Formato Parquet en Azure Data Factory y Azure Synapse Analytics
SE APLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. ¡Obtenga más información sobre cómo iniciar una nueva evaluación gratuita!
Siga este artículo cuando quiera analizar los archivos Parquet o escribir los datos en formato Parquet.
El formato Parquet se admite para los conectores siguientes:
- Amazon S3
- Almacenamiento compatible con Amazon S3
- Azure Blob
- Azure Data Lake Storage Gen1
- Azure Data Lake Storage Gen2
- Archivos de Azure
- Sistema de archivos
- FTP
- Google Cloud Storage
- HDFS
- HTTP
- Oracle Cloud Storage
- SFTP
Para ver una lista de las características admitidas de todos los conectores disponibles, consulte el artículo Introducción a los conectores.
Uso del entorno de ejecución de integración autohospedado
Importante
Para la copia habilitada por el Entorno de ejecución de integración autohospedado, por ejemplo, entre almacenes de datos locales y en la nube, si no está copiando archivos Parquet tal cual, necesita instalar JRE 8 (Java Runtime Environment) de 64 bits, JDK 23 (Java Development Kit) u OpenJDK en su máquina IR. Consulte el párrafo siguiente para más información.
En el caso de las copias que se ejecutan en el IR autohospedado con la serialización o deserialización de archivos Parquet, para buscar el entorno de ejecución de Java, el servicio consulta primero el Registro (SOFTWARE\JavaSoft\Java Runtime Environment\{Current Version}\JavaHome) en busca de JRE; si no lo encuentra, comprueba la variable del sistema JAVA_HOME de OpenJDK.
- Para usar JRE: el IR de 64 bits necesita JRE de 64 bits. Puede encontrarlo aquí.
-
Para usar JDK: IR de 64 bits requiere JDK 23 de 64 bits. Puede encontrarlo aquí. Asegúrese de actualizar la variable del sistema
JAVA_HOMEa la carpeta raíz de la instalación de JDK 23, es decir,C:\Program Files\Java\jdk-23, y agregue la ruta de acceso a las carpetasC:\Program Files\Java\jdk-23\binyC:\Program Files\Java\jdk-23\bin\servera la variable del sistemaPath. - Para usar OpenJDK: se admite desde la versión 3.13 de IR. Empaquete jvm.dll con todos los demás ensamblados de OpenJDK necesarios en la máquina del IR autohospedado y establezca la variable de entorno del sistema JAVA_HOME en el valor que corresponda y, luego, reinicie el IR autohospedado para que surta efecto de inmediato. Para descargar Microsoft Build de OpenJDK, consulte Microsoft Build of OpenJDK™.
Sugerencia
Si copia datos desde o hacia Parquet mediante Integration Runtime autohospedado y recibe un error que indica que "Se produjo un error al invocar Java, mensaje: Espacio en el montón java.lang.OutOfMemoryError:Java", puede agregar una variable de entorno _JAVA_OPTIONS en la máquina que hospeda IR autohospedado para ajustar el tamaño del montón mínimo y máximo para JVM a fin de facilitar dicha copia y, a continuación, volver a ejecutar la canalización.
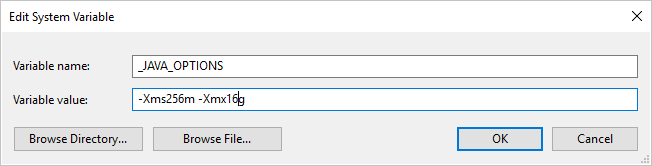
Ejemplo: establecimiento de la variable _JAVA_OPTIONS con el valor -Xms256m -Xmx16g. La marca Xms especifica el grupo de asignación de memoria inicial para una máquina virtual Java (JVM), mientras que Xmx especifica el grupo de asignación de memoria máxima. Esto significa que JVM se iniciará con la cantidad de memoria Xms y podrá utilizar Xmx como máximo. De manera predeterminada, el servicio usa un mínimo de 64 MB y un máximo de 1G.
Propiedades del conjunto de datos
Si desea ver una lista completa de las secciones y propiedades disponibles para definir conjuntos de datos, consulte el artículo sobre conjuntos de datos. En esta sección se proporciona una lista de las propiedades que admite el conjunto de datos de Parquet.
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type del conjunto de datos debe establecerse en Parquet. | Sí |
| ubicación | Configuración de ubicación de los archivos. Cada conector basado en archivos tiene su propio tipo de ubicación y propiedades compatibles en location.
Consulte los detalles en el artículo de conectores -> sección de propiedades del conjunto de datos. |
Sí |
| compressionCodec | El códec de compresión que se usará al escribir en archivos Parquet. Al realizar la lectura desde archivos Parquet, las instancias de Data Factory determinan automáticamente el códec de compresión basado en los metadatos del archivo. Los tipos admitidos son "none","gzip","snappy" (predeterminado) e "lzo". Tenga en cuenta que la actividad de copia no es compatible actualmente con LZO cuando hay archivos Parquet de lectura y escritura. |
No |
Nota
No se admiten espacios en blanco en el nombre de columna de los archivos Parquet.
A continuación encontrará un ejemplo de un conjunto de datos de Parquet en Azure Blob Storage:
{
"name": "ParquetDataset",
"properties": {
"type": "Parquet",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"container": "containername",
"folderPath": "folder/subfolder",
},
"compressionCodec": "snappy"
}
}
}
Propiedades de la actividad de copia
Si desea ver una lista completa de las secciones y propiedades disponibles para definir actividades, consulte el artículo sobre canalizaciones. En esta sección se proporciona una lista de las propiedades que admiten el receptor y el origen Parquet.
Parquet como origen
En la sección *source* de la actividad de copia se admiten las siguientes propiedades.
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type del origen de la actividad de copia debe establecerse en ParquetSource. | Sí |
| storeSettings | Un grupo de propiedades sobre cómo leer datos de un almacén de datos. Cada conector basado en archivos tiene su propia configuración de lectura admitida en storeSettings.
Consulte los detalles en el artículo de conectores -> sección de propiedades de la actividad de copia. |
No |
Parquet como receptor
En la sección *sink* de la actividad de copia se admiten las siguientes propiedades.
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type del receptor de la actividad de copia debe establecerse en ParquetSink. | Sí |
| formatSettings | Un grupo de propiedades. Consulte la tabla Configuración de escritura de Parquet a continuación. | No |
| storeSettings | Un grupo de propiedades sobre cómo escribir datos en un almacén de datos. Cada conector basado en archivos tiene su propia configuración de escritura admitida en storeSettings.
Consulte los detalles en el artículo de conectores -> sección de propiedades de la actividad de copia. |
No |
Configuración de escritura de Parquet compatible en formatSettings:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type de formatSettings debe establecerse en ParquetWriteSettings. | Sí |
| maxRowsPerFile | Al escribir datos en una carpeta, puede optar por escribir en varios archivos y especificar el número máximo de filas por archivo. | No |
| fileNamePrefix | Se aplica cuando se configura maxRowsPerFile.Especifique el prefijo de nombre de archivo al escribir datos en varios archivos, lo que da como resultado este patrón: <fileNamePrefix>_00000.<fileExtension>. Si no se especifica, el prefijo de nombre de archivo se generará automáticamente. Esta propiedad no se aplica cuando el origen es un almacén basado en archivos o un almacén de datos habilitado para la opción de partición. |
No |
Propiedades de Asignación de instancias de Data Flow
En los flujos de datos de asignación, puede leer y escribir formato Parquet en los siguientes almacenes de datos: Azure Blob Storage, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2 y SFT, y puede leer formato Parquet en Amazon S3.
Propiedades de origen
En la tabla siguiente se enumeran las propiedades que un origen Parquet admite. Puede editar estas propiedades en la pestaña Source options (Opciones del origen).
| Nombre | Descripción | Obligatorio | Valores permitidos | Propiedad de script de flujo de datos |
|---|---|---|---|---|
| Formato | El formato debe ser parquet. |
sí | parquet |
format |
| Rutas de acceso comodín | Se procesarán todos los archivos que coincidan con la ruta de acceso comodín. Reemplaza a la carpeta y la ruta de acceso del archivo establecidas en el conjunto de datos. | no | String[] | wildcardPaths |
| Ruta de acceso raíz de la partición | En el caso de datos de archivos con particiones, puede especificar una ruta de acceso raíz de la partición para leer las carpetas con particiones como columnas. | no | String | partitionRootPath |
| Lista de archivos | Si el origen apunta a un archivo de texto que enumera los archivos que se van a procesar. | no |
true o false |
fileList |
| Columna para almacenar el nombre de archivo | Se crea una nueva columna con el nombre y la ruta de acceso del archivo de origen. | no | String | rowUrlColumn |
| Después de finalizar | Se eliminan o mueven los archivos después del procesamiento. La ruta de acceso del archivo comienza en la raíz del contenedor. | no | Borrar: true o false Mover: [<from>, <to>] |
purgeFiles moveFiles |
| Filtrar por última modificación | Elija si desea filtrar los archivos en función de cuándo se modificaron por última vez. | no | Marca de tiempo | modifiedAfter modifiedBefore |
| No permitir que se encuentren archivos | Si es true, no se devuelve un error si no se encuentra ningún archivo. | no |
true o false |
ignoreNoFilesFound |
Ejemplo de origen
En la imagen siguiente se presenta un ejemplo de una configuración de origen Parquet en flujos de datos de asignación.
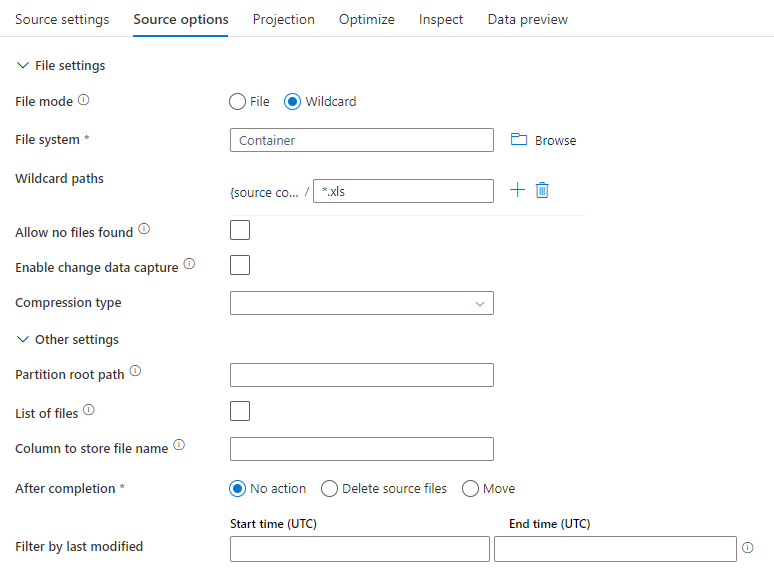
El script de flujo de datos asociado es:
source(allowSchemaDrift: true,
validateSchema: false,
rowUrlColumn: 'fileName',
format: 'parquet') ~> ParquetSource
Propiedades del receptor
En la tabla siguiente se enumeran las propiedades que un receptor Parquet admite. Puede editar estas propiedades en la pestaña Configuración.
| Nombre | Descripción | Obligatorio | Valores permitidos | Propiedad de script de flujo de datos |
|---|---|---|---|---|
| Formato | El formato debe ser parquet. |
sí | parquet |
format |
| Borrar la carpeta | Si la carpeta de destino se borra antes de escribir. | no |
true o false |
truncate |
| Opción de nombre de archivo | El formato de nombre de los datos escritos. De forma predeterminada, un archivo por partición en formato part-#####-tid-<guid>. |
no | Patrón: Cadena Por partición: Cadena[] Como datos de columna: Cadena Salida en un solo archivo: ['<fileName>'] |
filePattern partitionFileNames rowUrlColumn partitionFileNames |
Ejemplo de receptor
En la imagen siguiente se presenta un ejemplo de una configuración de receptor Parquet en flujos de datos de asignación.
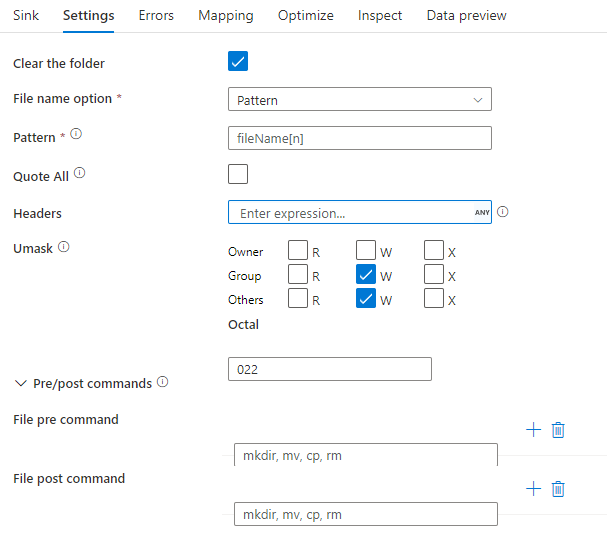
El script de flujo de datos asociado es:
ParquetSource sink(
format: 'parquet',
filePattern:'output[n].parquet',
truncate: true,
allowSchemaDrift: true,
validateSchema: false,
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> ParquetSink
Compatibilidad con tipos de datos
Actualmente, los tipos de datos complejos de Parquet (por ejemplo, MAP, LIST, STRUCT) solo se admiten en los flujos de datos, no en la actividad de copia. Para usar tipos complejos en flujos de datos, no importe el esquema de archivo en el conjunto de datos y deje el esquema en blanco en el conjunto de datos. A continuación, en la transformación de origen, importe la proyección.