Enfoques de arquitectura para IA y ML en soluciones multiinquilino
Un número cada vez mayor de soluciones multiinquilino se basa en la inteligencia artificial (IA) y el aprendizaje automático (ML). Una solución multiinquilino de inteligencia artificial o ML es aquella que proporciona funcionalidades basadas en ML a cualquier número de inquilinos. Por lo general, los inquilinos no pueden ver ni compartir los datos de ningún otro inquilino pero, en algunas situaciones, los inquilinos pueden usar los mismos modelos que otros inquilinos.
Las arquitecturas multiinquilino de IA y ML deben tener en cuenta los requisitos de datos y modelos, así como los recursos de proceso necesarios para entrenar los modelos y realizar inferencias a partir de estos. Es importante tener en cuenta cómo se implementan, distribuyen y orquestan los modelos de IA y ML multiinquilino, para asegurarse de que la solución es precisa, confiable y escalable.
A medida que las tecnologías de IA generativa, impulsadas por modelos de lenguaje grande y pequeño, ganan popularidad, es crucial establecer prácticas y estrategias operativas eficaces para gestionar estos modelos en entornos de producción mediante la adopción de operaciones de aprendizaje automático (MLOps) y GenAIOps (a veces conocidas como LLMOps).
Consideraciones clave y requisitos
Al trabajar con IA y ML, es importante tener en cuenta por separado los requisitos de entrenamiento e inferencia. El propósito del entrenamiento es crear un modelo predictivo basado en un conjunto de datos. Se realiza una inferencia cuando se usa el modelo para predecir algo en la aplicación. Cada uno de estos procesos tiene requisitos diferentes. En una solución multiinquilino, debe tener en cuenta cómo afecta el modelo de inquilino a cada proceso. Para asegurarse de que la solución proporcione resultados precisos, funcione bien con carga, sea rentable y pueda escalarse para un futuro crecimiento, tenga en cuenta cada uno de estos requisitos.
Aislamiento de inquilinos
Asegúrese de que los inquilinos no obtengan acceso no autorizado o no deseado a los datos o modelos de otros inquilinos. Trate los modelos con una sensibilidad similar a los datos sin procesar que los entrenó. Asegúrese de que los inquilinos comprenden cómo se usan sus datos para entrenar modelos y cómo los modelos entrenados con los datos de otros inquilinos se pueden usar con fines de inferencia en sus cargas de trabajo.
Hay tres enfoques comunes para trabajar con modelos de ML en soluciones multiinquilino: modelos específicos del inquilino, modelos compartidos y modelos compartidos optimizados.
Modelos específicos del inquilino
Los modelos que son específicos del inquilino solo se entrenan con los datos de un solo inquilino y se aplican solo a ese único inquilino. Los modelos específicos del inquilino son adecuados cuando los datos son confidenciales o cuando hay poco ámbito para aprender de los datos que proporciona un inquilino, y se aplica el modelo a otro inquilino. En el diagrama siguiente se muestra cómo crear una solución con modelos específicos del inquilino para dos inquilinos:
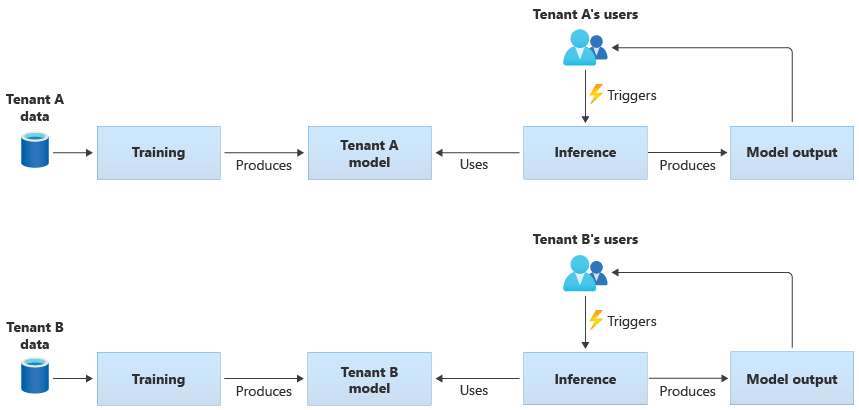
Modelos compartidos
En las soluciones que usan modelos compartidos, todos los inquilinos realizan inferencias basadas en el mismo modelo compartido. Los modelos compartidos pueden ser modelos previamente entrenados que se adquieren u obtienen de la comunidad. En el diagrama siguiente se muestra cómo todos los inquilinos pueden usar un único modelo entrenado previamente para la inferencia:
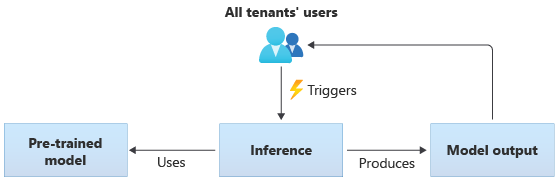
También puede crear sus propios modelos compartidos entrenándolos a partir de los datos que proporcionan todos los inquilinos. En el diagrama siguiente se muestra un único modelo compartido, que se entrena con datos de todos los inquilinos:

Importante
Si entrena un modelo compartido a partir de los datos de los inquilinos, asegúrese de que los inquilinos entiendan y acepten el uso de sus datos. Asegúrese de que la información de identificación se elimina de los datos de los inquilinos.
Tenga en cuenta lo que debe hacer si un inquilino tiene objeciones para que sus datos se usen para entrenar un modelo que se aplicará a otro inquilino. Por ejemplo, ¿podría excluir datos de inquilinos específicos del conjunto de datos de entrenamiento?
Modelos compartidos optimizados
También puede optar por adquirir un modelo base previamente entrenado y, a continuación, realizar un ajuste adicional del modelo para que sea aplicable a cada uno de los inquilinos, en función de sus propios datos. En el siguiente diagrama se muestra este enfoque:
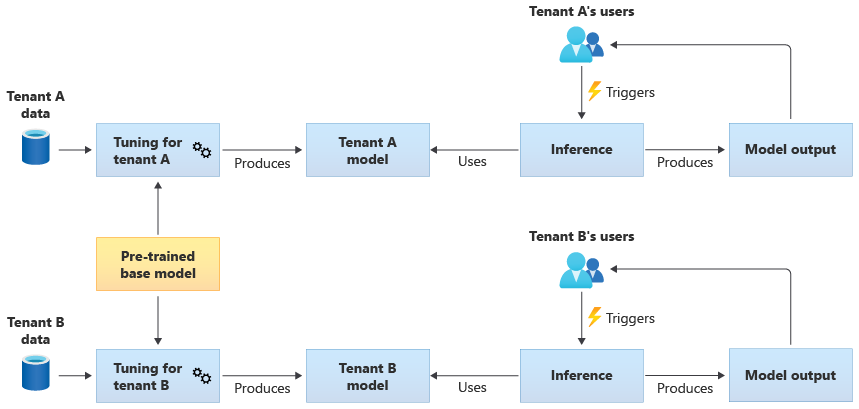
Escalabilidad
Tenga en cuenta cómo afecta el crecimiento de la solución al uso de los componentes de IA y ML. El crecimiento puede hacer referencia a un aumento en el número de inquilinos, a la cantidad de datos almacenados de cada inquilino, al número de usuarios y al volumen de solicitudes de la solución.
Entrenamiento: hay varios factores que influyen en los recursos necesarios para entrenar los modelos. Entre estos factores se incluye el número de modelos que tiene que entrenar, la cantidad de datos con que los entrena y la frecuencia con la que los entrena o reentrena. Si crea modelos específicos del inquilino, a medida que crece el número de inquilinos, también es probable que aumente la cantidad de recursos de proceso y almacenamiento que necesita. Si crea modelos compartidos y los entrena en función de los datos de todos los inquilinos, es menos probable que los recursos de entrenamiento se escalen a la misma velocidad que el crecimiento del número de inquilinos. Sin embargo, un aumento en la cantidad total de los datos de entrenamiento afectará a los recursos que se consumen, para entrenar ambos modelos: los compartidos y los específicos del inquilino.
Inferencia: los recursos necesarios para la inferencia suelen ser proporcionales al número de solicitudes que acceden a los modelos para efectuar un proceso de inferencia. A medida que aumenta el número de inquilinos, también es probable que aumente el número de solicitudes.
En general, se recomienda usar servicios de Azure que se escalen bien. Dado que las cargas de trabajo de IA y ML tienden a usar contenedores, Azure Kubernetes Service (AKS) y Azure Container Instances (ACI) son normalmente opciones habituales para las cargas de trabajo de IA y ML. AKS suele ser una buena opción para habilitar a gran escala y escalar dinámicamente los recursos de proceso en función de la demanda. Para cargas de trabajo pequeñas, ACI puede ser una plataforma de proceso sencilla de configurar, aunque no se escala tan fácilmente como AKS.
Rendimiento
Tenga en cuenta los requisitos de rendimiento de los componentes de IA y ML de la solución para el entrenamiento y para la inferencia. Es importante aclarar los requisitos de latencia y rendimiento de cada proceso de forma que pueda medir y mejorar según sea necesario.
Entrenamiento: el entrenamiento a menudo se realiza como un proceso por lotes, lo que significa que es posible que no sea tan sensible al rendimiento como otras partes de la carga de trabajo. Sin embargo, debe asegurarse de que aprovisiona recursos suficientes para realizar el entrenamiento del modelo de forma eficaz, incluso a medida que escala.
Inferencia: la inferencia es un proceso sensible a la latencia, que a menudo requiere una respuesta rápida o incluso en tiempo real. Incluso si no necesita realizar la inferencia en tiempo real, asegúrese de que supervisa el rendimiento de la solución y usa los servicios adecuados para optimizar la carga de trabajo.
Considere la posibilidad de usar las funcionalidades informáticas de alto rendimiento de Azure para las cargas de trabajo de IA y ML. Azure proporciona muchos tipos diferentes de máquinas virtuales y otras instancias de hardware. Considere si la solución se beneficiaría del uso de CPU, GPU, FPGA u otros entornos acelerados por hardware. Azure también proporciona inferencia en tiempo real con GPU de NVIDIA, incluidos los servidores de inferencia de NVIDIA Triton. Para los requisitos de proceso de prioridad baja, considere la posibilidad de usar grupos de nodos de acceso puntual de AKS. Para más información sobre la optimización de los servicios de proceso en una solución multiinquilino, consulte Enfoques de arquitectura para el proceso en soluciones multiinquilino.
El entrenamiento de modelos normalmente requiere muchas interacciones con los almacenes de datos, por lo que también es importante tener en cuenta la estrategia de datos y el rendimiento que proporciona la capa de datos. Para más información sobre los servicios multiinquilino y de datos, consulte Enfoques arquitectónicos para el almacenamiento y los datos en soluciones de multiinquilino.
Piense en la posibilidad de generar perfiles del rendimiento de la solución. Por ejemplo, Azure Machine Learning proporciona funcionalidades de generación de perfiles que puede usar al desarrollar e instrumentar la solución.
Complejidad de la implementación
Al crear una solución para que use IA y ML, puede elegir usar componentes pregenerados o crear componentes personalizados. Hay dos decisiones fundamentales que debe tomar. La primera es la plataforma o servicio que usará para IA y ML. La segunda es si usa modelos previamente entrenados o crea sus propios modelos personalizados.
Plataformas: Hay muchos servicios de Azure que puede usar para las cargas de trabajo de IA y ML. Por ejemplo, Servicios de Azure AI y Azure OpenAI Service proporcionan API para realizar la inferencia en modelos precompilados y Microsoft administra los recursos subyacentes. Servicios de Azure AI permite implementar rápidamente una nueva solución, pero le ofrece menos control sobre cómo se realizan el entrenamiento y la inferencia, y es posible que no se adapte a todos los tipos de carga de trabajo. Por el contrario, Azure Machine Learning es una plataforma que le permite compilar, entrenar y usar sus propios modelos de ML. Azure Machine Learning proporciona control y flexibilidad, pero aumenta la complejidad del diseño y la implementación. Consulte los productos y tecnologías de aprendizaje automático de Microsoft para tomar una decisión informada al seleccionar un enfoque.
Modelos: aunque no use un modelo completo proporcionado por un servicio como Servicios de Azure AI, puede acelerar el desarrollo mediante un modelo entrenado previamente. Si un modelo previamente entrenado no se adapta con precisión a sus necesidades, considere la posibilidad de ampliarlo mediante la aplicación de una técnica denominada aprendizaje por transferencia o ajuste preciso. El aprendizaje por transferencia le permite ampliar un modelo existente y aplicarlo a un dominio diferente. Por ejemplo, si va a crear un servicio de recomendaciones de música multiinquilino, puede considerar la posibilidad de crear un modelo previamente entrenado de recomendaciones de música y usar el aprendizaje por transferencia para entrenar este modelo para que se adapte a las preferencias de música de un usuario específico.
Mediante el uso de plataformas de ML precompilada como Servicios de Azure AI o Azure OpenAI Service, o bien un modelo entrenado previamente, puede reducir significativamente los costos iniciales de investigación y desarrollo. El uso de plataformas precompiladas podría ahorrarle muchos meses de investigación y evitar la necesidad de contratar científicos de datos altamente cualificados para entrenar, diseñar y optimizar modelos.
Optimización de costos
Por lo general, las cargas de trabajo de IA y ML generan la mayor parte de sus costos por los recursos de proceso necesarios para el entrenamiento y la inferencia del modelo. Consulte Enfoques de arquitectura para el proceso en soluciones multiinquilino para averiguar cómo optimizar el costo de la carga de trabajo de proceso para sus requisitos.
Tenga en cuenta los siguientes requisitos al planear los costos de IA y ML:
- Determine las SKU de proceso para el entrenamiento. Por ejemplo, consulte las instrucciones sobre cómo hacer esto con Azure Machine Learning.
- Determine las SKU de proceso para la inferencia. Para obtener un ejemplo de estimación de costes para la inferencia, consulte las instrucciones de Azure Machine Learning.
- Supervise el uso. Mediante la observación del uso de los recursos de proceso, puede determinar si debe reducir o aumentar su capacidad mediante la implementación de diferentes SKU, o escalar los recursos de proceso a medida que cambien sus requisitos. Consulte Supervisión de Azure Machine Learning.
- Optimice el entorno de los clústeres de proceso. Cuando use clústeres de proceso, supervise el uso del clúster o configure el escalado automático para reducir verticalmente los nodos de proceso.
- Comparta los recursos de proceso. Considere si puede optimizar el costo de los recursos de proceso si los comparte entre varios inquilinos.
- Tenga en cuenta el presupuesto. Averigüe si tiene un presupuesto fijo y supervise su consumo en consecuencia. Puede configurar presupuestos para evitar gastos excesivos y asignar cuotas en función de la prioridad del inquilino.
Enfoques y patrones que se deben tener en cuenta
Azure proporciona un conjunto de servicios para habilitar las cargas de trabajo de IA y ML. Hay varios enfoques arquitectónicos comunes que se usan en las soluciones multiinquilino: usar soluciones precompiladas de IA y ML, crear una arquitectura personalizada de IA o ML mediante Azure Machine Learning y usar una de las plataformas de análisis de Azure.
Uso de servicios de precompilados de IA y ML
Es un procedimiento recomendado intentar usar servicios precompilados de IA y ML siempre que pueda. Por ejemplo, es posible que su organización esté empezando a considerar el uso de IA y ML, y quiera integrarlos rápidamente con un servicio útil. O puede que tenga requisitos básicos que no requieran entrenamiento y desarrollo de modelos de ML personalizados. Los servicios de ML precompilados le permiten usar la inferencia sin necesidad de crear ni entrenar sus propios modelos.
Azure ofrece varios servicios que proporcionan tecnología de IA y ML en varios dominios, incluido el reconocimiento del lenguaje, el reconocimiento de voz, el conocimiento, el reconocimiento de documentos y formularios y Computer Vision. Los servicios precompilados de IA/ML de Azure incluyen Servicios de Azure AI, Azure OpenAI Service, Búsqueda de Azure AI e Documento de inteligencia de Azure AI. Cada servicio proporciona una interfaz sencilla para la integración y una colección de modelos previamente entrenados y probados. Como servicios administrados, ofrecen contratos de nivel de servicio y requieren poca configuración o administración continuas. No es necesario desarrollar ni probar sus propios modelos para usar estos servicios.
Muchos servicios administrados de ML no requieren datos ni entrenamiento del modelo, por lo que normalmente no hay problemas de aislamiento de datos de inquilino. Sin embargo, cuando trabaje con Búsqueda de AI en una solución multiinquilino, consulte Patrones de diseño para aplicaciones SaaS multiinquilino y Búsqueda de Azure AI.
Tenga en cuenta los requisitos de escalado de los componentes de la solución. Por ejemplo, muchas de las API de Servicios de Azure AI admiten un número máximo de solicitudes por segundo. Si implementa un único recurso de Servicios de AI para compartirlo entre los inquilinos, a medida que aumenta el número de inquilinos, es posible que tenga que escalar a varios recursos.
Nota:
Algunos servicios administrados le permiten entrenar con sus propios datos. Entre estos servicios se incluyen Custom Vision, Face API, los modelos personalizados de Document Intelligence y algunos modelos de OpenAI que admiten la personalización y el ajuste preciso. Cuando trabaje con estos servicios, es importante que tenga en cuenta los requisitos de aislamiento de los datos de los inquilinos.
Arquitectura personalizada de IA y ML
Si la solución requiere modelos personalizados o trabaja en un dominio que no está cubierto por un servicio administrado de ML, considere la posibilidad de crear su propia arquitectura de IA y ML. Azure Machine Learning proporciona un conjunto de funcionalidades para orquestar el entrenamiento y la implementación de modelos de ML. Azure Machine Learning admite muchas bibliotecas de aprendizaje automático de código abierto, incluidas PyTorch, TensorFlow, Scikity Keras. Puede supervisar continuamente las métricas de rendimiento de los modelos, detectar un desfase de datos y desencadenar el reentrenamiento para mejorar el rendimiento del modelo. A lo largo del ciclo de vida de los modelos de ML, Azure Machine Learning permite la capacidad de auditoría y la gobernanza con seguimiento y linaje integrados de todos los artefactos de ML.
Al trabajar en una solución multiinquilino, es importante tener en cuenta los requisitos de aislamiento de los inquilinos durante las fases de entrenamiento e inferencia. También debe determinar el proceso de entrenamiento e implementación del modelo. Azure Machine Learning proporciona una canalización para entrenar modelos e implementarlos en un entorno que se usará para la inferencia. En un contexto multiinquilino, tenga en cuenta si los modelos se deben implementar en recursos de proceso compartidos o si cada inquilino tiene recursos dedicados. Diseñe las canalizaciones de implementación del modelo en función del modelo de aislamiento y del proceso de implementación del inquilino.
Cuando use modelos de código abierto, es posible que tenga que volver a entrenar estos modelos mediante el aprendizaje por transferencia o el ajuste. Tenga en cuenta cómo administrará los diferentes modelos y datos de entrenamiento para cada inquilino, así como las versiones del modelo.
En el diagrama siguiente se muestra una arquitectura de ejemplo que usa Azure Machine Learning. En el ejemplo se usa el enfoque de aislamiento de modelos específicos del inquilino.
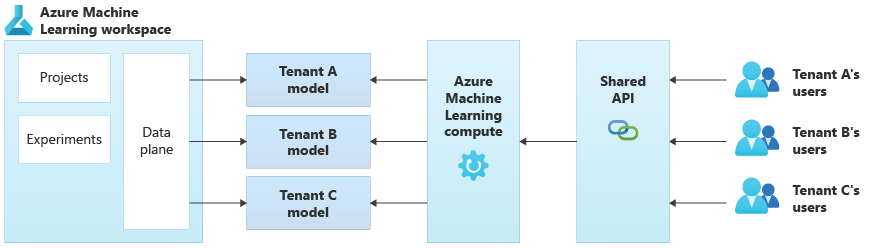
Soluciones integradas de IA y ML
Azure proporciona varias plataformas de análisis eficaces que se pueden usar para diferentes propósitos. Estas plataformas incluyen Azure Synapse Analytics, Databricks y Apache Spark.
Puede considerar el uso de estas plataformas para IA y ML cuando necesite escalar las funcionalidades de ML a un número muy grande de inquilinos y cuando necesite orquestación y proceso a gran escala. También puede considerar el uso de estas plataformas de IA y ML cuando necesite una amplia plataforma de análisis para otras partes de la solución, como para el análisis de datos y la integración con informes a través de Microsoft Power BI. Puede implementar una sola plataforma que abarque todas sus necesidades de IA y ML. Al implementar plataformas de datos en una solución multiinquilino, consulte Enfoques arquitectónicos para el almacenamiento y los datos en soluciones de multiinquilino.
Modelos operativos de ML
Al adoptar la inteligencia artificial y el aprendizaje automático, incluidas las prácticas de inteligencia artificial generativa, se recomienda mejorar y evaluar continuamente las funcionalidades de la organización para administrarlas. La introducción de MLOps y GenAIOps proporciona objetivamente un marco para ampliar continuamente las funcionalidades de las prácticas de inteligencia artificial y aprendizaje automático de su organización. Revise los documentos Modelo de madurez de MLOps y Modelo de madurez de LLMOps para obtener más instrucciones.
Antipatrones que se deben evitar
- No tener en cuenta los requisitos de aislamiento. Es importante considerar cuidadosamente cómo aislar los datos y los modelos de los inquilinos, para el entrenamiento y la inferencia. Si no lo hace, podría infringir los requisitos legales o contractuales. También se podría reducir la precisión de los modelos a la hora de entrenar con datos de varios inquilinos, si los datos son sustancialmente diferentes.
- Vecinos ruidosos. Considere si los procesos de entrenamiento o inferencia podrían estar sujetos al problema de vecino ruidoso. Por ejemplo, si tiene varios inquilinos grandes y un único inquilino pequeño, asegúrese de que el entrenamiento del modelo para los inquilinos grandes no consuma accidentalmente todos los recursos de proceso y se queden sin inquilinos más pequeños. Use la supervisión y la gobernanza de los recursos para mitigar el riesgo de que la carga de trabajo de proceso de un inquilino se vea afectada por la actividad de otros inquilinos.
Colaboradores
Microsoft mantiene este artículo. Originalmente lo escribieron los siguientes colaboradores.
Autor principal:
- Kevin Ashley | Senior Customer Engineer, FastTrack for Azure
Otros colaboradores:
- Paul Burpo | Principal Customer Engineer, FastTrack for Azure
- John Downs | Ingeniero principal de software
- Daniel Scott-Raynsford | Partner Technology Strategist
- Arsen Vladimirskiy | Principal Customer Engineer, FastTrack for Azure
- Vic Perdana | Arquitecto de soluciones de asociados de ISV
Pasos siguientes
- Consulte los enfoques que se indican en Enfoques de arquitectura para el proceso en soluciones multiinquilino.
- Para obtener más información sobre cómo diseñar canalizaciones de Azure Machine Learning para admitir varios inquilinos, consulte Una solución para la canalización de ML en modo multiinquilino.