Copia de datos de Teradata Vantage mediante Azure Data Factory y Synapse Analytics
SE APLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. Obtenga información sobre cómo iniciar una nueva evaluación gratuita.
En este artículo se resume el uso de la actividad de copia en canalizaciones de Azure Data Factory y Synapse Analytics para copiar datos de Teradata Vantage. Se basa en la introducción a la actividad de copia.
Funcionalidades admitidas
Este conector de Teradata se admite para las siguientes características:
| Funcionalidades admitidas | IR |
|---|---|
| Actividad de copia (origen/-) | ① ② |
| Actividad de búsqueda | ① ② |
① Azure Integration Runtime ② Entorno de ejecución de integración autohospedado
Consulte la tabla de almacenes de datos compatibles para ver una lista de almacenes de datos que la actividad de copia admite como orígenes o receptores.
En concreto, este conector Teradata admite las siguientes funcionalidades:
- Teradata versión 14.10, 15.0, 15.10, 16.0, 16.10 y 16.20.
- La copia de datos con autenticación básica, de Windows o LDAP.
- Copia en paralelo desde un origen Teradata. Consulte la sección Copia en paralelo desde Teradata para obtener más detalles.
Prerrequisitos
Si el almacén de datos se encuentra en una red local, una red virtual de Azure o una nube privada virtual de Amazon, debe configurar un entorno de ejecución de integración autohospedado para conectarse a él.
Si el almacén de datos es un servicio de datos en la nube administrado, puede usar Azure Integration Runtime. Si el acceso está restringido a las direcciones IP que están aprobadas en las reglas de firewall, puede agregar direcciones IP de Azure Integration Runtime a la lista de permitidos.
También puede usar la característica del entorno de ejecución de integración de red virtual administrada de Azure Data Factory para acceder a la red local sin instalar ni configurar un entorno de ejecución de integración autohospedado.
Consulte Estrategias de acceso a datos para más información sobre los mecanismos de seguridad de red y las opciones que admite Data Factory.
Si utiliza el entorno de ejecución de integración autohospedado, tenga en cuenta que proporciona un controlador de Teradata integrado a partir de la versión 3.18. No es necesario instalar manualmente ninguno. El controlador requiere "Visual C++ Redistributable 2012 Update 4" en la máquina del entorno de ejecución de integración autohospedado. Si aún no está instalada, descárguela de aquí.
Introducción
Para realizar la actividad de copia con una canalización, puede usar una de los siguientes herramientas o SDK:
- La herramienta Copiar datos
- Azure Portal
- El SDK de .NET
- El SDK de Python
- Azure PowerShell
- API REST
- La plantilla de Azure Resource Manager
Creación de un servicio vinculado en Teradata mediante la interfaz de usuario
Siga estos pasos para crear un servicio vinculado en Teradata en la interfaz de usuario de Azure Portal.
Vaya a la pestaña Administrar del área de trabajo de Azure Data Factory o Synapse y seleccione Servicios vinculados; luego haga clic en Nuevo:
Busque Teradata y seleccione el conector de Teradata.
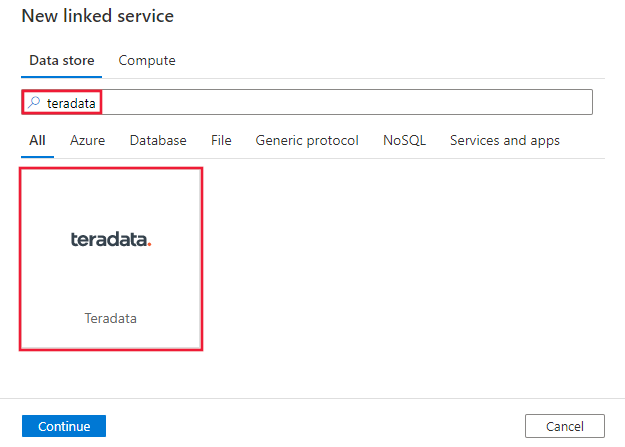
Configure los detalles del servicio, pruebe la conexión y cree el nuevo servicio vinculado.
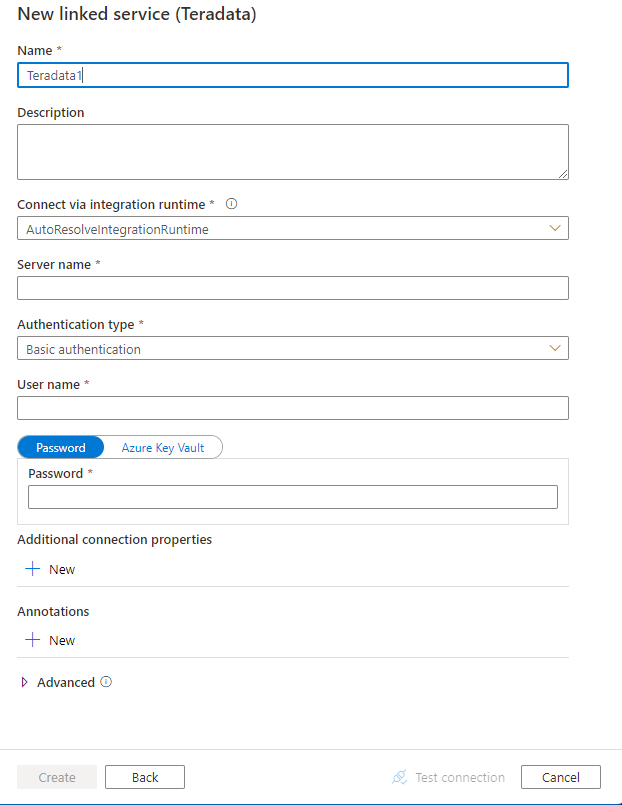
Detalles de configuración del conector
Las secciones siguientes proporcionan detalles sobre las propiedades que se usan para definir entidades de Data Factory específicas del conector de Teradata.
Propiedades del servicio vinculado
Las siguientes propiedades son compatibles con el servicio vinculado Teradata:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type se debe establecer en Teradata. | Sí |
| connectionString | Especifica la información necesaria para conectarse a la instancia de Teradata. Consulte los ejemplos siguientes. También puede poner una contraseña en Azure Key Vault y extraer la configuración de password de la cadena de conexión. Consulte el artículo Almacenamiento de credenciales en Azure Key Vault para obtener información detallada. |
Sí |
| username | Especifique un nombre de usuario para conectarse a Teradata. Se aplica cuando se usa autenticación de Windows. | No |
| password | Especifique la contraseña de la cuenta de usuario que se especificó para el nombre de usuario. También puede hacer referencia a un secreto almacenado en Azure Key Vault. Se aplica al utilizar la autenticación de Windows o hacer referencia a la contraseña en Key Vault para la autenticación básica. |
No |
| connectVia | El entorno Integration Runtime que se usará para conectarse al almacén de datos. Obtenga más información en la sección Requisitos previos. Si no se especifica, se usará Azure Integration Runtime. | No |
Puede establecer más propiedades de conexión en la cadena de conexión, según su caso:
| Propiedad | Descripción | Valor predeterminado |
|---|---|---|
| TdmstPortNumber | Número de puerto usado para acceder a la base de datos de Teradata. No cambie este valor a menos que el equipo de soporte técnico le indique que lo haga. |
1025 |
| UseDataEncryption | Especifica si se va a cifrar toda la comunicación con la base de datos de Teradata. Los valores permitidos son 0 o 1. - 0 (deshabilitado, valor predeterminado) : cifra únicamente la información de autenticación. - 1 (habilitado) : cifra todos los datos que se pasan entre el controlador y la base de datos. |
0 |
| CharacterSet | El juego de caracteres que se va a utilizar para la sesión. Por ejemplo, CharacterSet=UTF16.Este valor puede ser un juego de caracteres definido por el usuario o uno de los siguientes juegos de caracteres predefinidos: - ASCII - UTF8 - UTF16 - LATIN1252_0A - LATIN9_0A - LATIN1_0A - Shift-JIS (Windows, compatible con DOS, KANJISJIS_0S) - EUC (compatible con Unix, KANJIEC_0U) - IBM Mainframe (KANJIEBCDIC5035_0I) - KANJI932_1S0 - BIG5 (TCHBIG5_1R0) - GB (SCHGB2312_1T0) - SCHINESE936_6R0 - TCHINESE950_8R0 - NetworkKorean (HANGULKSC5601_2R4) - HANGUL949_7R0 - ARABIC1256_6A0 - CYRILLIC1251_2A0 - HEBREW1255_5A0 - LATIN1250_1A0 - LATIN1254_7A0 - LATIN1258_8A0 - THAI874_4A0 |
ASCII |
| MaxRespSize | El tamaño máximo del búfer de respuesta para las solicitudes SQL, en kilobytes (KB). Por ejemplo, MaxRespSize=10485760.En Teradata Database versión 16.00 o posterior, el valor máximo es 7361536. En el caso de las conexiones que usan versiones anteriores, el valor máximo es 1048576. |
65536 |
| MechanismName | Para usar el protocolo LDAP para autenticar la conexión, especifique MechanismName=LDAP. |
N/D |
Ejemplo de uso de la autenticación básica
{
"name": "TeradataLinkedService",
"properties": {
"type": "Teradata",
"typeProperties": {
"connectionString": "DBCName=<server>;Uid=<username>;Pwd=<password>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Ejemplo de uso de la autenticación de Windows
{
"name": "TeradataLinkedService",
"properties": {
"type": "Teradata",
"typeProperties": {
"connectionString": "DBCName=<server>",
"username": "<username>",
"password": "<password>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Ejemplo de uso de la autenticación LDAP
{
"name": "TeradataLinkedService",
"properties": {
"type": "Teradata",
"typeProperties": {
"connectionString": "DBCName=<server>;MechanismName=LDAP;Uid=<username>;Pwd=<password>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Nota
Todavía se admite la carga siguiente. En el futuro, sin embargo, debe usar la nueva.
Carga anterior:
{
"name": "TeradataLinkedService",
"properties": {
"type": "Teradata",
"typeProperties": {
"server": "<server>",
"authenticationType": "<Basic/Windows>",
"username": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Propiedades del conjunto de datos
En esta sección se proporciona una lista de las propiedades que admite el conjunto de datos de Teradata. Si desea ver una lista completa de las secciones y propiedades disponibles para definir conjuntos de datos, consulte Conjuntos de datos.
Para copiar datos de Teradata, se admiten las siguientes propiedades:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type del conjunto de datos debe establecerse en TeradataTable. |
Sí |
| database | El nombre de la instancia de Teradata. | No (si se especifica "query" en el origen de la actividad) |
| table | El nombre de la tabla de la instancia de Teradata. | No (si se especifica "query" en el origen de la actividad) |
Ejemplo:
{
"name": "TeradataDataset",
"properties": {
"type": "TeradataTable",
"typeProperties": {},
"schema": [],
"linkedServiceName": {
"referenceName": "<Teradata linked service name>",
"type": "LinkedServiceReference"
}
}
}
Nota
El conjunto de datos del tipo RelationalTable todavía se admite. Sin embargo, se recomienda usar el nuevo.
Carga anterior:
{
"name": "TeradataDataset",
"properties": {
"type": "RelationalTable",
"linkedServiceName": {
"referenceName": "<Teradata linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {}
}
}
Propiedades de la actividad de copia
En esta sección se proporciona una lista de las propiedades que admite el origen de Teradata. Para ver una lista completa de las secciones y propiedades disponibles para definir actividades, consulte Canalizaciones.
Teradata como origen
Sugerencia
Para cargar datos desde Teradata de manera eficaz con la creación de particiones de datos, obtenga más información en la sección Copia en paralelo desde Teradata.
Para copiar datos desde Teradata, en la sección source de la actividad de copia se admiten las siguientes propiedades:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type del origen de la actividad de copia debe establecerse en TeradataSource. |
Sí |
| Query | Use la consulta SQL personalizada para leer los datos. Un ejemplo es "SELECT * FROM MyTable".Si habilita la carga con particiones, deberá enlazar todos los parámetros de partición integrados correspondientes en la consulta. Consulte la sección Copia en paralelo desde Teradata para obtener algunos ejemplos. |
No (si se especifica la tabla en el conjunto de datos) |
| partitionOptions | Especifica las opciones de creación de particiones de datos que se usan para cargar datos desde Teradata. Los valores permitidos son los siguientes: None (valor predeterminado), Hash y DynamicRange. Cuando se habilita una opción de partición (es decir, no None), el grado de paralelismo para cargar simultáneamente datos desde Teradata se controla mediante la configuración parallelCopies en la actividad de copia. |
No |
| partitionSettings | Especifique el grupo de configuración para la creación de particiones de datos. Se aplica cuando la opción de partición no es None. |
No |
| partitionColumnName | Especifique el nombre de la columna de origen que usará la partición por rangos o la partición de hash para la copia en paralelo. Si no se especifica, se detecta automáticamente el índice principal de la tabla y se usa como columna de partición. Se aplica si la opción de partición es Hash o DynamicRange. Si usa una consulta para recuperar datos de origen, enlace ?AdfHashPartitionCondition o ?AdfRangePartitionColumnName en la cláusula WHERE. Consulte un ejemplo en la sección Copia en paralelo desde Teradata. |
No |
| partitionUpperBound | El valor máximo de la columna de partición para copiar datos. Se aplica cuando la opción de partición es DynamicRange. Si usa la consulta para recuperar datos de origen, enlace ?AdfRangePartitionUpbound en la cláusula WHERE. Consulte la sección Copia en paralelo desde Teradata para ver un ejemplo. |
No |
| partitionLowerBound | El valor mínimo de la columna de partición para copiar datos. Se aplica si la opción de partición es DynamicRange. Si usa una consulta para recuperar datos de origen, enlace ?AdfRangePartitionLowbound en la cláusula WHERE. Consulte la sección Copia en paralelo desde Teradata para ver un ejemplo. |
No |
Nota
RelationalSource todavía se admite, pero no es compatible con la nueva carga en paralelo integrada desde Teradata (opciones de partición). Sin embargo, se recomienda usar el nuevo.
Ejemplo: copia de datos mediante una consulta básica sin partición
"activities":[
{
"name": "CopyFromTeradata",
"type": "Copy",
"inputs": [
{
"referenceName": "<Teradata input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "TeradataSource",
"query": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Copia en paralelo desde Teradata
El conector de Teradata proporciona la creación de particiones de datos integrados para copiar datos de Teradata en paralelo. Puede encontrar las opciones de creación de particiones de datos en la pestaña Origen de la actividad de copia.

Al habilitar la copia con particiones, el servicio ejecuta consultas en paralelo en el origen de Teradata para cargar los datos mediante particiones. El grado en paralelo se controla mediante el valor parallelCopies de la actividad de copia. Por ejemplo, si establece parallelCopies en cuatro, el servicio genera y ejecuta al mismo tiempo cuatro consultas de acuerdo con la configuración y la opción de partición que ha especificado, y cada consulta recupera una porción de datos de la Teradata.
Es recomendable que habilite la copia en paralelo con la creación de particiones de datos, especialmente si carga grandes cantidades de datos de Teradata. Estas son algunas configuraciones sugeridas para diferentes escenarios. Cuando se copian datos en un almacén de datos basado en archivos, se recomienda escribirlos en una carpeta como varios archivos (solo especifique el nombre de la carpeta), en cuyo caso el rendimiento es mejor que escribirlos en un único archivo.
| Escenario | Configuración sugerida |
|---|---|
| Carga completa de una tabla grande. | Opción de partición: hash. Durante la ejecución, el servicio detecta automáticamente la columna de índice principal, le aplica un hash y copia los datos mediante particiones. |
| Cargue grandes cantidades de datos mediante una consulta personalizada. | Opción de partición: hash. Consulta: SELECT * FROM <TABLENAME> WHERE ?AdfHashPartitionCondition AND <your_additional_where_clause>.Columna de partición: especifique la columna usada para aplicar la partición hash. Si no se especifica, el servicio detectará automáticamente la columna PK de la tabla que ha especificado en el conjunto de datos de Teradata. Durante la ejecución, el servicio reemplaza ?AdfHashPartitionCondition por la lógica de partición hash y la envía a Teradata. |
| Carga de grandes cantidades de datos mediante una consulta personalizada, con una columna de enteros con valor distribuido uniformemente para la creación de particiones por rangos. | Opciones de partición: partición por rangos dinámica. Consulta: SELECT * FROM <TABLENAME> WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>.Columna de partición: especifique la columna usada para crear la partición de datos. Puede crear particiones en la columna con un tipo de datos entero. Límite de partición superior y límite de partición inferior: especifique si quiere filtrar en la columna de partición para recuperar solo los datos entre el intervalo inferior y el superior. Durante la ejecución, el servicio reemplaza ?AdfRangePartitionColumnName, ?AdfRangePartitionUpbound y ?AdfRangePartitionLowbound por el nombre real de la columna y los rangos de valores de cada partición y se los envía a Teradata. Por ejemplo, si establece la columna de partición "ID" con un límite inferior de 1 y un límite superior de 80, con la copia en paralelo establecida en 4, el servicio recupera los datos de 4 particiones. Los identificadores están comprendidos entre [1, 20], [21, 40], [41, 60] y [61, 80] respectivamente. |
Ejemplo: consulta con partición hash
"source": {
"type": "TeradataSource",
"query": "SELECT * FROM <TABLENAME> WHERE ?AdfHashPartitionCondition AND <your_additional_where_clause>",
"partitionOption": "Hash",
"partitionSettings": {
"partitionColumnName": "<hash_partition_column_name>"
}
}
Ejemplo: consulta con partición por rangos dinámica
"source": {
"type": "TeradataSource",
"query": "SELECT * FROM <TABLENAME> WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<dynamic_range_partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column>",
"partitionLowerBound": "<lower_value_of_partition_column>"
}
}
Asignación de tipos de datos para Teradata
Al copiar datos de Teradata, se aplican las siguientes asignaciones de los tipos de datos de Teradata a los tipos de datos internos utilizados por el servicio. Para más información acerca de la forma en que la actividad de copia asigna el tipo de datos y el esquema de origen al receptor, consulte el artículo sobre asignaciones de tipos de datos y esquema.
| Tipo de datos de Teradata | Tipo de datos de servicio provisional |
|---|---|
| BigInt | Int64 |
| Blob | Byte[] |
| Byte | Byte[] |
| ByteInt | Int16 |
| Char | String |
| Clob | String |
| Date | DateTime |
| Decimal | Decimal |
| Double | Double |
| Graphic | No compatible. Se aplica la conversión explícita en la consulta de origen. |
| Entero | Int32 |
| Interval Day | No compatible. Se aplica la conversión explícita en la consulta de origen. |
| Interval Day To Hour | No compatible. Se aplica la conversión explícita en la consulta de origen. |
| Interval Day To Minute | No compatible. Se aplica la conversión explícita en la consulta de origen. |
| Interval Day To Second | No compatible. Se aplica la conversión explícita en la consulta de origen. |
| Interval Hour | No compatible. Se aplica la conversión explícita en la consulta de origen. |
| Interval Hour To Minute | No compatible. Se aplica la conversión explícita en la consulta de origen. |
| Interval Hour To Second | No compatible. Se aplica la conversión explícita en la consulta de origen. |
| Interval Minute | No compatible. Se aplica la conversión explícita en la consulta de origen. |
| Interval Minute To Second | No compatible. Se aplica la conversión explícita en la consulta de origen. |
| Interval Month | No compatible. Se aplica la conversión explícita en la consulta de origen. |
| Interval Second | No compatible. Se aplica la conversión explícita en la consulta de origen. |
| Interval Year | No compatible. Se aplica la conversión explícita en la consulta de origen. |
| Interval Year To Month | No compatible. Se aplica la conversión explícita en la consulta de origen. |
| Number | Double |
| Period (Date) | No compatible. Se aplica la conversión explícita en la consulta de origen. |
| Period (Time) | No compatible. Se aplica la conversión explícita en la consulta de origen. |
| Period (Time With Time Zone) | No compatible. Se aplica la conversión explícita en la consulta de origen. |
| Period (Timestamp) | No compatible. Se aplica la conversión explícita en la consulta de origen. |
| Period (Timestamp With Time Zone) | No compatible. Se aplica la conversión explícita en la consulta de origen. |
| SmallInt | Int16 |
| Time | TimeSpan |
| Time With Time Zone | TimeSpan |
| Timestamp | DateTime |
| Timestamp With Time Zone | DateTime |
| VarByte | Byte[] |
| VarChar | String |
| VarGraphic | No compatible. Se aplica la conversión explícita en la consulta de origen. |
| Xml | No compatible. Se aplica la conversión explícita en la consulta de origen. |
Propiedades de la actividad de búsqueda
Para obtener información detallada sobre las propiedades, consulte Actividad de búsqueda.
Contenido relacionado
Para obtener una lista de almacenes de datos que la actividad de copia admite como orígenes y receptores, vea Almacenes de datos que se admiten.