Mejora de la calidad de la cadena RAG
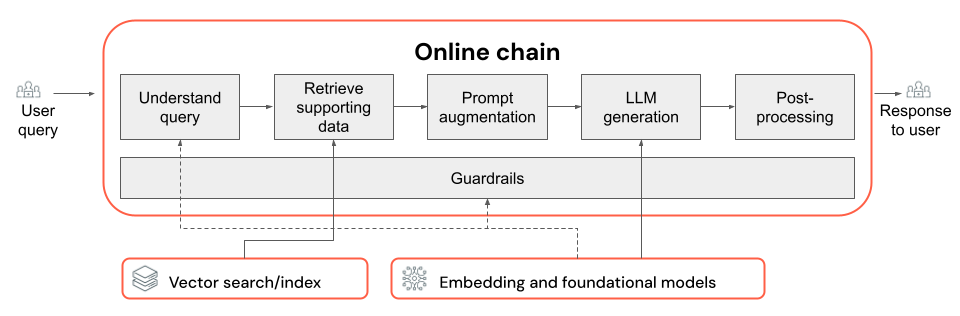
En este artículo se explica cómo mejorar la calidad de la aplicación RAG mediante componentes de la cadena RAG.
La cadena RAG toma una consulta de usuario como entrada, recupera información relevante dada esa consulta y genera una respuesta adecuada basada en los datos recuperados. Aunque los pasos exactos dentro de una cadena RAG pueden variar considerablemente en función del caso de uso y los requisitos, estos son los componentes clave que se deben tener en cuenta al crear la cadena RAG:
- Comprensión de consultas: analizar y transformar consultas de usuario para representar mejor la intención y extraer información relevante, como filtros o palabras clave, a fin de mejorar el proceso de recuperación.
- Recuperación: buscar los fragmentos de información más relevantes dada una consulta de recuperación. En el caso de los datos no estructurados, esto suele implicar una búsqueda semántica o basada en palabras clave, o una combinación de estas.
- Aumento de mensajes: combinar una consulta de usuario con información recuperada e instrucciones para guiar LLM hacia la generación de respuestas de alta calidad.
- LLM: seleccionar el modelo más adecuado (y los parámetros del modelo) para que la aplicación optimice o equilibre el rendimiento, la latencia y el costo.
- Posprocesamiento y límites de protección: aplicar pasos de procesamiento adicionales y medidas de seguridad para garantizar que las respuestas que genera LLM sean temáticas, coherentes de forma fáctica y cumplan directrices o restricciones específicas.
La implementación y evaluación iterativa de correcciones de calidad muestra cómo recorrer en iteración los componentes de una cadena.
Comprensión de consultas
El uso de la consulta de usuario directamente como consulta de recuperación puede funcionar para algunas consultas. Pero generalmente resulta beneficioso reformular la consulta antes del paso de recuperación. La comprensión de consultas consta de un paso (o una serie de pasos) al principio de una cadena para analizar y transformar las consultas de usuario a fin de representar mejor la intención, extraer información relevante y, en última instancia, ayudar al proceso de recuperación posterior. Entre los enfoques para transformar una consulta de usuario a fin de mejorar la recuperación se incluyen los siguientes:
Reescritura de consultas: la reescritura de consultas implica traducir una consulta de usuario a una o varias consultas que representen mejor la intención original. El objetivo es reformular la consulta de una manera que aumente la probabilidad de que el paso de recuperación encuentre los documentos más relevantes. Esto puede ser especialmente útil cuando se trabaja con consultas complejas o ambiguas que podrían no coincidir directamente con la terminología usada en los documentos de recuperación.
Ejemplos:
- Parafrasear el historial de conversaciones en un chat de varios turnos
- Corregir errores ortográficos en la consulta del usuario
- Reemplazar palabras o frases en la consulta de usuario por sinónimos para capturar una gama más amplia de documentos pertinentes
Importante
La reescritura de consultas debe realizarse junto con cambios en el componente de recuperación.
Extracción de filtros: en algunos casos, las consultas de usuario pueden contener filtros o criterios específicos que se pueden usar para restringir los resultados de la búsqueda. La extracción de filtros implica identificar y extraer estos filtros de la consulta y moverlos al paso de recuperación como parámetros adicionales. Esto puede ayudar a mejorar la relevancia de los documentos recuperados centrándose en subconjuntos específicos de los datos disponibles.
Ejemplos:
- Extraer períodos de tiempo específicos mencionados en la consulta, como "artículos de los últimos 6 meses" o "informes de 2023".
- Identificar menciones de productos, servicios o categorías específicos en la consulta, como "Servicios profesionales de Databricks" o "portátiles".
- Extraer entidades geográficas de la consulta, como nombres de ciudad o códigos de país.
Nota:
La extracción de filtros debe realizarse junto con cambios en la extracción de metadatos de componentes de canalización de datos y cadena de recuperación. El paso de extracción de metadatos debe asegurarse de que los campos de metadatos pertinentes están disponibles para cada documento o fragmento, y el paso de recuperación debe implementarse para aceptar y aplicar filtros extraídos.
Además de la reescritura de consultas y la extracción de filtros, otra consideración importante en la descripción de las consultas es si se debe usar una sola llamada LLM o varias. Aunque el uso de una sola llamada con un aviso cuidadosamente diseñado puede ser eficaz, hay casos en los que dividir el proceso de comprensión de consultas en varias llamadas LLM puede dar lugar a mejores resultados. Esto, por cierto, es una regla generalmente aplicable cuando se intenta implementar una serie de pasos lógicos complejos en una sola solicitud.
Por ejemplo, puedes usar una llamada LLM para clasificar la intención de consulta, otra para extraer entidades pertinentes y una tercera para volver a escribir la consulta en función de la información extraída. Aunque es posible que este enfoque agregue cierta latencia al proceso general, puede permitir un control más específico y mejorar potencialmente la calidad de los documentos recuperados.
Comprensión de consultas de varios pasos para un bot de soporte técnico
Este es el modo en que un componente de comprensión de consultas de varios pasos podría buscar un bot de soporte técnico al cliente:
- Clasificación de intenciones: usa una llamada LLM para clasificar la consulta del usuario en categorías predefinidas, como "información” del producto", "solución de problemas" o "administración de cuentas".
- Extracción de entidades: en función de la intención identificada, usa otra llamada LLM para extraer entidades pertinentes de la consulta, como nombres de producto, errores notificados o números de cuenta.
- Reescritura de consultas: usa la intención extraída y las entidades para reescribir la consulta original en un formato más específico y dirigido, por ejemplo, "Mi cadena RAG no se puede implementar en Model Serving, veo el siguiente error…".
Recuperación
El componente de recuperación de la cadena RAG se encarga de encontrar los fragmentos de información más relevantes dada una consulta de recuperación. En el contexto de los datos no estructurados, la recuperación normalmente implica una búsqueda semántica, búsqueda basada en palabras clave y filtrado de metadatos, o una combinación de estos. La elección de la estrategia de recuperación depende de los requisitos específicos de la aplicación, la naturaleza de los datos y los tipos de consultas que esperas controlar. Vamos a comparar estas opciones:
- Búsqueda semántica: esta característica usa un modelo de inserción para convertir cada fragmento de texto en una representación vectorial que captura su significado semántico. Al comparar la representación vectorial de la consulta de recuperación con las representaciones vectoriales de los fragmentos, la búsqueda semántica puede recuperar documentos conceptualmente similares, incluso si no contienen las palabras clave exactas de la consulta.
- Búsqueda basada en palabras clave: esta característica determina la relevancia de los documentos analizando la frecuencia y distribución de palabras compartidas entre la consulta de recuperación y los documentos indexados. Cuanto más a menudo aparecen las mismas palabras en la consulta y en un documento, mayor es la puntuación de relevancia asignada a ese documento.
- Búsqueda híbrida: esta característica combina los puntos fuertes de las búsquedas de tipo semántica y basada en palabras clave utilizando un proceso de recuperación en dos pasos. En primer lugar, realiza una búsqueda semántica para recuperar un conjunto de documentos conceptualmente relevantes. Después, aplica la búsqueda basada en palabras clave en este conjunto reducido para mejorar aún más los resultados en función de las coincidencias exactas de palabras clave. Por último, combina las puntuaciones de ambos pasos para clasificar los documentos.
Comparación de estrategias de recuperación
En la tabla siguiente se contrastan estas estrategias de recuperación entre sí:
| Búsqueda semántica | Búsqueda de palabra clave | Búsqueda híbrida | |
|---|---|---|---|
| Explicación sencilla | Si los mismos conceptos aparecen en la consulta y en un documento potencial, son pertinentes. | Si las mismas palabras aparecen en la consulta y en un documento potencial, son pertinentes. Cuantas más palabras de la consulta aparezcan en el documento, más relevante es ese documento. | Ejecuta una búsqueda semántica y una búsqueda por palabras clave y combina los resultados. |
| Ejemplo de caso de uso | Servicio de atención al cliente donde las consultas de usuario son diferentes de las palabras de los manuales del producto. Ejemplo: "¿cómo puedo activar mi teléfono?" y la sección del manual se llama "conmutar el inicio/apagado". | Servicio de atención al cliente en el que las consultas contienen términos técnicos específicos y no descriptivos. Ejemplo: "¿qué hace el modelo HD7-8D?" | Consultas de atención al cliente que combinan términos semánticos y técnicos. Ejemplo: "¿cómo puedo activar mi HD7-8D?" |
| Enfoques técnicos | Usa inserciones para representar texto en un espacio vectorial continuo, lo que permite la búsqueda semántica. | Se basa en métodos discretos basados en tokens, como bolsa de palabras, TF-IDF, BM25, para la coincidencia de palabras clave. | Usa un enfoque de reclasificación para combinar los resultados, como la fusión de clasificación recíproca o un modelo de reclasificación. |
| Strengths | Recuperar información contextualmente similar en una consulta, incluso si no se usan las palabras exactas. | Escenarios que requieren coincidencias precisas de palabras clave, ideales para consultas específicas centradas en términos como, por ejemplo, nombres de producto. | Combina lo mejor de ambos enfoques. |
Formas de mejorar el proceso de recuperación
Además de estas estrategias principales de recuperación, hay varias técnicas que puedes aplicar para mejorar aún más el proceso de recuperación:
- Expansión de consultas: esta característica puede ayudar a capturar una gama más amplia de documentos relevantes mediante diversas variaciones de la consulta de recuperación. Esto se puede lograr realizando búsquedas individuales para cada consulta expandida o mediante una concatenación de todas las consultas de búsqueda expandidas en una sola consulta de recuperación.
Nota:
La expansión de consultas debe realizarse junto con los cambios realizados en el componente de comprensión de consultas (cadena RAG). Las diversas variaciones de una consulta de recuperación normalmente se generan en este paso.
- Reclasificación: después de recuperar un conjunto inicial de fragmentos, aplica criterios de clasificación adicionales (por ejemplo, ordenar por tiempo) o un modelo reclasificador para volver a ordenar los resultados. La reclasificación puede ayudar a priorizar los fragmentos más relevantes según una consulta de recuperación específica. La reclasificación con modelos entre codificadores, como mxbai-rerank y ColBERTv2, puede producir un aumento en el rendimiento de recuperación.
- Filtrado de metadatos: usa filtros de metadatos extraídos del paso de comprensión de consultas para restringir el espacio de búsqueda en función de criterios específicos. Los filtros de metadatos pueden incluir atributos como el tipo de documento, la fecha de creación, el autor o las etiquetas específicas del dominio. Al combinar filtros de metadatos con la búsqueda semántica o basada en palabras clave, puedes crear una recuperación más dirigida y eficaz.
Nota:
El filtrado de metadatos debe realizarse junto con cambios en los componentes de comprensión de consultas (cadena RAG) y extracción de metadatos (canalización de datos).
Aumento de las indicaciones
El aumento de las indicaciones es el paso en el que la consulta de usuario se combina con la información recuperada y las instrucciones de una plantilla de aviso para guiar el modelo de lenguaje hacia la generación de respuestas de alta calidad. Se requiere iteración en esta plantilla para optimizar la solicitud proporcionada a la llamada LLM (también conocida como ingeniería de indicaciones) para asegurarse de que el modelo se guía para generar respuestas precisas, fundamentadas y coherentes.
Hay guías completas de ingeniería de indicaciones, pero estas son algunas consideraciones que debes tener en cuenta al recorrer en iteración la plantilla de indicaciones:
- Especificación de ejemplos
- Incluye ejemplos de consultas bien formadas y sus respuestas ideales correspondientes dentro de la propia plantilla de indicaciones (aprendizaje en pocos pasos). Esto ayuda al modelo a comprender el formato, el estilo y el contenido deseados de las respuestas.
- Una manera útil de encontrar buenos ejemplos es identificar tipos de consultas con las que tiene problemas la cadena. Crea respuestas de referencia para esas consultas e inclúyelas como ejemplos en la indicación.
- Asegúrate de que los ejemplos que proporciones son representativos de las consultas de usuario que prevés en el momento de la inferencia. Pretende cubrir una amplia gama de consultas esperadas para ayudar al modelo a generalizar mejor.
- Parametrización de la plantilla de indicaciones
- Diseña la plantilla de indicaciones para que sea flexible parametrizándola a fin de incorporar información adicional más allá de los datos recuperados y la consulta de usuario. Esto podrían ser variables como la fecha actual, el contexto del usuario u otros metadatos pertinentes.
- La inserción de estas variables en la indicación en el momento de la inferencia puede permitir respuestas más personalizadas o compatibles con el contexto.
- Planteamiento de la solicitud de la cadena de pensamientos
- Para consultas complejas en las que las respuestas directas no sean fácilmente aparentes, plantéate la solicitud de la cadena de pensamiento (CoT). Esta estrategia de ingeniería de indicaciones divide las preguntas complicadas en pasos más sencillos y secuenciales, que guían la llamada LLM por un proceso de razonamiento lógico.
- Al solicitar al modelo que "piense en el problema paso a paso", le animas a proporcionar respuestas más detalladas y bien razonadas, lo que puede ser especialmente eficaz para gestionar consultas de varios pasos o de final abierto.
- Es posible que las indicaciones no se transfieran entre modelos
- Debes reconocer que las indicaciones a menudo no se transfieren de forma fluida entre diferentes modelos de lenguaje. Cada modelo tiene sus propias características únicas, de modo que una indicación que funciona bien para un modelo puede no ser tan eficaz para otro.
- Experimente con diferentes formatos y longitudes de aviso, consulte guías en línea (como Libro de cocina de OpenAI o libro de cocina antrópico) y prepárese para adaptar y refinar los mensajes al cambiar entre modelos.
LLM
El componente de generación de la cadena RAG toma la plantilla de indicación aumentada del paso anterior y la pasa a una llamada LLM. Al seleccionar y optimizar una llamada LLM para el componente de generación de una cadena RAG, ten en cuenta los siguientes factores, que son igualmente aplicables a cualquier otro paso que implique llamadas LLM:
- Experimenta con diferentes modelos listos para usar.
- Cada modelo tiene sus propiedades, puntos fuertes y puntos débiles propios y únicos. Algunos modelos pueden tener una mejor comprensión de determinados dominios o tener un mejor rendimiento en tareas específicas.
- Tal como se ha mencionado anteriormente, ten en cuenta que la elección del modelo también puede influir en el proceso de ingeniería de indicaciones, ya que los diferentes modelos pueden responder de forma diferente a las mismas indicaciones.
- Si hay varios pasos en la cadena que requieren una llamada LLM, como llamadas a fin de comprender consultas además del paso de generación, considera la posibilidad de usar diferentes modelos para distintos pasos. Los modelos de uso general más caros pueden ser excesivos para tareas como determinar la intención de una consulta de usuario.
- Empieza poco a poco y escala verticalmente según sea necesario.
- Aunque puede ser tentador llegar inmediatamente a los modelos más potentes y capaces disponibles (por ejemplo, GPT-4, Claude), a menudo es más eficaz empezar con modelos más pequeños y ligeros.
- En muchos casos, las alternativas de código abierto más pequeñas, como Llama 3 o DBRX, pueden proporcionar resultados satisfactorios a un costo menor y con tiempos de inferencia más rápidos. Estos modelos pueden ser especialmente eficaces para las tareas que no requieren un razonamiento muy complejo o amplios conocimientos globales.
- A medida que desarrollas y mejoras la cadena RAG, evalúa continuamente el rendimiento y las limitaciones del modelo elegido. Si detectas que el modelo tiene problemas con determinados tipos de consultas o no proporciona respuestas suficientemente detalladas o precisas, considera la posibilidad de escalar verticalmente a un modelo más capaz.
- Supervisa el impacto de cambiar los modelos en métricas clave, como la calidad de respuesta, la latencia y el costo, para asegurarte de que estás buscando el equilibrio adecuado para los requisitos de tu caso de uso específico.
- Optimización de los parámetros del modelo
- Experimenta con diferentes configuraciones de parámetros para encontrar el equilibrio óptimo entre la calidad de respuesta, la diversidad y la coherencia. Por ejemplo, ajustar temperature puede controlar la aleatoriedad del texto generado, mientras que max_tokens puede limitar la longitud de la respuesta.
- Ten en cuenta que la configuración óptima de parámetros puede variar en función de la tarea específica, el mensaje y el estilo de salida deseado. Prueba y mejora esta configuración de forma iterativa en función de la evaluación de las respuestas generadas.
- Ajuste específico de una tarea
- A medida que mejoras el rendimiento, considera la posibilidad de ajustar los modelos más pequeños para las subtareas específicas dentro de la cadena RAG, como la comprensión de consultas.
- Al entrenar modelos especializados para tareas individuales con la cadena RAG, puedes mejorar el rendimiento general, reducir la latencia y reducir los costos de inferencia en comparación con el uso de un único modelo grande para todas las tareas.
- Entrenamiento previo continuo
- Si la aplicación RAG se ocupa de un dominio especializado o requiere conocimientos que no están bien representados en el LLM entrenado previamente, considera la posibilidad de realizar un entrenamiento previo continuo (CPT) en datos específicos del dominio.
- El entrenamiento previo continuo puede mejorar la comprensión de un modelo de terminología o conceptos específicos únicos para tu dominio. A su vez, esto puede reducir la necesidad de una amplia ingeniería de indicaciones o algunos ejemplos de pocos pasos.
Posprocesamiento y límites de protección
Después de que LLM genere una respuesta, a menudo es necesario aplicar técnicas de posprocesamiento o límites de protección para garantizar que la salida cumple los requisitos de formato, estilo y contenido deseados. Este último paso (o últimos pasos) de la cadena puede ayudar a mantener la coherencia y la calidad en las respuestas generadas. Si vas a implementar límites de protección y posprocesamiento, ten en cuenta algunos de los siguientes aspectos:
- Aplicación del formato de salida
- En función de tu caso de uso, puedes requerir que las respuestas generadas se ajusten a un formato específico, como una plantilla estructurada o un tipo de archivo determinado (como JSON, HTML, Markdown, etc.).
- Si se requiere una salida estructurada, las bibliotecas como Instructor o Outlines proporcionan buenos puntos de partida para implementar este tipo de paso de validación.
- Al desarrollar, dedica tiempo a asegurarte de que el paso de posprocesamiento es lo suficientemente flexible como para gestionar las variaciones en las respuestas generadas al tiempo que mantiene el formato necesario.
- Mantenimiento de la coherencia del estilo
- Si la aplicación RAG tiene directrices de estilo específicas o requisitos de tono (por ejemplo, formales frente a casuales, concisas frente a detalladas), un paso de posprocesamiento puede comprobar y aplicar estos atributos de estilo en las respuestas generadas.
- Filtros de contenido y barreras de seguridad
- Según la naturaleza de la aplicación RAG y los posibles riesgos asociados con el contenido generado, puede ser importante implementar filtros de contenido o barreras de seguridad para evitar la salida de información inadecuada, ofensiva o perjudicial.
- Considera la posibilidad de usar modelos como Llama Guard o API específicamente diseñadas para la moderación y seguridad de contenido, como API de moderación de OpenAI, para implementar barreras de seguridad.
- Gestión de alucinaciones
- La defensa contra las alucinaciones también se puede implementar como un paso de posprocesamiento. Esto puede implicar hacer referencias cruzadas en la salida generada con documentos recuperados o usar LLM adicionales para validar la precisión fáctica de la respuesta.
- Desarrolla mecanismos de reserva para gestionar los casos en los que la respuesta generada no cumple los requisitos de precisión fáctica, como generar respuestas alternativas o proporcionar renuncias de responsabilidad al usuario.
- Control de errores
- Con los pasos de posprocesamiento, implementa mecanismos para tratar correctamente los casos en los que el paso encuentra un problema o no puede generar una respuesta satisfactoria. Esto podría implicar la generación de una respuesta predeterminada o la derivación del problema a un operador humano para una revisión manual.
< anterior: mejora de la calidad de la canalización de datos