Operaciones de aprendizaje automático
Las operaciones de aprendizaje automático (también denominadas MLOps) hacen referencia a la aplicación de los principios de DevOps a las aplicaciones basadas en IA. Para implementar operaciones de aprendizaje automático en una organización, deben existir tecnologías, aptitudes y procesos específicos. El objetivo es ofrecer soluciones de aprendizaje automático sólidas, escalables, automatizadas y de confianza.
En este artículo, obtendrá información sobre cómo planificar recursos para admitir operaciones de aprendizaje automático en el nivel de organización. Revise los procedimientos recomendados y las recomendaciones que se basan en el uso de Azure Machine Learning para adoptar operaciones de aprendizaje automático en la empresa.
¿Qué son las operaciones de aprendizaje automático?
Los marcos y algoritmos modernos de aprendizaje automático hacen que sea cada vez más fácil desarrollar modelos que puedan realizar predicciones precisas. Las operaciones de aprendizaje automático son una manera estructurada de incorporar el aprendizaje automático en el desarrollo de aplicaciones en la empresa.
En un escenario de ejemplo, ha creado un modelo de Machine Learning que supera todas sus expectativas de precisión y deja impresionados a sus patrocinadores comerciales. Ahora es el momento de implementar el modelo en producción, pero es posible que esto no sea tan fácil como esperaba. Es probable que la organización tenga que disponer de personas, procesos y tecnologías para poder usar el modelo de Machine Learning en producción.
Con el tiempo, usted o un compañero suyo podría desarrollar un nuevo modelo que funcione mejor que el modelo original. El reemplazo de un modelo de Machine Learning que se usa en producción genera algunas preocupaciones que son importantes para la organización:
- Querrá implementar el nuevo modelo sin interrumpir las operaciones empresariales que se basan en el modelo implementado.
- Con fines normativos, es posible que tenga que explicar las predicciones del modelo o volver a crearlo si se generan predicciones inusuales o sesgadas a partir de los datos del nuevo modelo.
- Los datos que se usan en el modelo y el entrenamiento de aprendizaje automático pueden cambiar con el tiempo. Si se cambian los datos, es posible que tenga que volver a entrenar periódicamente el modelo para mantener la precisión de sus predicciones. Será necesario asignar a una persona o rol la responsabilidad de incorporar los datos, supervisar el rendimiento del modelo, volver a entrenarlo y corregirlo si se produce un error.
Supongamos que tiene una aplicación que entrega las predicciones de un modelo a través de una API REST. Incluso un caso de uso simple como este podría causar problemas en producción. La implementación de una estrategia de operaciones de aprendizaje automático puede ayudarle a abordar los problemas de implementación y a respaldar las operaciones empresariales que dependan de las aplicaciones basadas en IA.
Algunas tareas de operaciones de aprendizaje automático encajan bien en el marco general de DevOps. Entre los ejemplos se incluyen la configuración de pruebas unitarias y pruebas de integración y el seguimiento de los cambios mediante el control de versiones. Otras tareas son más exclusivas de las operaciones de aprendizaje automático y, entre ellas, se pueden incluir las siguientes:
- Habilitación de la experimentación y comparación continuas frente a un modelo de línea base.
- Supervisión de los datos entrantes para detectar desfases de datos.
- Desencadenamiento del reentrenamiento del modelo y configuración de una reversión para la recuperación ante desastres.
- Creación de canalizaciones de datos reutilizables para el entrenamiento y la puntuación.
El objetivo de las operaciones de aprendizaje automático es salvar la distancia entre el desarrollo y la producción, y ofrecer valor a los clientes más rápidamente. Para lograr este objetivo, debe replantearse los procesos tradicionales de desarrollo y producción.
No todos los requisitos de las operaciones de aprendizaje automático de las organizaciones son iguales. La arquitectura de las operaciones de aprendizaje automático de una gran empresa multinacional probablemente no será igual que la infraestructura que establece una pequeña startup. Las organizaciones suelen ser pequeñas en un comienzo y crecen a medida que aumentan su madurez, su catálogo de modelos y su experiencia.
El modelo de madurez de las operaciones de aprendizaje automático puede ayudarle a ver dónde se encuentra su organización en la escala de madurez de las operaciones de aprendizaje automático y ayudarle a planificar el crecimiento futuro.
Comparación entre las operaciones de aprendizaje automático y DevOps
Las operaciones de aprendizaje automático se diferencian de DevOps en varias áreas fundamentales. Las operaciones de aprendizaje automático tienen estas características:
- La exploración precede al desarrollo y las operaciones.
- El ciclo de vida de la ciencia de datos requiere una manera de trabajar adaptable.
- Límites de calidad de los datos y progreso del límite de disponibilidad.
- Se requiere un mayor esfuerzo operativo que en DevOps.
- Los equipos de trabajo requieren especialistas y expertos en la materia.
Si necesita un resumen, consulte los siete principios de las operaciones de aprendizaje automático.
La exploración precede al desarrollo y las operaciones
Los proyectos de ciencia de datos difieren de los proyectos de desarrollo de aplicaciones o de ingeniería de datos. Un proyecto de ciencia de datos puede pasar a producción, pero normalmente hay más pasos involucrados que en una implementación tradicional. Después de un análisis inicial, podría quedar claro que no se puede alcanzar el resultado empresarial con los conjuntos de datos disponibles. Una fase de exploración más detallada suele ser el primer paso de un proyecto de ciencia de datos.
El objetivo de la fase de exploración es definir y refinar el problema. Durante esta fase, los científicos de datos ejecutan análisis exploratorios de datos. Usan estadísticas y visualizaciones para confirmar o descartar las hipótesis de los problemas. Las partes interesadas deben comprender que es posible que el proyecto no avance más allá de esta fase. Al mismo tiempo, es importante que esta fase sea lo más fluida posible para obtener resultados rápidos. A menos que el problema que se deba solucionar incluya un elemento de seguridad, evite restringir la fase exploratoria con procesos y procedimientos. Los científicos de datos deben tener permiso para trabajar con las herramientas y los datos que prefieran. Se necesitan datos reales para este trabajo de exploración.
El proyecto puede pasar a las fases de experimentación y desarrollo cuando las partes interesadas confíen en que el proyecto de ciencia de datos es factible y puede ofrecer valor empresarial real. En esta fase, las prácticas de desarrollo se vuelven cada vez más importantes. Como procedimiento recomendado, capture las métricas de todos los experimentos que se lleven a cabo en esta fase. También es importante incorporar el control de código fuente para que pueda comparar modelos y alternar entre distintas versiones del código.
Entre las actividades de desarrollo se incluyen la refactorización, las pruebas y la automatización del código de exploración en canalizaciones de experimentación repetibles. La organización debe crear aplicaciones y canalizaciones para entregar los modelos. La refactorización del código en bibliotecas y componentes modulares ayuda a aumentar la reutilización, las pruebas y la optimización del rendimiento.
Por último, las canalizaciones de inferencia por lotes o de aplicaciones que entregan los modelos se implementan en entornos de producción o ensayo. Además de supervisar la confiabilidad y el rendimiento de la infraestructura, como en el caso de una aplicación estándar, en la implementación de un modelo de Machine Learning, debe supervisar continuamente la calidad y el perfil de los datos, y el modelo para detectar degradaciones o desfases. Los modelos de Machine Learning también requieren un reentrenamiento con el tiempo para seguir siendo pertinentes en un entorno cambiante.
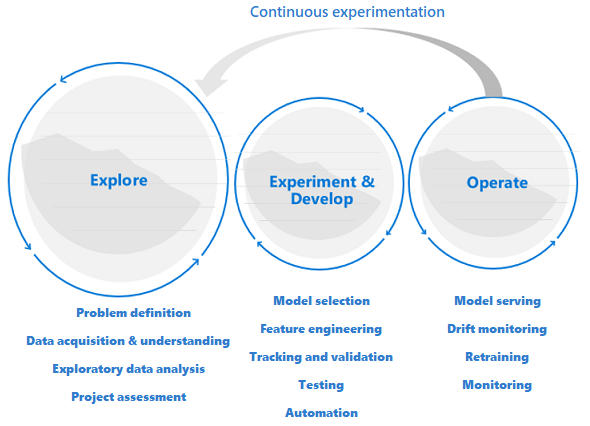
El ciclo de vida de la ciencia de datos requiere una manera de trabajar adaptable
Dado que la naturaleza y la calidad de los datos inicialmente son dudosas, es posible que no logre sus objetivos empresariales si aplica un proceso típico de DevOps a un proyecto de ciencia de datos. La exploración y la experimentación son actividades y necesidades recurrentes a lo largo del proceso de aprendizaje automático. Los equipos de Microsoft usan un ciclo de vida del proyecto y un proceso de trabajo que reflejan la naturaleza de las actividades específicas de la ciencia de datos. El Proceso de ciencia de datos en equipo y el Proceso de ciclo de vida de la ciencia de datos son ejemplos de implementaciones de referencia.
Límites de calidad de los datos y progreso del límite de disponibilidad
Para que un equipo de aprendizaje automático desarrolle de manera eficaz aplicaciones basadas en aprendizaje automático, se prefiere el acceso a los datos de producción para todos los entornos de trabajo pertinentes. Si no es posible acceder a los datos de producción debido a requisitos de cumplimiento o restricciones técnicas, considere la posibilidad de implementar el control de acceso basado en roles de Azure (RBAC de Azure) con Azure Machine Learning, el acceso Just-In-Time o canalizaciones de movimiento de datos para crear réplicas de datos de producción y mejorar la productividad de los usuarios.
El aprendizaje automático requiere un mayor esfuerzo operativo
A diferencia del software tradicional, el rendimiento de una solución de aprendizaje automático corre el riesgo constante de degradación debido a que depende de la calidad de los datos. Para mantener una solución cualitativa en producción, es fundamental supervisar y volver a evaluar continuamente la calidad de los datos y del modelo. Se espera que un modelo de producción requiera el reentrenamiento, la reimplementación y el ajuste oportunos. Estas tareas son adicionales a la seguridad diaria, la supervisión de la infraestructura y los requisitos de cumplimiento, y requieren una experiencia especializada.
Los equipos de aprendizaje automático requieren especialistas y expertos en la materia
Aunque los proyectos de ciencia de datos comparten roles con los proyectos de TI normales, el éxito de un esfuerzo de aprendizaje automático depende en gran medida de la presencia fundamental de especialistas en tecnologías de aprendizaje automático y expertos en la materia. Un especialista en tecnologías tiene la experiencia adecuada para realizar experimentaciones de aprendizaje automático de un extremo a otro. Un experto en la materia puede apoyar al especialista mediante el análisis y la síntesis de los datos o la calificación de los datos para su uso.
Los roles técnicos comunes que son exclusivos de los proyectos de ciencia de datos son los siguientes: experto en la materia, ingeniero de datos, científico de datos, ingeniero de IA, validador de modelos e ingeniero de aprendizaje automático. Para obtener más información sobre los roles y las tareas de un equipo de ciencia de datos típico, consulte el Proceso de ciencia de datos en equipo.
Siete principios de las operaciones de aprendizaje automático
A medida que planifique la adopción de operaciones de aprendizaje automático en su organización, considere la posibilidad de aplicar los siguientes principios básicos como base:
Uso del control de versiones para las salidas de las experimentaciones, los datos y el código. A diferencia del desarrollo de software tradicional, los datos tienen una influencia directa en la calidad de los modelos de Machine Learning. Debe aplicar versiones a la base de código de las experimentaciones, pero aplíquelas también a los conjuntos de datos para asegurarse de poder reproducir los resultados de las inferencias o los experimentos. La aplicación de versiones a las salidas de las experimentaciones, como los modelos, puede ahorrar esfuerzo y el costo de los cálculos de las recreaciones.
Uso de varios entornos. Para separar el desarrollo y las pruebas del trabajo de producción, replique la infraestructura en al menos dos entornos. El control de acceso para los usuarios puede ser diferente para cada entorno.
Administración de la infraestructura y las configuraciones como código. Al crear y actualizar los componentes de la infraestructura en los entornos de trabajo, use la infraestructura como código, de modo que las incoherencias no se desarrollen en los entornos. Administre las especificaciones de los trabajos de experimentación de aprendizaje automático como código, de modo que pueda volver a ejecutar y reutilizar fácilmente una versión del experimento en varios entornos.
Supervisión y administración de los experimentos de aprendizaje automático. Supervise los indicadores clave de rendimiento y otros artefactos de los experimentos de aprendizaje automático. Cuando se mantiene un historial del rendimiento de los trabajos, se puede hacer un análisis cuantitativo del éxito de las experimentaciones y mejorar la agilidad y la colaboración dentro del equipo.
Prueba del código, validación de la integridad de los datos y garantía de la calidad del modelo. Pruebe la base de código de las experimentaciones para comprobar la corrección de la preparación de los datos y las funciones de extracción de características, la integridad de los datos y el rendimiento de los modelos.
Integración y entrega continuas de aprendizaje automático. Use la integración continua (CI) para automatizar las pruebas de su equipo. Incluya el entrenamiento de los modelos como parte de las canalizaciones de entrenamiento continuo. Incluya pruebas A/B como parte de la versión para asegurarse de que solo se usa un modelo cualitativo en producción.
Supervisión de servicios, modelos y datos. Al entregar modelos en un entorno de operaciones de aprendizaje automático, es fundamental supervisar el tiempo de actividad y el cumplimiento de la infraestructura de los servicios, así como la calidad de los modelos. Configure la supervisión para detectar el desfase de los datos y de los modelos y para comprender si es necesario un reentrenamiento. Considere la posibilidad de configurar desencadenadores para el reentrenamiento automático.
Procedimientos recomendados de Azure Machine Learning
Azure Machine Learning ofrece servicios de automatización, orquestación y administración de recursos para ayudarle a administrar el ciclo de vida de los flujos de trabajo de entrenamiento e implementación de modelos de Machine Learning. Revise los procedimientos recomendados y las recomendaciones para aplicar operaciones de aprendizaje automático en las áreas de recursos de personas, procesos y tecnologías que admite Azure Machine Learning.
Personas
Trabaje en equipos de proyectos para usar mejor el conocimiento de especialistas y dominios de su organización. Configure áreas de trabajo de Azure Machine Learning para cada proyecto a fin de cumplir los requisitos de segregación de los casos de uso.
Defina un conjunto de responsabilidades y tareas como un rol para que cualquier miembro de un equipo de proyectos de operaciones de aprendizaje automático pueda asignarse a varios roles y pueda desempeñarlos. Use roles personalizados en Azure para definir un conjunto de operaciones detalladas de RBAC de Azure para Azure Machine Learning que cada rol pueda llevar a cabo.
Estandarice un ciclo de vida para los proyectos y una metodología ágil. El Proceso de ciencia de datos en equipo ofrece una implementación de referencia para el ciclo de vida.
Los equipos equilibrados pueden ejecutar todas las fases de las operaciones de aprendizaje automático, incluida la exploración, el desarrollo y las operaciones.
Proceso
Estandarice una plantilla de código para reutilizar el código y acelerar el tiempo de inicialización de un nuevo proyecto o cuando un nuevo miembro del equipo se una al proyecto. Use canalizaciones de Azure Machine Learning, scripts de envío de trabajos y canalizaciones de CI/CD como base para las nuevas plantillas.
Use el control de versiones. Los trabajos que se envían desde una carpeta con copia de seguridad de Git hacen automáticamente un seguimiento de los metadatos del repositorio con el trabajo en Azure Machine Learning para la reproducibilidad.
Aplique versiones a las entradas y salidas de los experimentos con fines de reproducibilidad. Use conjuntos de datos de Azure Machine Learning y funcionalidades de administración de modelos y administración de entornos para facilitar la aplicación de versiones.
Cree un historial de ejecución del experimento para comparar, planificar y colaborar. Use un marco de seguimiento de experimentos, como MLflow, para recopilar métricas.
Mida y controle de manera continua la calidad del trabajo del equipo a través de la CI en toda la base de código de las experimentaciones.
Finalice de manera anticipada el entrenamiento en el proceso cuando un modelo no converja. Use un marco de seguimiento de experimentos y el historial de ejecución en Azure Machine Learning para supervisar las ejecuciones de los trabajos.
Defina una estrategia de administración de modelos y experimentos. Considere la posibilidad de usar un nombre como champion para hacer referencia al modelo de línea base actual. Un modelo challenger es un modelo candidato que podría ofrecer un mejor rendimiento que el modelo champion en producción. Aplique etiquetas en Azure Machine Learning para marcar los experimentos y los modelos. En un escenario como la previsión de ventas, podría tardarse meses en determinar si las predicciones del modelo son precisas.
Incluya el entrenamiento de los modelos en la compilación a fin de elevar la CI para el entrenamiento continuo. Por ejemplo, comience el entrenamiento de los modelos con el conjunto de datos completo con cada solicitud de incorporación de cambios.
Reduzca el tiempo que se tarda en recibir comentarios acerca de la calidad de la canalización de aprendizaje automático mediante la ejecución de una compilación automatizada en una muestra de los datos. Use parámetros de canalización de Azure Machine Learning para parametrizar los conjuntos de datos de entrada.
Use la implementación continua (CD) en los modelos de Machine Learning para automatizar la implementación y las pruebas de los servicios de puntuación en tiempo real en los entornos de Azure.
En algunos sectores regulados, es posible que se exija completar pasos de validación de modelos para poder usar un modelo de Machine Learning en un entorno de producción. Al automatizar los pasos de validación, se podría acelerar el tiempo de entrega. Cuando los pasos de validación o revisión manual sigan siendo un cuello de botella, analice si puede certificar la canalización automatizada de validación de modelos. Use etiquetas de recursos en Azure Machine Learning para indicar el cumplimiento de los recursos y los candidatos para revisión, o como desencadenadores para la implementación.
No vuelva a entrenar en producción y reemplace directamente el modelo de producción sin hacer pruebas de integración. Aunque el rendimiento de los modelos y los requisitos funcionales puedan parecer adecuados, entre otros posibles problemas, un modelo reentrenado podría tener una superficie mayor de entorno e interrumpir el entorno del servidor.
Cuando el acceso a datos de producción está disponible solo en producción, use RBAC de Azure y roles personalizados para brindar acceso de lectura a un número selecto de profesionales de aprendizaje automático. Es posible que algunos roles necesiten leer los datos para realizar la exploración de datos relacionada. Como alternativa, haga que una copia de los datos esté disponible en los entornos que no son de producción.
Logre un acuerdo en las convenciones de nomenclatura y etiquetas para los experimentos de Azure Machine Learning para diferenciar las canalizaciones de aprendizaje automático de línea base de reentrenamiento del trabajo experimental.
Technology
Si actualmente envía trabajos a través de la UI o la CLI del Estudio de Azure Machine Learning, en lugar de enviar trabajos a través del SDK, use la CLI o tareas de Azure DevOps para Machine Learning para configurar los pasos de la canalización de automatización. Este proceso podría reducir la superficie del código al volver a usar los mismos envíos de trabajos directamente desde las canalizaciones de automatización.
Use una programación basada en eventos. Por ejemplo, desencadene una canalización de pruebas de modelos sin conexión mediante Azure Functions tras el registro de un nuevo modelo. O bien, envíe una notificación a un alias de correo electrónico designado cuando una canalización crítica no se ejecute. Azure Machine Learning crea eventos en Azure Event Grid. Se pueden suscribir varios roles para recibir notificaciones de un evento.
Cuando use Azure DevOps para la automatización, use tareas de Azure DevOps para Machine Learning para usar modelos de Machine Learning como desencadenadores de las canalizaciones.
Cuando desarrolle paquetes de Python para su aplicación de aprendizaje automático, puede hospedarlos en un repositorio de Azure DevOps como artefactos y publicarlos como fuente. Mediante este enfoque, puede integrar el flujo de trabajo de DevOps para compilar paquetes con el área de trabajo de Azure Machine Learning.
Considere la posibilidad de usar un entorno de ensayo para probar la integración del sistema de canalizaciones de aprendizaje automático con componentes de aplicación ascendentes o descendentes.
Cree pruebas unitarias y de integración para los puntos de conexión de inferencia para mejorar la depuración y acelerar el tiempo de implementación.
Para desencadenar el reentrenamiento, use monitores de conjuntos de datos y flujos de trabajo controlados por eventos. Suscríbase a eventos de desfase de datos y automatice el desencadenador de las canalizaciones de aprendizaje automático para volver a entrenarlas.
Fábrica de IA para operaciones de aprendizaje automático de la organización
Un equipo de ciencia de datos podría decidir que puede administrar internamente varios casos de uso de aprendizaje automático. La adopción de operaciones de aprendizaje automático ayuda a una organización a configurar equipos de proyectos para mejorar la calidad, la confiabilidad y el mantenimiento de las soluciones. A través de equipos equilibrados, procesos admitidos y automatización de la tecnología, un equipo que adopte operaciones de aprendizaje automático puede escalar el desarrollo de nuevos casos de uso y centrarse en este proceso.
A medida que crece el número de casos de uso en una organización, la carga de administración de admitir los casos de uso aumenta de manera lineal o incluso más. El desafío de la organización pasa a ser la forma en que acelerar el tiempo de comercialización, respaldar una evaluación más rápida de la viabilidad de los casos de uso, implementar la repetibilidad y usar mejor los recursos y conjuntos de aptitudes disponibles en una variedad de proyectos. Para muchas organizaciones, el desarrollo de una fábrica de IA es la solución.
Una fábrica de IA es un sistema de procesos empresariales repetibles y artefactos estandarizados que facilita el desarrollo y la implementación de un gran conjunto de casos de uso de aprendizaje automático. Una fábrica de IA optimiza la configuración de los equipos, los procedimientos recomendados, la estrategia de las operaciones de aprendizaje automático, los patrones arquitectónicos y las plantillas reutilizables que se adaptan a los requisitos empresariales.
Una fábrica efectiva de IA se basa en procesos repetibles y recursos reutilizables para ayudar a la organización a escalar de forma eficaz de decenas a miles de casos de uso.
En la ilustración siguiente se resumen los elementos clave de una fábrica de IA:

Estandarización según patrones arquitectónicos repetibles
La repetibilidad es una característica fundamental de una fábrica de IA. Los equipos de ciencia de datos pueden acelerar el desarrollo de proyectos y mejorar la coherencia entre proyectos mediante el desarrollo de algunos patrones arquitectónicos repetibles que cubren la mayoría de los casos de uso de aprendizaje automático de su organización. Cuando se ponen en práctica estos patrones, la mayoría de los proyectos pueden usar los patrones para conseguir las siguientes ventajas:
- Fase de diseño acelerado.
- Aprobaciones aceleradas de los equipos de TI y de seguridad cuando reutilizan herramientas entre distintos proyectos.
- Desarrollo acelerado debido a infraestructuras reutilizables como plantillas de código y plantillas de proyecto.
Los patrones arquitectónicos pueden incluir, entre otros, los temas siguientes:
- Servicios preferidos para cada fase del proyecto
- Conectividad y gobernanza de datos
- Una estrategia de las operaciones de aprendizaje automático adaptada a los requisitos del sector, la empresa o la clasificación de datos
- Modelos champion y challenger de administración de experimentos
Facilitación de la colaboración y el intercambio entre equipos
Los repositorios de código y las utilidades compartidos pueden acelerar el desarrollo de soluciones de aprendizaje automático. Los repositorios de código se pueden desarrollar de manera modular durante el desarrollo de los proyectos de modo que sean lo suficientemente genéricos como para que se usen en otros proyectos. Se pueden poner a disposición en un repositorio central al que puedan acceder todos los equipos de ciencia de datos.
Uso compartido y reutilización de la propiedad intelectual
Para maximizar la reutilización del código, revise la siguiente propiedad intelectual al principio de un proyecto:
- Código interno que se diseñase para reutilizarse en la organización. Entre los ejemplos se incluyen paquetes y módulos.
- Conjuntos de datos que se creasen en otros proyectos de aprendizaje automático o que estén disponibles en el ecosistema de Azure.
- Proyectos existentes de ciencia de datos que tengan una arquitectura y problemas empresarial similares.
- Repositorios de GitHub o de código abierto que puedan acelerar el proyecto.
Cualquier retrospectiva del proyecto debe incluir un elemento de acción para determinar si los elementos del proyecto se pueden compartir y generalizar para reutilizarse de forma más amplia. La lista de recursos que la organización puede compartir y reutilizar se amplía con el tiempo.
Para ayudar con el uso compartido y la detección, muchas organizaciones han introducido repositorios compartidos para organizar fragmentos de código y artefactos de aprendizaje automático. Los artefactos en Azure Machine Learning, incluidos los conjuntos de datos, los modelos, los entornos y las canalizaciones, se puede definir como código, lo que hace que se puedan compartir de manera eficaz entre proyectos y áreas de trabajo.
Plantillas de proyecto
Para acelerar el proceso de migración de soluciones existentes y maximizar la reutilización del código, muchas organizaciones estandarizan una plantilla de proyecto para iniciar nuevos proyectos. Algunos ejemplos de plantillas de proyecto recomendadas para usar con Azure Machine Learning son ejemplos de Azure Machine Learning, el Proceso de ciclo de vida de la ciencia de datos y el Proceso de ciencia de datos en equipo.
Administración central de datos
El proceso de obtención de acceso a los datos para la utilización en la exploración o producción puede llevar mucho tiempo. Muchas organizaciones centralizan la administración de datos para reunir a productores y consumidores de datos a fin de facilitarles el acceso a los datos para la experimentación con el aprendizaje automático.
Utilidades compartidas
Su organización puede usar paneles centralizados de toda la empresa para consolidar la información de registro y supervisión. Los paneles pueden incluir el registro de errores, la telemetría y la disponibilidad del servicio, y la supervisión del rendimiento de los modelos.
Use las métricas de Azure Monitor para compilar un panel para Azure Machine Learning y servicios asociados como Azure Storage. Un panel le ayuda a realizar un seguimiento del progreso de las experimentaciones, el estado de la infraestructura de proceso y la utilización de la cuota de GPU.
Equipo especializado en ingeniería de aprendizaje automático
Muchas organizaciones han implementado el rol de ingeniero de aprendizaje automático. Un ingeniero de aprendizaje automático se especializa en la creación y ejecución de canalizaciones sólidas de aprendizaje automático, supervisión de desfases y reentrenamiento de flujos de trabajo, y supervisión de paneles. El ingeniero tiene la responsabilidad general de industrializar la solución de aprendizaje automático, desde el desarrollo hasta la producción. El ingeniero trabaja en estrecha colaboración con los ingenieros de datos, los arquitectos y los equipos de seguridad y operaciones para asegurarse de que se han puesto en marcha todos los controles necesarios.
Aunque la ciencia de datos requiere profundos conocimientos en la materia, la ingeniería de aprendizaje automático es más técnica. La diferencia hace que el ingeniero de aprendizaje automático sea más flexible, de modo que puede trabajar en varios proyectos y con varios departamentos empresariales. Las prácticas de ciencia de datos de gran tamaño pueden beneficiarse de un equipo de ingeniería especializado en aprendizaje automático que impulse la repetibilidad y la reutilización de flujos de trabajo de automatización en varios casos de uso y áreas empresariales.
Habilitación y documentación
Es importante brindar instrucciones claras sobre el proceso de las fábricas de IA a los equipos y usuarios nuevos y existentes. La guía ayuda a garantizar la coherencia y el esfuerzo que se exige al equipo de ingeniería de aprendizaje automático cuando industrializa un proyecto. Considere la posibilidad de diseñar contenido específicamente para los distintos roles dentro de su organización.
Cada cual tiene una forma de aprendizaje propia, por lo que una combinación de los siguientes tipos de guías puede ayudar a acelerar la adopción del marco de las fábricas de IA:
- Un centro con vínculos a todos los artefactos. Por ejemplo, este centro podría ser un canal de Microsoft Teams o un sitio de Microsoft SharePoint.
- Entrenamiento y un plan habilitación diseñado para cada rol.
- Una presentación de resúmenes generales del enfoque y un vídeo complementario.
- Un documento o cuaderno de estrategias detallados.
- Vídeos de procedimientos.
- Evaluaciones de la preparación.
Serie de vídeos de operaciones de aprendizaje automático en Azure
En una serie de vídeos sobre las operaciones de aprendizaje automático en Azure se muestra cómo establecer operaciones de aprendizaje automático para una solución de aprendizaje automático, desde el desarrollo inicial hasta la producción.
Ética
La ética desempeña un papel fundamental en el diseño de una solución de IA. Si no se ponen en práctica principios éticos, los modelos entrenados puede mostrar el mismo sesgo que está presente en los datos con los que se entrenaron. El resultado puede ser que el proyecto se interrumpa. Lo que es más importante es que la reputación de la organización podría estar en riesgo.
Para asegurarse de que los principios éticos clave que la organización defiende se implementen en todos los proyectos, la organización debe proporcionar una lista de estos principios y de las formas de validarlos desde una perspectiva técnica durante la fase de pruebas. Use las características de aprendizaje automático de Azure Machine Learning para comprender de qué se hace responsable el aprendizaje automático y para obtener información sobre cómo realizar la compilación en las operaciones de aprendizaje automático.
Pasos siguientes
Obtenga más información sobre cómo organizar y configurar entornos de Azure Machine Learning o vea una serie de vídeos prácticos sobre las operaciones de aprendizaje automático en Azure.
Obtenga más información sobre cómo administrar presupuestos, cuotas y costos en el nivel de organización mediante Azure Machine Learning: