En este artículo se describen el proceso de diseño, los principios y las opciones tecnológicas para usar Azure Synapse para crear una solución segura de almacén de lago de datos. Nos centramos en las consideraciones de seguridad y las decisiones técnicas clave.
Apache®, Apache Spark® y el logotipo de la llama son marcas registradas o marcas comerciales de Apache Software Foundation en Estados Unidos y otros países. El uso de estas marcas no implica la aprobación de Apache Software Foundation.
Architecture
El siguiente diagrama muestra la arquitectura de la solución de almacén de lago de datos. Está diseñado para controlar las interacciones entre los servicios con el fin de mitigar las amenazas de seguridad. Las soluciones variarán en función de los requisitos funcionales y de seguridad.

Descargue un archivo Visio de esta arquitectura.
Flujo de datos
El flujo de datos de la solución se muestra en el diagrama siguiente:

- Los datos se cargan desde el origen de datos a la zona de aterrizaje de datos, ya sea en Azure Blob Storage o en un recurso compartido de archivos proporcionado por Azure Files. Los datos se cargan mediante un sistema o programa de cargador por lotes. Los datos de streaming se capturan y almacenan en Blob Storage mediante la característica de captura de Azure Event Hubs. Puede haber varios orígenes de datos. Por ejemplo, varias fábricas diferentes pueden cargar los datos de sus operaciones. Para obtener información sobre cómo proteger el acceso a Blob Storage, recursos compartidos de archivos y otros recursos de almacenamiento, consulte Recomendaciones de seguridad para Blob Storage y Planeamiento de una implementación de Azure Files.
- La llegada del archivo de datos desencadena Azure Data Factory para procesar los datos y almacenarlos en el lago de datos de la zona de datos principal. La carga de datos en la zona de datos principal de Azure Data Lake protege frente a la filtración de datos.
- Azure Data Lake almacena los datos sin procesar que se obtienen de diferentes orígenes. Está protegido por reglas de firewall y redes virtuales. Bloquea todos los intentos de conexión procedentes de la red pública de Internet.
- La llegada de datos al lago de datos desencadena la canalización de Azure Synapse, o un desencadenador con tiempo ejecuta un trabajo de procesamiento de datos. Apache Spark en Azure Synapse se activa y ejecuta un trabajo o cuaderno de Spark. También organiza el flujo de proceso de datos en el almacén de lago de datos. Las canalizaciones de Azure Synapse convierten datos de la zona Bronze a la zona Silver y, a continuación, a la Zona Gold.
- Un trabajo o cuaderno de Spark ejecuta el trabajo de procesamiento de datos. Un trabajo de protección de datos o de aprendizaje automático también se pueden ejecutar en Spark. Los datos estructurados de la zona Gold se almacenan en formato Delta Lake.
- Un grupo de SQL sin servidor crea tablas externas que usan los datos almacenados en Delta Lake. El grupo de SQL sin servidor proporciona un motor de consulta SQL eficaz y eficiente y puede admitir cuentas de usuario SQL tradicionales o cuentas de usuario Microsoft Entra.
- Power BI se conecta al grupo de SQL sin servidor para visualizar los datos. Crea informes o paneles mediante los datos del almacén de lago de datos.
- Los científicos o analistas de datos pueden iniciar sesión en Azure Synapse Studio para lo siguiente:
- Mejorar aún más los datos
- Analizar para obtener información empresarial
- Entrenar el modelo de Machine Learning
- Las aplicaciones empresariales se conectan a un grupo de SQL sin servidor y usan los datos para admitir otros requisitos de operaciones empresariales.
- Azure Pipelines ejecuta el proceso de CI/CD que compila, prueba e implementa automáticamente la solución. Está diseñado para minimizar la intervención humana durante el proceso de implementación.
Componentes
A continuación se muestran los componentes clave de esta solución de almacén de lago de datos:
- Azure Synapse
- Archivos de Azure
- Event Hubs
- Blob Storage
- Almacén de Azure Data Lake
- Azure DevOps
- Power BI
- Data Factory
- Azure Bastion
- Azure Monitor
- Microsoft Defender for Cloud
- Azure Key Vault
Alternativas
- Si necesita procesamiento de datos en tiempo real, puede, en lugar de almacenar archivos individuales en la zona de aterrizaje de datos, usar Apache Structured Streaming para recibir el flujo de datos de Event Hubs y procesarlo.
- Si los datos tienen una estructura compleja y requieren consultas SQL complejas, considere la posibilidad de almacenarlos en un grupo de SQL dedicado en lugar de un grupo de SQL sin servidor.
- Si los datos contienen muchas estructuras de datos jerárquicas (por ejemplo, tiene una estructura JSON grande), es posible que quiera almacenarlos en Azure Synapse Data Explorer.
Detalles del escenario
Azure Synapse Analytics es una plataforma de datos versátil que admite el almacenamiento de datos empresariales, el análisis de datos en tiempo real, las canalizaciones, el procesamiento de datos de serie temporal, el aprendizaje automático y la gobernanza de datos. Para admitir estas funcionalidades, integra varias tecnologías diferentes, como:
- Almacenamiento de datos empresariales
- Grupos de SQL sin servidor
- Spark de Apache
- Pipelines
- Data Explorer
- Funcionalidades de aprendizaje automático
- Gobernanza de datos unificada de Microsoft Purview
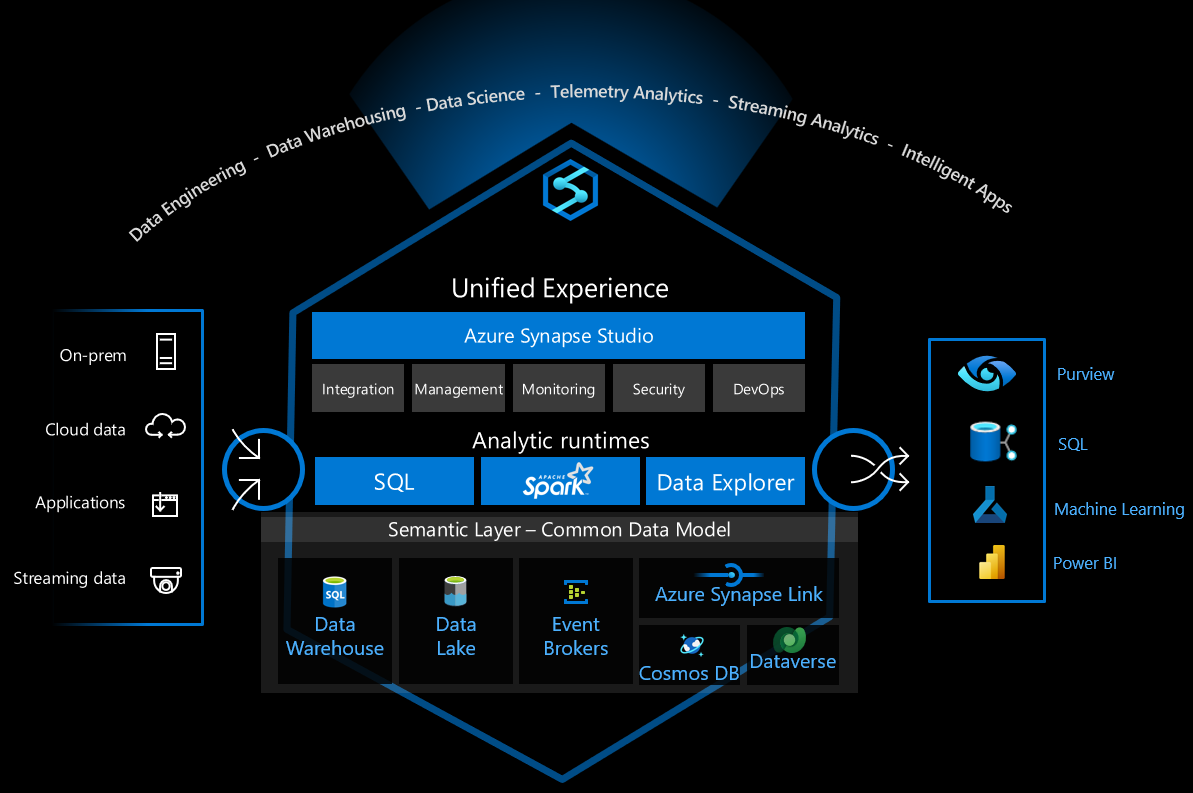
Estas funcionalidades brindan muchas posibilidades, pero hay muchas decisiones técnicas que se deben tomar para configurar de forma segura la infraestructura para su uso seguro.
En este artículo se describen el proceso de diseño, los principios y las opciones tecnológicas para usar Azure Synapse para crear una solución segura de almacén de lago de datos. Nos centramos en las consideraciones de seguridad y las decisiones técnicas clave. La solución usa estos servicios de Azure:
- Azure Synapse
- Grupos de SQL sin servidor de Azure Synapse
- Apache Spark en Azure Synapse Analytics
- Canalizaciones de Azure Synapse
- Azure Data Lake
- Azure DevOps.
El objetivo es proporcionar instrucciones sobre la creación de una plataforma segura y rentable de almacén de lago de datos para uso empresarial y sobre cómo hacer que las tecnologías funcionen conjuntamente de forma fluida y segura.
Posibles casos de uso
Un almacén de lago de datos es una arquitectura de administración de datos moderna que combina las características de rentabilidad, escala y flexibilidad de un lago de datos con las funcionalidades de administración de datos y transacciones de un almacenamiento de datos. Un almacén de lago de datos puede controlar una gran cantidad de datos y admitir escenarios de inteligencia empresarial y aprendizaje automático. También puede procesar datos de diversas estructuras de datos y orígenes de datos. Para más información, consulte ¿Qué es Databricks Lakehouse?
Algunos casos de uso comunes para la solución que se describe aquí son los siguientes:
- Análisis de telemetría de Internet de las cosas (IoT)
- Automatización de fábricas inteligentes (para fabricación)
- Seguimiento de las actividades y el comportamiento del consumidor (para comercio minorista)
- Administración de eventos e incidentes de seguridad
- Supervisión de los registros y el comportamiento de las aplicaciones
- Procesamiento y análisis empresarial de datos semiestructurados
Diseño de alto nivel
Esta solución se centra en las prácticas de diseño e implementación de seguridad en la arquitectura. El grupo de SQL sin servidor, Apache Spark en Azure Synapse, canalizaciones de Azure Synapse, Data Lake Storage y Power BI son los servicios clave que se usan para implementar el patrón de almacén de lago de datos.
Esta es la arquitectura de diseño de soluciones de alto nivel:

Elegir el enfoque de seguridad
Hemos iniciado el diseño de seguridad mediante la herramienta Modelado de amenazas. La herramienta nos ayudó a lo siguiente:
- Comunicarse con las partes interesadas del sistema sobre posibles riesgos.
- Definir el límite de confianza en el sistema.
En función de los resultados del modelado de amenazas, hemos convertido las siguientes áreas de seguridad en nuestras prioridades principales:
- Identidad y control de acceso
- Protección de redes
- Seguridad de DevOps
Hemos diseñado las características de seguridad y los cambios de la infraestructura para proteger el sistema mediante la mitigación de los principales riesgos de seguridad identificados con estas prioridades principales.
Para obtener más información sobre lo que se debe comprobar y considerar, consulte:
- Seguridad en Microsoft Cloud Adoption Framework para Azure
- Control de acceso
- Protección de recursos
- Seguridad de la innovación
Plan de protección de redes y recursos
Uno de los principios clave de seguridad de Cloud Adoption Framework es el principio de Confianza cero: al diseñar la seguridad para cualquier componente o sistema, reduzca el riesgo de que los atacantes amplíen su acceso suponiendo que otros recursos de la organización están en peligro.
En función del resultado del modelado de amenazas, la solución adopta la recomendación de implementación de microsegmentación en confianza cero y define varios límites de seguridad. La red virtual de Azure y la protección contra la filtración de datos de Azure Synapse son las tecnologías clave que se usan para implementar el límite de seguridad con el fin de proteger los recursos de datos y los componentes críticos.
Dado que Azure Synapse se compone de varias tecnologías diferentes, se necesita lo siguiente:
Identifique los componentes de Synapse y los servicios relacionados que se usan en el proyecto.
Azure Synapse es una plataforma de datos versátil que puede controlar muchas necesidades de procesamiento de datos diferentes. En primer lugar, es necesario decidir qué componentes de Azure Synapse se usan en el proyecto para que podamos planear cómo protegerlos. También es necesario determinar qué otros servicios se comunican con estos componentes de Azure Synapse.
En la arquitectura del almacén de lago de datos, los componentes clave son los siguientes:
- SQL sin servidor de Azure Synapse
- Apache Spark en Azure Synapse
- Canalizaciones de Azure Synapse
- Data Lake Storage
- Azure DevOps
Defina los comportamientos de comunicación legales entre los componentes.
Necesitamos definir los comportamientos de comunicación permitidos entre los componentes. Por ejemplo, ¿queremos que el motor de Spark se comunique directamente con la instancia de SQL dedicada o deseamos que se comunique a través de un proxy como la canalización de integración de datos de Azure Synapse o Data Lake Store?
En función del principio de Confianza cero, bloqueamos la comunicación si no hay necesidad empresarial de interacción. Por ejemplo, bloqueamos un motor de Spark que se encuentra en un inquilino desconocido para que se comunique directamente con Data Lake Storage.
Elija la solución de seguridad adecuada para aplicar los comportamientos de comunicación definidos.
En Azure, varias tecnologías de seguridad pueden aplicar los comportamientos de comunicación de servicio definidos. Por ejemplo, en Data Lake Storage puede usar una lista de direcciones IP permitidas para controlar el acceso a un lago de datos, pero también puede elegir qué redes virtuales, servicios de Azure e instancias de recursos están permitidas. Cada método de protección proporciona una protección de seguridad diferente. Elija uno en función de las necesidades empresariales y las limitaciones ambientales. La configuración usada en esta solución se describe en la sección siguiente.
Implemente la detección de amenazas y las defensas avanzadas para los recursos críticos.
Para los recursos críticos, lo más conveniente es implementar la detección de amenazas y las defensas avanzadas. Los servicios ayudan a identificar amenazas y desencadenar alertas, para que el sistema pueda notificar a los usuarios sobre infracciones de seguridad.
Tenga en cuenta las técnicas siguientes para proteger mejor las redes y los recursos:
Implementación de redes perimetrales para proporcionar zonas de seguridad para canalizaciones de datos
Cuando una carga de trabajo de canalización de datos requiere acceso a datos externos y a la zona de aterrizaje de datos, lo más conveniente es implementar una red perimetral y separarla con una canalización de extracción, transformación y carga (ETL).
Habilitación de Defender for Cloud para todas las cuentas de almacenamiento
Defender for Cloud desencadena alertas de seguridad cuando detecta intentos inusuales y potencialmente dañinos de acceder a las cuentas de almacenamiento o vulnerar la seguridad de las mismas. Para más información, consulte el artículo sobre configuración de Microsoft Defender para Storage.
Bloqueo de una cuenta de almacenamiento para evitar cambios en la configuración o la eliminación malintencionada
Para más información, consulte Aplicación de un bloqueo de Azure Resource Manager a una cuenta de almacenamiento.
Arquitectura con protección de red y recursos
En la tabla siguiente se describen los comportamientos de comunicación definidos y las tecnologías de seguridad elegidas para esta solución. Las opciones se basaron en los métodos descritos en Plan de protección de recursos y redes.
| De (Cliente) | Para (Servicio) | Comportamiento | Configuración | Notas | |
|---|---|---|---|---|---|
| Internet | Data Lake Storage | Denegar todo | Regla de firewall: denegación predeterminada | Valor predeterminado: "Denegar" | Regla de firewall: denegación predeterminada |
| Canalización de Azure Synapse/Spark | Data Lake Storage | Permitir (instancia) | Red virtual: punto de conexión privado administrado (Data Lake Storage) | ||
| SQL de Synapse | Data Lake Storage | Permitir (instancia) | Regla de firewall: instancias de recursos (Synapse SQL) | Synapse SQL necesita acceder a Data Lake Storage mediante identidades administradas | |
| Agente de Azure Pipelines | Data Lake Storage | Permitir (instancia) | Regla de firewall: redes virtuales seleccionadas Punto de conexión de servicio: Storage |
Para omisión de pruebas de integración: "AzureServices" (regla de firewall) |
|
| Internet | Área de trabajo de Synapse | Denegar todo | Regla de firewall | ||
| Agente de Azure Pipelines | Área de trabajo de Synapse | Permitir (instancia) | Red virtual: punto de conexión privado | Requiere tres puntos de conexión privados (desarrollo, SQL sin servidor y SQL dedicado) | |
| Red virtual administrada de Synapse | Inquilino de Azure de Internet o no autorizado | Denegar todo | Red virtual: protección de filtración de datos de Synapse | ||
| Canalización de Synapse/Spark | Key Vault | Permitir (instancia) | Red virtual: punto de conexión privado administrado (Key Vault) | Valor predeterminado: "Denegar" | |
| Agente de Azure Pipelines | Key Vault | Permitir (instancia) | Regla de firewall: redes virtuales seleccionadas * Punto de conexión de servicio: Key Vault |
pruebas de integración: "AzureServices" (regla de firewall) | |
| Azure Functions | SQL sin servidor de Synapse | Permitir (instancia) | Red virtual: punto de conexión privado (SQL sin servidor de Synapse) | ||
| Canalización de Synapse/Spark | Azure Monitor | Permitir (instancia) | Red virtual: punto de conexión privado (Azure Monitor) |
Por ejemplo, en el plan queremos hacer lo siguiente:
- Crear un área de trabajo de Azure Synapse con una red virtual administrada
- Proteger la salida de datos de áreas de trabajo de Azure Synapse mediante Protección contra la filtración de datos en áreas de trabajo de Azure Synapse Analytics
- Administre la lista de inquilinos de Microsoft Entra aprobados para el área de trabajo de Azure Synapse.
- Configurar reglas de red para conceder tráfico a la cuenta de Storage desde redes virtuales seleccionadas, acceder solo y deshabilitar el acceso a la red pública.
- Usar puntos de conexión privados administrados para conectar la red virtual administrada por Azure Synapse al lago de datos
- Usar instancia de recursos para conectar de forma segura Azure Synapse SQL al lago de datos
Consideraciones
Estas consideraciones implementan los pilares del Azure Well-Architected Framework, que es un conjunto de principios rectores que puede utilizar para mejorar la calidad de una carga de trabajo. Para más información, consulte Marco de buena arquitectura de Microsoft Azure.
Seguridad
Para obtener información sobre el pilar de seguridad del marco de buena arquitectura, consulte Seguridad.
Control de identidades y acceso
Hay varios componentes en el sistema. Cada uno requiere una configuración de administración de identidades y acceso (IAM) diferente. Estas configuraciones deben colaborar para proporcionar una experiencia de usuario simplificada. Por lo tanto, usamos las siguientes instrucciones de diseño al implementar el control de identidades y acceso.
Elección de una solución de identidad para diferentes capas de control de acceso
- Hay cuatro soluciones de identidad diferentes en el sistema.
- Cuenta de SQL (SQL Server)
- Entidad de servicio (Microsoft Entra ID)
- Identidad administrada (Microsoft Entra ID)
- Cuenta de usuario (Microsoft Entra ID)
- Hay cuatro capas de control de acceso diferentes en el sistema.
- Capa de acceso a la aplicación: elija la solución de identidad para roles de AP.
- La capa de acceso de base de datos y tablas de Azure Synapse: elija la solución de identidad para los roles de las bases de datos.
- Capa de acceso a recursos externos de Azure Synapse: elija la solución de identidad para acceder a los recursos externos.
- Capa de acceso a Data Lake Store: elija la solución de identidad para controlar el acceso a archivos en el almacenamiento.

Una parte fundamental del control de identidades y acceso es elegir la solución de identidad adecuada para cada capa de control de acceso. Los principios de diseño de seguridad del marco de buena arquitectura de Azure sugieren usar controles nativos e impulsar la simplificación. Por consiguiente, esta solución usa la cuenta de usuario Microsoft Entra del usuario final en la aplicación y en las capas de acceso a Azure Synapse DB. Utiliza las soluciones nativas de IAM propias y proporciona un control de acceso específico. La capa de acceso a recursos externos de Azure Synapse y la capa de acceso a Data Lake usan la identidad administrada en Azure Synapse para simplificar el proceso de autorización.
- Hay cuatro soluciones de identidad diferentes en el sistema.
Consideración del acceso con privilegios mínimos
Un principio rector de Confianza cero sugiere proporcionar acceso Just-In-Time y Just-Enough a los recursos críticos. Consulte Azure AD Privileged Identity Management (PIM) para mejorar la seguridad en el futuro.
Protección del servicio vinculado
Los servicios vinculados definen la información de conexión necesaria para que un servicio se conecte a recursos externos. Es importante proteger las configuraciones de los servicios vinculados.
- Cree un servicio vinculado de Azure Data Lake con Private Link.
- Use la identidad administrada como método de autenticación en los servicios vinculados.
- Use Azure Key Vault para proteger las credenciales de acceso al servicio vinculado.

Evaluación de puntuación de seguridad y detección de amenazas
Para conocer el estado de seguridad del sistema, la solución usa Microsoft Defender for Cloud para evaluar la seguridad de la infraestructura y detectar problemas de seguridad. Microsoft Defender for Cloud es una herramienta para la administración de la posición de seguridad y la protección contra amenazas. Puede proteger las cargas de trabajo que se ejecutan en Azure, híbridas y otras plataformas en la nube.

Habilitará automáticamente el plan Gratis de Defender for Cloud en todas las suscripciones de Azure la primera vez que visite las páginas de Defender for Cloud en Azure Portal. Se recomienda encarecidamente que lo habilite para obtener la evaluación y las sugerencias de la posición de seguridad en la nube. Microsoft Defender for Cloud proporcionará la puntuación de seguridad y algunas instrucciones de fortalecimiento de la seguridad para las suscripciones.
Si la solución necesita funcionalidades avanzadas de administración de seguridad y detección de amenazas, como la detección y las alertas de actividades sospechosas, puede habilitar la protección de cargas de trabajo en la nube individualmente para distintos recursos.
Optimización de costos
Para obtener información sobre el pilar de optimización de costos del marco de buena arquitectura, consulte Optimización de costos.
Una ventaja clave de la solución del almacén de lago de datos es su arquitectura escalable y rentable. La mayoría de los componentes de la solución usan la facturación basada en el consumo y se escalarán automáticamente. En esta solución, todos los datos se almacenan en Data Lake Storage. Solo paga por almacenar los datos si no ejecuta ninguna consulta ni procesa datos.
Los precios de esta solución dependen del uso de los siguientes recursos clave:
- SQL sin servidor de Azure Synapse: use la facturación basada en el consumo y pague solo por lo que use.
- Apache Spark en Azure Synapse: use la facturación basada en el consumo y pague solo por lo que use.
- Canalizaciones de Azure Synapse: use la facturación basada en el consumo y pague solo por lo que use.
- Lagos de datos de Azure: use la facturación basada en el consumo y pague solo por lo que use.
- Power BI: el costo se basa en la licencia que compre.
- Private Link: use la facturación basada en el consumo y pague solo por lo que use.
Las diferentes soluciones de protección de seguridad tienen diferentes modos de costos. Debe elegir la solución de seguridad en función de sus necesidades empresariales y los costos de la solución.
Puede usar la calculadora de precios de Azure para estimar el costo de la solución.
Excelencia operativa
Para obtener información sobre el pilar de excelencia operativa del marco de buena arquitectura, consulte Excelencia operativa.
Uso de un agente de canalización autohospedado habilitado para la red virtual para los servicios de CI/CD
El agente de canalización de Azure DevOps predeterminado no admite la comunicación de red virtual porque usa un intervalo de direcciones IP muy amplio. Esta solución implementa un agente autohospedado de Azure DevOps en la red virtual para que los procesos de DevOps puedan comunicarse sin problemas con los demás servicios de la solución. Las cadenas de conexión y los secretos para ejecutar los servicios de CI/CD se almacenan en un almacén de claves independiente. Durante el proceso de implementación, el agente autohospedado accede al almacén de claves de la zona de datos principal para actualizar las configuraciones de recursos y los secretos. Para más información, consulte el documento Uso de instancias de Key Vault independientes. Esta solución también usa conjuntos de escalado de máquinas virtuales para asegurarse de que el motor de DevOps puede escalar y reducir vertical y automáticamente en función de la carga de trabajo.

Implementación del examen de seguridad de la infraestructura y las pruebas de humo en la canalización de CI/CD
Una herramienta de análisis estático para examinar archivos de infraestructura como código (IaC) puede ayudar a detectar y evitar configuraciones incorrectas que pueden provocar problemas de seguridad o cumplimiento. Las pruebas de humo de seguridad garantizan que las medidas de seguridad vitales del sistema estén habilitadas correctamente, protegiendo frente a errores de implementación.
- Use una herramienta de análisis estático para examinar plantillas de infraestructura como código (IaC) para detectar y evitar configuraciones incorrectas que pueden provocar problemas de seguridad o cumplimiento. Use herramientas como Checkov o Terrascan para detectar y evitar riesgos de seguridad.
- Asegúrese de que la canalización de CD controla correctamente los errores de implementación. Cualquier error de implementación relacionado con las características de seguridad debe tratarse como un error crítico. La canalización debe reintentar la acción con errores o contener la implementación.
- Valide las medidas de seguridad de la canalización de implementación mediante la ejecución de pruebas de humo de seguridad. Las pruebas de humo de seguridad, como validar el estado de configuración de los recursos implementados o los casos de prueba que examinan escenarios de seguridad críticos, pueden garantizar que el diseño de seguridad funcione según lo previsto.
Colaboradores
Microsoft mantiene este artículo. Originalmente lo escribieron los siguientes colaboradores.
Autor principal:
- Herman Wu | Ingeniero sénior de software
Otros colaboradores:
- Ian Chen | Ingeniero principal de software
- Jose Contreras | Ingeniero principal de software
- Roy Chan | Director de ingeniería principal de software
Pasos siguientes
- Documentación de producto de Azure
- Otros artículos
- ¿Qué es Azure Synapse Analytics?
- Grupo de SQL sin servidor en Azure Synapse Analytics
- Apache Spark en Azure Synapse Analytics
- Canalizaciones y actividades en Azure Data Factory y Azure Synapse Analytics
- ¿Qué es el Explorador de datos de Azure Synapse? (versión preliminar)
- Funcionalidades de Machine Learning en Azure Synapse Analytics
- ¿Qué es Microsoft Purview?
- Azure Synapse Analytics y Azure Purview funcionan mejor juntos
- Introducción a Azure Data Lake Storage Gen2
- ¿Qué es Azure Data Factory?
- Series de blogs de patrones de datos actuales: almacén de lago de datos
- ¿Qué es Microsoft Defender for Cloud?
- Almacén de lago de datos, almacenamiento de datos y arquitectura de plataforma de datos moderna
- Los procedimientos recomendados para organizar almacenes de lago de datos y áreas de trabajo de Azure Synapse
- Descripción de los puntos de conexión privados de Azure Synapse
- Azure Synapse Analytics: información nueva sobre la seguridad de los datos
- Línea base de seguridad de Azure para un grupo de SQL dedicado de Azure Synapse (anteriormente SQL DW)
- Seguridad de red en la nube 101: puntos de conexión de servicio frente a puntos de conexión privados de Azure
- Procedimiento para configurar el control de acceso para el área de trabajo de Azure Synapse
- Conexión a Azure Synapse Studio con centros de Azure Private Link
- Implementación de los artefactos del área de trabajo de Azure Synapse en un área de trabajo de Azure Synapse de RED VIRTUAL administrada
- Integración y entrega continuas en un área de trabajo de Azure Synapse Analytics
- Puntuación segura en Microsoft Defender for Cloud
- Procedimientos recomendados para usar Azure Key Vault
- Escenario de Adatum Corporation para la administración y el análisis de datos en Azure