Coordina las acciones realizadas por una colección de instancias de colaboración de una aplicación distribuida mediante la elección de una instancia como líder que asume la responsabilidad de administrar las otras. Esto puede ayudar a garantizar que las instancias no entren en conflicto, provoquen la contención de recursos compartidos o interfieran por accidente con el trabajo que realizan otras instancias.
Contexto y problema
Una aplicación en la nube típica tiene muchas tareas que actúan de manera coordinada. Estas instancias podrían ser todas instancias que ejecutan el mismo código y que requieren acceso a los mismos recursos, o podría estar funcionando juntas en paralelo para realizar las partes individuales de un cálculo complejo.
Las instancias de tarea podrían ejecutarse por separado la mayor parte del tiempo, pero también podría ser necesario coordinar las acciones de cada una para garantizar que no entren en conflicto, provoquen la contención de recursos compartidos o interfieran por accidente con el trabajo que realizan otras instancias de tarea.
Por ejemplo:
- En un sistema basado en la nube que implementa escalado horizontal, varias instancias de la misma tarea podrían estar ejecutándose al mismo tiempo y cada instancia atender a un usuario diferente. Si estas instancias escriben en un recurso compartido, es necesario coordinar sus acciones para evitar que cada instancia sobrescriba los cambios realizados por las demás.
- Si las tareas ejecutan elementos individuales de un cálculo complejo en paralelo, los resultados deben agregarse cuando dichos cálculos finalicen.
Las instancia de tarea son todas del mismo nivel, por lo que no hay un líder natural que actúe como coordinador o agregador.
Solución
Se debe elegir una única instancia de tarea para que actúe como líder, y esta instancia debe coordinar las acciones de las demás instancias de tarea subordinadas. Si todas las instancias de tarea ejecutan el mismo código, cada una de ellas tiene la capacidad para actuar como líder. Por lo tanto, el proceso de elección debe administrarse con cuidado para evitar que dos o más instancias asuman la posición de líder al mismo tiempo.
El sistema debe proporcionar un mecanismo eficaz para seleccionar el líder. Este método tiene que hacer frente a eventos, como interrupciones de red o errores de proceso. En muchas de las soluciones, las instancias de tarea subordinadas supervisan el líder a través de algún tipo de método de latido o mediante sondeo. Si el líder designado termina de forma inesperada, o un error de red hace que el líder no esté disponible para las instancias de tarea subordinadas, será necesario elegir un nuevo líder.
Existen varias estrategias para elegir un líder entre un conjunto de tareas en un entorno distribuido, como son:
- Competir para adquirir una exclusión mutua compartida y distribuida. La primera instancia de tarea que adquiere la exclusión mutua es el líder. Sin embargo, el sistema debe asegurarse de que, si el líder finaliza o se desconecta del resto del sistema, se libere la exclusión mutua para permitir que otra instancia de tarea se convierta en el líder. Esta estrategia se muestra en el ejemplo que se incluye a continuación.
- Implementar uno de los algoritmos de Leader Election comunes como el algoritmo Bully Algorithm, el Algoritmo de consenso Raft o el Algoritmo Ring. Estos algoritmos dan por supuesto que cada candidato de la elección tiene un identificador único y que puede comunicarse con los otros candidatos de manera confiable.
Problemas y consideraciones
Tenga en cuenta los puntos siguientes al decidir cómo implementar este patrón:
- El proceso de elegir un líder debería ser resistente a errores transitorios y persistentes.
- Tiene que ser posible detectar cuándo el líder ha generado un error o ha dejado de estar disponible (por ejemplo, debido a un error de comunicación). La rapidez con que se necesite la detección depende del sistema. Algunos sistemas podrían funcionar durante un corto espacio de tiempo sin un líder, en cuyo transcurso un error transitorio podría corregirse. En otros casos, podría ser necesario detectar el error del líder inmediatamente y desencadenar una nueva elección.
- En un sistema que implementa el escalado automático horizontal, el líder podría finalizarse si el sistema se reduce y cierra algunos de los recursos de computación.
- El uso de una exclusión mutua compartida distribuida introduce una dependencia en el servicio externo que proporciona la exclusión mutua. El servicio constituye un punto único de error. Si por algún motivo deja de estar disponible, el sistema no podrá elegir un líder.
- El uso de un único proceso dedicado como líder es un enfoque sencillo. Sin embargo, si el proceso produce un error, podría haber un considerable retraso mientras se reinicia. La latencia resultante puede afectar al rendimiento y a los tiempos de respuesta de otros procesos si están a la espera de que el líder coordine una operación.
- La implementación de uno de los algoritmos de Leader Election proporciona manualmente la máxima flexibilidad para optimizar y ajustar el código.
- Evite convertir el líder en un cuello de botella en el sistema. La finalidad del líder es coordinar el trabajo de las tareas subordinadas, y no tiene que participar necesariamente en este trabajo, aunque debería poder hacerlo si la tarea no se elige como líder.
Cuándo usar este patrón
Use este patrón cuando las tareas de una aplicación distribuida, como una solución hospedada en las nube, necesiten una cuidadosa coordinación y no haya un líder natural.
Este patrón puede ser útil en los siguientes casos:
- Hay un líder natural o un proceso dedicado que puede actuar siempre como líder. Por ejemplo, podría implementarse un proceso de singleton que coordine las instancias de tarea. Si se produce un error en este proceso o su estado no es correcto, el sistema puede cerrarlo y reiniciarlo.
- La coordinación entre las tareas se puede lograr con un método más ligero. Por ejemplo, si varias instancias de tarea solo necesitan acceso coordinado a un recurso compartido, una solución mejor es usar bloqueo optimista o pesimista para controlar el acceso.
- Una solución de terceros, como Apache ZooKeeper, puede ser una solución más eficaz.
Diseño de cargas de trabajo
Un arquitecto debe evaluar cómo se puede usar el patrón Leader Election en el diseño de su carga de trabajo para abordar los objetivos y principios descritos en los pilares del Marco de buena arquitectura de Azure. Por ejemplo:
| Fundamento | Cómo apoya este patrón los objetivos de los pilares |
|---|---|
| Las decisiones de diseño de la fiabilidad ayudan a que la carga de trabajo sea resistente a los errores y a garantizar que se recupere a un estado de pleno funcionamiento después de que se produzca un error. | Este patrón mitiga el efecto del mal funcionamiento del nodo mediante el redireccionamiento fiable del trabajo. También implementa la conmutación por error a través de algoritmos de consenso cuando un líder no funciona correctamente. - RE:05 Redundancia - RE:07 Recuperación automática |
Al igual que con cualquier decisión de diseño, hay que tener en cuenta las ventajas y desventajas con respecto a los objetivos de los otros pilares que podrían introducirse con este patrón.
Ejemplo
En el ejemplo de Leader Election de GitHub se muestra cómo usar una concesión en un blob de Azure Storage a fin de proporcionar un mecanismo para implementar una exclusión mutua compartida y distribuida. Esta exclusión mutua se puede usar para elegir un líder entre un grupo de instancias de trabajo disponibles. La primera instancia de rol en adquirir la concesión se elige como líder y lo sigue siendo hasta que libera la concesión o es incapaz de renovarla. Otras instancias de trabajador pueden continuar con la supervisión de la concesión del blob en caso de que el líder ya no esté disponible.
Una concesión de blob es un bloqueo exclusivo de escritura sobre un blob. Un único blob solo puede ser el sujeto de una concesión en cualquier momento en el tiempo. Una instancia de trabajo puede solicitar una concesión sobre un blob especificado y se le concederá la concesión si ninguna otra instancia de trabajo mantiene una concesión sobre el mismo blob. En caso contrario, la solicitud inicia una excepción.
Para evitar que una instancia de líder con errores conserve la concesión de forma indefinida, especifique una duración para la concesión. Cuando expire, la concesión estará disponible. Sin embargo, mientras una instancia mantenga la concesión puede solicitar que esta se renueve, así que se le otorgará durante un periodo de tiempo adicional. La instancia de líder puede repetir continuamente este proceso si desea conservar la concesión. Para más información sobre cómo conceder un blob, consulte Lease Blob (API de REST).
La clase BlobDistributedMutex del ejemplo de C# contiene el método RunTaskWhenMutexAcquired que permite que una instancia de trabajo intente adquirir una concesión sobre un blob especificado. Los detalles del blog (el nombre, el contenedor y la cuenta de almacenamiento) se pasan al constructor en un objeto BlobSettings cuando se crea el objeto BlobDistributedMutex (este objeto es una estructura sencilla que se incluye el código de ejemplo). El constructor también acepta un elemento Task que hace referencia al código que debe ejecutar la instancia de trabajo si adquiere correctamente la concesión sobre el blob y se elige como líder. Tenga en cuenta que el código que administra los detalles de bajo nivel de adquisición de la concesión se implementa en una clase auxiliar independiente llamada BlobLeaseManager.
public class BlobDistributedMutex
{
...
private readonly BlobSettings blobSettings;
private readonly Func<CancellationToken, Task> taskToRunWhenLeaseAcquired;
...
public BlobDistributedMutex(BlobSettings blobSettings,
Func<CancellationToken, Task> taskToRunWhenLeaseAcquired, ... )
{
this.blobSettings = blobSettings;
this.taskToRunWhenLeaseAcquired = taskToRunWhenLeaseAcquired;
...
}
public async Task RunTaskWhenMutexAcquired(CancellationToken token)
{
var leaseManager = new BlobLeaseManager(blobSettings);
await this.RunTaskWhenBlobLeaseAcquired(leaseManager, token);
}
...
El método RunTaskWhenMutexAcquired del código de ejemplo anterior invoca el método RunTaskWhenBlobLeaseAcquired mostrado en el código de ejemplo siguiente para adquirir realmente la concesión. El método RunTaskWhenBlobLeaseAcquired se ejecuta de forma asincrónica. Si la concesión se adquirió correctamente, la instancia de trabajo se elige como líder. El propósito del delegado taskToRunWhenLeaseAcquired es realizar el trabajo que coordina las otras instancias de trabajo. Si la concesión no se adquiere, otra instancia de trabajo se elije como líder y la instancia de trabajo actual queda como la subordinada. Tenga en cuenta que el método TryAcquireLeaseOrWait es un método auxiliar que utiliza el objeto BlobLeaseManager para adquirir la concesión.
private async Task RunTaskWhenBlobLeaseAcquired(
BlobLeaseManager leaseManager, CancellationToken token)
{
while (!token.IsCancellationRequested)
{
// Try to acquire the blob lease.
// Otherwise wait for a short time before trying again.
string? leaseId = await this.TryAcquireLeaseOrWait(leaseManager, token);
if (!string.IsNullOrEmpty(leaseId))
{
// Create a new linked cancellation token source so that if either the
// original token is canceled or the lease can't be renewed, the
// leader task can be canceled.
using (var leaseCts =
CancellationTokenSource.CreateLinkedTokenSource(new[] { token }))
{
// Run the leader task.
var leaderTask = this.taskToRunWhenLeaseAcquired.Invoke(leaseCts.Token);
...
}
}
}
...
}
La tarea iniciada por el líder también se ejecuta de manera asincrónica. Mientras se ejecuta esta tarea, el método RunTaskWhenBlobLeaseAcquired mostrado en el siguiente código de ejemplo intenta periódicamente renovar la concesión. Esto ayuda a garantizar que la instancia de trabajo sigue siendo el líder. En la solución de ejemplo, el retraso entre solicitudes de renovación es menor que el tiempo especificado para la duración de la concesión a fin de evitar que otra instancia de trabajo se elija como líder. Si se produce un error en la renovación por cualquier motivo, se cancela la tarea específica de líder.
Si no se renueva la concesión o se cancela la tarea (probablemente debido al cierre de la instancia de trabajo), se libera la concesión. En este momento, esta u otra instancia de trabajo pueden elegirse como líder. El extracto de código siguiente muestra esta parte del proceso.
private async Task RunTaskWhenBlobLeaseAcquired(
BlobLeaseManager leaseManager, CancellationToken token)
{
while (...)
{
...
if (...)
{
...
using (var leaseCts = ...)
{
...
// Keep renewing the lease in regular intervals.
// If the lease can't be renewed, then the task completes.
var renewLeaseTask =
this.KeepRenewingLease(leaseManager, leaseId, leaseCts.Token);
// When any task completes (either the leader task itself or when it
// couldn't renew the lease) then cancel the other task.
await CancelAllWhenAnyCompletes(leaderTask, renewLeaseTask, leaseCts);
}
}
}
}
...
}
El método KeepRenewingLease es otro método auxiliar que usa el objeto BlobLeaseManager para renovar la concesión. El método CancelAllWhenAnyCompletes cancela las tareas especificadas como los dos primeros parámetros. En el diagrama siguiente se ilustra el uso de la clase BlobDistributedMutex para elegir un líder y ejecutar una tarea que coordina las operaciones.
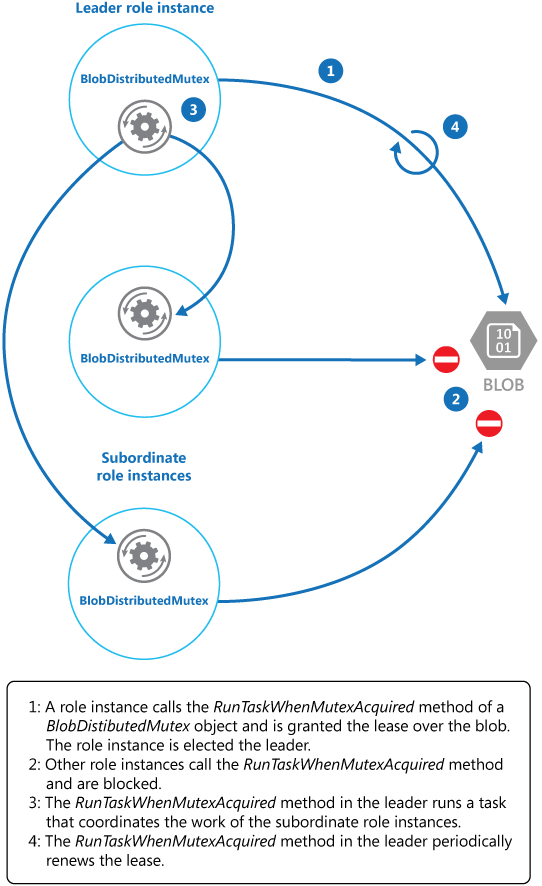
En el ejemplo de código siguiente se muestra cómo usar la clase BlobDistributedMutex dentro de una instancia de trabajo. Este código adquiere una concesión sobre un blob denominado MyLeaderCoordinatorTask en el contenedor de la concesión en Azure Blob Storage y especifica que el código definido en el método MyLeaderCoordinatorTask debe ejecutarse si la instancia de trabajo se elige como líder.
// Create a BlobSettings object with the connection string or managed identity and the name of the blob to use for the lease
BlobSettings blobSettings = new BlobSettings(storageConnStr, "leases", "MyLeaderCoordinatorTask");
// Create a new BlobDistributedMutex object with the BlobSettings object and a task to run when the lease is acquired
var distributedMutex = new BlobDistributedMutex(
blobSettings, MyLeaderCoordinatorTask);
// Wait for completion of the DistributedMutex and the UI task before exiting
await distributedMutex.RunTaskWhenMutexAcquired(cancellationToken);
...
// Method that runs if the worker instance is elected the leader
private static async Task MyLeaderCoordinatorTask(CancellationToken token)
{
...
}
Tenga en cuenta los siguientes puntos acerca de la solución de ejemplo:
- El blob es un posible único punto de error. Si el servicio de blob deja de estar disponible, o no es accesible, el líder no podrá renovar la concesión y ninguna otra instancia de trabajo podrá adquirirla. En este caso, ninguna instancia de trabajo podrá funcionar como líder. Sin embargo, el servicio de blob está diseñado para ser resistente, por lo que se considera improbable el error completo de dicho servicio.
- Si la tarea que realiza el líder se detiene, el líder puede continuar y renovar la concesión, lo que impide que cualquier otra instancia de trabajo pueda adquirirla y asuma la posición de líder para coordinar las tareas. En el mundo real, se debe comprobar el mantenimiento del líder a intervalos frecuentes.
- El proceso de elección es no determinista. No se puede realizar ninguna suposición acerca de qué instancia de trabajo adquirirá la concesión del blob y se convertirá en líder.
- El blob que se usa como el destino de la concesión no debe usarse para otros fines. Si una instancia de trabajo intenta almacenar datos en este blob, estos datos no podrán estar accesibles a menos que la instancia de trabajo sea el líder y mantenga la concesión del blob.
Pasos siguientes
Las directrices siguientes también pueden ser importantes a la hora de implementar este patrón:
- Este patrón tiene una aplicación de ejemplo descargable.
- Guía de escalado automático. Es posible iniciar y detener instancias de los hosts de las tareas a medida que varía la carga de la aplicación. El escalado automático puede ayudar a mantener el rendimiento y la capacidad de proceso durante los períodos de procesamiento máximo.
- Modelo asincrónico basado en tareas
- Un ejemplo que ilustra el algoritmo Bully.
- Un ejemplo que ilustra el algoritmo Ring.
- Apache Curator una biblioteca cliente de Apache ZooKeeper.
- El artículo Lease Blob (API de REST) en MSDN.