Troubleshoot guidance
This article addresses frequent questions about prompt flow usage.
Flow authoring related issues
"Package tool isn't found" error occurs when you update the flow for a code-first experience
When you update flows for a code-first experience, if the flow utilized the Faiss Index Lookup, Vector Index Lookup, Vector DB Lookup, or Content Safety (Text) tools, you might encounter the following error message:
Package tool 'embeddingstore.tool.faiss_index_lookup.search' is not found in the current environment.
To resolve the issue, you have two options:
Option 1
Update your compute session to the latest base image version.
Select Raw file mode to switch to the raw code view. Then open the flow.dag.yaml file.

Update the tool names.
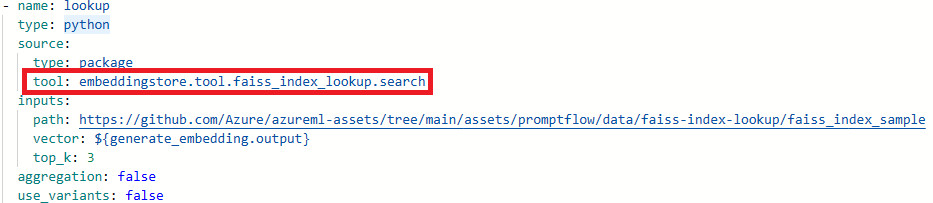
Tool New tool name Faiss Index Lookup promptflow_vectordb.tool.faiss_index_lookup.FaissIndexLookup.search Vector Index Lookup promptflow_vectordb.tool.vector_index_lookup.VectorIndexLookup.search Vector DB Lookup promptflow_vectordb.tool.vector_db_lookup.VectorDBLookup.search Content Safety (Text) content_safety_text.tools.content_safety_text_tool.analyze_text Save the flow.dag.yaml file.
Option 2
- Update your compute session to the latest base image version
- Remove the old tool and re-create a new tool.
"No such file or directory" error
Prompt flow relies on a file share storage to store a snapshot of the flow. If the file share storage has an issue, you might encounter the following problem. Here are some workarounds you can try:
If you're using a private storage account, see Network isolation in prompt flow to make sure your workspace can access your storage account.
If the storage account is enabled for public access, check whether there's a datastore named
workspaceworkingdirectoryin your workspace. It should be a file share type.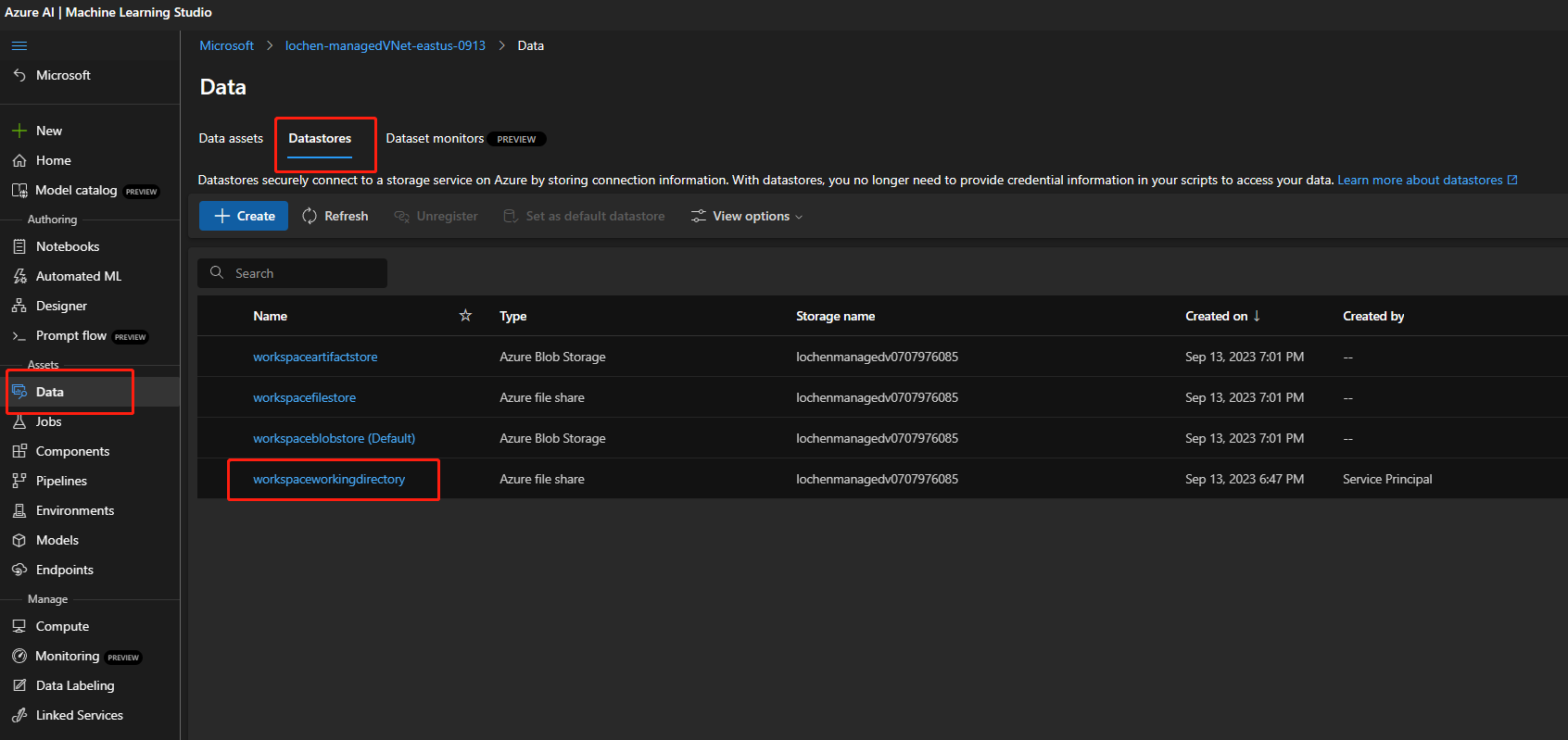
- If you didn't get this datastore, you need to add it in your workspace.
- Create a file share with the name
code-391ff5ac-6576-460f-ba4d-7e03433c68b6. - Create a datastore with the name
workspaceworkingdirectory. See Create datastores.
- Create a file share with the name
- If you have a
workspaceworkingdirectorydatastore but its type isblobinstead offileshare, create a new workspace. Use storage that doesn't enable hierarchical namespaces for Azure Data Lake Storage Gen2 as a workspace default storage account. For more information, see Create workspace.
- If you didn't get this datastore, you need to add it in your workspace.

Flow is missing

There are possible reasons for this issue:
If public access to your storage account is disabled, you must ensure access by either adding your IP to the storage firewall or enabling access through a virtual network that has a private endpoint connected to the storage account.
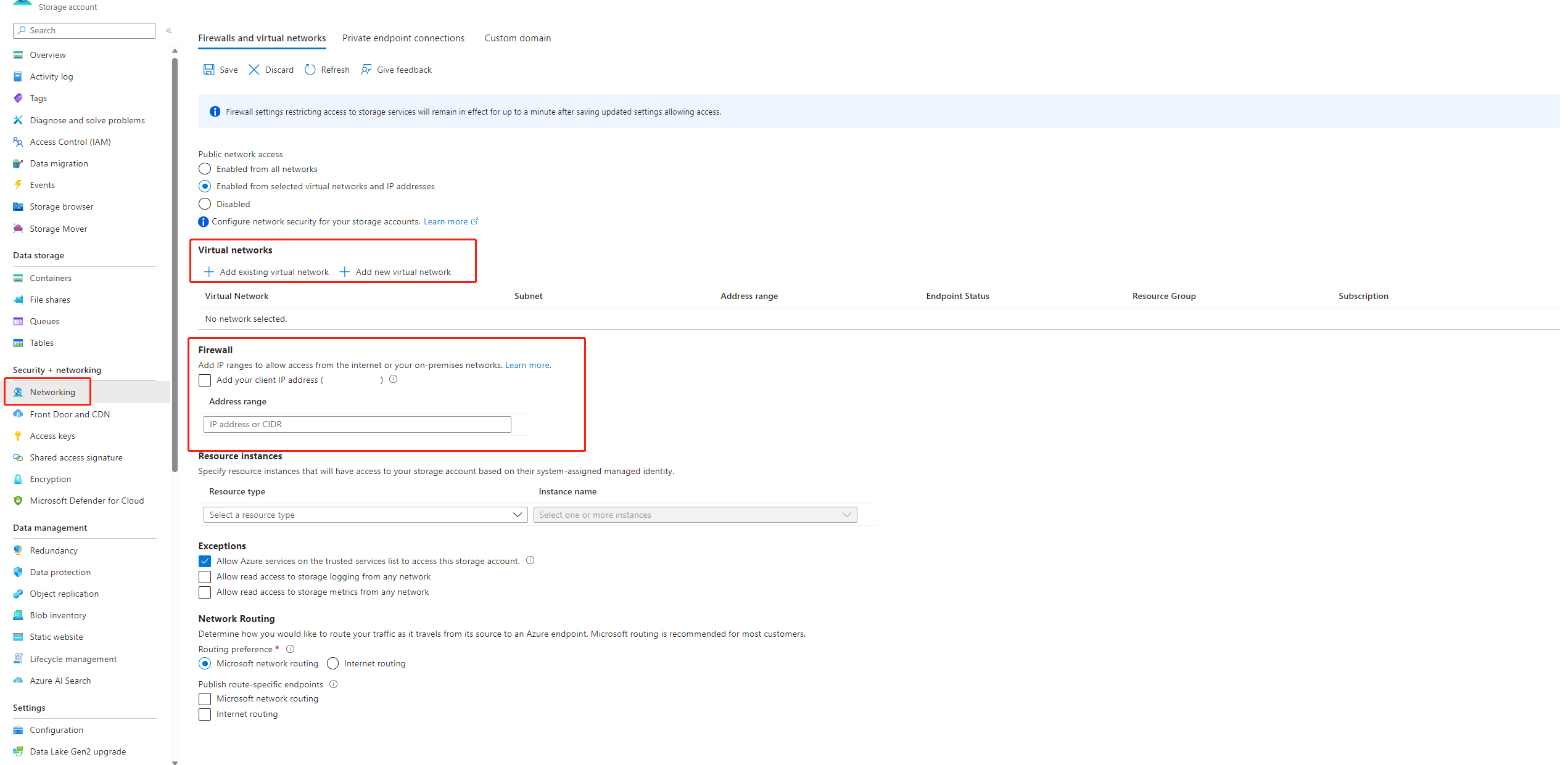
There are some cases, the account key in datastore is out of sync with the storage account, you can try to update the account key in datastore detail page to fix this.
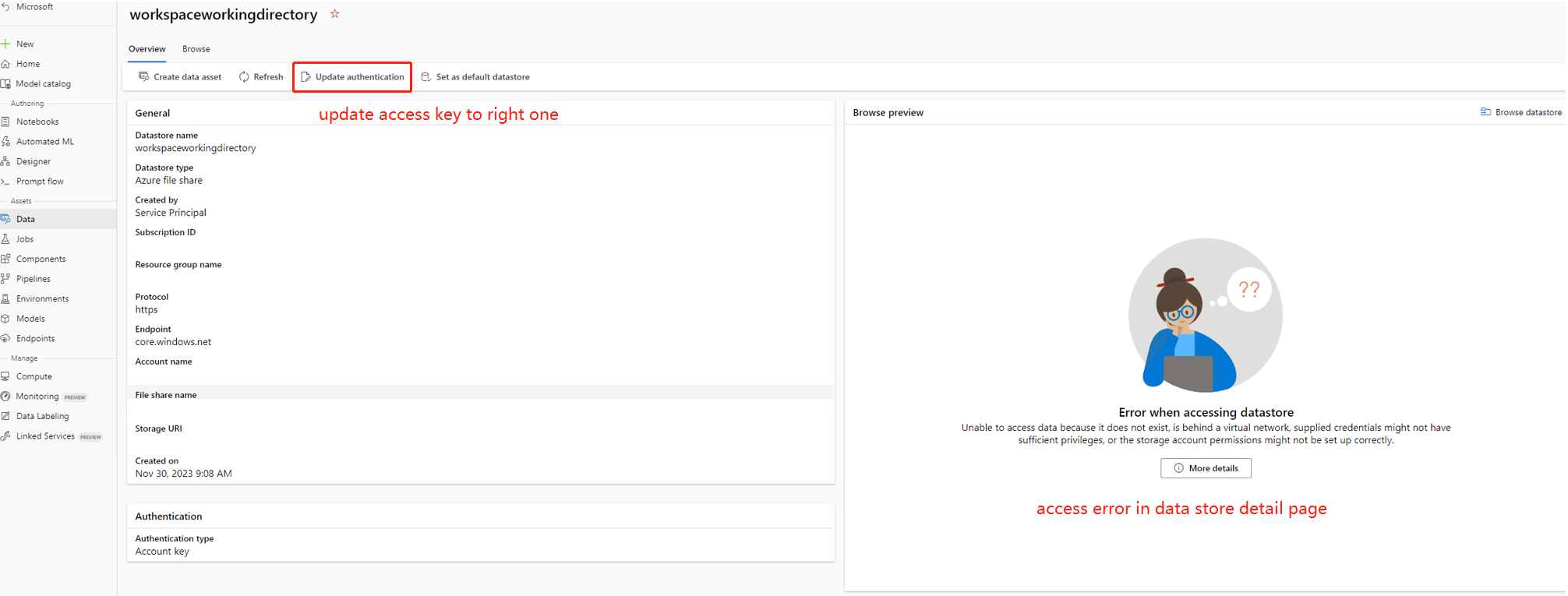
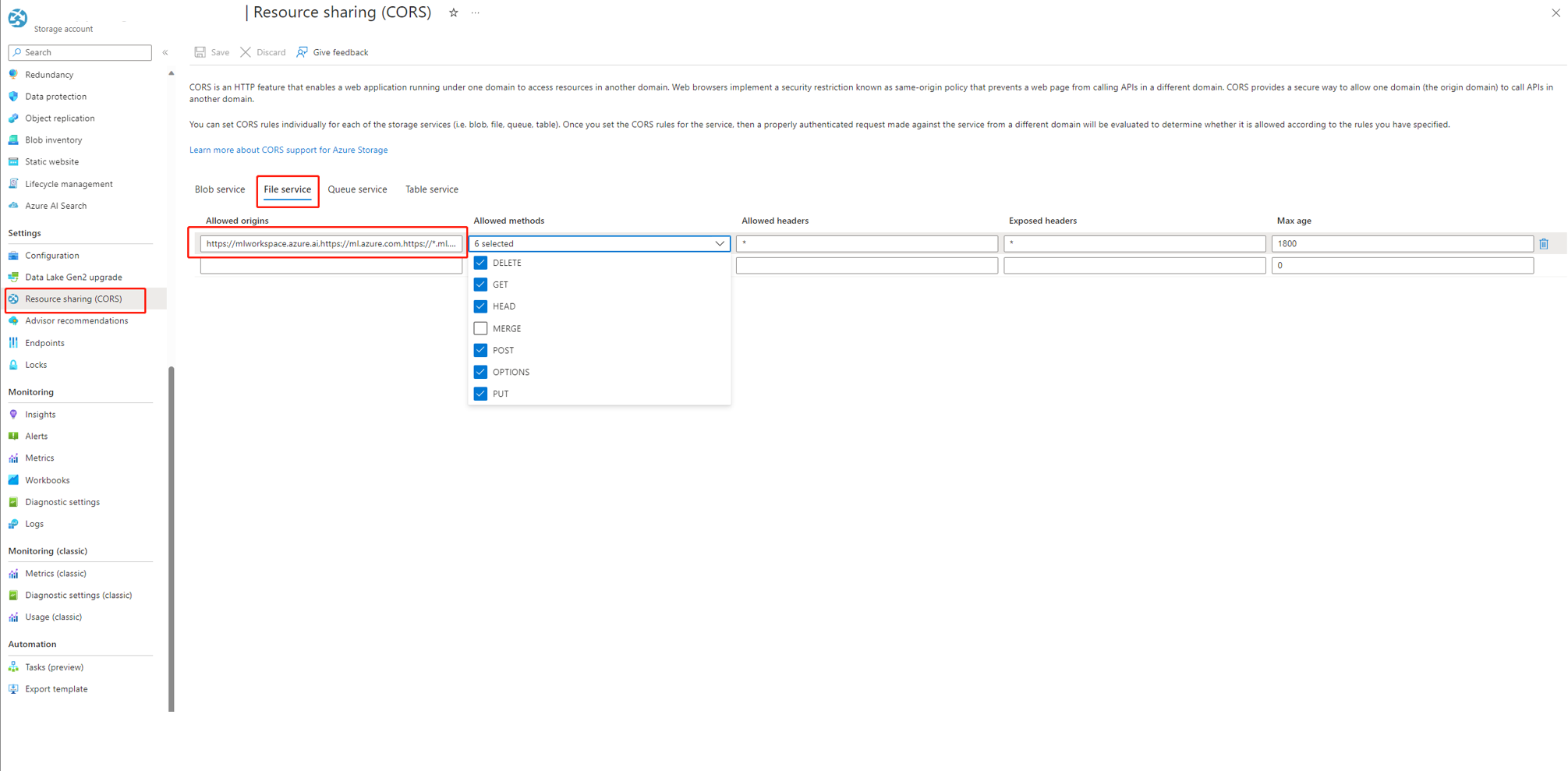
If you're using Azure AI Foundry, the storage account needs to set CORS to allow Azure AI Foundry access the storage account, otherwise, you see the flow missing issue. You can add following CORS settings to the storage account to fix this issue.
- Go to storage account page, select
Resource sharing (CORS)undersettings, and select toFile servicetab. - Allowed origins:
https://mlworkspace.azure.ai,https://ml.azure.com,https://*.ml.azure.com,https://ai.azure.com,https://*.ai.azure.com,https://mlworkspacecanary.azure.ai,https://mlworkspace.azureml-test.net - Allowed methods:
DELETE, GET, HEAD, POST, OPTIONS, PUT
- Go to storage account page, select



Compute session related issues
Run failed because of "No module named XXX"
This type of error related to compute session lacks required packages. If you're using a default environment, make sure the image of your compute session is using the latest version. If you're using a custom base image, make sure you installed all the required packages in your docker context. For more information, see Customize base image for compute session.
Where to find the serverless instance used by compute session?
You can view the serverless instance used by compute session in the compute session list tab under compute page. Learn more about how to manage serverless instance.
Compute session failures using custom base image
Compute session start failure with requirements.txt or custom base image
Compute session support to use requirements.txt or custom base image in flow.dag.yaml to customize the image. We would recommend you to use requirements.txt for common case, which will use pip install -r requirements.txt to install the packages. If you have dependency more than python packages, you need to follow the Customize base image to create build a new image base on top of prompt flow base image. Then use it in flow.dag.yaml. Learn more how to specify base image in compute session.
- You can't use arbitrary base image to create Compute session, you need to use the base image provide by prompt flow.
- Don't pin the version of
promptflowandpromptflow-toolsinrequirements.txt, because we already include them in the base image. Using old version ofpromptflowandpromptflow-toolsmay cause unexpected behavior.
Flow run related issues
How to find the raw inputs and outputs of in LLM tool for further investigation?
In prompt flow, on flow page with successful run and run detail page, you can find the raw inputs and outputs of LLM tool in the output section. Select the view full output button to view full output.

Trace section includes each request and response to the LLM tool. You can check the raw message sent to the LLM model and the raw response from the LLM model.

How to fix 409 error from Azure OpenAI?
You may encounter 409 error from Azure OpenAI, it means you have reached the rate limit of Azure OpenAI. You can check the error message in the output section of LLM node. Learn more about Azure OpenAI rate limit.

Identify which node consumes the most time
Check the compute session logs.
Try to find the following warning log format:
{node_name} has been running for {duration} seconds.
For example:
Case 1: Python script node runs for a long time.

In this case, you can find that
PythonScriptNodewas running for a long time (almost 300 seconds). Then you can check the node details to see what's the problem.Case 2: LLM node runs for a long time.
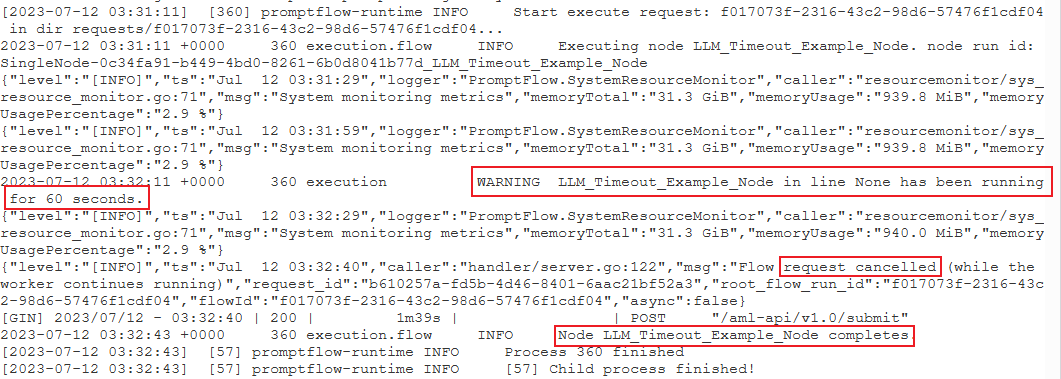
In this case, if you find the message
request canceledin the logs, it might be because the OpenAI API call is taking too long and exceeding the timeout limit.An OpenAI API timeout could be caused by a network issue or a complex request that requires more processing time. For more information, see OpenAI API timeout.
Wait a few seconds and retry your request. This action usually resolves any network issues.
If retrying doesn't work, check whether you're using a long context model, such as
gpt-4-32k, and have set a large value formax_tokens. If so, the behavior is expected because your prompt might generate a long response that takes longer than the interactive mode's upper threshold. In this situation, we recommend tryingBulk testbecause this mode doesn't have a timeout setting.
If you can't find anything in logs to indicate it's a specific node issue:
- Contact the prompt flow team (promptflow-eng) with the logs. We try to identify the root cause.


Flow deployment related issues
Lack authorization to perform action "Microsoft.MachineLearningService/workspaces/datastores/read"
If your flow contains Index Look Up tool, after deploying the flow, the endpoint needs to access workspace datastore to read MLIndex yaml file or FAISS folder containing chunks and embeddings. Hence, you need to manually grant the endpoint identity permission to do so.
You can either grant the endpoint identity AzureML Data Scientist on workspace scope, or a custom role that contains "MachineLearningService/workspace/datastore/reader" action.
Upstream request timeout issue when consuming the endpoint
If you use CLI or SDK to deploy the flow, you may encounter timeout error. By default the request_timeout_ms is 5000. You can specify at max to 5 minutes, which is 300,000 ms. Following is example showing how to specify request time-out in the deployment yaml file. To learn more, see deployment schema.
request_settings:
request_timeout_ms: 300000
OpenAI API hits authentication error
If you regenerate your Azure OpenAI key and manually update the connection used in prompt flow, you may encounter errors like "Unauthorized. Access token is missing, invalid, audience is incorrect or have expired." when invoking an existing endpoint created before key regenerating.
This is because the connections used in the endpoints/deployments won't be automatically updated. Any change for key or secrets in deployments should be done by manual update, which aims to avoid impacting online production deployment due to unintentional offline operation.
- If the endpoint was deployed in the studio UI, you can just redeploy the flow to the existing endpoint using the same deployment name.
- If the endpoint was deployed using SDK or CLI, you need to make some modification to the deployment definition such as adding a dummy environment variable, and then use
az ml online-deployment updateto update your deployment.
Vulnerability issues in prompt flow deployments
For prompt flow runtime related vulnerabilities, following are approaches, which can help mitigate:
- Update the dependency packages in your requirements.txt in your flow folder.
- If you're using customized base image for your flow, you need to update the prompt flow runtime to latest version and rebuild your base image, then redeploy the flow.
For any other vulnerabilities of managed online deployments, Azure Machine Learning fixes the issues in a monthly manner.
"MissingDriverProgram Error" or "Could not find driver program in the request"
If you deploy your flow and encounter the following error, it might be related to the deployment environment.
'error':
{
'code': 'BadRequest',
'message': 'The request is invalid.',
'details':
{'code': 'MissingDriverProgram',
'message': 'Could not find driver program in the request.',
'details': [],
'additionalInfo': []
}
}
Could not find driver program in the request
There are two ways to fix this error.
(Recommended) You can find the container image uri in your custom environment detail page, and set it as the flow base image in the flow.dag.yaml file. When you deploy the flow in UI, you just select Use environment of current flow definition, and the backend service will create the customized environment based on this base image and
requirement.txtfor your deployment. Learn more about the environment specified in the flow definition.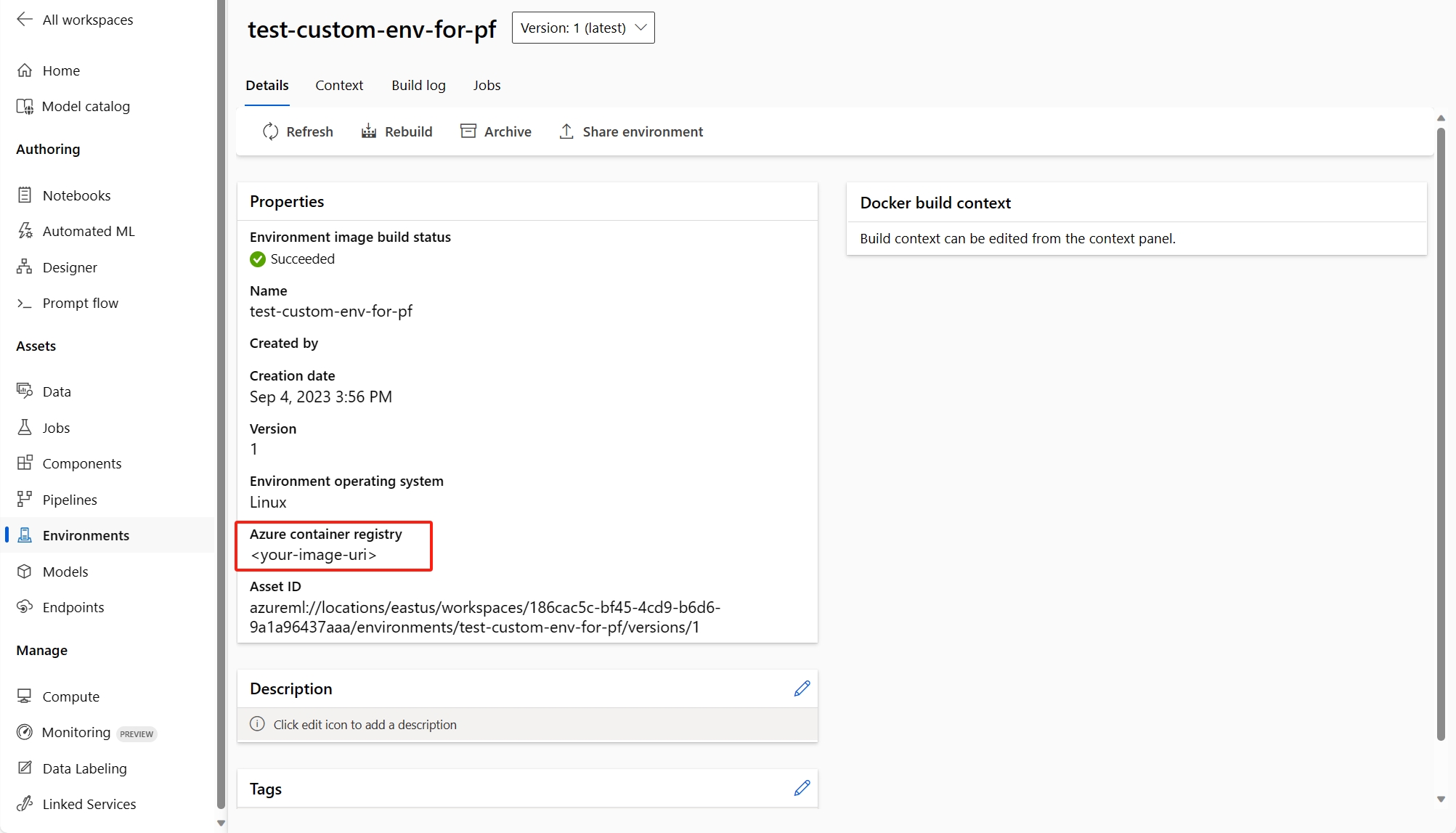
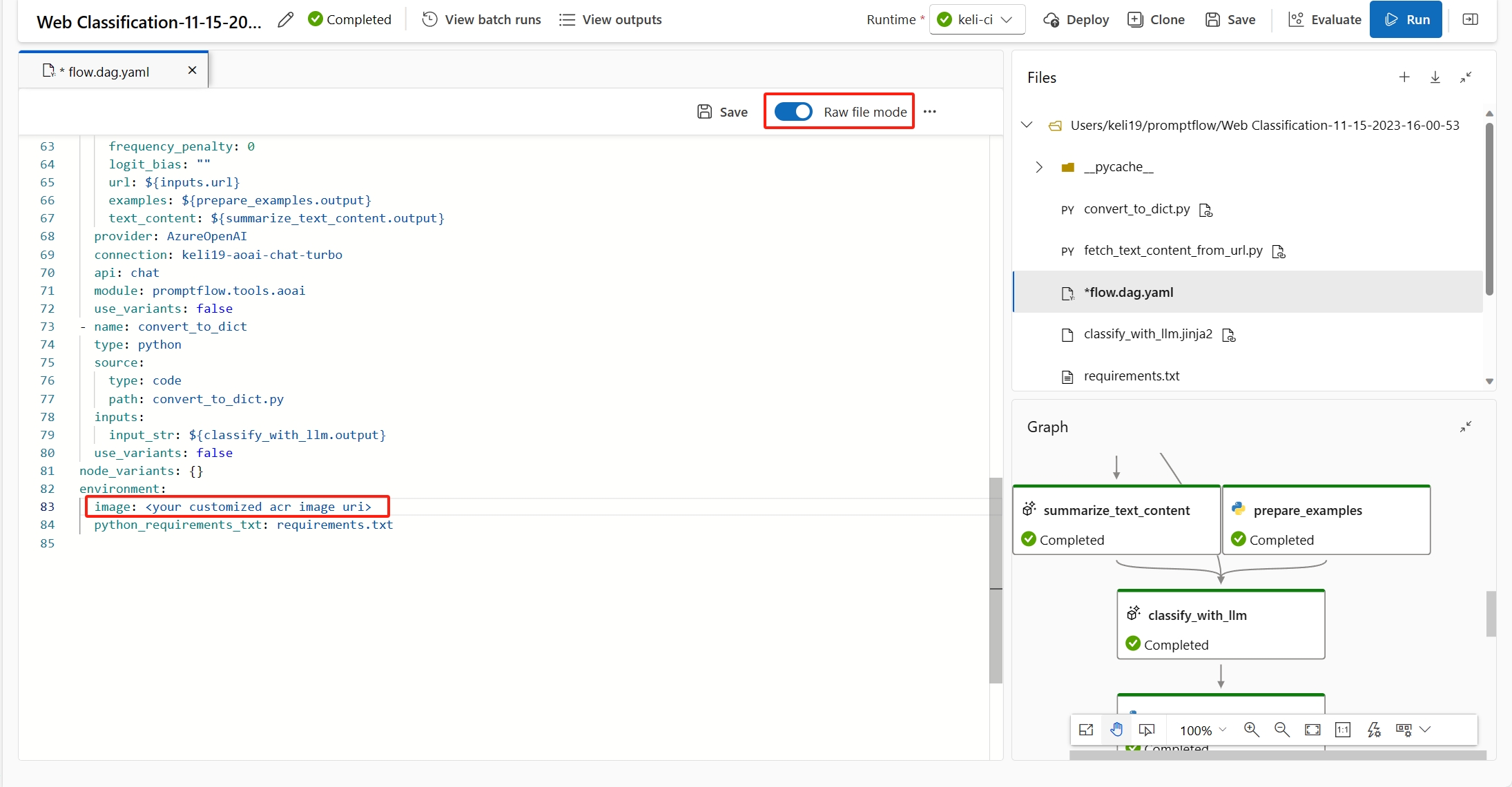
You can fix this error by adding
inference_configin your custom environment definition.Following is an example of customized environment definition.


$schema: https://azuremlschemas.azureedge.net/latest/environment.schema.json
name: pf-customized-test
build:
path: ./image_build
dockerfile_path: Dockerfile
description: promptflow customized runtime
inference_config:
liveness_route:
port: 8080
path: /health
readiness_route:
port: 8080
path: /health
scoring_route:
port: 8080
path: /score
Model response taking too long
Sometimes, you might notice that the deployment is taking too long to respond. There are several potential factors for this to occur.
- The model used in the flow isn't powerful enough (example: use GPT 3.5 instead of text-ada)
- Index query isn't optimized and taking too long
- Flow has many steps to process
Consider optimizing the endpoint with above considerations to improve the performance of the model.
Unable to fetch deployment schema
After you deploy the endpoint and want to test it in the Test tab in the endpoint detail page, if the Test tab shows Unable to fetch deployment schema, you can try the following two methods to mitigate this issue:

- Make sure you have granted the correct permission to the endpoint identity. Learn more about how to grant permission to the endpoint identity.
- It might be because you ran your flow in an old version runtime and then deployed the flow, the deployment used the environment of the runtime that was in old version as well. To update the runtime, follow Update a runtime on the UI and rerun the flow in the latest runtime and then deploy the flow again.
Access denied to list workspace secret
If you encounter an error like "Access denied to list workspace secret", check whether you have granted the correct permission to the endpoint identity. Learn more about how to grant permission to the endpoint identity.
Authentication and identity related issues
How do I use credential-less datastore in prompt flow?
To use credential-less storage in Azure AI Foundry portal, you need to basically do the following things:
- Change the data store auth type to None.
- Grant project MSI and user blob/file data contributor permission on storage.
Change auth type of datastore to None
You can follow Identity-based data authentication this part to make your datastore credential-less.
You need to change auth type of datastore to None, which stands for meid_token based auth. You can make change from datastore detail page, or CLI/SDK: https://github.com/Azure/azureml-examples/tree/main/cli/resources/datastore

For blob based datastore, you can change auth type and also enable workspace MSI to access the storage account.

For file share based datastore, you can change auth type only.

Grant permission to user identity or managed identity
To use credential-less datastore in prompt flow, you need to grant enough permissions to user identity or managed identity to access the datastore.
- Make sure workspace system assigned managed identity have
Storage Blob Data ContributorandStorage File Data Privileged Contributoron the storage account, at least need read/write (better also include delete) permission. - If you're using user identity this default option in prompt flow, you need to make sure the user identity has following role on the storage account:
Storage Blob Data Contributoron the storage account, at least need read/write (better also include delete) permission.Storage File Data Privileged Contributoron the storage account, at least need read/write (better also include delete) permission.
- If you're using user assigned managed identity, you need to make sure the managed identity has following role on the storage account:
Storage Blob Data Contributoron the storage account, at least need read/write (better also include delete) permission.Storage File Data Privileged Contributoron the storage account, at least need read/write (better also include delete) permission.- Meanwhile, you need to assign user identity
Storage Blob Data Readrole to storage account at least, if you want to use prompt flow to authoring and test flow.
- If you still can't view the flow detail page and the first time you using prompt flow is earlier than 2024-01-01, you need to grant workspace MSI as
Storage Table Data Contributorto storage account linked with workspace.