Formato de texto delimitado en Azure Data Factory y Azure Synapse Analytics
SE APLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. Obtenga información sobre cómo iniciar una nueva evaluación gratuita.
Siga este artículo cuando quiera analizar los archivos de texto delimitado o escribir los datos en formato de texto delimitado.
El formato de texto delimitado se admite para los conectores siguientes:
- Amazon S3
- Almacenamiento compatible con Amazon S3
- Azure Blob
- Azure Data Lake Storage Gen1
- Azure Data Lake Storage Gen2
- Archivos de Azure
- Sistema de archivos
- FTP
- Google Cloud Storage
- HDFS
- HTTP
- Oracle Cloud Storage
- SFTP
Propiedades del conjunto de datos
Si desea ver una lista completa de las secciones y propiedades disponibles para definir conjuntos de datos, consulte el artículo sobre conjuntos de datos. En esta sección se proporciona una lista de las propiedades que admite el conjunto de datos de texto delimitado.
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type del conjunto de datos debe establecerse en DelimitedText. | Sí |
| ubicación | Configuración de ubicación de los archivos. Cada conector basado en archivos tiene su propio tipo de ubicación y propiedades compatibles en location. |
Sí |
| columnDelimiter | Los caracteres usados para separar las columnas en un archivo. El valor predeterminado es coma ,. Cuando el delimitador de columna se define como cadena vacía (es decir, ningún delimitador), toda la línea se toma como una sola columna.Actualmente, el delimitador de columna como cadena vacía solo se admite para el flujo de datos de asignación, pero no para la actividad de copia. |
No |
| rowDelimiter | Para actividad de copia, el carácter único o «\r\n» usado para separar las filas en un archivo. El valor predeterminado es cualquiera de los siguientes en lectura: [«\r\n», «\r», «\n»] y «\r\n» en escritura. «\r\n» solo se admite en el comando copiar. Para Flujo de datos de asignación, uno o dos caracteres que se usan para separar las filas de un archivo. El valor predeterminado es cualquiera de los siguientes en lectura: [«\r\n», «\r», «\n»] y «\n» en escritura. Cuando el delimitador de fila se establece en ningún delimitador (cadena vacía), también debe establecerse el delimitador de columna como ningún delimitador (cadena vacía), lo que significa que se trata todo el contenido como un valor único. Actualmente, solo se admite el delimitador de fila como cadena vacía para el flujo de datos de asignación, pero no para la actividad de copia. |
No |
| quoteChar | El carácter único para entrecomillar los valores de columna si contiene el delimitador de columna. El valor predeterminado es comillas dobles ". Cuando quoteChar se define como una cadena vacía, significa que no hay ningún carácter de comillas y el valor de la columna no está entre comillas, y escapeChar se usa como carácter de escape para el delimitador de columna y para sí mismo. |
No |
| escapeChar | El carácter único para escapar las comillas dentro de un valor entre comillas. El valor predeterminado es barra diagonal inversa \ . Cuando escapeChar se define como una cadena vacía, quoteChar también debe establecerse como una cadena vacía. En este caso, asegúrese de que ninguno de los valores de columna contenga delimitadores. |
No |
| firstRowAsHeader | Especifica si se debe tratar o convertir la primera fila como una línea de encabezado con nombres de columnas. Los valores permitidos son true y false (predeterminado). Si la primera fila como encabezado es falsa, tenga en cuenta que la vista previa de los datos de la interfaz de usuario y la salida de la actividad de búsqueda generan automáticamente los nombres de columna como Prop_ {n} (a partir de 0) y la actividad de copia requiere una asignación explícita del origen al receptor y busca las columnas por ordinal (a partir de 1) y flujo de datos de asignación, y busca las columnas con el nombre Column_{n} (a partir de 1). |
No |
| nullValue | Especifica la representación de cadena del valor null. El valor predeterminado es una cadena vacía. |
No |
| encodingName | El tipo de codificación usado para leer y escribir archivos de prueba. Estos son los valores permitidos: "UTF-8","UTF-8 sin BOM", "UTF-16", "UTF-16BE", "UTF-32", "UTF-32BE", "US-ASCII", "UTF-7", "BIG5", "EUC-JP", "EUC-KR", "GB2312", "GB18030", "JOHAB", "SHIFT-JIS", "CP875", "CP866", "IBM00858", "IBM037", "IBM273", "IBM437", "IBM500", "IBM737", "IBM775", "IBM850", "IBM852", "IBM855", "IBM857", "IBM860", "IBM861", "IBM863", "IBM864", "IBM865", "IBM869", "IBM870", "IBM01140", "IBM01141", "IBM01142", "IBM01143", "IBM01144", "IBM01145", "IBM01146", "IBM01147", "IBM01148", "IBM01149", "ISO-2022-JP", "ISO-2022-KR", "ISO-8859-1", "ISO-8859-2", "ISO-8859-3", "ISO-8859-4", "ISO-8859-5", "ISO-8859-6", "ISO-8859-7", "ISO-8859-8", "ISO-8859-9", "ISO-8859-13", "ISO-8859-15", "WINDOWS-874", "WINDOWS-1250", "WINDOWS-1251", "WINDOWS-1252", "WINDOWS-1253", "WINDOWS-1254", "WINDOWS-1255", "WINDOWS-1256", "WINDOWS-1257", "WINDOWS-1258". Tenga en cuenta que el flujo de datos de asignación no admite la codificación UTF-7. Nota: El flujo de datos de asignación no admite la codificación UTF-8 con marca de orden de bytes (BOM). |
No |
| compressionCodec | El códec de compresión usado para leer y escribir archivos de texto. Los valores permitidos son bzip2, gzip, deflate, ZipDeflate, TarGzip, Tar, snappy o Iz4. La opción predeterminada no se comprime. Tenga en cuenta que actualmente la actividad de copia no admite "snappy" ni "lz4", y que el flujo de datos de asignación no admite "ZipDeflate", "TarGzip" ni "Tar". Tenga en cuenta que, cuando se utiliza la actividad de copia para descomprimir archivos ZipDeflate/TarGzip/Tar y escribir en el almacén de datos receptor basado en archivos, los archivos se extraen de manera predeterminada en la carpeta: <path specified in dataset>/<folder named as source compressed file>/. Use preserveZipFileNameAsFolder/preserveCompressionFileNameAsFolder en el origen de la actividad de copia para controlar si se debe conservar el nombre de los archivos comprimidos como una estructura de carpetas. |
No |
| compressionLevel | La razón de compresión. Los valores permitidos son Optimal o Fastest. - Fastest: la operación de compresión debe completarse tan pronto como sea posible, incluso si el archivo resultante no se comprime de forma óptima. - Optimal: la operación de compresión se debe comprimir óptimamente, incluso si tarda más tiempo en completarse. Para más información, consulte el tema Nivel de compresión . |
No |
A continuación encontrará un ejemplo de un conjunto de datos de texto delimitado en Azure Blob Storage:
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"container": "containername",
"folderPath": "folder/subfolder",
},
"columnDelimiter": ",",
"quoteChar": "\"",
"escapeChar": "\"",
"firstRowAsHeader": true,
"compressionCodec": "gzip"
}
}
}
Propiedades de la actividad de copia
Si desea ver una lista completa de las secciones y propiedades disponibles para definir actividades, consulte el artículo sobre canalizaciones. En esta sección se proporciona una lista de las propiedades que admiten el origen y el receptor de texto delimitado.
Texto delimitado como origen
En la sección *source* de la actividad de copia se admiten las siguientes propiedades.
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type del origen de la actividad de copia debe establecerse en DelimitedTextSource. | Sí |
| formatSettings | Un grupo de propiedades. Consulte la tabla Configuración de lectura de texto delimitado a continuación. | No |
| storeSettings | Un grupo de propiedades sobre cómo leer datos de un almacén de datos. Cada conector basado en archivos tiene su propia configuración de lectura admitida en storeSettings. |
No |
Configuración de lectura de texto delimitado admitida en formatSettings:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type de formatSettings debe establecerse en DelimitedTextReadSettings. | Sí |
| skipLineCount | Indica el número de filas no vacías que se omitirán al leer datos de archivos de entrada. Si se especifican ambos valores skipLineCount y firstRowAsHeader, las líneas se omiten primero y, luego, la información del encabezado se lee a partir del archivo de entrada. |
No |
| compressionProperties | Un grupo de propiedades sobre cómo descomprimir datos para un códec de compresión determinado. | No |
| preserveZipFileNameAsFolder (en compressionProperties->type como ZipDeflateReadSettings) |
Se aplica cuando el conjunto de datos de entrada se configura con compresión ZipDeflate. Indica si se debe conservar el nombre del archivo ZIP de origen como estructura de carpetas durante la copia. - Cuando se establece en true (valor predeterminado) , el servicio escribe los archivos descomprimidos en <path specified in dataset>/<folder named as source zip file>/.- Cuando se establece en false, el servicio escribe los archivos descomprimidos directamente en <path specified in dataset>. Asegúrese de que no tenga nombres de archivo duplicados en distintos archivos ZIP de origen para evitar comportamientos acelerados o inesperados. |
No |
| preserveCompressionFileNameAsFolder (en compressionProperties->type como TarGZipReadSettings o TarReadSettings) |
Se aplica cuando el conjunto de datos de entrada está configurado con la compresión TarGzip/Tar. Indica si se debe conservar el nombre del archivo de origen comprimido como estructura de carpetas durante la copia. - Cuando se establece en true (valor predeterminado) , el servicio escribe los archivos descomprimidos en <path specified in dataset>/<folder named as source compressed file>/. - Cuando se establece en false, el servicio escribe los archivos descomprimidos directamente en <path specified in dataset>. Asegúrese de que no haya nombres de archivo duplicados en distintos archivos de origen para evitar comportamientos acelerados o inesperados. |
No |
"activities": [
{
"name": "CopyFromDelimitedText",
"type": "Copy",
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"storeSettings": {
"type": "AzureBlobStorageReadSettings",
"recursive": true
},
"formatSettings": {
"type": "DelimitedTextReadSettings",
"skipLineCount": 3,
"compressionProperties": {
"type": "ZipDeflateReadSettings",
"preserveZipFileNameAsFolder": false
}
}
},
...
}
...
}
]
Texto delimitado como receptor
En la sección *sink* de la actividad de copia se admiten las siguientes propiedades.
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type del origen de la actividad de copia debe establecerse en DelimitedTextSink. | Sí |
| formatSettings | Un grupo de propiedades. Consulte la tabla Configuración de escritura de texto delimitado a continuación. | No |
| storeSettings | Un grupo de propiedades sobre cómo escribir datos en un almacén de datos. Cada conector basado en archivos tiene su propia configuración de escritura admitida en storeSettings. |
No |
Configuración de escritura de texto delimitado admitida en formatSettings:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type de formatSettings debe establecerse en DelimitedTextWriteSettings. | Sí |
| fileExtension | La extensión de archivo que se usa para denominar los archivos de salida, por ejemplo: .csv, .txt. Debe especificarse cuando no se especifica fileName en el conjunto de datos DelimitedText de salida. Cuando el nombre de archivo se configure en el conjunto de resultados de salida, se usará como nombre de archivo receptor y se omitirá la configuración de la extensión de archivo. |
Sí, cuando no se especifica el nombre de archivo en el conjunto de datos de salida |
| maxRowsPerFile | Al escribir datos en una carpeta, puede optar por escribir en varios archivos y especificar el número máximo de filas por archivo. | No |
| fileNamePrefix | Se aplica cuando se configura maxRowsPerFile.Especifique el prefijo de nombre de archivo al escribir datos en varios archivos, lo que da como resultado este patrón: <fileNamePrefix>_00000.<fileExtension>. Si no se especifica, el prefijo de nombre de archivo se generará automáticamente. Esta propiedad no se aplica cuando el origen es un almacén basado en archivos o un almacén de datos habilitado para la opción de partición. |
No |
Propiedades de Asignación de instancias de Data Flow
En los flujos de datos de asignación, puede leer y escribir en formato de texto delimitado en los siguientes almacenes de datos: Azure Blob Storage, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2 y SFTP, y puede leer el formato de texto delimitado de Amazon S3.
Conjunto de datos insertado
Los flujos de datos de asignación admiten "conjuntos de datos insertados" como opción para definir el origen y el receptor. Un conjunto de datos delimitado insertado se define directamente dentro de las transformaciones de origen y receptor y no se comparte fuera del flujo de datos definido. Resulta útil para parametrizar las propiedades del conjunto de datos directamente dentro del flujo de datos y puede beneficiarse de un rendimiento mejorado de los conjuntos de datos de ADF compartidos.
Al leer un gran número de carpetas y archivos de origen, puede mejorar el rendimiento de la detección de archivos de flujo de datos estableciendo la opción "Esquema proyectado por el usuario" dentro del Cuadro de diálogo Proyección | Opciones de esquema. Esta opción desactiva la detección automática de esquemas predeterminada de ADF y mejorará considerablemente el rendimiento de la detección de archivos. Antes de establecer esta opción, asegúrese de importar la proyección para que ADF tenga un esquema existente para la proyección. Esta opción no funciona con el desfase de esquema.
Propiedades de origen
En la tabla siguiente se enumeran las propiedades que un origen de texto delimitado admite. Puede editar estas propiedades en la pestaña Source options (Opciones de origen).
| Nombre | Descripción | Obligatorio | Valores permitidos | Propiedad de script de flujo de datos |
|---|---|---|---|---|
| Rutas de acceso comodín | Se procesarán todos los archivos que coincidan con la ruta de acceso comodín. Reemplaza a la carpeta y la ruta de acceso del archivo establecidas en el conjunto de datos. | no | String[] | wildcardPaths |
| Ruta de acceso raíz de la partición | En el caso de datos de archivos con particiones, puede especificar una ruta de acceso raíz de la partición para leer las carpetas con particiones como columnas. | no | String | partitionRootPath |
| Lista de archivos | Si el origen apunta a un archivo de texto que enumera los archivos que se van a procesar. | no | true o false |
fileList |
| Filas de varias líneas | El archivo de código fuente contiene filas que abarcan varias líneas. Los valores de varias líneas deben estar entre comillas. | no true ni false |
multiLineRow | |
| Columna para almacenar el nombre de archivo | Se crea una nueva columna con el nombre y la ruta de acceso del archivo de origen. | no | String | rowUrlColumn |
| Después de finalizar | Se eliminan o mueven los archivos después del procesamiento. La ruta de acceso del archivo comienza en la raíz del contenedor. | no | Borrar: true o false Mover: ['<from>', '<to>'] |
purgeFiles moveFiles |
| Filtrar por última modificación | Elija si desea filtrar los archivos en función de cuándo se modificaron por última vez. | no | Marca de tiempo | modifiedAfter modifiedBefore |
| No permitir que se encuentren archivos | Si es true, no se devuelve un error si no se encuentra ningún archivo. | no | true o false |
ignoreNoFilesFound |
| Máximo de columnas | El valor predeterminado es 20480. Personalice este valor cuando el número de columna sea superior a 20480 | No | Entero | maxColumns |
Nota
La compatibilidad de orígenes de flujo de datos para la lista de archivos se limita a 1024 entradas en el archivo. Para incluir más archivos, use caracteres comodín en la lista de archivos.
Ejemplo de origen
En la imagen siguiente se presenta un ejemplo de una configuración de origen de texto delimitado en flujos de datos de asignación.
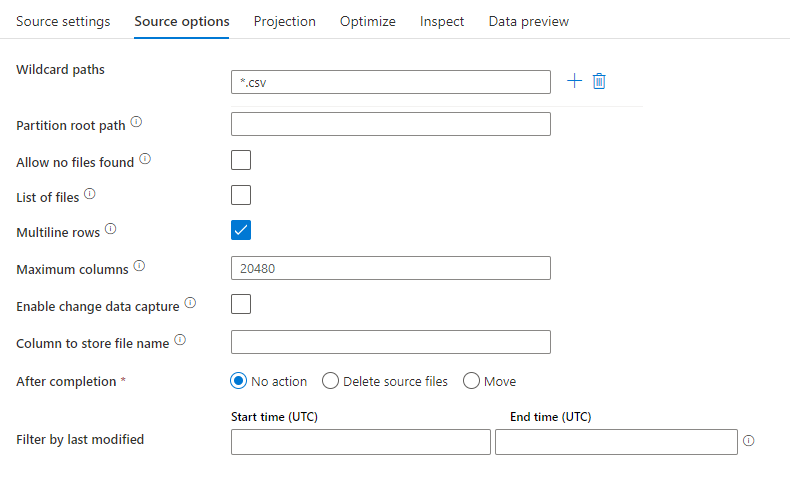
El script de flujo de datos asociado es:
source(
allowSchemaDrift: true,
validateSchema: false,
ignoreNoFilesFound: false,
multiLineRow: true,
wildcardPaths:['*.csv']) ~> CSVSource
Nota:
Los orígenes de flujo de datos admiten un conjunto limitado de globalidad de Linux que es compatible con los sistemas de archivos de Hadoop.
Propiedades del receptor
En la tabla siguiente se enumeran las propiedades que un receptor de texto delimitado admite. Puede editar estas propiedades en la pestaña Configuración.
| Nombre | Descripción | Obligatorio | Valores permitidos | Propiedad de script de flujo de datos |
|---|---|---|---|---|
| Borrar la carpeta | Si la carpeta de destino se borra antes de escribir. | no | true o false |
truncate |
| Opción de nombre de archivo | El formato de nombre de los datos escritos. De forma predeterminada, un archivo por partición en formato part-#####-tid-<guid>. |
no | Patrón: Cadena Por partición: Cadena[] Asignar nombre al archivo como datos de columna: cadena Salida en un solo archivo: ['<fileName>'] Asignar nombre a la carpeta como datos de columna: cadena |
filePattern partitionFileNames rowUrlColumn partitionFileNames rowFolderUrlColumn |
| Entrecomillar todo | Incluye todos los valores entre comillas. | no | true o false |
quoteAll |
| Encabezado | Agrega encabezados de cliente a archivos de salida. | no | [<string array>] |
header |
Ejemplo de receptor
En la imagen siguiente se presenta un ejemplo de una configuración de receptor de texto delimitado en flujos de datos de asignación.
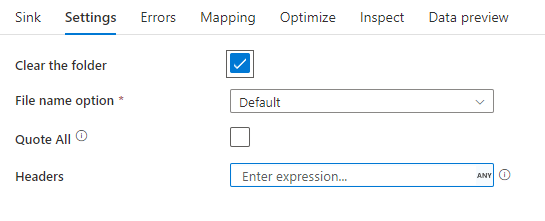
El script de flujo de datos asociado es:
CSVSource sink(allowSchemaDrift: true,
validateSchema: false,
truncate: true,
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> CSVSink
Conectores y formatos relacionados
Estos son algunos conectores y formatos comunes relacionados con el formato de texto delimitado:
- Azure Blob Storage
- Formato binario
- Dataverse
- Formato Delta
- Formato Excel
- Sistema de archivos
- FTP
- HTTP
- Formato JSON
- Formato Parquet