Lakehouse reference architectures (download)
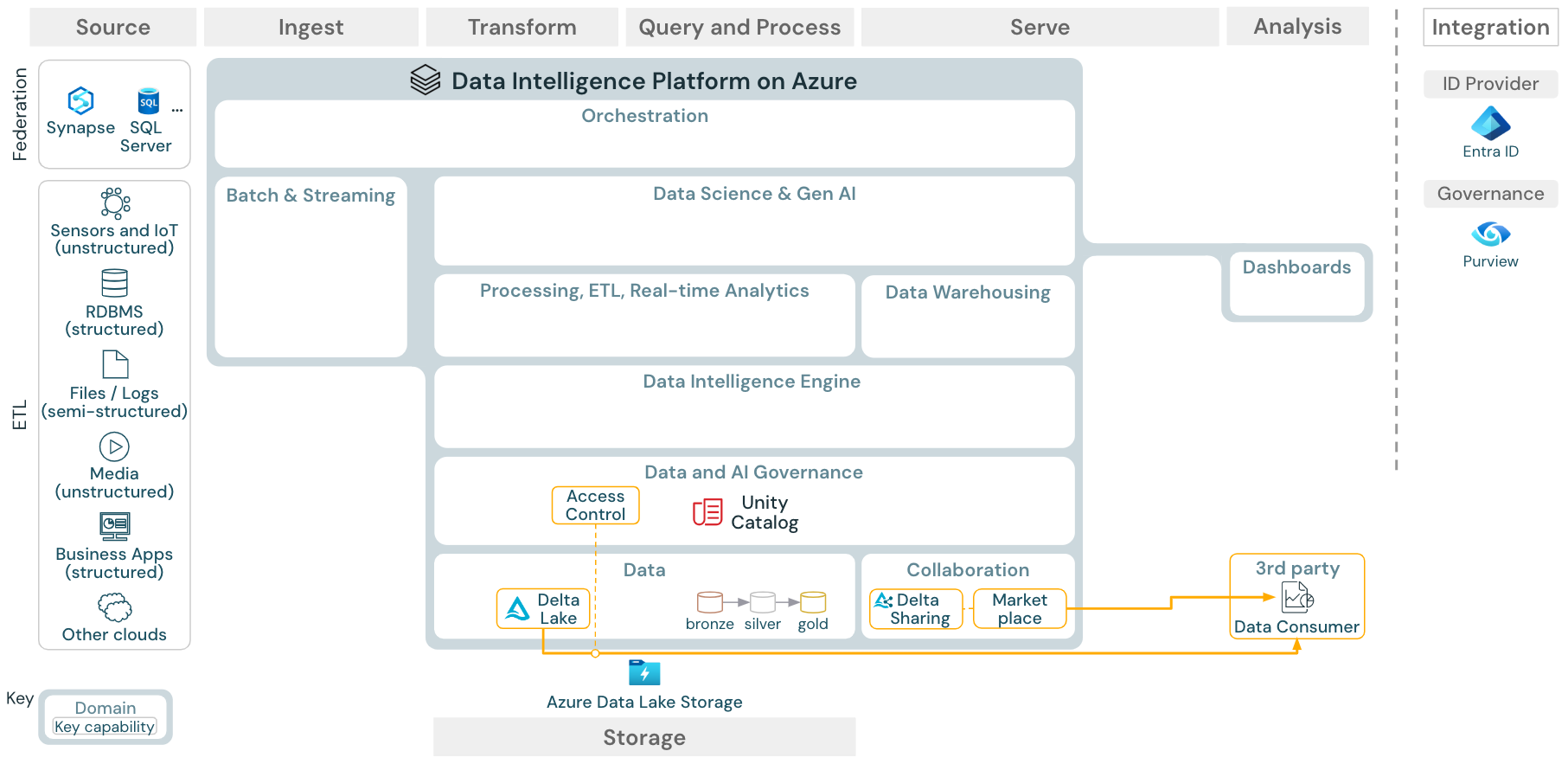
This article covers architectural guidance for the lakehouse in terms of data source, ingestion, transformation, querying and processing, serving, analysis, and storage.
Each reference architecture has a downloadable PDF in 11 x 17 (A3) format.
While the lakehouse on Databricks is an open platform that integrates with a large ecosystem of partner tools, the reference architectures focus only on Azure services and the Databricks lakehouse. The cloud provider services shown are selected to illustrate the concepts and are not exhaustive.
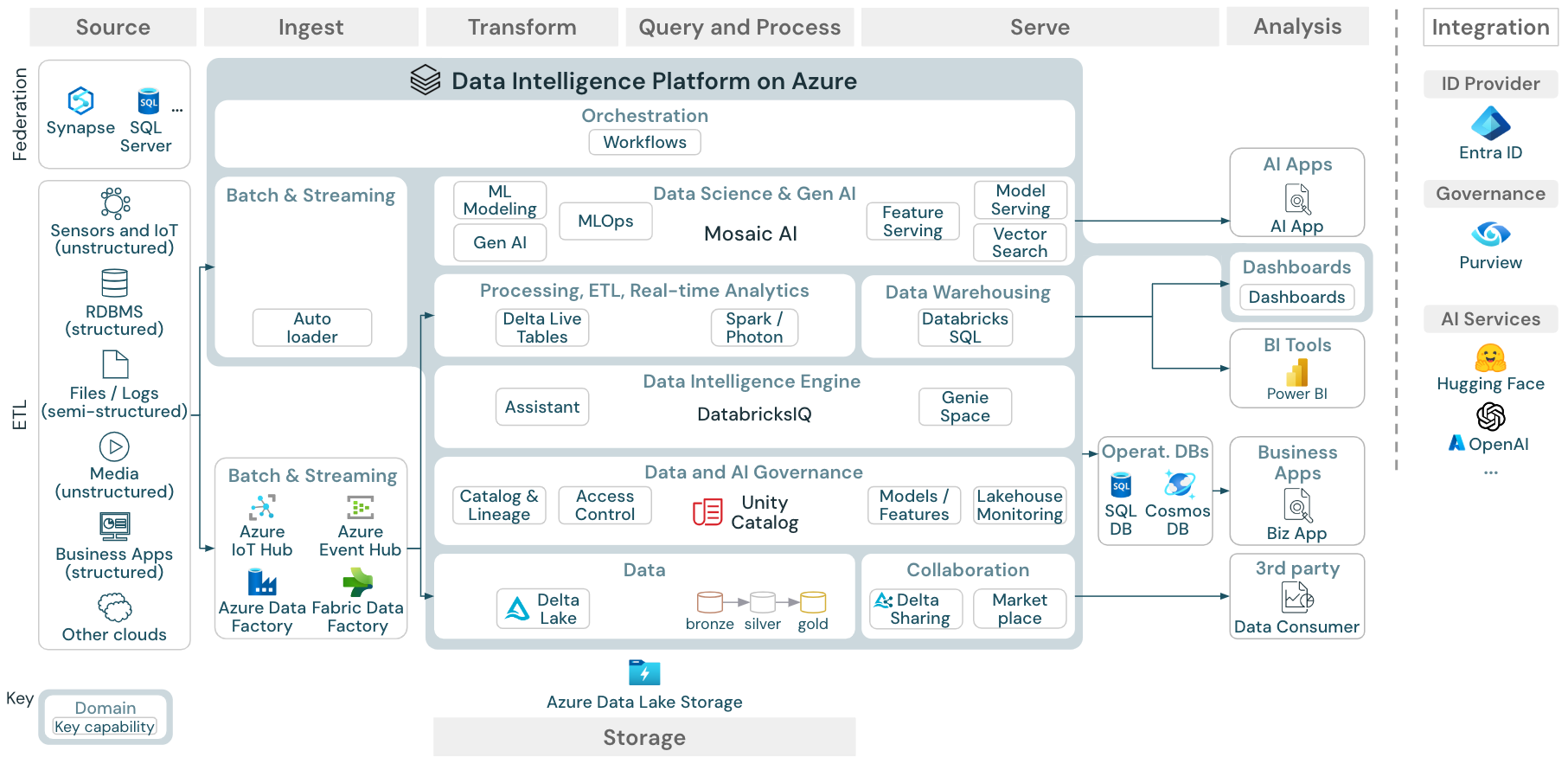
Download: Reference architecture for the Azure Databricks lakehouse
The Azure reference architecture shows the following Azure-specific services for ingesting, storage, serving, and analysis:
- Azure Synapse and SQL Server as source systems for Lakehouse Federation
- Azure IoT Hub and Azure Event Hubs for streaming ingest
- Azure Data Factory for batch ingest
- Azure Data Lake Storage Gen 2 (ADLS) as the object storage
- Azure SQL DB and Azure Cosmos DB as operational databases
- Azure Purview as the enterprise catalog to which UC exports schema and lineage information
- Power BI as the BI tool
Organization of the reference architectures
The reference architecture is structured along the swim lanes Source, Ingest, Transform, Query/Process, Serve, Analysis, and Storage:
Source
The architecture distinguishes between semi-structured and unstructured data (sensors and IoT, media, files/logs), and structured data (RDBMS, business applications). SQL sources (RDBMS) can also be integrated into the lakehouse and Unity Catalog without ETL through lakehouse federation. In addition, data might be loaded from other cloud providers.
Ingest
Data can be ingested into the lakehouse via batch or streaming:
- Databricks LakeFlow Connect offers built-in connectors for ingestion from enterprise applications and databases. The resulting ingestion pipeline is governed by Unity Catalog and is powered by serverless compute and Delta Live Tables.
- Files delivered to cloud storage can be loaded directly using the Databricks Auto Loader.
- For batch ingestion of data from enterprise applications into Delta Lake, the Databricks lakehouse relies on partner ingest tools with specific adapters for these systems of record.
- Streaming events can be ingested directly from event streaming systems such as Kafka using Databricks Structured Streaming. Streaming sources can be sensors, IoT, or change data capture processes.
Storage
Data is typically stored in the cloud storage system where the ETL pipelines use the medallion architecture to store data in a curated way as Delta files/tables.
Transform and Query / process
The Databricks lakehouse uses its engines Apache Spark and Photon for all transformations and queries.
DLT (Delta Live Tables) is a declarative framework for simplifying and optimizing reliable, maintainable, and testable data processing pipelines.
Powered by Apache Spark and Photon, the Databricks Data Intelligence Platform supports both types of workloads: SQL queries via SQL warehouses, and SQL, Python and Scala workloads via workspace clusters.
For data science (ML Modeling and Gen AI), the Databricks AI and Machine Learning platform provides specialized ML runtimes for AutoML and for coding ML jobs. All data science and MLOps workflows are best supported by MLflow.
Serving
For DWH and BI use cases, the Databricks lakehouse provides Databricks SQL, the data warehouse powered by SQL warehouses, and serverless SQL warehouses.
For machine learning, model serving is a scalable, real-time, enterprise-grade model serving capability hosted in the Databricks control plane. Mosaic AI Gateway is Databricks solution for governing and monitoring access to supported generative AI models and their associated model serving endpoints.
Operational databases: External systems, such as operational databases, can be used to store and deliver final data products to user applications.
Collaboration: Business partners get secure access to the data they need through Delta Sharing. Based on Delta Sharing, the Databricks Marketplace is an open forum for exchanging data products.
Analysis
The final business applications are in this swim lane. Examples include custom clients such as AI applications connected to Mosaic AI Model Serving for real-time inference or applications that access data pushed from the lakehouse to an operational database.
For BI use cases, analysts typically use BI tools to access the data warehouse. SQL developers can additionally use the Databricks SQL Editor (not shown in the diagram) for queries and dashboarding.
The Data Intelligence Platform also offers dashboards to build data visualizations and share insights.
Integrate
- The Databricks platform integrates with standard identity providers for user management and single sign on (SSO).
External AI services like OpenAI, LangChain or HuggingFace can be used directly from within the Databricks Intelligence Platform.
External orchestrators can either use the comprehensive REST API or dedicated connectors to external orchestration tools like Apache Airflow.
Unity Catalog is used for all data & AI governance in the Databricks Intelligence Platform and can integrate other databases into its governance through Lakehouse Federation.
Additionally, Unity Catalog can be integrated into other enterprise catalogs, e.g. Purview. Contact the enterprise catalog vendor for details.
Common capabilities for all workloads
In addition, the Databricks lakehouse comes with management capabilities that support all workloads:
Data and AI governance
The central data and AI governance system in the Databricks Data Intelligence Platform is Unity Catalog. Unity Catalog provides a single place to manage data access policies that apply across all workspaces and supports all assets created or used in the lakehouse, such as tables, volumes, features (feature store), and models (model registry). Unity Catalog can also be used to capture runtime data lineage across queries run on Databricks.
Databricks lakehouse monitoring allows you to monitor the data quality of all of the tables in your account. It can also track the performance of machine learning models and model-serving endpoints.
For observability, system tables is a Databricks-hosted analytical store of your account’s operational data. System tables can be used for historical observability across your account.
Data intelligence engine
The Databricks Data Intelligence Platform allows your entire organization to use data and AI. It is powered by DatabricksIQ and combines generative AI with the unification benefits of a lakehouse to understand the unique semantics of your data.
The Databricks Assistant is available in Databricks notebooks, SQL editor, and file editor as a context-aware AI assistant for developers.
Automation & Orchestration
Databricks Jobs orchestrate data processing, machine learning, and analytics pipelines on the Databricks Data Intelligence Platform. Delta Live Tables allow you to build reliable and maintainable ETL pipelines with declarative syntax. The platform also supports CI/CD and MLOps
High-level use cases for the Data Intelligence Platform on Azure
Databricks LakeFlow Connect offers built-in connectors for ingestion from enterprise applications and databases. The resulting ingestion pipeline is governed by Unity Catalog and is powered by serverless compute and Delta Live Tables. LakeFlow Connect leverages efficient incremental reads and writes to make data ingestion faster, scalable, and more cost-efficient, while your data remains fresh for downstream consumption.
Use case: Ingestion with Lakeflow Connect:
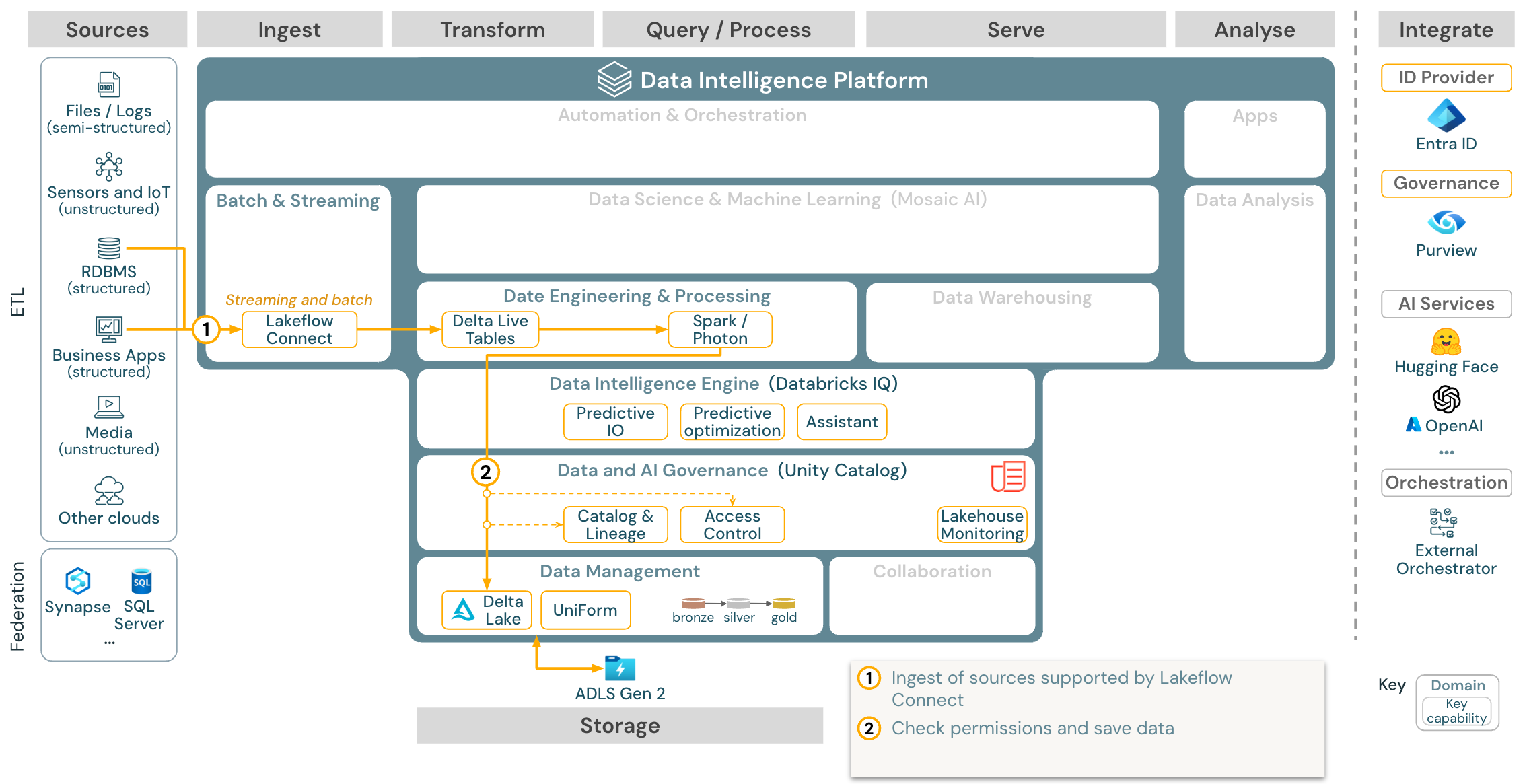
Download: Batch ETL reference architecture for Azure Databricks.
Use case: Batch ETL
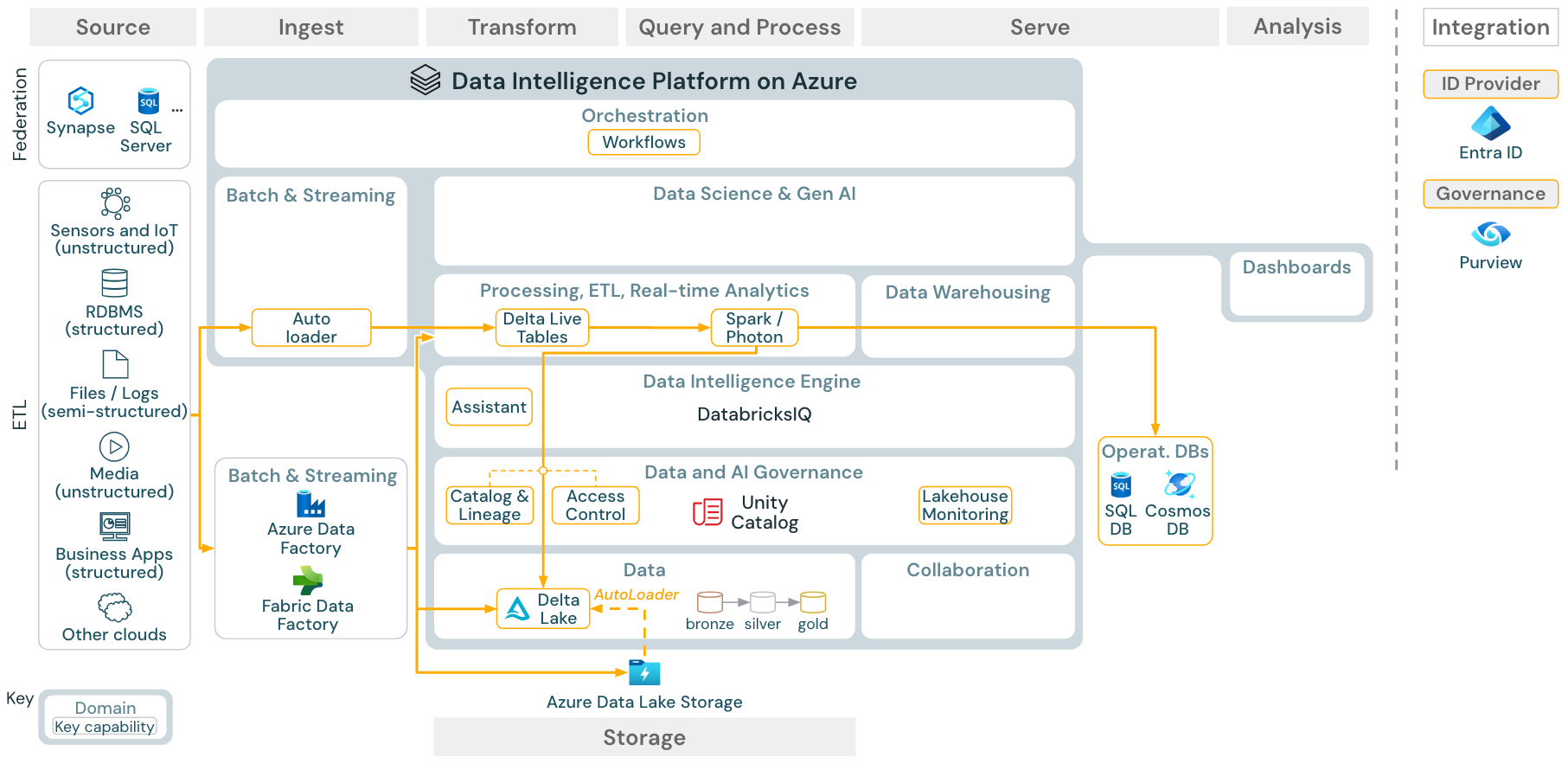
Download: Batch ETL reference architecture for Azure Databricks
Ingest tools use source-specific adapters to read data from the source and then either store it in the cloud storage from where Auto Loader can read it, or call Databricks directly (for example, with partner ingest tools integrated into the Databricks lakehouse). To load the data, the Databricks ETL and processing engine - via DLT - runs the queries. Single or multitask workflows can be orchestrated by Databricks Jobs and governed by Unity Catalog (access control, audit, lineage, and so on). If low-latency operational systems require access to specific golden tables, they can be exported to an operational database such as an RDBMS or key-value store at the end of the ETL pipeline.
Use case: Streaming and change data capture (CDC)
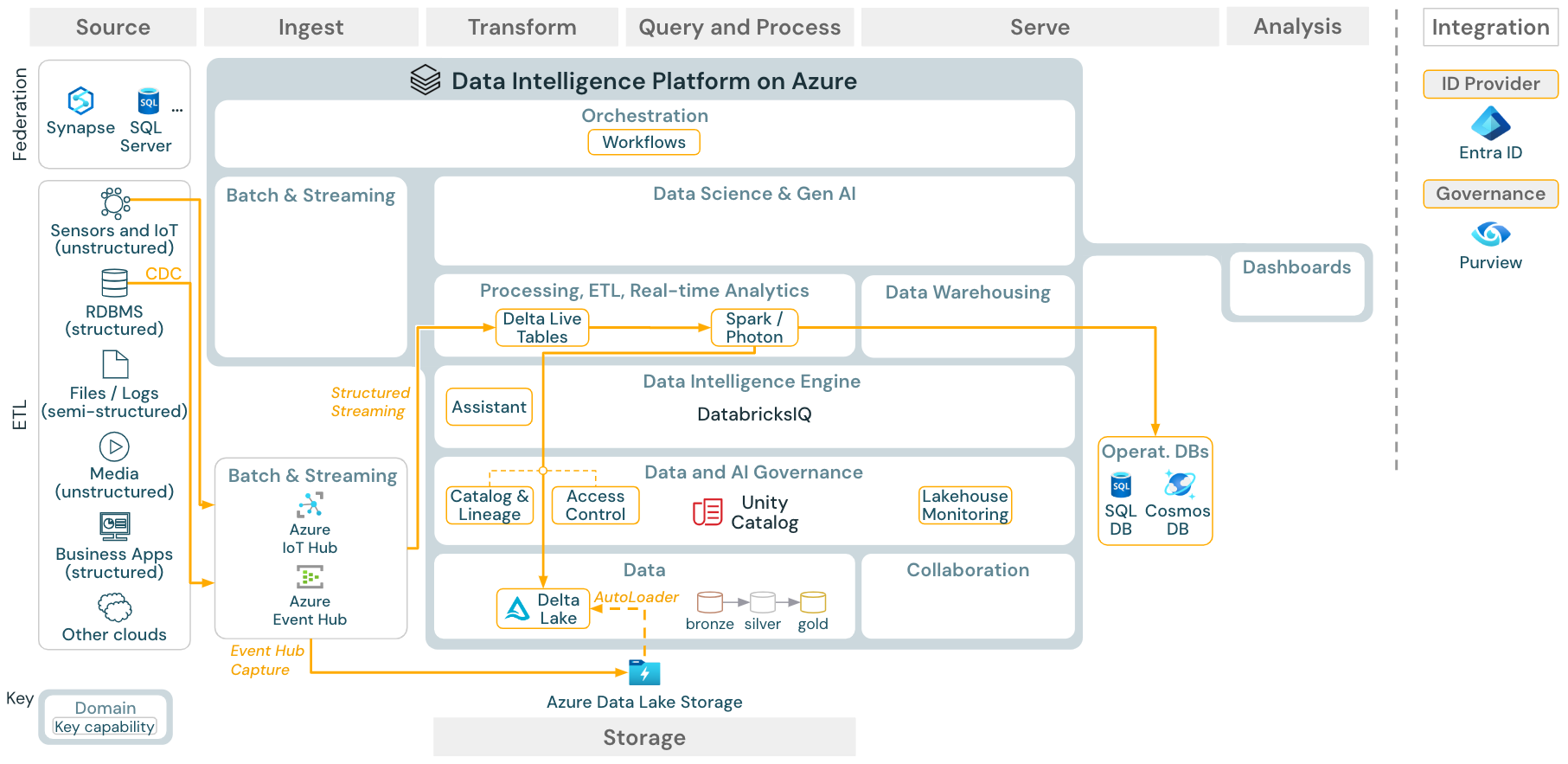
Download: Spark structured streaming architecture for Azure Databricks
The Databricks ETL engine uses Spark Structured Streaming to read from event queues such as Apache Kafka or Azure Event Hub. The downstream steps follow the approach of the Batch use case above.
Real-time change data capture (CDC) typically uses an event queue to store the extracted events. From there, the use case follows the streaming use case.
If CDC is done in batch where the extracted records are stored in cloud storage first, then Databricks Autoloader can read them and the use case follows Batch ETL.
Use case: Machine learning and AI
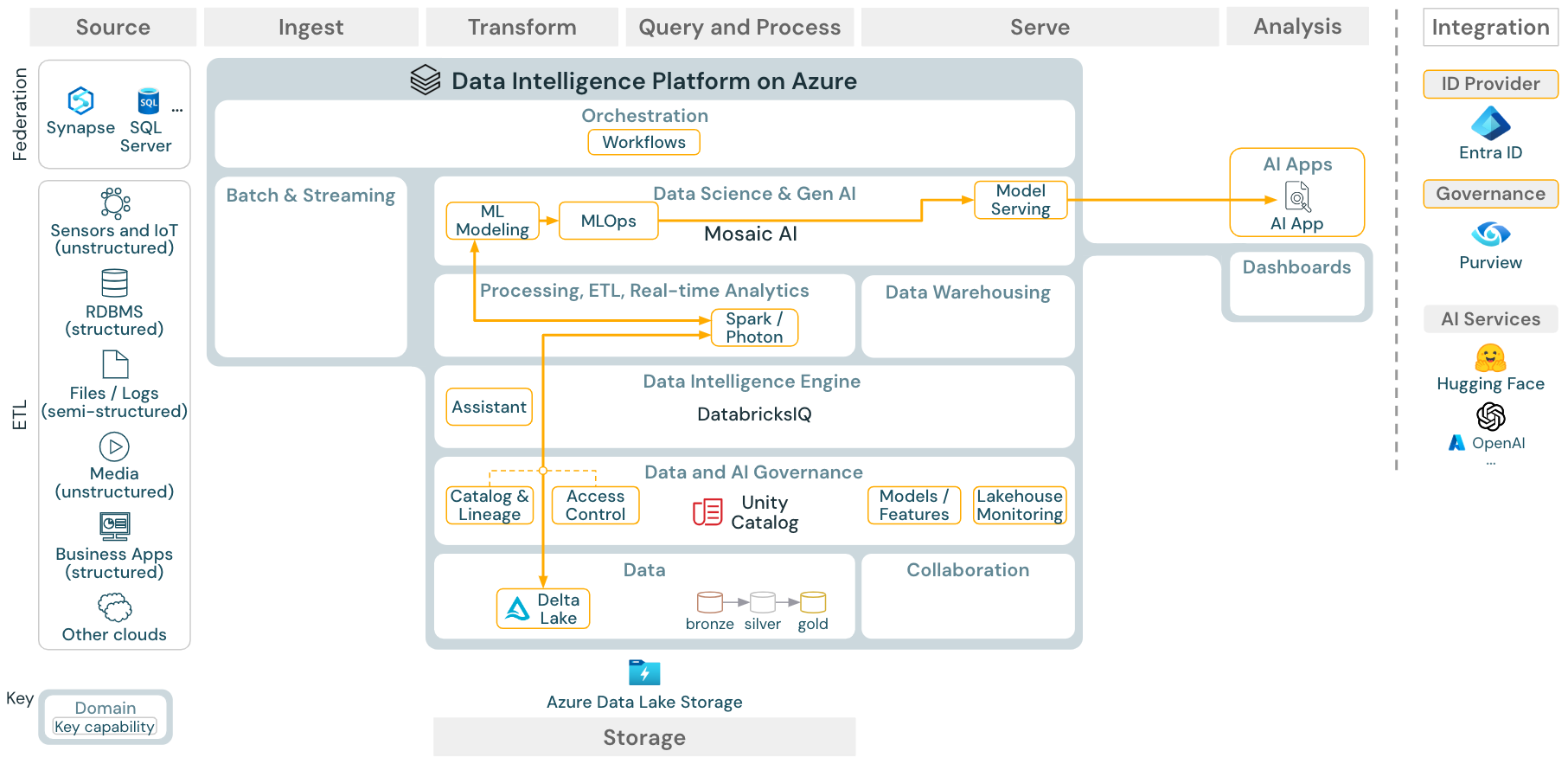
Download: Machine learning and AI reference architecture for Azure Databricks
For machine learning, the Databricks Data Intelligence Platform provides Mosaic AI, which comes with state-of-the-art machine and deep learning libraries. It provides capabilities such as Feature Store and model registry (both integrated into Unity Catalog), low-code features with AutoML, and MLflow integration into the data science lifecycle.
All data science-related assets (tables, features, and models) are governed by Unity Catalog and data scientists can use Databricks Jobs to orchestrate their jobs.
For deploying models in a scalable and enterprise-grade way, use the MLOps capabilities to publish the models in model serving.
Use case: Generative AI (Gen AI) agent applications
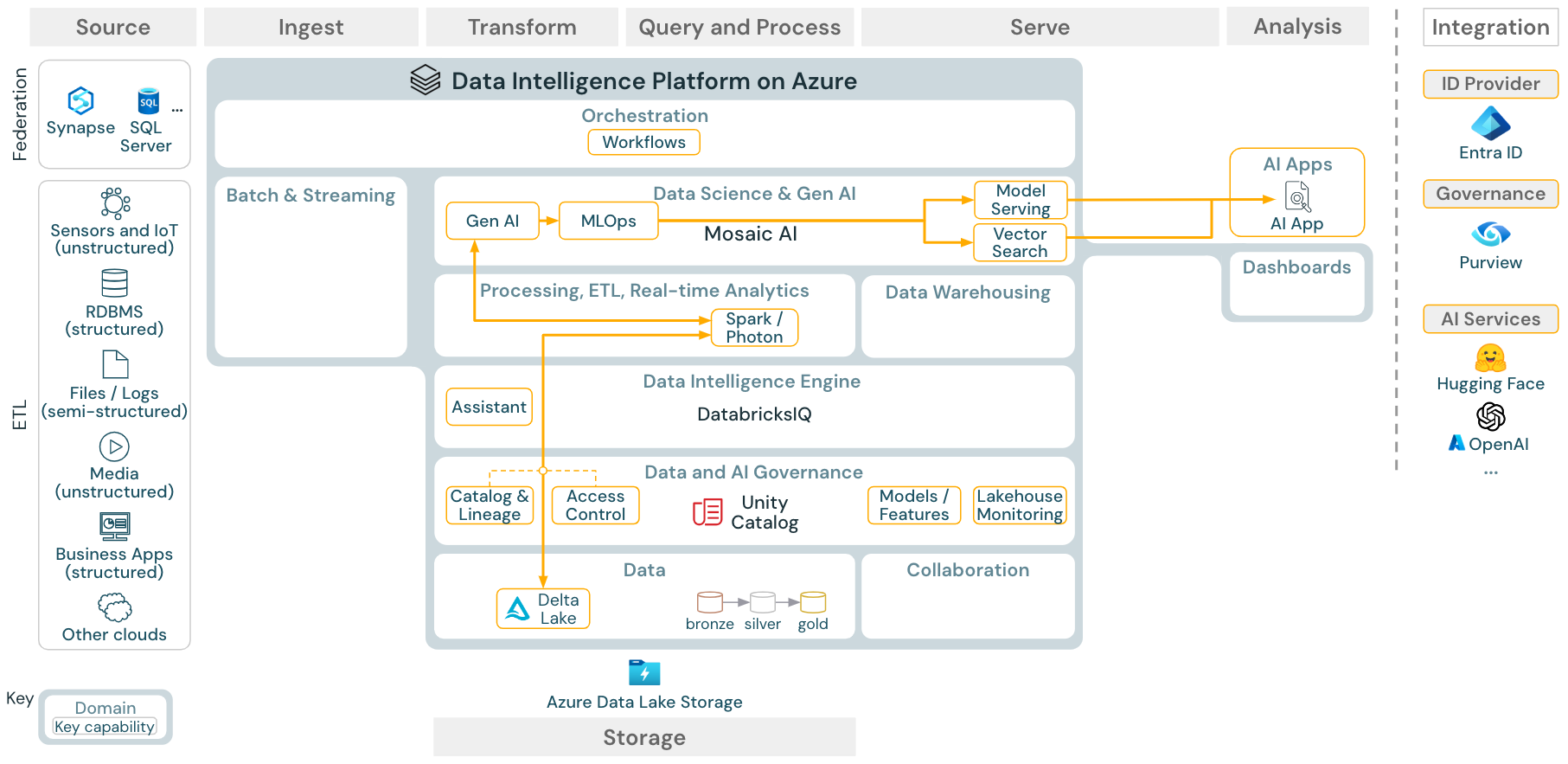
Download: Gen AI application reference architecture for Azure Databricks
For generative AI use cases, Mosaic AI comes with state-of-the-art libraries and specific gen AI capabilities from prompt engineering to fine-tuning of existing models and pre-training from scratch. The above architecture shows an example of how vector search can be integrated to create a gen AI application using RAG (retrieval augmented generation).
For deploying models in a scalable and enterprise-grade way, use the MLOps capabilities to publish the models in model serving.
Use case: BI and SQL analytics
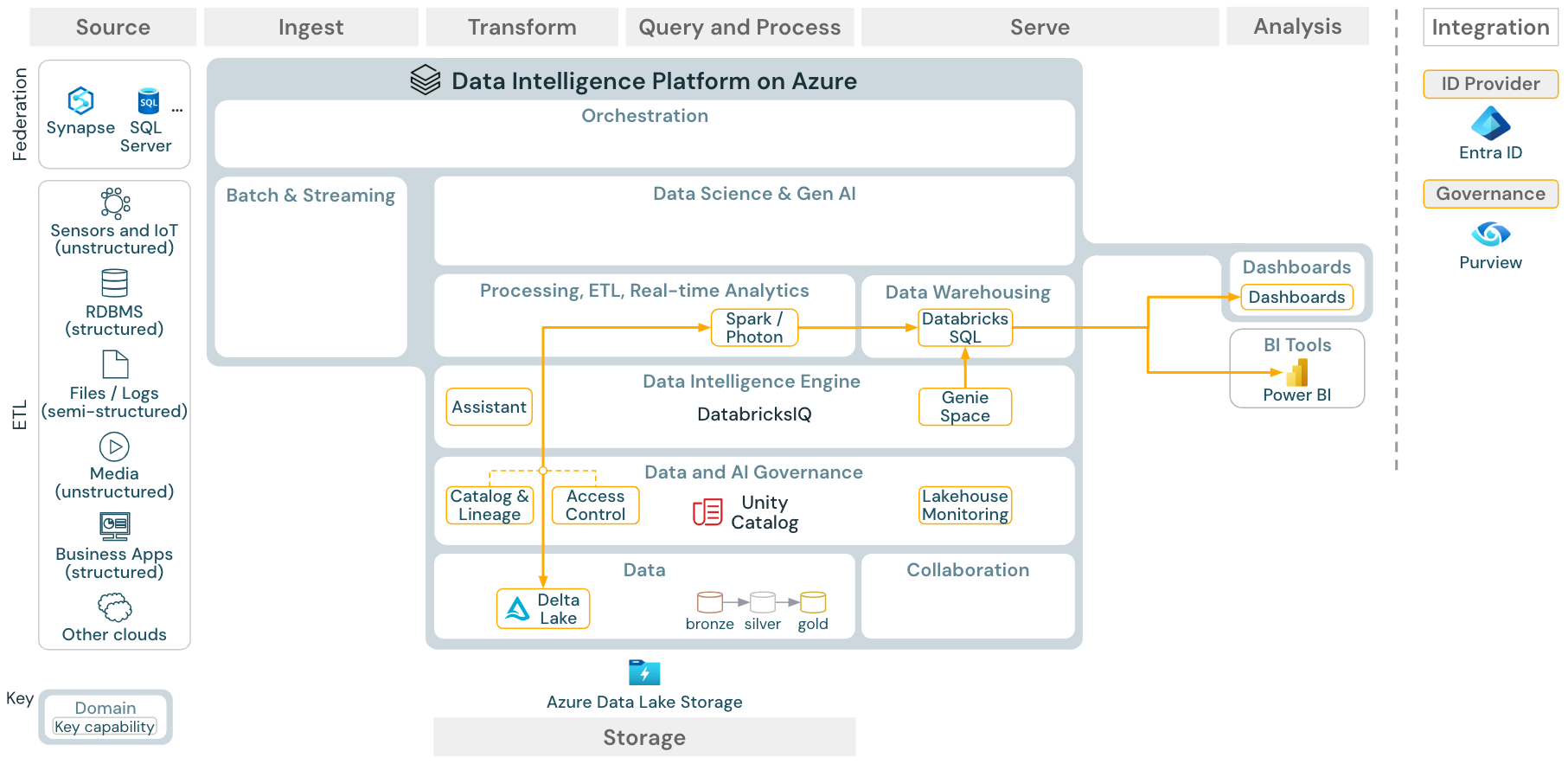
Download: BI and SQL analytics reference architecture for Azure Databricks
For BI use cases, business analysts can use dashboards, the Databricks SQL editor or specific BI tools such as Tableau or Power BI. In all cases, the engine is Databricks SQL (serverless or non-serverless) and data discovery, exploration, and access control are provided by Unity Catalog.
Use case: Lakehouse federation
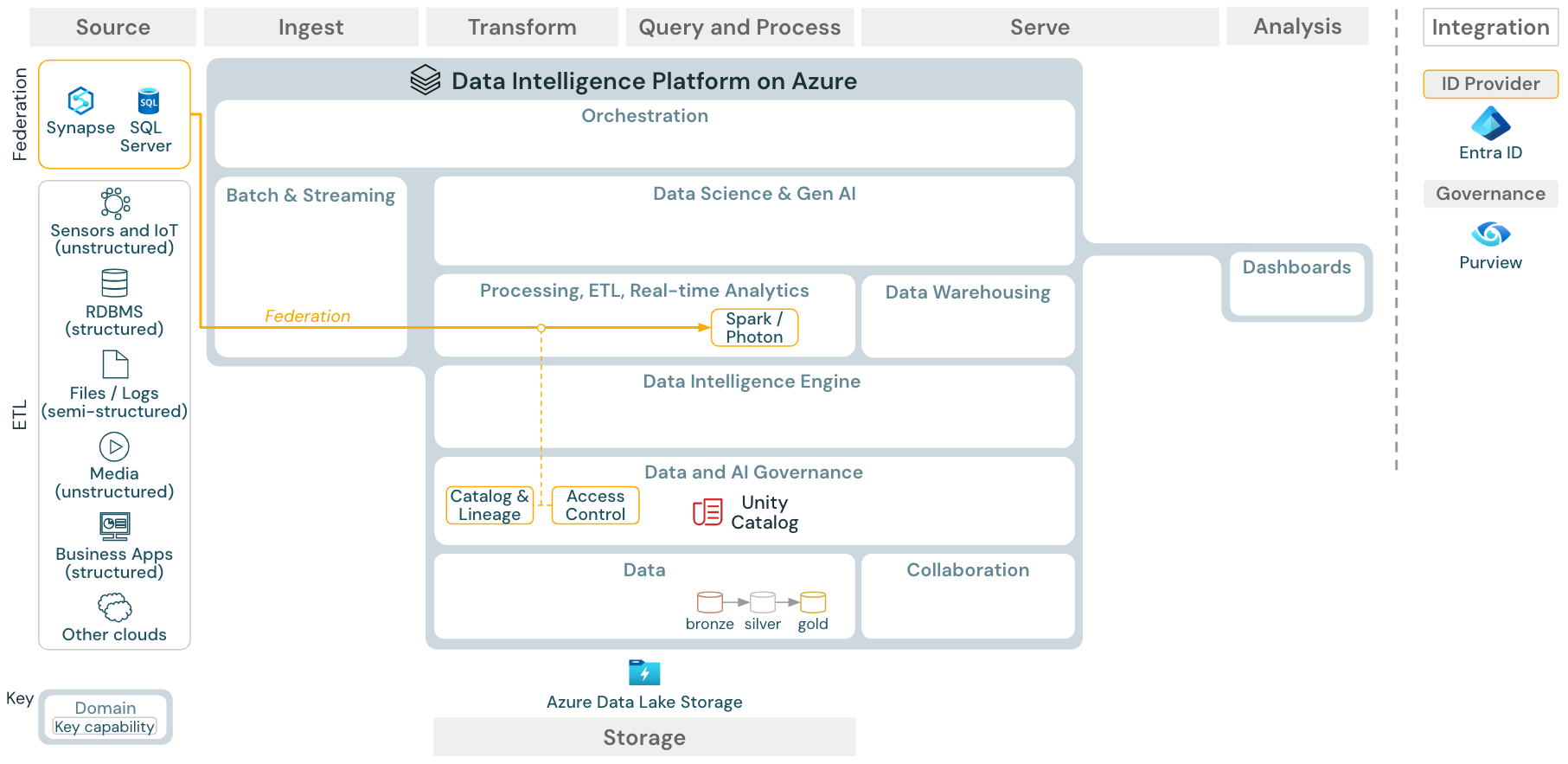
Download: Lakehouse federation reference architecture for Azure Databricks
Lakehouse federation allows external data SQL databases (such as MySQL, Postgres, SQL Server, or Azure Synapse) to be integrated with Databricks.
All workloads (AI, DWH, and BI) can benefit from this without the need to ETL the data into object storage first. The external source catalog is mapped into the Unity catalog and fine-grained access control can be applied to access via the Databricks platform.
Use case: Enterprise data sharing
Download: Enterprise data sharing reference architecture for Azure Databricks
Enterprise-grade data sharing is provided by Delta Sharing. It provides direct access to data in the object store secured by Unity Catalog, and Databricks Marketplace is an open forum for exchanging data products.