Azure Computer Vision
An Azure artificial intelligence service that analyzes content in images and video.
379 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EBS%3C/text%3E%3C/svg%3E)
I am using the basic Code for the READ OCR that Microsoft gives in their getting started guide. The only modification is that I am running that program with multiprocessing with 4 cores so I am making multiple calls to the API at the same time.
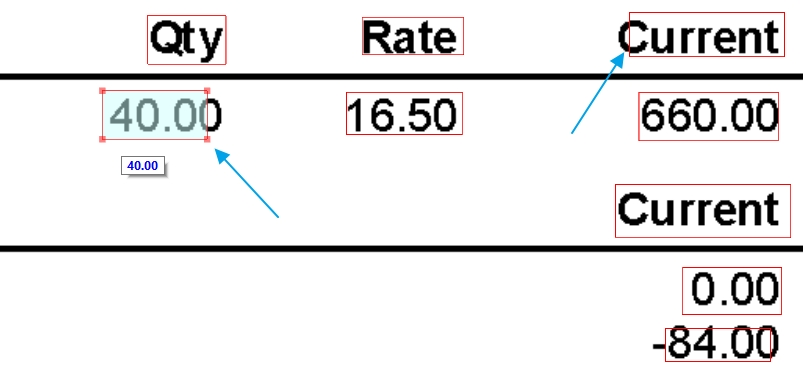
The READ OCR sometimes gives me a Bounding Box of a word that is either too large or too small for that word. You can see in the screenshot below that the word "40.00" was completely found but the bounding box is too small and does not cover the entire word. The same issue happens with the word "Current". There is cases where the bounding box is too large as well.
Any help would be appreciated!
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EGM%3C/text%3E%3C/svg%3E)
Hi, can you please provide steps to reproduce this issue? If you have a repo to share that would be helpful as well. Thanks.
Using the sample, I'm able to get great accuracy. Please share steps to reproduce the issue you've described above, thanks.

I have a parent program that creates 6-8 forks of the Sample code that Microsoft has for the Cognitive Service READ. The files that are being passed to Microsoft are on my local machine. The only difference I have in my code from the Sample code is the output is saved to a file in a specific format.
The actual results are good but the accuracy of the "boundingbox" for each word seems to be off. You can see in the image posted in the question that the value "40.00" was found read correctly but the bounding box is not aligned correctly.
Thank you
Hi, thanks for your feedback. We are still reviewing your feedback, will share updates as soon as possible. Thanks.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EET%3C/text%3E%3C/svg%3E)
it is 2024 and this problem is still there. we have it on thousands of documents. what is even more strange is that in the document intelligence studio on hover you can see the correct values displayed. it also correctly highlights the words. but the results in the json via api or in the "result" tab in studio are slightly off