Transformación de datos en Azure Virtual Network mediante la actividad de Hive en Azure Data Factory con Azure Portal
SE APLICA A:  Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. Obtenga información sobre cómo iniciar una nueva evaluación gratuita.
En este tutorial, se usa Azure Portal para crear una canalización de Data Factory que transforma los datos mediante la actividad de Hive en un clúster de HDInsight que se encuentra en una instancia de Azure Virtual Network (VNet). En este tutorial, realizará los siguientes pasos:
- Creación de una factoría de datos.
- Creación de una instancia de Integration Runtime autohospedada
- Creación de servicios vinculados con Azure Storage y Azure HDInsight
- Creación de una canalización con la actividad de Hive
- Desencadenamiento de una ejecución de la canalización
- Supervisión de la ejecución de la canalización
- Comprobación del resultado
Si no tiene una suscripción a Azure, cree una cuenta gratuita antes de empezar.
Requisitos previos
Nota:
Se recomienda usar el módulo Azure Az de PowerShell para interactuar con Azure. Para comenzar, consulte Instalación de Azure PowerShell. Para más información sobre cómo migrar al módulo Az de PowerShell, consulte Migración de Azure PowerShell de AzureRM a Az.
Cuenta de Azure Storage. Cree un script de Hive y cárguelo en Azure Storage. La salida desde el script de Hive se almacena en esta cuenta de almacenamiento. En este ejemplo, el clúster de HDInsight usa esta cuenta de Azure Storage como el almacenamiento principal.
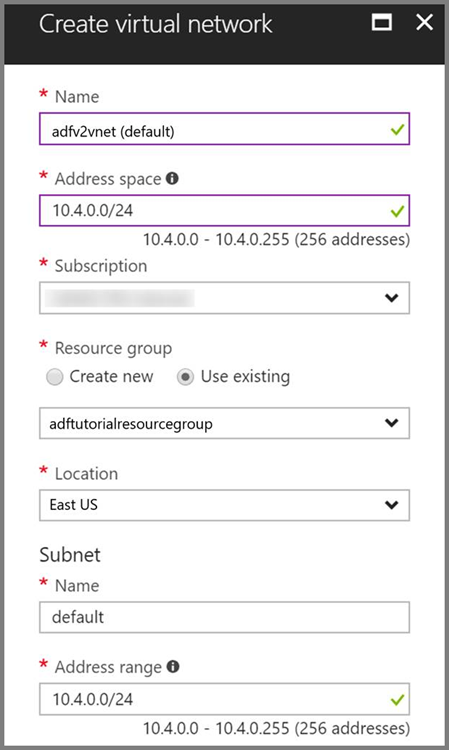
Azure Virtual Network. Si no tiene ninguna instancia de Azure Virtual Network, cree una siguiendo estas instrucciones. En este ejemplo, HDInsight se encuentra en una instancia de Azure Virtual Network. A continuación, puede ver una configuración de ejemplo de Azure Virtual Network.
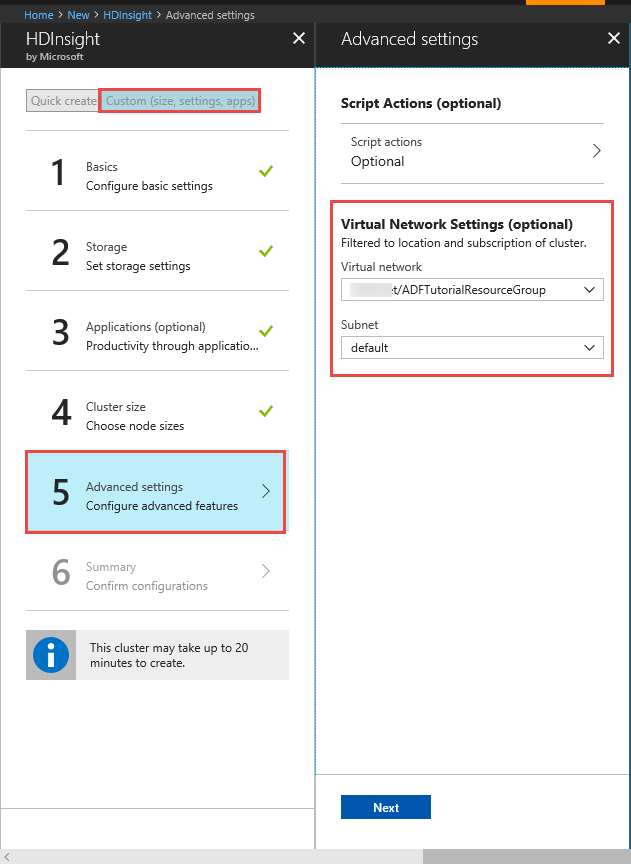
Clúster de HDInsight. Consulte el artículo siguiente para crear un clúster de HDInsight y unirlo a la red virtual que creó en el paso anterior: Extender Azure HDInsight mediante una instancia de Azure Virtual Network. A continuación, puede ver una configuración de ejemplo de HDInsight en una red virtual.
Azure PowerShell. Siga las instrucciones de Instalación y configuración de Azure PowerShell.
Una máquina virtual. Cree una máquina virtual de Azure y únala a la misma red virtual que contiene el clúster de HDInsight. Para obtener más información, consulte Creación de máquinas virtuales.
Carga del script de Hive en la cuenta de Blob Storage
Cree un archivo SQL de Hive denominado hivescript.hql con el siguiente contenido:
DROP TABLE IF EXISTS HiveSampleOut; CREATE EXTERNAL TABLE HiveSampleOut (clientid string, market string, devicemodel string, state string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE LOCATION '${hiveconf:Output}'; INSERT OVERWRITE TABLE HiveSampleOut Select clientid, market, devicemodel, state FROM hivesampletableEn Azure Blob Storage, cree un contenedor denominado adftutorial si no existe.
Cree una carpeta llamada hivescripts.
Cargue el archivo hivescript.hql en la subcarpeta hivescripts.
Crear una factoría de datos
Si aún no ha creado la factoría de datos, siga los pasos descritos en Inicio rápido: Creación de una factoría de datos mediante Azure Portal y Azure Data Factory Studio para crear una. Después de crearla, vaya a la factoría de datos en Azure Portal.

Seleccione Open (Abrir) en el icono Open Azure Data Factory Studio (Abrir Azure Data Factory Studio) para iniciar la aplicación de integración de datos en una pestaña independiente.
Creación de una instancia de Integration Runtime autohospedada
Como el clúster de Hadoop está dentro de una red virtual, debe instalar un entorno de ejecución de integración (IR) autohospedado en la misma red virtual. En esta sección, va a crear una nueva máquina virtual, se unirá a la misma red virtual e instalará un entorno de ejecución de integración autohospedado en ella. El entorno de ejecución de integración autohospedado permite al servicio Data Factory enviar solicitudes de proceso a un servicio de proceso como HDInsight en una red virtual. También permite mover datos hacia los almacenes de datos de una red virtual y, desde estos, a Azure. Puede usar un entorno de ejecución de integración autohospedado cuando el almacén de datos o de procesos está también en un entorno local.
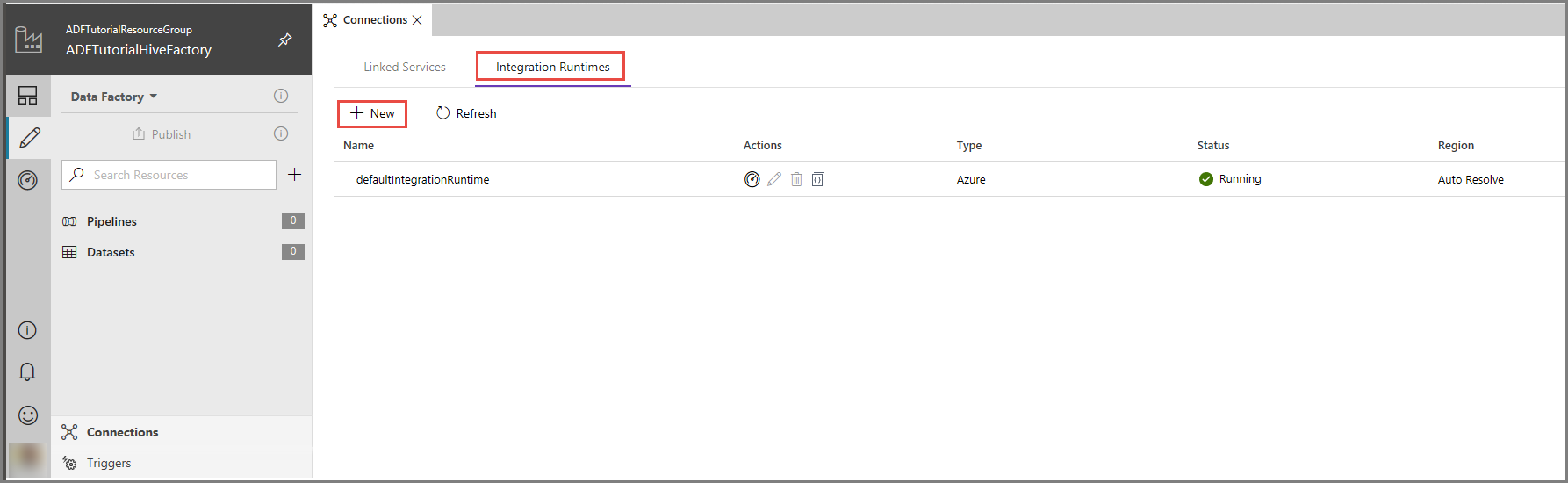
En la interfaz de usuario de Azure Data Factory, haga clic en Connections (Conexiones) en la parte inferior de la ventana, vaya a la pestaña Integration Runtimes y haga clic en el botón + New (+Nuevo) en la barra de herramientas.
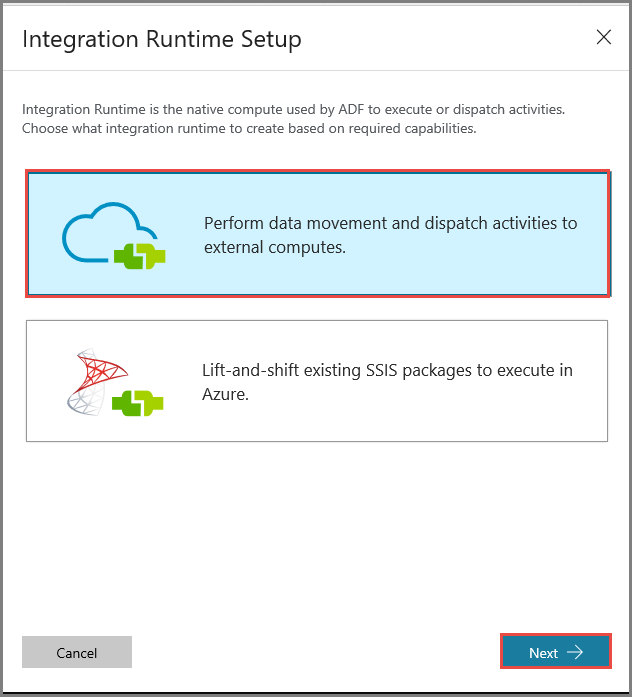
En la ventana Integration Runtime Setup (Configuración de Integration Runtime), seleccione la opción Perform data movement and dispatch activities to external computes (Realizar movimientos de datos y enviar actividades a procesos externos), y haga clic en Next (Siguiente).
Seleccione Private Network (Red privada) y haga clic en Next (Siguiente).
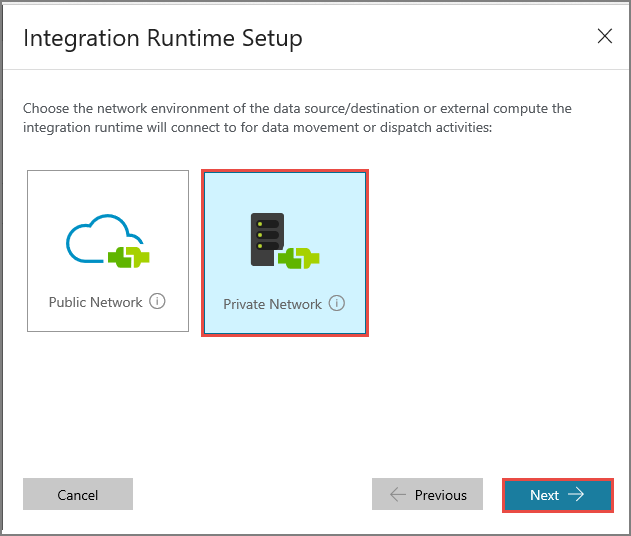
Escriba MySelfHostedIR como nombre y haga clic en Next (Siguiente).
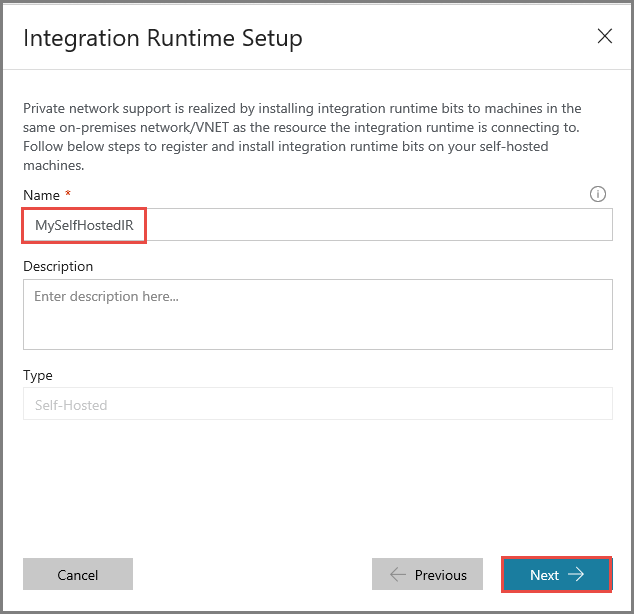
Copie la clave de autenticación del entorno de ejecución de integración haciendo clic en el botón de copia y guárdela. Mantenga la ventana abierta. Use esta clave para registrar el entorno de ejecución de integración instalado en una máquina virtual.
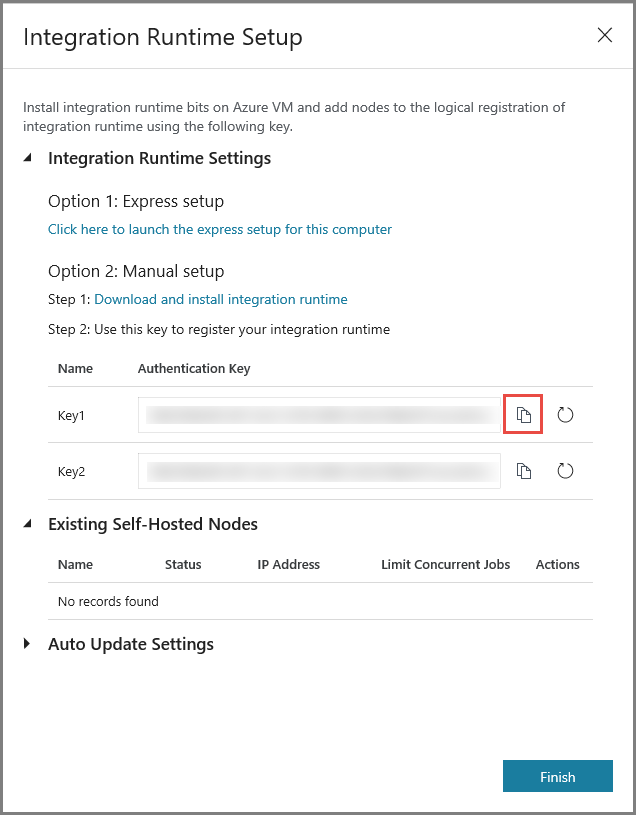
Instalación de un entorno de ejecución de integración en una máquina virtual
En la máquina virtual de Azure, descargue la instancia de Integration Runtime autohospedada. Use la clave de autenticación que obtuvo en el paso anterior para registrar manualmente el entorno de ejecución de integración autohospedado.
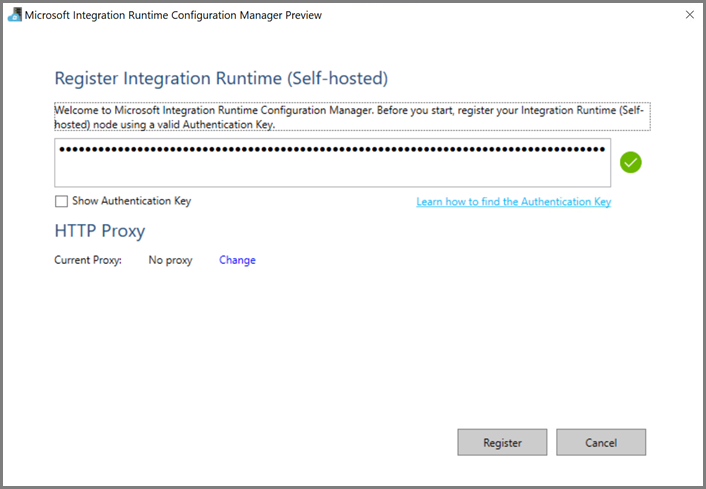
Verá el siguiente mensaje cuando se haya registrado correctamente el entorno de ejecución de integración autohospedado.
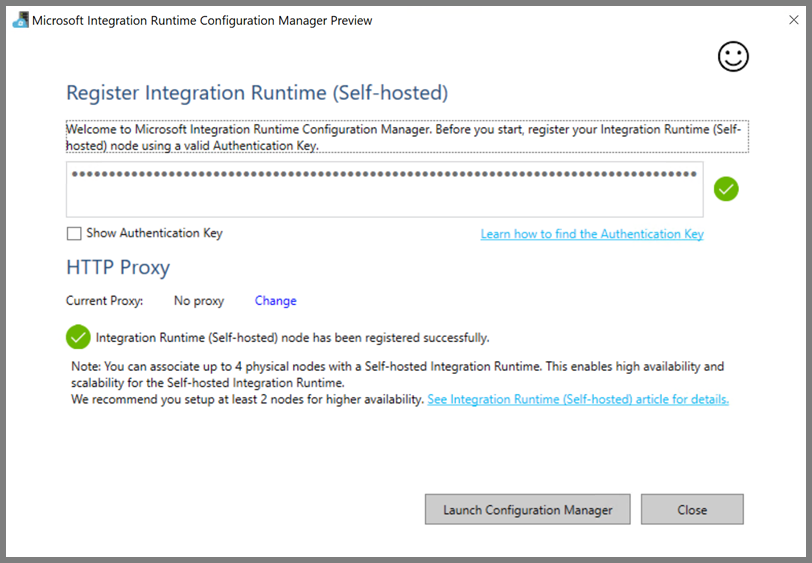
Haga clic en Iniciar Configuration Manager. Verá la siguiente página cuando el nodo esté conectado al servicio en la nube:
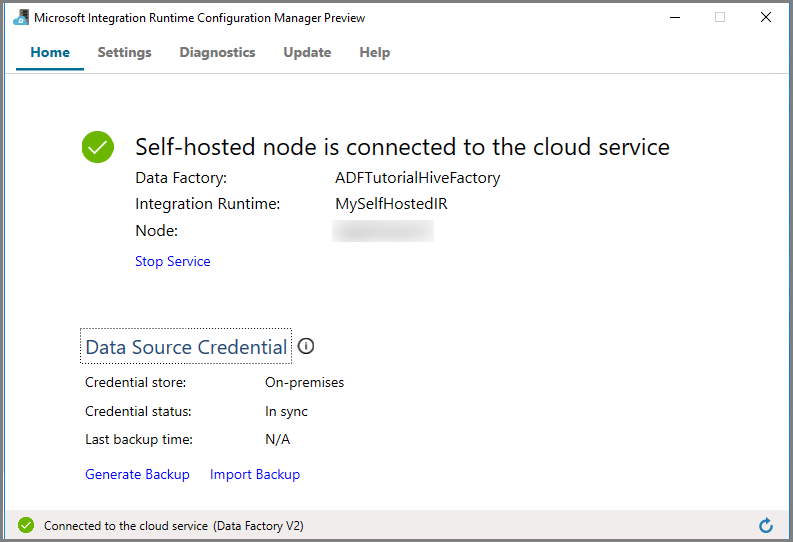
Entorno de ejecución de integración autohospedado en la interfaz de usuario de Azure Data Factory
En la interfaz de usuario de Azure Data Factory, debería ver el nombre de la máquina virtual autohospedada y su estado.
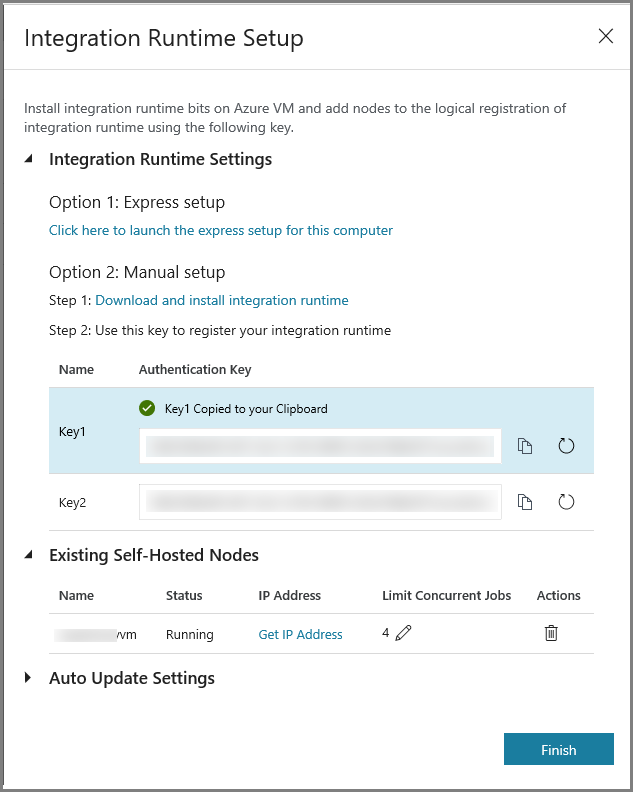
Haga clic en Finish (Finalizar) para cerrar la ventana Integration Runtime Setup (Configuración de Integration Runtime). Puede ver que el entorno de ejecución de integración autohospedado aparece en la lista de entornos.

Crear servicios vinculados
En esta sección, deberá crear e implementar dos servicios vinculados:
- Un servicio vinculado a Azure Storage que vincule una cuenta de Azure Storage con la factoría de datos. Este es el almacenamiento principal que usa el clúster de HDInsight. En este caso, puede usar esta cuenta de Azure Storage para almacenar el script de Hive y la salida del script.
- Un servicio vinculado a HDInsight. Azure Data Factory envía el script de Hive a este clúster de HDInsight para su ejecución.
Creación de un servicio vinculado de Azure Storage
Vaya a la pestaña Servicios vinculados y haga clic en Nuevo.
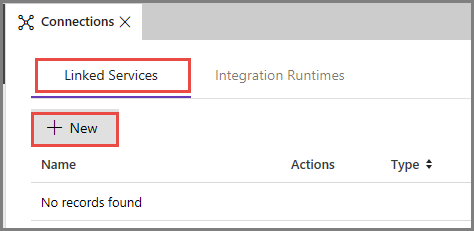
En la ventana New Linked Service (Nuevo servicio vinculado), seleccione Azure Blob Storage y haga clic en Continue (Continuar).
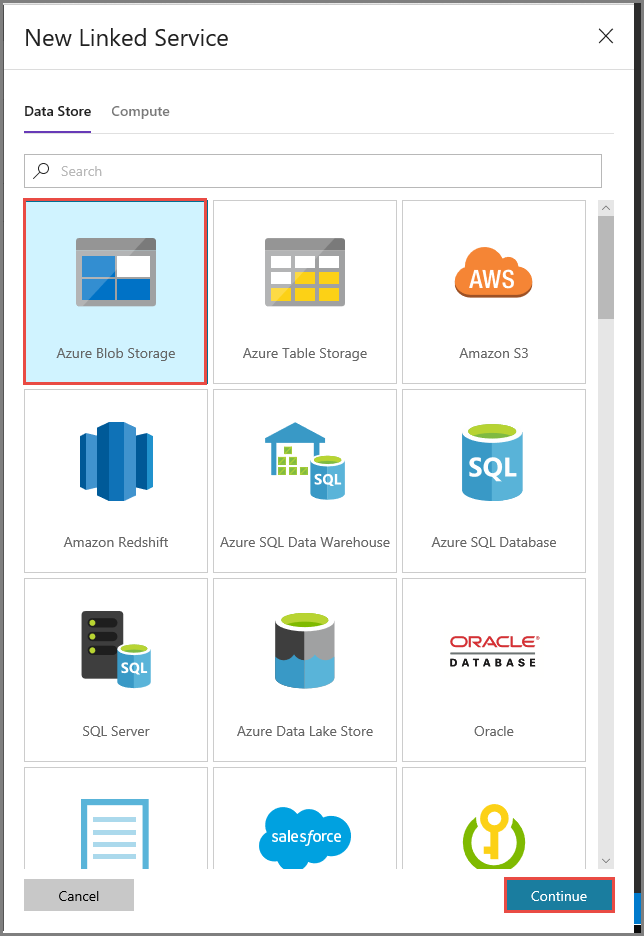
En la ventana New Linked Service (Nuevo servicio vinculado), realice los pasos siguientes:
Escriba AzureStorageLinkedService en Name (Nombre).
Seleccione MySelfHostedIR en la opción Connect via integration runtime (Conectar mediante IR).
Seleccione la cuenta de Azure Storage de Storage account name (Nombre de la cuenta de Storage).
Haga clic en Prueba de conexión para probar la conexión con la cuenta de almacenamiento.
Haga clic en Save(Guardar).
Creación del servicio vinculado de HDInsight
Haga clic en New (Nuevo) una vez más para crear otro servicio vinculado.
Vaya a la pestaña Compute, seleccione Azure HDInsight y haga clic en Continuar.
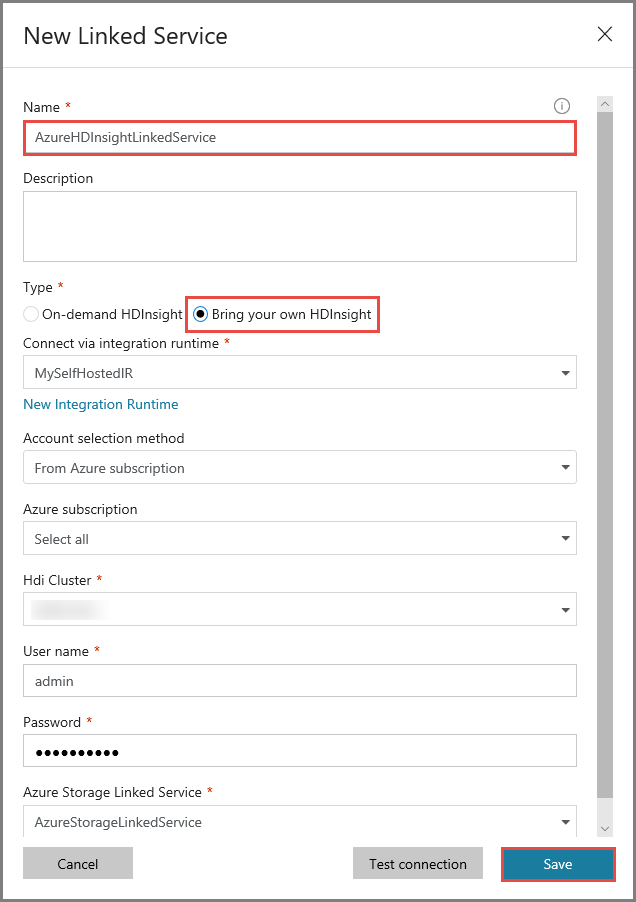
En la ventana New Linked Service (Nuevo servicio vinculado), realice los pasos siguientes:
Escriba AzureHDInsightLinkedService como nombre.
Seleccione Bring your own HDInsight (Traer su propio HDInsight).
Seleccione el clúster de HDInsight como clúster de HDI.
Escriba el nombre de usuario del clúster de HDInsight.
Escriba la contraseña del usuario.
En este artículo, se supone que tiene acceso al clúster a través de Internet. Por ejemplo, que se puede conectar al clúster en https://clustername.azurehdinsight.net. Esta dirección usa la puerta de enlace pública, que no está disponible si ha usado grupos de seguridad de red (NSG) o rutas definidas por el usuario (UDR) para restringir el acceso desde Internet. Para que Data Factory pueda enviar trabajos al clúster de HDInsight en Azure Virtual Network, debe configurar su instancia de Azure Virtual Network de modo que la URL pueda resolverse en la dirección IP privada de la puerta de enlace que usa HDInsight.
Desde Azure Portal, abra la instancia de Virtual Network en que se encuentra HDInsight. Abra la interfaz de red con nombres que empiecen por
nic-gateway-0. Anote su dirección IP privada. Por ejemplo: 10.6.0.15.Si su instancia de Azure Virtual Network tiene un servidor DNS, actualice el registro DNS para que la dirección URL del clúster de HDInsight
https://<clustername>.azurehdinsight.netpuede resolverse en10.6.0.15. Si no tiene ningún servidor DNS en su instancia de Azure Virtual Network, puede evitar este problema de forma temporal. Para ello, edite el archivo de hosts (C:\Windows\System32\drivers\etc) de todas las máquinas virtuales que se registran como nodos del entorno de ejecución de integración autohospedado mediante la adición de una entrada similar a la siguiente:10.6.0.15 myHDIClusterName.azurehdinsight.net
Crear una canalización
En este paso, se crea una canalización con una actividad de Hive. La actividad ejecuta el script de Hive para devolver datos de una tabla de ejemplo y guardarlos en una ruta de acceso que haya definido.
Tenga en cuenta los siguientes puntos:
- scriptPath apunta a la ruta de acceso al script de Hive de la cuenta de Azure Storage que usó para MyStorageLinkedService. La ruta de acceso distingue mayúsculas de minúsculas.
- Output es un argumento que se usa en el script de Hive. Use el formato de
wasbs://<Container>@<StorageAccount>.blob.core.windows.net/outputfolder/para que apunte a una carpeta existente de su instancia de Azure Storage. La ruta de acceso distingue mayúsculas de minúsculas.
En la interfaz de usuario de Data Factory, haga clic en + (signo más) en el panel izquierdo y haga clic en Pipeline (Canalización).
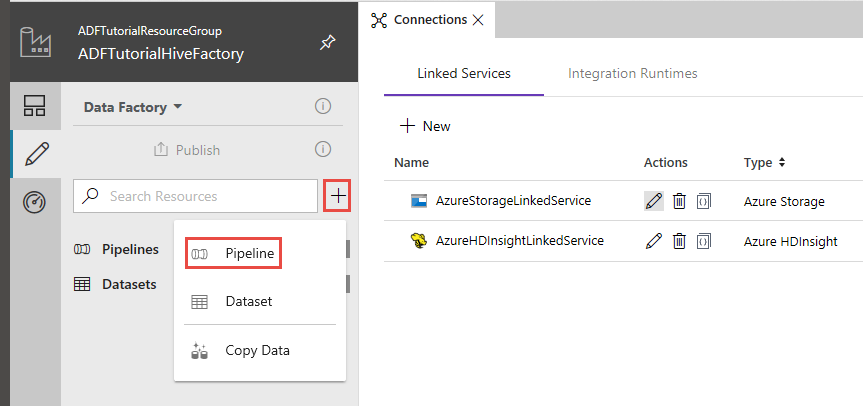
En el cuadro de herramientas Activities (Actividades), expanda HDInsight, arrastre la actividad Hive y colóquela en la superficie del diseñador de canalizaciones.
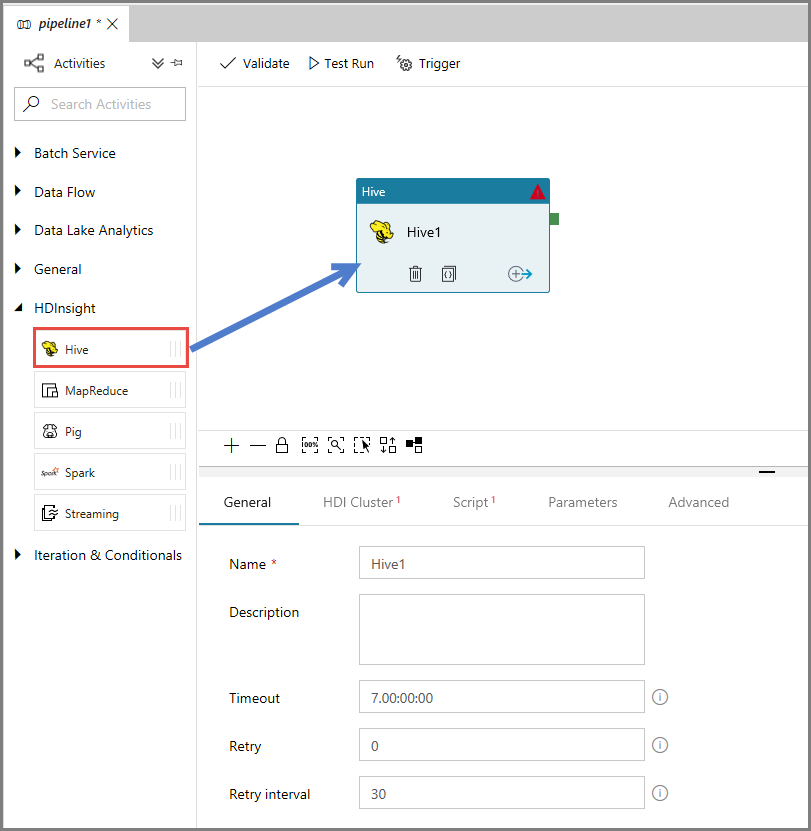
En la ventana de propiedades, vaya a la pestaña HDI Cluster (Clúster de HDI) y seleccione AzureHDInsightLinkedService como servicio vinculado a HDInsight.

Cambie a la pestaña Scripts y realice los pasos siguientes:
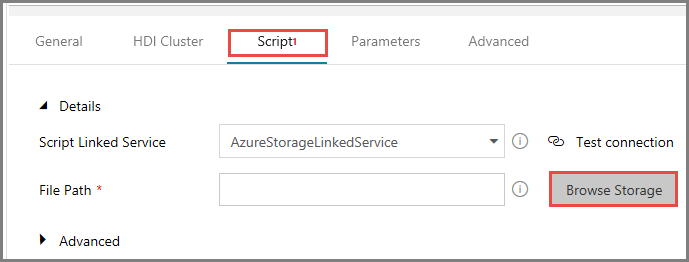
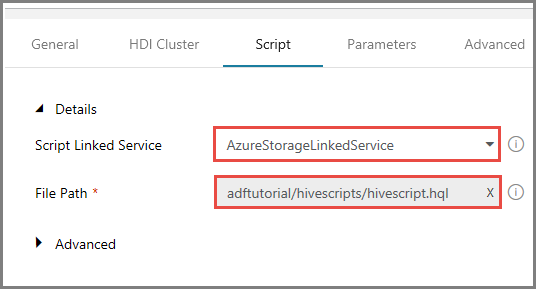
Seleccione AzureStorageLinkedService como servicio vinculado de script.
En File Path (Ruta de archivo), haga clic en Browse Storage (Examinar almacenamiento).
En la ventana Choose a file or folder (Elegir un archivo o carpeta), vaya a la carpeta hivescripts del contenedor adftutorial, seleccione hivescript.hql y haga clic en Finish (Finalizar).
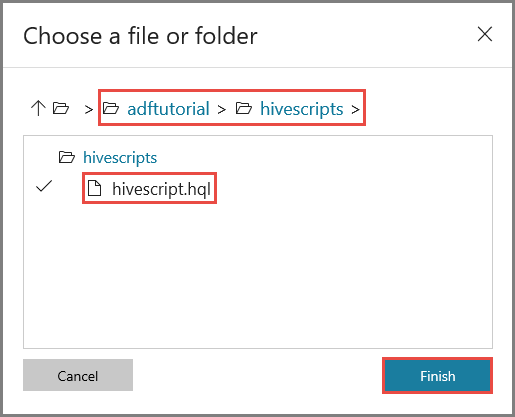
Confirme que ve adftutorial/hivescripts/hivescript.hql en File Path (Ruta de archivo).
En la pestaña Script, expanda la sección Advanced (Avanzadas).
Haga clic en Auto-fill from script (Rellenado automático a partir de script) en Parameters (Parámetros).
Escriba el valor del parámetro Output en el siguiente formato:
wasbs://<Blob Container>@<StorageAccount>.blob.core.windows.net/outputfolder/. Por ejemplo:wasbs://adftutorial@mystorageaccount.blob.core.windows.net/outputfolder/.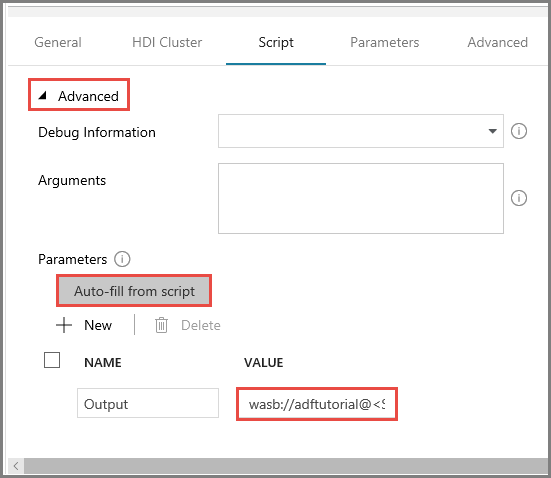
Para publicar artefactos en Data Factory, haga clic en Publish (Publicar).
Desencadenamiento de una ejecución de la canalización
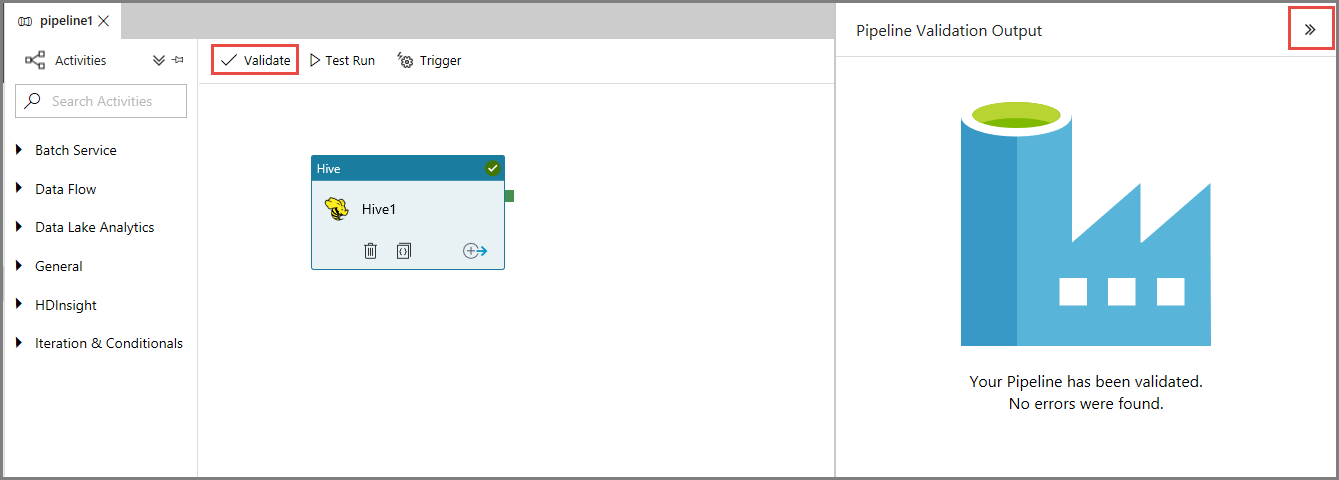
En primer lugar, valide la canalización haciendo clic en el botón Validate (Comprobar) en la barra de herramientas. Cierre la ventana Pipeline Validation Output (Salida de comprobación de canalización) haciendo clic en flecha derecha (>>).
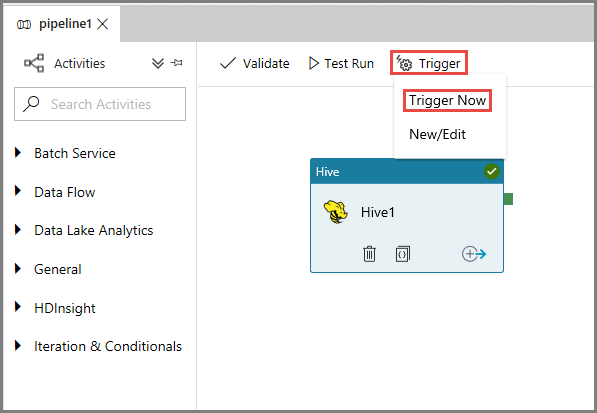
Para desencadenar una ejecución de la canalización, haga clic en Trigger (Desencadenar) en la barra de herramientas y en Trigger Now (Desencadenar ahora).
Supervisión de la ejecución de la canalización
Cambie a la pestaña Monitor (Supervisar) de la izquierda. Puede ver una ejecución de canalización en la lista Pipeline Runs (Ejecuciones de canalización).
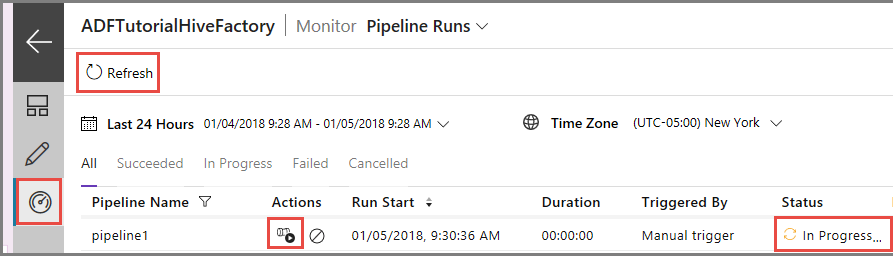
Haga clic en Refresh (Actualizar) para actualizar la lista.
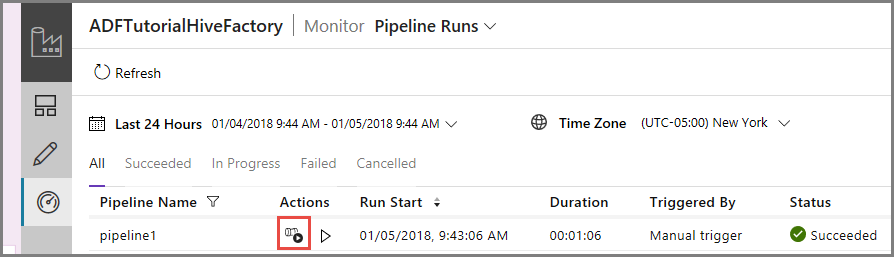
Para ver las ejecuciones de actividad asociadas a la de la canalización, primero haga clic en el vínculo View Activity Runs (Ver ejecuciones de actividad) de la columna Action (Acción). Otros vínculos de acción se usan para detener y volver a ejecutar la canalización.
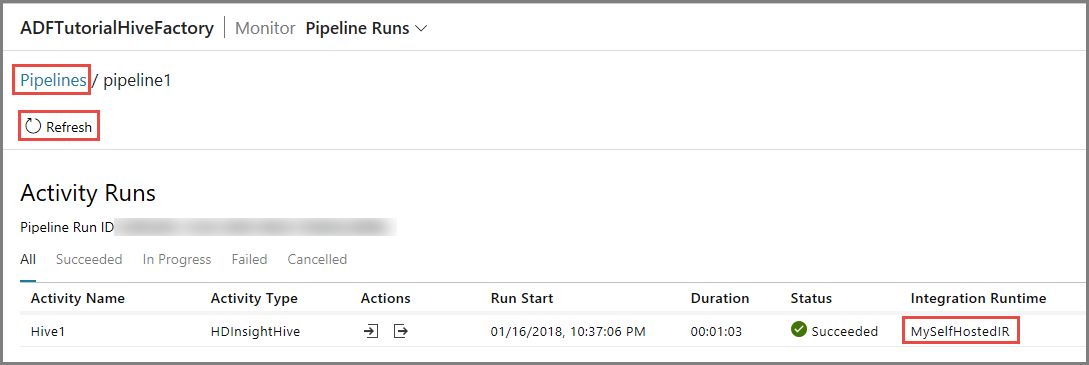
Verá solo una actividad de ejecución ya que solo hay una actividad en la canalización que sea del tipo HDInsightHive. Para volver a la vista anterior, haga clic en el vínculo Pipelines (Canalizaciones) de la parte superior.
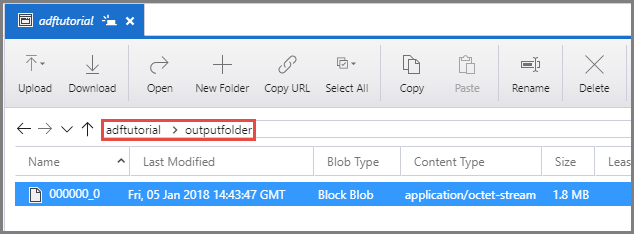
Confirme que ve un archivo de salida en la carpeta outputfolder del contenedor adftutorial.
Contenido relacionado
En este tutorial, realizó los pasos siguientes:
- Creación de una factoría de datos.
- Creación de una instancia de Integration Runtime autohospedada
- Creación de servicios vinculados con Azure Storage y Azure HDInsight
- Creación de una canalización con la actividad de Hive
- Desencadenamiento de una ejecución de la canalización
- Supervisión de la ejecución de la canalización
- Comprobación del resultado
Pase al tutorial siguiente para obtener información acerca de la transformación de datos mediante el uso de un clúster de Spark en Azure: