Deploy and configure care management analytics (preview) in healthcare data solutions
[This article is prerelease documentation and is subject to change.]
Care management analytics (preview) enables healthcare organizations to create analytical scenarios that support data-driven decision-making and improve patient outcomes. You can deploy and configure this capability after deploying healthcare data solutions to your Fabric workspace and the healthcare data foundations capability. This article outlines the deployment process and explains how to set up the sample data.
Care management analytics (preview) is an optional capability under healthcare data solutions in Microsoft Fabric. You have the flexibility to decide whether or not to use it, depending on your specific needs or scenarios.
Prerequisites
Install the foundational notebooks and pipelines in Deploy healthcare data foundations.
Deploy and configure CMS claims data transformations (preview), and run the claims data transformations pipeline.
Deploy the FHIR/clinical sample datasets as explained in Deploy sample data. We use this sample data to test the capability.
Deploy care management analytics (preview)
You can deploy the capability using the setup module explained in Healthcare data solutions: Deploy healthcare data foundations.
If you didn't use the setup module to deploy the capability and want to use the capability tile instead, follow these steps:
Go to the healthcare data solutions home page on Fabric.
Select the care management analytics (preview) tile.

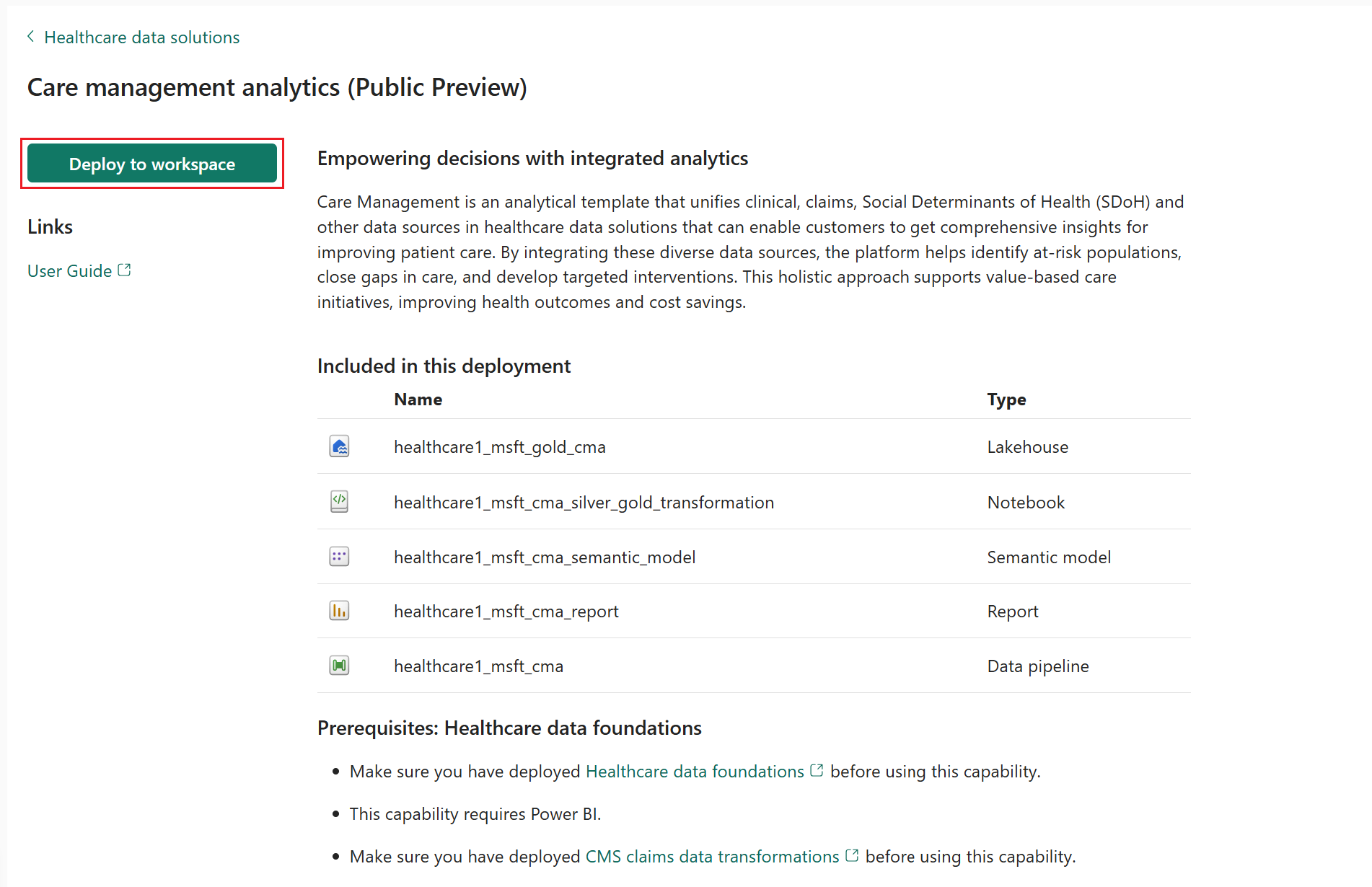
On the capability page, select Deploy to workspace.
The deployment can take a few minutes to complete. Don't close the tab or the browser while deployment is in progress. While you wait, you can work in another tab.
After the deployment completes, you can see a notification on the message bar.
Select Manage capability from the message bar to go to the Capability management page.
Here, you can view, configure, and manage the artifacts deployed with the capability.


Artifacts
The capability installs the following artifacts in your healthcare data solutions environment:
| Artifact | Type | Description |
|---|---|---|
| healthcare#_msft_gold_cma | Lakehouse | A custom-built gold lakehouse for care management analytics, where data is refined and structured for advanced analytics and reporting. |
| healthcare#_msft_cma_silver_gold_transformation | Notebook | Transforms and aggregates data from the silver lakehouse to the care management analytics gold lakehouse. |
| healthcare#_msft_cma | Data pipeline | Sequentially runs a series of notebooks to transform the data from its raw state in the bronze lakehouse to a transformed state in the silver lakehouse. It also aggregates data in the gold lakehouse. |
| healthcare#_msft_cma_semantic_model | Semantic model | A comprehensive data model optimized for predictive analytics and reporting dashboards, providing insights into care quality, patient outcomes, and operational efficiency. |
| healthcare#_msft_cma_report | Report | A Power BI template dashboard, with interactive reports from the care management analytics data model, to help you make data-driven decisions. |
Set up sample data
The sample data provided with healthcare data solutions includes FHIR (clinical) sample datasets. We use this sample data to run and test the care management analytics (preview) pipeline. You can also explore data transformation and progression through the bronze, silver, and gold lakehouses.
To access the sample datasets, verify whether you downloaded the clinical sample data into the following folder in the bronze lakehouse: SampleData\Clinical\FHIR-NDJSON\FHIR-HDS\51KSyntheticPatients. The Deploy sample data step automatically deploys the 51KSyntheticPatients sample dataset to the sample data folder.
Next, you must upload the sample data to the Process folder. Drop the clinical sample data files into this folder, so they can automatically move to an organized folder structure within the bronze lakehouse. To learn more about the unified folder structure, see Unified folder structure.
To upload the sample data:
- Go to
Process\Clinical\FHIR-NDJSON\FHIR-HDS\<namespace_folder>in the bronze lakehouse. - Select the ellipsis (...) beside the folder name > Upload > Upload files.
- Select and upload the clinical sample data from the sample data folder.
Alternatively, you can run the following code snippet in a notebook to copy the sample data into the Process folder.
In your healthcare data solutions Fabric workspace, select + New item.
On the New item pane, search and select Notebook.
Copy the following code snippet into the notebook:
from notebookutils import mssparkutils source_path = 'abfss://<workspace_name>@onelake.dfs.fabric.microsoft.com/<bronze_lakehouse_name>/Files/SampleData/Clinical/FHIR-NDJSON/FHIR-HDS/51KSyntheticPatients' target_path = 'abfss://<workspace_name>@onelake.dfs.fabric.microsoft.com/<bronze_lakehouse_name>/Files/Process/Clinical/FHIR-NDJSON/FHIR-HDS/' mssparkutils.fs.fastcp(source_path,target_path)Run the notebook. The clinical datasets now move to the designated location within the Process folder.