Evaluación del rendimiento: métricas que importan
En este artículo se describe la medición del rendimiento de una aplicación RAG para la calidad de recuperación, respuesta y rendimiento del sistema.
Recuperación, respuesta y rendimiento
Con un conjunto de evaluación, puede medir el rendimiento de la aplicación RAG en varias dimensiones diferentes, entre las que se incluyen:
- Calidad de recuperación: las métricas de recuperación evalúan la forma correcta en que la aplicación RAG recupera los datos auxiliares pertinentes. La precisión y la coincidencia son dos métricas de recuperación clave.
- Calidad de respuesta: las métricas de calidad de respuesta evalúan la calidad de respuesta que la aplicación RAG responde a la solicitud de un usuario. Las métricas de respuesta pueden medir, por ejemplo, si la respuesta resultante es precisa según la verdad básica, cómo de bien fundamentada estaba la respuesta dado el contexto recuperado (por ejemplo, ¿alucinó el LLM?) o cuál era el grado de seguridad de la respuesta (por ejemplo, sin toxicidad).
- Rendimiento del sistema (costo y latencia): las métricas capturan el costo general y el rendimiento de las aplicaciones RAG. La latencia general y el consumo de tokens son ejemplos de métricas de rendimiento de la cadena.
Es muy importante recopilar métricas de respuesta y recuperación. Una aplicación RAG puede responder mal a pesar de recuperar el contexto correcto; también puede proporcionar buenas respuestas en función de las recuperaciones erróneas. Solo al medir ambos componentes podemos diagnosticar y solucionar problemas con precisión en la aplicación.
Enfoques para medir el rendimiento
Hay dos enfoques clave para medir el rendimiento en estas métricas:
- Medición determinista: las métricas de costo y latencia se pueden calcular determinísticamente en función de las salidas de la aplicación. Si el conjunto de evaluación incluye una lista de documentos que contienen la respuesta a una pregunta, también se puede calcular de forma determinista un subconjunto de las métricas de recuperación.
- Medición basada en el juez de LLM: en este enfoque, un LLM independiente actúa como juez para evaluar la calidad de la recuperación y las respuestas de la aplicación RAG. Algunos jueces de LLM, como la corrección de respuestas, comparan la verdad básica con la etiqueta humana frente a las salidas de la aplicación. Otros jueces de LLM, como el de fundamentación, no requieren una verdad de base etiquetada por humanos para evaluar los resultados de sus aplicaciones.
Importante
Para que un juez LLM sea eficaz, debe optimizarse para comprender el caso de uso. Para ello, es preciso prestar atención a comprender dónde funciona el juez bien y dónde no funciona bien el juez y, a continuación, ajustar el juez para mejorarlo para los casos de error.
Evaluación del agente AI de Mosaic proporciona una implementación lista para usar, utilizando modelos de jueces de LLM hospedados, para cada métrica que se describe en esta página. La documentación de Evaluación de Agentes describe los detalles de cómo se implementan estas métricas y jueces y proporciona capacidades para afinar los jueces con sus datos para aumentar su precisión
Información general de las métricas
A continuación se muestra un resumen de las métricas que Databricks recomienda para medir la calidad, el costo y la latencia de la aplicación RAG. Estas métricas se implementan en la evaluación del agente de IA de Mosaico.
| Dimensión | Nombre de métrica | Pregunta | Medido por | ¿Necesita la verdad sobre el terreno? |
|---|---|---|---|---|
| Recuperación | chunk_relevance/precision | ¿Qué porcentaje de los fragmentos recuperados son relevantes para la solicitud? | Juez de LLM | No |
| Recuperación | document_recall | ¿Qué porcentaje de los documentos de verdad del suelo se representan en los fragmentos recuperados? | Determinista | Sí |
| Respuesta | corrección | En general, ¿generó el agente una respuesta correcta? | Juez de LLM | Sí |
| Respuesta | relevance_to_query | ¿Es pertinente la respuesta para la solicitud? | Juez de LLM | No |
| Respuesta | base | ¿Es la respuesta una alucinación o está basada en el contexto? | Juez de LLM | No |
| Respuesta | seguridad | ¿Hay contenido dañino en la respuesta? | Juez de LLM | No |
| Coste | total_token_count, total_input_token_count, total_output_token_count | ¿Cuál es el recuento total de tokens para las generaciones de LLM? | Determinista | No |
| Latencia | latency_seconds | ¿Cuál es la latencia de ejecutar la aplicación? | Determinista | No |
Funcionamiento de las métricas de recuperación
Las métricas de recuperación le ayudan a comprender si el recuperador proporciona resultados relevantes. Las métricas de recuperación se basan en precisión y recuperación.
| Nombre de la métrica | Pregunta respondida | Detalles |
|---|---|---|
| Precisión | ¿Qué porcentaje de los fragmentos recuperados son relevantes para la solicitud? | La precisión es la proporción de documentos recuperados que realmente son relevantes para la solicitud del usuario. Un juez de LLM se puede usar para evaluar la relevancia de cada fragmento recuperado en la solicitud del usuario. |
| Recuperación | ¿Qué porcentaje de los documentos de verdad del suelo se representan en los fragmentos recuperados? | La recuperación es la proporción de los documentos de verdad del suelo que se representan en los fragmentos recuperados. Se trata de una medida de la integridad de los resultados. |
Precisión y recuperación
A continuación se muestra una guía rápida sobre Precisión y recuperación adaptada del excelente artículo de Wikipedia.
Fórmula de precisión
La precisión mide "De los fragmentos que he recuperado, ¿qué % de estos elementos son realmente relevantes para la consulta de mi usuario?" La precisión computacional no requiere conocer todos los elementos relevantes.
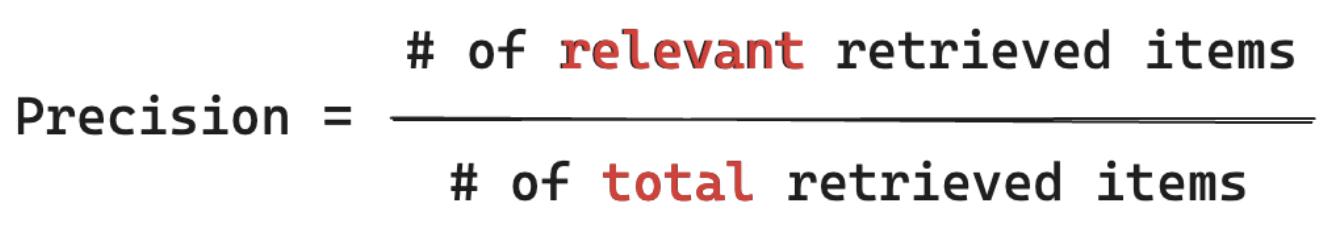
Fórmula de recuperación
Medidas de recuperación "De TODOS los documentos que sé que son relevantes para la consulta de mi usuario, ¿de qué % he recuperado un fragmento?" El cálculo de la memoria requiere que su verdad básica contenga todos los elementos relevantes. Los elementos pueden ser un documento o un fragmento de un documento.
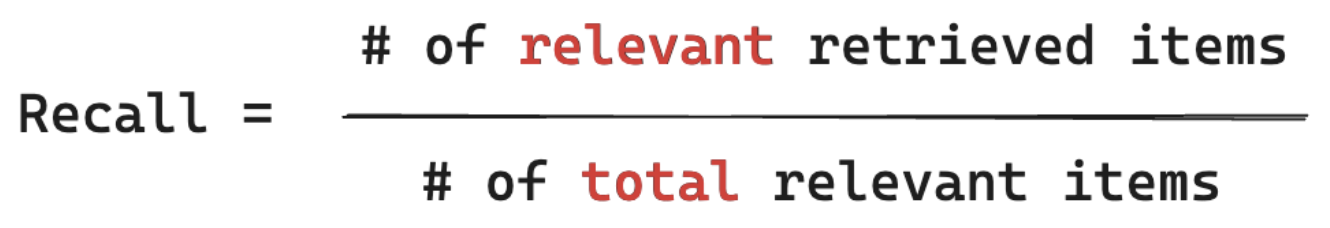
En el ejemplo siguiente, dos de los tres resultados recuperados eran relevantes para la consulta del usuario, por lo que la precisión era 0,66 (2/3). Los documentos recuperados incluían dos de un total de cuatro documentos pertinentes, por lo que la recuperación era 0,5 (2/4).