Copia de datos y envío de notificaciones por correo electrónico en caso de operación realizada correctamente y error
SE APLICA A:  Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. Obtenga información sobre cómo iniciar una nueva evaluación gratuita.
En este tutorial, creará una canalización de Data Factory que muestra algunas de las características del flujo de control. Esta canalización realiza una copia simple de un contenedor en Azure Blob Storage a otro contenedor de la misma cuenta de almacenamiento. Si la actividad de copia se realiza correctamente, la canalización envía los detalles de la operación de copia correcta (por ejemplo, la cantidad de datos escritos) en un correo electrónico de operación correcta. Si se produce un error en la actividad de copia, la canalización envía los detalles del error de copia (por ejemplo, el mensaje de error) en un correo electrónico de operación incorrecta. A lo largo del tutorial, verá cómo pasar parámetros.
Información general de alto nivel sobre el escenario: 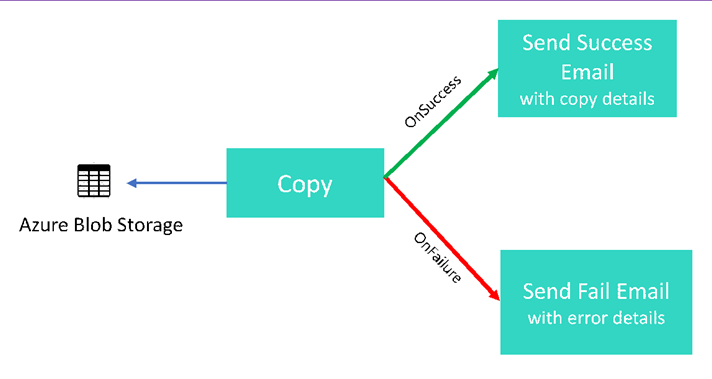
En este tutorial, realizará los siguientes pasos:
- Creación de una factoría de datos.
- Creación de un servicio vinculado de Azure Storage
- Creación de un conjunto de datos del blob de Azure
- Creación de una canalización que contenga una actividad de copia y una actividad web
- Envío de los resultados de las actividades en actividades subsiguientes
- Uso de las variables del sistema y del paso de parámetros
- Inicio de la ejecución de una canalización
- Supervisión de las ejecuciones de canalización y actividad
En este tutorial se usa Azure Portal. Puede usar otros mecanismos para interactuar con Azure Data Factory. Consulte "Inicios rápidos" en la tabla de contenido.
Requisitos previos
- Suscripción de Azure. Si no tiene una suscripción a Azure, cree una cuenta gratuita antes de empezar.
- Cuenta de Azure Storage. Blob Storage se puede usar como almacén de datos de origen. Si no tiene una cuenta de almacenamiento de Azure, consulte el artículo Crear una cuenta de almacenamiento para ver los pasos para su creación.
- Azure SQL Database. La base de datos se puede usar como almacén de datos receptor. Si no tiene ninguna base de datos en Azure SQL Database, consulte el artículo Creación de una base de datos en Azure SQL Database para ver los pasos y crear una.
Creación de la tabla de blobs
Inicie el Bloc de notas. Copie el texto siguiente y guárdelo como archivo input.txt en el disco.
John,Doe Jane,DoeUse herramientas como el Explorador de Azure Storage para realizar los pasos siguientes:
- Cree el contenedor adfv2branch.
- Cree la carpeta de entrada en el contenedor adfv2branch.
- Cargue el archivo input.txt en el contenedor.
Creación de puntos de conexión de flujo de trabajo del correo electrónico
Para desencadenar el envío de un correo electrónico de la canalización, defina el flujo de trabajo con Azure Logic Apps. Para más información sobre cómo crear un flujo de trabajo de aplicación lógica, consulte Creación de un flujo de trabajo de aplicación lógica de consumo de ejemplo.
Flujo de trabajo del correo electrónico de operación correcta
Creación de un flujo de trabajo de aplicación lógica de consumo denominado CopySuccessEmail. Agregue el desencadenador de solicitud denominado Cuando se recibe una solicitud HTTP y agregue la acción de Office 365 Outlook denominada Enviar un correo electrónico. Si se le pide, inicie sesión en la cuenta de Office 365 Outlook.
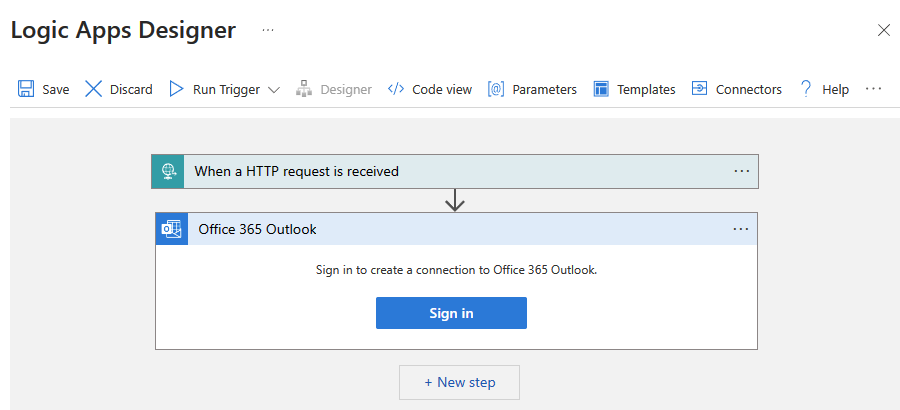
En el desencadenador de solicitud, rellene el cuadro Esquema JSON del cuerpo de la solicitud con el siguiente JSON:
{
"properties": {
"dataFactoryName": {
"type": "string"
},
"message": {
"type": "string"
},
"pipelineName": {
"type": "string"
},
"receiver": {
"type": "string"
}
},
"type": "object"
}
El desencadenador de solicitud del diseñador de flujo de trabajo debe tener el aspecto de la imagen siguiente:
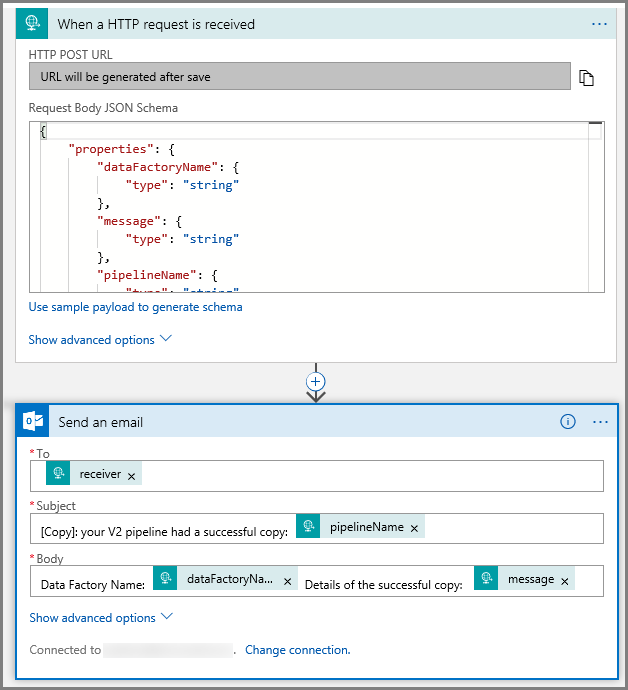
Para la acción Enviar un correo electrónico, personalice el formato del correo electrónico. Para ello, use las propiedades que se pasan en el esquema JSON del cuerpo de solicitud. Este es un ejemplo:
Guarde el flujo de trabajo. Tome nota de la URL de solicitud POST HTTP para el flujo de trabajo del correo electrónico de operación correcta:
//Success Request Url
https://prodxxx.eastus.logic.azure.com:443/workflows/000000/triggers/manual/paths/invoke?api-version=2016-10-01&sp=%2Ftriggers%2Fmanual%2Frun&sv=1.0&sig=000000
Flujo de trabajo del correo electrónico de operación incorrecta
Siga los mismos pasos para crear otro flujo de trabajo de aplicación lógica denominado CopyFailEmail. En el desencadenador de solicitud, el valor del esquema JSON del cuerpo de la solicitud es el mismo. Cambie el formato del correo electrónico, por ejemplo, la parte Subject, para adaptarlo para que sea un correo electrónico de operación incorrecta. Este es un ejemplo:
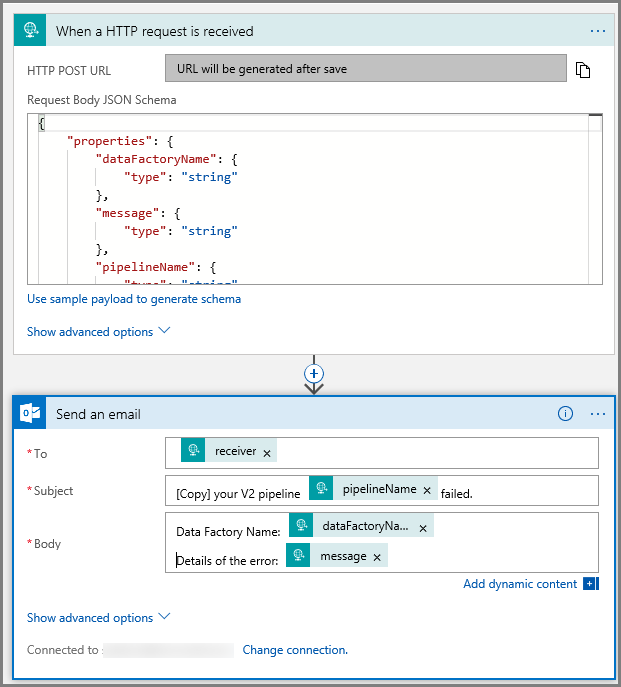
Guarde el flujo de trabajo. Tome nota de la URL de solicitud POST HTTP para el flujo de trabajo del correo electrónico de operación incorrecta:
//Fail Request Url
https://prodxxx.eastus.logic.azure.com:443/workflows/000000/triggers/manual/paths/invoke?api-version=2016-10-01&sp=%2Ftriggers%2Fmanual%2Frun&sv=1.0&sig=000000
Ahora debería tener dos URL de flujo de trabajo:
//Success Request Url
https://prodxxx.eastus.logic.azure.com:443/workflows/000000/triggers/manual/paths/invoke?api-version=2016-10-01&sp=%2Ftriggers%2Fmanual%2Frun&sv=1.0&sig=000000
//Fail Request Url
https://prodxxx.eastus.logic.azure.com:443/workflows/000000/triggers/manual/paths/invoke?api-version=2016-10-01&sp=%2Ftriggers%2Fmanual%2Frun&sv=1.0&sig=000000
Crear una factoría de datos
Inicie el explorador web Microsoft Edge o Google Chrome. Actualmente, la interfaz de usuario de Data Factory solo se admite en los exploradores web Microsoft Edge y Google Chrome.
Expanda el menú de la parte superior izquierda y seleccione Crear un recurso. Seleccione >Integración>Data Factory:

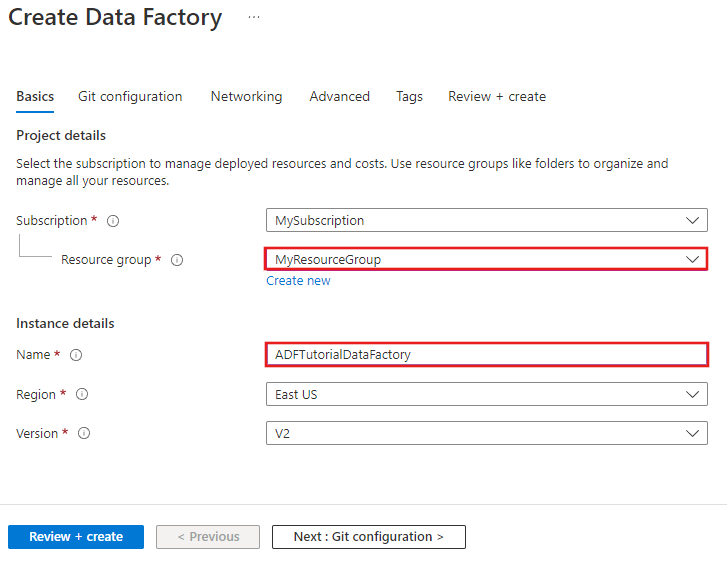
En la página New data factory (Nueva factoría de datos), escriba ADFTutorialDataFactory en Name (Nombre).
El nombre de la instancia de Azure Data Factory debe ser único de forma global. Si recibe el siguiente error, cambie el nombre de la factoría de datos (por ejemplo, yournameADFTutorialDataFactory) e intente crearlo de nuevo. Consulte el artículo Azure Data Factory: reglas de nomenclatura para conocer las reglas de nomenclatura de los artefactos de Data Factory.
El nombre "ADFTutorialDataFactory" de factoría de datos no está disponible.
Seleccione la suscripción de Azure donde desea crear la factoría de datos.
Para el grupo de recursos, realice uno de los siguientes pasos:
Seleccione en primer lugar Usar existentey después un grupo de recursos de la lista desplegable.
Seleccione Crear nuevoy escriba el nombre de un grupo de recursos.
Para obtener más información sobre los grupos de recursos, consulte Uso de grupos de recursos para administrar los recursos de Azure.
Seleccione V2 para la versión.
Seleccione la ubicación de Data Factory. En la lista desplegable solo se muestran las ubicaciones que se admiten. Los almacenes de datos (Azure Storage, Azure SQL Database, etc.) y los procesos (HDInsight, etc.) que usa la factoría de datos pueden encontrarse en otras regiones.
Seleccione Anclar al panel.
Haga clic en Crear.
Una vez completada la creación, verá la página Data Factory tal como se muestra en la imagen.
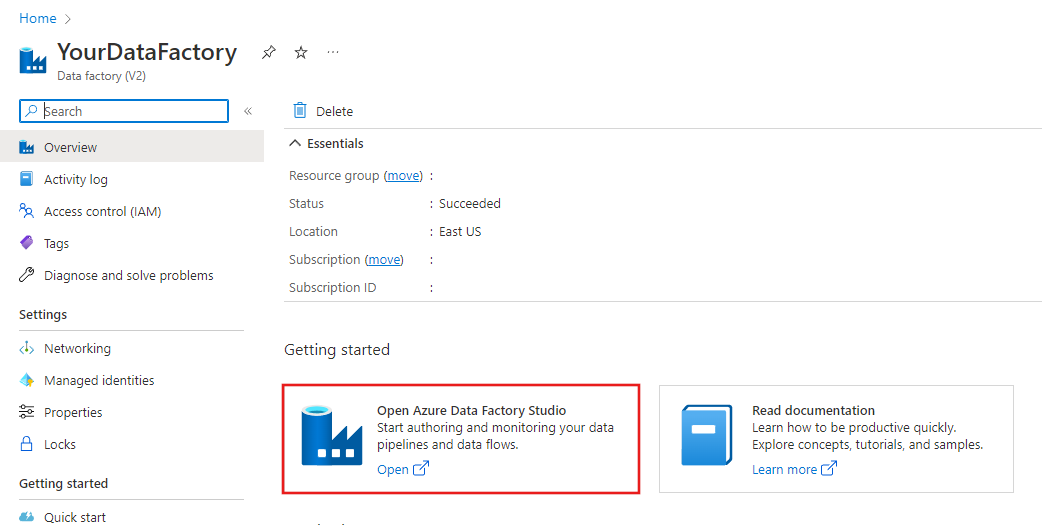
Haga clic en el icono Abrir Azure Data Factory Studio para iniciar la interfaz de usuario de Azure Data Factory en una pestaña aparte.
Crear una canalización
En este paso se crea una canalización con una actividad de copia y dos actividades web. Use las siguientes características para crear la canalización:
- Los parámetros de acceso de los conjuntos de datos de la canalización.
- La actividad web para invocar flujos de trabajo de aplicaciones lógicas para enviar mensajes de correo electrónico de operación correcta/incorrecta.
- Conexión de una actividad con otra (con operaciones correctas e incorrectas)
- Uso de la salida de una actividad como la entrada para la actividad subsiguiente
En la página principal de la interfaz de usuario de Data Factory, haga clic en el icono Orchestrate (Organizar).
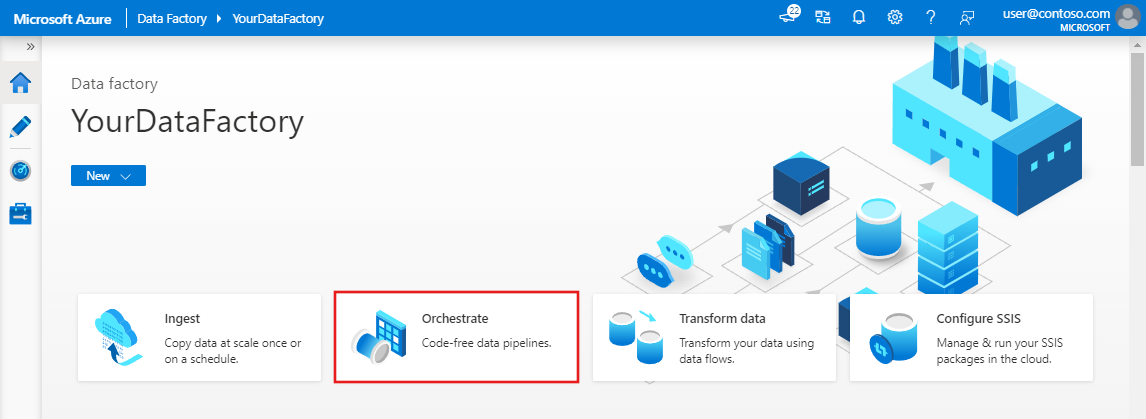
En la ventana de propiedades de la canalización, cambie a la pestaña Parameters (Parámetros) y a use el botón New (Nuevo) para agregar los siguientes tres parámetros de tipo String: sourceBlobContainer, sinkBlobContainer y receiver.
- sourceBlobContainer: parámetro de la canalización que consume el conjunto de datos del blob de origen.
- sinkBlobContainer: parámetro de la canalización que consume el conjunto de datos del blob receptor.
- receiver: parámetro que usan las dos actividades web de la canalización que envían correos electrónicos de operación correcta o incorrecta al receptor cuya dirección de correo electrónico especifica este parámetro.
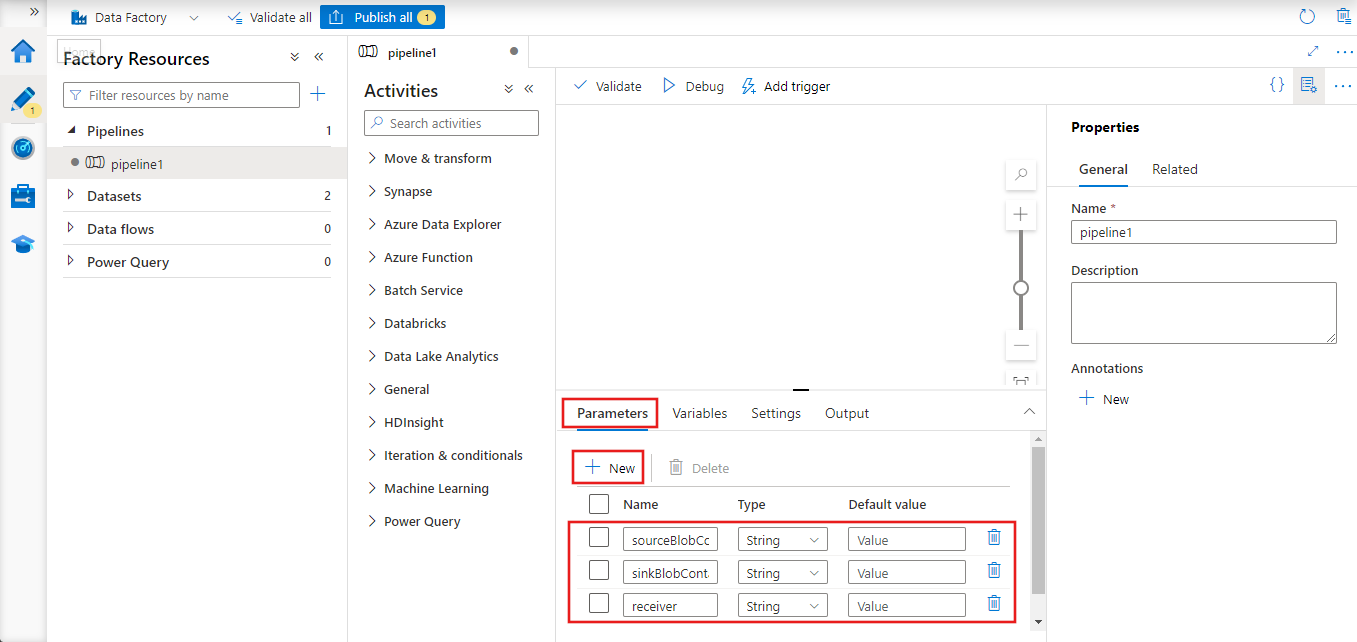
En el cuadro de herramientas Actividades, expanda Flujo de datos, arrastre la actividad de copia y colóquela en la superficie del diseñador de canalizaciones.
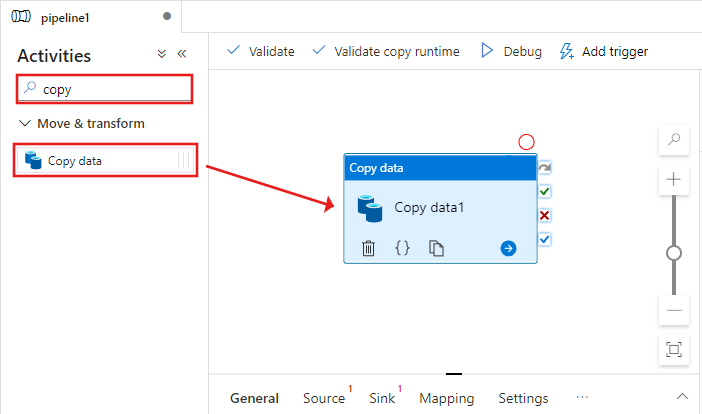
Seleccione la actividad de copia que ha arrastrado a la superficie del diseñador de canalizaciones. En la ventana Properties (Propiedades) de la actividad Copy (Copia) de la parte inferior, cambie a la pestaña Source (origen) y haga clic en + New (+ Nuevo). En este paso se crea un conjunto de datos de origen para la actividad de copia.
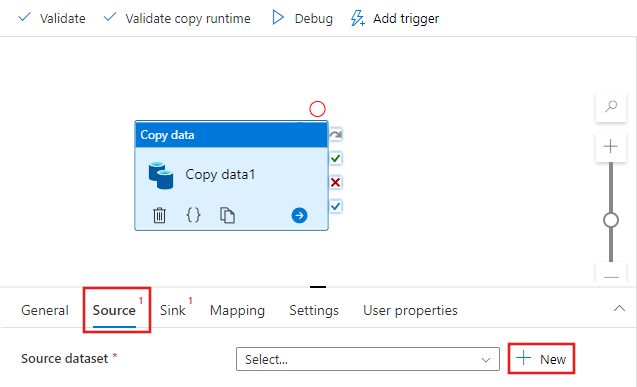
En la ventana Nuevo conjunto de datos, seleccione la pestaña Azure en la parte superior, elija Azure Blob Storage y seleccione Continuar.
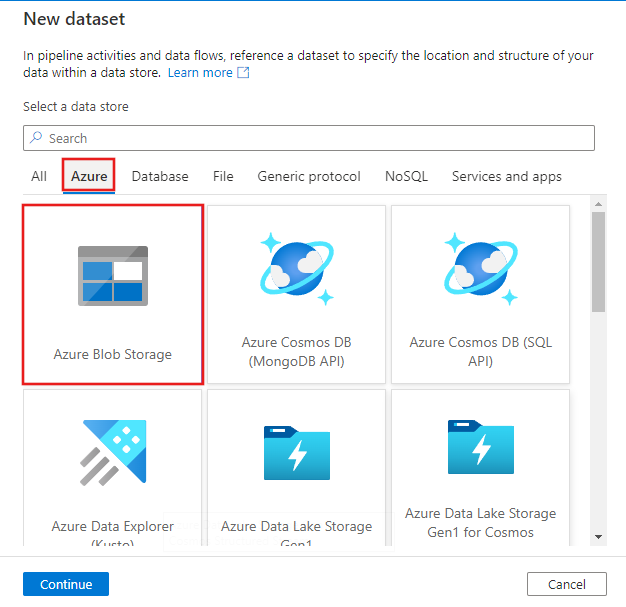
En la ventana Seleccionar formato, elija DelimitedText y seleccione Continuar.

Aparece una nueva pestaña denominada Definir propiedades. Cámbiele el nombre al conjunto de datos a SourceBlobDataset. Seleccione la lista desplegable Servicio vinculado y elija +Nuevo para crear un nuevo servicio vinculado al conjunto de datos de origen.
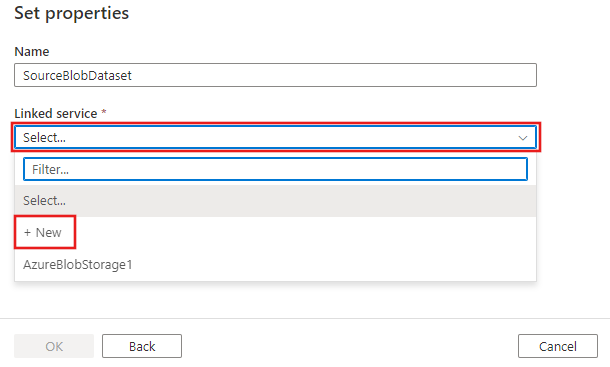
Se abre la ventana Nuevo servicio vinculado, donde puede rellenar las propiedades necesarias para el servicio vinculado.
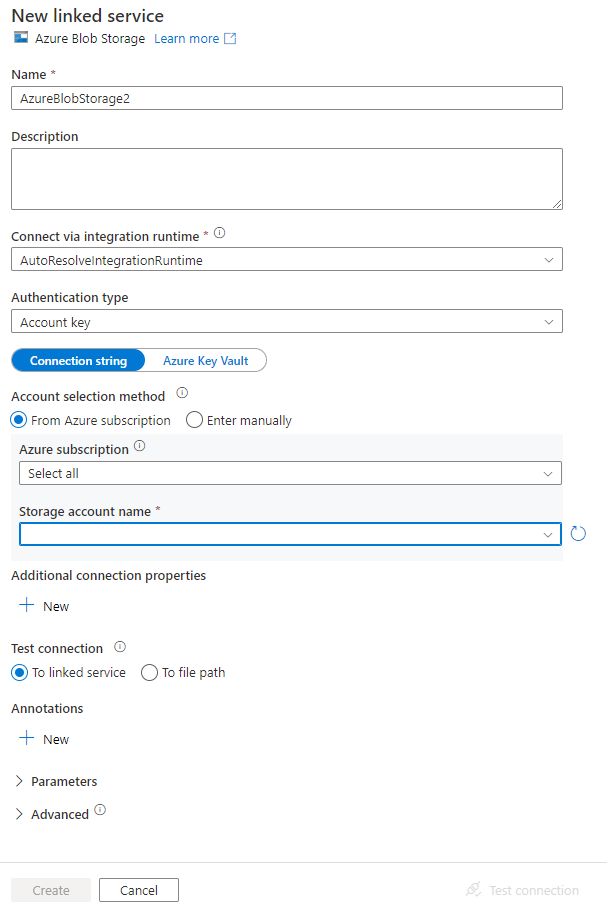
En la ventana New Linked Service (Nuevo servicio vinculado), realice los pasos siguientes:
- Escriba AzureStorageLinkedService en Name (Nombre).
- Seleccione la cuenta de Azure Storage en Storage account name (Nombre de la cuenta de Storage).
- Haga clic en Crear.
En la ventana Definir propiedades que aparece a continuación, seleccione Abrir este conjunto de datos para especificar un valor con parámetros para el nombre de archivo.
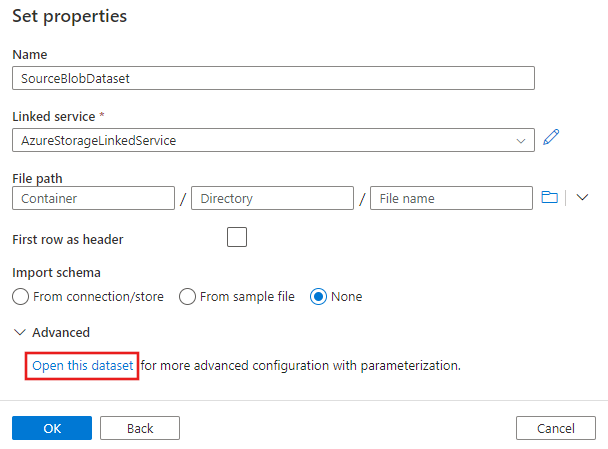
Escriba
@pipeline().parameters.sourceBlobContainerpara la carpeta yemp.txt, para el nombre de archivo.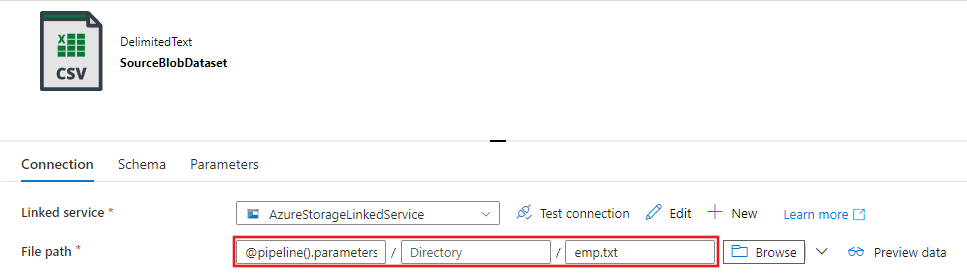
Vuelva a la pestaña de la canalización (o haga clic en la canalización en la vista de árbol de la izquierda) y seleccione la actividad de copia en el diseñador. Confirme que está seleccionado el nuevo conjunto de datos como Conjunto de datos de origen.
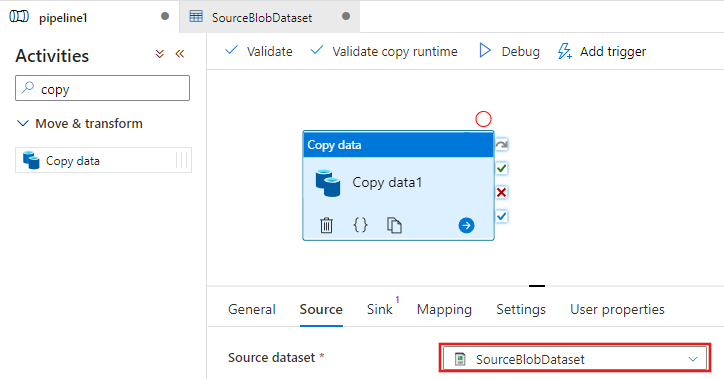
En la ventana de propiedades, cambie a la pestaña Sink (Receptor) y haga clic en + New (+ Nuevo) en Sink Dataset (Conjunto de datos receptor). En este paso se crea un conjunto de datos receptor para la actividad de copia, de manera similar a la creación del conjunto de datos de origen.
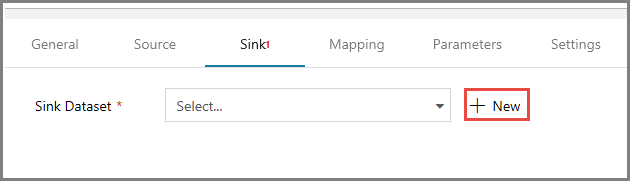
En la ventana Nuevo conjunto de datos, seleccione Azure Blob Storage y haga clic en Continuar. A continuación, vuelva a seleccionar DelimitedText en la ventana Seleccionar formato y haga clic otra vez en Continuar.
En la página Definir propiedades del conjunto de datos, escriba SinkBlobDataset en Nombre y seleccione AzureStorageLinkedService en Servicio vinculado.
Expanda la sección Avanzadas de la página de propiedades y seleccione Abrir este conjunto de datos.
En la pestaña Conexión del conjunto de datos, edite la Ruta de acceso del archivo. Escriba
@pipeline().parameters.sinkBlobContainerpara la carpeta y@concat(pipeline().RunId, '.txt')para el nombre de archivo. La expresión usa el identificador de la ejecución de canalización actual del nombre de archivo. Para la lista de las expresiones y variables del sistema admitidas, consulte las variables del sistema y el lenguaje de expresiones.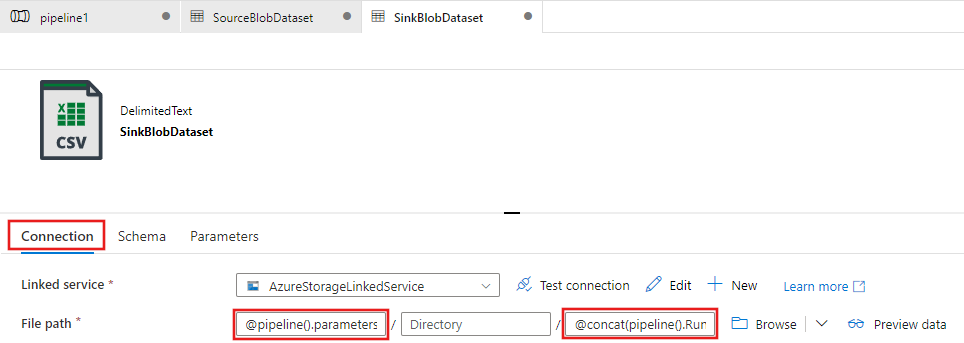
Vuelva a la pestaña de la canalización en la parte superior. Busque Web en el cuadro de búsqueda, arrastre una actividad Web y colóquela en la superficie del diseñador de canalizaciones. Establezca el nombre de la actividad en SendSuccessEmailActivity. La actividad web permite una llamada a cualquier punto de conexión de REST. Para más información sobre la actividad, consulte el artículo Web Activity (Actividad web). Esta canalización usa una actividad web para llamar al flujo de trabajo de correo electrónico de Logic Apps.
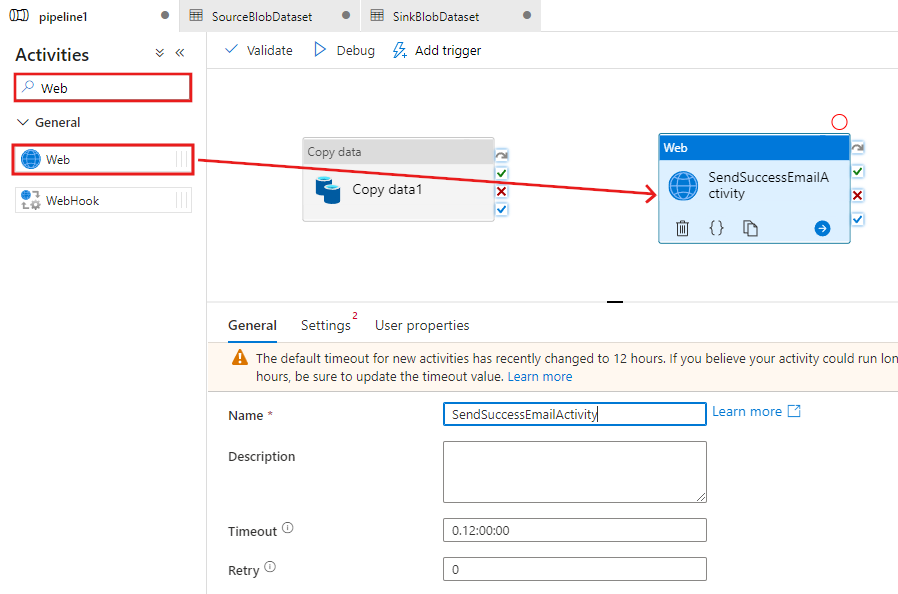
Cambie a la pestaña Settings (Configuración) en la pestaña General (General) y realice los pasos siguientes:
Como dirección URL, especifique la dirección URL del flujo de trabajo de aplicaciones lógicas que envía el correo electrónico de operación correcta.
Seleccione POST como Method (Método).
Haga clic en el vínculo + Add header (+ Agregar encabezado) de la sección Headers (Encabezados).
Agregue un encabezado Content-Type y establézcalo en application/json.
Especifique el siguiente JSON para Body (Cuerpo).
{ "message": "@{activity('Copy1').output.dataWritten}", "dataFactoryName": "@{pipeline().DataFactory}", "pipelineName": "@{pipeline().Pipeline}", "receiver": "@pipeline().parameters.receiver" }El cuerpo del mensaje contiene las siguientes propiedades:
Message, que pasa el valor
@{activity('Copy1').output.dataWritten. Tiene acceso a una propiedad de la actividad de copia anterior y pasa el valor de dataWritten. En caso de error, pasa la salida de error en lugar de@{activity('CopyBlobtoBlob').error.message.Data Factory Name, que pasa el valor
@{pipeline().DataFactory}. Se trata de una variable del sistema, lo que le permite obtener acceso al nombre de la factoría de datos correspondiente. Para obtener una lista de las variables del sistema, vea el artículo System Variables (Variables del sistema).Pipeline Name, que pasa el valor
@{pipeline().Pipeline}. También es una variable del sistema, lo que le permite obtener acceso al nombre de canalización correspondiente.Receiver, que pasa el valor "@pipeline().parameters.receiver"). y accede a los parámetros de la canalización.
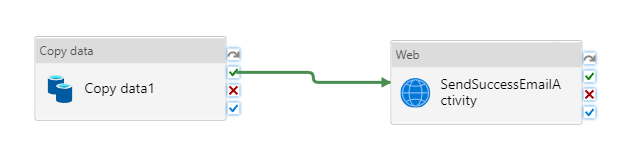
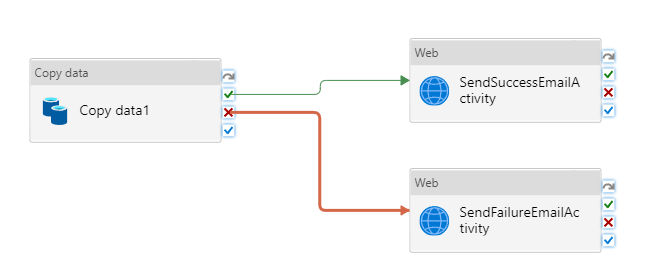
Conecte la actividad de copia a la actividad Web. Para ello, arrastre el botón con la marca de verificación verde que está junto a la actividad de copia y colóquelo en la actividad Web.
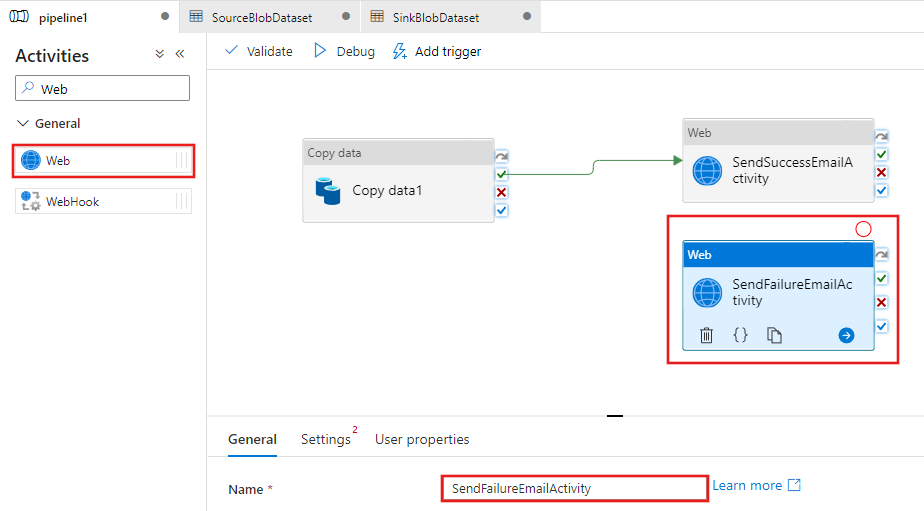
Arrastre la actividad Web del cuadro de herramientas de actividades y colóquela en la superficie del diseñador de canalizaciones; después, establezca el nombre en SendFailureEmailActivity.
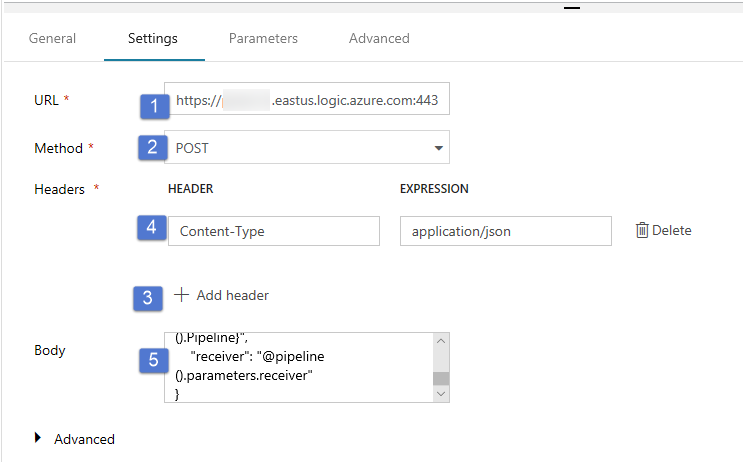
Cambie a la pestaña Settings (Configuración) y realice los pasos siguientes:
Como dirección URL, especifique la dirección URL del flujo de trabajo de aplicaciones lógicas que envía el correo electrónico de operación incorrecta.
Seleccione POST como Method (Método).
Haga clic en el vínculo + Add header (+ Agregar encabezado) de la sección Headers (Encabezados).
Agregue un encabezado Content-Type y establézcalo en application/json.
Especifique el siguiente JSON para Body (Cuerpo).
{ "message": "@{activity('Copy1').error.message}", "dataFactoryName": "@{pipeline().DataFactory}", "pipelineName": "@{pipeline().Pipeline}", "receiver": "@pipeline().parameters.receiver" }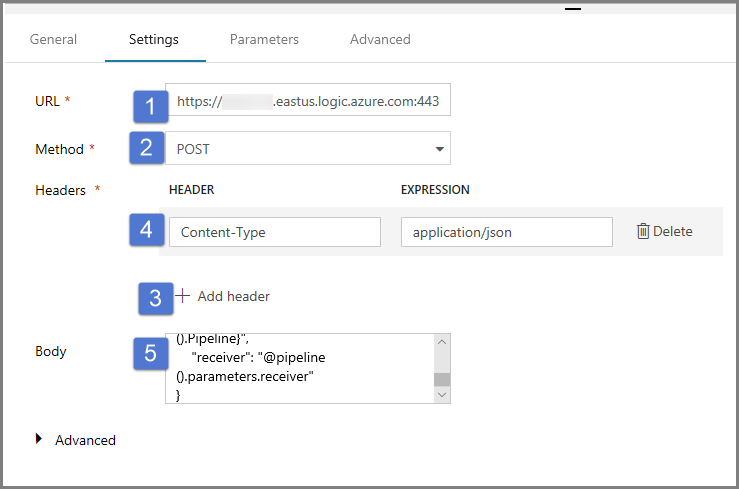
Seleccione el botón con una X roja que está a la derecha de la actividad de copia en el diseñador de canalizaciones y arrástrelo y colóquelo en la actividad sendFailureEmailActivity que acaba de crear.
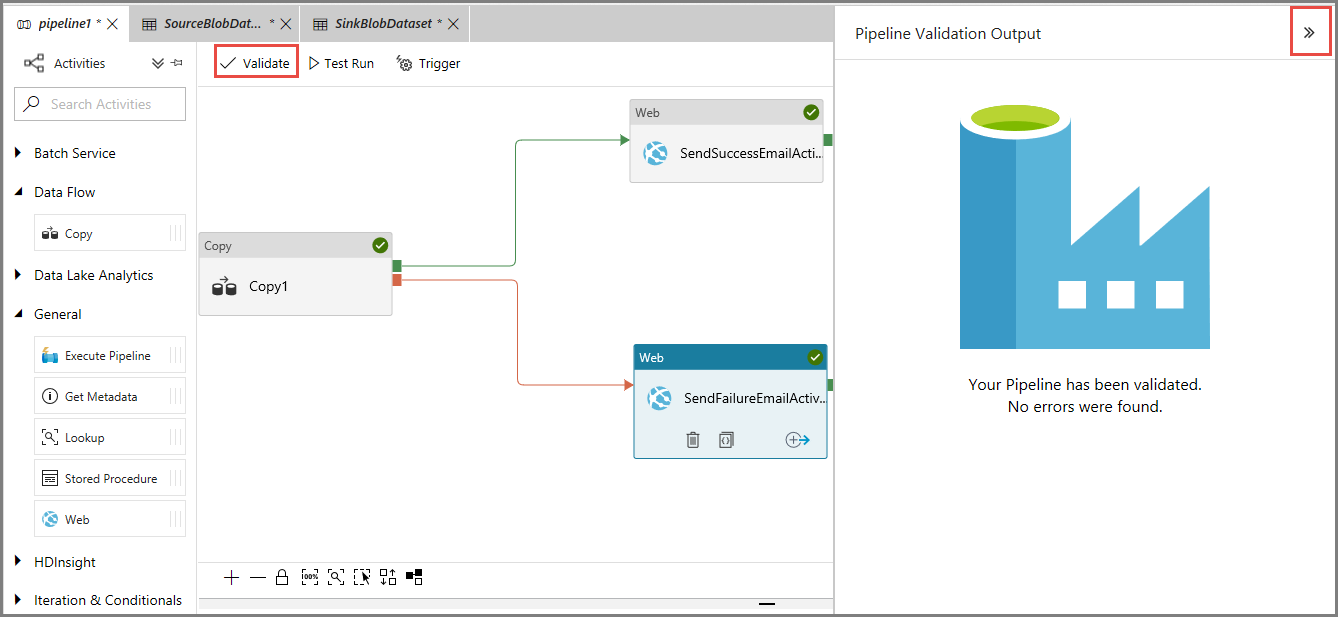
Para comprobar la canalización, haga clic en el botón Validate (Comprobar) en la barra de herramientas. Haga clic en el botón >> para cerrar la ventana Pipeline Validation Output (Salida de validación de canalización).
Para publicar las entidades (conjuntos de datos, canalizaciones, etc.) en el servicio Data Factory, seleccione Publish All (Publicar todo). Espere a que aparezca el mensaje Successfully published (Publicado correctamente).

Desencadenamiento de una ejecución de la canalización que se realiza correctamente
Para desencadenar una ejecución de canalización, haga clic en Trigger (Desencadenar) en la barra de herramientas y en Trigger Now (Desencadenar ahora).
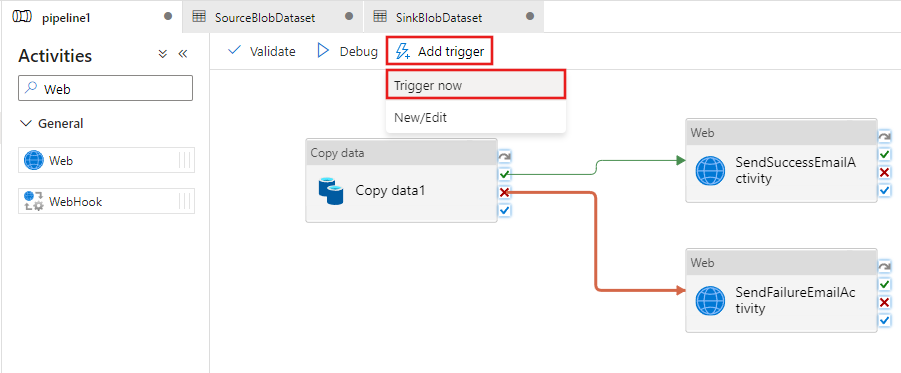
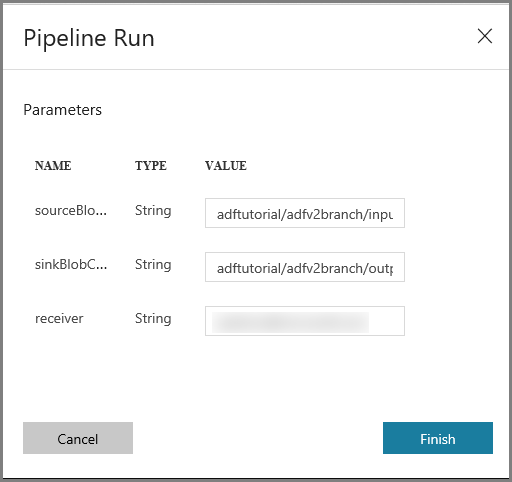
En la ventana Pipeline Run (Ejecución de canalización), lleve a cabo los pasos siguientes:
Escriba adftutorial/adfv2branch/input como parámetro sourceBlobContainer.
Escriba adftutorial/adfv2branch/output como parámetro sinkBlobContainer.
Escriba una dirección de correo electrónico en receiver.
Haga clic en Finish (Finalizar).
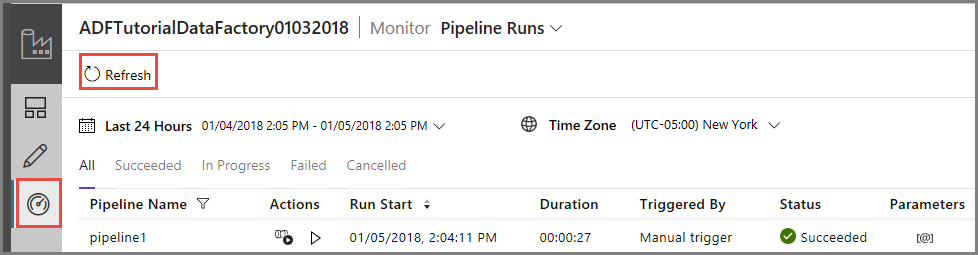
Supervisión de la correcta ejecución de la canalización
Para supervisar la ejecución de la canalización, cambie a la pestaña Monitor (Supervisar) de la izquierda. Verá que la ejecución de la canalización que desencadenó manualmente. Use el botón Refresh (Actualizar) para actualizar la lista.
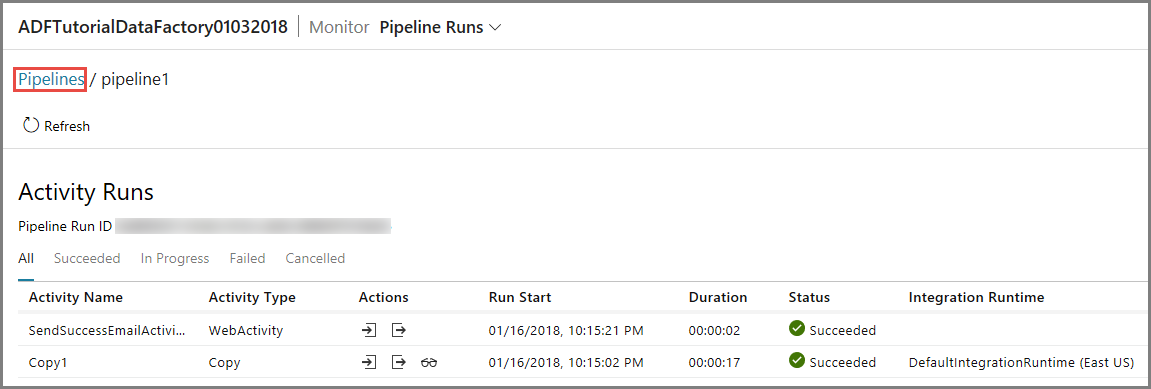
Para ver las ejecuciones de actividad asociadas con la de esta canalización, haga clic en el primer vínculo de la columna Actions (Acciones). Para volver a la vista anterior, haga clic en Pipelines (Canalizaciones) de la parte superior. Use el botón Refresh (Actualizar) para actualizar la lista.
Desencadenamiento de una ejecución de la canalización que se realiza incorrectamente
Cambie a la pestaña Edit (Editar) de la izquierda.
Para desencadenar una ejecución de canalización, haga clic en Trigger (Desencadenar) en la barra de herramientas y en Trigger Now (Desencadenar ahora).
En la ventana Pipeline Run (Ejecución de canalización), lleve a cabo los pasos siguientes:
- Escriba adftutorial/dummy/input como parámetro sourceBlobContainer. Asegúrese de que la carpeta ficticia no existe en el contenedor adftutorial.
- Escriba adftutorial/dummy/output en el parámetro sinkBlobContainer.
- Escriba una dirección de correo electrónico en receiver.
- Haga clic en Finalizar
Supervisión de la ejecución de canalización incorrecta
Para supervisar la ejecución de la canalización, cambie a la pestaña Monitor (Supervisar) de la izquierda. Verá que la ejecución de la canalización que desencadenó manualmente. Use el botón Refresh (Actualizar) para actualizar la lista.
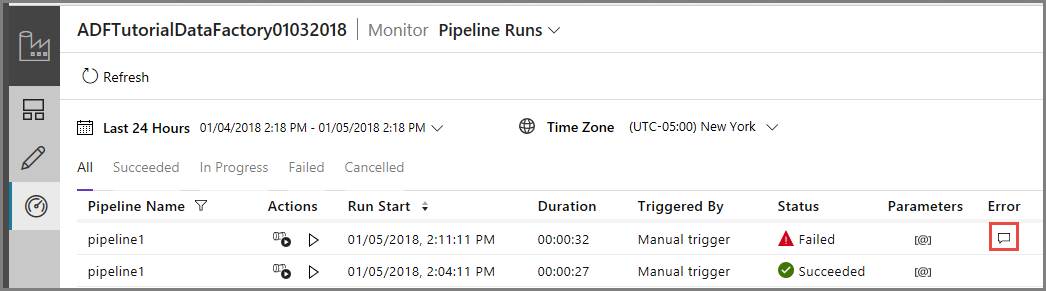
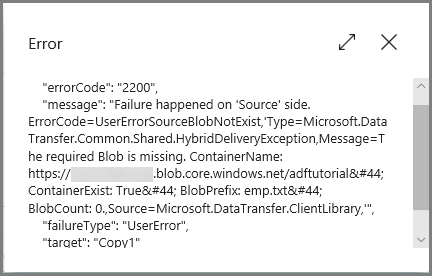
Haga clic en el vínculo Error para ver los detalles del error en la ejecución de la canalización.

Para ver las ejecuciones de actividad asociadas con la de esta canalización, haga clic en el primer vínculo de la columna Actions (Acciones). Use el botón Refresh (Actualizar) para actualizar la lista. Tenga en cuenta que en la actividad de copia de la canalización se produjo un error. La actividad web envió correctamente el correo electrónico de operación incorrecta al receptor especificado.
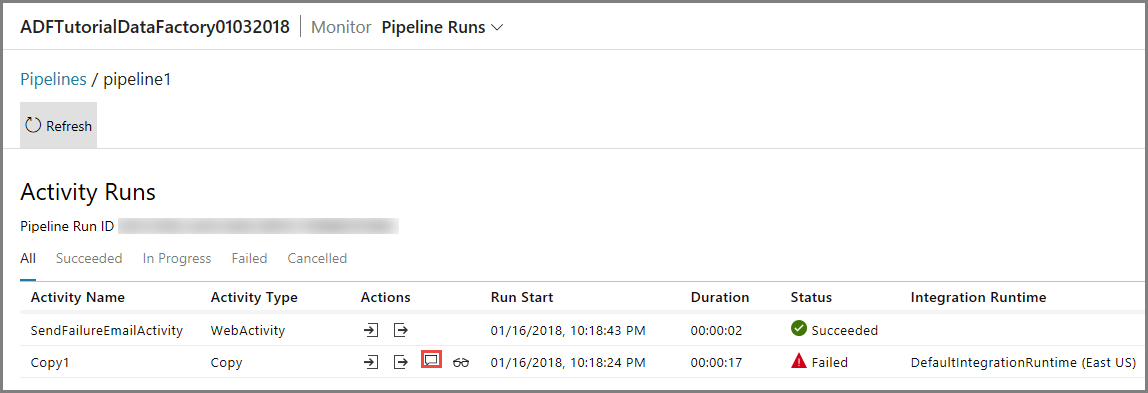
Haga clic en el vínculo Error de la columna Actions (Acciones) para ver los detalles sobre el error.
Contenido relacionado
En este tutorial, realizó los pasos siguientes:
- Creación de una factoría de datos.
- Creación de un servicio vinculado de Azure Storage
- Creación de un conjunto de datos del blob de Azure
- Creación de una canalización que contiene una actividad de copia y una actividad web
- Envío de los resultados de las actividades en actividades subsiguientes
- Uso de las variables del sistema y del paso de parámetros
- Inicio de la ejecución de una canalización
- Supervisión de las ejecuciones de canalización y actividad
Ahora puede continuar a la sección de conceptos para obtener más información sobre Azure Data Factory.