Transform data by running an Azure HDInsight activity
The Azure HDInsight activity in Data Factory for Microsoft Fabric allows you to orchestrate the following Azure HDInsight job types:
- Execute Hive queries
- Invoke a MapReduce program
- Execute Pig queries
- Execute a Spark program
- Execute a Hadoop Stream program
This article provides a step-by-step walkthrough that describes how to create an Azure HDInsight activity using the Data Factory interface.
Prerequisites
To get started, you must complete the following prerequisites:
- A tenant account with an active subscription. Create an account for free.
- A workspace is created.
Add an Azure HDInsight (HDI) activity to a pipeline with UI
Create a new data pipeline in your workspace.
Search for Azure HDInsight from the home screen card and select it or select the activity from the Activities bar to add it to the pipeline canvas.
Creating the activity from the home screen card:
Creating the activity from the Activities bar:
Select the new Azure HDInsight activity on the pipeline editor canvas if it isn't already selected.
Refer to the General settings guidance to configure the options found in the General settings tab.

Configure the HDI cluster
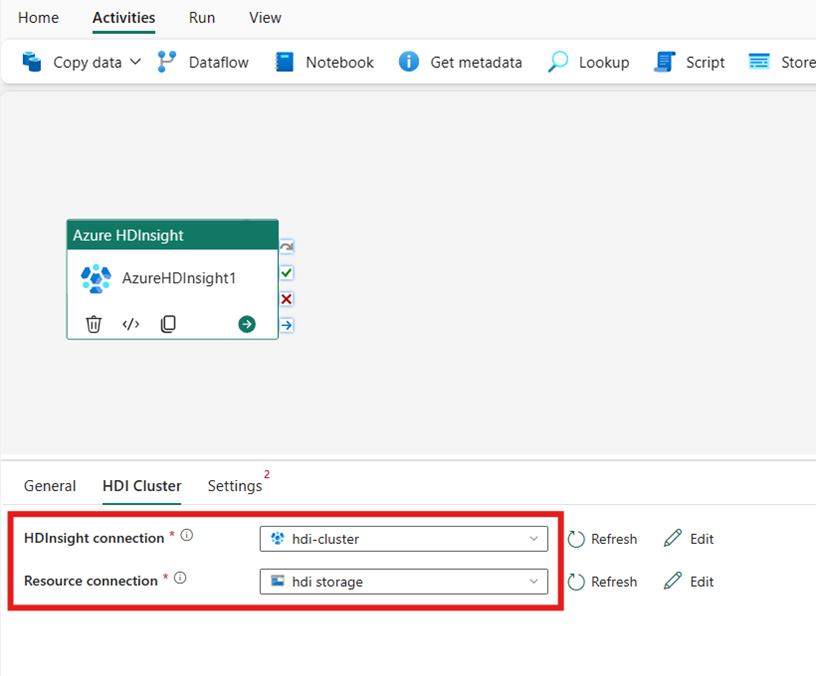
Select the HDI Cluster tab. Then you can choose an existing or create a new HDInsight connection.
For the Resource connection, choose the Azure Blob Storage that references your Azure HDInsight cluster. You can choose an existing Blob store or create a new one.
Configure settings
Select the Settings tab to see the advanced settings for the activity.
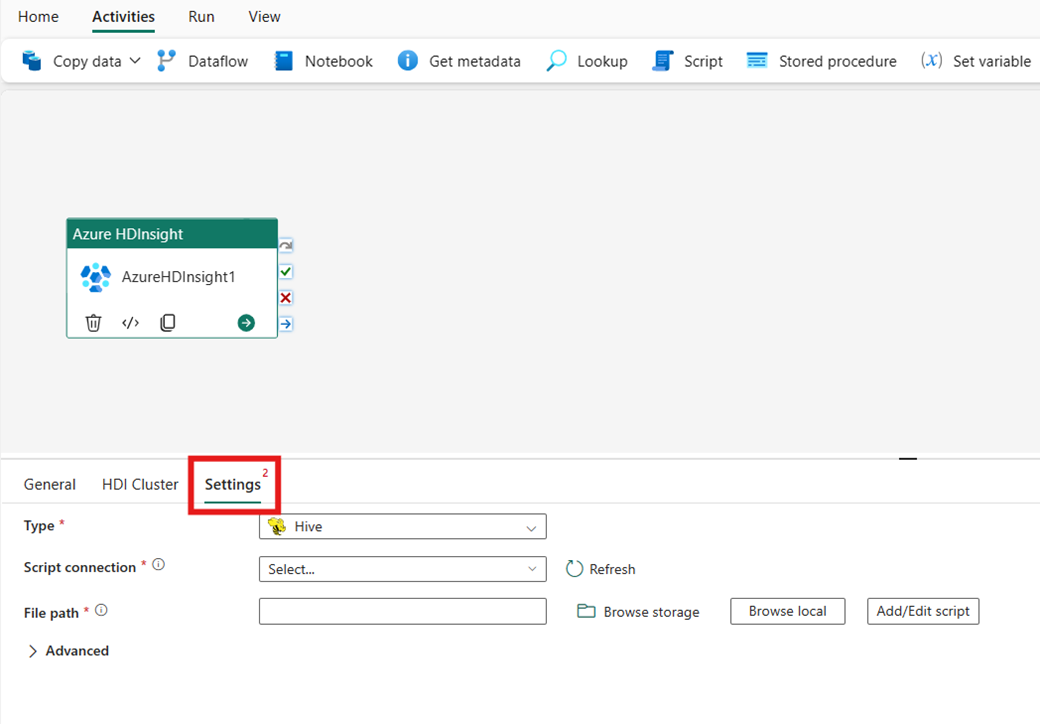
All advanced cluster properties and dynamic expressions supported in the Azure Data Factory and Synapse Analytics HDInsight linked service are now also supported in the Azure HDInsight activity for Data Factory in Microsoft Fabric, under the Advanced section in the UI. These properties all support easy-to-use custom parameterized expressions with dynamic content.
Cluster type
To configure settings for your HDInsight cluster, first choose its Type from the available options, including Hive, Map Reduce, Pig, Spark, and Streaming.
Hive
If you choose Hive for Type, the activity executes a Hive query. You can optionally specify the Script connection referencing a storage account that holds the Hive type. By default, the storage connection you specified in the HDI Cluster tab are used. You need to specify the File path to be executed on Azure HDInsight. Optionally, you can specify more configurations in the Advanced section, Debug information, Query timeout, Arguments, Parameters, and Variables.
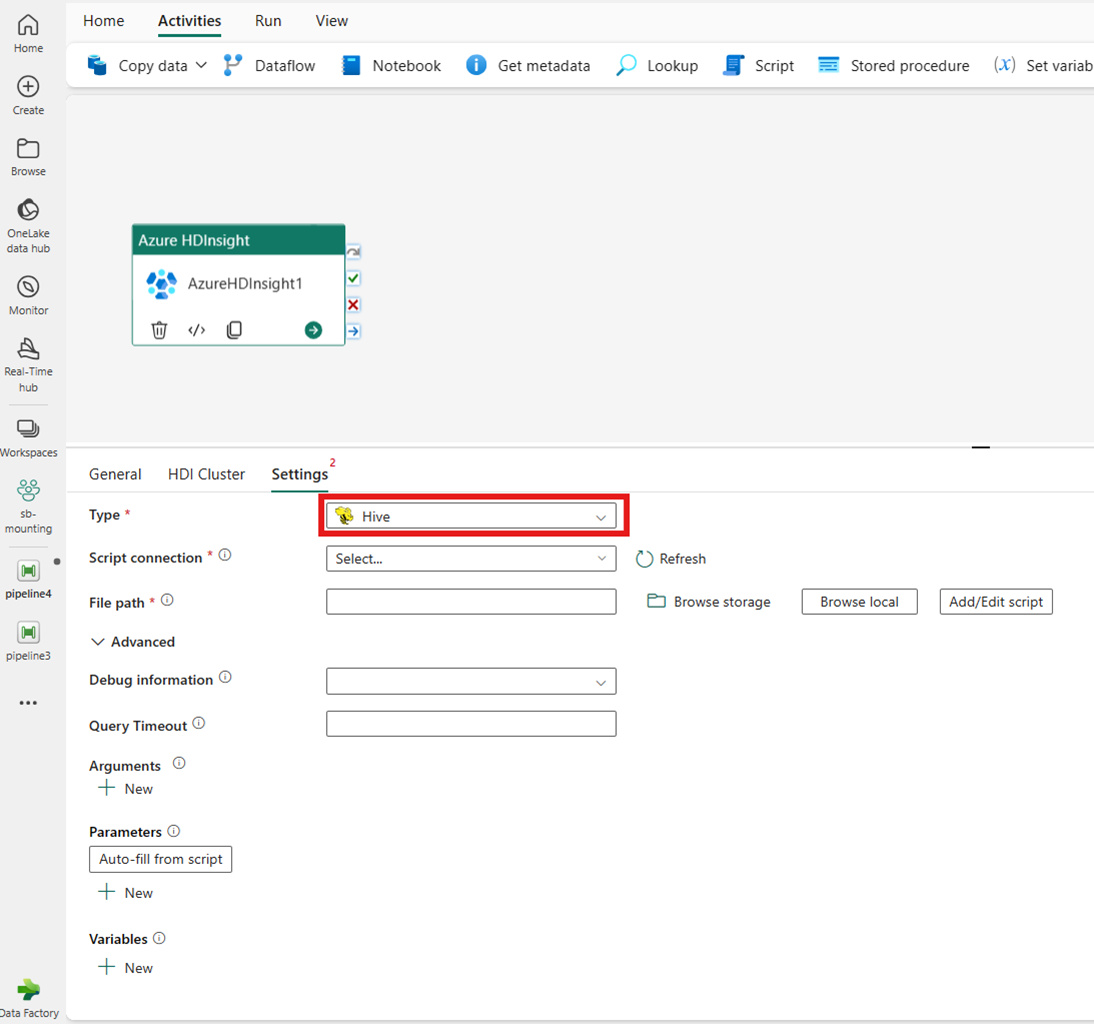
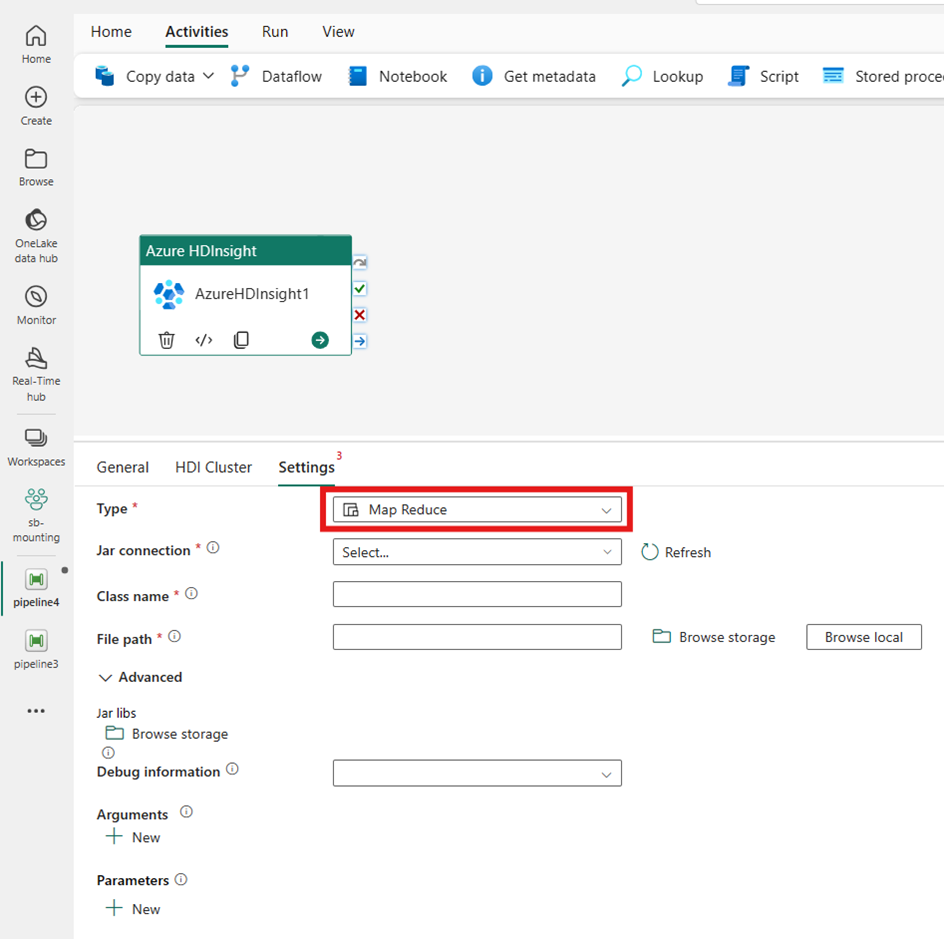
Map Reduce
If you choose Map Reduce for Type, the activity invokes a Map Reduce program. You can optionally specify in the Jar connection referencing a storage account that holds the Map Reduce type. By default, the storage connection you specified in the HDI Cluster tab is used. You need to specify the Class name and File path to be executed on Azure HDInsight. Optionally you can specify more configuration details, such as importing Jar libraries, debug information, arguments, and parameters under the Advanced section.
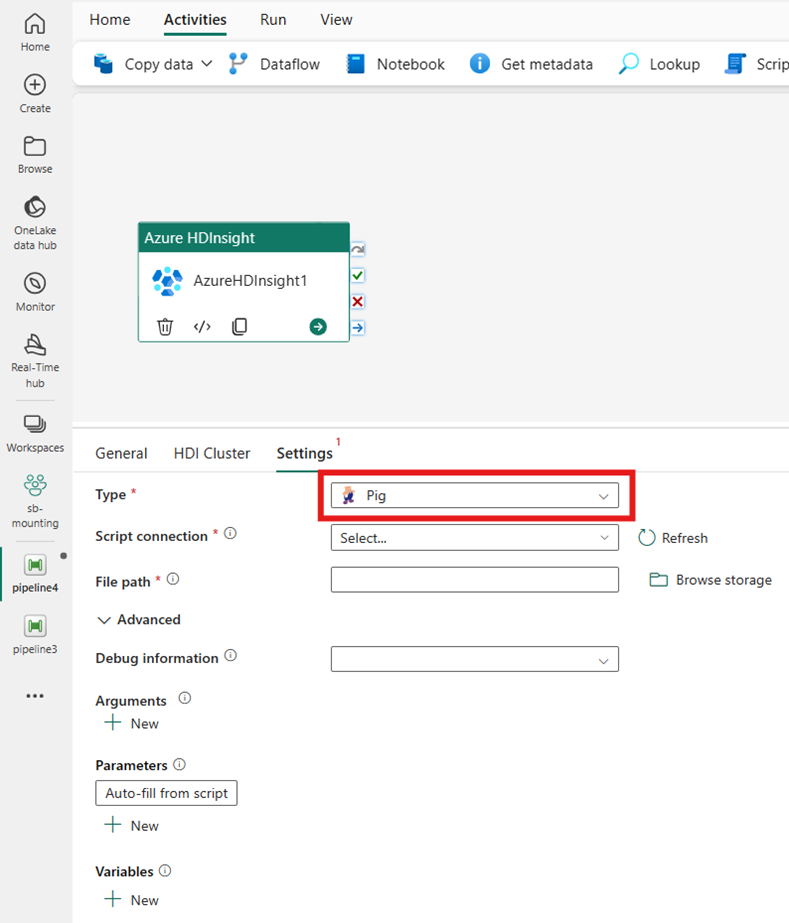
Pig
If you choose Pig for Type, the activity invokes a Pig query. You can optionally specify the Script connection setting that references the storage account that holds the Pig type. By default, the storage connection that you specified in the HDI Cluster tab is used. You need to specify the File path to be executed on Azure HDInsight. Optionally you can specify more configurations, such as debug information, arguments, parameters, and variables under the Advanced section.
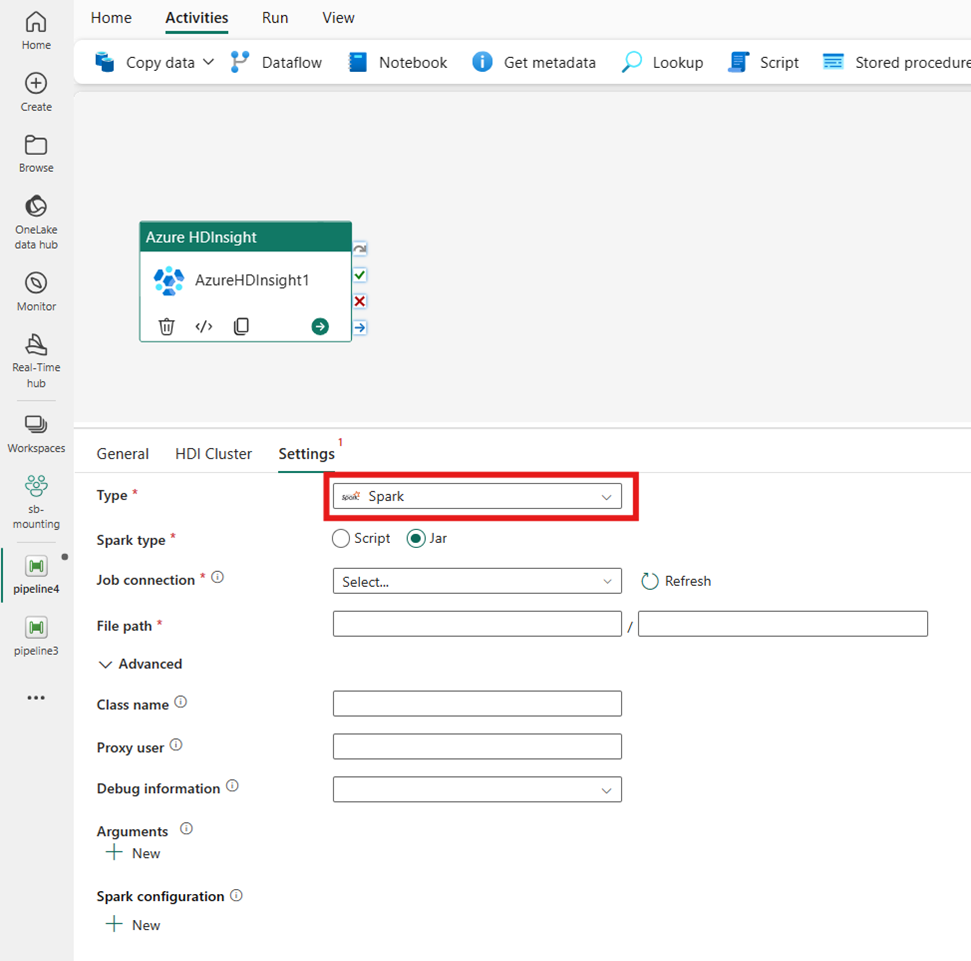
Spark
If you choose Spark for Type, the activity invokes a Spark program. Select either Script or Jar for the Spark type. You can optionally specify the Job connection referencing the storage account that holds the Spark type. By default, the storage connection you specified in the HDI Cluster tab is used. You need to specify the File path to be executed on Azure HDInsight. Optionally you can specify more configurations, such as class name, proxy user, debug information, arguments, and spark configuration under the Advanced section.
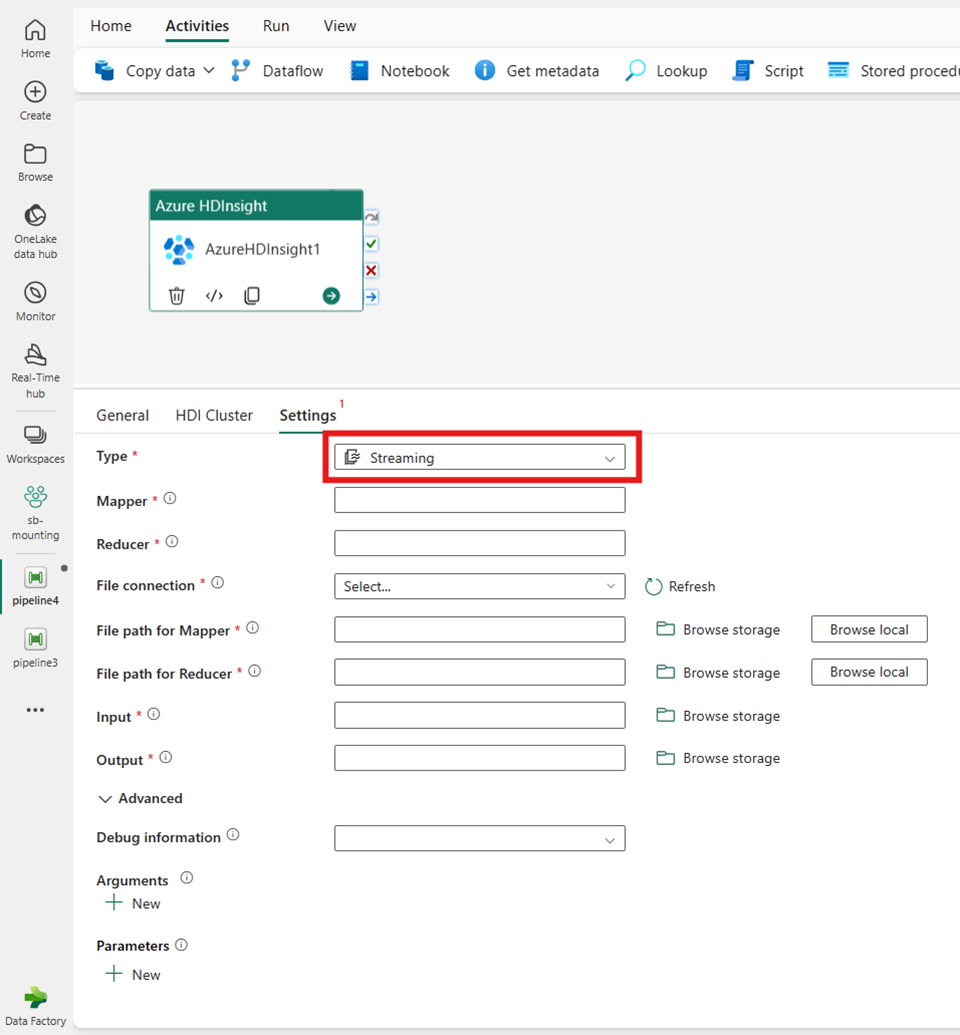
Streaming
If you choose Streaming for Type, the activity invokes a Streaming program. Specify the Mapper and Reducer names, and you can optionally specify the File connection referencing the storage account that holds the Streaming type. By default, the storage connection that you specified in the HDI Cluster tab is used. You need to specify the File path for Mapper and File path for Reducer to be executed on Azure HDInsight. Include the Input and Output options as well for the WASB path. Optionally you can specify more configurations, such as debug information, arguments, and parameters under the Advanced section.
Property reference
| Property | Description | Required |
|---|---|---|
| type | For Hadoop Streaming Activity, the activity type is HDInsightStreaming | Yes |
| mapper | Specifies the name of the mapper executable | Yes |
| reducer | Specifies the name of the reducer executable | Yes |
| combiner | Specifies the name of the combiner executable | No |
| file connection | Reference to an Azure Storage Linked Service used to store the Mapper, Combiner, and Reducer programs to be executed. | No |
| Only Azure Blob Storage and ADLS Gen2 connections are supported here. If you don't specify this connection, the storage connection defined in the HDInsight connection is used. | ||
| filePath | Provide an array of path to the Mapper, Combiner, and Reducer programs stored in the Azure Storage referred to by the file connection. | Yes |
| input | Specifies the WASB path to the input file for the Mapper. | Yes |
| output | Specifies the WASB path to the output file for the Reducer. | Yes |
| getDebugInfo | Specifies when the log files are copied to the Azure Storage used by HDInsight cluster (or) specified by scriptLinkedService. | No |
| Allowed values: None, Always, or Failure. Default value: None. | ||
| arguments | Specifies an array of arguments for a Hadoop job. The arguments are passed as command-line arguments to each task. | No |
| defines | Specify parameters as key/value pairs for referencing within the Hive script. | No |
Save and run or schedule the pipeline
After you configure any other activities required for your pipeline, switch to the Home tab at the top of the pipeline editor, and select the save button to save your pipeline. Select Run to run it directly, or Schedule to schedule it. You can also view the run history here or configure other settings.
