Use the Livy API to submit and execute session jobs
Note
The Livy API for Fabric Data Engineering is in preview.
Applies to: ✅ Data Engineering and Data Science in Microsoft Fabric
Submit Spark batch jobs using the Livy API for Fabric Data Engineering.
Prerequisites
Fabric Premium or Trial capacity with a Lakehouse.
A remote client such as Visual Studio Code with Jupyter Notebooks, PySpark, and the Microsoft Authentication Library (MSAL) for Python.
A Microsoft Entra app token is required to access the Fabric Rest API. Register an application with the Microsoft identity platform.
Some data in your lakehouse, this example uses NYC Taxi & Limousine Commission green_tripdata_2022_08 a parquet file loaded to the lakehouse.
The Livy API defines a unified endpoint for operations. Replace the placeholders {Entra_TenantID}, {Entra_ClientID}, {Fabric_WorkspaceID}, and {Fabric_LakehouseID} with your appropriate values when you follow the examples in this article.
Configure Visual Studio Code for your Livy API Session
Select Lakehouse Settings in your Fabric Lakehouse.

Navigate to the Livy endpoint section.
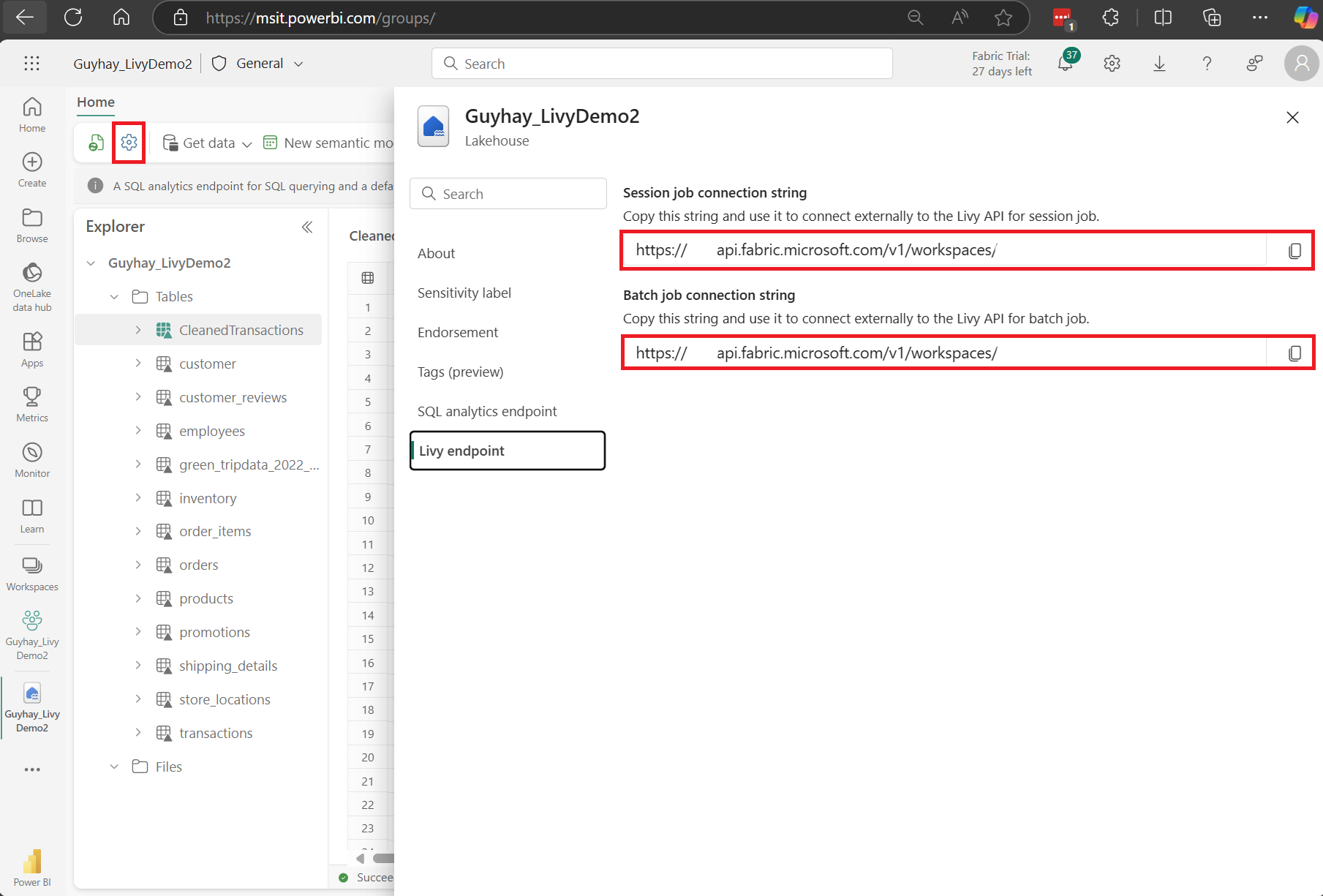
Copy the Session job connection string (first red box in the image) to your code.
Navigate to Microsoft Entra admin center and copy both the Application (client) ID and Directory (tenant) ID to your code.
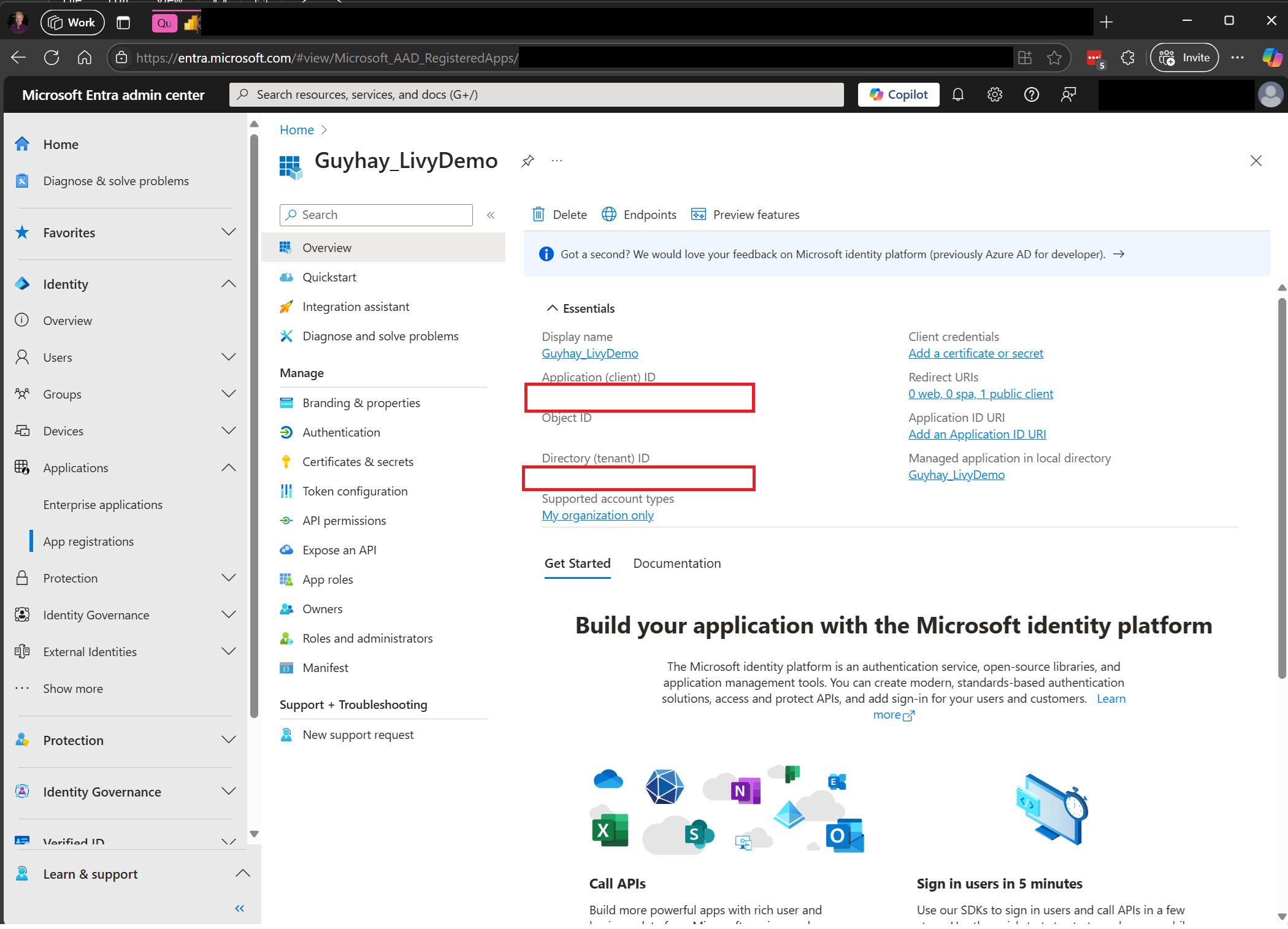



Create a Livy API Spark session
Create an
.ipynbnotebook in Visual Studio Code and insert the following code.from msal import PublicClientApplication import requests import time tenant_id = "Entra_TenantID" client_id = "Entra_ClientID" workspace_id = "Fabric_WorkspaceID" lakehouse_id = "Fabric_LakehouseID" app = PublicClientApplication( client_id, authority="https://login.microsoftonline.com/43a26159-4e8e-442a-9f9c-cb7a13481d48" ) result = None # If no cached tokens or user interaction needed, acquire tokens interactively if not result: result = app.acquire_token_interactive(scopes=["https://api.fabric.microsoft.com/Lakehouse.Execute.All", "https://api.fabric.microsoft.com/Lakehouse.Read.All", "https://api.fabric.microsoft.com/Item.ReadWrite.All", "https://api.fabric.microsoft.com/Workspace.ReadWrite.All", "https://api.fabric.microsoft.com/Code.AccessStorage.All", "https://api.fabric.microsoft.com/Code.AccessAzureKeyvault.All", "https://api.fabric.microsoft.com/Code.AccessAzureDataExplorer.All", "https://api.fabric.microsoft.com/Code.AccessAzureDataLake.All", "https://api.fabric.microsoft.com/Code.AccessFabric.All"]) # Print the access token (you can use it to call APIs) if "access_token" in result: print(f"Access token: {result['access_token']}") else: print("Authentication failed or no access token obtained.") if "access_token" in result: access_token = result['access_token'] api_base_url_mist='https://api.fabric.microsoft.com/v1' livy_base_url = api_base_url_mist + "/workspaces/"+workspace_id+"/lakehouses/"+lakehouse_id +"/livyApi/versions/2023-12-01/sessions" headers = {"Authorization": "Bearer " + access_token}Run the notebook cell, a popup should appear in your browser allowing you to choose the identity to sign-in with.
After you choose the identity to sign-in with, you'll also be asked to approve the Microsoft Entra app registration API permissions.
Close the browser window after completing authentication.

In Visual Studio Code, you should see the Microsoft Entra token returned.
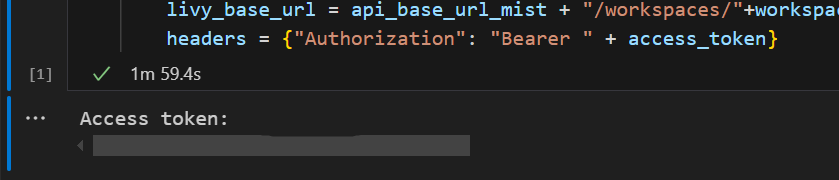
Add another notebook cell and insert this code.
create_livy_session = requests.post(livy_base_url, headers=headers, json={}) print('The request to create the Livy session is submitted:' + str(create_livy_session.json())) livy_session_id = create_livy_session.json()['id'] livy_session_url = livy_base_url + "/" + livy_session_id get_session_response = requests.get(livy_session_url, headers=headers) print(get_session_response.json())Run the notebook cell, you should see one line printed as the Livy session is created.

You can verify that the Livy session is created by using the [View your jobs in the Monitoring hub](#View your jobs in the Monitoring hub).





Submit a spark.sql statement using the Livy API Spark session
Add another notebook cell and insert this code.
# call get session API livy_session_id = create_livy_session.json()['id'] livy_session_url = livy_base_url + "/" + livy_session_id get_session_response = requests.get(livy_session_url, headers=headers) print(get_session_response.json()) while get_session_response.json()["state"] != "idle": time.sleep(5) get_session_response = requests.get(livy_session_url, headers=headers) execute_statement = livy_session_url + "/statements" payload_data = { "code": "spark.sql(\"SELECT * FROM green_tripdata_2022_08 where fare_amount = 60\").show()", "kind": "spark" } execute_statement_response = requests.post(execute_statement, headers=headers, json=payload_data) print('the statement code is submitted as: ' + str(execute_statement_response.json())) statement_id = str(execute_statement_response.json()['id']) get_statement = livy_session_url+ "/statements/" + statement_id get_statement_response = requests.get(get_statement, headers=headers) while get_statement_response.json()["state"] != "available": # Sleep for 5 seconds before making the next request time.sleep(5) print('the statement code is submitted and running : ' + str(execute_statement_response.json())) # Make the next request get_statement_response = requests.get(get_statement, headers=headers) rst = get_statement_response.json()['output']['data']['text/plain'] print(rst)Run the notebook cell, you should see several incremental lines printed as the job is submitted and the results returned.
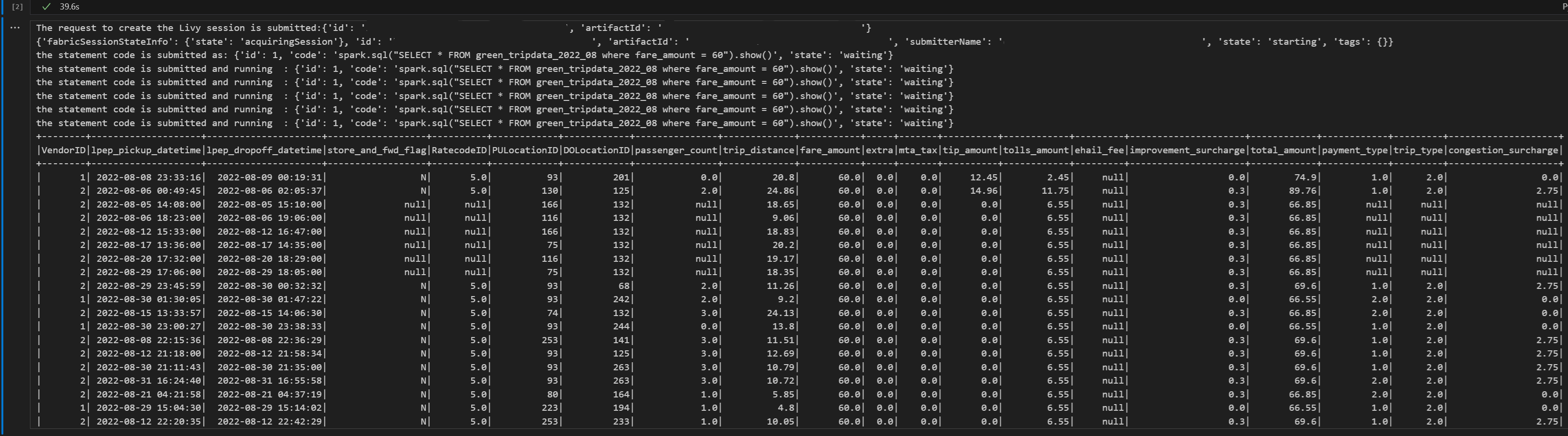

Submit a second spark.sql statement using the Livy API Spark session
Add another notebook cell and insert this code.
# call get session API livy_session_id = create_livy_session.json()['id'] livy_session_url = livy_base_url + "/" + livy_session_id get_session_response = requests.get(livy_session_url, headers=headers) print(get_session_response.json()) while get_session_response.json()["state"] != "idle": time.sleep(5) get_session_response = requests.get(livy_session_url, headers=headers) execute_statement = livy_session_url + "/statements" payload_data = { "code": "spark.sql(\"SELECT * FROM green_tripdata_2022_08 where tip_amount = 10\").show()", "kind": "spark" } execute_statement_response = requests.post(execute_statement, headers=headers, json=payload_data) print('the statement code is submitted as: ' + str(execute_statement_response.json())) statement_id = str(execute_statement_response.json()['id']) get_statement = livy_session_url+ "/statements/" + statement_id get_statement_response = requests.get(get_statement, headers=headers) while get_statement_response.json()["state"] != "available": # Sleep for 5 seconds before making the next request time.sleep(5) print('the statement code is submitted and running : ' + str(execute_statement_response.json())) # Make the next request get_statement_response = requests.get(get_statement, headers=headers) rst = get_statement_response.json()['output']['data']['text/plain'] print(rst)Run the notebook cell, you should see several incremental lines printed as the job is submitted and the results returned.
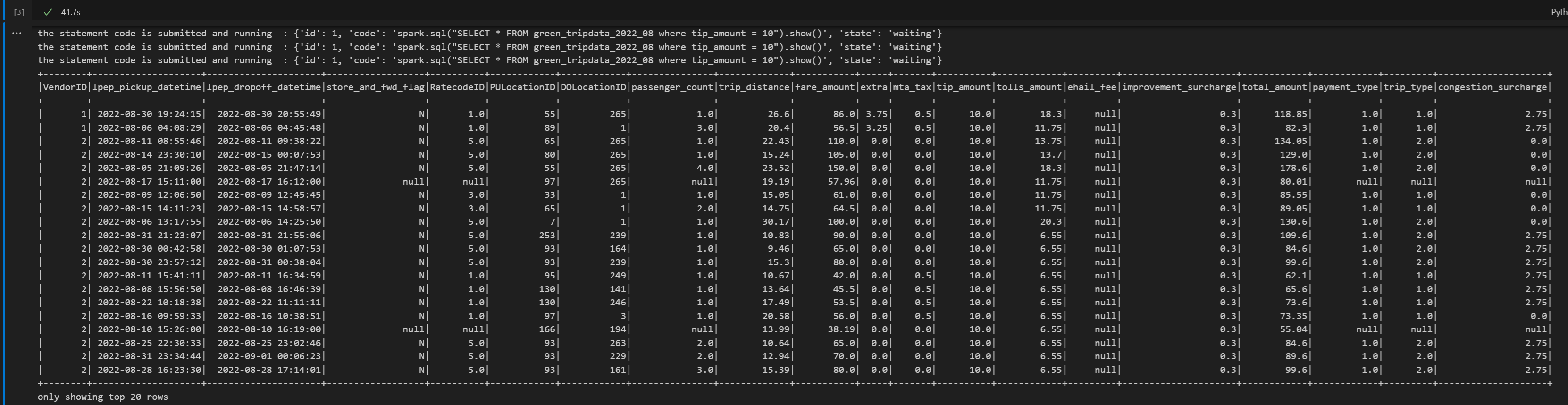

Close the Livy session with a third statement
Add another notebook cell and insert this code.
# call get session API with a delete session statement get_session_response = requests.get(livy_session_url, headers=headers) print('Livy statement URL ' + livy_session_url) response = requests.delete(livy_session_url, headers=headers) print (response)
View your jobs in the Monitoring hub
You can access the Monitoring hub to view various Apache Spark activities by selecting Monitor in the left-side navigation links.
When the session is in progress or in completed state, you can view the session status by navigating to Monitor.
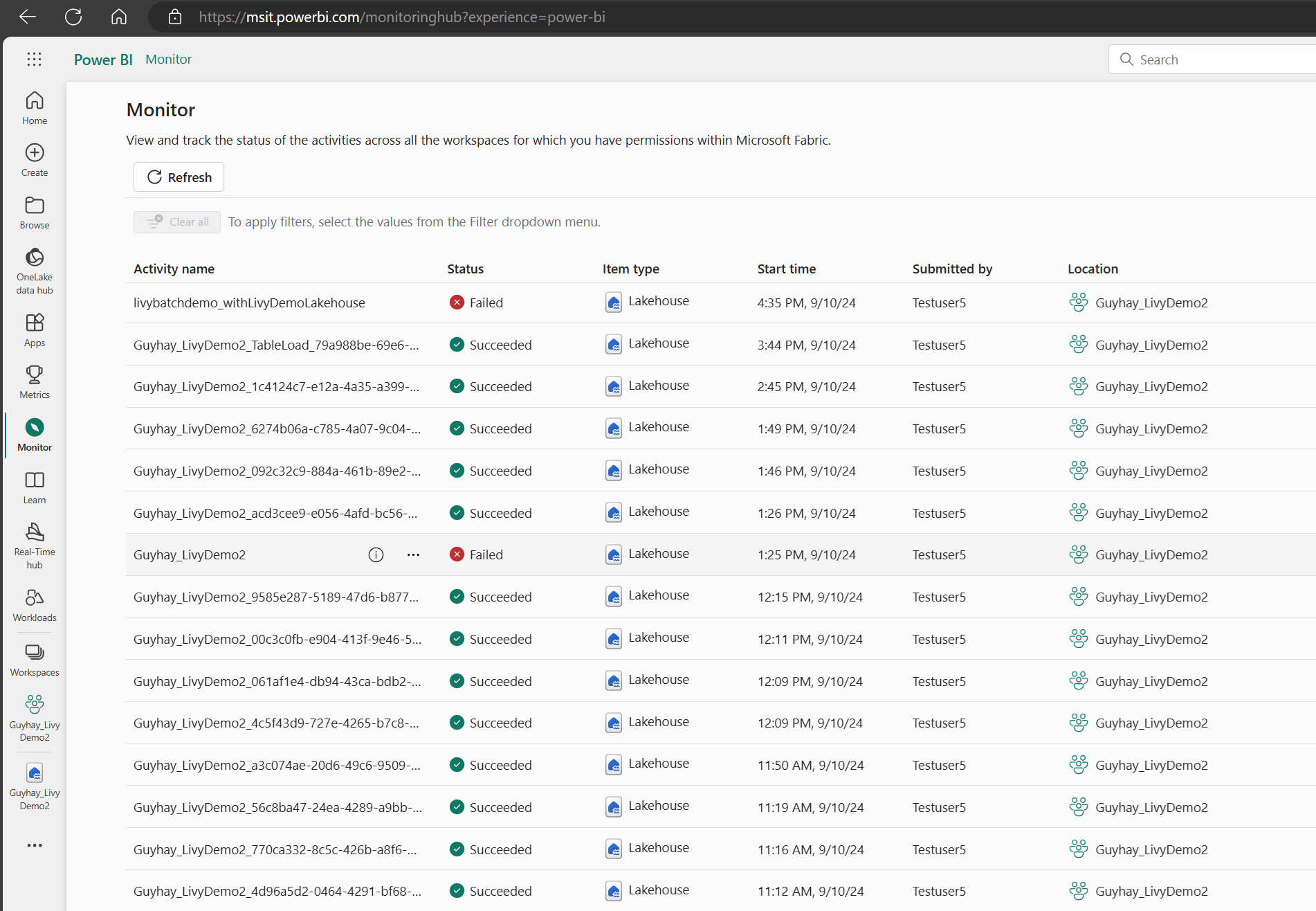
Select and open most recent activity name.
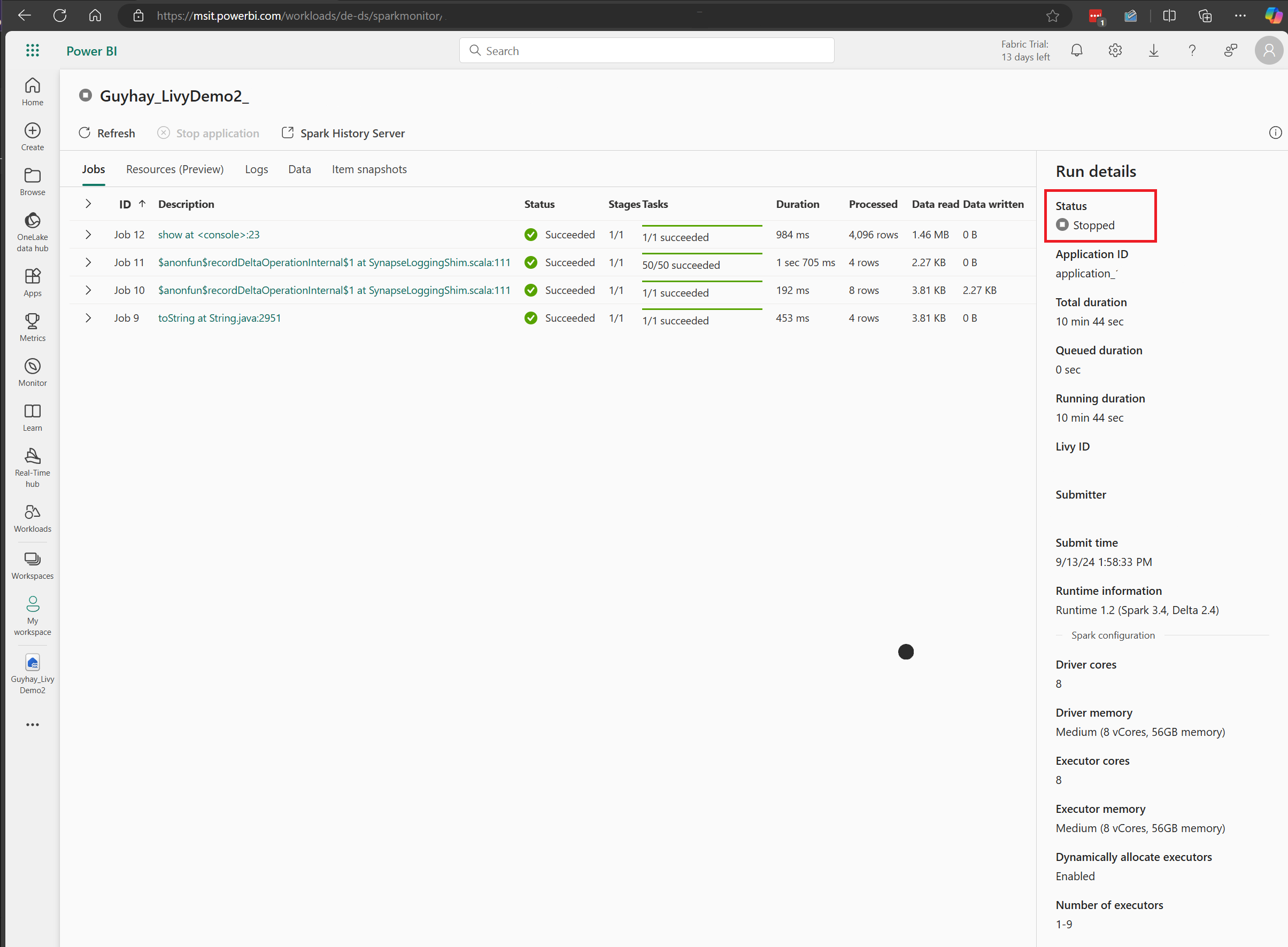
In this Livy API session case, you can see your previous sessions submissions, run details, Spark versions, and configuration. Notice the stopped status on the top right.

To recap the whole process, you need a remote client such as Visual Studio Code, an Microsoft Entra app token, Livy API endpoint URL, authentication against your Lakehouse, and finally a Session Livy API.