Pasos de procesamiento y descripción de canalización de datos RAG
En este artículo, obtendrá información sobre cómo preparar los datos no estructurados para su uso en aplicaciones RAG. Los datos no estructurados hacen referencia a datos sin una estructura u organización específicas, como documentos PDF que pueden incluir texto e imágenes, o contenido multimedia como audio o vídeos.
Los datos no estructurados carecen de un modelo o esquema de datos predefinido, lo que hace que sea imposible realizar consultas basándose únicamente en la estructura y los metadatos. Como resultado, los datos no estructurados requieren técnicas que puedan comprender y extraer el significado semántico del texto sin procesar, imágenes, audio u otro contenido.
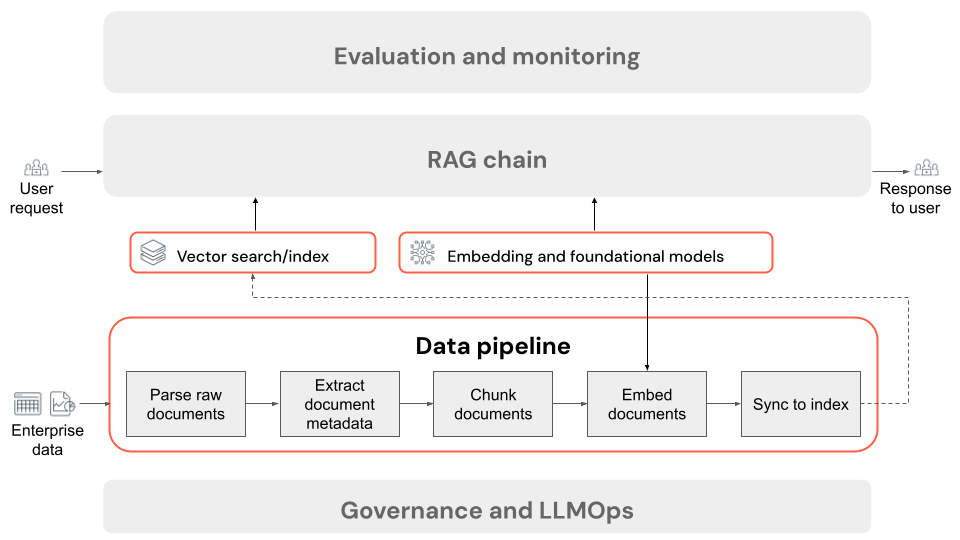
Durante la preparación de los datos, la canalización de datos de la aplicación RAG toma datos no estructurados sin procesar y los transforma en fragmentos discretos que se pueden consultar en función de su relevancia para una consulta del usuario. Los pasos clave del preprocesamiento de datos se describen a continuación. Cada paso tiene una variedad de botones que se pueden ajustar: para obtener una explicación más profunda sobre estos botones, consulte Mejorar la calidad de la aplicación RAG.
Preparación de datos no estructurados para la recuperación
En el resto de esta sección, se describe el proceso de preparación de datos no estructurados para la recuperación mediante la búsqueda semántica. La búsqueda semántica comprende el significado contextual y la intención de una consulta de usuario para proporcionar resultados de búsqueda más relevantes.
La búsqueda semántica es uno de los distintos enfoques que se pueden tomar al implementar el componente de recuperación de una aplicación RAG sobre datos no estructurados. Estos documentos tratan estrategias de recuperación alternativas en la sección de mandos de recuperación.
Pasos de una canalización de datos de aplicación RAG
Estos son los pasos típicos de una canalización de datos en una aplicación RAG mediante datos no estructurados:
- Analizar los documentos sin procesar: el paso inicial implica transformar los datos sin procesar en un formato utilizable. Esto puede incluir la extracción de texto, tablas e imágenes de una colección de archivos PDF o el empleo de técnicas de reconocimiento óptico de caracteres (OCR) para extraer texto de imágenes.
- Extraer metadatos de documento (opcional): en algunos casos, extraer y usar metadatos del documento, como títulos, números de página, direcciones URL u otra información, puede ayudar a que el paso de recuperación consulte con mayor precisión los datos correctos.
- Fragmentar documentos: para asegurarse de que los documentos analizados se ajustan al modelo de inserción y a la ventana de contexto del LLM, se dividen los documentos analizados en fragmentos más pequeños y discretos. La recuperación de estos fragmentos centrados, en lugar de documentos completos, proporciona al LLM un contexto más dirigido desde el que generar sus respuestas.
- Insertar fragmentos: en una aplicación RAG que usa la búsqueda semántica, un tipo especial de modelo de lenguaje llamado modelo de inserción transforma cada uno de los fragmentos del paso anterior en vectores numéricos, o listas de números, que encapsulan el significado de cada fragmento de contenido. Fundamentalmente, estos vectores representan el significado semántico del texto, no solo palabras clave de nivel de superficie. Esto permite realizar búsquedas basadas en significados en lugar de coincidencias de texto literal.
- Indexar los fragmentos en una base de datos vectorial: el último paso consiste en cargar las representaciones vectoriales de los fragmentos, junto con el texto del fragmento, en una base de datos vectorial. Una base de datos vectorial es un tipo especializado de base de datos diseñada para almacenar y buscar datos vectoriales de forma eficaz, como inserciones. Para mantener el rendimiento con un gran número de fragmentos, las bases de datos vectoriales suelen incluir un índice vectorial que usa varios algoritmos para organizar y asignar las inserciones vectoriales de una manera que optimiza la eficacia de la búsqueda. En el momento de la consulta, una solicitud del usuario se inserta en un vector y la base de datos aprovecha el índice de vectores para buscar los vectores de fragmento más similares, devolviendo los fragmentos de texto originales correspondientes.
El proceso de similitud informática puede ser costoso a nivel computacional. Los índices vectoriales, como el vector de búsqueda de Databricks, aceleran este proceso proporcionando un mecanismo para organizar y navegar de forma eficaz por inserciones, a menudo a través de métodos de aproximación sofisticados. Esto permite una clasificación rápida de los resultados más relevantes sin comparar cada inserción con la consulta del usuario individualmente.
Cada paso de la canalización de datos implica decisiones de ingeniería que afectan a la calidad de la aplicación RAG. Por ejemplo, elegir el tamaño correcto del fragmento en el paso 3 garantiza que el LLM recibe información específica pero contextualizada, mientras que la selección de un modelo de inserción adecuado en el paso 4 determina la precisión de los fragmentos devueltos durante la recuperación.
Este proceso de preparación de datos se conoce como preparación de datos sin conexión, ya que se produce antes de que el sistema responda a las consultas, a diferencia de los pasos en línea desencadenados cuando un usuario envía una consulta.