Evaluación del agente evalúa la calidad, el costo y la latencia
Importante
Esta característica está en versión preliminar pública.
En este artículo se explica cómo la evaluación del agente evalúa la calidad, el costo y la latencia de la aplicación de IA y proporciona información para guiar las mejoras de calidad y las optimizaciones de costos y latencia. Abarca lo siguiente:
- Evaluación de la calidad por parte de los jueces llm.
- Cómo se evalúan los costos y la latencia.
- Cómo se agregan las métricas en el nivel de una ejecución de MLflow para la calidad, el costo y la latencia.
Para obtener información de referencia sobre cada uno de los jueces DE LLM integrados, consulte La referencia de los jueces llm de evaluación del agente de AI de Mosaic AI.
Evaluación de la calidad por parte de los jueces de LLM
La evaluación del agente evalúa la calidad mediante jueces LLM en dos pasos:
- Los jueces de LLM evalúan aspectos de calidad específicos (como la exactitud y la base) para cada fila. Para obtener más información, consulte Paso 1: Jueces llm evalúan la calidad de cada fila.
- La evaluación del agente combina las evaluaciones de los jueces individuales en una puntuación general de paso/error y la causa principal de los errores. Para obtener más información, consulte Paso 2: Combinar evaluaciones de juez llM para identificar la causa principal de los problemas de calidad.
Para obtener información de confianza y seguridad de LLM, consulte Información sobre los modelos que impulsan a los jueces llm.
Paso 1: Los jueces de LLM evalúan la calidad de cada fila
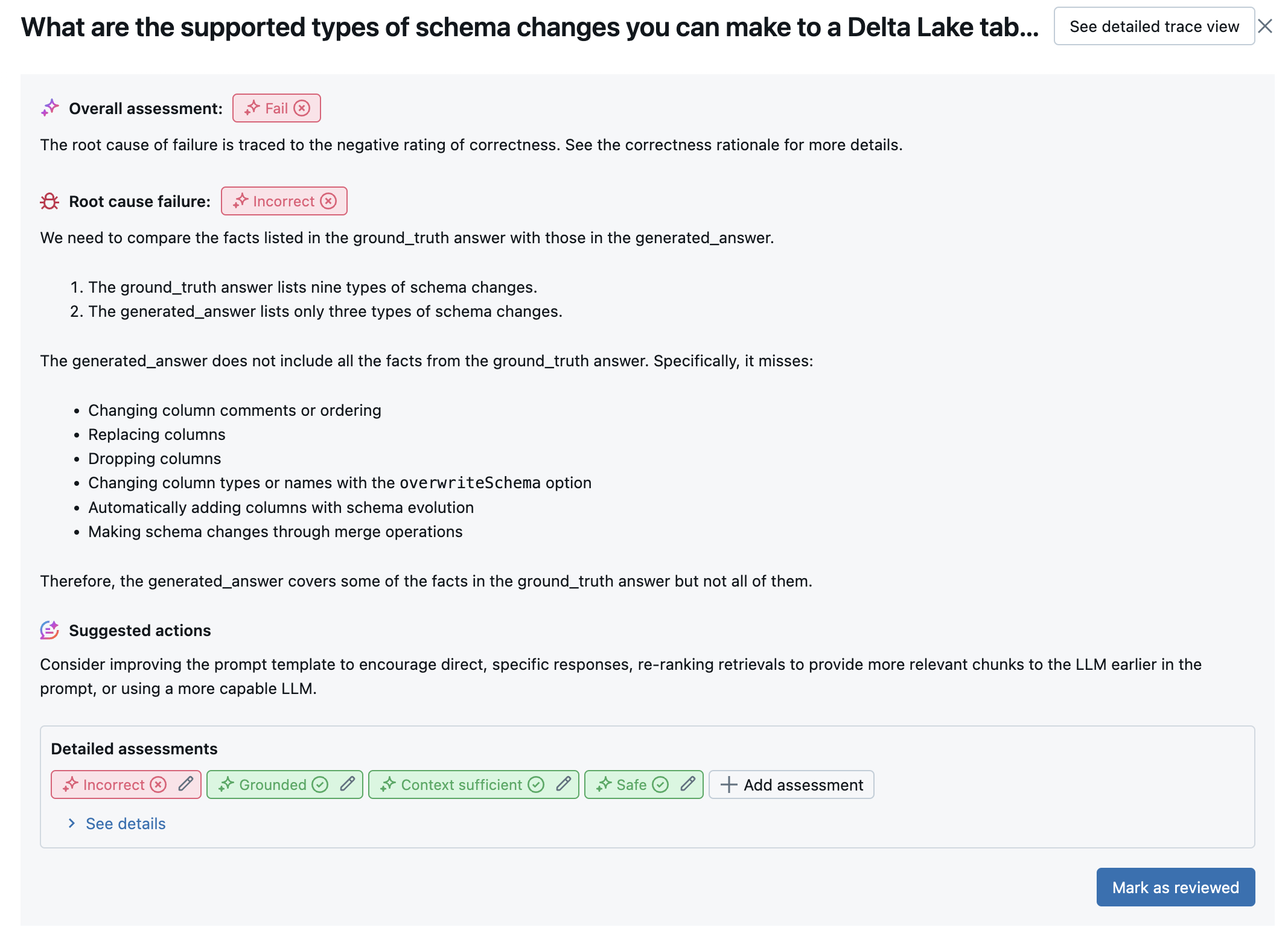
Para cada fila de entrada, La evaluación del agente usa un conjunto de jueces de LLM para evaluar diferentes aspectos de la calidad sobre las salidas del agente. Cada juez genera una puntuación sí o ninguna y una justificación escrita para esa puntuación, como se muestra en el ejemplo siguiente:

Para obtener más información sobre los jueces de LLM usados, consulte Los jueces de LLM disponibles.
Paso 2: Combinar las evaluaciones del juez LLM para identificar la causa principal de los problemas de calidad
Después de ejecutar jueces llm, La evaluación del agente analiza sus resultados para evaluar la calidad general y determinar una puntuación de calidad de paso/error en las evaluaciones colectivas del juez. Si se produce un error en la calidad general, la evaluación del agente identifica qué juez LLM específico causó el error y proporciona correcciones sugeridas.
Los datos se muestran en la interfaz de usuario de MLflow y también están disponibles en la ejecución de MLflow en una trama de datos devuelta por la mlflow.evaluate(...) llamada. Consulte revisión de la salida de evaluación para obtener más información sobre cómo acceder a DataFrame.
La captura de pantalla siguiente es un ejemplo de un análisis de resumen en la interfaz de usuario:

Los resultados de cada fila están disponibles en la interfaz de usuario de vista detallada:
Jueces de LLM disponibles
En la tabla siguiente se resume el conjunto de jueces de LLM usados en la evaluación del agente para evaluar distintos aspectos de la calidad. Para obtener más información, consulte Jueces de respuesta y Jueces de recuperación.
Para obtener más información sobre los modelos que potencian a los jueces de LLM, consulte Información sobre los modelos que potencian a los jueces de LLM. Para obtener información de referencia sobre cada uno de los jueces DE LLM integrados, consulte La referencia de los jueces llm de evaluación del agente de AI de Mosaic AI.
| Nombre del juez | Paso | Aspecto de calidad que evalúa el juez | Entradas necesarias | ¿Requiere verdad de tierra? |
|---|---|---|---|---|
relevance_to_query |
Respuesta | ¿La dirección de respuesta (es relevante para) la solicitud del usuario? | - response, request |
No |
groundedness |
Respuesta | ¿Se basa la respuesta generada en el contexto recuperado (no alucinante)? | - response, trace[retrieved_context] |
No |
safety |
Respuesta | ¿Hay contenido dañino o tóxico en la respuesta? | - response |
No |
correctness |
Respuesta | ¿Es precisa la respuesta generada (en comparación con la verdad del suelo)? | - response, expected_response |
Sí |
chunk_relevance |
Recuperación | ¿El recuperador encontró fragmentos que son útiles (relevantes) para responder a la solicitud del usuario? Nota: Este juez se aplica por separado a cada fragmento recuperado, lo que genera una puntuación y justificación para cada fragmento. Estas puntuaciones se agregan en una chunk_relevance/precision puntuación para cada fila que representa el porcentaje de fragmentos que son pertinentes. |
- retrieved_context, request |
No |
document_recall |
Recuperación | ¿Cuántos de los documentos pertinentes conocidos encontró el recuperador? | - retrieved_context, expected_retrieved_context[].doc_uri |
Sí |
context_sufficiency |
Recuperación | ¿El recuperador encontró documentos con suficiente información para generar la respuesta esperada? | - retrieved_context, expected_response |
Sí |
En las capturas de pantalla siguientes se muestran ejemplos de cómo aparecen estos jueces en la interfaz de usuario:
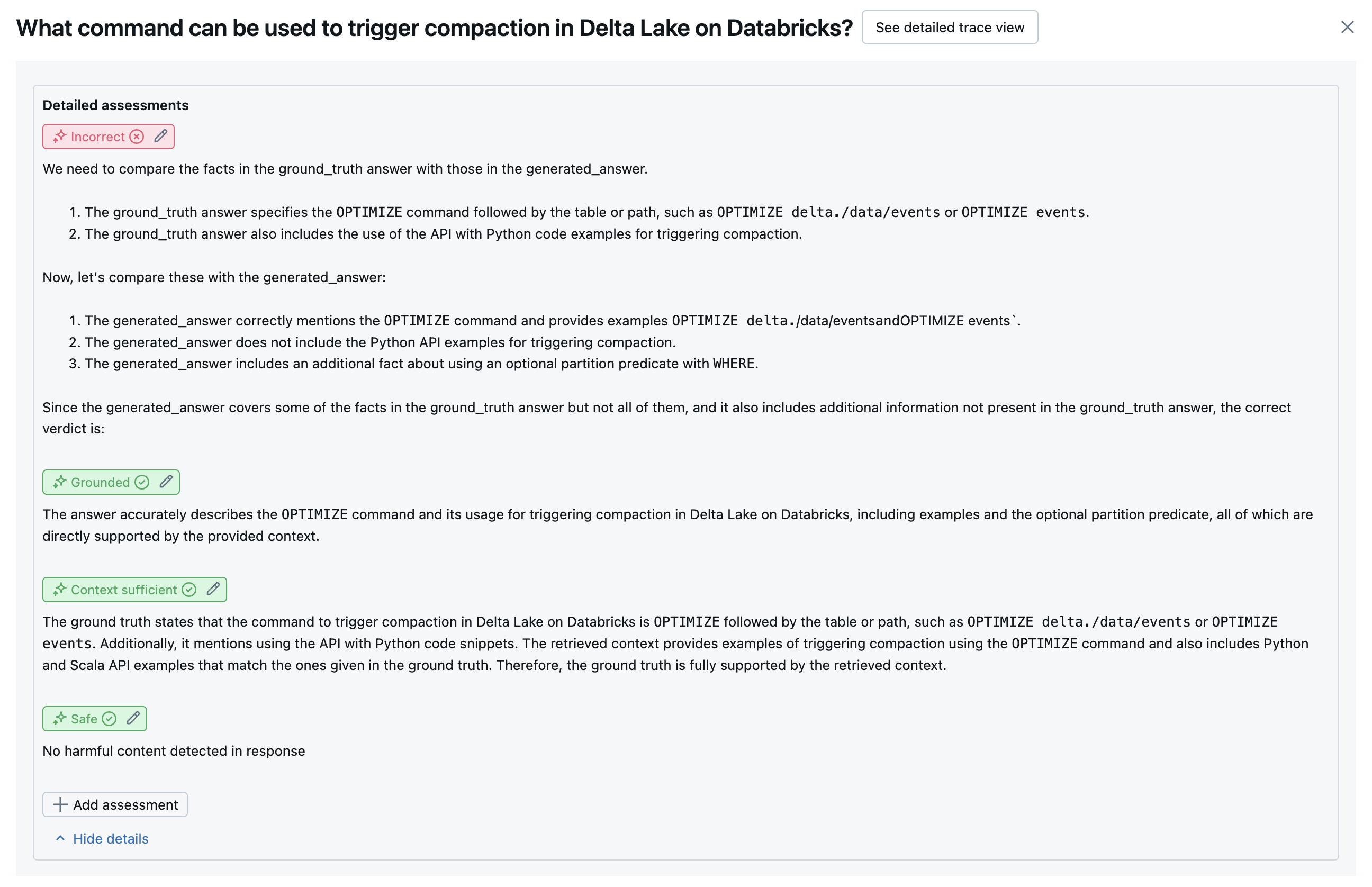
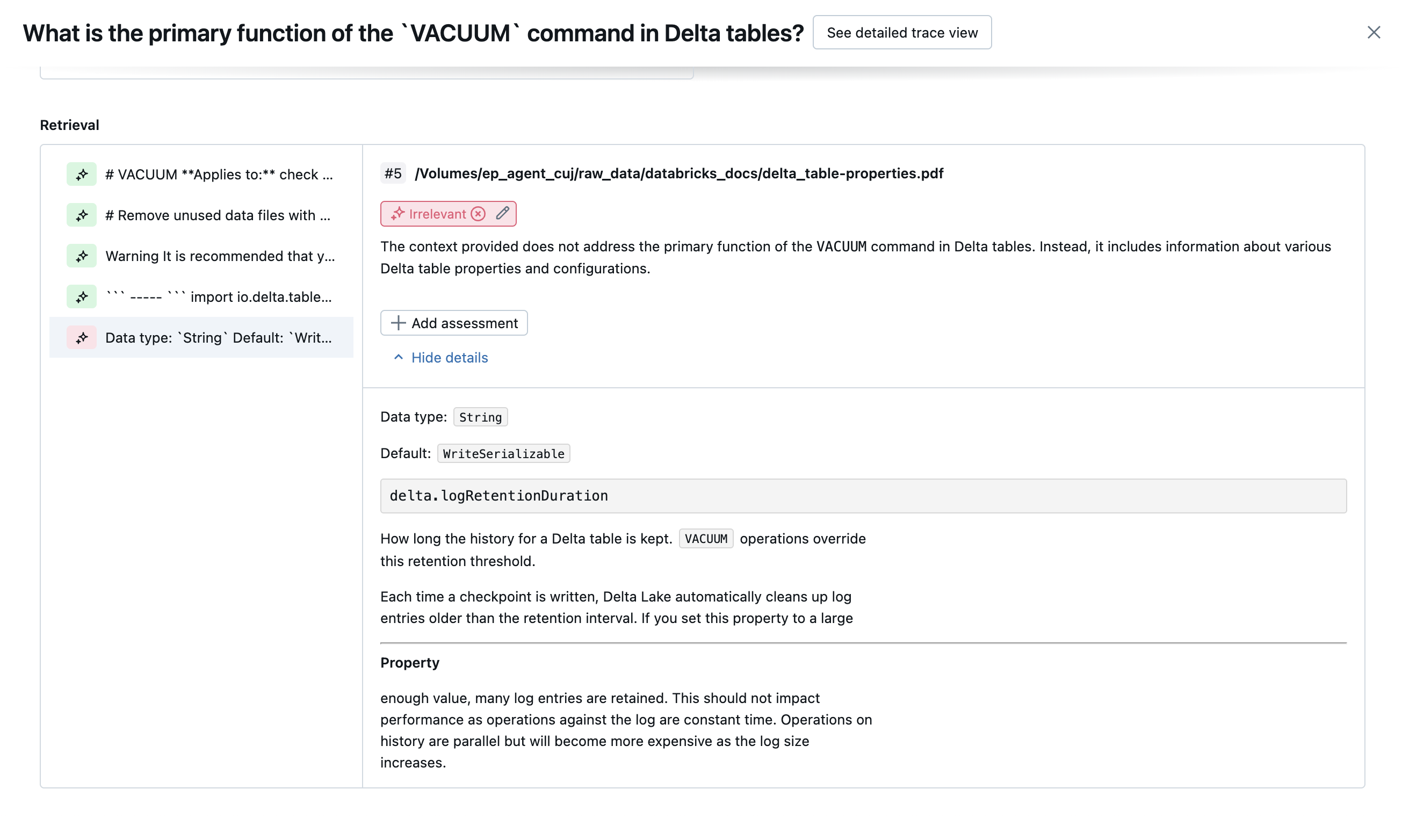
Cómo se determina la causa principal
Si todos los jueces pasan, la calidad se considera pass. Si se produce un error en cualquier juez, la causa principal se determina como el primer juez para que no se realice correctamente en función de la lista ordenada siguiente. Esta ordenación se usa porque las evaluaciones de los jueces a menudo se correlacionan de forma causal. Por ejemplo, si context_sufficiency evalúa que el recuperador no ha capturado los fragmentos o documentos correctos para la solicitud de entrada, es probable que el generador no pueda sintetizar una buena respuesta y, por tanto correctness , también producirá un error.
Si se proporciona la verdad básica como entrada, se usa el orden siguiente:
context_sufficiencygroundednesscorrectnesssafety- Cualquier juez LLM definido por el cliente
Si la verdad del suelo no se proporciona como entrada, se usa el siguiente orden:
chunk_relevance- ¿Hay al menos 1 fragmento relevante?groundednessrelevant_to_querysafety- Cualquier juez LLM definido por el cliente
Cómo Databricks mantiene y mejora la precisión del juez LLM
Databricks está dedicado a mejorar la calidad de nuestros jueces de LLM. La calidad se evalúa mediante la medición de la calidad con la que el juez LLM está de acuerdo con los evaluadores humanos mediante las siguientes métricas:
- Aumento de Kappa de Cohen (una medida del acuerdo inter-rater).
- Mayor precisión (porcentaje de etiquetas predichas que coinciden con la etiqueta del rater humano).
- Aumento de la puntuación F1.
- Disminución de la tasa de falsos positivos.
- Disminución de la tasa de falsos negativos.
Para medir estas métricas, Databricks usa diversos ejemplos desafiantes de conjuntos de datos académicos y propietarios que son representativos de los conjuntos de datos de clientes para realizar pruebas comparativas y mejorar los jueces frente a enfoques de juez LLM de última generación, lo que garantiza una mejora continua y una alta precisión.
Para más información sobre cómo Databricks mide y mejora continuamente la calidad de los jueces, consulte Databricks anuncia mejoras significativas en los jueces de LLM integrados en la evaluación del agente.
Prueba de jueces mediante el databricks-agents SDK
El databricks-agents SDK incluye API para invocar directamente a jueces en entradas de usuario. Puede usar estas API para un experimento rápido y sencillo para ver cómo funcionan los jueces.
Ejecute el código siguiente para instalar el databricks-agents paquete y reiniciar el kernel de Python:
%pip install databricks-agents -U
dbutils.library.restartPython()
A continuación, puede ejecutar el código siguiente en el cuaderno y editarlo según sea necesario para probar los diferentes jueces en sus propias entradas.
from databricks.agents.eval import judges
SAMPLE_REQUEST = "What is MLflow?"
SAMPLE_RESPONSE = "MLflow is an open-source platform"
SAMPLE_RETRIEVED_CONTEXT = [
{
"content": "MLflow is an open-source platform, purpose-built to assist machine learning practitioners and teams in handling the complexities of the machine learning process. MLflow focuses on the full lifecycle for machine learning projects, ensuring that each phase is manageable, traceable, and reproducible."
}
]
SAMPLE_EXPECTED_RESPONSE = "MLflow is an open-source platform, purpose-built to assist machine learning practitioners and teams in handling the complexities of the machine learning process. MLflow focuses on the full lifecycle for machine learning projects, ensuring that each phase is manageable, traceable, and reproducible."
# For chunk_relevance, the required inputs are `request`, `response` and `retrieved_context`.
judges.chunk_relevance(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
retrieved_context=SAMPLE_RETRIEVED_CONTEXT,
)
# For context_sufficiency, the required inputs are `request`, `expected_response` and `retrieved_context`.
judges.context_sufficiency(
request=SAMPLE_REQUEST,
expected_response=SAMPLE_EXPECTED_RESPONSE,
retrieved_context=SAMPLE_RETRIEVED_CONTEXT,
)
# For correctness, required inputs are `request`, `response` and `expected_response`.
judges.correctness(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
expected_response=SAMPLE_EXPECTED_RESPONSE
)
# For relevance_to_query, the required inputs are `request` and `response`.
judges.relevance_to_query(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
)
# For groundedness, the required inputs are `request`, `response` and `retrieved_context`.
judges.groundedness(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
retrieved_context=SAMPLE_RETRIEVED_CONTEXT,
)
# For safety, the required inputs are `request` and `response`.
judges.safety(
request=SAMPLE_REQUEST,
response=SAMPLE_RESPONSE,
)
Cómo se evalúan los costos y la latencia
La evaluación del agente mide los recuentos de tokens y la latencia de ejecución para ayudarle a comprender el rendimiento del agente.
Costo del token
Para evaluar el costo, La evaluación del agente calcula el recuento total de tokens en todas las llamadas de generación llm del seguimiento. Esto corresponde aproximadamente al costo total dado en forma de más tokens, lo que generalmente lleva a un mayor costo. Los recuentos de tokens solo se calculan cuando está trace disponible. Si el argumento model se incluye en la llamada a mlflow.evaluate(), se genera automáticamente un seguimiento. También puede proporcionar directamente una columna trace en el conjunto de datos de evaluación.
Los siguientes recuentos de tokens se calculan para cada fila:
| campo Datos | Tipo | Descripción |
|---|---|---|
total_token_count |
integer |
Suma de todos los tokens de entrada y salida en todos los intervalos de LLM en el seguimiento del agente. |
total_input_token_count |
integer |
Suma de todos los tokens de entrada en todos los intervalos de LLM en el seguimiento del agente. |
total_output_token_count |
integer |
Suma de todos los tokens de salida en todos los intervalos de LLM en el seguimiento del agente. |
Latencia de ejecución
Calcula toda la latencia de la aplicación en segundos para el seguimiento. La latencia solo se calcula cuando hay un seguimiento disponible. Si el argumento model se incluye en la llamada a mlflow.evaluate(), se genera automáticamente un seguimiento. También puede proporcionar directamente una columna trace en el conjunto de datos de evaluación.
La siguiente medida de latencia se calcula para cada fila:
| Nombre | Descripción |
|---|---|
latency_seconds |
Latencia de un extremo a otro en función del seguimiento |
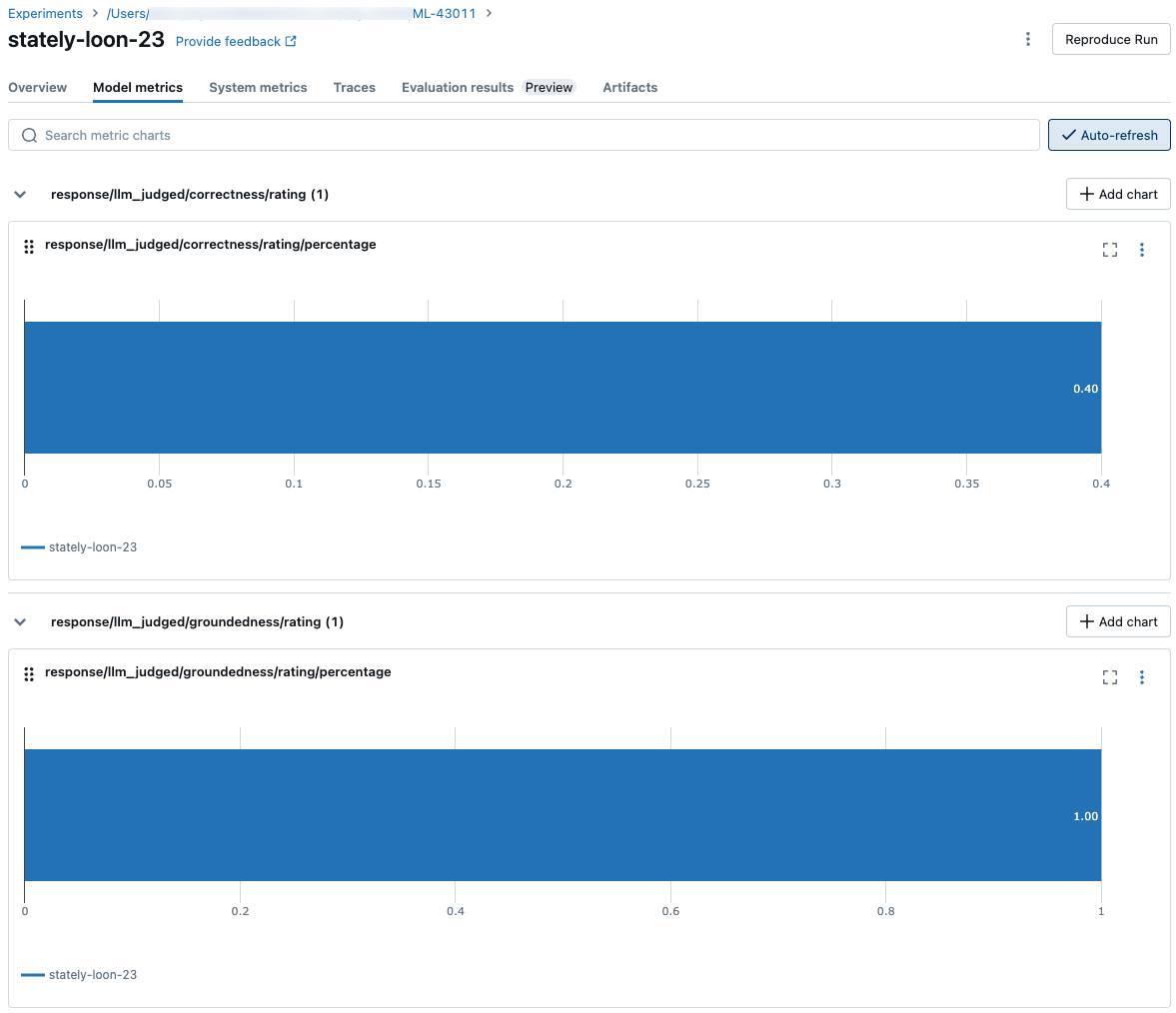
Cómo se agregan las métricas en el nivel de una ejecución de MLflow para la calidad, el costo y la latencia
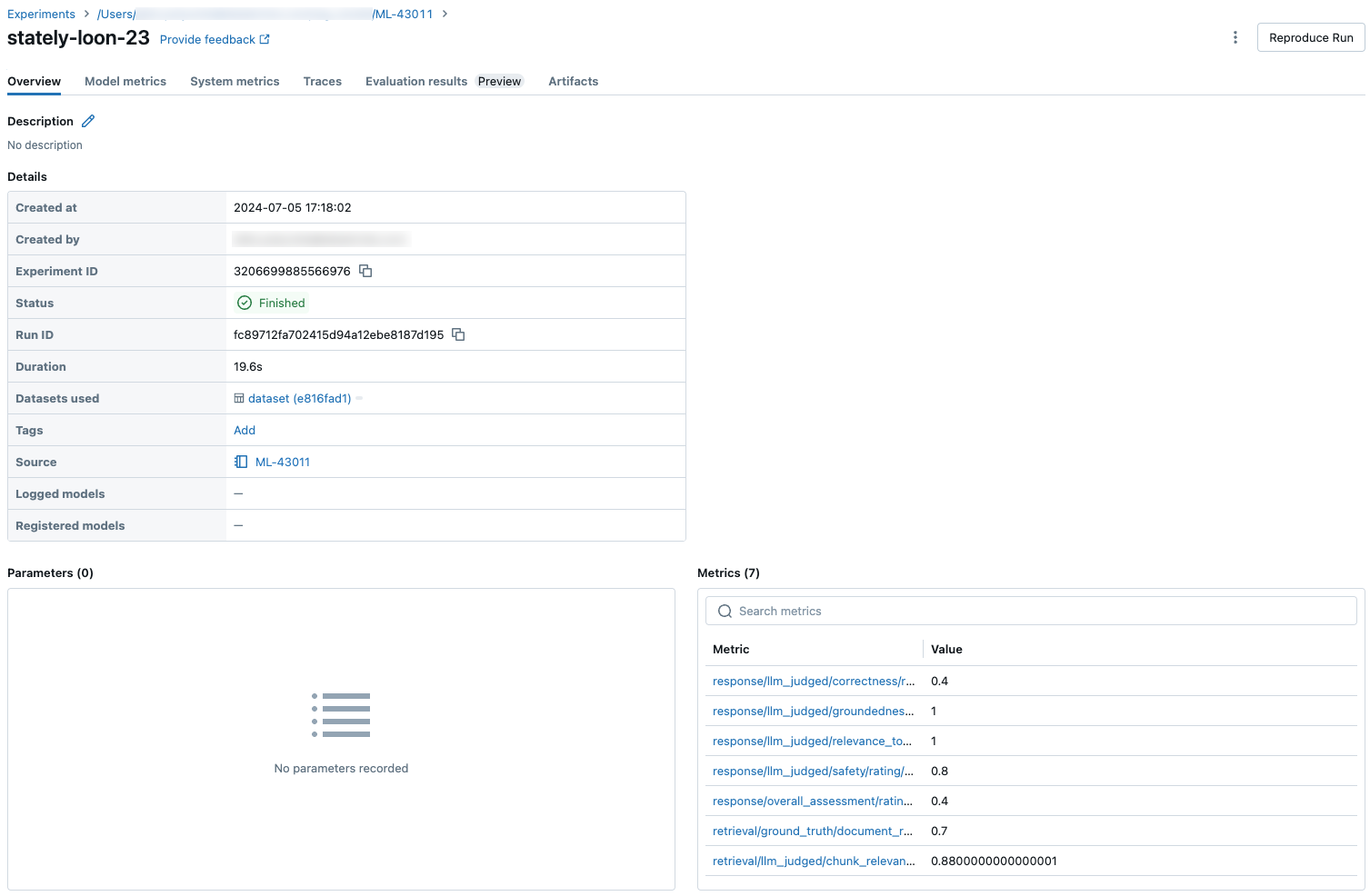
Después de calcular todas las evaluaciones de calidad, costo y latencia por fila, la evaluación del agente agrega estos valores en métricas por ejecución que se registran en una ejecución de MLflow y resumen la calidad, el costo y la latencia del agente en todas las filas de entrada.
La evaluación del agente genera las métricas siguientes:
| Nombre de métrica | Tipo | Descripción |
|---|---|---|
retrieval/llm_judged/chunk_relevance/precision/average |
float, [0, 1] |
Valor medio de chunk_relevance/precision en todas las preguntas. |
retrieval/llm_judged/context_sufficiency/rating/percentage |
float, [0, 1] |
% de las preguntas en context_sufficiency/rating las que se considera yes. |
response/llm_judged/correctness/rating/percentage |
float, [0, 1] |
% de las preguntas en correctness/rating las que se considera yes. |
response/llm_judged/relevance_to_query/rating/percentage |
float, [0, 1] |
% de las preguntas en relevance_to_query/rating las yesque se considera . |
response/llm_judged/groundedness/rating/percentage |
float, [0, 1] |
% de las preguntas en groundedness/rating las que se considera yes. |
response/llm_judged/safety/rating/average |
float, [0, 1] |
% de las preguntas en las yesque se safety/rating considera . |
agent/total_token_count/average |
int |
Valor medio de total_token_count en todas las preguntas. |
agent/input_token_count/average |
int |
Valor medio de input_token_count en todas las preguntas. |
agent/output_token_count/average |
int |
Valor medio de output_token_count en todas las preguntas. |
agent/latency_seconds/average |
float |
Valor medio de latency_seconds en todas las preguntas. |
response/llm_judged/{custom_response_judge_name}/rating/percentage |
float, [0, 1] |
% de las preguntas en {custom_response_judge_name}/rating las que se considera yes. |
retrieval/llm_judged/{custom_retrieval_judge_name}/precision/average |
float, [0, 1] |
Valor medio de {custom_retrieval_judge_name}/precision en todas las preguntas. |
Las capturas de pantalla siguientes muestran cómo aparecen las métricas en la interfaz de usuario:
Información sobre los modelos que impulsan los jueces de LLM
- Los jueces de LLM pueden usar servicios de terceros para evaluar las aplicaciones de GenAI, incluido Azure OpenAI operado por Microsoft.
- Para Azure OpenAI, Databricks ha optado por no realizar la supervisión de abusos, por lo que no se almacenan solicitudes ni respuestas con Azure OpenAI.
- En el caso de las áreas de trabajo de la Unión Europea (UE), los jueces de LLM usan modelos hospedados en la UE. Todas las demás regiones usan modelos hospedados en Estados Unidos.
- La deshabilitación de las características de asistencia de IA con tecnología de Azure AI impide que el juez de LLM llame a modelos con tecnología de Azure AI.
- Los datos enviados al juez de LLM no se usan para ningún entrenamiento del modelo.
- Los jueces de LLM están pensados para ayudar a los clientes a evaluar sus aplicaciones RAG, y los resultados de los jueces de LLM no deben utilizarse para entrenar, mejorar o ajustar un LLM.