Guía para la recuperación ante desastres: Azure SQL Managed Instance
Se aplica a: ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Azure SQL Managed Instance proporciona una garantía de alta disponibilidad líder del sector de al menos el 99,99 % para admitir una amplia variedad de aplicaciones, incluidas aplicaciones críticas, que deben estar siempre disponibles. Azure SQL Managed Instance ofrece también la posibilidad de tener capacidades de continuidad empresarial clave con las que puede llevar a cabo una recuperación ante desastres rápida en caso de producirse una interrupción regional. Este artículo contiene información de gran valor que conviene revisar antes de la implementación de una aplicación.
Aunque siempre estamos esforzándonos por proporcionar alta disponibilidad, hay ocasiones en las que el servicio de Azure SQL Managed Instance sufre interrupciones, lo que hace que la base de datos deje de estar disponible y, por tanto, afecta a la aplicación. Cuando la supervisión del servicio detecta problemas que provocan errores de conectividad generalizados, averías o problemas de rendimiento, el servicio declara automáticamente una interrupción para mantener al usuario informado.
Interrupción del servicio
En caso de que se produzca una interrupción del servicio de Azure SQL Managed Instance, encontrara más detalles relacionados con esa interrupción en los siguientes sitios:
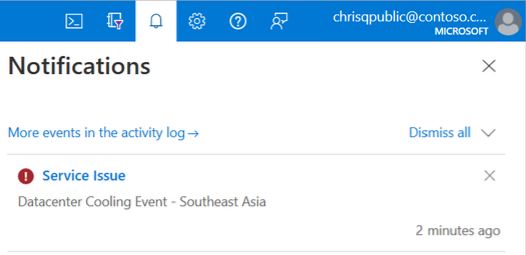
Banner de Azure Portal
Si se detecta que su suscripción está afectada, verá una alerta de interrupción de un problema de servicio en las notificaciones de Azure Portal:
Ayuda y soporte técnico o Soporte y solución de problemas
Al crear una incidencia de soporte técnico en Ayuda y soporte técnico o en Soporte y solución de problemas, verá información sobre los problemas que afectan a los recursos. Seleccione Ver los detalles de la interrupción para obtener más información y un resumen del alcance. También aparece una alerta en la página Nueva solicitud de soporte técnico.
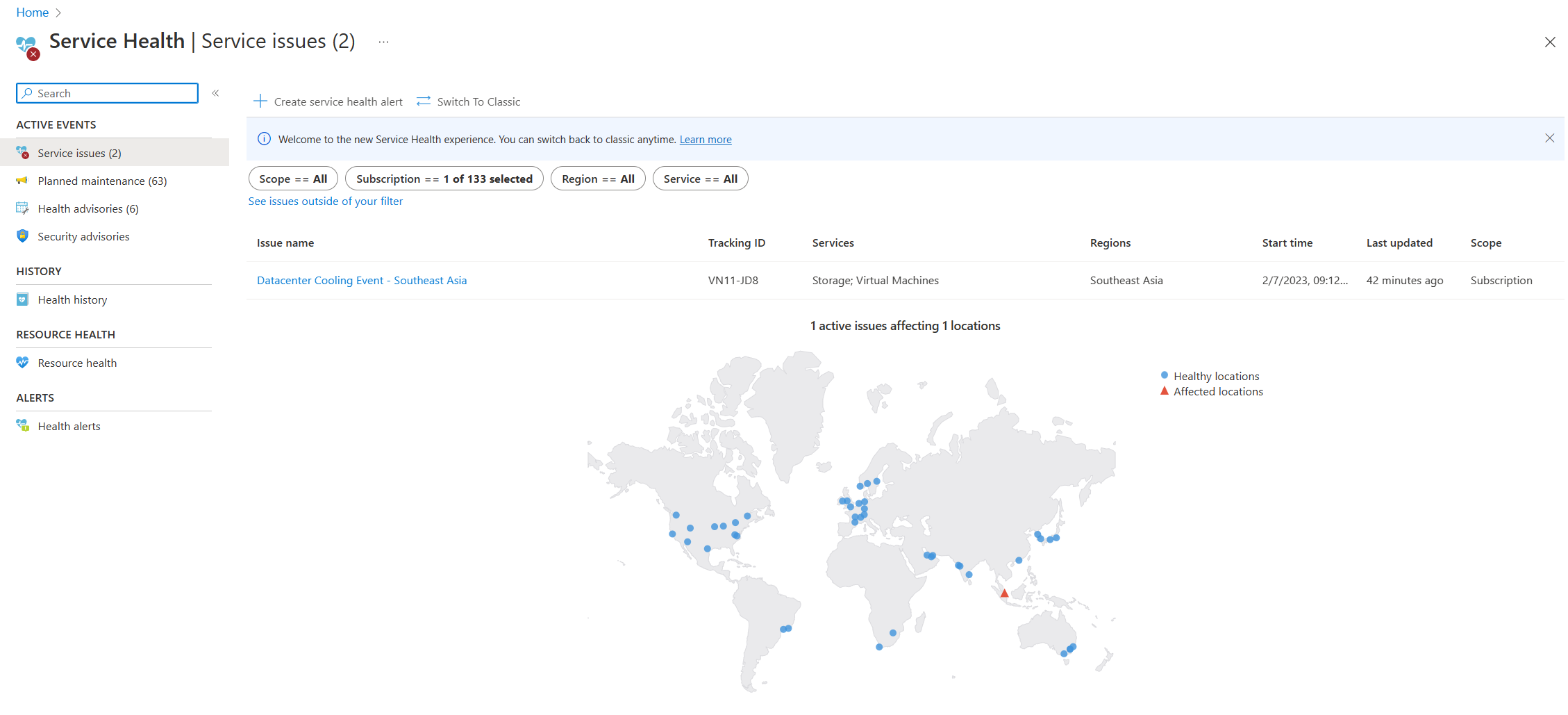
Estado del servicio
La página Estado del servicio de Azure Portal contiene información sobre el estado global del centro de datos de Azure. Busca ‘estado del servicio’ en la barra de búsqueda de Azure Portal y, a continuación, consulta Problemas de servicio en la categoría Eventos activos. También puede ver el estado de un recurso concreto en la página Estado de los recursos del recurso en cuestión, en el menú Ayuda. A continuación se muestra una captura de pantalla de ejemplo de la página Estado del servicio con información sobre un problema de servicio activo en el sudeste asiático:
Notificación de correo electrónico
Si has configurado alertas, recibirás una notificación por correo electrónico de
azure-noreply@microsoft.comcuando una interrupción del servicio afecte a tu suscripción y recurso. El cuerpo del correo electrónico suele comenzar con «La alerta del registro de actividad... se activó por un problema de servicio para la suscripción de Azure...». Para obtener más información sobre las alertas de estado de servicios, vea Recepción de alertas del registro de actividad en notificaciones de servicio de Azure mediante Azure Portal.


Cuándo iniciar la recuperación ante desastres durante una interrupción
En caso de producirse una interrupción del servicio que afecta a los recursos de la aplicación, ten en cuenta las siguientes líneas de acción:
Los equipos de profesionales de Azure trabajan diligentemente para restaurar la disponibilidad del servicio lo antes posible, pero dependiendo de la causa principal, a veces pueden tardar horas. Si la aplicación puede tolerar un tiempo de inactividad considerable, puede esperar hasta que se complete la recuperación. En este caso, no se requieren acciones por su parte. Consulte el estado de un recurso concreto en la página Estado de los recursos del recurso en cuestión, en el menú Ayuda. Consulte la página Estado de los recursos para ver las actualizaciones y la información más reciente sobre una interrupción. Después de la recuperación de la región, se restaura la disponibilidad de la aplicación.
La recuperación en otra región de Azure puede requerir cambiar las cadenas de conexión de la aplicación o usar el redireccionamiento DNS, lo que puede conllevar una pérdida de datos permanente. Por lo tanto, la recuperación ante desastres solo se debe realizar cuando la duración de la interrupción se aproxime al objetivo de tiempo de recuperación (RTO) de la aplicación. Si la aplicación está implementada en producción, se debe realizar una supervisión periódica del estado de la aplicación y confirmar que la recuperación solo se garantiza cuando se produce un error de conectividad prolongado desde el nivel de aplicación a la base de datos. Dependiendo de la tolerancia de la aplicación a los tiempos de inactividad y de la posible responsabilidad comercial, el usuario puede decidir si esperar a que el servicio se recupere o iniciar la recuperación ante desastres por sí mismo.
Guía de recuperación de interrupciones
Considera la posibilidad de realizar los siguientes pasos si la interrupción de Azure SQL Managed Instance en una región no se ha mitigado durante un período de tiempo prolongado y afecta al acuerdo de nivel de servicio (SLA) de la aplicación:
Conmutación por error (sin pérdida de datos) en una instancia secundaria con replicación geográfica
Si los grupos de conmutación por error están habilitados, compruebe que el estado del recurso de las instancia principal y secundaria aparece reflejado como En línea en Azure Portal. Si es así, el plano de datos de las instancias tanto principal como secundaria es correcto.
Inicie una conmutación por error de grupos de conmutación por error en la región secundaria mediante lo siguiente:
Nota:
Una conmutación por error requiere una sincronización de datos completa antes de intercambiar los roles y no produce pérdida de datos. Dependiendo del tipo de interrupción del servicio, no hay ninguna garantía de que la conmutación por error sin pérdida de datos se complete correctamente, pero merece la pena probar como la primera opción de recuperación.
Conmutación por error forzada (posible pérdida de datos) en una instancia secundaria con replicación geográfica
Si la conmutación por error no se completa correctamente y surgen errores, o si el estado de la base de datos principal no es En línea, sopese detenidamente la posibilidad de realizar una conmutación por error forzada, con una posible pérdida de datos en la región secundaria.
Para iniciar una conmutación por error forzada, use lo siguiente:
- Azure Portal, pero elija una Conmutación por error forzada.
- PowerShell, pero use
--allow-data-loss. - CLI de Azure, pero use
-AllowDataLoss.
Geo-restore
Si no se han habilitado los grupos de conmutación por error, puede usar como último recurso la restauración geográfica para recuperarse de una interrupción. La restauración geográfica usa copias de seguridad con replicación geográfica como origen. Se puede restaurar una base de datos situada en cualquier instancia en cualquier región de Azure desde las copias de seguridad con replicación geográfica más recientes. Puede solicitar una restauración geográfica, incluso si la instancia o toda la región está inaccesible debido a una interrupción.
Para obtener más información sobre las restauraciones geográficas mediante la CLI de Azure, Azure Portal, PowerShell o la API REST, vea Restauración geográfica.
Configuración de la base de datos después de realizar la recuperación
Si se usa la conmutación por error o restauración geográficas para recuperarse tras una interrupción, hay que asegurarse de que la conectividad con la nueva instancia está configurada correctamente para que se pueda reanudar el funcionamiento normal de la aplicación. Esta es una lista de comprobación de las tareas necesarias para que la producción de la base de datos recuperada esté lista.
Importante
Se recomienda realizar simulacros periódicos de la estrategia de recuperación ante desastres para comprobar la tolerancia de la aplicación, así como todos los aspectos operativos del procedimiento de recuperación. Es posible que las demás capas de la infraestructura de la aplicación deban reconfigurarse. Para obtener más información sobre los pasos para conseguir una arquitectura resistente, revise la Lista de comprobación de alta disponibilidad y recuperación ante desastres.
Actualización de cadenas de conexión
- Si se usa la restauración geográfica, hay que asegurarse de que la conectividad con la instancia nueva está configurada correctamente para que se pueda reanudar el funcionamiento normal de la aplicación. Dado que la base de datos recuperada reside en otra instancia, es preciso que actualice la cadena de conexión de la aplicación para que apunte a ese servidor. Para obtener más información sobre cómo cambiar las cadenas de conexión, consulte el lenguaje de desarrollo adecuado para la biblioteca de conexiones.
- Si se usan grupos de conmutación por error para recuperarse de una interrupción y se emplean agentes de escucha de solo lectura y solo escritura en las cadenas de conexión de la aplicación, no será necesaria ninguna acción más, ya que las conexiones se dirigirán automáticamente a la nueva base de datos principal.
Configurar reglas de firewall
Asegúrese de que las reglas de NSG y de tabla de rutas configuradas para la instancia secundaria coinciden con las configuradas en la instancia principal. Para obtener más información, revise la configuración de subred asistida por servicio.
Configuración de inicios de sesión de y de usuarios de la base de datos
Cree los inicios de sesión que deben estar presentes en la base de datos master de la instancia secundaria y asegúrese de que estos tienen los permisos adecuados en la base de datos master, si procede.
Configuración de alertas de telemetría
Asegúrese de que la configuración de la regla de alerta existente se actualiza para asignarla a la nueva instancia principal. Para obtener más información sobre las reglas de alerta de las bases de datos, consulte Recibir notificaciones de alerta y Realización de seguimiento del estado.
Habilitar auditoría
Si tiene la auditoría configurada en la instancia principal, haga que sea idéntica en la secundaria. Para obtener más información, vea Auditoría de Azure SQL para Azure SQL Managed Instance.
Contenido relacionado
Para obtener más información, revise:
- Escenarios de continuidad.
- Copias de seguridad automatizadas
- Restauración de una base de datos a partir de las copias de seguridad iniciadas por el servicio.
- Grupos de migración tras error.
- Guía de recuperación ante desastres
- Lista de comprobación de alta disponibilidad y recuperación ante desastres.
- Bases de datos con redundancia de zona