How to generate embeddings with Azure AI model inference
Important
Items marked (preview) in this article are currently in public preview. This preview is provided without a service-level agreement, and we don't recommend it for production workloads. Certain features might not be supported or might have constrained capabilities. For more information, see Supplemental Terms of Use for Microsoft Azure Previews.
This article explains how to use embeddings API with models deployed to Azure AI model inference in Azure AI services.
Prerequisites
To use embedding models in your application, you need:
An Azure subscription. If you're using GitHub Models, you can upgrade your experience and create an Azure subscription in the process. Read Upgrade from GitHub Models to Azure AI model inference if that's your case.
An Azure AI services resource. For more information, see Create an Azure AI Services resource.
The endpoint URL and key.
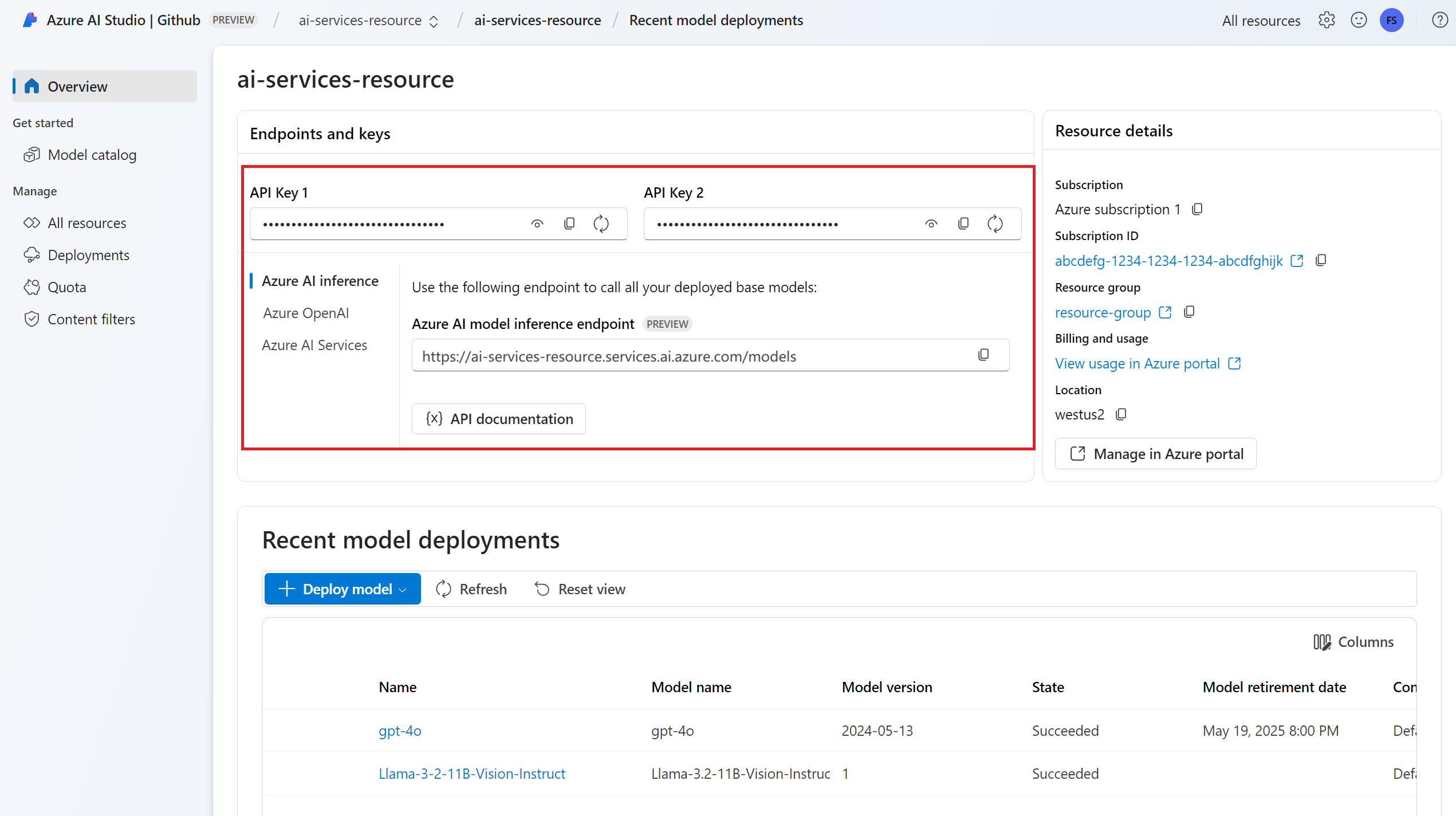

An embeddings model deployment. If you don't have one read Add and configure models to Azure AI services to add an embeddings model to your resource.
Install the Azure AI inference package with the following command:
pip install -U azure-ai-inferenceTip
Read more about the Azure AI inference package and reference.
Use embeddings
First, create the client to consume the model. The following code uses an endpoint URL and key that are stored in environment variables.
import os
from azure.ai.inference import EmbeddingsClient
from azure.core.credentials import AzureKeyCredential
model = EmbeddingsClient(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=AzureKeyCredential(os.environ["AZURE_INFERENCE_CREDENTIAL"]),
model="text-embedding-3-small"
)
If you have configured the resource to with Microsoft Entra ID support, you can use the following code snippet to create a client.
import os
from azure.ai.inference import EmbeddingsClient
from azure.core.credentials import AzureKeyCredential
model = EmbeddingsClient(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=DefaultAzureCredential(),
model="text-embedding-3-small"
)
Create embeddings
Create an embedding request to see the output of the model.
response = model.embed(
input=["The ultimate answer to the question of life"],
)
Tip
When creating a request, take into account the token's input limit for the model. If you need to embed larger portions of text, you would need a chunking strategy.
The response is as follows, where you can see the model's usage statistics:
import numpy as np
for embed in response.data:
print("Embeding of size:", np.asarray(embed.embedding).shape)
print("Model:", response.model)
print("Usage:", response.usage)
It can be useful to compute embeddings in input batches. The parameter inputs can be a list of strings, where each string is a different input. In turn the response is a list of embeddings, where each embedding corresponds to the input in the same position.
response = model.embed(
input=[
"The ultimate answer to the question of life",
"The largest planet in our solar system is Jupiter",
],
)
The response is as follows, where you can see the model's usage statistics:
import numpy as np
for embed in response.data:
print("Embeding of size:", np.asarray(embed.embedding).shape)
print("Model:", response.model)
print("Usage:", response.usage)
Tip
When creating batches of request, take into account the batch limit for each of the models. Most models have a 1024 batch limit.
Specify embeddings dimensions
You can specify the number of dimensions for the embeddings. The following example code shows how to create embeddings with 1024 dimensions. Notice that not all the embedding models support indicating the number of dimensions in the request and on those cases a 422 error is returned.
response = model.embed(
input=["The ultimate answer to the question of life"],
dimensions=1024,
)
Create different types of embeddings
Some models can generate multiple embeddings for the same input depending on how you plan to use them. This capability allows you to retrieve more accurate embeddings for RAG patterns.
The following example shows how to create embeddings that are used to create an embedding for a document that will be stored in a vector database:
from azure.ai.inference.models import EmbeddingInputType
response = model.embed(
input=["The answer to the ultimate question of life, the universe, and everything is 42"],
input_type=EmbeddingInputType.DOCUMENT,
)
When you work on a query to retrieve such a document, you can use the following code snippet to create the embeddings for the query and maximize the retrieval performance.
from azure.ai.inference.models import EmbeddingInputType
response = model.embed(
input=["What's the ultimate meaning of life?"],
input_type=EmbeddingInputType.QUERY,
)
Notice that not all the embedding models support indicating the input type in the request and on those cases a 422 error is returned. By default, embeddings of type Text are returned.
Important
Items marked (preview) in this article are currently in public preview. This preview is provided without a service-level agreement, and we don't recommend it for production workloads. Certain features might not be supported or might have constrained capabilities. For more information, see Supplemental Terms of Use for Microsoft Azure Previews.
This article explains how to use embeddings API with models deployed to Azure AI model inference in Azure AI services.
Prerequisites
To use embedding models in your application, you need:
An Azure subscription. If you're using GitHub Models, you can upgrade your experience and create an Azure subscription in the process. Read Upgrade from GitHub Models to Azure AI model inference if that's your case.
An Azure AI services resource. For more information, see Create an Azure AI Services resource.
The endpoint URL and key.
An embeddings model deployment. If you don't have one read Add and configure models to Azure AI services to add an embeddings model to your resource.
Install the Azure Inference library for JavaScript with the following command:
npm install @azure-rest/ai-inferenceTip
Read more about the Azure AI inference package and reference.
Use embeddings
First, create the client to consume the model. The following code uses an endpoint URL and key that are stored in environment variables.
import ModelClient from "@azure-rest/ai-inference";
import { isUnexpected } from "@azure-rest/ai-inference";
import { AzureKeyCredential } from "@azure/core-auth";
const client = new ModelClient(
process.env.AZURE_INFERENCE_ENDPOINT,
new AzureKeyCredential(process.env.AZURE_INFERENCE_CREDENTIAL),
"text-embedding-3-small"
);
If you have configured the resource to with Microsoft Entra ID support, you can use the following code snippet to create a client.
import ModelClient from "@azure-rest/ai-inference";
import { isUnexpected } from "@azure-rest/ai-inference";
import { DefaultAzureCredential } from "@azure/identity";
const client = new ModelClient(
process.env.AZURE_INFERENCE_ENDPOINT,
new DefaultAzureCredential(),
"text-embedding-3-small"
);
Create embeddings
Create an embedding request to see the output of the model.
var response = await client.path("/embeddings").post({
body: {
input: ["The ultimate answer to the question of life"],
}
});
Tip
When creating a request, take into account the token's input limit for the model. If you need to embed larger portions of text, you would need a chunking strategy.
The response is as follows, where you can see the model's usage statistics:
if (isUnexpected(response)) {
throw response.body.error;
}
console.log(response.embedding);
console.log(response.body.model);
console.log(response.body.usage);
It can be useful to compute embeddings in input batches. The parameter inputs can be a list of strings, where each string is a different input. In turn the response is a list of embeddings, where each embedding corresponds to the input in the same position.
var response = await client.path("/embeddings").post({
body: {
input: [
"The ultimate answer to the question of life",
"The largest planet in our solar system is Jupiter",
],
}
});
The response is as follows, where you can see the model's usage statistics:
if (isUnexpected(response)) {
throw response.body.error;
}
console.log(response.embedding);
console.log(response.body.model);
console.log(response.body.usage);
Tip
When creating batches of request, take into account the batch limit for each of the models. Most models have a 1024 batch limit.
Specify embeddings dimensions
You can specify the number of dimensions for the embeddings. The following example code shows how to create embeddings with 1024 dimensions. Notice that not all the embedding models support indicating the number of dimensions in the request and on those cases a 422 error is returned.
var response = await client.path("/embeddings").post({
body: {
input: ["The ultimate answer to the question of life"],
dimensions: 1024,
}
});
Create different types of embeddings
Some models can generate multiple embeddings for the same input depending on how you plan to use them. This capability allows you to retrieve more accurate embeddings for RAG patterns.
The following example shows how to create embeddings that are used to create an embedding for a document that will be stored in a vector database:
var response = await client.path("/embeddings").post({
body: {
input: ["The answer to the ultimate question of life, the universe, and everything is 42"],
input_type: "document",
}
});
When you work on a query to retrieve such a document, you can use the following code snippet to create the embeddings for the query and maximize the retrieval performance.
var response = await client.path("/embeddings").post({
body: {
input: ["What's the ultimate meaning of life?"],
input_type: "query",
}
});
Notice that not all the embedding models support indicating the input type in the request and on those cases a 422 error is returned. By default, embeddings of type Text are returned.
Important
Items marked (preview) in this article are currently in public preview. This preview is provided without a service-level agreement, and we don't recommend it for production workloads. Certain features might not be supported or might have constrained capabilities. For more information, see Supplemental Terms of Use for Microsoft Azure Previews.
This article explains how to use embeddings API with models deployed to Azure AI model inference in Azure AI services.
Prerequisites
To use embedding models in your application, you need:
An Azure subscription. If you're using GitHub Models, you can upgrade your experience and create an Azure subscription in the process. Read Upgrade from GitHub Models to Azure AI model inference if that's your case.
An Azure AI services resource. For more information, see Create an Azure AI Services resource.
The endpoint URL and key.
An embeddings model deployment. If you don't have one read Add and configure models to Azure AI services to add an embeddings model to your resource.
Add the Azure AI inference package to your project:
<dependency> <groupId>com.azure</groupId> <artifactId>azure-ai-inference</artifactId> <version>1.0.0-beta.1</version> </dependency>Tip
Read more about the Azure AI inference package and reference.
If you are using Entra ID, you also need the following package:
<dependency> <groupId>com.azure</groupId> <artifactId>azure-identity</artifactId> <version>1.13.3</version> </dependency>Import the following namespace:
package com.azure.ai.inference.usage; import com.azure.ai.inference.EmbeddingsClient; import com.azure.ai.inference.EmbeddingsClientBuilder; import com.azure.ai.inference.models.EmbeddingsResult; import com.azure.ai.inference.models.EmbeddingItem; import com.azure.core.credential.AzureKeyCredential; import com.azure.core.util.Configuration; import java.util.ArrayList; import java.util.List;
Use embeddings
First, create the client to consume the model. The following code uses an endpoint URL and key that are stored in environment variables.
EmbeddingsClient client = new EmbeddingsClient(
URI.create(System.getProperty("AZURE_INFERENCE_ENDPOINT")),
new AzureKeyCredential(System.getProperty("AZURE_INFERENCE_CREDENTIAL")),
"text-embedding-3-small"
);
If you have configured the resource to with Microsoft Entra ID support, you can use the following code snippet to create a client.
client = new EmbeddingsClient(
URI.create(System.getProperty("AZURE_INFERENCE_ENDPOINT")),
new DefaultAzureCredential(),
"text-embedding-3-small"
);
Create embeddings
Create an embedding request to see the output of the model.
EmbeddingsOptions requestOptions = new EmbeddingsOptions()
.setInput(Arrays.asList("The ultimate answer to the question of life"));
Response<EmbeddingsResult> response = client.embed(requestOptions);
Tip
When creating a request, take into account the token's input limit for the model. If you need to embed larger portions of text, you would need a chunking strategy.
The response is as follows, where you can see the model's usage statistics:
System.out.println("Embedding: " + response.getValue().getData());
System.out.println("Model: " + response.getValue().getModel());
System.out.println("Usage:");
System.out.println("\tPrompt tokens: " + response.getValue().getUsage().getPromptTokens());
System.out.println("\tTotal tokens: " + response.getValue().getUsage().getTotalTokens());
It can be useful to compute embeddings in input batches. The parameter inputs can be a list of strings, where each string is a different input. In turn the response is a list of embeddings, where each embedding corresponds to the input in the same position.
requestOptions = new EmbeddingsOptions()
.setInput(Arrays.asList(
"The ultimate answer to the question of life",
"The largest planet in our solar system is Jupiter"
));
response = client.embed(requestOptions);
The response is as follows, where you can see the model's usage statistics:
Tip
When creating batches of request, take into account the batch limit for each of the models. Most models have a 1024 batch limit.
Specify embeddings dimensions
You can specify the number of dimensions for the embeddings. The following example code shows how to create embeddings with 1024 dimensions. Notice that not all the embedding models support indicating the number of dimensions in the request and on those cases a 422 error is returned.
Create different types of embeddings
Some models can generate multiple embeddings for the same input depending on how you plan to use them. This capability allows you to retrieve more accurate embeddings for RAG patterns.
The following example shows how to create embeddings that are used to create an embedding for a document that will be stored in a vector database:
List<String> input = Arrays.asList("The answer to the ultimate question of life, the universe, and everything is 42");
requestOptions = new EmbeddingsOptions(input, EmbeddingInputType.DOCUMENT);
response = client.embed(requestOptions);
When you work on a query to retrieve such a document, you can use the following code snippet to create the embeddings for the query and maximize the retrieval performance.
input = Arrays.asList("What's the ultimate meaning of life?");
requestOptions = new EmbeddingsOptions(input, EmbeddingInputType.QUERY);
response = client.embed(requestOptions);
Notice that not all the embedding models support indicating the input type in the request and on those cases a 422 error is returned. By default, embeddings of type Text are returned.
Important
Items marked (preview) in this article are currently in public preview. This preview is provided without a service-level agreement, and we don't recommend it for production workloads. Certain features might not be supported or might have constrained capabilities. For more information, see Supplemental Terms of Use for Microsoft Azure Previews.
This article explains how to use embeddings API with models deployed to Azure AI model inference in Azure AI services.
Prerequisites
To use embedding models in your application, you need:
An Azure subscription. If you're using GitHub Models, you can upgrade your experience and create an Azure subscription in the process. Read Upgrade from GitHub Models to Azure AI model inference if that's your case.
An Azure AI services resource. For more information, see Create an Azure AI Services resource.
The endpoint URL and key.
An embeddings model deployment. If you don't have one read Add and configure models to Azure AI services to add an embeddings model to your resource.
Install the Azure AI inference package with the following command:
dotnet add package Azure.AI.Inference --prereleaseTip
Read more about the Azure AI inference package and reference.
If you are using Entra ID, you also need the following package:
dotnet add package Azure.Identity
Use embeddings
First, create the client to consume the model. The following code uses an endpoint URL and key that are stored in environment variables.
EmbeddingsClient client = new EmbeddingsClient(
new Uri(Environment.GetEnvironmentVariable("AZURE_INFERENCE_ENDPOINT")),
new AzureKeyCredential(Environment.GetEnvironmentVariable("AZURE_INFERENCE_CREDENTIAL"))
);
If you configured the resource to with Microsoft Entra ID support, you can use the following code snippet to create a client. Note that here includeInteractiveCredentials is set to true only for demonstration purposes so authentication can happen using the web browser. On production workloads, you should remove such parameter.
TokenCredential credential = new DefaultAzureCredential(includeInteractiveCredentials: true);
AzureAIInferenceClientOptions clientOptions = new AzureAIInferenceClientOptions();
BearerTokenAuthenticationPolicy tokenPolicy = new BearerTokenAuthenticationPolicy(credential, new string[] { "https://cognitiveservices.azure.com/.default" });
clientOptions.AddPolicy(tokenPolicy, HttpPipelinePosition.PerRetry);
client = new EmbeddingsClient(
new Uri("https://<resource>.services.ai.azure.com/models"),
credential,
clientOptions,
);
Create embeddings
Create an embedding request to see the output of the model.
EmbeddingsOptions requestOptions = new EmbeddingsOptions()
{
Input = {
"The ultimate answer to the question of life"
},
Model = "text-embedding-3-small"
};
Response<EmbeddingsResult> response = client.Embed(requestOptions);
Tip
When creating a request, take into account the token's input limit for the model. If you need to embed larger portions of text, you would need a chunking strategy.
The response is as follows, where you can see the model's usage statistics:
Console.WriteLine($"Embedding: {response.Value.Data}");
Console.WriteLine($"Model: {response.Value.Model}");
Console.WriteLine("Usage:");
Console.WriteLine($"\tPrompt tokens: {response.Value.Usage.PromptTokens}");
Console.WriteLine($"\tTotal tokens: {response.Value.Usage.TotalTokens}");
It can be useful to compute embeddings in input batches. The parameter inputs can be a list of strings, where each string is a different input. In turn the response is a list of embeddings, where each embedding corresponds to the input in the same position.
EmbeddingsOptions requestOptions = new EmbeddingsOptions()
{
Input = {
"The ultimate answer to the question of life",
"The largest planet in our solar system is Jupiter"
},
Model = "text-embedding-3-small"
};
Response<EmbeddingsResult> response = client.Embed(requestOptions);
The response is as follows, where you can see the model's usage statistics:
Tip
When creating batches of request, take into account the batch limit for each of the models. Most models have a 1024 batch limit.
Specify embeddings dimensions
You can specify the number of dimensions for the embeddings. The following example code shows how to create embeddings with 1024 dimensions. Notice that not all the embedding models support indicating the number of dimensions in the request and on those cases a 422 error is returned.
Create different types of embeddings
Some models can generate multiple embeddings for the same input depending on how you plan to use them. This capability allows you to retrieve more accurate embeddings for RAG patterns.
The following example shows how to create embeddings that are used to create an embedding for a document that will be stored in a vector database:
var input = new List<string> {
"The answer to the ultimate question of life, the universe, and everything is 42"
};
var requestOptions = new EmbeddingsOptions()
{
Input = input,
InputType = EmbeddingInputType.DOCUMENT,
Model = "text-embedding-3-small"
};
Response<EmbeddingsResult> response = client.Embed(requestOptions);
When you work on a query to retrieve such a document, you can use the following code snippet to create the embeddings for the query and maximize the retrieval performance.
var input = new List<string> {
"What's the ultimate meaning of life?"
};
var requestOptions = new EmbeddingsOptions()
{
Input = input,
InputType = EmbeddingInputType.QUERY,
Model = "text-embedding-3-small"
};
Response<EmbeddingsResult> response = client.Embed(requestOptions);
Notice that not all the embedding models support indicating the input type in the request and on those cases a 422 error is returned. By default, embeddings of type Text are returned.
Important
Items marked (preview) in this article are currently in public preview. This preview is provided without a service-level agreement, and we don't recommend it for production workloads. Certain features might not be supported or might have constrained capabilities. For more information, see Supplemental Terms of Use for Microsoft Azure Previews.
This article explains how to use embeddings API with models deployed to Azure AI model inference in Azure AI services.
Prerequisites
To use embedding models in your application, you need:
An Azure subscription. If you're using GitHub Models, you can upgrade your experience and create an Azure subscription in the process. Read Upgrade from GitHub Models to Azure AI model inference if that's your case.
An Azure AI services resource. For more information, see Create an Azure AI Services resource.
The endpoint URL and key.
- An embeddings model deployment. If you don't have one read Add and configure models to Azure AI services to add an embeddings model to your resource.
Use embeddings
To use the text embeddings, use the route /embeddings appended to the base URL along with your credential indicated in api-key. Authorization header is also supported with the format Bearer <key>.
POST https://<resource>.services.ai.azure.com/models/embeddings?api-version=2024-05-01-preview
Content-Type: application/json
api-key: <key>
If you have configured the resource with Microsoft Entra ID support, pass you token in the Authorization header:
POST https://<resource>.services.ai.azure.com/models/embeddings?api-version=2024-05-01-preview
Content-Type: application/json
Authorization: Bearer <token>
Create embeddings
Create an embedding request to see the output of the model.
{
"model": "text-embedding-3-small",
"input": [
"The ultimate answer to the question of life"
]
}
Tip
When creating a request, take into account the token's input limit for the model. If you need to embed larger portions of text, you would need a chunking strategy.
The response is as follows, where you can see the model's usage statistics:
{
"id": "0ab1234c-d5e6-7fgh-i890-j1234k123456",
"object": "list",
"data": [
{
"index": 0,
"object": "embedding",
"embedding": [
0.017196655,
// ...
-0.000687122,
-0.025054932,
-0.015777588
]
}
],
"model": "text-embedding-3-small",
"usage": {
"prompt_tokens": 9,
"completion_tokens": 0,
"total_tokens": 9
}
}
It can be useful to compute embeddings in input batches. The parameter inputs can be a list of strings, where each string is a different input. In turn the response is a list of embeddings, where each embedding corresponds to the input in the same position.
{
"model": "text-embedding-3-small",
"input": [
"The ultimate answer to the question of life",
"The largest planet in our solar system is Jupiter"
]
}
The response is as follows, where you can see the model's usage statistics:
{
"id": "0ab1234c-d5e6-7fgh-i890-j1234k123456",
"object": "list",
"data": [
{
"index": 0,
"object": "embedding",
"embedding": [
0.017196655,
// ...
-0.000687122,
-0.025054932,
-0.015777588
]
},
{
"index": 1,
"object": "embedding",
"embedding": [
0.017196655,
// ...
-0.000687122,
-0.025054932,
-0.015777588
]
}
],
"model": "text-embedding-3-small",
"usage": {
"prompt_tokens": 19,
"completion_tokens": 0,
"total_tokens": 19
}
}
Tip
When creating batches of request, take into account the batch limit for each of the models. Most models have a 1024 batch limit.
Specify embeddings dimensions
You can specify the number of dimensions for the embeddings. The following example code shows how to create embeddings with 1024 dimensions. Notice that not all the embedding models support indicating the number of dimensions in the request and on those cases a 422 error is returned.
{
"model": "text-embedding-3-small",
"input": [
"The ultimate answer to the question of life"
],
"dimensions": 1024
}
Create different types of embeddings
Some models can generate multiple embeddings for the same input depending on how you plan to use them. This capability allows you to retrieve more accurate embeddings for RAG patterns.
The following example shows how to create embeddings that are used to create an embedding for a document that will be stored in a vector database. Since text-embedding-3-small doesn't support this capability, we are using an embedding model from Cohere in the following example:
{
"model": "cohere-embed-v3-english",
"input": [
"The answer to the ultimate question of life, the universe, and everything is 42"
],
"input_type": "document"
}
When you work on a query to retrieve such a document, you can use the following code snippet to create the embeddings for the query and maximize the retrieval performance. Since text-embedding-3-small doesn't support this capability, we are using an embedding model from Cohere in the following example:
{
"model": "cohere-embed-v3-english",
"input": [
"What's the ultimate meaning of life?"
],
"input_type": "query"
}
Notice that not all the embedding models support indicating the input type in the request and on those cases a 422 error is returned. By default, embeddings of type Text are returned.