local. Considere otras opciones para las copias de seguridad. Para más información, consulte la sección Redundancia del almacenamiento de copias de seguridad de Copias de seguridad automatizadas en Azure SQL Database.
- En el paso 14, en la configuración de las reglas de Firewall, para Permitir que los servicios y recursos de Azure accedan a este servidor, seleccione Sí.
Cuando llegue a la sección Consulta de la base de datos, siga estos pasos:
En el paso 3, escriba la información de inicio de sesión del administrador del servidor de Autenticación de SQL para iniciar sesión.
Nota:
Si se produce un error de inicio de sesión con un mensaje de error similar a El cliente con la dirección IP 'xx.xx.xx.xx' no puede acceder al servidor, seleccione Allowlist IP xx.xx.xx.xx en el servidor <your-sqlserver-name> al final del mensaje de error. Espere hasta que las reglas de firewall del servidor completen la actualización y, a continuación, seleccione Aceptar de nuevo.
Después de ejecutar la consulta de ejemplo en el paso 5, borre el editor y cree tablas.
Escriba la siguiente consulta para crear el esquema para TLOG.
create table TLOG_msp1_WLStore (ID DECIMAL(38) NOT NULL, TYPE DECIMAL(38) NOT NULL, HANDLE DECIMAL(38) NOT NULL, RECORD VARBINARY(MAX) NOT NULL, PRIMARY KEY (ID));
create table TLOG_msp2_WLStore (ID DECIMAL(38) NOT NULL, TYPE DECIMAL(38) NOT NULL, HANDLE DECIMAL(38) NOT NULL, RECORD VARBINARY(MAX) NOT NULL, PRIMARY KEY (ID));
create table TLOG_msp3_WLStore (ID DECIMAL(38) NOT NULL, TYPE DECIMAL(38) NOT NULL, HANDLE DECIMAL(38) NOT NULL, RECORD VARBINARY(MAX) NOT NULL, PRIMARY KEY (ID));
create table wl_servlet_sessions (wl_id VARCHAR(100) NOT NULL, wl_context_path VARCHAR(100) NOT NULL, wl_is_new CHAR(1), wl_create_time DECIMAL(20), wl_is_valid CHAR(1), wl_session_values VARBINARY(MAX), wl_access_time DECIMAL(20), wl_max_inactive_interval INTEGER, PRIMARY KEY (wl_id, wl_context_path));
Después de una ejecución correcta, debería ver el mensaje Consulta correcta: Filas afectadas: 0.
Estas tablas de base de datos se usan para almacenar datos de sesión y registro de transacciones (TLOG) para los clústeres y aplicaciones de WLS. Para obtener más información, consulte Uso de un almacén de TLOG de JDBC y Uso de una base de datos para el almacenamiento persistente (persistencia de JDBC).
A continuación, cree un grupo de conmutación por error de Azure SQL Database siguiendo los pasos de Azure Portal en Configuración de un grupo de conmutación por error para Azure SQL Database. Solo necesita las secciones siguientes: Crear grupo de conmutación por error y Probar conmutación por error planeada. Siga estos pasos a medida que avanza por el artículo y vuelva a este artículo después de crear y configurar el grupo de conmutación por error de Azure SQL Database.
Cuando llegue a la sección Crear grupo de conmutación por error, siga estos pasos:
- En el paso 5 para crear el grupo de conmutación por error, seleccione la opción para crear un nuevo servidor secundario y, a continuación, siga estos pasos:
- Escriba y guarde el nombre del grupo de conmutación por error; por ejemplo, failovergroupname-ejb120623.
- Escriba y guarde el nombre de servidor único; por ejemplo, sqlserversecondary-ejb120623.
- Introduzca el mismo usuario y contraseña que en su servidor principal.
- En Ubicación, seleccione una región diferente a la que usó para la base de datos principal.
- Asegúrese de que 'Permitir que los servicios de Azure accedan al servidor' esté seleccionado.
- En el paso 5 para configurar las Bases de datos del grupo, seleccione la base de datos que creó en el servidor principal; por ejemplo, mySampleDatabase.
- En el paso 5 para crear el grupo de conmutación por error, seleccione la opción para crear un nuevo servidor secundario y, a continuación, siga estos pasos:
Después de completar todos los pasos de la sección Probar conmutación por error planeada, mantenga abierta la página del grupo de conmutación por error y úsela para la prueba de conmutación por error de los clústeres de WLS más adelante.
Nota:
Este artículo le guía sobre cómo crear una base de datos única en Azure SQL Database con autenticación de SQL para simplificar, dado que la configuración de alta disponibilidad y recuperación ante desastres, en la que se centra este artículo, ya es muy compleja. Una práctica más segura consiste en usar la Autenticación de Microsoft Entra para Azure SQL para autenticar la conexión del servidor de bases de datos. Para obtener información sobre cómo configurar la conexión de base de datos con la autenticación de Microsoft Entra, consulte Configuración de conexiones de base de datos sin contraseña para aplicaciones Java en Oracle WebLogic Server.
Configuración de clústeres de WLS emparejados en máquinas virtuales de Azure
En esta sección, creará dos clústeres de WLS en máquinas virtuales de Azure mediante la oferta de Clúster de Oracle WebLogic Server en máquinas virtuales de Azure. El clúster del Este de EE. UU. es principal y se configura como el clúster activo más adelante. El clúster de Oeste de EE. UU. es secundario y se configura como el clúster pasivo más adelante.
Configuración del clúster de WLS principal
En primer lugar, abra la oferta de Clúster de Oracle WebLogic Server en máquinas virtuales de Azure en el explorador y seleccione Crear. Debería ver el panel Aspectos básicos de la oferta.
Siga estos pasos para completar el panel Aspectos básicos:
- Asegúrese de que el valor que se muestra para Suscripción es el mismo que tiene los roles enumerados en la sección de requisitos previos.
- En el campo Grupo de recursos, seleccione Crear nuevo y rellene un valor único para el grupo de recursos, por ejemplo, wls-cluster-eastus-ejb120623.
- En Detalles de la instancia, en Región, seleccione Este de EE. UU.
- En Credenciales para máquinas virtuales y WebLogic, proporcione una contraseña para la cuenta de administrador de la máquina virtual y el administrador de WebLogic, respectivamente. Guarde el nombre de usuario y la contraseña del administrador de WebLogic. Para mejorar la seguridad, plantéese usar una clave pública SSH como tipo de autenticación de máquina virtual.
- Deje los valores predeterminados para los demás campos.
- Seleccione Siguiente para ir al panel Configuración de TLS/SSL.

Deje los valores predeterminados en el panel Configuración de TLS/SSL, seleccione Siguiente para ir al panel Azure Application Gateway y, a continuación, siga estos pasos.
- En Conectar a Azure Application Gateway, seleccione Sí.
- En la opción Seleccionar certificado TLS/SSL deseado, seleccione Generar un certificado autofirmado.
- Seleccione Siguiente para ir al panel Redes.

Debería ver todos los campos rellenados previamente con los valores predeterminados en el panel Redes. Siga estos pasos para guardar la configuración de red:
Seleccione Editar red virtual. Guarde el espacio de direcciones de la red virtual; por ejemplo, 10.1.4.0/23.
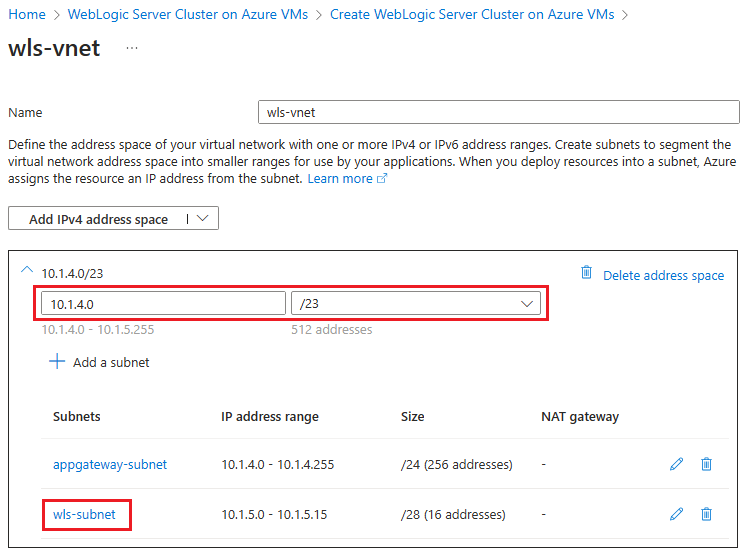
Seleccione
wls-subnetpara editar la subred. En Detalles de subred, guarde la dirección inicial y el tamaño de la subred; por ejemplo, 10.1.5.0 y /28.
Si realiza alguna modificación, guarde los cambios.
Vuelva al panel Redes.
Seleccione Siguiente para ir al panel Base de datos.


En los pasos siguientes se mostrarán cómo completar el panel de la base de datos :
- En ¿Conectarse a una base de datos?, seleccione Sí.
- En Elegir tipo de base de datos, seleccione Microsoft SQL Server (compatibilidad con conexión sin contraseña).
- En Nombre JNDI, escriba jdbc/WebLogicCafeDB.
- En Cadena de conexión de origen de datos, reemplace los marcadores de posición por los valores que guardó en la sección anterior para la base de datos SQL principal; por ejemplo, jdbc:sqlserver://sqlserverprimary-ejb120623.database.windows.net:1433;database=mySampleDatabase.
- En Protocolo de transacción global, seleccione Ninguno.
- En Nombre de usuario de base de datos, reemplace los marcadores de posición por los valores que guardó en la sección anterior para la base de datos SQL principal, por ejemplo, azureuser@sqlserverprimary-ejb120623.
- Escriba la contraseña de inicio de sesión del administrador del servidor que guardó anteriormente para Contraseña de base de datos. Introduzca el mismo valor para Confirmar contraseña.
- Deje los valores predeterminados para los demás campos.
- Seleccione Revisar + crear.
- Espere hasta que se complete correctamente el proceso Ejecutando validación final... y, a continuación, seleccione Crear.

Nota:
Este artículo le guía para conectarse a una base de datos de Azure SQL Database con autenticación SQL por simplicidad, ya que la configuración de alta disponibilidad y recuperación ante desastres en la que este artículo se centra ya es muy compleja. Una práctica más segura consiste en usar la Autenticación de Microsoft Entra para Azure SQL para autenticar la conexión del servidor de bases de datos. Para obtener información sobre cómo configurar la conexión de base de datos con la autenticación de Microsoft Entra, consulte Configuración de conexiones de base de datos sin contraseña para aplicaciones Java en Oracle WebLogic Server.
Después de un tiempo, debería ver la página Implementación donde se muestra Implementación en curso.
Nota:
Si ve algún problema durante el proceso Ejecutando validación final..., corríjalo e inténtelo de nuevo.
En función de las condiciones de la red y de otras actividades de la región seleccionada, la implementación puede tardar hasta 50 minutos en completarse. Después, debería ver el texto Su implementación se ha completado en la página de implementación.
Mientras tanto, usted puede configurar el clúster WLS secundario en paralelo.
Configuración del clúster de WLS secundario
Siga los mismos pasos descritos en la sección Configuración del clúster de WLS principal para configurar el clúster de WLS secundario en la región de Oeste de EE. UU., excepto las siguientes diferencias:
En el panel Aspectos básicos, siga estos pasos:
- En el campo grupo de recursos , seleccione Crear nuevo y rellene un valor único diferente para el grupo de recursos; por ejemplo, wls-cluster-westtus-ejb120623.
- En Detalles de la instancia, en Región, seleccione Oeste de EE. UU.
En el panel Redes, siga estos pasos:
En Editar red virtual, escriba el mismo espacio de direcciones de la red virtual que el clúster de WLS principal; por ejemplo, 10.1.4.0/23.
Nota:
Debería ver un mensaje de advertencia similar al siguiente: El espacio de direcciones '10.1.4.0/23 (10.1.4.0 - 10.1.5.255)' se superpone con el espacio de direcciones '10.1.4.0/23 (10.1.4.0 - 10.1.5.255)' de la red virtual 'wls-vnet'. Las redes virtuales con espacio de direcciones superpuesto no se pueden emparejar. Si piensa emparejar estas redes virtuales, cambie el espacio de direcciones '10.1.4.0/23 (10.1.4.0 - 10.1.5.255)'. Puede omitir este mensaje porque necesita dos clústeres de WLS con la misma configuración de red.
En
wls-subnet, escriba la misma dirección inicial y tamaño de subred que el clúster principal de WLS; por ejemplo, 10.1.5.0 y /28.
En el panel de base de datos, siga estos pasos:
- En Cadena de conexión de origen de datos, reemplace los marcadores de posición por los valores que guardó en la sección anterior para la base de datos SQL secundaria; por ejemplo, jdbc:sqlserver://sqlserversecondary-ejb120623.database.windows.net:1433;database=mySampleDatabase.
- En Nombre de usuario de base de datos, reemplace los marcadores de posición por los valores que guardó en la sección anterior para la base de datos SQL secundaria, por ejemplo, azureuser@sqlserversecondary-ejb120623.
Reflejar la configuración de red de los dos clústeres
Durante la fase de reanudación de transacciones pendientes en el clúster de WLS secundario después de una conmutación por error, WLS comprueba la propiedad del almacén de TLOG. Para pasar correctamente la comprobación, todos los servidores administrados del clúster secundario deben tener la misma dirección IP privada que el clúster principal.
En esta sección se muestra cómo reflejar la configuración de red del clúster principal en el clúster secundario.
En primer lugar, siga estos pasos para configurar las opciones de red para el clúster principal una vez completada la implementación:
En el panel Información general sobre la implementación, seleccione Ir al grupo de recursos.
Seleccione el nombre de la interfaz de red
adminVM_NIC_with_pub_ip.- En Configuración, seleccione Configuraciones IP.
- Seleccione
ipconfig1. - En Configuración de dirección IP privada, seleccione Estática en Asignación. Guarde la dirección IP privada.
- Seleccione Guardar.
Vuelva al grupo de recursos del clúster de WLS principal y repita el paso 3 para las interfaces de red
mspVM1_NIC_with_pub_ip,mspVM2_NIC_with_pub_ip, andmspVM3_NIC_with_pub_ip.Espere hasta que finalicen todas las actualizaciones. Puede seleccionar el icono de notificaciones en el portal de Azure para abrir el panel de Notificaciones de para la supervisión del estado.

Vuelva al grupo de recursos del clúster principal de WLS y copie el nombre del recurso con el tipo Punto de conexión privado, por ejemplo, 7e8c8bsaep. Use ese nombre para buscar la interfaz de red restante; por ejemplo, 7e8c8bsaep.nic.c0438c1a-1936-4b62-864c-6792eec3741a. Selecciónela y siga los pasos anteriores para obtener su dirección IP privada.
A continuación, siga estos pasos para configurar las opciones de red del clúster secundario una vez completada la implementación:
En el panel Información general de la página de implementación , seleccione Ir al grupo de recursos.
Para las interfaces de red
adminVM_NIC_with_pub_ip,mspVM1_NIC_with_pub_ip,mspVM2_NIC_with_pub_ipymspVM3_NIC_with_pub_ip, siga los pasos anteriores para actualizar la asignación de direcciones IP privadas a Estática.Espere hasta que finalicen todas las actualizaciones.
Para las interfaces de red
mspVM1_NIC_with_pub_ip,mspVM2_NIC_with_pub_ipymspVM3_NIC_with_pub_ip, siga los pasos anteriores, pero actualice la dirección IP privada con el mismo valor usado con el clúster principal. Espere hasta que se complete la actualización actual de la interfaz de red antes de continuar con la siguiente.Nota:
No se puede cambiar la dirección IP privada de la interfaz de red que forma parte de un punto de conexión privado. Para reflejar fácilmente las direcciones IP privadas de las interfaces de red para los servidores administrados, considere la posibilidad de actualizar la dirección IP privada de
adminVM_NIC_with_pub_ipcon una dirección IP que no se use. En función de la asignación de direcciones IP privadas en los dos clústeres, es posible que tenga que actualizar también la dirección IP privada en el clúster principal.
En la tabla siguiente se muestra un ejemplo de reflejo de la configuración de red para dos clústeres:
| Clúster | interfaz de red | Dirección IP privada (antes) | Dirección IP privada (después) | Secuencia de actualización |
|---|---|---|---|---|
| Principal | 7e8c8bsaep.nic.c0438c1a-1936-4b62-864c-6792eec3741a |
10.1.5.4 |
10.1.5.4 |
|
| Principal | adminVM_NIC_with_pub_ip |
10.1.5.7 |
10.1.5.7 |
|
| Principal | mspVM1_NIC_with_pub_ip |
10.1.5.5 |
10.1.5.5 |
|
| Principal | mspVM2_NIC_with_pub_ip |
10.1.5.8 |
10.1.5.9 |
1 |
| Principal | mspVM3_NIC_with_pub_ip |
10.1.5.6 |
10.1.5.6 |
|
| Secundario | 1696b0saep.nic.2e19bf46-9799-4acc-b64b-a2cd2f7a4ee1 |
10.1.5.8 |
10.1.5.8 |
|
| Secundario | adminVM_NIC_with_pub_ip |
10.1.5.5 |
10.1.5.4 |
4 |
| Secundario | mspVM1_NIC_with_pub_ip |
10.1.5.7 |
10.1.5.5 |
5 |
| Secundario | mspVM2_NIC_with_pub_ip |
10.1.5.6 |
10.1.5.9 |
2 |
| Secundario | mspVM3_NIC_with_pub_ip |
10.1.5.4 |
10.1.5.6 |
3 |
Compruebe el conjunto de direcciones IP privadas de todos los servidores administrados, que consta del grupo de back-end de Azure Application Gateway que implementó en cada clúster. Si se actualiza, siga estos pasos para actualizar el grupo de back-end de Azure Application Gateway en consecuencia:
- Abra el grupo de recursos del clúster.
- Busque el recurso myAppGateway con el tipo Application Gateway. Haz clic para abrirlo.
- En la sección Configuración, seleccione Grupos de back-end y, a continuación, seleccione
myGatewayBackendPool. - Cambie los valores de Destinos de back-end con las direcciones IP privadas actualizadas y, a continuación, seleccione Guardar. Espere hasta que se complete.
- En la sección Configuración, seleccione Sondeos de estado y, a continuación, seleccione HTTPhealthProbe.
- Asegúrese de que la opción Deseo probar el estado de back-end antes de agregar el sondeo de estado esté seleccionada y, a continuación, seleccione Probar. Debería ver que el valor de Estado del grupo de back-end
myGatewayBackendPoolestá marcado como correcto. Si no es así, compruebe si las direcciones IP privadas se han actualizado según lo previsto y que las máquinas virtuales se están ejecutando, vuelva a probar el sondeo de estado. Debe solucionar y resolver el problema antes de continuar.
En el ejemplo siguiente, se actualiza el grupo de back-end de Azure Application Gateway para cada clúster:
| Clúster | Grupo de servidores de back-end de Azure Application Gateway | Destinos de back-end (antes) | Destinos de back-end (después) |
|---|---|---|---|
| Principal | myGatewayBackendPool |
(10.1.5.5, 10.1.5.8, 10.1.5.6) |
(10.1.5.5, 10.1.5.9, 10.1.5.6) |
| Secundario | myGatewayBackendPool |
(10.1.5.7, 10.1.5.6, 10.1.5.4) |
(10.1.5.5, 10.1.5.9, 10.1.5.6) |
Para automatizar el reflejo de la configuración de red, considere utilizar la CLI de Azure. Para más información, consulte Introducción a la CLI de Azure.
Comprobación de las implementaciones de los clústeres
Ha implementado una instancia de Azure Application Gateway y un servidor de administración de WLS en cada clúster. La instancia de Azure Application Gateway actúa como equilibrador de carga para todos los servidores administrados del clúster. El servidor de administración de WLS proporciona una consola web para la configuración del clúster.
Siga estos pasos para comprobar si la instancia de Azure Application Gateway y la consola de administración de WLS de cada clúster funcionan antes de pasar al paso siguiente:
- Regrese a la página de implementación y luego seleccione Salidas .
- Copie el valor de la propiedad appGatewayURL. Anexe la cadena weblogic/ready y, a continuación, abra esa dirección URL en una nueva pestaña del explorador. Debería ver una página vacía sin ningún mensaje de error. Si no es así, debe solucionar y resolver el problema antes de continuar.
- Copie y guarde el valor de la propiedad adminConsole. Ábralo en una nueva pestaña del explorador. Debería ver la página de inicio de sesión de la Consola de administración de WebLogic Server. Inicie sesión en la consola con el nombre de usuario y la contraseña del administrador de WebLogic que guardó anteriormente. Si no puede iniciar sesión, debe solucionar y resolver el problema antes de continuar.
Siga estos pasos para obtener la dirección IP de Azure Application Gateway para cada clúster. Estos valores se usarán al configurar Azure Traffic Manager más adelante.
- Abra el grupo de recursos donde se implementa el clúster; por ejemplo, seleccione Información general para volver al panel Información general de la página de implementación. A continuación, seleccione Ir al grupo de recursos.
- Encuentra el recurso
gwipcon el tipo dirección IP pública , y luego selecciónalo para abrirlo. Busque el campo Dirección IP y guarde su valor.
Configuración de una instancia de Azure Traffic Manager
En esta sección, creará una instancia de Azure Traffic Manager para distribuir el tráfico a las aplicaciones públicas en las regiones globales de Azure. El punto de conexión principal apunta a la instancia de Azure Application Gateway en el clúster de WLS principal y el punto de conexión secundario apunta a la instancia de Azure Application Gateway en el clúster de WLS secundario.
Cree un perfil de Azure Traffic Manager siguiendo Inicio rápido: Crear un perfil de Traffic Manager mediante el portal de Azure. Omita la sección Requisitos previos. Solo necesita las secciones siguientes: Crear un perfil de Traffic Manager, Agregar puntos de conexión de Traffic Manager y Probar perfil de Traffic Manager. Siga estos pasos a medida que avanza por estas secciones y vuelva a este artículo después de crear y configurar Azure Traffic Manager.
Cuando llegue a la sección Crear un perfil de Traffic Manager, en el paso 2, para Crear perfil de Traffic Manager, siga estos pasos:
- Guarde el nombre de perfil de Traffic Manager único para Nombre (por ejemplo,
tmprofile-ejb120623). - Guarde el nuevo nombre del grupo de recursos para Grupo de recursos; por ejemplo,
myResourceGroupTM1.
- Guarde el nombre de perfil de Traffic Manager único para Nombre (por ejemplo,
Cuando llegue a la sección Agregar puntos de conexión de Traffic Manager, siga estos pasos:
Realice esta acción adicional después del paso Seleccione el perfil en los resultados de la búsqueda
En Configuración, seleccione Configuración.
En Período de vida (TTL) de DNS, escriba 10.
En Configuración del monitor de punto de conexión, en Ruta de acceso, escriba /weblogic/ready.
En Configuración de conmutación por error de punto de conexión rápido, use los siguientes valores:
- En Sondeo interno, escriba 10.
- En Número tolerado de errores, escriba 3.
- En Tiempo de espera de sondeo, 5.
Seleccione Guardar. Espere hasta que se complete.
En el paso 4 para agregar el punto de conexión
myPrimaryEndpointprincipal, siga estos pasos:En Tipo de recurso de destino, seleccione Dirección IP pública.
Seleccione la lista desplegable Elegir dirección IP pública y escriba la dirección IP de Application Gateway implementada en el clúster de WLS Este de EE. UU. que guardó anteriormente. Debería ver una entrada coincidente. Selecciónela para Dirección IP pública.
En el paso 6 para añadir un punto de conmutación automática o un punto de conexión secundario
myFailoverEndpoint, debe seguir estos pasos:En Tipo de recurso de destino, seleccione Dirección IP pública.
Seleccione la lista desplegable Elegir dirección IP pública y escriba la dirección IP de Application Gateway implementada en el clúster de WLS de Oeste de EE. UU. 2 que guardó anteriormente. Debería ver una entrada coincidente. Selecciónela para Dirección IP pública.
Espere un rato. Seleccione Actualizar hasta que el valor de Estado de supervisión de ambos puntos de conexión sea En línea.
Cuando llegue a la sección Prueba de un perfil de Traffic Manager, siga estos pasos:
En la sección Compruebe el nombre DNS, en el paso 3, guarde el nombre de DNS del perfil de Traffic Manager; por ejemplo,
http://tmprofile-ejb120623.trafficmanager.net.En la sección Ver Traffic Manager en acción, siga estos pasos:
En el paso 1 y 3, anexe /weblogic/ready al nombre DNS del perfil de Traffic Manager en el explorador web, por ejemplo,
http://tmprofile-ejb120623.trafficmanager.net/weblogic/ready. Debería ver una página vacía sin ningún mensaje de error.Después de completar todos los pasos, asegúrese de habilitar el punto de conexión principal haciendo referencia al paso 2, pero reemplace Deshabilitado por Habilitado. A continuación, vuelva a la página Puntos de conexión.
Ahora tiene los puntos de conexión habilitados y en línea en el perfil de Traffic Manager. Mantenga abierta la página y úsela para supervisar el estado del punto de conexión más adelante.
Configuración de la alta disponibilidad y recuperación ante desastres combinada para clústeres de WLS
En esta sección, configurará la alta disponibilidad y recuperación ante desastres para clústeres de WLS.
Preparación de la aplicación de ejemplo
En esta sección, compilará y empaquetará una aplicación CRUD Java/JakartaEE de ejemplo que más adelante implementará y ejecutará en clústeres de WLS para realizar pruebas de conmutación por error.
La aplicación usa la persistencia de sesión JDBC de WebLogic Server para almacenar datos de sesión HTTP. El origen de datos jdbc/WebLogicCafeDB almacena los datos de sesión para habilitar la conmutación por error y el equilibrio de carga en un clúster de servidores WebLogic. Configura un esquema de persistencia para conservar los datos de la aplicación coffee en el mismo origen de datos jdbc/WebLogicCafeDB.
Siga estos pasos para compilar y empaquetar el ejemplo:
Use los siguientes comandos para clonar el repositorio de ejemplo y desactive la etiqueta correspondiente a este artículo:
git clone https://github.com/Azure-Samples/azure-cafe.git cd azure-cafe git checkout 20231206Si ves un mensaje acerca de
Detached HEAD, puedes ignorarlo.Use los siguientes comandos para navegar al directorio de ejemplo y, a continuación, compile y empaquete el ejemplo:
cd weblogic-cafe mvn clean package
Cuando el paquete se genera correctamente, puede encontrarlo en <parent-path-to-your-local-clone>/azure-cafe/weblogic-cafe/target/weblogic-cafe.war. Si no ve el paquete, debe solucionar el problema antes de continuar.
Implementación de la aplicación de ejemplo
Ahora siga estos pasos para implementar la aplicación de ejemplo en los clústeres, empezando por el clúster principal:
- Abra adminConsole del clúster en una nueva pestaña del explorador web. Inicie sesión en la Consola de administración de WebLogic Server con el nombre de usuario y la contraseña del administrador de WebLogic que guardó anteriormente.
- Busque Estructura de dominio>wlsd>Implementaciones en el panel de navegación. Seleccione Implementaciones.
- Seleccione Bloquear y editar>Instalar>Cargue los archivos>Elegir archivo. Seleccione el archivo weblogic-cafe.war que preparó anteriormente.
- Seleccione Siguiente>Siguiente>Siguiente. Seleccione
cluster1con la opción Todos los servidores del clúster para los destinos de implementación. Seleccione Siguiente>Finalizar. Seleccione Activar cambios. - Cambie a la pestaña Control y seleccione weblogic-cafe en la tabla de implementaciones. Seleccione Iniciar con la opción Atención a todas las solicitudes>Sí. Espere un tiempo y actualice la página hasta que vea que el estado de la implementación weblogic-cafe es Activo. Cambie a la pestaña de Supervisión y compruebe que la raíz del contexto de la aplicación implementada es /weblogic-cafe. Mantenga abierta la consola de administración de WLS para que pueda usarla más adelante para su posterior configuración.
Repita los mismos pasos en la Consola de administración del servidor WebLogic, pero para el clúster secundario en la región Oeste de EE. UU.
Actualización del host de front-end
Siga estos pasos para que los clústeres de WLS reconozcan Azure Traffic Manager. Dado que Azure Traffic Manager es el punto de entrada para las solicitudes de usuario, actualice el host front del clúster de WebLogic Server con el nombre DNS del perfil de Traffic Manager, empezando por el clúster principal.
- Asegúrese de que ha iniciado sesión en la consola de administración de WebLogic Server.
- Vaya a Estructura de dominio>wlsd>Entorno>Clústeres en el panel de navegación. Seleccione Clústeres.
- Seleccione
cluster1en la tabla de clústeres. - Seleccione Bloquear y editar>HTTP. Quite el valor actual del Host de front-end y escriba el nombre DNS del perfil de Traffic Manager que guardó anteriormente, sin el http:// inicial, por ejemplo, tmprofile-ejb120623.trafficmanager.net. Seleccione Guardar>Activar cambios.
Repita los mismos pasos en la Consola de administración del servidor WebLogic, pero para el clúster secundario en la región Oeste de EE. UU.
Configuración del almacén de registros de transacciones
A continuación, configure el almacén de registros de transacciones de JDBC para todos los servidores administrados de clústeres, empezando por el clúster principal. Esta práctica se describe en Uso de archivos de registro de transacciones para recuperar transacciones.
Siga estos pasos en el clúster principal de WLS en la región Este de EE. UU.:
- Asegúrese de que ha iniciado sesión en la consola de administración de WebLogic Server.
- Vaya a Estructura de dominio>wlsd>Entorno>Servidores en el panel de navegación. Seleccione Servidores.
- Debería ver los servidores msp1, msp2y msp3 que aparecen en la tabla de servidores.
- Seleccione
msp1>Servicios>Bloquear & Editar. En Almacén de registros de transacciones, seleccione JDBC. - En Tipo>Origen de datos, seleccione jdbc/WebLogicCafeDB.
- Confirme que el valor de Nombre de prefijo es TLOG_msp1_, que es el valor predeterminado. Si el valor es diferente, cámbielo a TLOG_msp1_.
- Seleccione Guardar.
- Seleccione Servidores>msp2 y repita los mismos pasos, excepto que el valor predeterminado de Nombre de prefijo es TLOG_msp2_.
- Seleccione Servers>msp3y repita los mismos pasos, excepto que el valor predeterminado de Nombre de prefijo es TLOG_msp3_.
- Seleccione Activar cambios.
Repita los mismos pasos en la Consola de administración del servidor WebLogic, pero para el clúster secundario en la región Oeste de EE. UU.
Reinicio de los servidores administrados del clúster principal
A continuación, siga estos pasos para reiniciar todos los servidores administrados del clúster principal para que los cambios surtan efecto:
- Asegúrese de que ha iniciado sesión en la consola de administración de WebLogic Server.
- Vaya a Estructura de dominio>wlsd>Entorno>Servidores en el panel de navegación. Seleccione Servidores.
- Seleccione la pestaña Control. Seleccione msp1, msp2 y msp3. Seleccione Apagar con la opción Cuando finalice el trabajo>Sí. Seleccione el icono de actualizar. Espere hasta que el valor Estado de la última acción sea TASK COMPLETED. Debería ver que el valor de Estado de los servidores seleccionados es SHUTDOWN. Vuelva a seleccionar el icono de actualización para detener la supervisión del estado.
- Seleccione msp1, msp2y msp3 de nuevo. Seleccione Iniciar>Sí. Seleccione el icono de actualizar. Espere hasta que el valor Estado de la última acción sea TASK COMPLETED. Debería ver que el valor de Estado de los servidores seleccionados es RUNNING. Vuelva a seleccionar el icono de actualización para detener la supervisión del estado.
Detén las máquinas virtuales en el clúster secundario
Ahora, siga estos pasos para detener todas las máquinas virtuales del clúster secundario para que sea pasivo:
- Abra la página principal de Azure Portal en una nueva pestaña del explorador y, a continuación, seleccione Todos los recursos. En el cuadro Filtrar por cualquier campo..., escriba el nombre del grupo de recursos donde se implementa el clúster secundario; por ejemplo, wls-cluster-westus-ejb120623.
- Seleccione Tipo igual a todo para abrir el filtro Tipo. En Valor, escriba Máquina virtual. Debería ver una entrada coincidente. Selecciónelo en Valor. Seleccione Aplicar. Debería ver 4 máquinas virtuales en la lista, incluidas adminVM, mspVM1, mspVM2y mspVM3.
- Selecciónelas para abrir cada una de ellas. Seleccione Detener y confirme la opción para cada máquina virtual.
- Seleccione el icono de notificaciones del portal de Azure para abrir el panel de Notificaciones .
- Supervise el evento Detener máquina virtual para cada máquina virtual hasta que el valor sea Máquina virtual detenida correctamente. Mantenga abierta la página para poder usarla para la prueba de conmutación por error más adelante.
Ahora, cambie a la pestaña del explorador donde se supervisa el estado de los puntos de conexión de Traffic Manager. Actualice la página hasta que vea que el estado del punto de conexión myFailoverEndpoint sea Degradado y el del punto de conexión myPrimaryEndpoint sea En línea.
Nota:
Es probable que una solución de alta disponibilidad y recuperación ante desastres preparada para producción quiera lograr un RTO menor, dejando las máquinas virtuales en ejecución, pero solo deteniendo el software WLS que se ejecuta en las máquinas virtuales. A continuación, en caso de conmutación por error, las máquinas virtuales ya se estarían ejecutando y el software WLS tardaría menos tiempo en iniciarse. En este artículo se decidió detener las máquinas virtuales porque el software implementado por el clúster de Oracle WebLogic Server en máquinas virtuales de Azure inicia automáticamente el software de WLS cuando se inician las máquinas virtuales.
Comprobación de la aplicación
Dado que el clúster principal está en funcionamiento, actúa como el clúster activo y controla todas las solicitudes de usuario enrutadas por el perfil de Traffic Manager.
Abra el nombre DNS del perfil de Azure Traffic Manager en una nueva pestaña del explorador, anexando la raíz de contexto /weblogic-cafe de la aplicación implementada, por ejemplo, http://tmprofile-ejb120623.trafficmanager.net/weblogic-cafe. Cree un nuevo café con nombre y precio, por ejemplo, Café 1 con el precio 10. Esta entrada se conserva en la tabla de datos de la aplicación y en la tabla de sesión de la base de datos. La UI que ve debería ser similar a la que aparece en la siguiente captura de pantalla:

Si la IU no se parece, solucione el problema antes de continuar.
Mantenga abierta la página para poder usarla para la prueba de conmutación por error más adelante.
Prueba de una conmutación por error de principal a secundaria
Para probar la conmutación por error, debe conmutar manualmente el servidor de base de datos principal y el clúster al servidor de base de datos secundario y al clúster y, a continuación, conmutar por recuperación mediante Azure Portal en esta sección.
Conmutación por error en un sitio secundario
En primer lugar, siga estos pasos para apagar las máquinas virtuales del clúster principal:
- Busque el nombre del grupo de recursos donde se implementa el clúster WLS principal; por ejemplo, wls-cluster-eastus-ejb120623. A continuación, siga los pasos descritos en la sección Detención de máquinas virtuales del clúster secundario, pero cambie el grupo de recursos de destino al clúster de WLS principal para detener todas las máquinas virtuales de ese clúster.
- Cambie a la pestaña del explorador de Traffic Manager, actualice la página hasta que vea que el valor de Estado de supervisión del punto de conexión myPrimaryEndpoint es Degradado.
- Cambie a la pestaña del explorador de la aplicación de ejemplo y actualice la página. Debería ver 504 Gateway Time-out o 502 Bad Gateway porque no se puede acceder a ninguno de los puntos de conexión.
A continuación, siga estos pasos para conmutar por error la instancia de Azure SQL Database desde el servidor principal al servidor secundario:
- Cambie a la pestaña del explorador del grupo de conmutación por error de Azure SQL Database.
- Seleccione Conmutación por error>Sí.
- Espere hasta que se complete.
A continuación, siga estos pasos para iniciar todos los servidores del clúster secundario:
- Ve a la pestaña del navegador donde detuviste todas las máquinas virtuales del clúster secundario.
- Seleccione la máquina virtual
adminVM. Seleccione Inicio. - Supervise el evento Iniciando máquina virtual para
adminVMen el panel Notificaciones y espere hasta que el valor sea Máquina virtual iniciada. - Cambie a la pestaña del explorador de la Consola de administración de WebLogic Server para el clúster secundario y, a continuación, actualice la página hasta que vea la página de bienvenida para iniciar sesión.
- Vuelva a la pestaña del explorador donde se muestran todas las máquinas virtuales del clúster secundario. Para las máquinas virtuales
mspVM1,mspVM2ymspVM3, seleccione cada una para abrirla y, a continuación, seleccione Iniciar. - Para las máquinas virtuales
mspVM1,mspVM2ymspVM3, supervise el evento Iniciando máquina virtual en el panel Notificaciones y espere hasta que el valor sea Máquina virtual iniciada.
Por último, siga estos pasos para comprobar la aplicación de ejemplo después de que el punto de conexión myFailoverEndpoint esté en estado En línea:
Cambie a la pestaña del explorador de Traffic Manager y, a continuación, actualice la página hasta que vea que el valor de Estado de supervisión del punto de conexión
myFailoverEndpointes En línea.Cambie a la pestaña del explorador de la aplicación de ejemplo y actualice la página. Debería ver los mismos datos almacenados en la tabla de datos de la aplicación y la tabla de sesión mostrada en la interfaz de usuario, como se muestra en la captura de pantalla siguiente:

Si no observa este comportamiento, puede deberse a que Traffic Manager está tardando en actualizar el DNS para que apunte al sitio alternativo. El problema también podría ser que el explorador almacenara en caché el resultado de la resolución de nombres DNS que apunta al sitio con errores. Espere un rato y vuelva a actualizar la página.
Nota:
Una solución de alta disponibilidad y recuperación ante desastres preparada para producción tendría en cuenta la copia continua de la configuración de WLS de la base de datos principal a los clústeres secundarios según una programación periódica. Para obtener información sobre cómo hacerlo, consulte las referencias a la documentación de Oracle al final de este artículo.
Para automatizar la conmutación por error, considere la posibilidad de usar alertas sobre las métricas de Traffic Manager y Azure Automation. Para más información, consulte la sección Alertas sobre métricas de Traffic Manager de Métricas y alertas de Traffic Manager y Uso de una alerta para desencadenar un runbook de Azure Automation.
Conmutación por recuperación al sitio principal
Siga los mismos pasos de la sección Conmutación por error al sitio secundario para conmutar por recuperación al sitio principal, incluido el servidor de base de datos y el clúster, excepto las siguientes diferencias:
- En primer lugar, apague las máquinas virtuales en el clúster secundario. Debería ver que el punto de conexión myFailoverEndpoint ha cambiado a Degradado.
- A continuación, realiza un failover de la Azure SQL Database desde el servidor secundario al servidor principal.
- A continuación, inicie todos los servidores del clúster principal.
- Por último, compruebe la aplicación de ejemplo después de que el estado del punto de conexión myPrimaryEndpoint sea En línea.
Limpieza de recursos
Si no va a seguir usando los clústeres de WLS y otros componentes, siga estos pasos para eliminar los grupos de recursos para limpiar los recursos usados en este tutorial:
- Escriba el nombre del grupo de recursos de los servidores de Azure SQL Database (por ejemplo,
myResourceGroup) en el cuadro de búsqueda de la parte superior de Azure Portal y seleccione el grupo de recursos coincidente en los resultados de búsqueda. - Seleccione Eliminar grupo de recursos.
- En Escriba el nombre del grupo de recursos para confirmar la eliminación, escriba el nombre del grupo de recursos.
- Seleccione Eliminar.
- Repita los pasos del 1 al 4 para el grupo de recursos de Traffic Manager; por ejemplo,
myResourceGroupTM1. - Repita los pasos del 1 al 4 para el grupo de recursos del clúster principal de WLS; por ejemplo,
wls-cluster-eastus-ejb120623. - Repita los pasos del 1 al 4 para el grupo de recursos del clúster secundario de WLS; por ejemplo,
wls-cluster-westus-ejb120623.
Pasos siguientes
En este tutorial, ha configurado una solución de alta disponibilidad y recuperación ante desastres que consta de un nivel de infraestructura de aplicación activo-pasivo con un nivel de base de datos activo-pasivo y en el que ambos niveles abarcan dos sitios geográficamente diferentes. En el primer sitio, tanto el nivel de infraestructura de la aplicación como el nivel de base de datos están activos. En el segundo sitio, se cierra el dominio secundario y la base de datos secundaria está en espera.
Continúe explorando las siguientes referencias para conocer más opciones para compilar soluciones de alta disponibilidad y recuperación ante desastres y ejecutar WLS en Azure: