Uso de patrones de columnas en el flujo de datos de asignación
SE APLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. Obtenga información sobre cómo iniciar una nueva evaluación gratuita.
Varias transformaciones de flujos de datos de asignación permiten hacer referencia a columnas de plantilla en función de patrones en lugar de nombres de columna codificados de forma rígida. Esta coincidencia se conoce como patrones de columna. Puede definir patrones para buscar la coincidencia de columnas según el nombre, el tipo de datos, la secuencia, el origen o la posición, en lugar de requerir nombres de campo exactos. Hay dos escenarios en los que resultan útiles los patrones de columna:
- Si los campos de origen de entrada cambian a menudo, como en el caso de columnas que cambian en los archivos de texto o bases de datos NoSQL. Este escenario se conoce como desfase de esquema.
- Si desea realizar una operación común en un grupo grande de columnas. Por ejemplo, si desea convertir cada columna que contiene "total" en el nombre de columna en un valor doble.
Patrones de columna en columna derivada y de agregado
Para agregar un patrón de columna a una columna derivada, de agregado o de transformación de ventana, haga clic en Agregar encima de la lista de columnas o el icono del signo más junto a una columna derivada existente. Seleccione Add column pattern (Agregar patrón de columna).
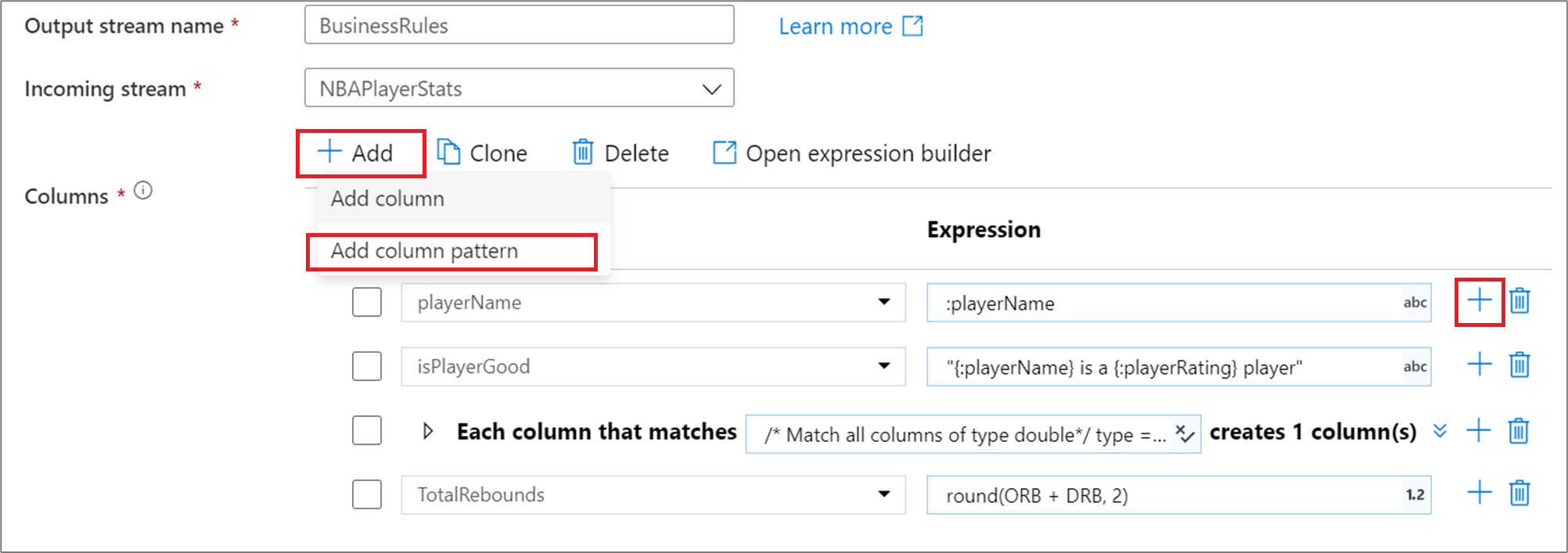
Use el generador de expresiones para escribir la condición de coincidencia. Cree una expresión booleana que busque la coincidencia con las columnas en función de los elementos name, type, stream, origin y position de la columna. El patrón afectará a cualquier columna, desfasada o definida, donde la condición devuelva true.
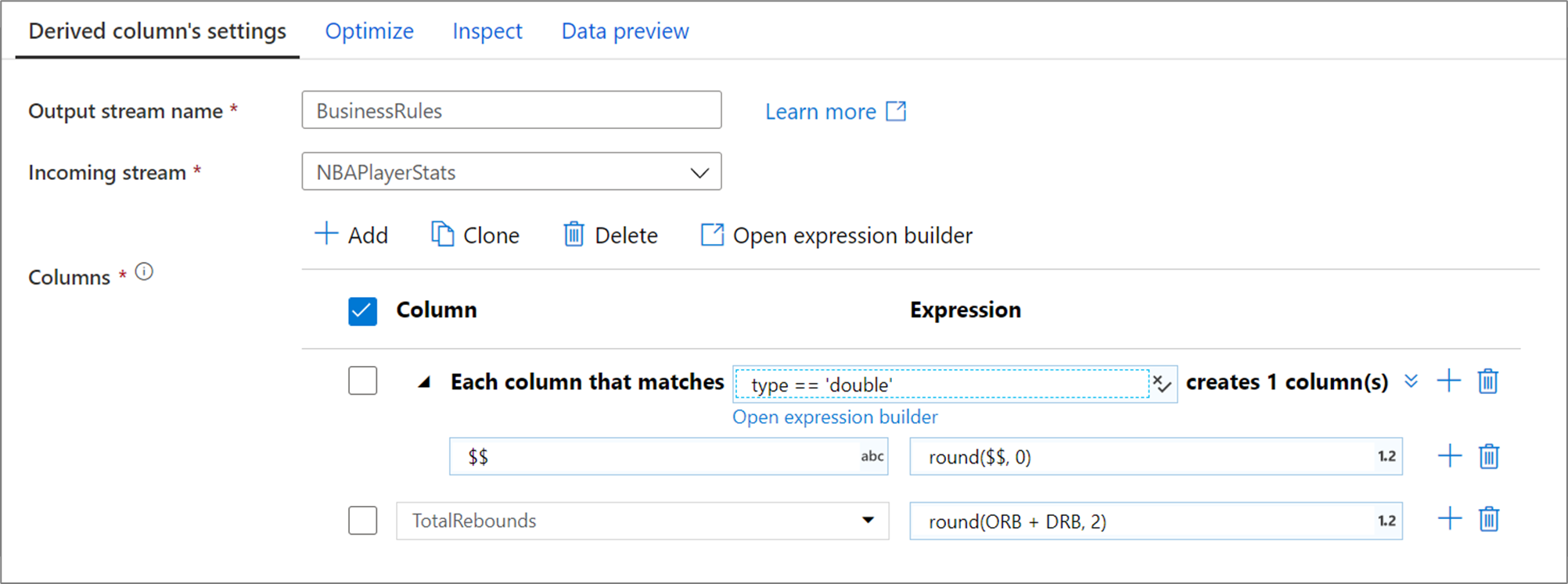
El patrón de columna anterior coincide con cada columna de tipo de datos doble y crea una columna derivada por coincidencia. Al indicar $$ como campo de nombre de columna, todas las columnas coincidentes se actualizan con el mismo nombre. El valor de cada columna es el valor existente redondeado a dos decimales.
Para comprobar que la condición de coincidencia es correcta, puede validar el esquema de salida de las columnas definidas en la pestaña Inspeccionar u obtener una instantánea de los datos en la pestaña Vista previa de los datos.
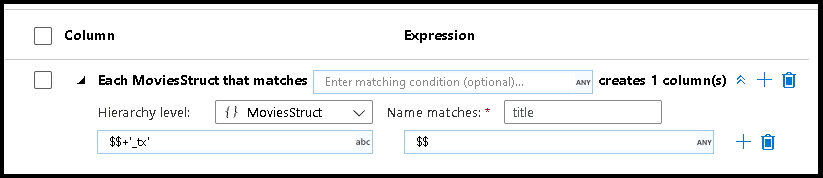
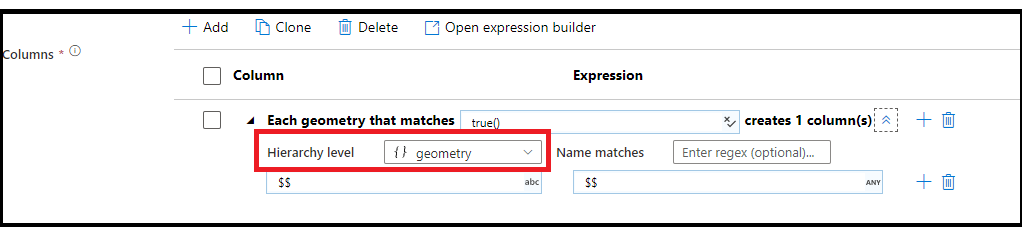
Coincidencia de patrones jerárquica
También puede crear una coincidencia de patrones dentro en estructuras jerárquicas complejas. Expanda la sección Each MoviesStruct that matches en la que se le solicitará cada jerarquía en el flujo de datos. Después, puede crear patrones de coincidencia para las propiedades dentro de la jerarquía elegida.
Aplanamiento de estructuras
Cuando los datos tienen estructuras complejas, como matrices, estructuras jerárquicas o mapas, puede usar la transformación Aplanar para desenrollar matrices y desnormalizar los datos. Para estructuras y mapas, use la transformación de columna derivada con patrones de columna para formar la tabla relacional aplanada a partir de las jerarquías. Puede usar los patrones de columna que se parecen a este ejemplo, que aplana la jerarquía de geografía en un formulario de tabla relacional:
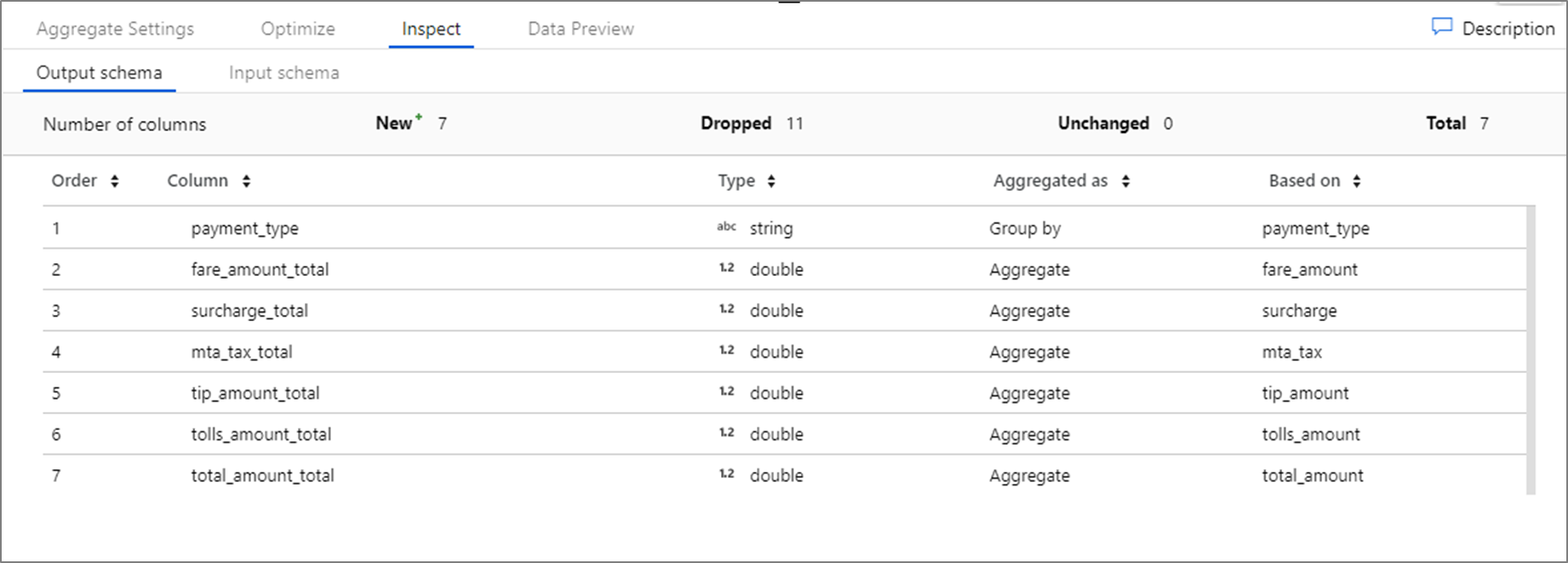
Asignación basada en reglas en selección y receptor
Cuando asigna columnas en transformaciones de origen y selección, puede agregar asignación fija o asignación basada en reglas. Busque la coincidencia según los elementos name, type, stream, origin y position de las columnas. Puede usar cualquier combinación de asignaciones basadas en reglas y fijas. De forma predeterminada, todas las proyecciones con más de 50 columnas tendrán como valor predeterminado una asignación basada en reglas que coincida con todas las columnas y que genere el nombre insertado.
Para agregar una asignación basada en reglas, haga clic en Agregar asignación y seleccione Rule based mapping (Asignación basada en reglas).

Cada asignación basada en reglas requiere dos entradas: la condición por la que buscar coincidencias y el nombre de cada columna asignada. Ambos valores se insertaron a través del generador de expresiones. En el cuadro de expresión de la izquierda, escriba la condición de coincidencia booleana. En el cuadro de expresión de la derecha, especifique a qué se asignará la columna coincidente.

Use la sintaxis de $$ para hacer referencia al nombre de entrada de una columna coincidente. Utilizando la imagen anterior como ejemplo, supongamos que un usuario desea buscar coincidencias en todas las columnas de cadena cuyos nombres tengan más de 6 caracteres. Si una columna de entrada se denomina test, la expresión $$ + '_short' cambiará el nombre de la columna test_short. Si esta es la única asignación que existe, todas las columnas que no cumplan la condición se quitarán de los datos de salida.
Los patrones coinciden con las columnas desfasadas y definidas. Para ver qué columnas definidas están asignadas mediante una regla, haga clic en el icono de las gafas junto a la regla. Compruebe la salida mediante la vista previa de los datos.
Asignación de expresión regular
Si hace clic en el icono del botón de contenido adicional hacia abajo, puede especificar una condición de asignación de regex. Una condición de asignación de regex coincide con todos los nombres de columna que coinciden con la condición regex especificada. Se puede usar en combinación con las asignaciones estándar basadas en reglas.

El ejemplo anterior coincide con el patrón regex (r) o cualquier nombre de columna que contenga un "r" en minúscula. De forma similar a la asignación basada en reglas estándar, todas las columnas coincidentes se modifican por la condición de la derecha con $$ sintaxis.
Jerarquías basadas en reglas
Si la proyección definida tiene una jerarquía, puede usar la asignación basada en reglas para asignar las subcolumnas de las jerarquías. Especifique una condición de coincidencia y la columna compleja cuyas subcolumnas desee asignar. Todas las subcolumnas coincidentes se enviarán con la regla para asignar un nombre de salida especificada a la derecha.
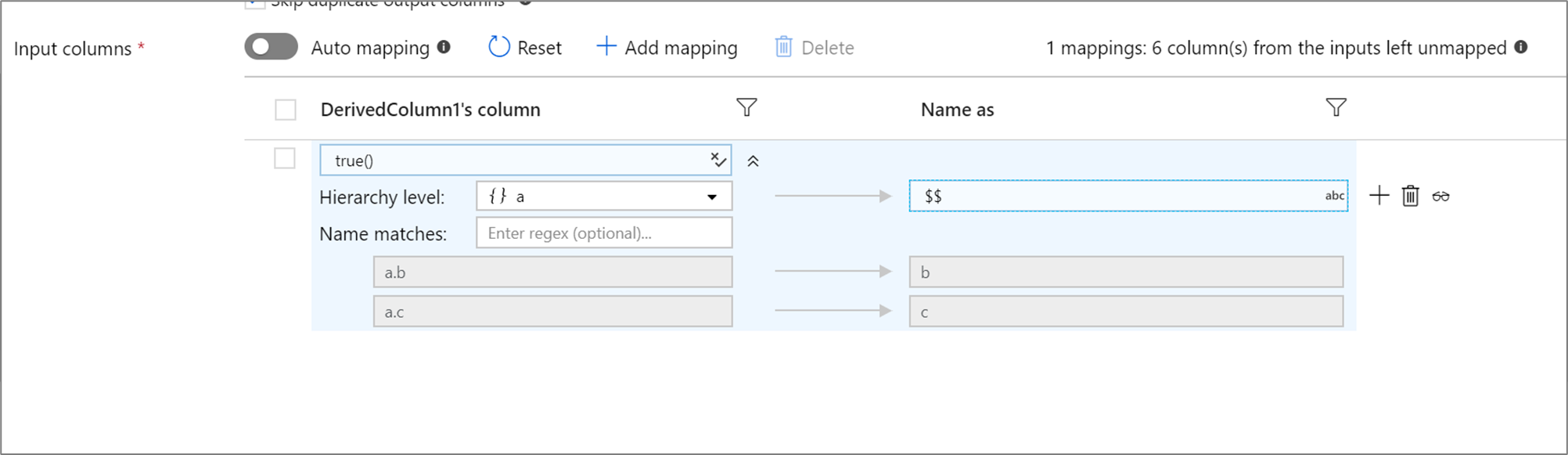
En el ejemplo anterior se hace coincidir con todas las subcolumnas de la columna compleja a. a contiene dos subcolumnas b y c. El esquema de salida incluirá dos columnas b y c, ya que la condición para asignar un nombre de salida es $$.
Valores de expresión de coincidencia de patrones.
$$se traduce al nombre o valor de cada coincidencia en tiempo de ejecución. Piense en$$como equivalente athis.$0se traduce en la coincidencia del nombre de columna actual en tiempo de ejecución para los tipos escalares. Para los tipos jerárquicos,$0representa la ruta de acceso de la jerarquía de columnas coincidentes actual.namerepresenta el nombre de cada columna de entradatyperepresenta el tipo de datos de cada columna de entrada. La lista de tipos de datos del sistema de tipos de flujos de datos se puede encontrar aquí.streamrepresenta el nombre asociado a cada secuencia o transformación del flujopositiones la posición ordinal de las columnas en el flujo de datosorigines la transformación en la que se ha originado o se ha actualizado por última vez una columna
Contenido relacionado
- Obtenga más información sobre el lenguaje de expresiones de los flujos de datos de asignación para las transformaciones de datos.
- Uso de patrones de columnas en la transformación de receptor y en la transformación de selección con asignación basada en reglas.