Tutorial: Deploy and query a custom model
This article provides the basic steps for deploying and querying a custom model, that is a traditional ML model, using Mosaic AI Model Serving. The model must be registered in Unity Catalog or in the workspace model registry.
To learn about serving and deploying generative AI models instead, see the following articles:
Step 1: Log the model
There are different ways to log your model for model serving:
| Logging technique | Description |
|---|---|
| Autologging | This is automatically turned on when you use Databricks Runtime for machine learning. It’s the easiest way but gives you less control. |
| Logging using MLflow’s built-in flavors | You can manually log the model with MLflow’s built-in model flavors. |
Custom logging with pyfunc |
Use this if you have a custom model or if you need extra steps before or after inference. |
The following example shows how to log your MLflow model using the transformer flavor and specify parameters you need for your model.
with mlflow.start_run():
model_info = mlflow.transformers.log_model(
transformers_model=text_generation_pipeline,
artifact_path="my_sentence_generator",
inference_config=inference_config,
registered_model_name='gpt2',
input_example=input_example,
signature=signature
)
After your model is logged be sure to check that your model is registered in either Unity Catalog or the MLflow Model Registry.
Step 2: Create endpoint using the Serving UI
After your registered model is logged and you are ready to serve it, you can create a model serving endpoint using the Serving UI.
Click Serving in the sidebar to display the Serving UI.
Click Create serving endpoint.
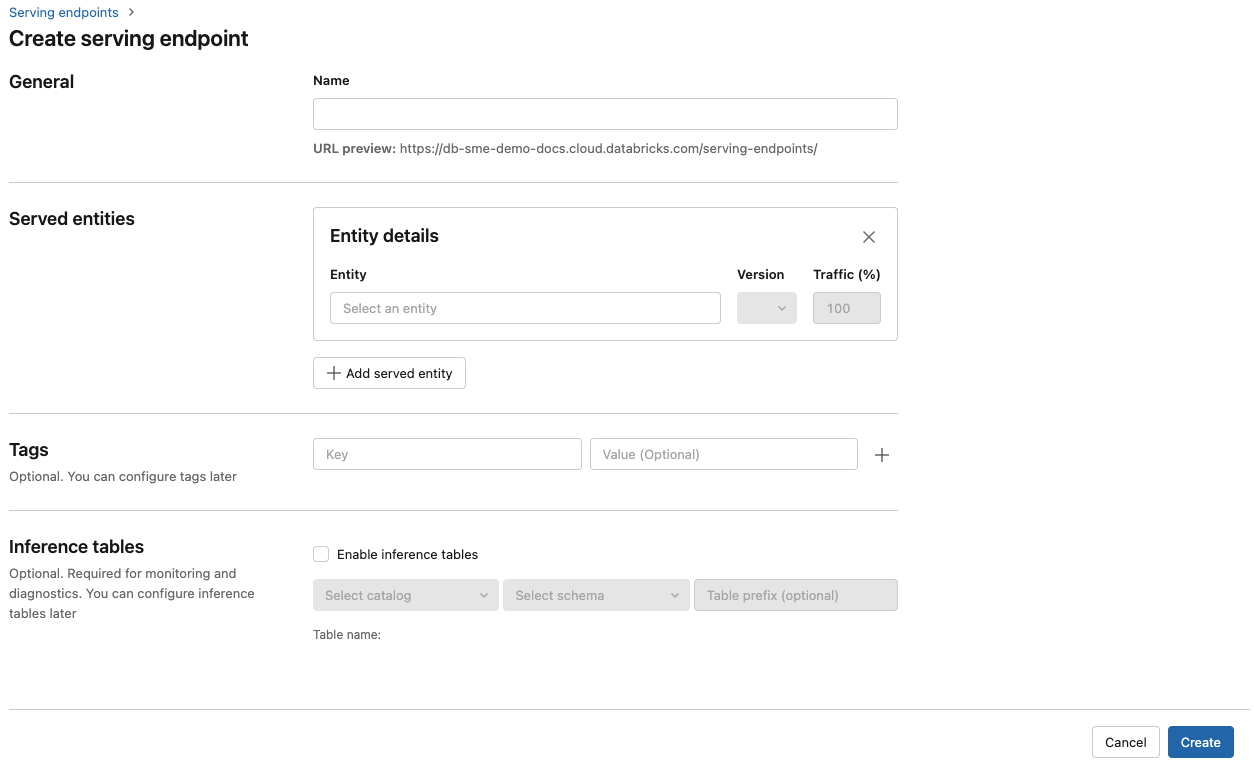
In the Name field, provide a name for your endpoint.
In the Served entities section
- Click into the Entity field to open the Select served entity form.
- Select the type of model you want to serve. The form dynamically updates based on your selection.
- Select which model and model version you want to serve.
- Select the percentage of traffic to route to your served model.
- Select what size compute to use.
- Under Compute Scale-out, select the size of the compute scale out that corresponds with the number of requests this served model can process at the same time. This number should be roughly equal to QPS x model execution time.
- Available sizes are Small for 0-4 requests, Medium 8-16 requests, and Large for 16-64 requests.
- Specify if the endpoint should scale to zero when not in use.
Click Create. The Serving endpoints page appears with Serving endpoint state shown as Not Ready.
If you prefer to create an endpoint programmatically with the Databricks Serving API, see Create custom model serving endpoints.
Step 3: Query the endpoint
The easiest and fastest way to test and send scoring requests to your served model is to use the Serving UI.
From the Serving endpoint page, select Query endpoint.
Insert the model input data in JSON format and click Send Request. If the model has been logged with an input example, click Show Example to load the input example.
{ "inputs" : ["Hello, I'm a language model,"], "params" : {"max_new_tokens": 10, "temperature": 1} }
To send scoring requests, construct a JSON with one of the supported keys and a JSON object corresponding to the input format. See Query serving endpoints for custom models for supported formats and guidance on how to send scoring requests using the API.
If you plan to access your serving endpoint outside of the Azure Databricks Serving UI, you need a DATABRICKS_API_TOKEN.
Important
As a security best practice for production scenarios, Databricks recommends that you use machine-to-machine OAuth tokens for authentication during production.
For testing and development, Databricks recommends using a personal access token belonging to service principals instead of workspace users. To create tokens for service principals, see Manage tokens for a service principal.
Example notebooks
See the following notebook for serving a MLflow transformers model with Model Serving.
Deploy a Hugging Face transformers model notebook
See the following notebook for serving a MLflow pyfunc model with Model Serving. For additional details on customizing your model deployments, see Deploy Python code with Model Serving.