Coordine un conjunto de acciones distribuidas como una única operación. Si se produce un error en cualquiera de las acciones, intente controlar de forma transparente los errores o deshaga el trabajo realizado para que la operación se realice o produzca un error de mantera integral. De este modo se agrega resistencia al sistema distribuido y se permite que se recupere y que repita las acciones que produjeron errores duraderos, de proceso o a causa de excepciones transitorias.
Contexto y problema
Una aplicación realiza tareas con una serie de pasos, algunos de los cuales podrían invocar servicios remotos o acceder a recursos remotos. Los pasos individuales podrían ser independientes entre sí, pero están organizados por la lógica de la aplicación que implementa la tarea.
Siempre que sea posible, la aplicación debe asegurarse de que la tarea se ejecuta por completo y resuelve los errores que puedan producirse al acceder a servicios o recursos remotos. Pueden producirse errores por diversos motivos. Por ejemplo, la red podría estar inactiva o las comunicaciones, interrumpidas; un servicio remoto podría no responder o encontrarse en estado inestable; o un recurso remoto podría estar inaccesible temporalmente, quizás por restricciones. En muchos casos, los errores serán transitorios y se podrán controlar mediante el patrón Retry.
Si la aplicación detecta un error más permanente o que no se puede recuperar fácilmente, debe ser capaz de restaurar el sistema a un estado coherente y garantizar la integridad de toda la operación.
Solución
El patrón Scheduler Agent Supervisor define los actores siguientes. Estos actores orquestan los pasos necesarios que se deben incluir como parte de la tarea global.
El componente Scheduler organiza la ejecución de los pasos que forman la tarea y orquesta su funcionamiento. Estos pasos se pueden combinar en una canalización o un flujo de trabajo. El componente Scheduler es responsable de garantizar que se realicen los pasos de este flujo de trabajo en el orden correcto. A medida que se realiza cada paso, Scheduler registra el estado del flujo de trabajo, como "paso aún no iniciado", "paso en ejecución" o "paso completado". La información de estado también debe incluir un límite máximo del tiempo permitido para completar el paso, denominado tiempo de vigencia. Si un paso requiere acceso a un recurso o servicio remoto, el componente Scheduler invoca al componente Agent adecuado y le pasa los detalles del trabajo que se debe realizar. Normalmente, el componente Scheduler se comunica con un componente Agent a través de la mensajería de solicitud/respuesta asincrónica. Esto se puede implementar mediante colas, aunque también se pueden usar otras tecnologías de mensajería distribuidas.
El componente Scheduler realiza una función similar a la de Process Manager del patrón Process Manager. El flujo de trabajo real normalmente lo define e implementa un motor de flujo de trabajo que el componente Scheduler controla. Este enfoque separa la lógica de negocios del flujo de trabajo del componente Scheduler.
El componente Agent contienen lógica que encapsula una llamada a un servicio remoto o acceso a un recurso remoto a los cuales hace referencia un paso de una tarea. Normalmente, cada componente Agent encapsula las llamadas a un único servicio o recurso, al implementar el control de errores y la lógica de reintento adecuados (de acuerdo con una restricción de tiempo de espera, que se describe más adelante). Al implementar la lógica de reintento, pase un identificador estable entre todos los reintentos para que el servicio remoto pueda usarlo en cualquier lógica de desduplicación que pueda tener. Si los pasos del flujo de trabajo que ejecuta el componente Scheduler utilizan varios servicios y recursos en pasos diferentes, cada paso puede hacer referencia a una instancia de Agent diferente (es un detalle de implementación del patrón).
Supervisor supervisa el estado de los pasos de la tarea que realiza el componente Scheduler. Se ejecuta periódicamente (la frecuencia será específica del sistema) y examina el estado de pasos que mantiene Scheduler. Si detecta alguno con tiempo de espera agotado o error, organiza la instancia de Agent adecuada para recuperar el paso o ejecutar la acción correctiva correspondiente (esto puede implicar modificar el estado de un paso). Tenga en cuenta que la recuperación o las acciones correctivas las implementan el componente Scheduler y el componente Agent. El componente Supervisor solo tiene que solicitar que estas acciones se realicen.
Scheduler, Agent y Supervisor son componentes lógicos y su implementación física depende de la tecnología utilizada. Por ejemplo, se pueden implementar varios agentes lógicos como parte de un servicio web.
El componente Scheduler conserva la información sobre el progreso de la tarea y el estado de cada paso en un almacén de datos durable que se conoce como el almacén de estado. El componente Supervisor puede utilizar esta información para ayudar a determinar si se produjo un error en un paso. En la ilustración se muestra la relación entre el componente Scheduler, los componentes Agent, el componente Supervisor y el almacén de estado.
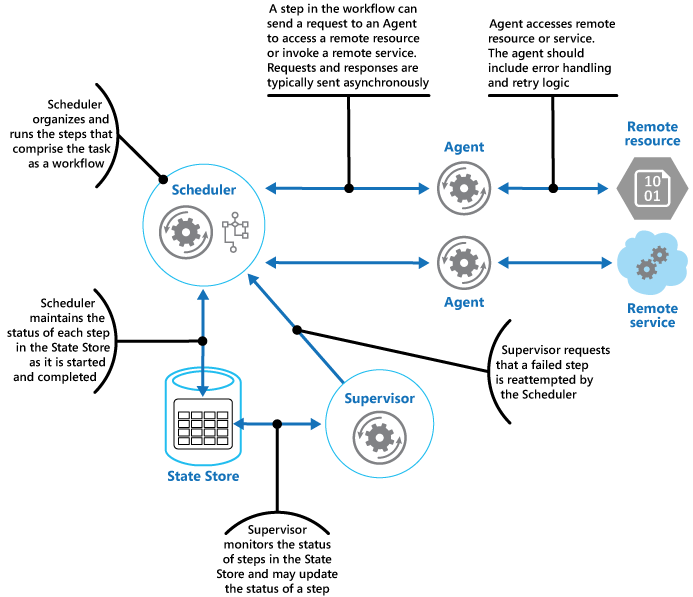
Nota
En este diagrama se muestra una versión simplificada del patrón. En una implementación real, puede haber varias instancias del componente Scheduler que ejecuten un subconjunto de tareas distinto cada una al mismo tiempo. De igual forma, el sistema puede ejecutar varias instancias de cada instancia del componente Agent, o incluso varias instancias del componente Supervisor. En este caso, las instancias de Supervisor deben coordinar su trabajo entre sí con atención para garantizar que no compiten por recuperar las mismas tareas y pasos con error. El patrón Leader Election proporciona una posible solución a este problema.
Cuando la aplicación está preparada ejecutar una tarea, envía una solicitud al componente Scheduler. El componente Scheduler registra la información de estado de la tarea y sus pasos (por ejemplo, paso aún no iniciado) en el almacén de estado e inicia las operaciones que se definieron en el flujo de trabajo. Al iniciar cada paso, el componente Scheduler actualiza la información de estado del paso en el almacén de estado (por ejemplo, paso en ejecución).
Si un paso hace referencia a un servicio o recurso remoto, el componente Scheduler envía un mensaje al componente Agent adecuado. El mensaje contiene la información que el componente Agent necesita para pasarla al servicio o acceder al recurso, además del tiempo de vigencia de la operación. Si el componente Agent completa la operación correctamente, devuelve una respuesta al componente Scheduler. Entonces, el componente Scheduler actualiza la información de estado en el almacén de estado (por ejemplo, paso completado) y realiza el paso siguiente. Este proceso continúa hasta que la tarea se haya completado.
El componente Agent puede implementar cualquier lógica de reintento necesaria para realizar su trabajo. Sin embargo, si el componente Agent no completa su trabajo antes de que expire el tiempo de vigencia, el componente Scheduler presupone que se ha producido un error en la operación. En este caso, el componente Agent debe detener su trabajo y no intentar devolver nada a Scheduler (ni siquiera un mensaje de error), ni tampoco intentar cualquier forma de recuperación. La razón de esta restricción es que, cuando se agota el tiempo de espera de un paso o este último produce un error, otra instancia de Agent puede programarse para ejecutar el paso con error (este proceso se describe después).
Si se produce un error en la instancia del componente Agent, el componente Scheduler no recibirá respuesta. El patrón no distingue entre un paso cuyo tiempo de espera se haya agotado y otro que haya producido un error real.
Si se agota el tiempo de espera de un paso o este produce un error, el almacén de estado contendrá un registro que indique que el paso está en ejecución, pero que su tiempo de vigencia ha expirado. Supervisor busca este tipo de pasos y los intenta recuperar. Una posible estrategia es que el componente Supervisor actualice el valor de vigencia para aumentar el tiempo disponible para completar el paso y que envíe un mensaje al componente Scheduler con la identificación del paso cuyo tiempo de espera se ha agotado. Entonces, el componente Scheduler intentará repetir el paso. Sin embargo, este diseño requiere que las tareas sean idempotentes. El sistema debe contener infraestructura para mantener la coherencia. Para obtener más información, consulte Infraestructura repetible, Diseño de aplicaciones de Azure para lograr resistencia y disponibilidad y Guía de decisiones de la coherencia de recursos.
Puede que el componente Supervisor necesite impedir que se intente realizar el mismo paso, en caso de que produzca errores o su tiempo de espera se agote continuamente. Para ello, el componente Supervisor puede conservar un recuento de reintentos de los pasos junto con la información de estado en el almacén de estado. Si este número supera un umbral predefinido, el componente Supervisor adopta una estrategia de espera durante un tiempo prolongado antes de notificar al componente Scheduler que debe reintentar el paso, con la expectativa de que el error se resuelva durante este tiempo. Como alternativa, el componente Supervisor puede enviar un mensaje al componente Scheduler para solicitar que se deshaga toda la tarea mediante la implementación de un patrón Compensating Transaction. Este enfoque dependerá de que el componente Scheduler y las instancias del componente Agent proporcionen la información necesaria para implementar las operaciones de compensación para cada paso que se completara correctamente.
El componente Supervisor no está diseñado para supervisar el componente Scheduler y las instancias del componente Agent y reiniciarlos si se produce un error. Este aspecto del sistema debe controlarse desde la infraestructura donde se ejecutan estos componentes. De forma similar, el componente Supervisor no debería conocer las operaciones empresariales reales que ejecutan las tareas del componente Scheduler (incluida la compensación en caso de error en estas tareas). De esto se ocupa la lógica del flujo de trabajo que implementó el componente Scheduler. La única responsabilidad del componente Supervisor consiste en determinar si se ha producido un error en un paso y organizarlo para que se repita o para que la tarea que contenga el paso con error se deshaga.
Si el componente Scheduler se reinicia tras un error o si su flujo de trabajo en ejecución finaliza inesperadamente, el componente Scheduler debe ser capaz de determinar el estado de las tareas en proceso que estaba controlando cuando se produjo el error y estar preparado para reanudarlas desde ese punto. Los detalles de la implementación de este proceso suelen ser específicos del sistema. Si no se puede recuperar la tarea, podría ser necesario deshacer el trabajo que la tarea ya haya realizado. También podría ser necesario implementar un patrón Compensating Transaction.
La principal ventaja de este patrón es que el sistema es resistente a errores temporales inesperados o irrecuperables. El sistema puede construirse para que sea de recuperación automática. Por ejemplo, si se produce un error en una instancia de Agent o Scheduler, se puede iniciar otra y Supervisor puede organizar la reanudación de una tarea. Si se produce un error en la instancia de Supervisor, otra puede iniciarse y retomarlo desde ese punto. Si la instancia de Supervisor está programada para ejecutarse periódicamente, se puede iniciar automáticamente una nueva después de un intervalo predefinido. El almacén de estado se puede replicar hasta alcanzar un mayor grado de resistencia.
Problemas y consideraciones
A la hora de decidir cómo implementar este patrón, debe considerar los siguientes puntos:
Este patrón puede ser difícil de implementar y requiere una comprobación exhaustiva de los posibles modos de error del sistema.
La lógica de recuperación/reintento implementada por Scheduler es compleja y depende de la información de estado que se conserva en el almacén de estado. También podría ser necesario registrar la información de implementación de una transacción de compensación en un almacén de datos durables. También se puede producir un error en una transacción compensatoria.
La frecuencia de ejecución de Supervisor es importante. Debe ejecutarse con la frecuencia suficiente como para evitar que los pasos con error bloqueen una aplicación durante mucho tiempo, pero no demasiada como para sobrecargar.
Los pasos que realiza una instancia de Agent pueden ejecutarse más de una vez. La lógica que implementa estos pasos debe ser idempotente.
Cuándo usar este patrón
Utilice este patrón cuando un proceso que se ejecuta en un entorno distribuido, como la nube, debe ser resistente a los errores de comunicación u operativos.
Este patrón puede no ser adecuado para las tareas que no invocan servicios remotos o acceden a recursos remotos.
Diseño de cargas de trabajo
Un arquitecto debe evaluar cómo se puede usar el patrón Scheduler Agent Supervisor en el diseño de su carga de trabajo para abordar los objetivos y principios descritos en los pilares del Marco de buena arquitectura de Azure. Por ejemplo:
| Fundamento | Cómo apoya este patrón los objetivos de los pilares |
|---|---|
| Las decisiones de diseño de la fiabilidad ayudan a que la carga de trabajo sea resistente a los errores y a garantizar que se recupere a un estado de pleno funcionamiento después de que se produzca un error. | Este patrón utiliza métricas de estado para detectar fallos y redirigir las tareas a un agente correcto con el fin de mitigar los efectos de un mal funcionamiento. - RE:05 Redundancia - RE:07 Recuperación automática |
| La eficiencia del rendimiento ayuda a que la carga de trabajo satisfaga eficazmente las demandas mediante optimizaciones en el escalado, los datos y el código. | Este patrón utiliza métricas de rendimiento y capacidad para detectar la utilización actual y enrutar las tareas a un agente que tenga capacidad. También puede utilizarlo para priorizar la ejecución del trabajo de mayor prioridad sobre el de menor prioridad. - PE:05 Escapado y particiones - PE:09 Flujos críticos |
Al igual que con cualquier decisión de diseño, hay que tener en cuenta las ventajas y desventajas con respecto a los objetivos de los otros pilares que podrían introducirse con este patrón.
Ejemplo
Una aplicación web que implementa un sistema de comercio electrónico se ha implementado en Microsoft Azure. Los usuarios pueden ejecutar esta aplicación para examinar los productos disponibles y realizar pedidos. La interfaz de usuario se ejecuta como un rol web y los elementos de procesamiento de pedidos de la aplicación se implementan como conjunto de roles de trabajo. Parte de la lógica de procesamiento de pedidos implica el acceso a un servicio remoto y este aspecto del sistema podría ser propenso a errores transitorios o más duraderos. Por este motivo, los diseñadores utilizaron el patrón Scheduler Agent Supervisor para implementar los elementos de procesamiento de pedidos del sistema.
Cuando un cliente realiza un pedido, la aplicación construye un mensaje que lo describe y envía este mensaje a una cola. Un proceso de envío independiente, que se ejecuta en un rol de trabajo, recupera el mensaje, inserta los detalles del pedido en la base de datos de pedidos y crea un registro para el proceso de pedido en el almacén de estado. Tenga en cuenta que las inserciones en la base de datos de pedidos y el almacén de estado se realizan como parte de la misma operación. El proceso de envío está diseñado para garantizar que ambas inserciones se realizan juntas.
La información de estado que crea el proceso de envío para el pedido incluye:
OrderID. Identificador del pedido en la base de datos de pedidos.
LockedBy. Identificador de la instancia del rol de trabajo que controla el pedido. Puede haber varias instancias actuales del rol de trabajo que ejecuten la instancia de Scheduler, pero solo una controla el pedido.
CompleteBy. Tiempo en el que se debe procesar el pedido.
ProcessState. Estado actual de la tarea de control del pedido. Los estados posibles son:
- Pendiente. El pedido se ha creado, pero aún no se ha iniciado el procesamiento.
- Processing. El pedido se está procesando en este momento.
- Processed. El pedido se ha procesado correctamente.
- Error. Se ha producido un error en el procesamiento del pedido.
FailureCount. Número de veces que se ha intentado procesar el pedido.
En esta información de estado, el campo OrderID se copia desde el identificador de pedido del pedido nuevo. Los campos LockedBy y CompleteBy están establecidos en null, el campo ProcessState, en Pending y el campo FailureCount, en 0.
Nota
En este ejemplo, la lógica de control de pedidos es relativamente sencilla y solo tiene un único paso que invoca un servicio remoto. En un escenario más complejo de varios pasos, el proceso de envío probablemente implicaría varios pasos, por lo que se crearían varios registros en el almacén de estado, donde cada uno describirá el estado de un paso individual.
Scheduler también se ejecuta como parte de un rol de trabajo e implementa la lógica de negocios que controla el pedido. Una instancia de Scheduler que sondea nuevos pedidos examina el almacén de estado en busca de los registros donde el valor del campo LockedBy sea Null, mientras que el del campo ProcessState sea Pending. Cuando Scheduler encuentra un nuevo pedido, inmediatamente rellena el campo LockedBy con su propio identificador de instancia, establece el campo CompleteBy en la hora adecuada y el campo ProcessState en Processing. El código está diseñado como exclusivo y atómico para garantizar que dos instancias simultáneas de Scheduler no pueden controlar el mismo pedido a la vez.
A continuación, Scheduler ejecuta el flujo de trabajo empresarial para procesar el pedido de forma asincrónica, al pasar el valor del campo OrderID del almacén de estado. El flujo de trabajo que controla el pedido recupera los detalles de este de la base de datos de pedidos y realiza su trabajo. Cuando un paso del flujo de trabajo de procesamiento del pedido necesita invocar el servicio remoto, utiliza una instancia de Agent. El paso del flujo de trabajo se comunica con Agent mediante un par de colas de mensajes de Azure Service Bus que actúan como canal de solicitud/respuesta. En la ilustración se muestra una vista general de la solución.
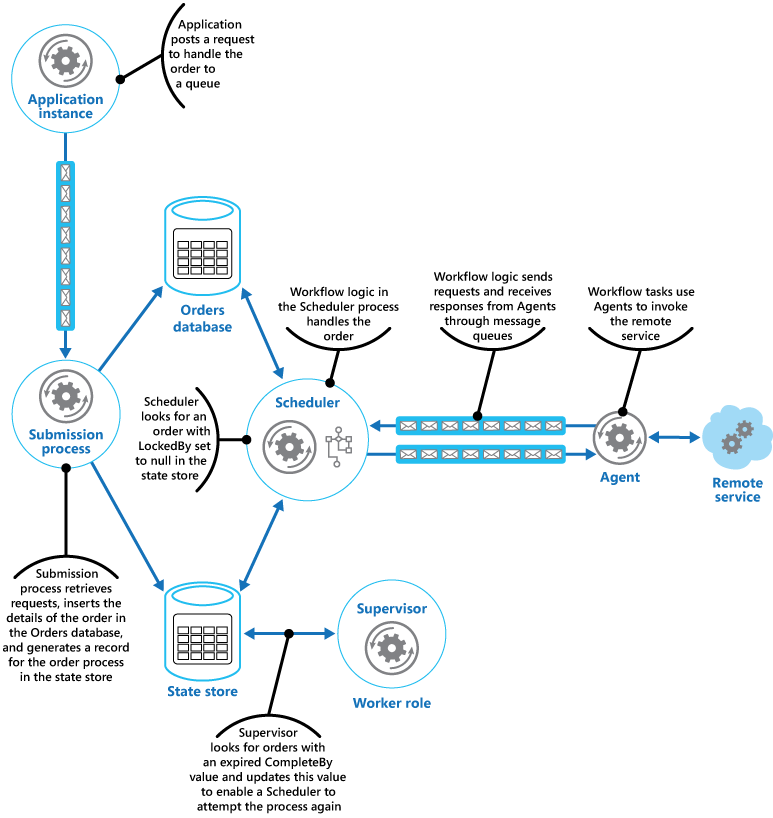
El mensaje enviado a la instancia de Agent desde un paso del flujo de trabajo describe el pedido e incluye el tiempo de vigencia. Si Agent recibe respuesta desde el servicio remoto antes de que expire el tiempo de vigencia, envía un mensaje de respuesta a la cola de Service Bus donde escucha el flujo de trabajo. Cuando el paso del flujo de trabajo recibe el mensaje de respuesta válido, completa el procesamiento y Scheduler establece el campo ProcessState del estado de pedido en "Processed". En este momento, el procesamiento del pedido se ha completado correctamente.
Si el tiempo de vigencia expira antes de que Agent reciba respuesta del servicio remoto, la instancia simplemente detiene el procesamiento y deja de controlar el pedido. De forma similar, si el flujo de trabajo que controla el pedido supera el tiempo de vigencia, también termina. En ambos casos, el estado del pedido en el almacén de estado sigue como Processing, pero el tiempo de vigencia indica que ha transcurrido el tiempo de procesamiento del pedido y se considera que se ha producido un error. Tenga en cuenta que si la instancia de Agent que accede al servicio remoto o el flujo de trabajo que controla el pedido finalizan inesperadamente, la información del almacén de estado permanecerá como Processing y finalmente tendrá un valor de tiempo de vigencia expirado.
Si Agent detecta un error irrecuperable y permanente al intentar ponerse en contacto con el servicio remoto, puede enviar una respuesta de error al flujo de trabajo. Scheduler puede establecer el estado del pedido en Error y generar un evento que avise a un operador. Entonces, el operador puede intentar resolver manualmente la causa del error y volver a enviar el paso de procesamiento con error.
Supervisor examina periódicamente el almacén de estado en busca de pedidos con valor de tiempo de vigencia expirado. Si encuentra un registro, incrementa el campo FailureCount. Si el valor de FailureCount está por debajo de un umbral determinado, Supervisor restablece el campo LockedBy en Null, actualiza el campo CompleteBy con un nuevo tiempo de vigencia y establece el campo ProcessState en Pending. Una instancia de Scheduler puede recoger este pedido y procesarlo como antes. Si el valor de FailureCount supera un umbral determinado, se presupone que el error no es transitorio. Supervisor establece el estado del pedido en Error y genera un evento que avisa a un operador.
En este ejemplo, la instancia de Supervisor se implementa en un rol de trabajo independiente. Puede usar una variedad de estrategias para organizar la ejecución de la tarea de Supervisor, como el servicio Azure Scheduler (que no debe confundirse con el componente Scheduler de este patrón). Para obtener más información sobre el servicio Azure Scheduler, visite la página de Scheduler.
Aunque no se muestra en este ejemplo, Scheduler puede necesitar mantener informada a la aplicación que envió el pedido sobre el progreso y el estado de este. La aplicación y Scheduler están aislados entre ellos para que no dependan el uno del otro. La aplicación no sabe qué instancia de Scheduler controla el pedido y Scheduler desconoce la instancia de aplicación que lo envió.
Para permitir informar del estado del pedido, la aplicación puede usar su propia cola de respuestas privada. Los detalles de esta cola de respuestas se incluiría como parte de la solicitud al proceso de envío, que incluiría esta información en el almacén de estado. Scheduler publicaría mensajes en esta cola que indicaran el estado del pedido (solicitud recibida, pedido completado, error en el pedido, etc.). En estos mensajes debe incluirse el identificador de pedido para que la aplicación los pueda correlacionar con la solicitud original.
Pasos siguientes
Las directrices siguientes también pueden ser importantes a la hora de implementar este patrón:
Manual de mensajería asincrónica. En general, los componentes del patrón Scheduler Agent Supervisor se ejecutan desacoplados entre ellos y se comunican de forma asincrónica. Describe algunos de los posibles enfoques para implementar la comunicación asincrónica basada en colas de mensajes.
Reference 6: A Saga on Sagas (Referencia 6: una saga sobre sagas). Ejemplo que muestra el uso de un administrador de procesos por el patrón CQRS (parte de la guía de viaje de CQRS).
Recursos relacionados
Los patrones siguientes también podrían ser importantes a la hora de implementar este patrón:
Patrón Retry. Las instancias de Agent pueden usar este patrón para reintentar una operación con acceso a un servicio o recurso remoto que haya producido un error previamente de forma transparente. Se utiliza cuando se cree que la causa del error es transitoria y se puede corregir.
Patrón Circuit Breaker. Una instancia de Agent puede utilizar este patrón para controlar errores que tardan un tiempo variable en solucionarse durante la conexión a un recurso o servicio remoto.
Patrón Compensating Transaction. Si el flujo de trabajo que realiza una instancia de Scheduler no se puede completar correctamente, podría ser necesario deshacer el trabajo anterior. El patrón Compensating Transaction describe la manera de lograrlo para las operaciones que siguen el modelo de coherencia final. Estos tipos de operaciones las implementa normalmente una instancia de Scheduler que realiza flujos de trabajo y procesos empresariales complejos.
Patrón Leader Election. Podría ser necesario coordinar las acciones de varias instancias de Supervisor para impedir que intenten recuperar el mismo proceso con error. El patrón Leader Election describe cómo hacerlo.
Arquitectura en la nube: patrón Scheduler-Agent-Supervisor en el blog de Clemens Vasters