Implementación de una carga de trabajo de IoT Edge con uso compartido de GPU en Azure Stack Edge Pro
En este artículo se describe el modo en que las cargas de trabajo en contenedor pueden compartir las GPU en el dispositivo Azure Stack Edge Pro GPU. El enfoque implica habilitar el servicio multiproceso (MPS) y, a continuación, especificar las cargas de trabajo de GPU a través de una implementación de IoT Edge.
Requisitos previos
Antes de comenzar, asegúrese de que:
Tiene acceso a un dispositivo Azure Stack Edge Pro GPU que está activado y que tiene configurado el proceso. Tiene el punto de conexión de la API de Kubernetes y ha agregado este punto de conexión al archivo
hostsdel cliente que va a acceder al dispositivo.Tiene acceso a un sistema cliente con un sistema operativo compatible. Si usa un cliente Windows, el sistema debe ejecutar PowerShell 5.0 o posterior para acceder al dispositivo.
Guarde el siguiente
jsonde implementación en el sistema local. Usará información de este archivo para ejecutar la implementación de IoT Edge. Esta implementación se basa en contenedores CUDA simples que están disponibles públicamente en Nvidia.{ "modulesContent": { "$edgeAgent": { "properties.desired": { "modules": { "cuda-sample1": { "settings": { "image": "nvidia/samples:nbody", "createOptions": "{\"Entrypoint\":[\"/bin/sh\"],\"Cmd\":[\"-c\",\"/tmp/nbody -benchmark -i=1000; while true; do echo no-op; sleep 10000;done\"],\"HostConfig\":{\"IpcMode\":\"host\",\"PidMode\":\"host\"}}" }, "type": "docker", "version": "1.0", "env": { "NVIDIA_VISIBLE_DEVICES": { "value": "0" } }, "status": "running", "restartPolicy": "never" }, "cuda-sample2": { "settings": { "image": "nvidia/samples:nbody", "createOptions": "{\"Entrypoint\":[\"/bin/sh\"],\"Cmd\":[\"-c\",\"/tmp/nbody -benchmark -i=1000; while true; do echo no-op; sleep 10000;done\"],\"HostConfig\":{\"IpcMode\":\"host\",\"PidMode\":\"host\"}}" }, "type": "docker", "version": "1.0", "env": { "NVIDIA_VISIBLE_DEVICES": { "value": "0" } }, "status": "running", "restartPolicy": "never" } }, "runtime": { "settings": { "minDockerVersion": "v1.25" }, "type": "docker" }, "schemaVersion": "1.1", "systemModules": { "edgeAgent": { "settings": { "image": "mcr.microsoft.com/azureiotedge-agent:1.0", "createOptions": "" }, "type": "docker" }, "edgeHub": { "settings": { "image": "mcr.microsoft.com/azureiotedge-hub:1.0", "createOptions": "{\"HostConfig\":{\"PortBindings\":{\"443/tcp\":[{\"HostPort\":\"443\"}],\"5671/tcp\":[{\"HostPort\":\"5671\"}],\"8883/tcp\":[{\"HostPort\":\"8883\"}]}}}" }, "type": "docker", "status": "running", "restartPolicy": "always" } } } }, "$edgeHub": { "properties.desired": { "routes": { "route": "FROM /messages/* INTO $upstream" }, "schemaVersion": "1.1", "storeAndForwardConfiguration": { "timeToLiveSecs": 7200 } } }, "cuda-sample1": { "properties.desired": {} }, "cuda-sample2": { "properties.desired": {} } } }
Comprobación del controlador de GPU, versión de CUDA
El primer paso consiste en comprobar que el dispositivo está ejecutando las versiones de controlador de GPU y CUDA necesarias.
Conéctese a la interfaz de PowerShell del dispositivo.
Ejecute el siguiente comando:
Get-HcsGpuNvidiaSmiEn la salida de Nvidia smi, tome nota de la versión de la GPU y de CUDA en el dispositivo. Si ejecuta software de Azure Stack Edge 2102, esta versión se corresponde con las siguientes versiones de controlador:
- Versión del controlador de GPU: 460.32.03
- Versión de CUDA: 11.2
A continuación, se incluye una salida de ejemplo:
[10.100.10.10]: PS>Get-HcsGpuNvidiaSmi K8S-1HXQG13CL-1HXQG13: Tue Feb 23 10:34:01 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 0000041F:00:00.0 Off | 0 | | N/A 40C P8 15W / 70W | 0MiB / 15109MiB | 0% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+ [10.100.10.10]: PS>Mantenga esta sesión abierta, ya que la usará para ver la salida de Nvidia smi en todo el artículo.
Implementación sin uso compartido de contexto
Ahora puede implementar una aplicación en el dispositivo cuando el servicio multiproceso no se está ejecutando y no hay ningún uso compartido de contexto. La implementación se realiza a través de Azure Portal en el espacio de nombres iotedge que existe en el dispositivo.
Creación de un usuario en el espacio de nombres de IoT Edge
En primer lugar, creará un usuario que se conectará al espacio de nombres iotedge. Los módulos de IoT Edge se implementan en el espacio de nombres iotedge. Para más información, consulte los espacios de nombres de Kubernetes.
Siga estos pasos para crear un usuario y conceder al usuario el acceso al espacio de nombres iotedge.
Conéctese a la interfaz de PowerShell del dispositivo.
Cree un nuevo usuario en el espacio de nombres
iotedge. Ejecute el siguiente comando:New-HcsKubernetesUser -UserName <user name>A continuación, se incluye una salida de ejemplo:
[10.100.10.10]: PS>New-HcsKubernetesUser -UserName iotedgeuser apiVersion: v1 clusters: - cluster: certificate-authority-data: ===========================//snipped //======================// snipped //============================= server: https://compute.myasegpudev.wdshcsso.com:6443 name: kubernetes contexts: - context: cluster: kubernetes user: iotedgeuser name: iotedgeuser@kubernetes current-context: iotedgeuser@kubernetes kind: Config preferences: {} users: - name: iotedgeuser user: client-certificate-data: ===========================//snipped //======================// snipped //============================= client-key-data: ===========================//snipped //======================// snipped ============================ PQotLS0tLUVORCBSU0EgUFJJVkFURSBLRVktLS0tLQo=Copie la salida mostrada en texto sin formato. Guarde la salida como un archivo config (sin extensión) en la carpeta
.kubedel perfil de usuario en el equipo local, por ejemplo,C:\Users\<username>\.kube.Conceda al usuario que creó el acceso al espacio de nombres
iotedge. Ejecute el siguiente comando:Grant-HcsKubernetesNamespaceAccess -Namespace iotedge -UserName <user name>A continuación, se incluye una salida de ejemplo:
[10.100.10.10]: PS>Grant-HcsKubernetesNamespaceAccess -Namespace iotedge -UserName iotedgeuser [10.100.10.10]: PS>
Para instrucciones detalladas, consulte Conexión y administración de un clúster de Kubernetes mediante kubectl en un dispositivo de Azure Stack Edge Pro GPU.
Implementación de módulos a través del portal
Implemente módulos de IoT Edge mediante Azure Portal. Implementará módulos de ejemplo de Nvidia CUDA disponibles públicamente que ejecutan la simulación de n cuerpos.
Asegúrese de que el servicio de IoT Edge se está ejecutando en el dispositivo.
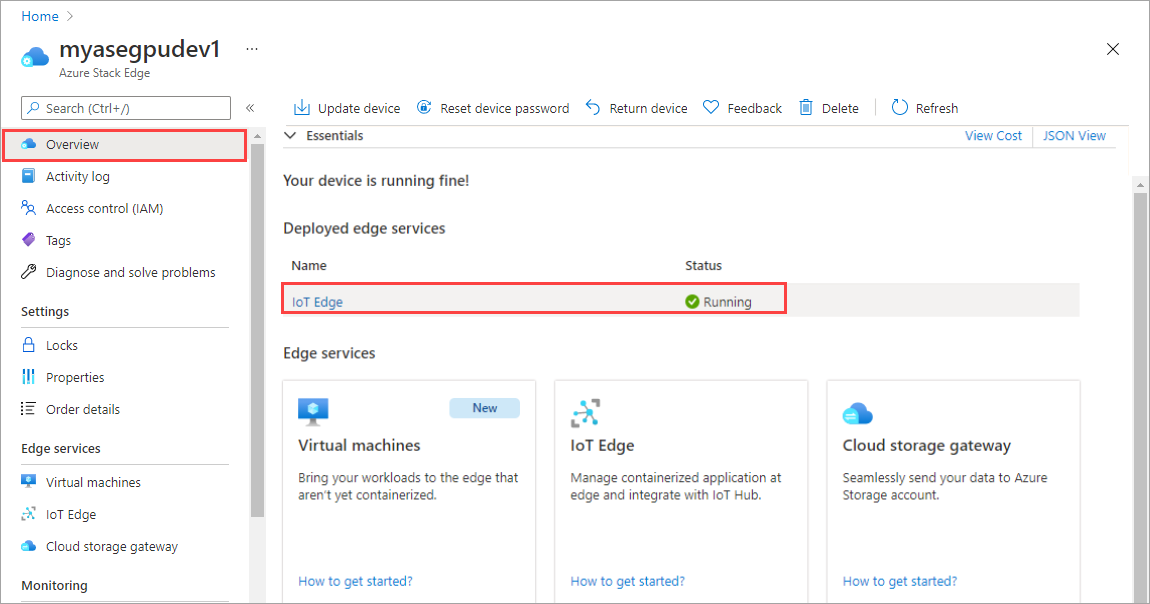
Seleccione el icono de IoT Edge en el panel de la derecha. Vaya a IoT Edge > Propiedades. En el panel de la derecha, seleccione el recurso de IoT Hub asociado con el dispositivo.
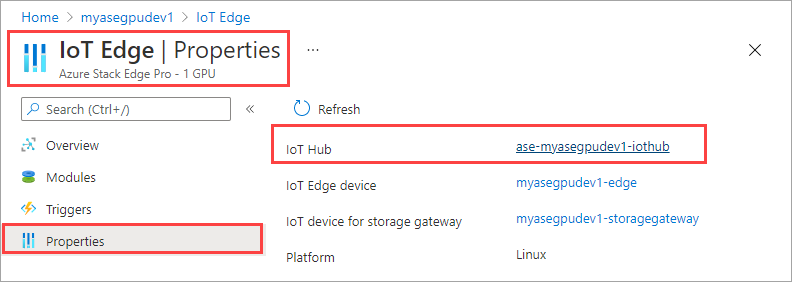
En el recurso de IoT Hub, vaya a Administración de dispositivos automática > IoT Edge. En el panel de la derecha, seleccione el dispositivo de IoT Edge asociado con el dispositivo.
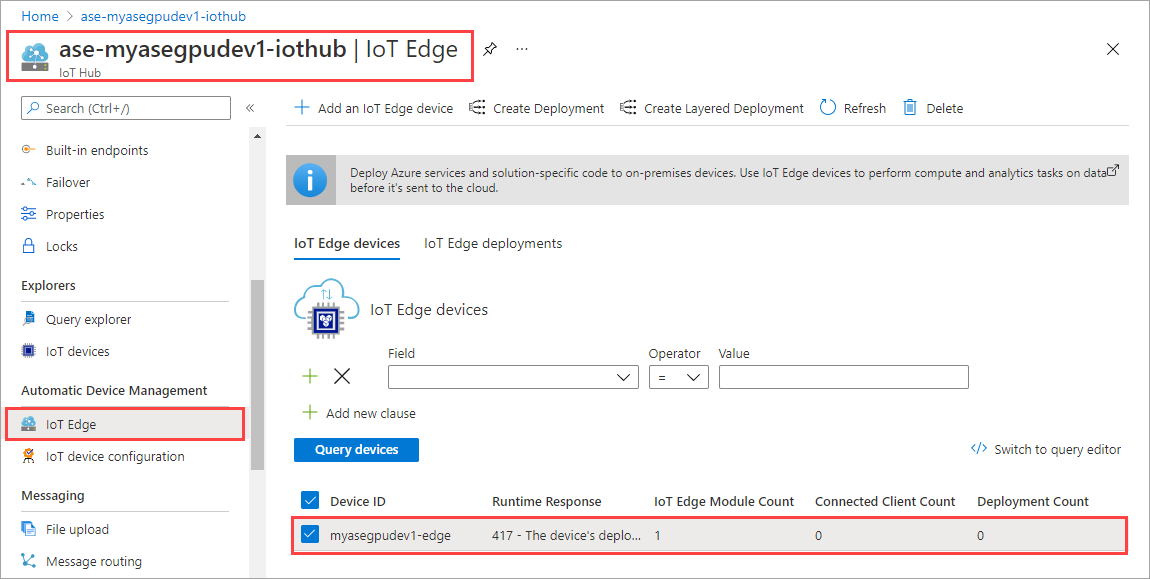
Seleccione Set modules (Establecer módulos).
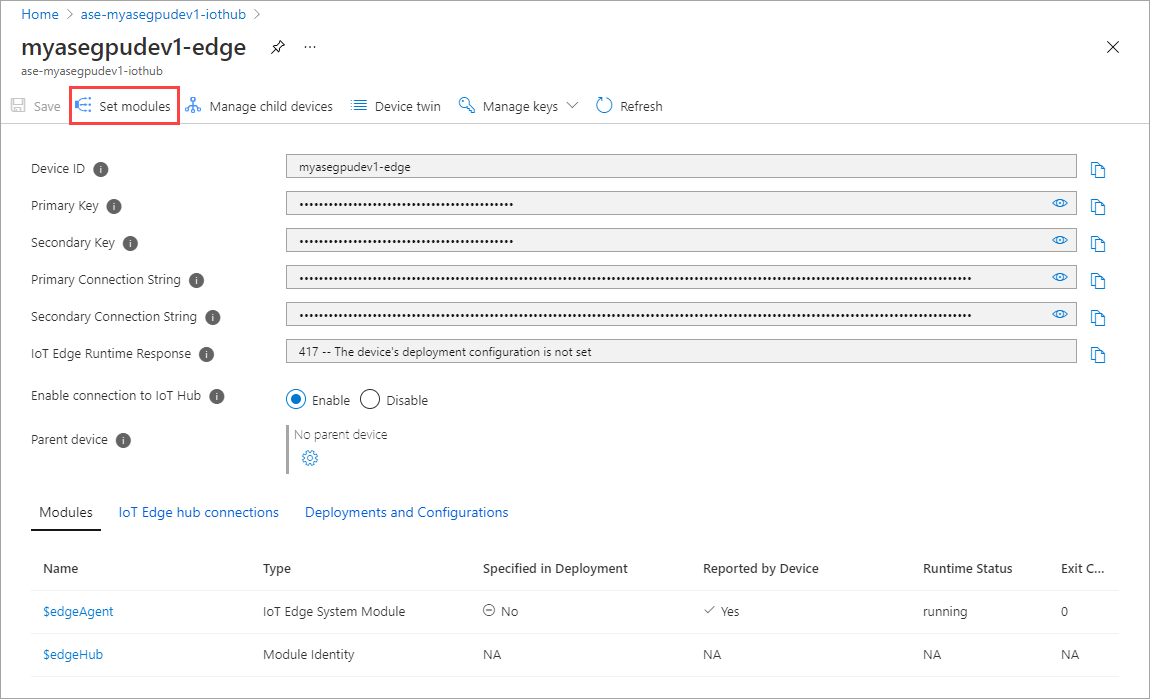
Seleccione + Agregar > + Módulo IoT Edge.
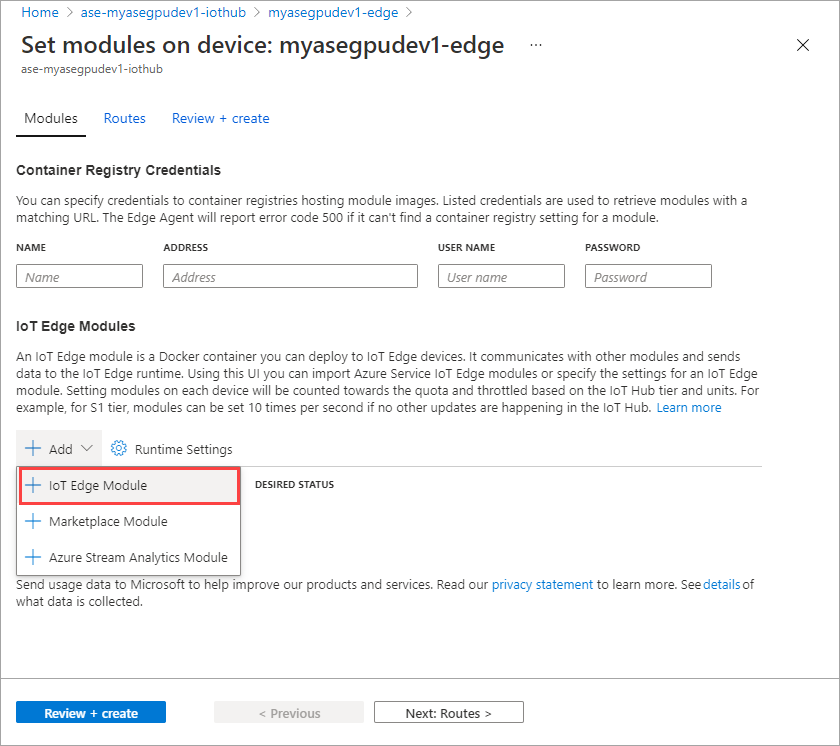
En la pestaña Configuración del módulo, proporcione el Nombre del módulo IoT Edge y el URI de la imagen. Establezca Image pull policy (Directiva de extracción de imagen) en On create (En la creación).
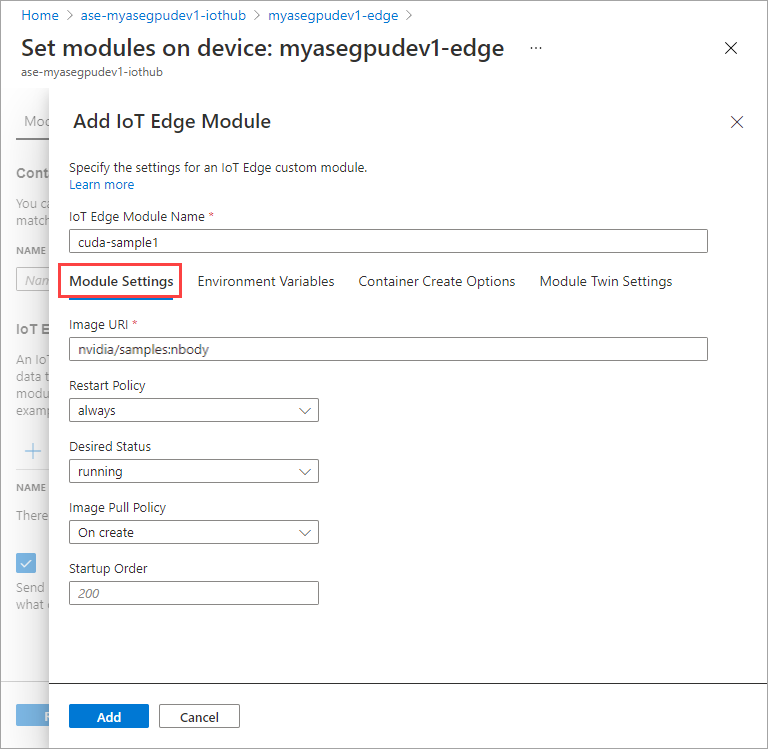
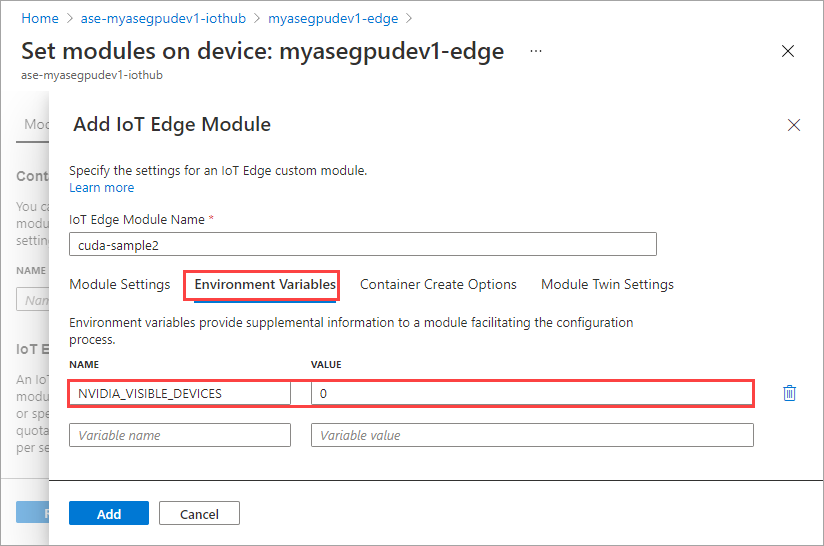
En la pestaña Variables de entorno, especifique NVIDIA_VISIBLE_DEVICES como 0.
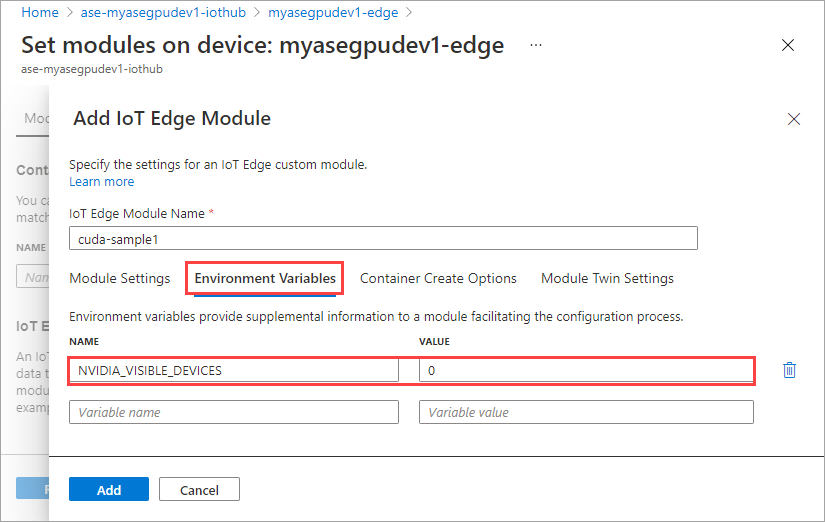
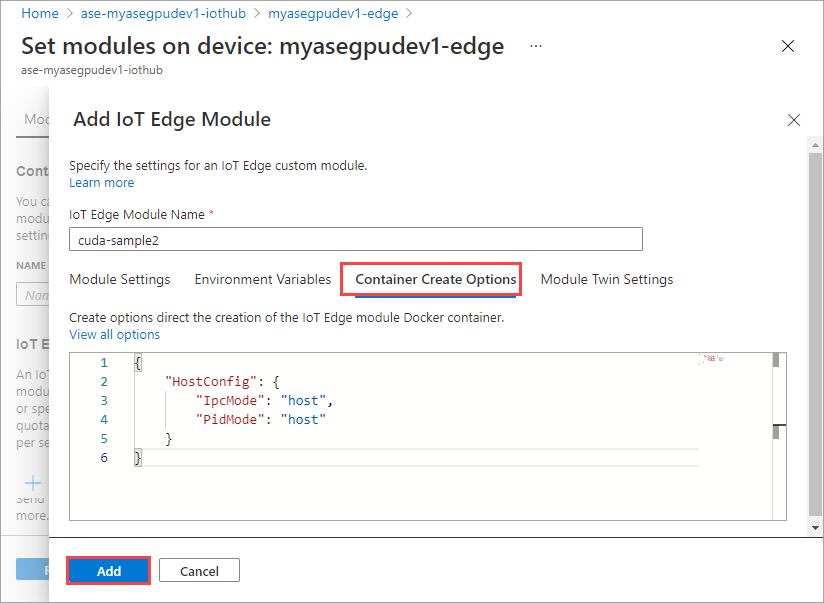
En la pestaña Opciones de creación del contenedor, proporcione las opciones siguientes:
{ "Entrypoint": [ "/bin/sh" ], "Cmd": [ "-c", "/tmp/nbody -benchmark -i=1000; while true; do echo no-op; sleep 10000;done" ], "HostConfig": { "IpcMode": "host", "PidMode": "host" } }Las opciones se muestran de la siguiente manera:
Seleccione Agregar.
El módulo que ha agregado debe aparecer en el estado En ejecución.
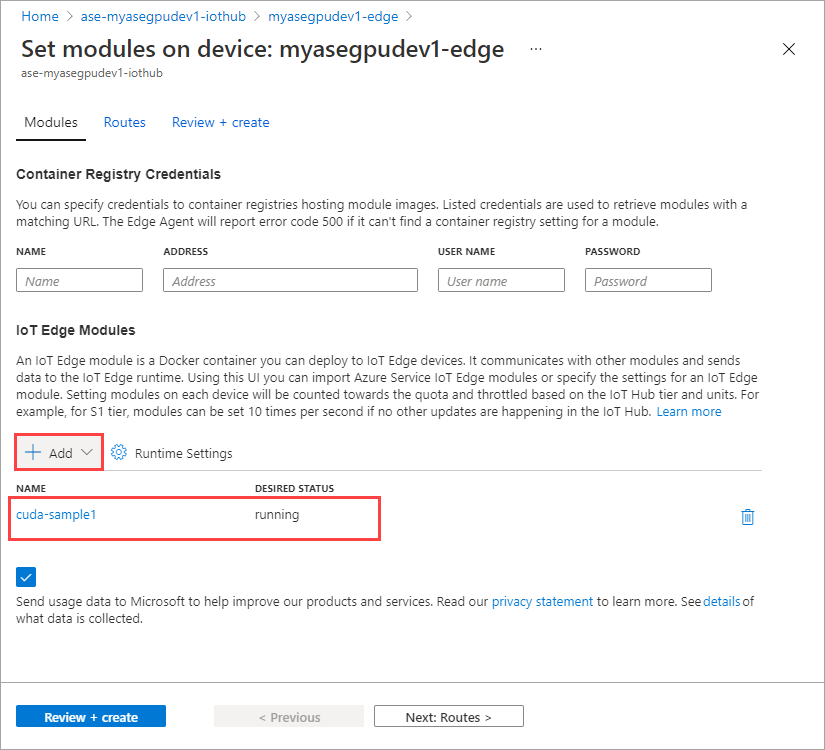
Repita todos los pasos para agregar un módulo que siguió al agregar el primer módulo. En este ejemplo, proporcione el nombre del módulo como
cuda-sample2.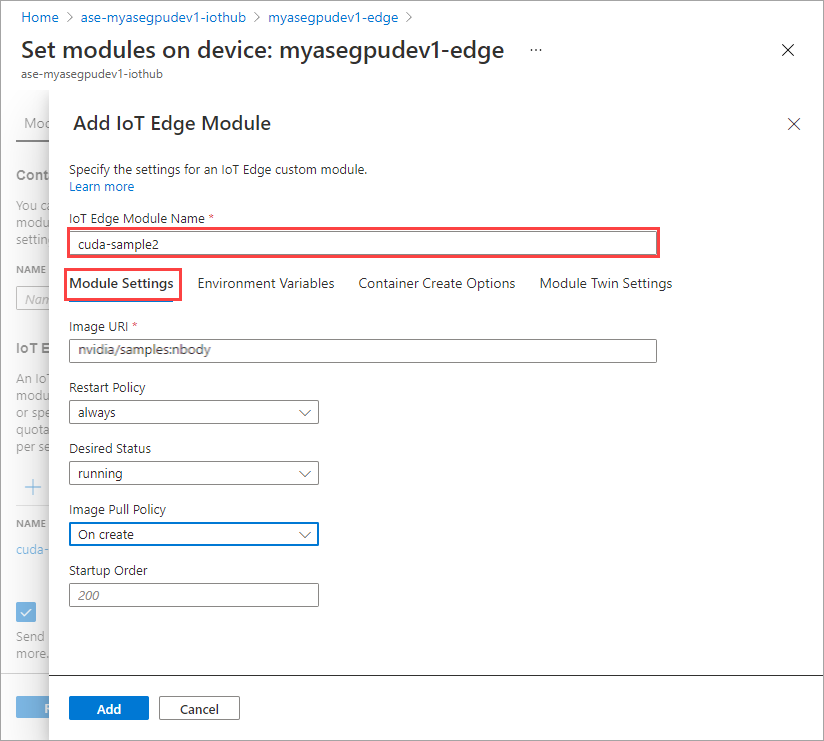
Use la misma variable de entorno ya que ambos módulos compartirán la misma GPU.
Use las mismas opciones de creación de contenedor que proporcionó para el primer módulo y seleccione Agregar.
En la página Establecer módulos, seleccione Revisar y crear y, después, seleccione Crear.
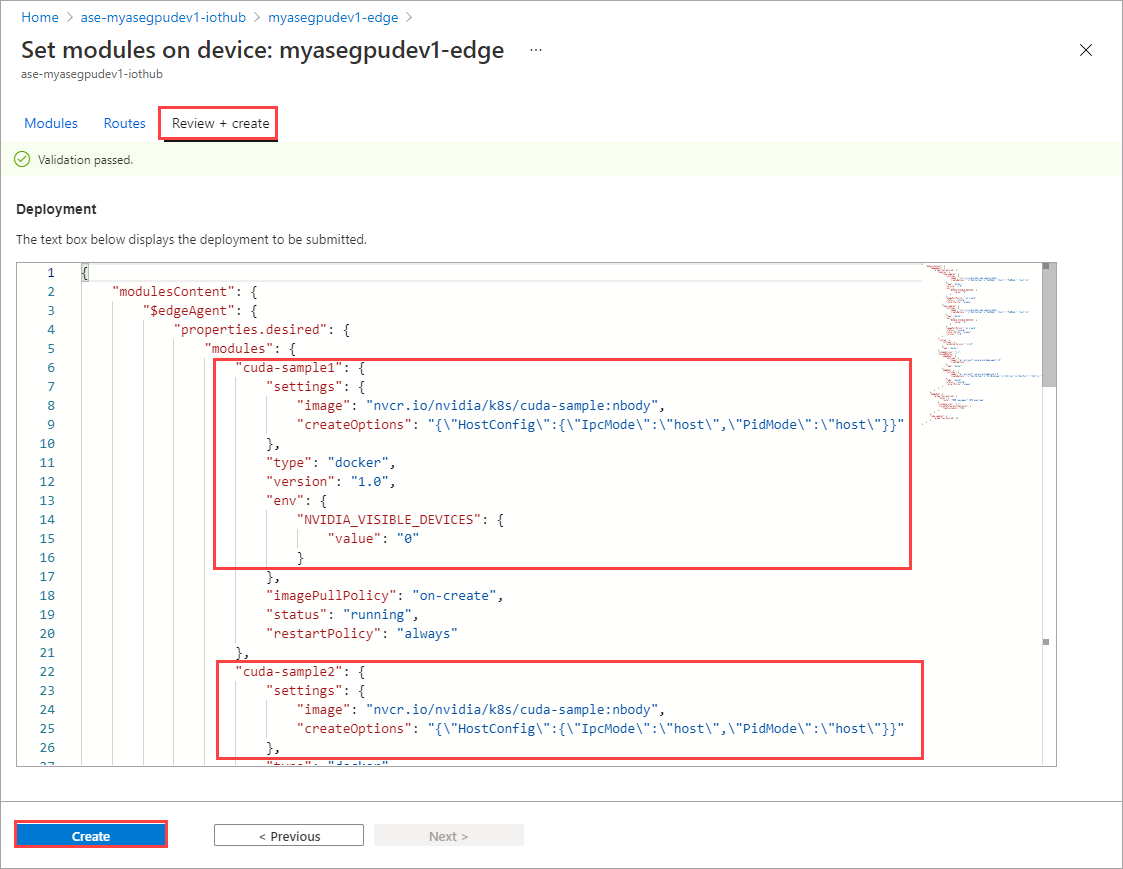
El Estado en tiempo de ejecución de ambos módulos debe indicar ahora En ejecución.
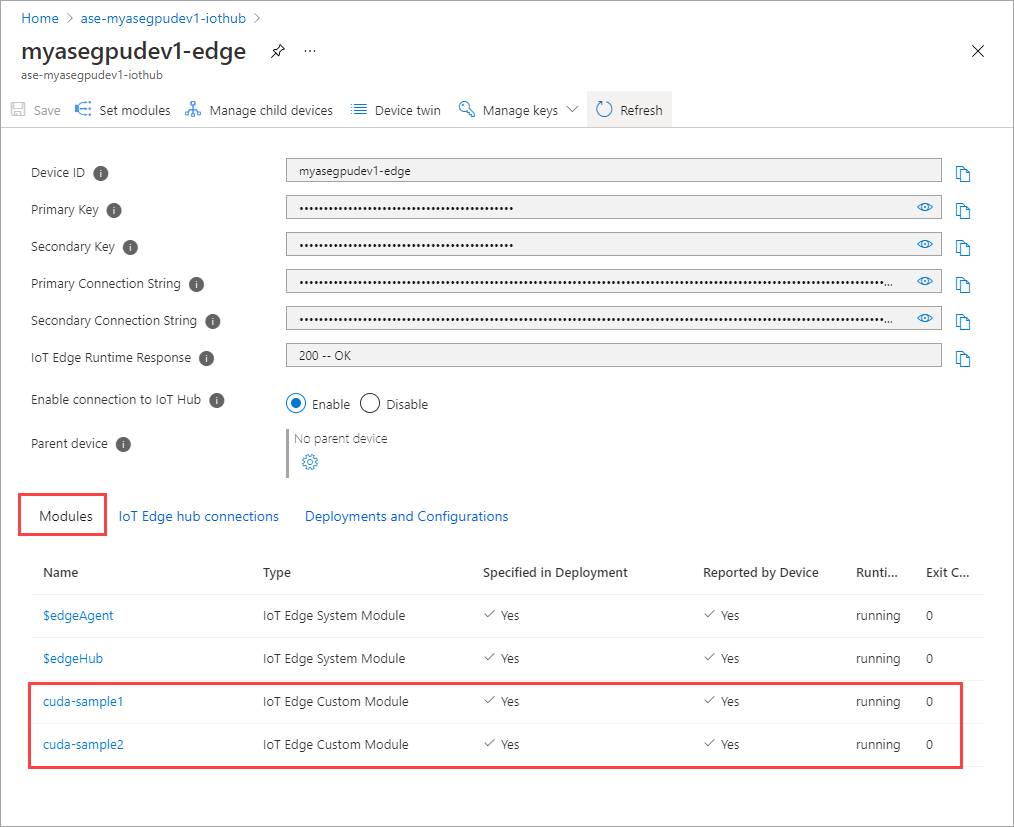
Supervisión de la implementación de cargas de trabajo
Abra una nueva sesión de PowerShell.
Enumere los pods que se ejecutan en el espacio de nombres
iotedge. Ejecute el siguiente comando:kubectl get pods -n iotedgeA continuación, se incluye una salida de ejemplo:
PS C:\WINDOWS\system32> kubectl get pods -n iotedge --kubeconfig C:\GPU-sharing\kubeconfigs\configiotuser1 NAME READY STATUS RESTARTS AGE cuda-sample1-869989578c-ssng8 2/2 Running 0 5s cuda-sample2-6db6d98689-d74kb 2/2 Running 0 4s edgeagent-79f988968b-7p2tv 2/2 Running 0 6d21h edgehub-d6c764847-l8v4m 2/2 Running 0 24h iotedged-55fdb7b5c6-l9zn8 1/1 Running 1 6d21h PS C:\WINDOWS\system32>Hay dos pods,
cuda-sample1-97c494d7f-lnmnsycuda-sample2-d9f6c4688-2rld9, que se ejecutan en el dispositivo.Mientras ambos contenedores ejecutan la simulación de n cuerpos, consulte el uso de la GPU en la salida de Nvidia smi. Vaya a la interfaz de PowerShell del dispositivo y ejecute
Get-HcsGpuNvidiaSmi.Este es un ejemplo de salida cuando ambos contenedores ejecutan la simulación de n cuerpos:
[10.100.10.10]: PS>Get-HcsGpuNvidiaSmi K8S-1HXQG13CL-1HXQG13: Fri Mar 5 13:31:16 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 00002C74:00:00.0 Off | 0 | | N/A 52C P0 69W / 70W | 221MiB / 15109MiB | 100% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | 0 N/A N/A 188342 C /tmp/nbody 109MiB | | 0 N/A N/A 188413 C /tmp/nbody 109MiB | +-----------------------------------------------------------------------------+ [10.100.10.10]: PS>Como puede ver, hay dos contenedores que se ejecutan con la simulación de n cuerpos en la GPU 0. También puede ver el uso de memoria correspondiente.
Una vez completada la simulación, la salida de Nvidia smi mostrará que no hay ningún proceso en ejecución en el dispositivo.
[10.100.10.10]: PS>Get-HcsGpuNvidiaSmi K8S-1HXQG13CL-1HXQG13: Fri Mar 5 13:54:48 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 00002C74:00:00.0 Off | 0 | | N/A 34C P8 9W / 70W | 0MiB / 15109MiB | 0% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+ [10.100.10.10]: PS>Después de que la simulación de n cuerpos se haya completado, consulte los registros para comprender los detalles de la implementación y el tiempo necesario para la finalización de la simulación.
Este es un ejemplo de salida del primer contenedor:
PS C:\WINDOWS\system32> kubectl -n iotedge --kubeconfig C:\GPU-sharing\kubeconfigs\configiotuser1 logs cuda-sample1-869989578c-ssng8 cuda-sample1 Run "nbody -benchmark [-numbodies=<numBodies>]" to measure performance. ==============// snipped //===================// snipped //============= > Windowed mode > Simulation data stored in video memory > Single precision floating point simulation > 1 Devices used for simulation GPU Device 0: "Turing" with compute capability 7.5 > Compute 7.5 CUDA device: [Tesla T4] 40960 bodies, total time for 10000 iterations: 170171.531 ms = 98.590 billion interactions per second = 1971.801 single-precision GFLOP/s at 20 flops per interaction no-op PS C:\WINDOWS\system32>Este es un ejemplo de salida del segundo contenedor:
PS C:\WINDOWS\system32> kubectl -n iotedge --kubeconfig C:\GPU-sharing\kubeconfigs\configiotuser1 logs cuda-sample2-6db6d98689-d74kb cuda-sample2 Run "nbody -benchmark [-numbodies=<numBodies>]" to measure performance. ==============// snipped //===================// snipped //============= > Windowed mode > Simulation data stored in video memory > Single precision floating point simulation > 1 Devices used for simulation GPU Device 0: "Turing" with compute capability 7.5 > Compute 7.5 CUDA device: [Tesla T4] 40960 bodies, total time for 10000 iterations: 170054.969 ms = 98.658 billion interactions per second = 1973.152 single-precision GFLOP/s at 20 flops per interaction no-op PS C:\WINDOWS\system32>Detenga la implementación del módulo. En el recurso de IoT Hub del dispositivo:
Vaya a Automatic Device Deployment (Implementación de dispositivos automática) > IoT Edge. Seleccione el dispositivo de IoT Edge correspondiente a su dispositivo.
Vaya a Establecer módulos y seleccione un módulo.
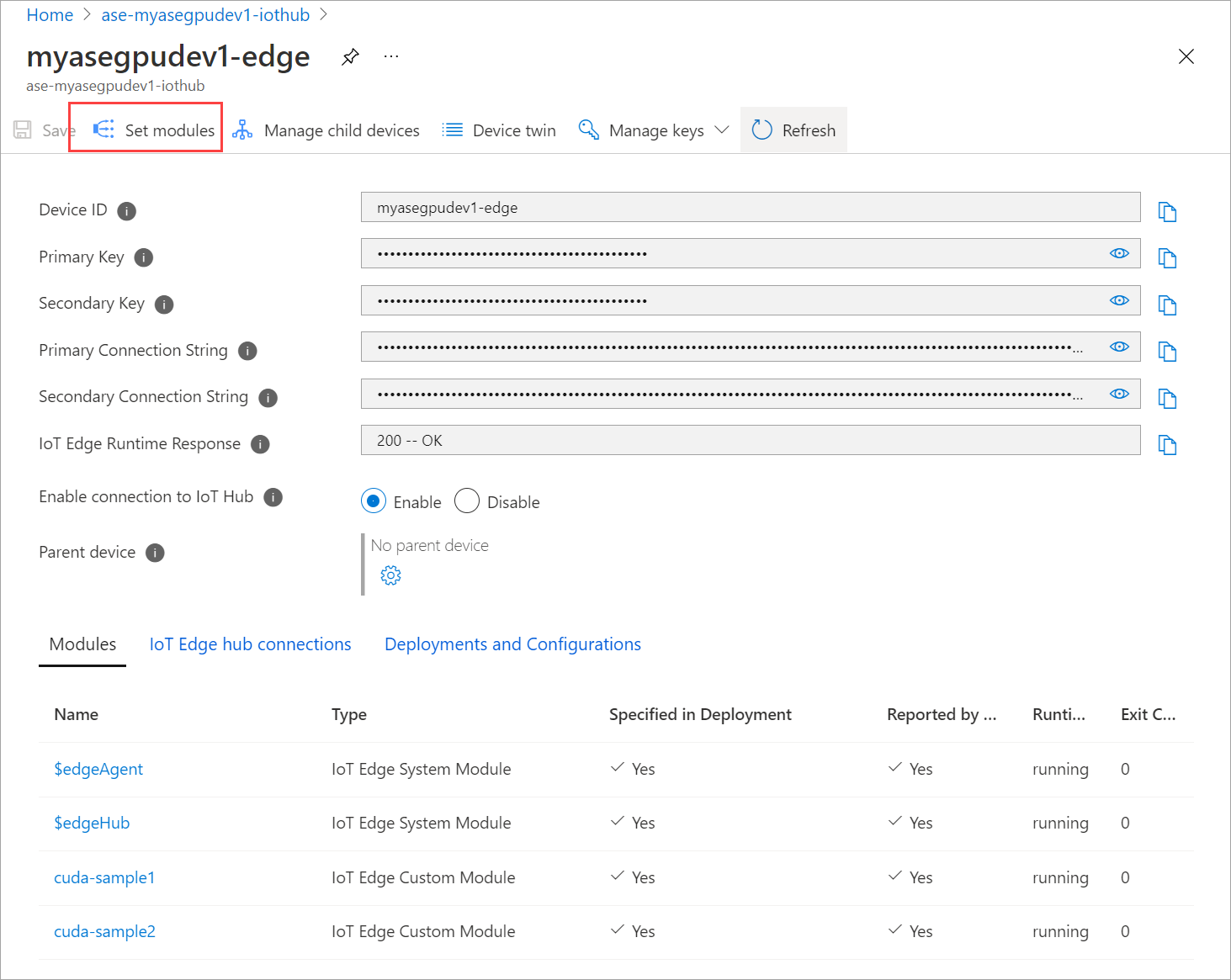
En la pestaña Módulos, seleccione un módulo.
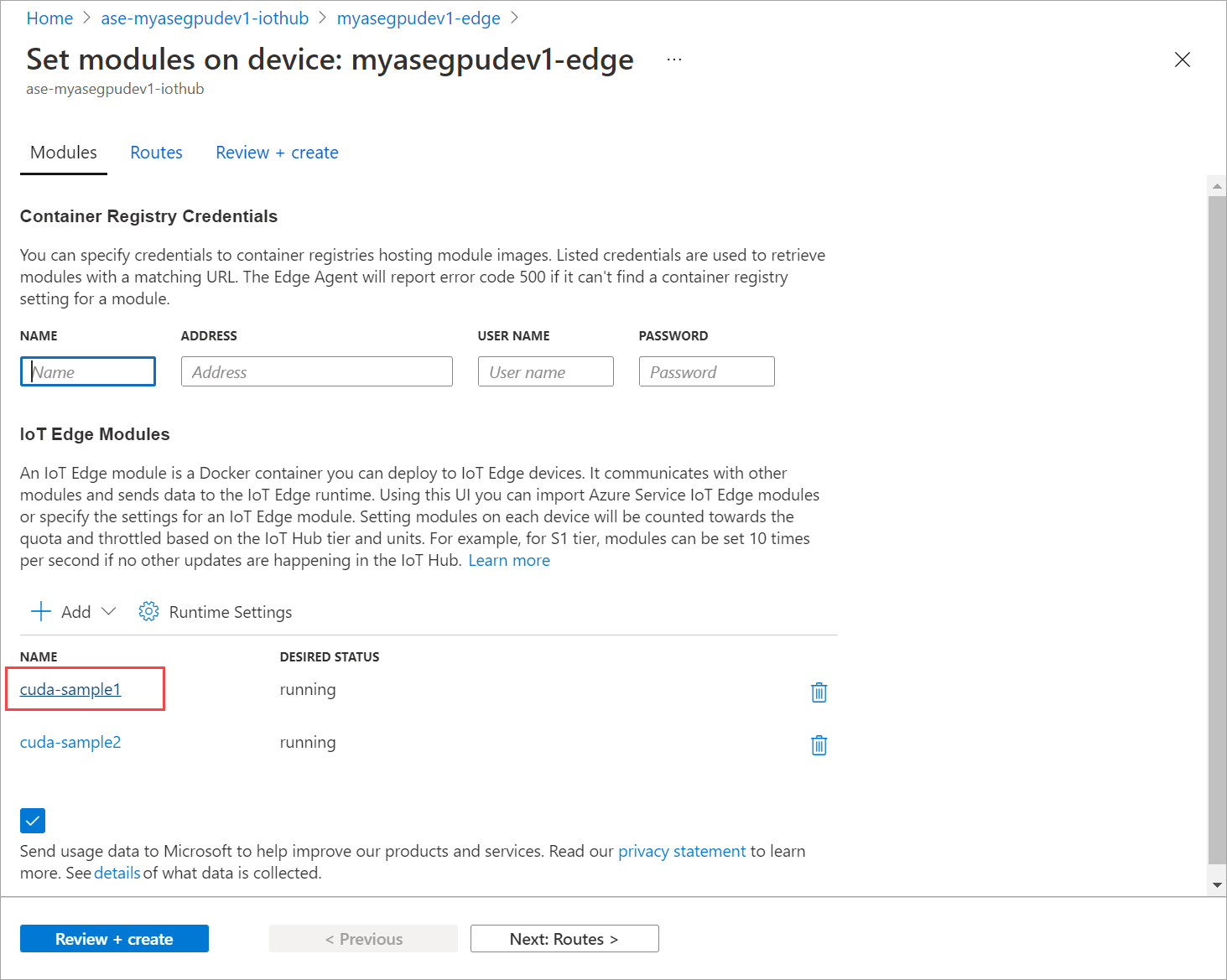
En la pestaña Configuración del módulo, establezca el Estado deseado en detenido. Seleccione Actualizar.
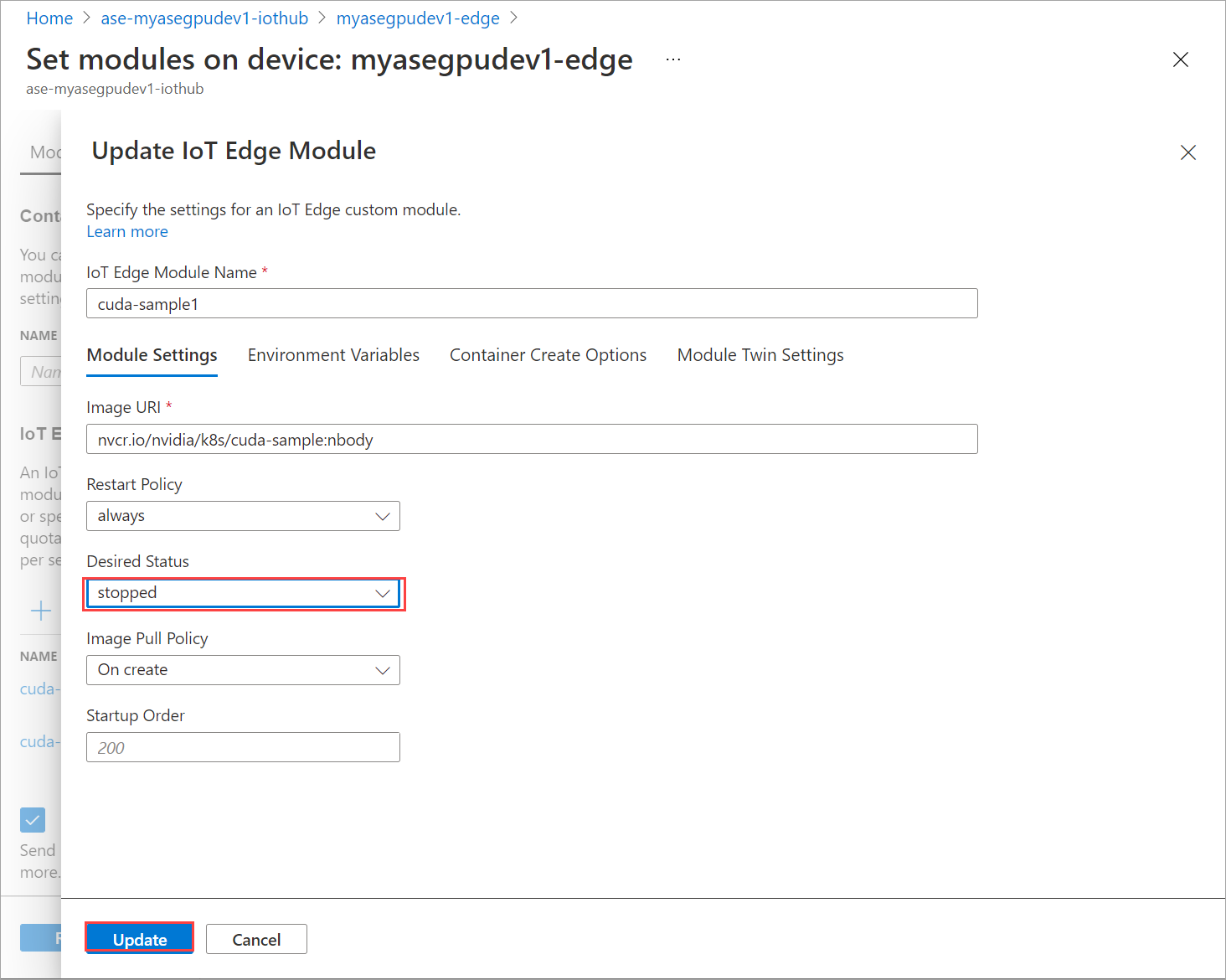
Repita los pasos para detener el segundo módulo implementado en el dispositivo. Seleccione Revisar y crear y, luego, Crear. Esto debe actualizar la implementación.
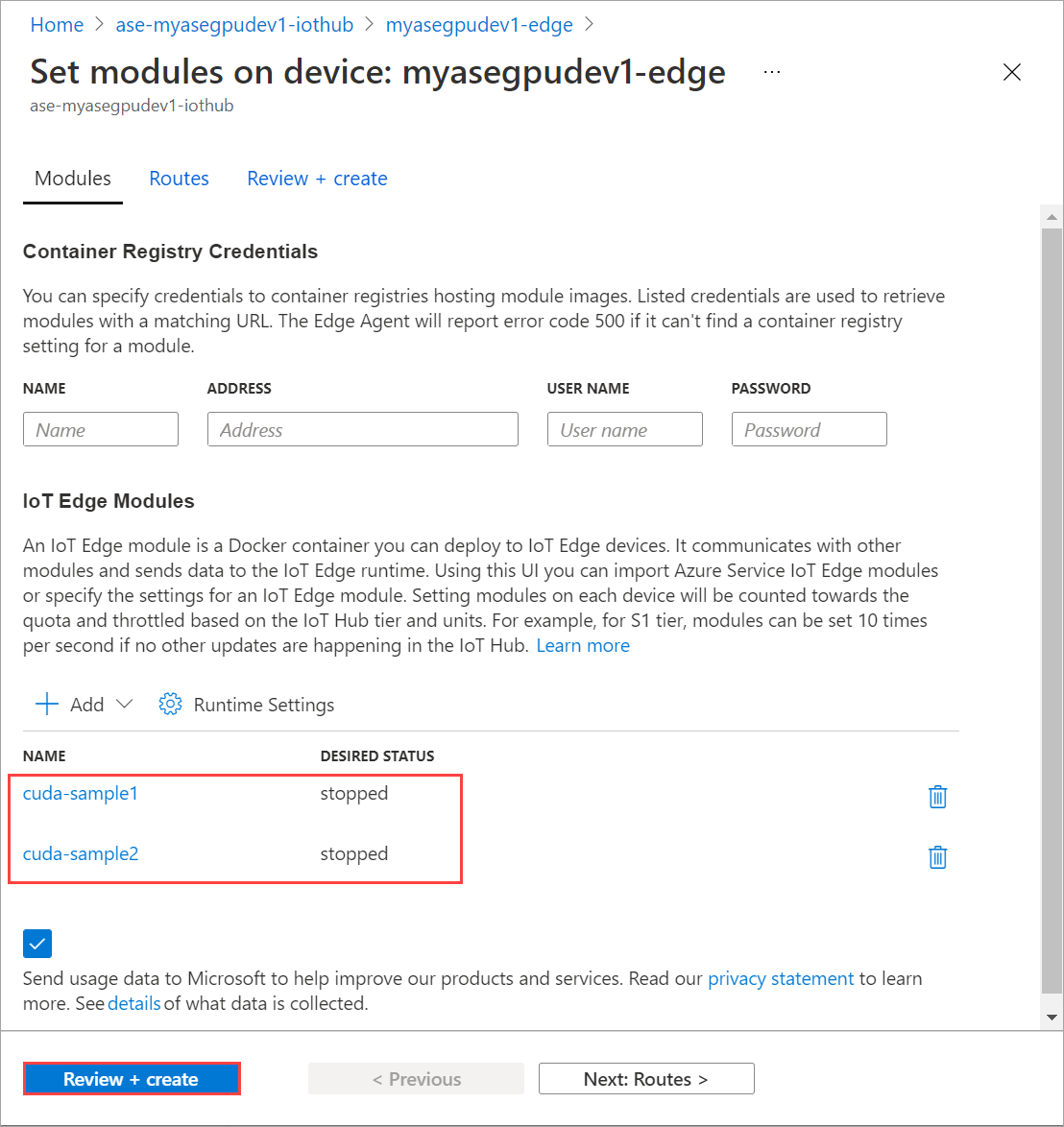
Actualice la página Establecer módulos varias veces, hasta que el Estado en tiempo de ejecución del módulo indique Detenido.
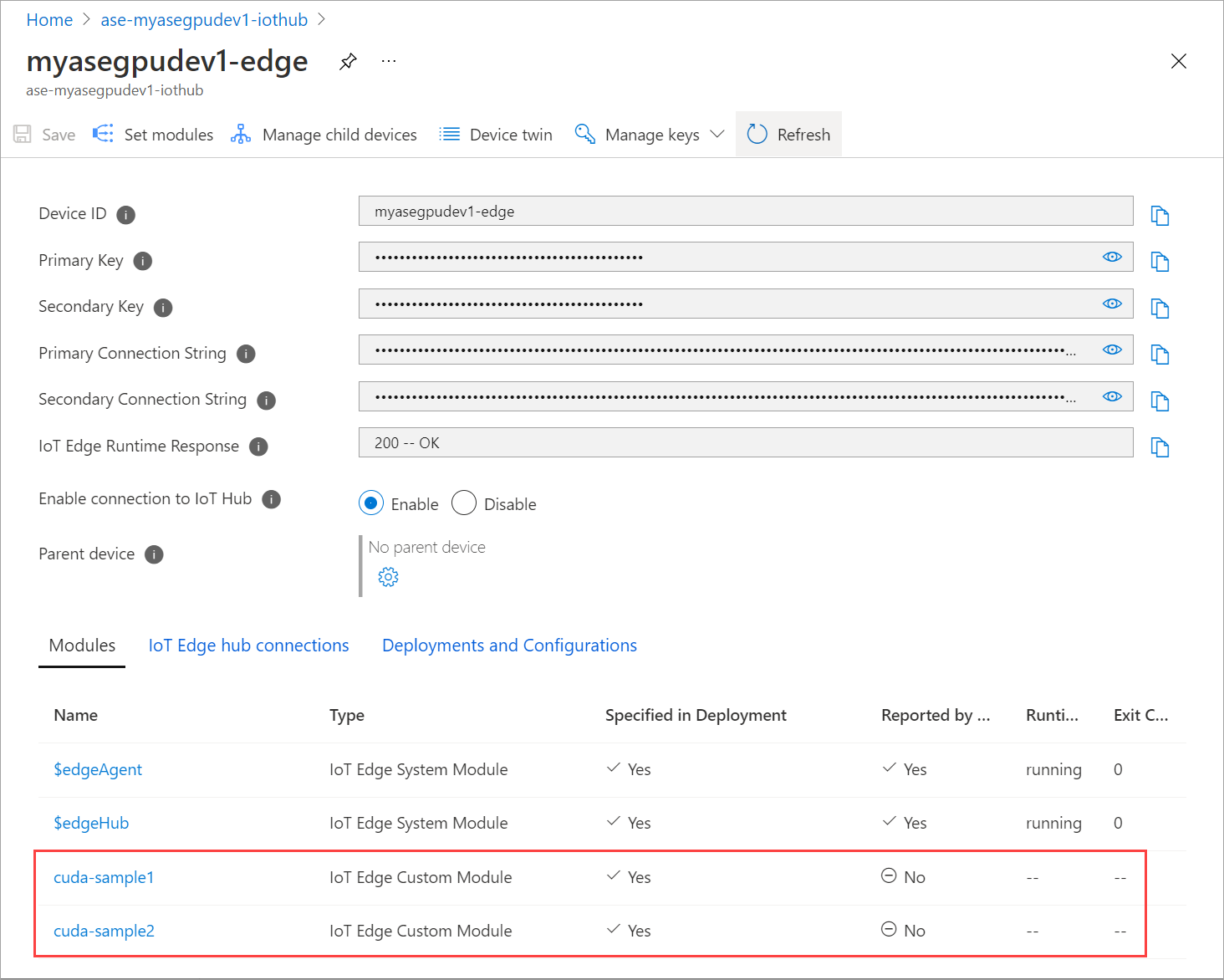
Implementación con uso compartido de contexto
Ahora puede implementar la simulación de n cuerpos en dos contenedores CUDA cuando se ejecuta MPS en el dispositivo. En primer lugar, habilitará MPS en el dispositivo.
Conéctese a la interfaz de PowerShell del dispositivo.
Para habilitar MPS en el dispositivo, ejecute el comando
Start-HcsGpuMPS.[10.100.10.10]: PS>Start-HcsGpuMPS K8S-1HXQG13CL-1HXQG13: Set compute mode to EXCLUSIVE_PROCESS for GPU 0000191E:00:00.0. All done. Created nvidia-mps.service [10.100.10.10]: PS>Obtenga la salida de Nvidia smi de la interfaz de PowerShell del dispositivo. Puede ver que el proceso
nvidia-cuda-mps-servero el servicio MPS se está ejecutando en el dispositivo.A continuación, se incluye una salida de ejemplo:
[10.100.10.10]: PS>Get-HcsGpuNvidiaSmi K8S-1HXQG13CL-1HXQG13: Thu Mar 4 12:37:39 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 00002C74:00:00.0 Off | 0 | | N/A 36C P8 9W / 70W | 28MiB / 15109MiB | 0% E. Process | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | 0 N/A N/A 122792 C nvidia-cuda-mps-server 25MiB | +-----------------------------------------------------------------------------+ [10.100.10.10]: PS>Get-HcsGpuNvidiaSmiImplemente los módulos que detuvo anteriormente. Establezca el Estado deseado en En ejecución a través de Establecer módulos.
Esta es la salida de ejemplo:
PS C:\WINDOWS\system32> kubectl get pods -n iotedge --kubeconfig C:\GPU-sharing\kubeconfigs\configiotuser1 NAME READY STATUS RESTARTS AGE cuda-sample1-869989578c-2zxh6 2/2 Running 0 44s cuda-sample2-6db6d98689-fn7mx 2/2 Running 0 44s edgeagent-79f988968b-7p2tv 2/2 Running 0 5d20h edgehub-d6c764847-l8v4m 2/2 Running 0 27m iotedged-55fdb7b5c6-l9zn8 1/1 Running 1 5d20h PS C:\WINDOWS\system32>Puede ver que los módulos están implementados y en ejecución en el dispositivo.
Cuando se implementan los módulos, la simulación de n cuerpos también inicia su ejecución en ambos contenedores. Esta es la salida de ejemplo cuando se ha completado la simulación en el primer contenedor:
PS C:\WINDOWS\system32> kubectl -n iotedge logs cuda-sample1-869989578c-2zxh6 cuda-sample1 Run "nbody -benchmark [-numbodies=<numBodies>]" to measure performance. ==============// snipped //===================// snipped //============= > Windowed mode > Simulation data stored in video memory > Single precision floating point simulation > 1 Devices used for simulation GPU Device 0: "Turing" with compute capability 7.5 > Compute 7.5 CUDA device: [Tesla T4] 40960 bodies, total time for 10000 iterations: 155256.062 ms = 108.062 billion interactions per second = 2161.232 single-precision GFLOP/s at 20 flops per interaction no-op PS C:\WINDOWS\system32>Esta es la salida de ejemplo cuando se ha completado la simulación en el segundo contenedor:
PS C:\WINDOWS\system32> kubectl -n iotedge --kubeconfig C:\GPU-sharing\kubeconfigs\configiotuser1 logs cuda-sample2-6db6d98689-fn7mx cuda-sample2 Run "nbody -benchmark [-numbodies=<numBodies>]" to measure performance. ==============// snipped //===================// snipped //============= > Windowed mode > Simulation data stored in video memory > Single precision floating point simulation > 1 Devices used for simulation GPU Device 0: "Turing" with compute capability 7.5 > Compute 7.5 CUDA device: [Tesla T4] 40960 bodies, total time for 10000 iterations: 155366.359 ms = 107.985 billion interactions per second = 2159.697 single-precision GFLOP/s at 20 flops per interaction no-op PS C:\WINDOWS\system32>Obtenga la salida de Nvidia smi de la interfaz de PowerShell del dispositivo cuando ambos contenedores ejecuten la simulación de n cuerpos. Esta es una salida de ejemplo. Hay tres procesos, el proceso
nvidia-cuda-mps-server(tipo C) corresponde al servicio MPS y los procesos/tmp/nbody(tipo M + C) corresponden a las cargas de trabajo de n cuerpos implementadas por los módulos.[10.100.10.10]: PS>Get-HcsGpuNvidiaSmi K8S-1HXQG13CL-1HXQG13: Thu Mar 4 12:59:44 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 00002C74:00:00.0 Off | 0 | | N/A 54C P0 69W / 70W | 242MiB / 15109MiB | 100% E. Process | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | 0 N/A N/A 56832 M+C /tmp/nbody 107MiB | | 0 N/A N/A 56900 M+C /tmp/nbody 107MiB | | 0 N/A N/A 122792 C nvidia-cuda-mps-server 25MiB | +-----------------------------------------------------------------------------+ [10.100.10.10]: PS>Get-HcsGpuNvidiaSmi