January 2025
These features and Azure Databricks platform improvements were released in January 2025.
Note
Releases are staged. Your Azure Databricks account might not be updated until a week or more after the initial release date.
Additional ports for Azure Databricks
January 31, 2025
Network security groups now require ports 3306 and 8443-8451 for outbound access to Azure Databricks services from your vnet injection enabled workspaces. See Network security group rules for workspaces.
State store reader is now GA
January 31, 2025
Support for querying Structured Streaming state data and metadata is now GA in Databricks Runtime 14.3 LTS and above. See Read Structured Streaming state information.
Predictive optimization can now be enabled at the catalog or schema level
** January 31, 2025**
You can now enable predictive optimization at the catalog or schema level without first enabling it at the account level. See Predictive optimization for Unity Catalog managed tables.
Filtering full datasets for large tables is now supported
January 30, 2025
When filtering truncated data in a large table (output larger than 2MB or containing more than 10,000 rows), you can now choose to apply the filter to the entire dataset. See Filter results.
The Meta Llama 3.1 405B model family is retired on Foundation Model Fine-tuning
January 30, 2025
The Meta Llama 3.1 405B model family is retired on Foundation Model Fine-tuning. See Retired models for recommended replacement models.
Clean Rooms is GA
January 29, 2025
Azure Databricks Clean Rooms is now generally available. See What is Azure Databricks Clean Rooms?.
- Management APIs: New APIs have been introduced to automate clean room setup, orchestration, and monitoring. See Clean Rooms.
- Self-Collaboration: You can now create clean rooms in a single metastore to test your clean room before full deployment. See Step 2. Create a clean room.
- Output tables: Central clean rooms hosted on Azure now support output tables. Previously, they were only supported for central clean rooms hosted on AWS. However, collaborators in Databricks on all three clouds—AWS, Azure, and Google Cloud—can share notebooks that create output tables and read output tables generated when they run shared notebooks. Google Cloud collaborators must be participants in the Clean Rooms private preview. See Create and work with output tables in Databricks Clean Rooms.
- HIPAA Compliance: You can now create a clean room with a HIPAA compliance security profile. See Step 2. Create a clean room.
- Federated Sharing (Preview): Take advantage of the new query federation feature to seamlessly collaborate with partners across clouds and data platforms without replicating or migrating all the data. See What is Lakehouse Federation?.
Connect AI agent tools to external services (Public Preview)
January 29, 2025
AI agent tools can now connect to external applications like Slack, Google Calendar, or any service with an API using HTTP requests. Agents can use externally connected tools to automate tasks, send messages, and retrieve data from third-party platforms. See Connect AI agent tools to external services.
Delta Live Tables now supports publishing to tables in multiple schemas and catalogs
January 27 - February 5, 2025
By default, new pipelines created in Delta Live Tables now support creating and updating materialized views and streaming tables in multiple catalogs and schemas.
The new default behavior for pipeline configuration requires that users specify a target schema that becomes the default schema for the pipeline. The LIVE virtual schema and associated syntax is no longer required. For more details, see the following:
Databricks Runtime 16.2 (Beta)
January 27, 2025
Databricks Runtime 16.2 and Databricks Runtime 16.2 ML are now available as Beta releases.
See Databricks Runtime 16.2 and Databricks Runtime 16.2 for Machine Learning.
Comments now support email notifications and @ mentions
January 25, 2025
You can now mention users directly in comments by typing “@” followed by their username. Users will be notified of relevant comment activity through email. See Code comments.
Shortcut to adjust font size
January 25, 2025
You can now use a shortcut to quickly adjust the font size in the notebook, file, and SQL editors. Use Alt + and Alt - for Windows/Linux, or Opt + and Opt - for macOS.
There’s also a developer setting to control the editor font size. Navigate to Settings > Developer > Editor font size and select a font size.
OAuth token federation is now available in Public Preview
January 24, 2025
OAuth token federation is now available in Public Preview for account administrators.
Databricks OAuth token federation allows you to securely access Databricks APIs using tokens from your identity provider (IdP). OAuth token federation eliminates the need to manage Databricks secrets such as personal access tokens and Databricks OAuth client secrets.
Unless a Databricks account administrator makes modifications to policies, there will be no changes to current identity configuration and permissions. This feature can be applied to an entire account or to a specific service principal, which gives administrators flexibility when managing access to Databricks workspace resources.
For more details on using Databricks OAuth token federation to authorize access to your workspace resources, see Authenticate access to Azure Databricks using OAuth token federation.
Note
Microsoft Azure users can also use MS Entra tokens to securely use the Azure Databricks CLI commands and API calls.
Custom Python AI agents now support AI Gateway and streaming output
January 24, 2025
Mosaic AI Agent Framework now supports streaming output for deployed custom Python agents, improving the end-user experience and time to first token.
AI Gateway inference tables are now automatically enabled for custom Python agents, providing access to enhanced logging metadata. See Author AI agents in code.
Import workspace files with drag-and-drop
January 24, 2025
You can now drag and drop files and folders to import them into your workspace. Drag-and-drop works on the primary file browser page and the workspace file browser side panel, which is available in the notebook, query, and file editors. See Import a file.
Meta Llama 3.3 now powers AI Functions that use Foundation Model APIs
January 24, 2025
AI Functions that use Foundation Model APIs are now powered by Meta Llama 3.3 70B Instruct for chat tasks.
Notebook output improvements
January 23, 2025
The following improvements have been made to the notebook output experience:
- Is one of filtering: In the results table, you can now filter a column using Is one of and choose the values you want to filter for. To do this, click the menu next to a column and click Filter. A filter modal will open for you to add the conditions you want to filter against. To learn more about filtering results, see Filter results.
- Result table copy as: You can now copy a result table as CSV, TSV, or Markdown. Select the data you want to copy, then right-click, select Copy as, and choose the format you’d like. Results are copied to your clipboard. See Copy data to clipboard.
- Download naming: When you download the results of a cell, the download name now corresponds to the notebook name. See Download results.
Faster notebook load times
January 23, 2025
When you first open a notebook, initial load times are now up to 26% faster for a 99-cell notebook and 6% faster for a 10-cell notebook.
Notebooks are now supported as workspace files
January 23, 2025
Notebooks are now supported as workspace files on Databricks Runtime 16.2 and above, and serverless environment 2 and above. You can now programmatically write, read, and delete notebooks just as you would any other file. This allows for programmatic interaction with notebooks from anywhere the workspace filesystem is available. For more information, see Notebooks as workspace files.
Failed tasks in continuous jobs are now automatically retried
January 22, 2025
This release includes an update to Databricks Jobs that improves failure handling for continuous jobs. With this change, task runs in a continuous job automatically retry when a run fails. The task runs are retried with an exponentially increasing delay until the maximum number of allowed retries is reached. See How are failures handled for continuous jobs?.
Notebooks: Databricks Assistant chat history available only to user who initiates it
January 22, 2025
In a notebook, the Databricks Assistant chat history is available only to the user who initiates the chat. For more information about privacy and security for Assistant, see Privacy and security.
Stats collection is now automated by predictive optimization
January 22 - April 30, 2025
Predictive optimization now automatically calculates statistics for Unity Catalog managed tables during writes to managed tables and automated maintenance jobs. See Predictive optimization for Unity Catalog managed tables.
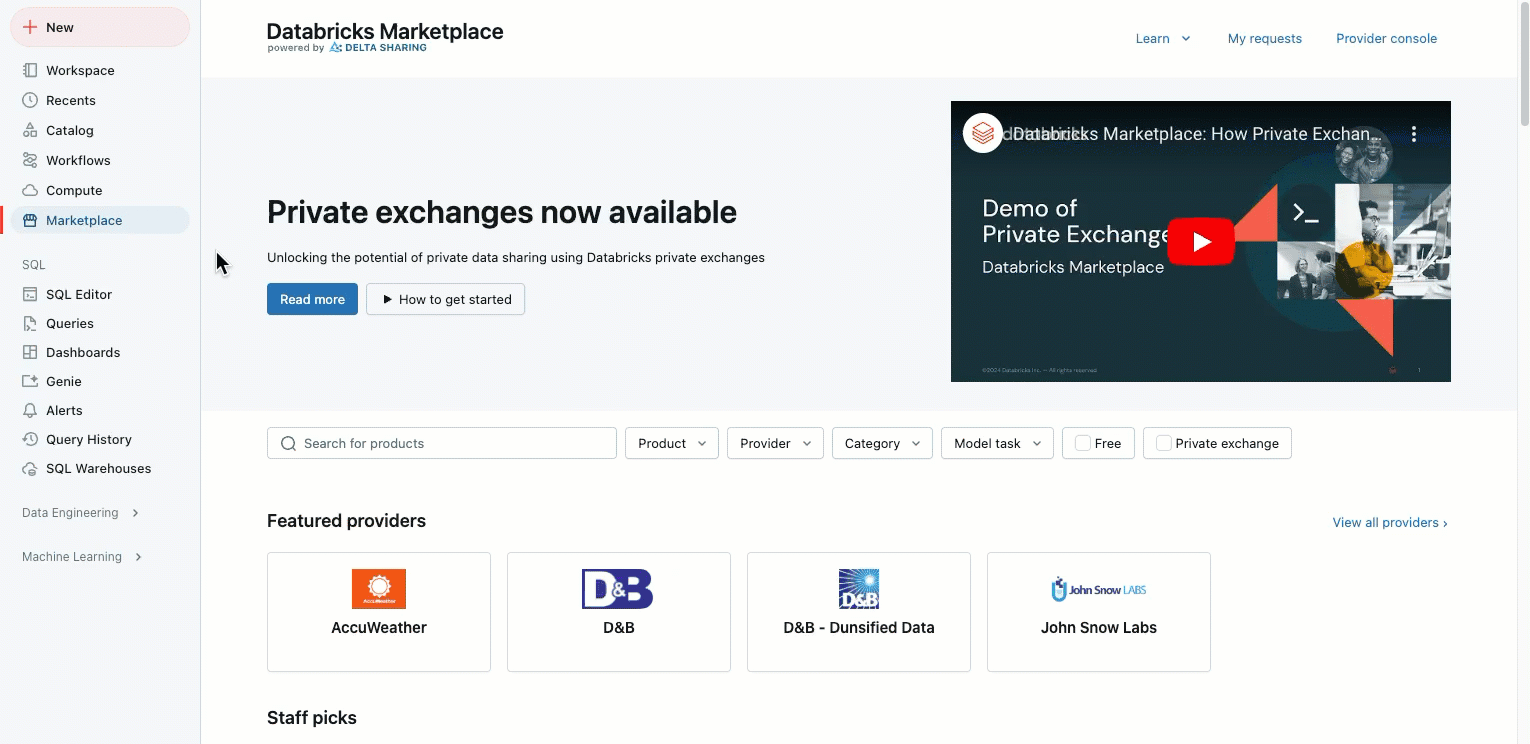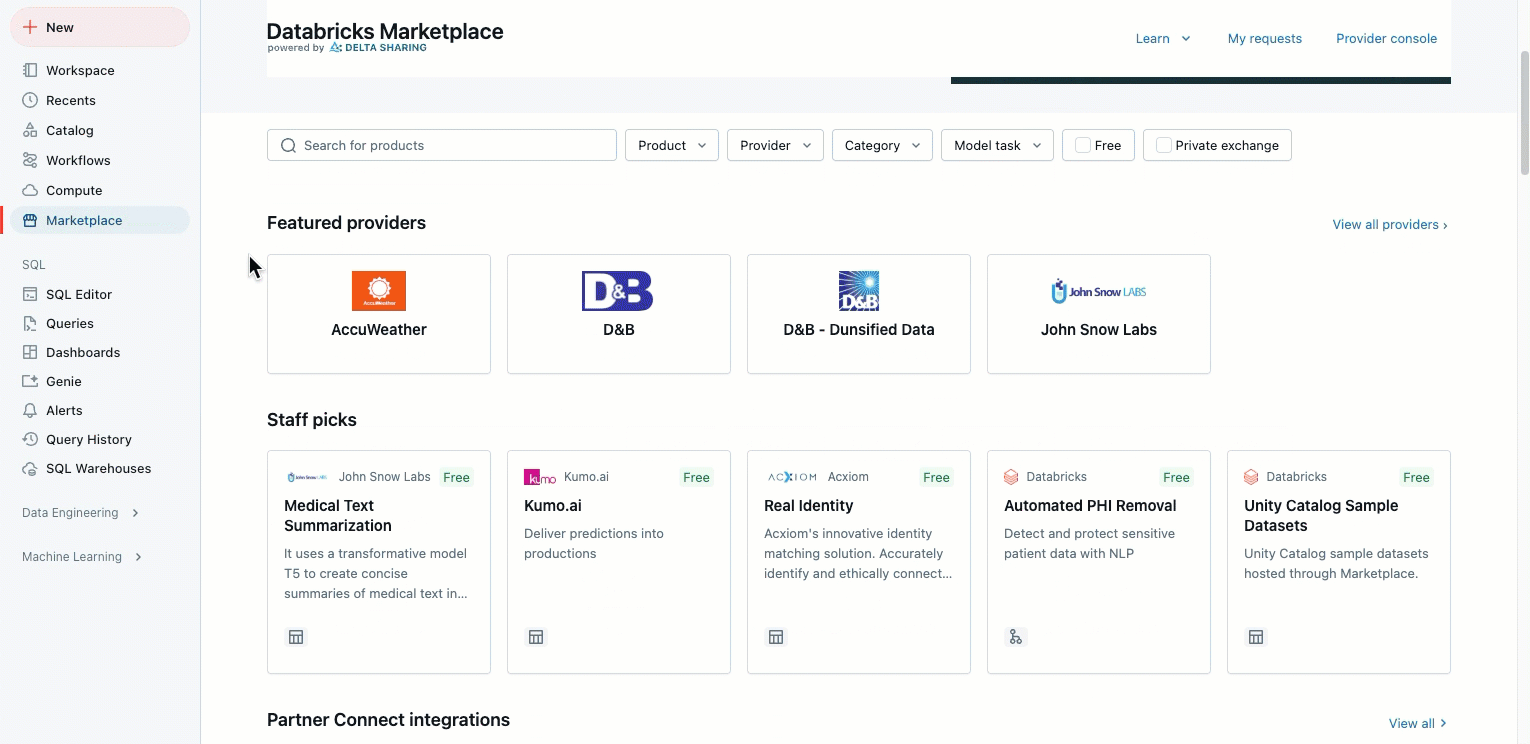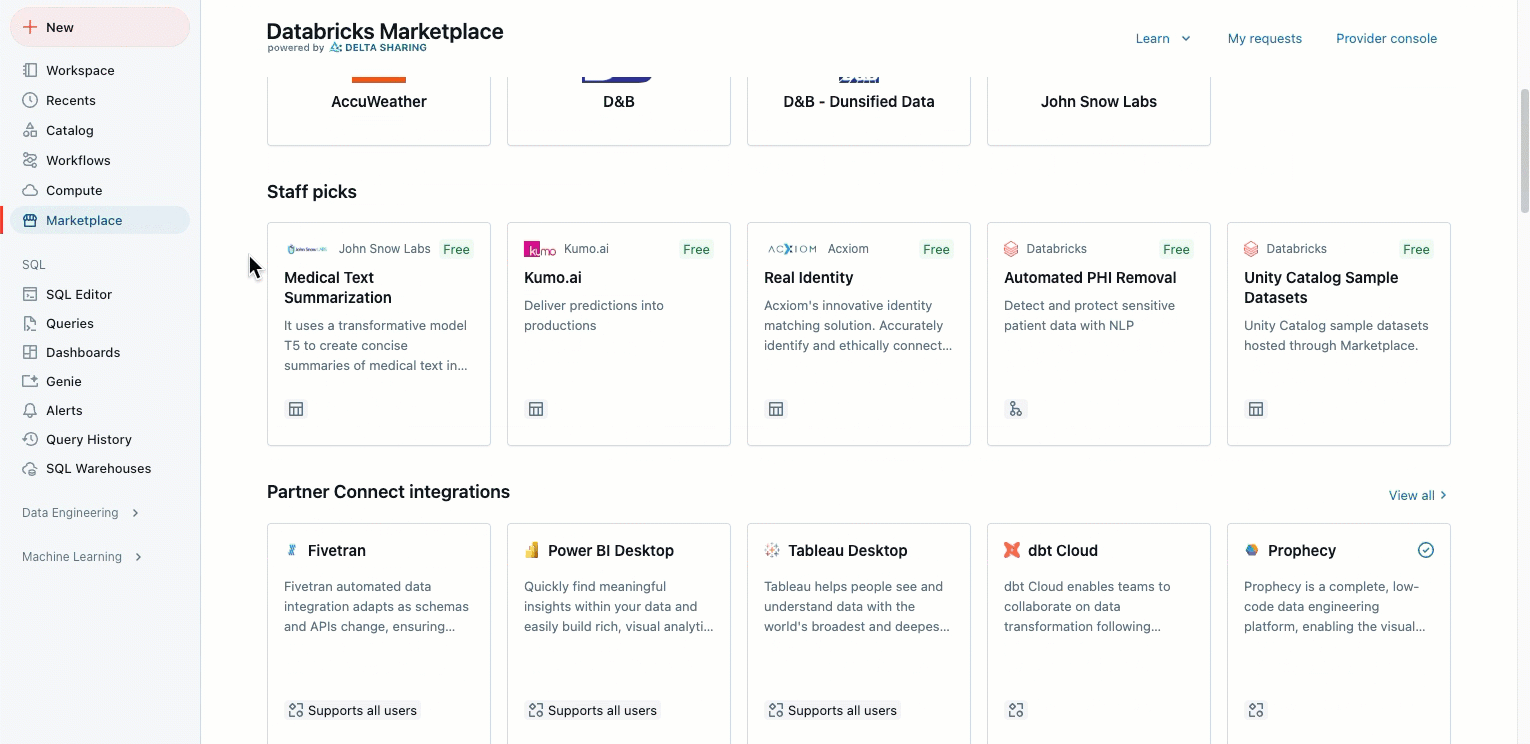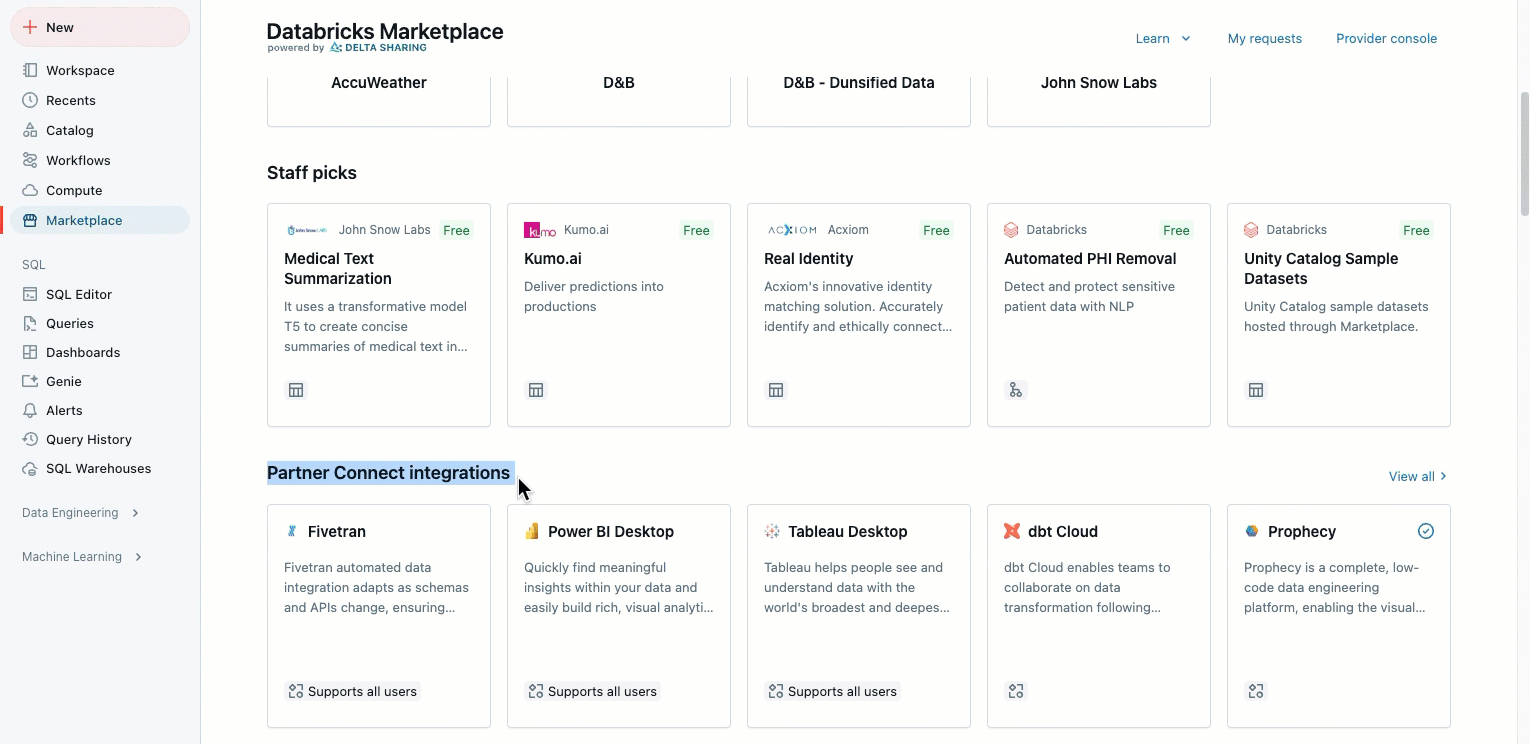
Update to Databricks Marketplace and Partner Connect UI
January 21, 2025
We have simplified the sidebar by combining Partner Connect and Marketplace into a single Marketplace link. The new Marketplace link is positioned higher on the sidebar for easier access.
Databricks JDBC driver 2.7.1
January 16, 2025
The Databricks JDBC Driver version 2.7.1 is now available for download from the JDBC driver download page.
This release includes the following enhancements and new features:
- Added a new
OAuthEnabledIPAddressRangesproperty that allows clients to override the default OAuth callback port(s), facilitating OAuth token acquisition in environments with network port restrictions. - Refresh token support is now available. This enables the driver to automatically refresh authentication tokens using the
Auth_RefreshTokenproperty. - Added support to use the system’s trusted store with a new
UseSystemTrustStoreproperty. When enabled (UseSystemTrustStore=1), the driver verifies connections using certificates from the system’s trusted store. - Added
UseServerSSLConfigsForOAuthEndPointproperty that when it is enabled, it allows clients to share the driver’s SSL configuration for the OAuth endpoint. - BASIC authentication is now disabled by default. To re-enable it, set the
allowBasicAuthenticationproperty to 1.
This release resolves the following issues:
- Unicode characters when using IBM JRE with the Arrow result set serialization feature are now properly handled.
- Complete error messages and causes for error code 401 are now returned.
- Cloud fetch download handlers are now released when they are finished.
- Heartbeat threads no longer leak when connections are created using the DataSource class.
- A potential
OAuth2Secretleak in the driver log has been resolved. - Query IDs in the driver log are no longer missing.
- Using OAuth token cache no longer hits tag mismatch bug.
This release includes upgrades to several third-party libraries to address vulnerabilities:
- arrow-memory-core 17.0.0 (previously 14.0.2)
- arrow-vector 17.0.0 (previously 14.0.2)
- arrow-format 17.0.0 (previously 14.0.2)
- arrow-memory-netty 17.0.0 (previously 14.0.2)
- arrow-memory-unsafe 17.0.0 (previously 14.0.2)
- commons-codec 1.17.0 (previously 1.15)
- flatbuffers-java 24.3.25 (previously 23.5.26)
- jackson-annotations-2.17.1 (previously 2.16.0)
- jackson-core-2.17.1 (previously 2.16.0)
- jackson-databind-2.17.1 (previously 2.16.0)
- jackson-datatype-jsr310-2.17.1 (previously 2.16.0)
- netty-buffer 4.1.115 (previously 4.1.100)
- netty-common 4.1.115 (previously 4.1.100)
For complete configuration information, see the Databricks JDBC Driver Guide installed with the driver download package.
Lakehouse Federation supports Teradata (Public Preview)
January 15, 2025
You can now run federated queries on data managed by Teradata. See Run federated queries on Teradata.
databricks-agents SDK 0.14.0 release: Custom evaluation metrics
January 14, 2025
With databricks-agents==0.14.0, Mosaic AI Agent Evaluation now supports custom metrics, allowing users to define evaluation metrics tailored to their specific GenAI business use case.
This release also adds support for:
ChatAgentandChatModelfrom themlflow.evaluate(model_type='databricks-agent')harness.- Using
mlflow.evaluate(model_type='databricks-agent')from outside of a Databricks notebook when authenticated using thedatabricksCLI. - Support for nested
RETRIEVALspans in agent traces. - Support for a simple array of dictionaries as the
dataargument tomlflow.evaluate(). - A simpler stdout when running
mlflow.evaluate().
AI Gateway now supports provisioned throughput (Public Preview)
January 10, 2025
Mosaic AI Gateway now supports Foundation Model APIs provisioned throughput workloads on model serving endpoints.
You can now enable the following governance and monitoring features on your model serving endpoints that use provisioned throughput:
- Permission and rate limiting to control who has access and how much access.
- Payload logging to monitor and audit data being sent to model APIs using inference tables.
- Usage tracking to monitor operational usage on endpoints and associated costs using system tables.
- AI Guardrails to prevent unwanted data and unsafe data in requests and responses.
- Traffic routing to minimize production outages during and after deployment.
Databricks Runtime 15.2 series support ends
January 7, 2025
Support for Databricks Runtime 15.2 and Databricks Runtime 15.2 for Machine Learning ended on January 7. See Databricks support lifecycles.
Databricks Runtime 15.3 series support ends
January 7, 2025
Support for Databricks Runtime 15.3 and Databricks Runtime 15.3 for Machine Learning ended on January 7. See Databricks support lifecycles.
Meta Llama 2, 3 and Code Llama model family retirements on Foundation Model Fine-tuning
January 7, 2025
The following model families have been retired and are no longer supported on Foundation Model Fine-tuning. See Retired models for recommended replacement models.
- Meta-Llama-3
- Meta-Llama-2
- Code Llama