Apache Spark Runtimes in Fabric
Microsoft Fabric Runtime is an Azure-integrated platform based on Apache Spark that enables the execution and management of data engineering and data science experiences. It combines key components from both internal and open-source sources, providing customers with a comprehensive solution. For simplicity, we refer to Microsoft Fabric Runtime powered by Apache Spark as Fabric Runtime.
Major components of Fabric Runtime:
Apache Spark - a powerful open-source distributed computing library that enables large-scale data processing and analytics tasks. Apache Spark provides a versatile and high-performance platform for data engineering and data science experiences.
Delta Lake - an open-source storage layer that brings ACID transactions and other data reliability features to Apache Spark. Integrated within Fabric Runtime, Delta Lake enhances data processing capabilities and ensures data consistency across multiple concurrent operations.
The Native Execution Engine - is a transformative enhancement for Apache Spark workloads, offering significant performance gains by directly executing Spark queries on lakehouse infrastructure. Integrated seamlessly, it requires no code changes and avoids vendor lock-in, supporting both Parquet and Delta formats across Apache Spark APIs in Runtime 1.3 (Spark 3.5). This engine boosts query speeds up to four times faster than traditional OSS Spark, as shown by the TPC-DS 1TB benchmark, reducing operational costs and improving efficiency across various data tasks—including data ingestion, ETL, analytics, and interactive queries. Built on Meta’s Velox and Intel’s Apache Gluten, it optimizes resource use while handling diverse data processing scenarios.
Default-level packages for Java/Scala, Python, and R - packages that support diverse programming languages and environments. These packages are automatically installed and configured, allowing developers to apply their preferred programming languages for data processing tasks.
The Microsoft Fabric Runtime is built upon a robust open-source operating system, ensuring compatibility with various hardware configurations and system requirements.
Below, you find a comprehensive comparison of key components, including Apache Spark versions, supported operating systems, Java, Scala, Python, Delta Lake, and R, for Apache Spark-based runtimes within the Microsoft Fabric platform.
Tip
Always use the most recent, GA runtime version for your production workload, which currently is Runtime 1.3.
| Runtime 1.1 | Runtime 1.2 | Runtime 1.3 | |
|---|---|---|---|
| Release Stage | EOSA | GA | GA |
| Apache Spark | 3.3.1 | 3.4.1 | 3.5.0 |
| Operating System | Ubuntu 18.04 | Mariner 2.0 | Mariner 2.0 |
| Java | 8 | 11 | 11 |
| Scala | 2.12.15 | 2.12.17 | 2.12.17 |
| Python | 3.10 | 3.10 | 3.11 |
| Delta Lake | 2.2.0 | 2.4.0 | 3.2 |
| R | 4.2.2 | 4.2.2 | 4.4.1 |
Visit Runtime 1.1, Runtime 1.2 or Runtime 1.3 to explore details, new features, improvements, and migration scenarios for the specific runtime version.
Fabric optimizations
In Microsoft Fabric, both the Spark engine and the Delta Lake implementations incorporate platform-specific optimizations and features. These features are designed to use native integrations within the platform. It's important to note that all these features can be disabled to achieve standard Spark and Delta Lake functionality. The Fabric Runtimes for Apache Spark encompass:
- The complete open-source version of Apache Spark.
- A collection of nearly 100 built-in, distinct query performance enhancements. These enhancements include features like partition caching (enabling the FileSystem partition cache to reduce metastore calls) and Cross Join to Projection of Scalar Subquery.
- Built-in intelligent cache.
Within the Fabric Runtime for Apache Spark and Delta Lake, there are native writer capabilities that serve two key purposes:
- They offer differentiated performance for writing workloads, optimizing the writing process.
- They default to V-Order optimization of Delta Parquet files. The Delta Lake V-Order optimization is crucial for delivering superior read performance across all Fabric engines. To gain a deeper understanding of how it operates and how to manage it, refer to the dedicated article on Delta Lake table optimization and V-Order.
Multiple runtimes support
Fabric supports multiple runtimes, offering users the flexibility to seamlessly switch between them, minimizing the risk of incompatibilities or disruptions.
By default, all new workspaces use the latest runtime version, which is currently Runtime 1.3.
To change the runtime version at the workspace level, go to Workspace Settings > Data Engineering/Science > Spark settings. From the Environment tab, select your desired runtime version from the available options. Select Save to confirm your selection.
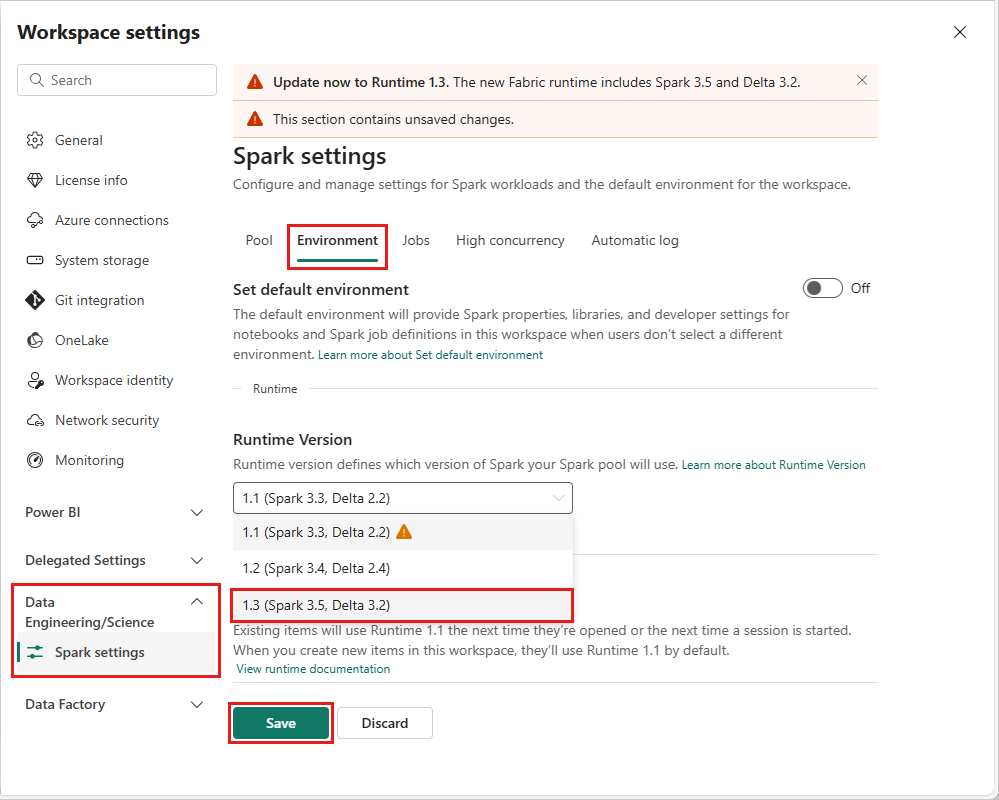
Once you make this change, all system-created items within the workspace, including Lakehouses, SJDs, and Notebooks, will operate using the newly selected workspace-level runtime version starting from the next Spark Session. If you're currently using a notebook with an existing session for a job or any lakehouse-related activity, that Spark session continue as is. However, starting from the next session or job, the selected runtime version will be applied.
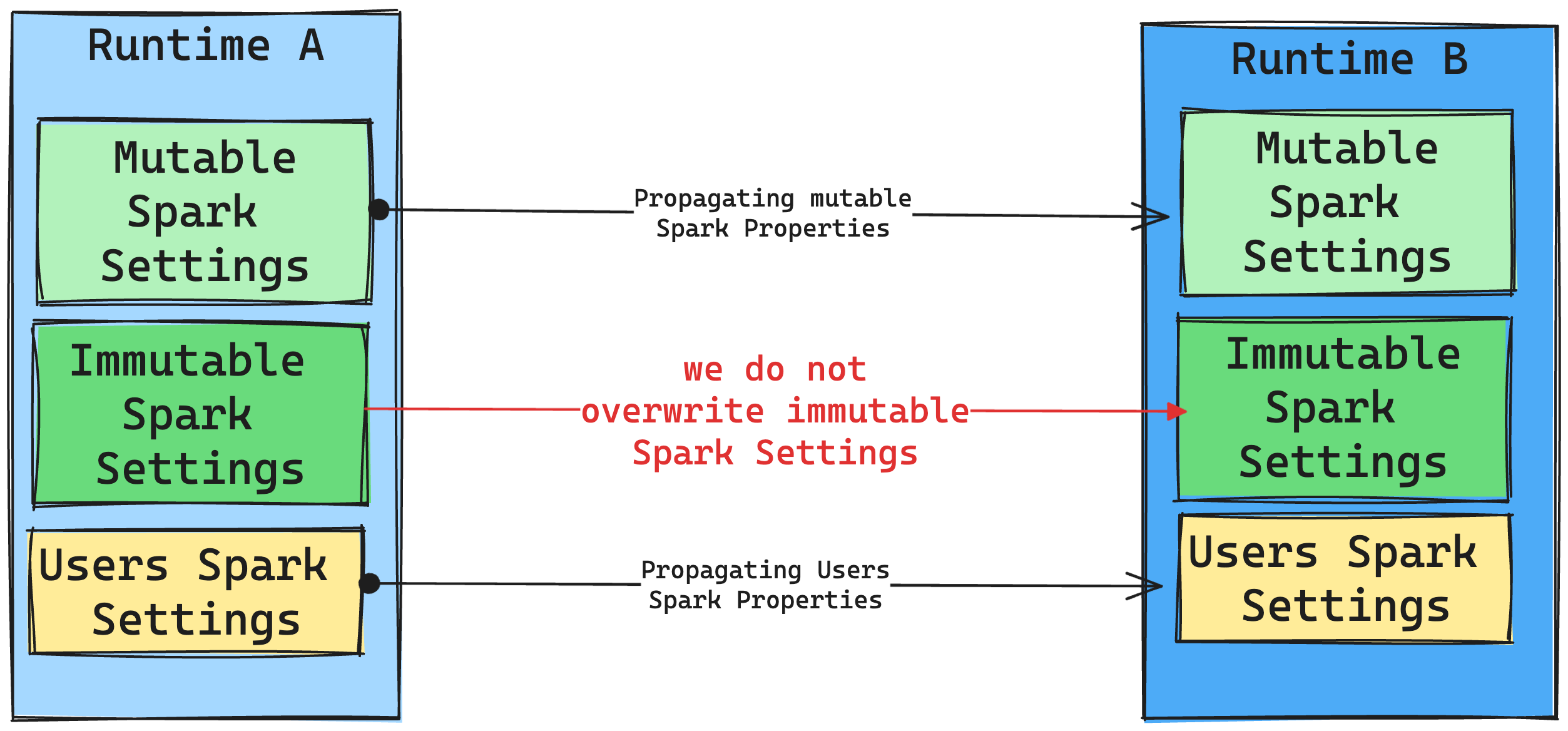
Consequences of runtime changes on Spark Settings
In general, we aim to migrate all Spark settings. However, if we identify that the Spark setting isn't compatible with Runtime B, we issue a warning message and refrain from implementing the setting.
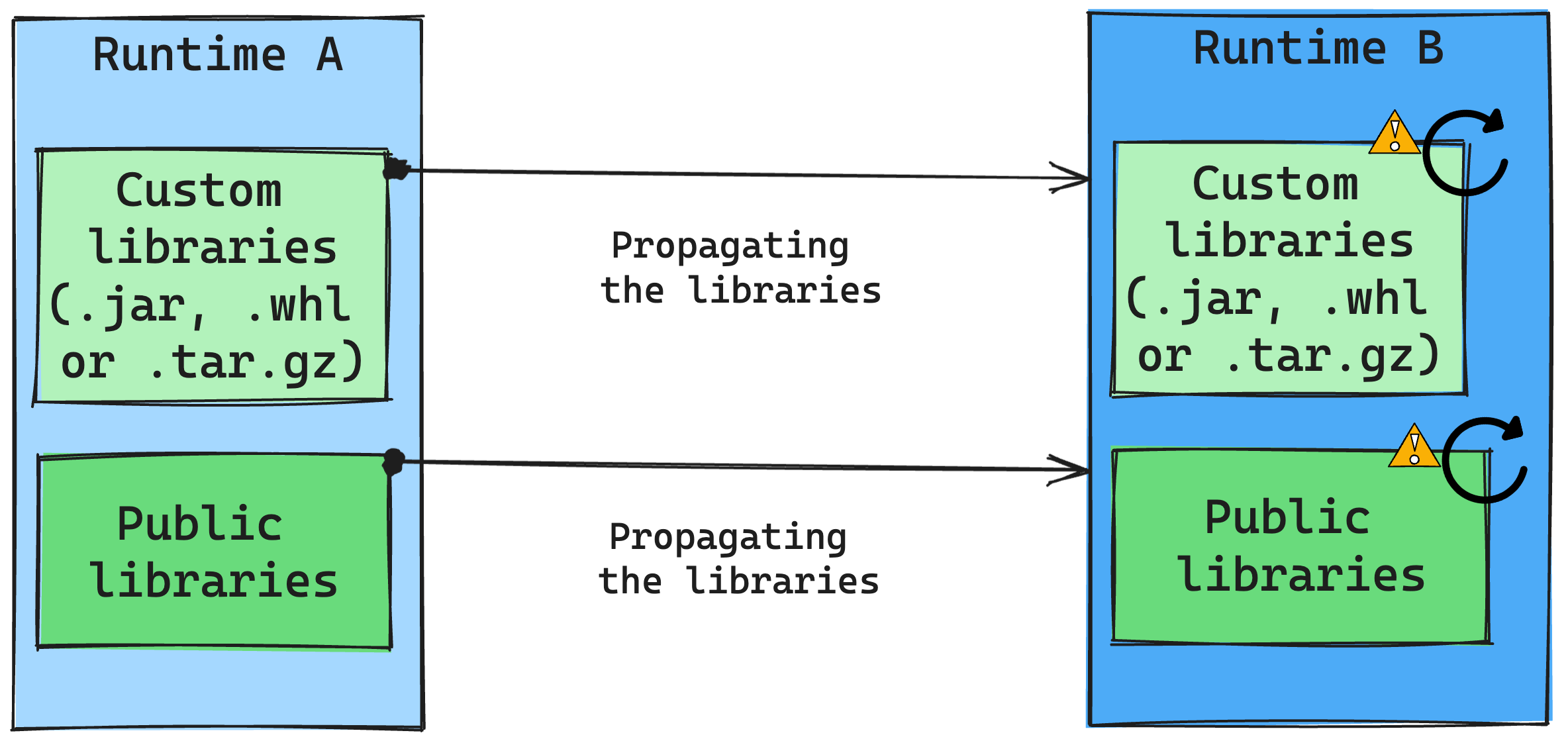
Consequences of runtime changes on library management
In general, our approach is to migrate all libraries from Runtime A to Runtime B, including both Public and Custom Runtimes. If the Python and R versions remain unchanged, the libraries should function properly. However, for Jars, there's a significant likelihood that they may not work due to alterations in dependencies, and other factors such as changes in Scala, Java, Spark, and the operating system.
The user is responsible for updating or replacing any libraries that don't work with Runtime B. If there's a conflict, which means that Runtime B includes a library originally defined in Runtime A, our library management system will try to create the necessary dependency for Runtime B based on the user's settings. However, the building process will fail if a conflict occurs. In the error log, users can see which libraries are causing conflicts and make adjustments to their versions or specifications.
Upgrade Delta Lake protocol
Delta Lake features are always backwards compatible, ensuring tables created in a lower Delta Lake version can seamlessly interact with higher versions. However, when certain features are enabled (for example, by using delta.upgradeTableProtocol(minReaderVersion, minWriterVersion) method, forward compatibility with lower Delta Lake versions may be compromised. In such instances, it's essential to modify workloads referencing the upgraded tables to align with a Delta Lake version that maintains compatibility.
Each Delta table is associated with a protocol specification, defining the features it supports. Applications that interact with the table, either for reading or writing, rely on this protocol specification to determine if they are compatible with the table's feature set. If an application lacks the capability to handle a feature listed as supported in the table's protocol, It's unable to read from or write to that table.
The protocol specification is divided into two distinct components: the read protocol and the write protocol. Visit the page "How does Delta Lake manage feature compatibility?" to read details about it.

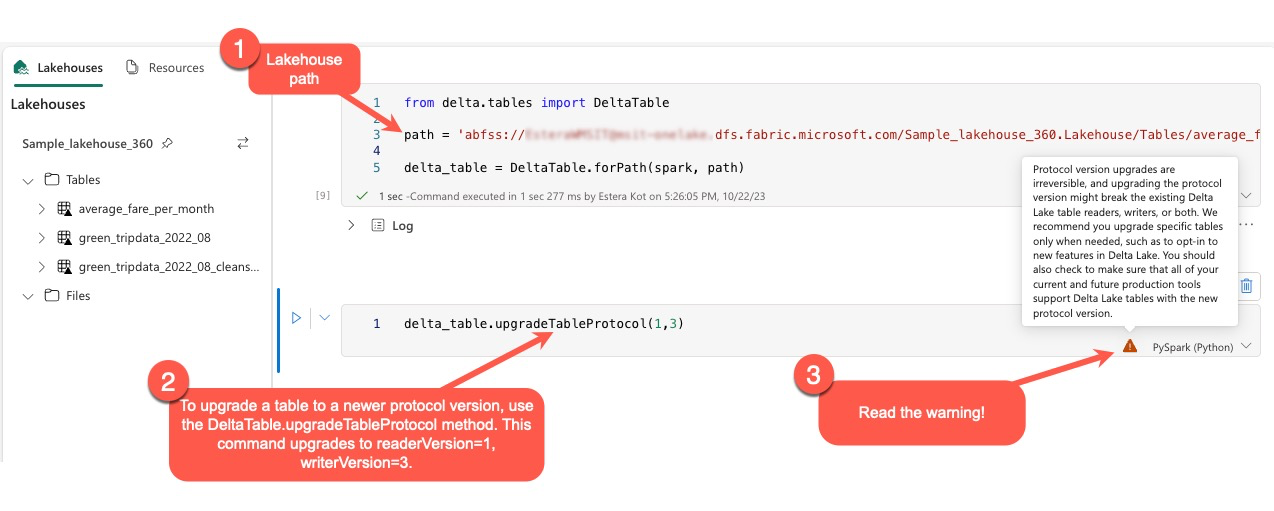
Users can execute the command delta.upgradeTableProtocol(minReaderVersion, minWriterVersion) within the PySpark environment, and in Spark SQL and Scala. This command allows them to initiate an update on the Delta table.
It's essential to note that when performing this upgrade, users receive a warning indicating that upgrading the Delta protocol version is a nonreversible process. This means that once the update is executed, it cannot be undone.
Protocol version upgrades can potentially impact the compatibility of existing Delta Lake table readers, writers, or both. Therefore, it's advisable to proceed with caution and upgrade the protocol version only when necessary, such as when adopting new features in Delta Lake.
Additionally, users should verify that all current and future production workloads and processes are compatible with Delta Lake tables using the new protocol version to ensure a seamless transition and prevent any potential disruptions.
Delta 2.2 vs Delta 2.4 changes
In the latest Fabric Runtime, version 1.3 and Fabric Runtime, version 1.2, the default table format (spark.sql.sources.default) is now delta. In previous versions of Fabric Runtime, version 1.1 and on all Synapse Runtime for Apache Spark containing Spark 3.3 or below, the default table format was defined as parquet. Check the table with Apache Spark configuration details for differences between Azure Synapse Analytics and Microsoft Fabric.
All tables created using Spark SQL, PySpark, Scala Spark, and Spark R, whenever the table type is omitted, will create the table as delta by default. If scripts explicitly set the table format, that will be respected. The command USING DELTA in Spark create table commands becomes redundant.
Scripts that expect or assume parquet table format should be revised. The following commands are not supported in Delta tables:
ANALYZE TABLE $partitionedTableName PARTITION (p1) COMPUTE STATISTICSALTER TABLE $partitionedTableName ADD PARTITION (p1=3)ALTER TABLE DROP PARTITIONALTER TABLE RECOVER PARTITIONSALTER TABLE SET SERDEPROPERTIESLOAD DATAINSERT OVERWRITE DIRECTORYSHOW CREATE TABLECREATE TABLE LIKE