Mejora de la calidad de las canalizaciones de datos RAG
En este artículo se describe cómo experimentar con las opciones de canalización de datos desde un punto de vista práctico en la implementación de cambios en la canalización de datos.
Componentes clave de la canalización de datos
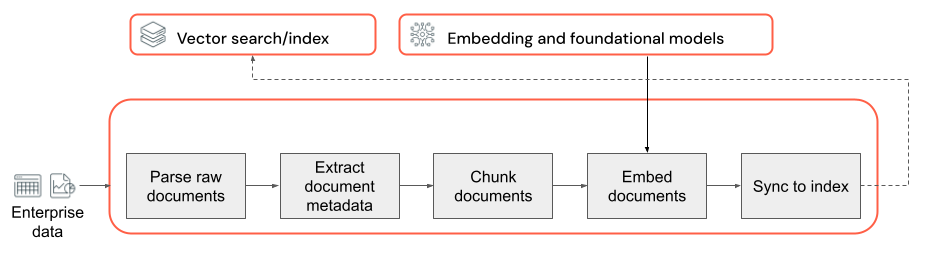
La base de cualquier aplicación RAG con datos no estructurados es la canalización de datos. Esta canalización es responsable de preparar los datos no estructurados en un formato que la aplicación RAG pueda usar de forma eficaz. Aunque esta canalización de datos puede ser arbitrariamente compleja, estos son los componentes clave que debes tener en cuenta al compilar la aplicación RAG por primera vez:
- Composición del corpus: seleccionar los orígenes de datos y el contenido adecuados en función del caso de uso específico.
- Análisis: extraer información relevante de los datos sin procesar mediante técnicas de análisis adecuadas.
- Fragmentación: dividir los datos analizados en fragmentos más pequeños y administrables para conseguir una recuperación eficaz.
- Inserción: convertir los datos de texto fragmentados en una representación vectorial numérica que captura su significado semántico.
Composición del corpus
Sin el corpus de datos correcto, la aplicación RAG no puede recuperar la información necesaria para responder a una consulta de usuario. Los datos adecuados dependen completamente de los requisitos y objetivos específicos de la aplicación, lo que hace fundamental dedicar tiempo a comprender los matices de los datos disponibles (consulta la sección de recopilación de requisitos para obtener instrucciones sobre esto).
Por ejemplo, al compilar un bot de asistencia al cliente, puedes considerar la posibilidad de incluir lo siguiente:
- Documentos de la base de conocimiento
- Preguntas más frecuentes (P+F)
- Manuales y especificaciones del producto
- Guías de solución de problemas
Ponte en contacto con expertos en la materia y las partes interesadas desde el principio de cualquier proyecto para ayudar a identificar y conservar el contenido relevante que podría mejorar la calidad y la cobertura del corpus de datos. Pueden proporcionar información sobre los tipos de consultas que es probable que envíen los usuarios y ayudar a priorizar la información más importante que se va a incluir.
Análisis
Después de identificar los orígenes de datos de la aplicación RAG, el siguiente paso es extraer la información necesaria de los datos sin procesar. Este proceso, conocido como análisis, implica transformar los datos no estructurados en un formato que la aplicación RAG pueda usar de forma eficaz.
Las técnicas y herramientas de análisis específicas que uses dependen del tipo de datos con los que trabajas. Por ejemplo:
- Documentos de texto (PDF, documentos de Word): bibliotecas fuera de la plataforma, como no estructurados y pyPDF2 pueden controlar varios formatos de archivo y proporcionar opciones para personalizar el proceso de análisis.
- Documentos HTML: se pueden usar bibliotecas de análisis HTML, como BeautifulSoup, para extraer contenido relevante de las páginas web. Con ellas, puedes navegar por la estructura HTML, seleccionar elementos específicos y extraer el texto o atributos deseados.
- Imágenes y documentos escaneados: las técnicas de reconocimiento óptico de caracteres (OCR) suelen ser necesarias para extraer texto de las imágenes. Entre las bibliotecas populares de OCR se incluyen Teseract, Amazon Textract, OCR de Visión de Azure AI y Google Cloud Vision API.
Procedimientos recomendados para el análisis de datos
Cuando analices los datos, ten en cuenta los siguientes procedimientos recomendados:
- Limpieza de datos: procesa previamente el texto extraído para quitar cualquier información irrelevante o molesta, como encabezados, pies de página o caracteres especiales. Sé consciente de la reducción de la cantidad de información innecesaria o con formato incorrecto que la cadena RAG necesita procesar.
- Control de errores y excepciones: implementa mecanismos de control y registro de errores para identificar y resolver los problemas detectados durante el proceso de análisis. Esto te ayuda a identificar y corregir problemas rápidamente. Al hacer esto se suele apuntar a problemas ascendentes con la calidad de los datos de origen.
- Personalización de la lógica de análisis: en función de la estructura y el formato de los datos, es posible que tengas que personalizar la lógica de análisis para extraer la información más relevante. Aunque puede requerir esfuerzo adicional por adelantado, invierte el tiempo para hacerlo si es necesario; suele evitar muchos problemas de calidad de bajada.
- Evaluación de la calidad del análisis: evalúa periódicamente la calidad de los datos analizados revisando manualmente una muestra de la salida. Esto puede ayudarte a identificar cualquier problema o área para mejorar el proceso de análisis.
Fragmentación
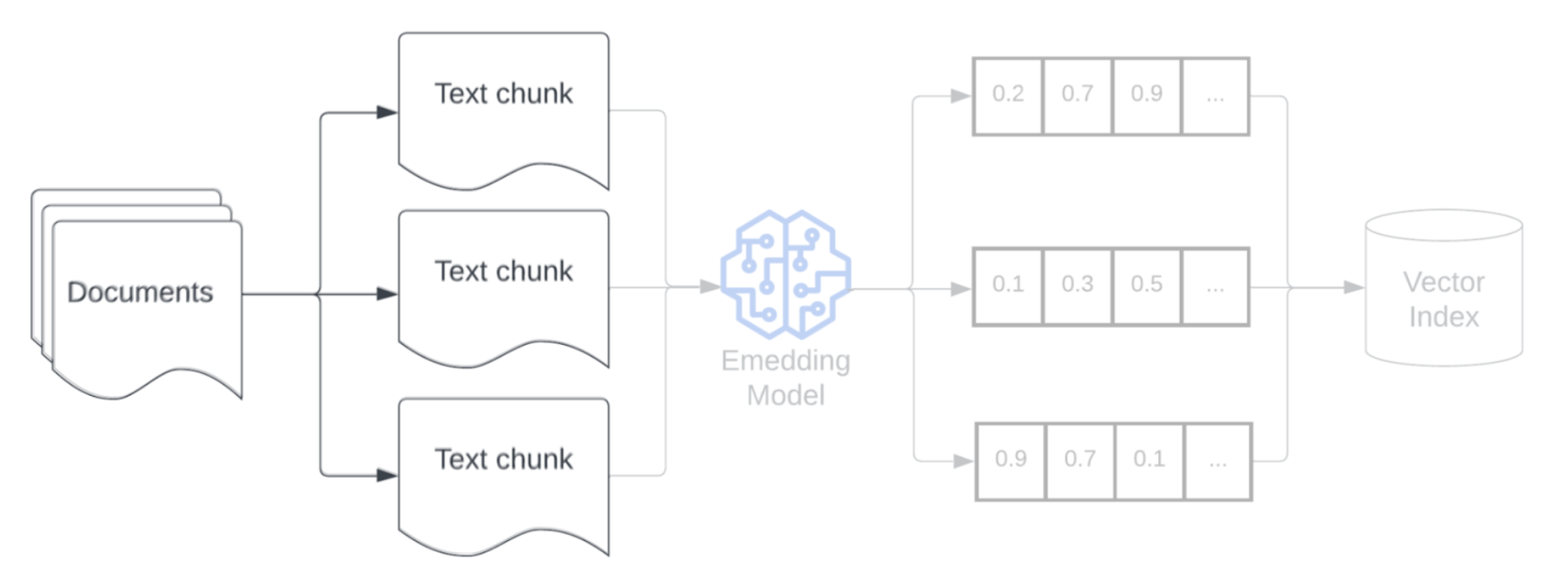
Después de analizar los datos sin procesar en un formato más estructurado, el siguiente paso consiste en dividirlos en unidades más pequeñas y administrables denominadas fragmentos. La segmentación de documentos grandes en fragmentos más pequeños y concentrados semánticamente garantiza que los datos recuperados se ajusten al contexto de LLM, al tiempo que minimiza la inclusión de información irrelevante o distracción. Las opciones tomadas en la fragmentación afectarán directamente a los datos recuperados que proporciona LLM, lo que lo convierte en una de las primeras capas de optimización en una aplicación RAG.
Al fragmentar los datos, ten en cuenta los siguientes factores:
- Estrategia de fragmentación: el método que se usa para dividir el texto original en fragmentos. Esto puede implicar técnicas básicas, como la división por oraciones, párrafos o recuentos de caracteres o tokens específicos, mediante estrategias de división más avanzadas específicas del documento.
- Tamaño del fragmento: los fragmentos más pequeños pueden centrarse en detalles específicos, pero pierden información cercana. Los fragmentos más grandes pueden capturar más contexto, pero también pueden incluir información irrelevante.
- Superposición entre fragmentos: para asegurarte de que no se pierde información importante al dividir los datos en fragmentos, considera la posibilidad de incluir cierta superposición entre fragmentos adyacentes. La superposición puede garantizar la continuidad y la conservación del contexto entre fragmentos.
- Coherencia semántica: siempre que sea posible, intenta crear fragmentos que sean semánticamente coherentes, lo que significa que contienen información relacionada y pueden permanecer por sí mismos como una unidad significativa de texto. Esto se puede lograr teniendo en cuenta la estructura de los datos originales, como párrafos, secciones o límites de temas.
- Metadatos: incluir metadatos relevantes en cada fragmento, como el nombre del documento de origen, el encabezado de sección o los nombres de producto, puede hacer que el proceso de recuperación mejore. Esta información adicional del fragmento puede ayudar a que las consultas de recuperación con fragmentos coincidan.
Estrategias de fragmentación de datos
Buscar el método de fragmentación correcto es iterativo y depende del contexto. No hay ningún enfoque único que sea válido para todos los casos; el tamaño óptimo del fragmento y el método dependerán del caso de uso específico y de la naturaleza de los datos que se procesan. En términos generales, las estrategias de fragmentación se pueden ver como las siguientes:
- Fragmentación de tamaño fijo: divide el texto en fragmentos de un tamaño predeterminado, como un número fijo de caracteres o tokens (por ejemplo, LangChain CharacterTextSplitter). Aunque la división por un número arbitrario de caracteres o tokens es rápida y fácil de configurar, normalmente no dará lugar a fragmentos coherentes semánticamente.
- Fragmentación basada en párrafos: usa los límites de párrafo natural del texto para definir fragmentos. Este método puede ayudar a conservar la coherencia semántica de los fragmentos, ya que los párrafos suelen contener información relacionada (por ejemplo, LangChain RecursiveCharacterTextSplitter).
- Fragmentación específica del formato: formatos como Markdown o HTML tienen una estructura inherente dentro de ellos que se puede usar para definir límites de fragmentos (por ejemplo, encabezados markdown). Herramientas como MarkdownHeaderTextSplitter de LangChain o los separadores basados en HTML encabezado/sección se pueden usar para este propósito.
- Fragmentación semántica: técnicas como el modelado de temas se puede aplicar para identificar secciones semánticamente coherentes dentro del texto. Estos enfoques analizan el contenido o la estructura de cada documento para determinar los límites de fragmentos más adecuados en función de los cambios en el tema. Aunque tiene más implicación que los enfoques más básicos, la fragmentación semántica puede ayudar a crear fragmentos más alineados con las divisiones semánticas naturales en el texto (consulta LangChain SemanticChunker para obtener un ejemplo de esto).
Ejemplo: fragmentación del tamaño de corrección
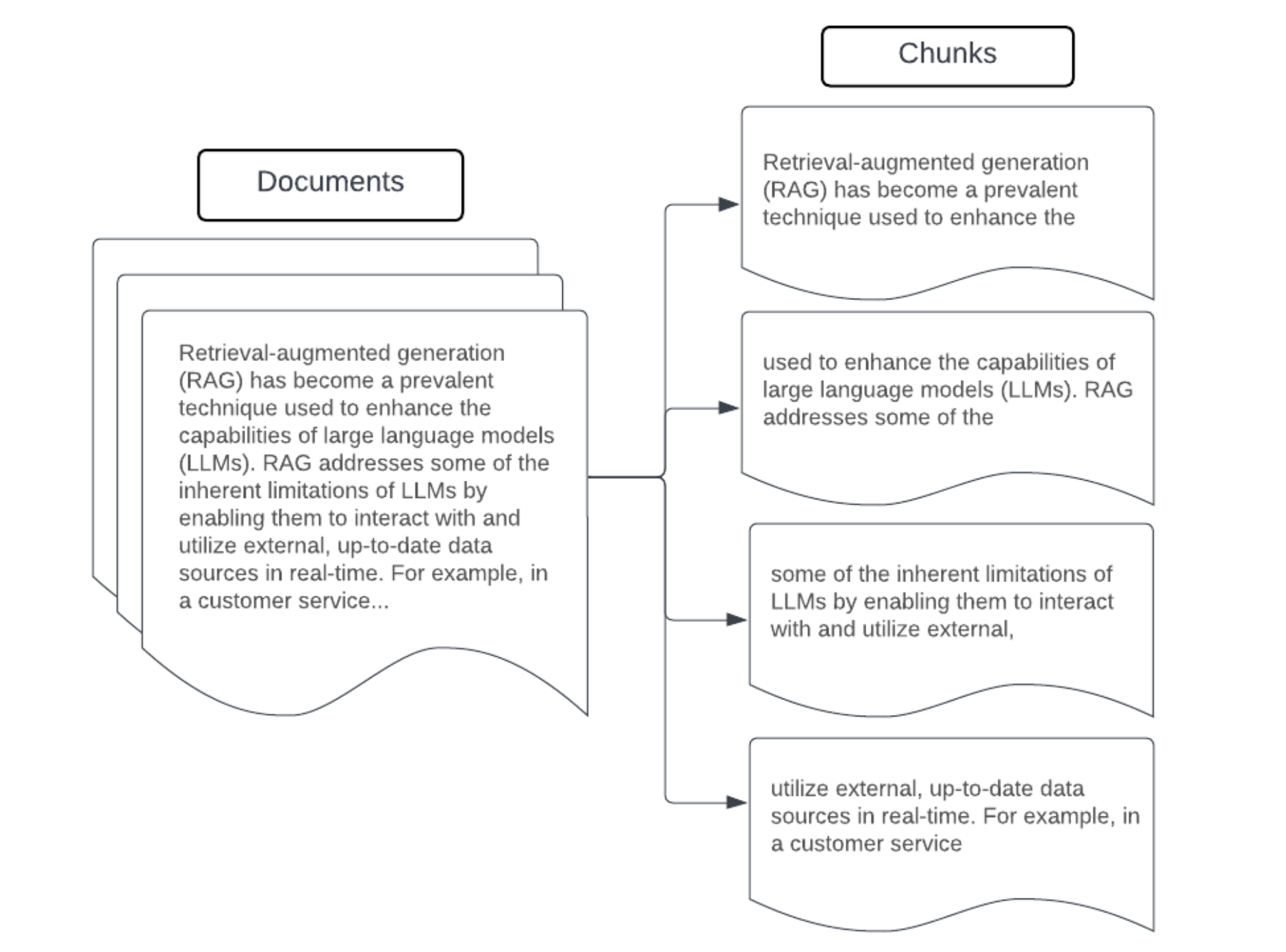
Ejemplo de fragmentación de tamaño fijo mediante recursiveCharacterTextSplitter de LangChain con chunk_size=100 y chunk_overlap=20. ChunkViz proporciona una manera interactiva de visualizar cómo diferentes valores de tamaño de fragmento y de superposición de fragmentos con separadores de caracteres de LangChain afectan a los fragmentos resultantes.
Modelo de inserción
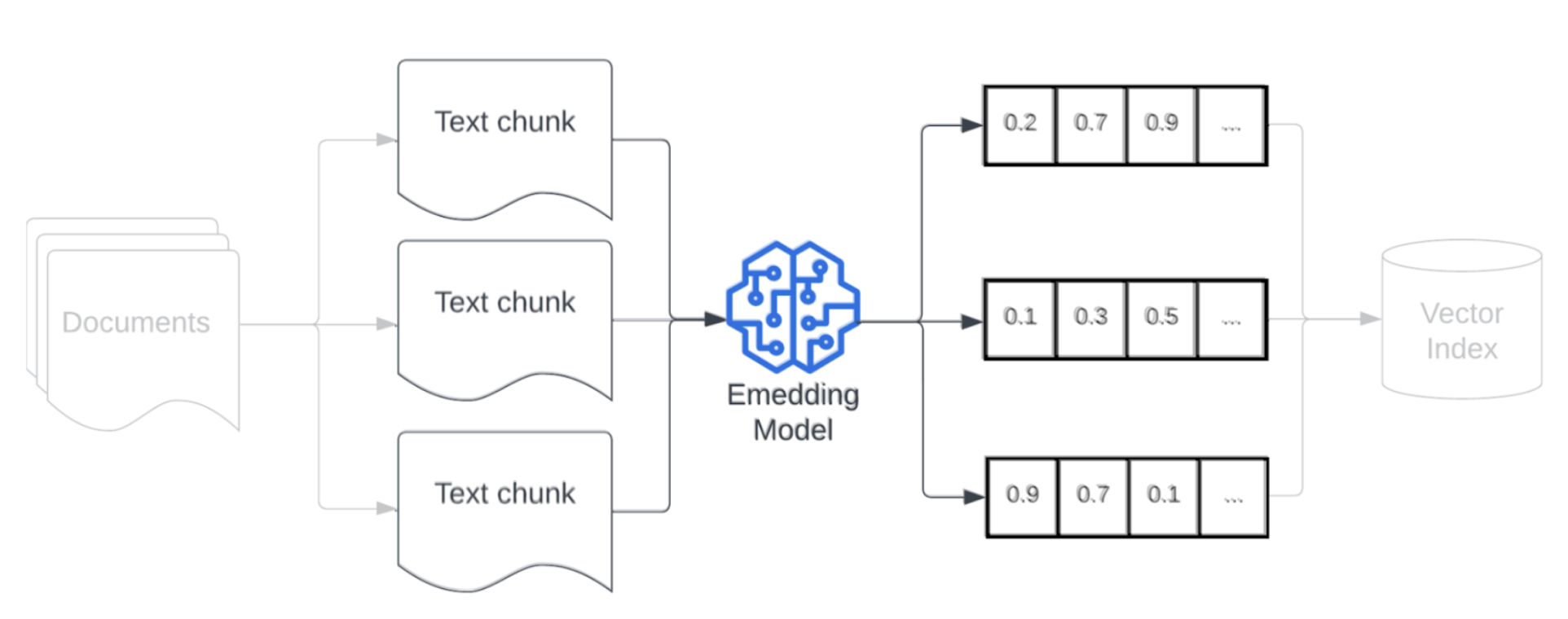
Después de fragmentar los datos, el siguiente paso consiste en convertir los fragmentos de texto en una representación vectorial mediante un modelo de inserción. Se usa un modelo de inserción para convertir cada fragmento de texto en una representación vectorial que captura su significado semántico. Al representar fragmentos como vectores densos, las inserciones permiten una recuperación rápida y precisa de los fragmentos más relevantes en función de su similitud semántica con una consulta de recuperación. La consulta de recuperación, en el momento de la consulta, se transformará mediante el mismo modelo de inserción que se usó para insertar fragmentos en la canalización de datos.
Al seleccionar un modelo de inserción, ten en cuenta los siguientes factores:
- Elección del modelo: cada modelo de inserción tiene sus matices y es posible que las pruebas comparativas disponibles no capturen las características específicas de los datos. Experimenta con diferentes modelos de inserción fuera de la plataforma, incluso aquellos que pueden ser clasificados en tablas de clasificación estándar como MTEB. Algunos ejemplos que se deben tener en cuenta son los siguientes:
- Tokens máximos: ten en cuenta el límite máximo de tokens para el modelo de inserción elegido. Si pasas fragmentos que superan este límite, se truncarán, lo que podría conllevar la pérdida de información importante. Por ejemplo, bge-large-en-v1.5 tiene un límite máximo de 512 tokens.
- Tamaño del modelo: los modelos de inserción más grandes suelen ofrecer un mejor rendimiento, pero requieren más recursos informáticos. Logra un equilibrio entre el rendimiento y la eficacia en función de su caso de uso específico y los recursos disponibles.
- Ajuste: si la aplicación RAG se ocupa del lenguaje específico del dominio (por ejemplo, acrónimos internos de la empresa o terminología), considera la posibilidad de ajustar el modelo de inserción en los datos específicos del dominio. Esto puede ayudar al modelo a capturar mejor los matices y la terminología de su dominio concreto, y a menudo puede generar un mejor rendimiento de recuperación.