¿Qué son la continuidad empresarial, la alta disponibilidad y la recuperación ante desastres?
En este artículo se definen y describen la continuidad empresarial y el planeamiento de la continuidad empresarial en términos de administración de riesgos mediante el diseño de alta disponibilidad y recuperación ante desastres. Aunque este artículo no proporciona instrucciones explícitas sobre cómo satisfacer sus propias necesidades de continuidad empresarial, le ayuda a comprender los conceptos que se usan en las instrucciones de confiabilidad de Microsoft.
Continuidad empresarial es el estado en el que una empresa puede continuar las operaciones durante errores, interrupciones o desastres. La continuidad empresarial requiere planificación proactiva, preparación e implementación de sistemas y procesos resistentes.
La planeación de la continuidad empresarial requiere identificar, comprender, clasificar y administrar riesgos. En función de los riesgos y sus probabilidades, adapte su diseño tanto para la alta disponibilidad (HA) como para la recuperación ante desastres (DR).
La alta disponibilidad consiste en diseñar una solución que resista a los problemas diarios y que satisfaga las necesidades empresariales de disponibilidad.
La recuperación ante desastres consiste en planear cómo tratar riesgos poco comunes y las interrupciones catastróficas que puede haber como resultado.
Continuidad empresarial
En general, las soluciones en la nube están vinculadas directamente a las operaciones empresariales. El hecho de que una solución en la nube no esté disponible o experimente un problema grave puede afectar gravemente a las operaciones comerciales. Una consecuencia grave puede interrumpir la continuidad empresarial.
Entre las consecuencias graves en la continuidad empresarial, se incluyen las siguientes:
- Pérdida de ingresos empresariales.
- Imposibilidad de proporcionar un servicio importante a los usuarios.
- Incumplimiento de un compromiso con un cliente u otra parte.
Es importante comprender y comunicar las expectativas empresariales y las consecuencias de los errores a las partes interesadas importantes, incluidas aquellas que diseñen, implementen y gestionen la carga de trabajo. Esas partes interesadas responden, entonces, compartiendo los costes que implica hacer realidad esa visión. Normalmente hay un proceso de negociación y revisiones de esa visión en función del presupuesto y otras restricciones.
Planeamiento de la continuidad empresarial
Para controlar o evitar completamente un impacto negativo en la continuidad empresarial, es importante crear de forma proactiva un plan de continuidad empresarial. Un plan de continuidad empresarial se basa en la evaluación de riesgos y en el desarrollo de métodos de control de esos riesgos a través de diversos enfoques. Los riesgos y enfoques específicos que se debe mitigar varían para cada organización y carga de trabajo.
Un plan de continuidad empresarial no solo tiene en cuenta las características de resistencia de la propia plataforma en la nube, sino también las características de la aplicación. Un plan de continuidad empresarial sólido también incorpora todos los aspectos de soporte técnico en la empresa, como personas, procesos manuales o automatizados relacionados con el negocio, y otras tecnologías.
El planeamiento de continuidad empresarial debe incluir los siguientes pasos secuenciales:
Identificación de riesgos. Identifique los riesgos para la disponibilidad o la funcionalidad de una carga de trabajo. Los posibles riesgos podrían ser problemas de red, errores de hardware, errores humanos, interrupción de la región, etc. Conozca las consecuencias de cada riesgo.
Clasificación de riesgos. Clasifique cada riesgo como un riesgo común, que se debe tener en cuenta en los planes de alta disponibilidad, o en un riesgo poco común, que debe formar parte del planeamiento de la recuperación ante desastres.
Mitigación de riesgos. Diseñe estrategias de mitigación de alta disponibilidad o recuperación ante desastres para minimizar o mitigar los riesgos, como la redundancia, la replicación, la conmutación por error y las copias de seguridad. Además, considere las mitigaciones y controles no técnicos y basados en procesos.
El planeamiento de la continuidad empresarial es un proceso, no un evento único. Cualquier plan de continuidad empresarial que se cree se debe revisar y actualizar periódicamente para asegurarse de que sigue siendo relevante y eficaz, y que admite las necesidades empresariales actuales.
Identificación de riesgos
La fase inicial del planeamiento de la continuidad empresarial es identificar los riesgos para la disponibilidad o la funcionalidad de una carga de trabajo. Cada riesgo debe analizarse para comprender su probabilidad y su gravedad. La gravedad debe incluir cualquier posible tiempo de inactividad o pérdida de datos, así como si algún aspecto del resto del diseño de la solución podría compensar los efectos negativos.
La siguiente tabla es una lista no exhaustiva de riesgos, ordenados por probabilidad decreciente:
| Riesgo de ejemplo | Descripción | Regularidad (probabilidad) |
|---|---|---|
| Problema de red transitorio | Error temporal en un componente de la pila de red, que se puede recuperar después de un breve tiempo (normalmente unos segundos o menos). | Regular |
| Reinicio de máquina virtual | Reinicio de una máquina virtual que usa usted o un servicio dependiente. Es posible que se produzcan reinicios porque la máquina virtual se bloquee o necesite aplicar una revisión. | Regular |
| Error de hardware | Error de un componente dentro de un centro de datos, como un nodo de hardware, un bastidor o un clúster. | Ocasional |
| Interrupción del centro de datos | Una interrupción que afecta a la mayoría o a todos los centros de datos, como un error de alimentación, un problema de conectividad de red o problemas con la calefacción y la refrigeración. | Inusual |
| Interrupción de la región | Una interrupción que afecta a toda una zona metropolitana o a una zona más amplia, como un desastre natural importante. | Muy inusual |
El planeamiento de continuidad empresarial no es solo sobre la plataforma en la nube y la infraestructura. Es importante tener en cuenta el riesgo de errores humanos. Además, algunos riesgos que tradicionalmente podrían considerarse de seguridad, rendimiento o riesgos operativos también deben considerarse riesgos de confiabilidad porque afectan a la disponibilidad de la solución.
Estos son algunos ejemplos:
| Riesgo de ejemplo | Descripción |
|---|---|
| Pérdida de datos o daños | Los datos se han eliminado, sobrescrito o dañado por un accidente o una vulneración de seguridad, como un ataque de ransomware. |
| Error de software | Una implementación de código nuevo o actualizado presenta un error que afecta a la disponibilidad o integridad, lo que deja la carga de trabajo en un estado que no funciona correctamente. |
| Implementaciones con errores | Error en la implementación de un nuevo componente o versión, lo que deja la solución en un estado incoherente. |
| Ataques por denegación de servicio | El sistema se ha atacado en un intento de evitar el uso legítimo de la solución. |
| Administradores no autorizados | Un usuario con privilegios administrativos ha realizado intencionadamente una acción perjudicial contra el sistema. |
| Entrada inesperada del tráfico a una aplicación | Un pico en el tráfico ha sobrecargado los recursos del sistema. |
El Análisis del modo de error (FMA) es el proceso de identificar posibles formas en las que se puede producir un error en una carga de trabajo o sus componentes y cómo se comporta la solución en esas situaciones. Para obtener más información, consulte Recomendaciones para realizar el análisis del modo de error.
Clasificación del riesgo
Los planes de continuidad empresarial deben abordar riesgos comunes y poco comunes.
Se planean y se esperan riesgos comunes. Por ejemplo, en un entorno en la nube es habitual que haya errores transitorios, incluidas las interrupciones breves de red, reinicios del equipo debido a revisiones, tiempos de espera cuando un servicio está ocupado, etc. Dado que estos eventos se producen periódicamente, las cargas de trabajo deben poder superarlos.
Una estrategia de alta disponibilidad debe tener en cuenta y controlar cada riesgo de este tipo.
Los riesgos poco comunes suelen ser el resultado de un evento imprevisible, como un desastre natural o un ataque de red importante, que puede provocar una interrupción grave.
Los procesos de recuperación ante desastres se ocupan de estos riesgos poco frecuentes.
La alta disponibilidad y la recuperación ante desastres están relacionadas entre sí, por lo que es importante planear estrategias para ambas a la vez.
Es importante comprender que la clasificación de riesgos depende de la arquitectura de carga de trabajo y de los requisitos empresariales, y algunos riesgos se pueden clasificar como alta disponibilidad para una carga de trabajo y recuperación ante desastres para otra carga de trabajo. Por ejemplo, una interrupción completa de la región de Azure generalmente se consideraría un riesgo de recuperación ante desastres en las cargas de trabajo de esa región. Pero, para las cargas de trabajo que usan varias regiones de Azure en una configuración activa-activa con replicación completa, redundancia y conmutación automática por error de región, una interrupción de región se clasifica como un riesgo de alta disponibilidad.
Mitigación de riesgos
La mitigación de riesgos consiste en desarrollar estrategias de alta disponibilidad o recuperación ante desastres para minimizar o mitigar los riesgos de continuidad empresarial. La mitigación de riesgos puede basarse en la tecnología o el componente humano.
Mitigación de riesgos basados en la tecnología
La mitigación de riesgos basada en la tecnología usa controles de riesgo basados en cómo se implementa y configura la carga de trabajo; por ejemplo:
- Redundancia
- Replicación de datos
- Conmutación por error
- Copias de seguridad
Los controles de riesgo basados en tecnología deben tenerse en cuenta dentro del contexto del plan de continuidad empresarial.
Por ejemplo:
Requisitos de tiempo de inactividad bajo. Algunos planes de continuidad empresarial no pueden tolerar ninguna forma de riesgo de tiempo de inactividad debido a estrictos requisitos de alta disponibilidad. Hay ciertos controles basados en tecnología que pueden requerir tiempo para que un humano reciba la notificación al respecto y luego responda. Es probable que los controles de riesgo basados en tecnología que incluyan procesos manuales lentos no se ajusten a la inclusión en su estrategia de mitigación de riesgos.
Tolerancia a errores parciales. Algunos planes de continuidad empresarial pueden tolerar un flujo de trabajo que se ejecuta en un estado degradado. Cuando una solución funciona en un estado degradado, es posible que algunos componentes estén deshabilitados o no funcionen, pero las operaciones empresariales principales pueden seguir realizándose. Para más información, consulte Recomendaciones para la recuperación y conservación automáticas.
Mitigación de riesgos basada en humanos
La mitigación de riesgos basada en humanos usa controles de riesgo basados en procesos empresariales, como el siguiente:
- Desencadenar un cuaderno de estrategias de respuesta.
- Revertir a las operaciones manuales.
- Entrenamiento y cambios culturales.
Importante
Las personas que diseñan, implementan, gestionan y desarrollan la carga de trabajo deben ser competentes, animarse a hablar si tienen inquietudes y tener un sentido de responsabilidad por el sistema.
Dado que los controles de riesgo basados en humanos suelen ser más lentos que los controles basados en tecnología y más propensos a errores humanos, un buen plan de continuidad empresarial debe incluir un proceso de control de cambios formal para cualquier cosa que modifique el estado del sistema en ejecución. Por ejemplo, considere la posibilidad de implementar los siguientes procesos:
- Pruebe rigurosamente las cargas de trabajo de acuerdo con la importancia de la carga de trabajo. Para evitar problemas relacionados con los cambios, asegúrese de probar los cambios realizados en la carga de trabajo.
- Introduzca puertas de calidad estratégicas como parte de las prácticas de implementación seguras de la carga de trabajo. Para más información, consulte recomendaciones de procedimientos de implementación seguros.
- Formalice los procedimientos para el acceso a producción ad hoc y la manipulación de datos. Estas actividades, independientemente de lo menores que sean, pueden presentar un alto riesgo de causar incidentes de confiabilidad. Los procedimientos pueden incluir trabajar en conjunto con otro ingeniero, usar listas de verificación y obtener revisiones de pares antes de ejecutar scripts o aplicar cambios.
Alta disponibilidad
La alta disponibilidad es el estado en el que una carga de trabajo específica puede mantener su nivel de tiempo de actividad necesario día a día, incluso durante errores transitorios y errores intermitentes. Dado que estos eventos se producen periódicamente, es importante que cada carga de trabajo esté diseñada y configurada para la alta disponibilidad de acuerdo con los requisitos de las expectativas específicas de la aplicación y del cliente. La alta disponibilidad de cada carga de trabajo contribuye al plan de continuidad empresarial.
Dado que la alta disponibilidad puede variar con cada carga de trabajo, es importante comprender los requisitos y las expectativas del cliente al determinar la alta disponibilidad. Por ejemplo, una aplicación que su organización usa para pedir suministros de oficina podría requerir un nivel de tiempo de actividad relativamente bajo, mientras que una aplicación financiera crítica podría requerir un tiempo de actividad mucho mayor. Incluso dentro de una carga de trabajo, diferentes flujos pueden tener requisitos distintos. Por ejemplo, en una aplicación de comercio electrónico, los flujos que admiten la exploración y la realización de pedidos pueden ser más importantes que los flujos de procesamiento de pedidos y de back-office. Para obtener más información sobre los flujos, consulte recomendaciones para identificar y clasificar flujos.
Normalmente, el tiempo de actividad se mide en función del número de "nueves" en el porcentaje de tiempo de actividad. El porcentaje de tiempo de actividad se relaciona con la cantidad de tiempo de inactividad que se permite durante un período de tiempo determinado. Estos son algunos ejemplos:
- Un requisito de tiempo de actividad del 99,9 % (tres nueves) permite aproximadamente 43 minutos de tiempo de inactividad en un mes.
- Un requisito de tiempo de actividad del 99,95 % (tres nueves y medio) permite aproximadamente 21 minutos de tiempo de inactividad en un mes.
Cuanto mayor sea el requisito de tiempo de actividad, menor tolerancia tendrá a las interrupciones y más trabajo tendrá que realizar para alcanzar ese nivel de disponibilidad. El tiempo de actividad no se mide por el tiempo de actividad de un solo componente como un nodo, sino por la disponibilidad general de toda la carga de trabajo.
Importante
No diseñe en exceso su solución para alcanzar niveles de confiabilidad más altos que los justificados. Use los requisitos empresariales para guiar sus decisiones.
Alta disponibilidad: diseño
Para lograr los requisitos de alta disponibilidad, una carga de trabajo puede incluir una serie de elementos de diseño. Algunos de los elementos comunes se enumeran y se describen a continuación en esta sección.
Nota:
Algunas cargas de trabajo son críticas, lo que significa que cualquier tiempo de inactividad puede tener consecuencias graves para la vida y la seguridad humanas, o pérdidas financieras importantes. Si va a diseñar una carga de trabajo crítica, hay cosas específicas que debe tener en cuenta al diseñar la solución y administrar la continuidad empresarial. Para obtener más información, consulte Marco de buena arquitectura de Azure: cargas de trabajo críticas.
Servicios y niveles de Azure que admiten alta disponibilidad
Muchos servicios de Azure están diseñados para ser de alta disponibilidad y se pueden usar para crear cargas de trabajo de alta disponibilidad. Estos son algunos ejemplos:
- Azure Virtual Machine Scale Sets proporcionan alta disponibilidad para máquinas virtuales (VM) mediante la creación y administración automáticas de instancias de máquina virtual y la distribución de esas instancias de máquina virtual para reducir el impacto de los errores de infraestructura.
- Azure App Service proporciona alta disponibilidad a través de una variedad de enfoques, incluido mover automáticamente los trabajos de un nodo incorrecto a un nodo correcto y proporcionar funcionalidades para la recuperación automática de muchos tipos de errores comunes.
Utilice cada guía de confiabilidad del servicio para comprender las capacidades del servicio, decidir qué niveles usar y determinar qué capacidades incluir en su estrategia de alta disponibilidad.
Revise los acuerdos de nivel de servicio (SLA) de cada servicio para comprender los niveles de disponibilidad esperados y las condiciones que necesita cumplir. Es posible que tenga que seleccionar o evitar niveles específicos de servicios para lograr determinados niveles de disponibilidad. Algunos servicios de Microsoft se ofrecen con el entendimiento de que no se proporciona ningún SLA, como los niveles de desarrollo o básicos, o que el recurso podría recuperarse de su sistema en ejecución, como las ofertas basadas en puntos puntuales. Además, algunos niveles han agregado características de confiabilidad, como la compatibilidad con zonas de disponibilidad.
Tolerancia a errores
La tolerancia a errores es la capacidad de un sistema de seguir funcionando, en alguna capacidad definida, en caso de error. Por ejemplo, una aplicación web podría diseñarse para seguir funcionando incluso aunque se produzca un error en un único servidor web. La tolerancia a errores se puede lograr mediante redundancia, conmutación por error, creación de particiones, degradación correcta y otras técnicas.
La tolerancia a errores también requiere que las aplicaciones gestionen errores transitorios. Al compilar su propio código, es posible que tenga que habilitar el control de errores transitorios usted mismo. Algunos servicios de Azure proporcionan una gestión integrada de errores transitorios para algunas situaciones. Por ejemplo, de forma predeterminada, Azure Logic Apps reintenta automáticamente las solicitudes con errores a otros servicios. Para obtener más información, consulte Recomendaciones para el control de errores transitorios.
Redundancia
La redundancia es la práctica de duplicar instancias o datos para aumentar la confiabilidad de la carga de trabajo.
La redundancia se puede lograr mediante la distribución de réplicas o instancias redundantes de una de las maneras siguientes:
- Dentro de un centro de datos (redundancia local)
- Entre zonas de disponibilidad dentro de una región (redundancia de zona)
- Entre regiones (redundancia geográfica).
Estos son algunos ejemplos de cómo algunos servicios de Azure proporcionan opciones de redundancia:
- Azure App Service permite ejecutar varias instancias de la aplicación para asegurarse de que la aplicación permanezca disponible incluso aunque se produzca un error en una instancia. Si habilita la redundancia de zona, esas instancias se distribuirán entre varias zonas de disponibilidad en la región de Azure que use.
- Azure Storage proporciona alta disponibilidad mediante la replicación automática de datos al menos tres veces. Puede distribuir esas réplicas entre zonas de disponibilidad habilitando el almacenamiento con redundancia de zona (ZRS) y en muchas regiones también puede replicar los datos de almacenamiento entre regiones mediante el almacenamiento con redundancia geográfica (GRS).
- Azure SQL Database tiene varias réplicas para asegurarse de que los datos permanezcan disponibles incluso aunque se produzca un error en una réplica.
Para obtener más información sobre la redundancia, consulte Recomendaciones para el diseño de redundancia y Recomendaciones para el uso de zonas y regiones de disponibilidad.
Escalabilidad y elasticidad
La escalabilidad y la elasticidad son las capacidades de un sistema para controlar la mayor carga mediante la adición y eliminación de recursos (escalabilidad) y para hacerlo rápidamente a medida que cambian los requisitos (elasticidad). La escalabilidad y la elasticidad pueden ayudar a un sistema a mantener la disponibilidad durante las cargas máximas.
Muchos servicios de Azure admiten escalabilidad. Estos son algunos ejemplos:
- Azure Virtual Machine Scale Sets, Azure API Management y otros servicios admiten la escalabilidad automática de Azure Monitor. Con el escalado automático de Azure Monitor, puede especificar políticas como "cuando mi CPU supere constantemente el 80 %, agregar otra instancia".
- Azure Functions puede aprovisionar dinámicamente instancias para atender las solicitudes.
- Azure Cosmos DB admite el rendimiento de escalabilidad automática, donde el servicio puede administrar automáticamente los recursos asignados a las bases de datos en función de las directivas que especifique.
La escalabilidad es un factor clave que se debe tener en cuenta durante un mal funcionamiento parcial o completo. Si una réplica o una instancia de proceso no están disponibles, es posible que los componentes restantes necesiten cargar más para controlar la carga que el nodo defectuoso controló anteriormente. Considere la posibilidad de realizar un sobreaprovisionamiento si su sistema no puede escalar lo suficientemente rápido como para manejar los cambios esperados en la carga.
Para obtener más información sobre cómo diseñar un sistema escalable y elástico, consulte Recomendaciones para diseñar una estrategia de escalado confiable.
Técnicas de implementación sin tiempo de inactividad
Las implementaciones y otros cambios del sistema presentan un riesgo significativo de tiempo de inactividad. Dado que el riesgo de tiempo de inactividad es un desafío para los requisitos de alta disponibilidad, es importante utilizar prácticas de implementación de tiempo de inactividad cero para realizar actualizaciones y cambios de configuración sin ningún tiempo de inactividad requerido.
Las técnicas de implementación sin tiempo de inactividad pueden ser las siguientes:
- Actualizar un subconjunto de los recursos a la vez.
- Controlar la cantidad de tráfico que llega a la nueva implementación.
- Supervisión de cualquier impacto en los usuarios o el sistema.
- Corregir rápidamente el problema, como revertir a una implementación conocida anterior.
Para obtener más información sobre las técnicas de implementación sin tiempo de inactividad, consulte Prácticas de implementación segura.
Azure usa enfoques de implementación sin tiempo de inactividad para nuestros propios servicios. Al compilar sus propias aplicaciones, puede adoptar implementaciones de tiempo de inactividad cero a través de una variedad de enfoques, como los siguientes:
- Azure Container Apps proporciona varias revisiones de la aplicación, que se pueden usar para lograr implementaciones sin tiempo de inactividad.
- Azure Kubernetes Service (AKS) admite una variedad de técnicas de implementación sin tiempo de inactividad.
Aunque las implementaciones de tiempo de inactividad cero suelen estar asociadas a las implementaciones de aplicaciones, también se deben usar para los cambios de configuración. Estas son algunas maneras de aplicar los cambios de configuración de forma segura:
- Azure Storage le permite cambiar sus claves de acceso de la cuenta de almacenamiento en varias fases, lo que evita el tiempo de inactividad durante las operaciones de rotación de claves.
- Azure App Configuration proporciona marcas de características, instantáneasy otras funcionalidades que le ayudarán a controlar cómo se aplican los cambios de configuración.
Si decide no implementar implementaciones con tiempo de inactividad cero, asegúrese de definir ventanas de mantenimiento para poder realizar cambios en el sistema en el momento en que los usuarios lo esperan.
Pruebas automatizadas
Es importante probar la capacidad de la solución de resistir las interrupciones y los errores que considere tener en el ámbito de la alta disponibilidad. Muchos de estos errores se pueden simular en entornos de prueba. Probar la capacidad de la solución para tolerar o recuperarse automáticamente de una variedad de tipos de errores se denomina ingeniería de caos. La ingeniería de caos es fundamental para las organizaciones de bastante antigüedad con estrictos estándares para la alta disponibilidad. Azure Chaos Studio es una herramienta de ingeniería de caos que puede simular algunos tipos de errores comunes.
Para obtener más información, consulte Recomendaciones para diseñar una estrategia de pruebas de confiabilidad.
Supervisión y alertas
La supervisión le permite conocer el estado del sistema, incluso cuando se realizan mitigaciones automatizadas. La supervisión es fundamental para comprender cómo se comporta la solución y para observar las señales tempranas de errores, como el aumento de las tasas de error o el consumo elevado de recursos. Con las alertas, puede recibir de forma proactiva cambios importantes en su entorno.
Azure proporciona una variedad de funcionalidades de supervisión y alertas, entre las que se incluyen las siguientes:
- Azure Monitor recopila registros y métricas de recursos y aplicaciones de Azure, y puede enviar alertas y mostrar datos en los paneles.
- Application Insights de Azure Monitor proporciona una supervisión detallada de las aplicaciones.
- Azure Service Health y Azure Resource Health supervisa el estado de la plataforma de Azure y los recursos.
- Los eventos programados avisan cuándo se planifica el mantenimiento de las máquinas virtuales.
Para obtener más información, consulte Recomendaciones para diseñar una estrategia de supervisión y alertas confiable.
Recuperación ante desastres
Un desastre es un evento distinto, poco común e importante que tiene un impacto mayor y más duradero que el que una aplicación puede mitigar a través del aspecto de alta disponibilidad de su diseño. Algunos ejemplos de desastres son:
- Desastres naturales, como huracanes, terremotos, inundaciones o incendios.
- Errores humanos que producen un gran impacto, como eliminar accidentalmente los datos de producción o un firewall mal configurado que expone datos confidenciales.
- Incidentes de seguridad principales, como ataques por denegación de servicio o ransomware que provocan daños en los datos, pérdida de datos o interrupciones del servicio.
La recuperación ante desastres consiste en planear cómo responde a estos tipos de situaciones.
Nota:
Debe seguir los procedimientos recomendados en la solución para minimizar la probabilidad de estos eventos. Sin embargo, incluso después de una planeación proactiva cuidadosa, es prudente planear cómo respondería a estas situaciones si surgen.
Requisitos de recuperación ante desastres.
Debido a la rareza y gravedad de los eventos de desastre, el planeamiento de recuperación ante desastres aporta diferentes expectativas para la respuesta. Muchas organizaciones aceptan el hecho de que, en un escenario de desastre, cierto nivel de tiempo de inactividad o pérdida de datos es inevitable. Un plan de recuperación ante desastres completo debe especificar los siguientes requisitos empresariales críticos para cada flujo:
El objetivo de punto de recuperación (RPO) es la duración máxima de la pérdida de datos que es aceptable durante un desastre. El RPO se mide en unidades de tiempo, como "30 minutos de datos" o "cuatro horas de datos".
El objetivo de tiempo de recuperación (RTO) es la duración máxima del tiempo de inactividad aceptable en caso de desastre, donde el "tiempo de inactividad" se define según su especificación. El RTO también se mide en unidades de tiempo, como "ocho horas de tiempo de inactividad".
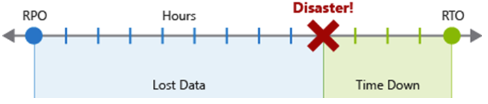
Cada componente o flujo de la carga de trabajo puede tener valores de RPO y RTO individuales. Examine los riesgos del escenario de desastres y las posibles estrategias de recuperación al decidir cuáles son los requisitos. El proceso de especificar un valor RPO y RTO crea eficazmente requisitos de recuperación ante desastres para la carga de trabajo como resultado de sus preocupaciones empresariales únicas (costos, impacto, pérdida de datos, etc.).
Nota:
Aunque es tentador apuntar a un RTO y RPO de cero (sin tiempo de inactividad y sin pérdida de datos en caso de desastre), en la práctica es difícil y costoso de implementar. Es importante que las partes interesadas técnicas y empresariales analicen estos requisitos juntos y decidan los requisitos realistas. Para obtener más información, consulte Recomendaciones para definir objetivos de confiabilidad.
Planes de recuperación ante desastres
Independientemente de la causa del desastre, es importante crear un plan de recuperación ante desastres bien definido y probable. Ese plan se usará como parte de la infraestructura y el diseño de aplicaciones para admitirlo activamente. Puede crear varios planes de recuperación ante desastres para diferentes tipos de situaciones. Los planes de recuperación ante desastres suelen depender de controles de procesos e intervención manual.
La recuperación ante desastres no es una característica automática de Azure. Sin embargo, muchos servicios proporcionan características y funcionalidades que puede usar para admitir las estrategias de recuperación ante desastres. Debe revisar las guías de confiabilidad para cada servicio de Azure para comprender cómo funciona el servicio y sus funcionalidades y, a continuación, asignar esas funcionalidades al plan de recuperación ante desastres.
En las secciones siguientes se enumeran algunos elementos comunes de un plan de recuperación ante desastres y se describe cómo Azure puede ayudarle a lograrlos.
Conmutación por error y conmutación por recuperación
Algunos planes de recuperación ante desastres implican el aprovisionamiento de una implementación secundaria en otra ubicación. Si un desastre afecta a la implementación principal de la solución, el tráfico se puede conmutar por error al otro sitio. La conmutación por error requiere una planeación e implementación cuidadosas. Azure proporciona una variedad de servicios para ayudar con la conmutación por error, como:
- Azure Site Recovery proporciona conmutación por error automatizada para entornos locales y soluciones hospedadas en máquinas virtuales en Azure.
- Azure Front Door y Azure Traffic Manager admiten la conmutación por error automatizada del tráfico entrante entre diferentes implementaciones de la solución, como en diferentes regiones.
Normalmente, se tarda algún tiempo en un proceso de conmutación por error para detectar que se ha producido un error en la instancia principal y cambiar a la instancia secundaria. Asegúrese de que el RTO de la carga de trabajo esté alineado con el tiempo de conmutación por error.
También es importante tener en cuenta la conmutación por recuperación, que es el proceso por el que se restauran las operaciones en la región primaria después de recuperarse. La conmutación por recuperación puede ser compleja de planear e implementar. Por ejemplo, es posible que los datos de la región primaria se hayan escrito después de que se iniciara la conmutación por error. Deberá tomar decisiones empresariales cuidadosas sobre cómo controlar esos datos.
Copias de seguridad
Las copias de seguridad implican realizar una copia de los datos y almacenarlos de forma segura durante un período de tiempo definido. Con las copias de seguridad, puede recuperarse de desastres cuando la conmutación automática por error a otra réplica no es posible o cuando se han producido daños en los datos.
Al usar copias de seguridad como parte de un plan de recuperación ante desastres, es importante tener en cuenta lo siguiente:
Ubicación de almacenamiento. Cuando se usan copias de seguridad como parte de un plan de recuperación ante desastres, deben almacenarse por separado en los datos principales. Normalmente, las copias de seguridad se almacenan en otra región de Azure.
Pérdida de datos. Dado que las copias de seguridad normalmente se realizan con poca frecuencia, la restauración de copias de seguridad suele implicar la pérdida de datos. Por este motivo, la recuperación de copia de seguridad debe usarse como último recurso y un plan de recuperación ante desastres debe especificar la secuencia de pasos e intentos de recuperación que deben realizarse antes de realizar una restauración desde una copia de seguridad. Es importante asegurarse de que el RPO de carga de trabajo esté alineado con el intervalo de copia de seguridad.
Tiempo de recuperación. La restauración de copias de seguridad suele tardar tiempo, por lo que es fundamental probar las copias de seguridad y los procesos de restauración para comprobar su integridad y comprender cuánto tarda el proceso de restauración. Asegúrese de que el RTO de la carga de trabajo tenga en cuenta el tiempo necesario para restaurar la copia de seguridad.
Muchos servicios de almacenamiento y datos de Azure admiten copias de seguridad, como los siguientes:
- Azure Backup proporciona copias de seguridad automatizadas para discos de máquina virtual, cuentas de almacenamiento, AKS y una gran variedad de otros orígenes.
- Muchos servicios de base de datos de Azure, incluidos Azure SQL Database y Azure Cosmos DB, tienen una funcionalidad de copia de seguridad automatizada para las bases de datos.
- Azure Key Vault proporciona características para realizar copias de seguridad de los secretos, certificados y claves.
Implementaciones automatizadas
Para implementar y configurar rápidamente los recursos necesarios por si se produce un desastre, use recursos de infraestructura como código (IaC), como archivos de Bicep, plantillas de ARM o un archivo de configuración de Terraform. El uso de IaC reduce el tiempo de recuperación y el potencial de error, en comparación con la implementación y configuración manual de recursos.
Pruebas y simulacros
Es fundamental validar y probar de forma rutinaria los planes de recuperación ante desastres, así como su estrategia de confiabilidad más amplia. Incluya todos los procesos humanos en sus simulacros y no se centre solo en los procesos técnicos.
Si no ha probado los procesos de recuperación en una simulación de desastre, es más probable que se enfrente a problemas importantes al usarlos en un desastre real. Además, al probar los planes de recuperación ante desastres y los procesos necesarios, puede validar la viabilidad de su RTO.
Para obtener más información, consulte Recomendaciones para diseñar una estrategia de pruebas de confiabilidad.
Contenido relacionado
- Use las guías de confiabilidad del servicio de Azure para comprender cómo cada servicio de Azure admite la confiabilidad en su diseño y para obtener información sobre las funcionalidades que puede crear en los planes de alta disponibilidad y recuperación ante desastres.
- Use el Marco de buena arquitectura de Azure: pilar de confiabilidad para obtener más información sobre cómo diseñar una carga de trabajo fiable en Azure.
- Use la perspectiva de Marco de buena arquitectura de los servicios de Azure para obtener más información sobre cómo configurar cada servicio de Azure para satisfacer sus requisitos de confiabilidad y los demás pilares del Marco de buena arquitectura.
- Para obtener más información sobre el planeamiento de la recuperación ante desastres, consulte Recomendaciones para diseñar una estrategia de recuperación ante desastres.