Manage Apache Spark libraries in Microsoft Fabric
A library is a collection of prewritten code that developers can import to provide functionality. By using libraries, you can save time and effort by not having to write code from scratch to do common tasks. Instead, import the library and use its functions and classes to achieve the desired functionality. Microsoft Fabric provides multiple mechanisms to help you manage and use libraries.
- Built-in libraries: Each Fabric Spark runtime provides a rich set of popular preinstalled libraries. You can find the full built-in library list in Fabric Spark Runtime.
- Public libraries: Public libraries are sourced from repositories such as PyPI and Conda, which are currently supported.
- Custom libraries: Custom libraries refer to code that you or your organization build. Fabric supports them in the .whl, .jar, and .tar.gz formats. Fabric supports .tar.gz only for the R language. For Python custom libraries, use the .whl format.
Summary of library management best practices
The following scenarios describe best practices when using libraries in Microsoft Fabric.
Scenario 1: Admin sets default libraries for the workspace
To set default libraries, you have to be the administrator of the workspace. As admin, you can perform these tasks:
- Create a new environment
- Install the required libraries in the environment
- Attach this environment as the workspace default
When your notebooks and Spark job definitions are attached to the Workspace settings, they start sessions with the libraries installed in the workspace's default environment.
Scenario 2: Persist library specifications for one or multiple code items
If you have common libraries for different code items and don't require frequent update, install the libraries in an environment and attach it to the code items is a good choice.
It will take some time to make the libraries in environments become effective when publishing. It normally takes 5-15 minutes, depending on the complexity of the libraries. During this process, the system will help to resolve the potential conflicts and download required dependencies.
One benefit of this approach is that the successfully installed libraries are guaranteed to be available when the Spark session is started with environment attached. It saves effort of maintaining common libraries for your projects.
It's highly recommended for pipeline scenarios with its stability.
Scenario 3: Inline installation in interactive run
If you are using the notebooks to write code interactively, using inline installation to add extra new PyPI/conda libraries or validate your custom libraries for one-time use is the best practice. Inline commands in Fabric allow you to have the library effective in the current notebook Spark session. It allows the quick installation but the installed library doesn't persist across different sessions.
Since %pip install generating different dependency trees from time to time, which might lead to library conflicts, inline commands are turned off by default in the pipeline runs and NOT recommended to be used in your pipelines.
Summary of supported library types
| Library type | Environment library management | Inline installation |
|---|---|---|
| Python Public (PyPI & Conda) | Supported | Supported |
| Python Custom (.whl) | Supported | Supported |
| R Public (CRAN) | Not supported | Supported |
| R custom (.tar.gz) | Supported as custom library | Supported |
| Jar | Supported as custom library | Supported |
Inline installation
Inline commands support managing libraries in each notebook sessions.
Python inline installation
The system restarts the Python interpreter to apply the change of libraries. Any variables defined before you run the command cell are lost. We strongly recommend that you put all the commands for adding, deleting, or updating Python packages at the beginning of your notebook.
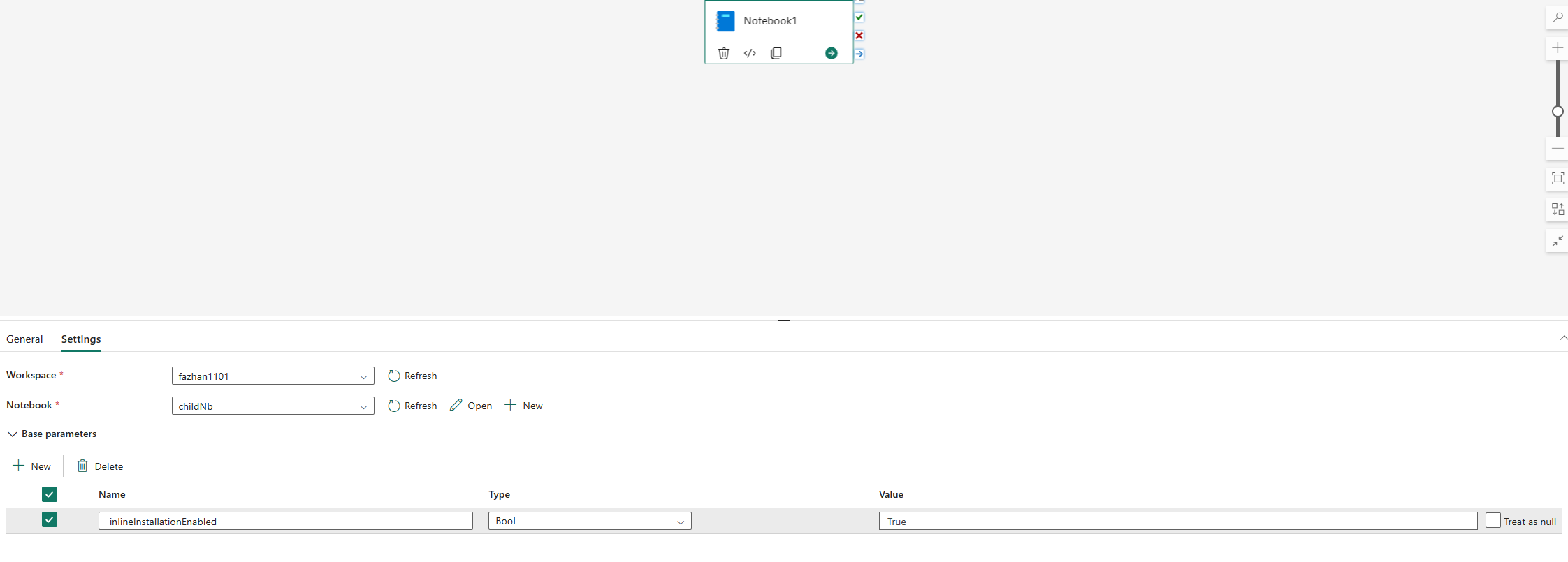
The inline commands for managing Python libraries are disabled in notebook pipeline run by default. If you want to enable %pip install for pipeline, add "_inlineInstallationEnabled" as bool parameter equals True in the notebook activity parameters.
Note
The %pip install may lead to inconsistent results from time to time. It's recommended to install library in an environment and use it in the pipeline.
In notebook reference runs, inline commands for managing Python libraries are not supported. To ensure the correctness of execution, it is recommended to remove these inline commands from the referenced notebook.
We recommend %pip instead of !pip. !pip is an IPython built-in shell command, which has the following limitations:
!piponly installs a package on the driver node, not executor nodes.- Packages that install through
!pipdon't affect conflicts with built-in packages or whether packages are already imported in a notebook.
However, %pip handles these scenarios. Libraries installed through %pip are available on both driver and executor nodes and are still effective even the library is already imported.
Tip
The %conda install command usually takes longer than the %pip install command to install new Python libraries. It checks the full dependencies and resolves conflicts.
You might want to use %conda install for more reliability and stability. You can use %pip install if you are sure that the library you want to install doesn't conflict with the preinstalled libraries in the runtime environment.
For all available Python inline commands and clarifications, see %pip commands and %conda commands.
Manage Python public libraries through inline installation
In this example, see how to use inline commands to manage libraries. Suppose you want to use altair, a powerful visualization library for Python, for a one-time data exploration. Suppose the library isn't installed in your workspace. The following example uses conda commands to illustrate the steps.
You can use inline commands to enable altair on your notebook session without affecting other sessions of the notebook or other items.
Run the following commands in a notebook code cell. The first command installs the altair library. Also, install vega_datasets, which contains a semantic model you can use to visualize.
%conda install altair # install latest version through conda command %conda install vega_datasets # install latest version through conda commandThe output of the cell indicates the result of the installation.
Import the package and semantic model by running the following code in another notebook cell.
import altair as alt from vega_datasets import dataNow you can play around with the session-scoped altair library.
# load a simple dataset as a pandas DataFrame cars = data.cars() alt.Chart(cars).mark_point().encode( x='Horsepower', y='Miles_per_Gallon', color='Origin', ).interactive()
Manage Python custom libraries through inline installation
You can upload your Python custom libraries to the resources folder of your notebook or the attached environment. The resources folders are the built-in file system provided by each notebook and environments. See Notebook resources for more details. After your upload, you can drag-and-drop the custom library to a code cell, the inline command to install the library is automatically generated. Or you can use the following command to install.
# install the .whl through pip command from the notebook built-in folder
%pip install "builtin/wheel_file_name.whl"
R inline installation
To manage R libraries, Fabric supports the install.packages(), remove.packages(), and devtools:: commands. For all available R inline commands and clarifications, see install.packages command and remove.package command.
Manage R public libraries through inline installation
Follow this example to walk through the steps of installing an R public library.
To install an R feed library:
Switch the working language to SparkR (R) in the notebook ribbon.
Install the caesar library by running the following command in a notebook cell.
install.packages("caesar")Now you can play around with the session-scoped caesar library with a Spark job.
library(SparkR) sparkR.session() hello <- function(x) { library(caesar) caesar(x) } spark.lapply(c("hello world", "good morning", "good evening"), hello)
Manage Jar libraries through inline installation
The .jar files are support at notebook sessions with following command.
%%configure -f
{
"conf": {
"spark.jars": "abfss://<<Lakehouse prefix>>.dfs.fabric.microsoft.com/<<path to JAR file>>/<<JAR file name>>.jar",
}
}
The code cell is using Lakehouse's storage as an example. At the notebook explorer, you can copy the full file ABFS path and replace in the code.
