Azure Machine Learning como producto de datos para el análisis a escala de la nube
Azure Machine Learning es una plataforma integrada para administrar el ciclo de vida de aprendizaje automático de principio a fin, incluida la ayuda con la creación, la operación y el consumo de modelos y flujos de trabajo de Machine Learning. Entre las ventajas del servicio se incluyen:
Las funcionalidades admiten a los creadores para aumentar su productividad al ayudarles a administrar experimentos, acceder a los datos, realizar un seguimiento de trabajos, ajustar hiperparámetros y automatizar flujos de trabajo.
La capacidad del modelo para ser explicado, reproducido, auditado e integrado con DevOps, junto con un modelo de control de seguridad robusto, puede ayudar a los operadores a satisfacer los requisitos de gobierno y cumplimiento.
Las funcionalidades de inferencia administradas y una sólida integración con los servicios de proceso y datos de Azure pueden ayudar a simplificar cómo se consume el servicio.
Azure Machine Learning cubre todos los aspectos del ciclo de vida de la ciencia de datos. Abarca el almacén de datos y el registro de conjuntos de datos para la implementación del modelo. Se puede usar para cualquier tipo de aprendizaje automático, desde el aprendizaje automático clásico hasta el aprendizaje profundo. Incluye aprendizaje supervisado y no supervisado. Tanto si prefiere escribir Python, código de R como usar opciones de código cero o de poco código, como el diseñador, puede compilar, entrenar y realizar un seguimiento de modelos precisos de aprendizaje automático y aprendizaje profundo en un área de trabajo de Azure Machine Learning.
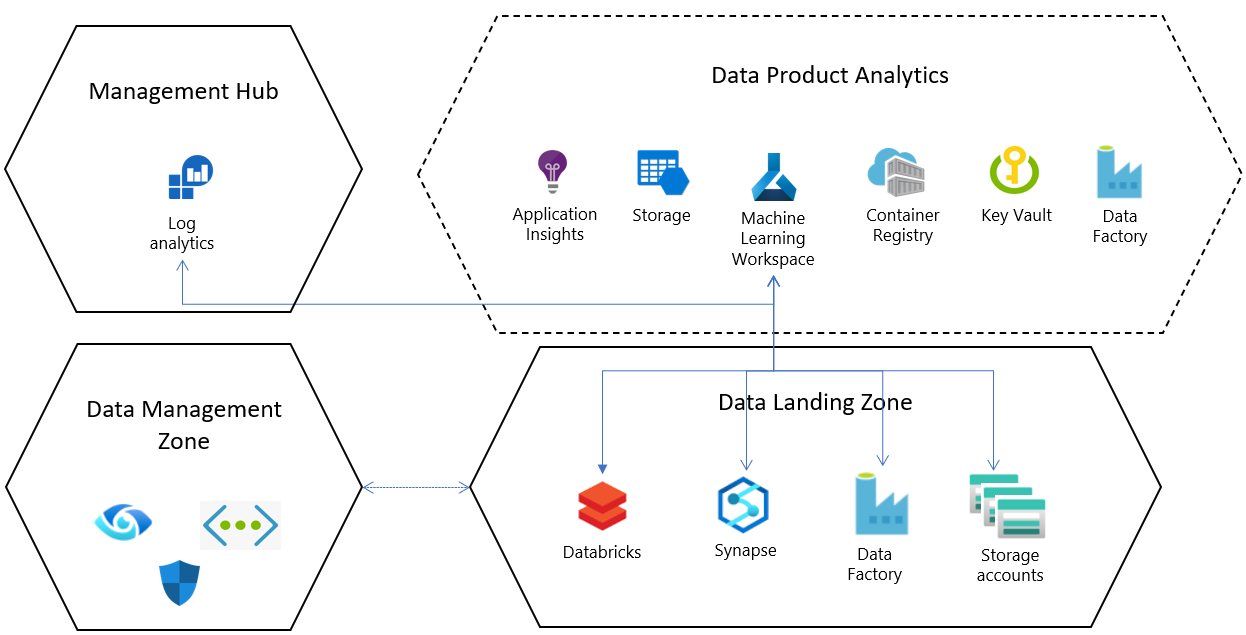
Azure Machine Learning, la plataforma Azure y los servicios de Azure AI pueden trabajar conjuntamente para administrar el ciclo de vida del aprendizaje automático. Un profesional de aprendizaje automático puede usar Azure Synapse Analytics, Azure SQL Database o Microsoft Power BI para empezar a analizar datos y realizar la transición a Azure Machine Learning para crear prototipos, administrar la experimentación y la operacionalización. En las zonas de aterrizaje de Azure, Azure Machine Learning se puede considerar un producto de datos .
Azure Machine Learning en análisis a escala de la nube
Una base de zonas de aterrizaje del Cloud Adoption Framework (CAF), zonas de aterrizaje de datos analíticos a escala de nube y la configuración de Azure Machine Learning ofrecen a los profesionales del aprendizaje automático un entorno preconfigurado en el cual puedan desplegar repetidamente nuevas cargas de trabajo de aprendizaje automático o migrar cargas de trabajo existentes. Estas funcionalidades pueden ayudar a los profesionales de aprendizaje automático a obtener más agilidad y valor para su tiempo.
Los siguientes principios de diseño pueden guiar la implementación de zonas de aterrizaje de Azure Machine Learning:
Acceso a datos acelerado: preconfigure los componentes de almacenamiento de la zona de aterrizaje como almacenes de datos en el área de trabajo de Azure Machine Learning.
Colaboración habilitada: Organizar los espacios de trabajo por proyecto y centralizar la gestión de acceso a los recursos de la zona de habilitación para facilitar la colaboración entre profesionales de la ingeniería de datos, ciencia de datos y aprendizaje automático.
Implementación segura: Como valor predeterminado para cada implementación, siga los procedimientos recomendados y use el aislamiento de red, la identidad y la administración de acceso para proteger los recursos de datos.
Autoservicio: Los profesionales de aprendizaje automático pueden obtener más agilidad y organización al explorar opciones para implementar nuevos recursos de proyecto.
Separación de preocupaciones entre la administración de datos y el consumo de datos: la identidad transferida es el tipo de autenticación predeterminado para Azure Machine Learning y el almacenamiento.
Aplicación de datos más rápida (alineada con el origen): se pueden preconfigurar las zonas de aterrizaje de Azure Data Factory, Azure Synapse Analytics y Databricks para su vinculación a Azure Machine Learning.
Observabilidad: El registro central y las configuraciones de referencia pueden ayudar a supervisar el entorno.
Introducción a la implementación
Nota
En esta sección se recomiendan configuraciones específicas del análisis a escala de la nube. Complementa la documentación de Azure Machine Learning y los procedimientos recomendados de Cloud Adoption Framework.
Organización y configuración del área de trabajo
Puede implementar el número de áreas de trabajo de aprendizaje automático que requieren las cargas de trabajo y para cada zona de aterrizaje que implemente. Las siguientes recomendaciones pueden ayudar a la configuración:
Implemente al menos un área de trabajo de aprendizaje automático por proyecto.
En función del ciclo de vida del proyecto de aprendizaje automático, implemente un área de trabajo de desarrollo (dev) para crear prototipos de casos de uso y explore los datos al principio. Para el trabajo que requiere experimentación continua, pruebas e implementación, implemente un área de trabajo de ensayo y producción.
Cuando se necesitan varios entornos para las áreas de trabajo de desarrollo, almacenamiento provisional y producción en una zona de aterrizaje de datos, se recomienda evitar la duplicación de datos al tener cada entorno en la misma zona de aterrizaje de datos de producción.
Consulte Organizar y configurar entornos de Azure Machine Learning para más información sobre cómo organizar y configurar recursos de Azure Machine Learning.
Para cada configuración de recursos predeterminada en una zona de aterrizaje de datos, un servicio Azure Machine Learning se implementa en un grupo de recursos dedicado con las siguientes configuraciones y recursos dependientes:
- Azure Key Vault
- Application Insights
- Azure Container Registry
- Use Azure Machine Learning para conectarse a una cuenta de Azure Storage y a la autenticación basada en identidad de Microsoft Entra para ayudar a los usuarios a conectarse a la cuenta.
- El registro de diagnóstico se configura para cada área de trabajo y se configura en un recurso central de Log Analytics a escala empresarial; esto puede ayudar a que el estado del trabajo y los estados de recursos de Azure Machine Learning se analicen de forma centralizada dentro y entre zonas de aterrizaje.
- Consulte ¿Qué es un área de trabajo de Azure Machine Learning? para más información sobre los recursos y dependencias de Azure Machine Learning.
Integración con los servicios principales de la zona de aterrizaje de datos
La zona de aterrizaje de datos incluye un conjunto predeterminado de servicios que se implementan en la capa de servicios de plataforma. Estos servicios principales se pueden configurar cuando Azure Machine Learning se implementa en la zona de aterrizaje de datos.
Conecte áreas de trabajo de Azure Synapse Analytics o Databricks como servicios vinculados para integrar datos y procesar macrodatos.
De forma predeterminada, los servicios de Data Lake se aprovisionan en la zona de aterrizaje de datos y las implementaciones de productos de Azure Machine Learning incluyen conexiones (almacenes de datos) que están preconfiguradas en estas cuentas de almacenamiento.
Conectividad de red
Las redes para implementar Azure Machine Learning en zonas de aterrizaje de Azure se configuran con los procedimientos recomendados de seguridad para Azure Machine Learning y los procedimientos recomendados de redes de CAF. Estos procedimientos recomendados incluyen las siguientes configuraciones:
- Azure Machine Learning y los recursos dependientes están configurados para usar puntos de conexión de Private Link.
- Los recursos de proceso administrados solo se implementan con direcciones IP privadas.
- La conectividad de red con el repositorio de imágenes base pública de Azure Machine Learning y los servicios de asociados, como Azure Artifacts, se pueden configurar en un nivel de red.
Administración de identidades y acceso
Tenga en cuenta las siguientes recomendaciones para administrar identidades de usuario y acceso con Azure Machine Learning:
Los almacenes de datos de Azure Machine Learning se pueden configurar para usar la autenticación basada en credenciales o identidades. Al usar el control de acceso y las configuraciones del lago de datos de Azure Data Lake Storage Gen2, configure los almacenes de datos para que usen la autenticación basada en identidades. Esto permite a Azure Machine Learning optimizar los permisos de acceso de usuario para el almacenamiento.
Use grupos de Microsoft Entra para administrar los permisos de usuario para los recursos de almacenamiento y aprendizaje automático.
Azure Machine Learning puede usar identidades administradas asignadas por el usuario para el control de acceso y limitar el intervalo de acceso a Azure Container Registry, Key Vault, Azure Storage y Application Insights.
Cree identidades administradas asignadas por el usuario a clústeres de proceso administrados creados en Azure Machine Learning.
Aprovisionamiento de la infraestructura a través de autoservicio
Se puede habilitar y gobernar el autoservicio con directivas para Azure Machine Learning. En la tabla siguiente se muestra un conjunto de directivas predeterminadas al implementar Azure Machine Learning. Para más información, consulte Definiciones de directivas integradas de Azure Policy para Azure Machine Learning.
| Política | Tipo | Referencia |
|---|---|---|
| Las áreas de trabajo de Azure Machine Learning deben usar Azure Private Link. | Integrada | Ver en el portal de Azure |
| Las áreas de trabajo de Azure Machine Learning deben usar identidades administradas asignadas por el usuario. | Integrada | Ver en Azure Portal |
| [Versión preliminar]: Configure los registros permitidos para los procesos de Azure Machine Learning especificados. | Integrada | Ver en Azure Portal |
| Configure áreas de trabajo de Azure Machine Learning con puntos de conexión privados. | Integrada | Ver en Azure Portal |
| Configure los procesos de aprendizaje automático para deshabilitar los métodos de autenticación locales. | Integrada | Ver en Azure Portal |
| Append-machinelearningcompute-setupscriptscreationscript | Personalizada (zonas de aterrizaje de CAF) | Ver en GitHub |
| Deny-machinelearning-hbiworkspace | Personalizada (zonas de aterrizaje de CAF) | Ver en GitHub |
| Deny-machinelearning-publicaccesswhenbehindvnet | Personalizada (zonas de aterrizaje de CAF) | Ver en GitHub |
| Deny-machinelearning-AKS | Personalizada (zonas de aterrizaje de CAF) | Ver en GitHub |
| Deny-machinelearningcompute-subnetid | Personalizada (zonas de aterrizaje de CAF) | Ver en GitHub |
| Deny-machinelearningcompute-vmsize | Personalizada (zonas de aterrizaje de CAF) | Ver en GitHub |
| Deny-machinelearningcomputecluster-remoteloginportpublicaccess | Personalizada (zonas de aterrizaje de CAF) | Ver en GitHub |
| Deny-machinelearningcomputecluster-scale | Personalizada (zonas de aterrizaje de CAF) | Ver en GitHub |
Recomendaciones para administrar el entorno
Las zonas de aterrizaje de datos de análisis a escala en la nube describen la implementación de referencia para implementaciones repetibles, lo que puede ayudarle a configurar entornos manejables y controlables. Tenga en cuenta las siguientes recomendaciones para usar Azure Machine Learning para administrar su entorno:
Use grupos de Microsoft Entra para administrar el acceso a los recursos de aprendizaje automático.
Publique un tablero de supervisión central para supervisar el estado de la canalización, el uso de cómputo y la gestión de cuotas para el aprendizaje automático.
Si tradicionalmente usa directivas integradas de Azure y necesita cumplir requisitos de cumplimiento adicionales, cree directivas personalizadas de Azure para mejorar la gobernanza y el autoservicio.
Para realizar un seguimiento de los costos de investigación y desarrollo, implemente un área de trabajo de aprendizaje automático en la zona de aterrizaje como recurso compartido durante las primeras fases de exploración del caso de uso.
Importante
Use clústeres de Azure Machine Learning para el entrenamiento de modelos de nivel de producción y Azure Kubernetes Service (AKS) para implementaciones de nivel de producción.
Sugerencia
Use Azure Machine Learning para proyectos de ciencia de datos. Abarca el flujo de trabajo de un extremo a otro con subservicios y características, y permite que el proceso se automatice completamente.
Pasos siguientes
Utiliza la plantilla Data Product Analytics y las instrucciones para implementar Azure Machine Learning, y consulta la documentación y los tutoriales de Azure Machine Learning para comenzar a desarrollar tus soluciones.
Continúe con los cuatro artículos siguientes de Cloud Adoption Framework para obtener más información sobre los procedimientos recomendados de implementación y administración de Azure Machine Learning para empresas:
Organizar y configurar entornos de Azure Machine Learning: al planear una implementación de Azure Machine Learning, ¿cómo afectan las estructuras de equipo, los entornos o la geografía de los recursos cómo se configuran las áreas de trabajo?
Procedimientos recomendados de Azure Machine Learning para la seguridad empresarial: obtenga información sobre cómo proteger el entorno y los recursos con Azure Machine Learning.
Administración de presupuestos, costos y cuota de Azure Machine Learning a escala de la organización: las organizaciones se enfrentan a muchos desafíos de administración y optimización al administrar cargas de trabajo, equipo y costos de proceso de usuario en los que se incurre en Azure Machine Learning.
Guía de Aprendizaje Automático DevOps: Aprendizaje automático DevOps es un cambio organizativo que se basa en una combinación de personas, procesos y tecnología para ofrecer soluciones de aprendizaje automático de forma sólida, escalable, confiable y automatizada. En esta guía se resumen los procedimientos recomendados e información para que las empresas usen Azure Machine Learning para adoptar DevOps de aprendizaje automático.